机器学习第八课之K-means聚类算法
目录
简介
一、K-means 的核心思想
二、K-means 聚类的工作流程
1. 确定聚类数量 K
2.初始化 K 个簇中心
3.簇分配:将数据点分配到最近的簇
4.更新簇中心:重新计算每个簇的中心
5.判断是否收敛
6.输出聚类结果
三、聚类效果评价方式
四、k-means的API
五、案例分析
1.导入必要的库
2. 数据读取与特征选择
3. 寻找最佳 K 值(聚类数量)
4. 可视化不同 K 值的聚类效果
5. 执行最终聚类
6. 评估最终聚类结果
总结
简介
我们将聚焦于K-means 聚类算法—— 这一在无监督学习领域应用广泛且极具实用性的经典算法。无论是在数据挖掘、图像分割,还是客户分群等众多领域,K-means 都以其简洁高效的特点占据着重要地位。本节课,我们将从算法的基本原理入手,深入浅出地解析 K-means 如何通过迭代优化将数据自动划分成不同的簇,让你明白 “物以类聚” 在机器学习中的实现逻辑。我们会详细讲解算法的核心步骤,包括初始质心的选择、数据点的分配、质心的更新等关键环节,同时也会探讨算法中 K 值的确定方法以及可能遇到的问题与解决策略。此外,还会结合实际案例,展示 K-means 在真实场景中的应用,帮助你更好地理解和运用这一算法。无论你是机器学习的初学者,还是希望巩固聚类算法知识的学习者,这一课都能为你带来清晰的思路和实用的技能。
一、K-means 的核心思想
K-means 的目标是将数据集划分为 K 个簇(clusters),使得每个数据点属于距离最近的簇中心。通过反复调整簇中心的位置,K-means 不断优化簇内的紧密度,从而获得尽量紧凑、彼此分离的簇。
核心概念
- 簇(Cluster):K-means 通过最小化簇内距离的平方和,实现数据点在簇内的聚集。一个簇是具有相似性的数据点集合,这里的 “相似性” 可根据具体场景定义(如特征值接近、行为模式一致等)。例如,可将电商平台用户划分为 “高频低消用户”“低频高消用户”“偶尔消费用户” 等簇。
- 簇中心(Centroid):作为簇的 “代表点”,其坐标是簇内所有数据点对应特征的平均值,用于衡量簇的中心位置。
- 簇分配与更新:K-means 通过迭代过程优化聚类结果:先随机确定 K 个初始簇中心,然后将每个数据点分配到距离最近的簇中心所在的簇(完成簇分配);接着根据新的簇内数据点重新计算各簇的中心(完成簇中心更新);重复上述步骤,直到簇中心的位置变化小于设定阈值(收敛),最终得到稳定的聚类结果。
二、K-means 聚类的工作流程
1. 确定聚类数量 K
- 首先需要人为指定聚类的数量(即最终要得到的簇的个数),记为 K。
- K 的选择需要结合业务场景或先验知识,例如 “将用户分为 3 类”“将产品分为 5 个等级” 等。若缺乏先验信息,可通过手肘法、轮廓系数法等辅助确定(后续可延伸补充)。
2.初始化 K 个簇中心
- 从数据集中随机选择 K 个数据点,作为初始的簇中心(Centroid)。
- 初始簇中心的选择会影响最终聚类结果(可能陷入局部最优),因此实际应用中常多次随机初始化并选择最优结果,或采用 K-means++ 算法优化初始中心的选择(使初始中心彼此距离更远)。
3.簇分配:将数据点分配到最近的簇
- 计算每个数据点与 K 个簇中心的距离(常用欧氏距离,也可根据场景选择曼哈顿距离等)。
