在 Elasticsearch 8.19 和 9.1 中引入更强大、更具弹性和可观测性的 ES|QL
作者:来自 Elastic Tyler Perkins

探索 Elasticsearch 8.19 和 9.1 中的 ES|QL 增强功能,包括内建的故障弹性、新的监控和可观测性能力等。
Elasticsearch 带来了大量新功能,帮助你为你的使用场景构建最佳搜索方案。深入了解我们的示例 notebooks,开始免费云试用,或立即在本地机器上尝试 Elastic。
我们很高兴宣布 Elasticsearch 8.19 和 9.1 正式发布。本次发布是 Elasticsearch Query Language( ES|QL )的一大飞跃,自去年在 8.14 版本中正式发布以来, ES|QL 每周已经在超过 10,000 个集群中使用。本次版本在四个关键主题上进行了重大增强:支持 lookup joins 的数据增强功能达到生产级、内建的故障弹性、新的监控和可观测性能力,以及支持大规模操作的强大新功能, ES|QL CCS 也已正式发布。
让我们深入了解详情。
生产级数据增强:LOOKUP JOIN 现已 GA
本次发布中最受期待的功能是 LOOKUP JOIN 现已正式发布( GA )。LOOKUP JOIN 从根本上简化了数据关联,消除了对数据反规范化或复杂低效的客户端 join 的需求。如果你对这个概念还不熟悉,我们关于 lookup join 的原始博客文章提供了很好的背景信息。
这种方式的一个关键优势是它的即时性。与需要管理策略并等待执行的摄取时 enrich processor 不同,lookup 索引可以被直接更新。然后,你下一次执行的 LOOKUP JOIN 查询就会反映这些变化,非常适合动态增强场景。
LOOKUP JOIN 命令允许你在单个查询中,用 lookup 索引中的上下文信息增强来自 source 索引的流数据。
示例:用员工目录信息增强安全日志。
FROM security_events
| WHERE event.action == "login_failure"
| KEEP