- 将每个数据点分配到 距离最近的簇中心所在的簇,形成 K 个临时簇。
4.更新簇中心:重新计算每个簇的中心
- 针对步骤 3 中得到的每个簇,计算簇内所有数据点的 均值(即每个特征维度的平均值),将这个均值作为该簇新的簇中心。
- 例如,一个簇包含数据点 (x₁,y₁)、(x₂,y₂)、(x₃,y₃),则新簇中心为 ((x₁+x₂+x₃)/3, (y₁+y₂+y₃)/3)。
5.判断是否收敛
- 比较更新后的簇中心与更新前的簇中心:
- 若所有簇中心的位置变化 小于预设的阈值(如距离变化趋近于 0),则认为聚类收敛,算法终止。
- 若未收敛,则返回步骤 3,重复 “簇分配→更新簇中心” 的过程,直到满足收敛条件。
6.输出聚类结果
- 收敛后,得到最终的 K 个簇及对应的簇中心,每个数据点都被明确分配到一个簇,聚类完成。
示例说明
假设对以下二维数据点进行 K=2 聚类:{(1,1), (1,2), (2,1), (5,5), (6,5), (5,6)}
- 随机选择初始中心:例如 (1,1) 和 (5,5);
- 簇分配:(1,1)、(1,2)、(2,1) 距离 (1,1) 更近,归为簇 1;(5,5)、(6,5)、(5,6) 距离 (5,5) 更近,归为簇 2;
- 更新中心:簇 1 新中心为 (1.33, 1.33),簇 2 新中心为 (5.33, 5.33);
- 再次分配:数据点与新中心的距离变化极小,簇分配不变,中心更新后变化趋近于 0,收敛,最终得到两个明显分离的簇。
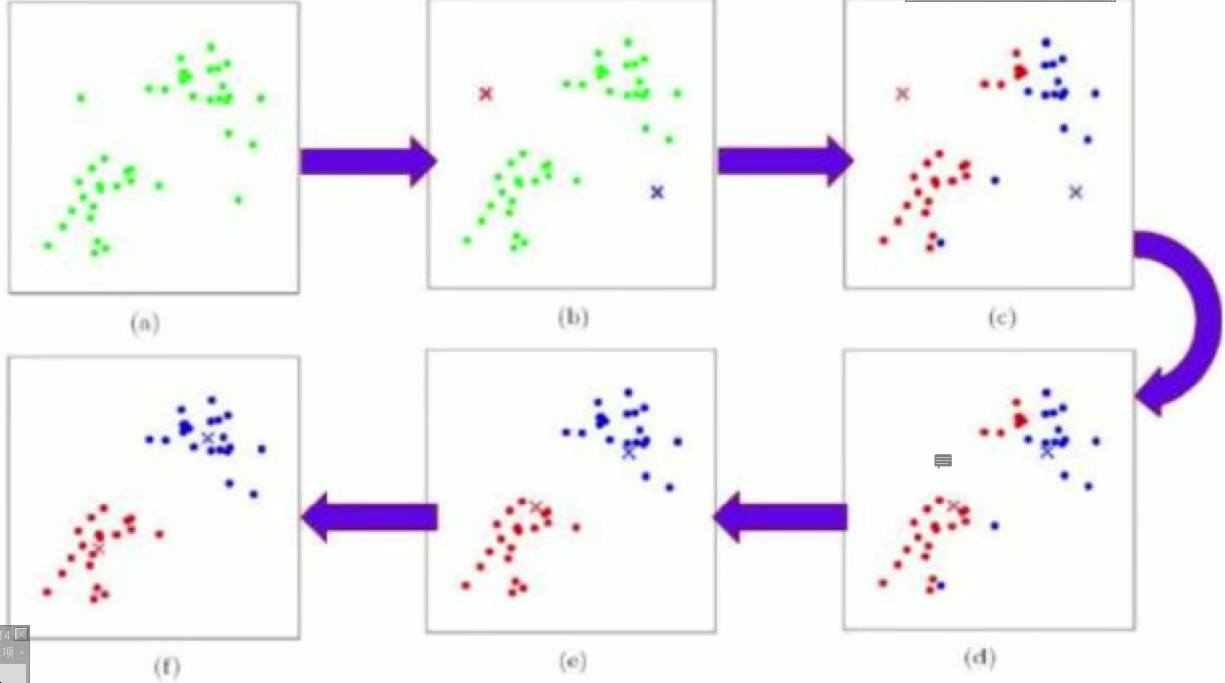
三、聚类效果评价方式
轮廓系数:
:对于第i个元素
,计算
:选取
计算所有x的轮廓系数,求出平均值即为当前聚类的整体轮廓系数。
- 轮廓系数范围在[-1,1]之间。该值越大,越合理。
- s(i)接近1,则说明样本i聚类合理;
- s(i)接近-1,则说明样本i更应该分类到另外的簇;
- 若s(i)近似为0,则说明样本i在两个簇的边界上。
四、k-means的API
class sklearn.cluster.KMeans(n_clusters=8,init='k-means++',n_init=10,max_iter=300,tol=0.0001,precompute_distances='auto',verbose=0,random_state=None,copy_x=True,n_jobs=None,algorithm='auto'
)[source]参数解释
n_clusters:- 类型:
int,默认值8 - 含义:要生成的簇(cluster)的数量,即你希望将数据集划分成多少个簇 ,比如
n_clusters=3就是划分成 3 个簇。
- 类型:
init:- 类型:
str或ndarray,默认值'k-means++' - 取值及含义:
'k-means++':一种智能初始化簇中心的方式,能让初始簇中心彼此尽可能远离,一定程度上避免因初始中心选择不佳导致聚类结果差的问题。'random':完全随机从数据集中选择初始簇中心。- 也可以传入一个形状为
(n_clusters, n_features)的ndarray,手动指定初始簇中心。
- 类型:
n_init:- 类型:
int,默认值10 - 含义:表示运行 K-Means 算法的不同初始簇中心配置的次数。算法会从这些不同的初始配置中,选取使聚类结果(比如簇内距离平方和最小)最优的那一次结果作为最终输出,增加该值可能提升结果质量,但会增加计算时间 。
- 类型:
max_iter:- 类型:
int,默认值300 - 含义:单次 K-Means 算法迭代(包括簇分配、更新簇中心过程)的最大次数,若达到该次数还未收敛(簇中心变化小于
tol等条件未满足),则停止迭代 。
- 类型:
tol:- 类型:
float,默认值0.0001 - 含义:簇中心变化的容忍度(阈值),当两次迭代中所有簇中心的变化量都小于该值时,认为算法收敛,停止迭代 。
- 类型:
precompute_distances:- 类型:
str或bool,默认值'auto' - 取值及含义:
'auto':让算法自动判断是否预先计算距离矩阵来加速计算,一般小数据集会启用预计算,大数据集可能不启用避免内存不足。True:强制预先计算距离矩阵。False:不预先计算距离矩阵,实时计算样本与簇中心的距离。
- 类型:
verbose:- 类型:
int,默认值0 - 含义:控制算法运行时的输出详细程度,
0表示不输出详细信息,1及以上会输出迭代过程中的一些日志(如每次迭代的簇内距离平方和等 )。
- 类型:
random_state:- 类型:
int、RandomState实例或None,默认值None - 含义:用于初始化簇中心的随机数生成器的种子(当
init='random'或init='k-means++'时起作用 ),设置固定值可让结果可复现,方便调试和对比实验。
- 类型:
copy_x:- 类型:
bool,默认值True - 含义:如果为
True,在计算过程中会复制原始数据X,避免直接修改原始数据;若为False,可能会在原始数据上进行一些操作(节省内存,但有修改原始数据风险 )。
- 类型:
n_jobs:- 类型:
int或None,默认值None - 含义:用于指定并行运行的作业数量,
-1表示使用所有可用的 CPU 核心并行计算,None在旧版本scikit-learn中通常等价于1(不并行 ),正数表示使用指定数量的核心,主要用于加速n_init过程中多次运行 K-Means 的情况 。
- 类型:
algorithm:- 类型:
str,默认值'auto' - 取值及含义:
'auto':让算法自动选择适合的优化算法(根据数据规模等判断,小数据用full,大数据用elkan)。'full':使用传统的 K-Means 算法实现(遍历计算距离 )。'elkan':利用三角不等式优化距离计算,在数据是稠密且簇分离较好时,计算速度更快,但对稀疏数据支持不好 。
- 类型:
五、案例分析
数据集分析
关于不同啤酒(或酒类饮品)的数据集,包含啤酒名称,卡路里,钠含量,酒精度,成本进行聚类。
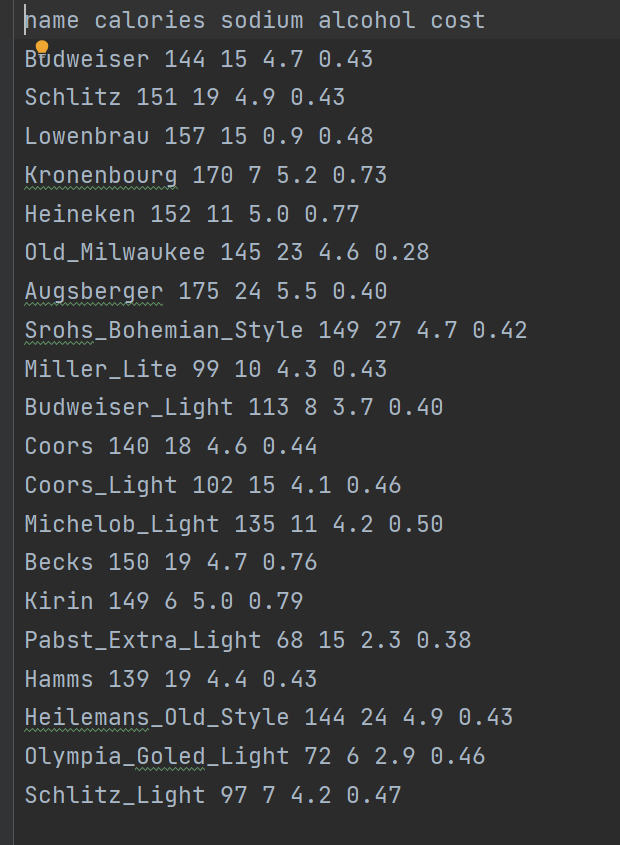
1.导入必要的库
import pandas as pd # 用于数据读取和处理
from sklearn.cluster import KMeans # 提供K-means聚类算法
from sklearn import metrics # 提供聚类评估指标(如轮廓系数)
import matplotlib.pyplot as plt # 用于数据可视化2. 数据读取与特征选择
# 读取数据文件
beer = pd.read_table("data.txt", sep=' ', encoding='utf8', engine='python')
# 选择用于聚类的特征列
X = beer[["calories", "sodium", "alcohol", "cost"]]- 从
data.txt文件中读取数据,假设该文件包含啤酒相关数据 - 选择了 4 个特征列:卡路里 (calories)、钠含量 (sodium)、酒精含量 (alcohol) 和成本 (cost) 作为聚类依据
3. 寻找最佳 K 值(聚类数量)
scores = []
for k in range(2, 10): # 测试K=2到K=9的情况# 训练K-means模型并获取聚类标签labels = KMeans(n_clusters=k).fit(X).labels_# 计算轮廓系数score = metrics.silhouette_score(X, labels)scores.append(score)- 轮廓系数 (silhouette score) 是评估聚类质量的指标,范围在 [-1, 1] 之间
- 值越接近 1,表示聚类效果越好(簇内相似度高,簇间差异大)
- 通过循环测试不同 K 值的聚类效果,为后续选择最佳 K 值做准备
[0.6917656034079486, 0.6731775046455796, 0.5857040721127795, 0.422548733517202, 0.4559182167013377, 0.43776116697963124, 0.38946337473125997, 0.39746405172426014]4. 可视化不同 K 值的聚类效果
# 打印不同K值对应的轮廓系数
print(scores)# 绘制得分结果
plt.plot(list(range(2, 10)), scores)
plt.xlabel("Number of Clusters Initialized")
plt.ylabel("Silhouette Score")
plt.show()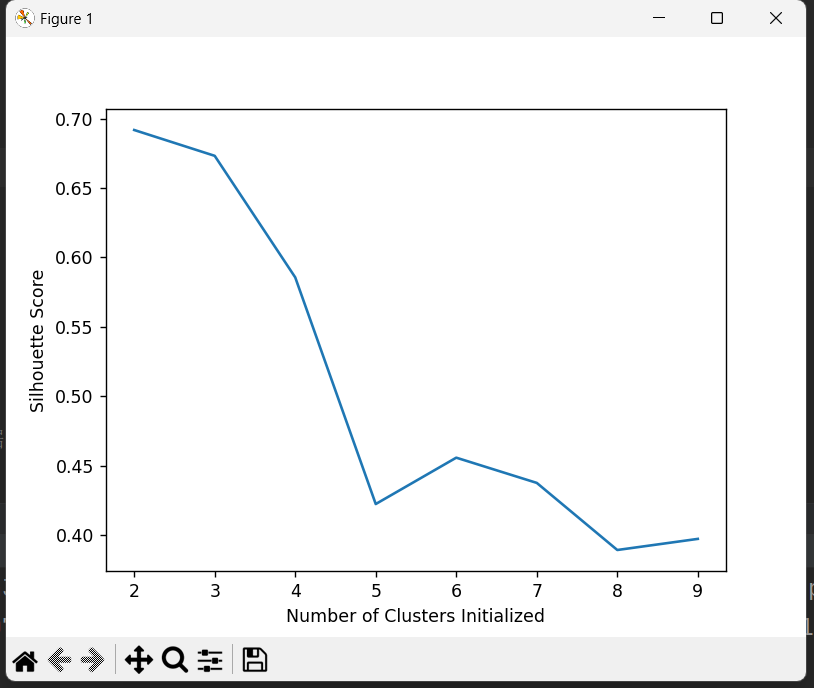
- 打印 K=2 到 K=9 对应的轮廓系数
- 绘制折线图直观展示不同 K 值的聚类效果,帮助确定最佳 K 值(通常选择轮廓系数较高的 K 值)
5. 执行最终聚类
# 选择K=2进行聚类
km = KMeans(n_clusters=2).fit(X) # 训练模型
beer['cluster'] = km.labels_ # 将聚类标签添加到原数据集- 根据前面的评估结果,选择 K=2 进行最终聚类
- 将每个样本的聚类标签(0 或 1)添加到原数据集中,方便后续分析
6. 评估最终聚类结果
# 计算最终聚类结果的轮廓系数
score = metrics.silhouette_score(X, beer.cluster)
print(score)- 单独计算 K=2 时的轮廓系数并打印
- 这个值可以作为最终聚类效果的量化评估指标
总结
K-means 是一种简洁、高效的聚类且为无监督算法,在数据聚类任务中应用广泛。它通过持续优化簇中心的位置,逐步收敛并挖掘出数据的聚类结构。不过,该算法对初始设定较为敏感,对簇的形态存在一定限制,更适用于呈球形且分布均匀的簇。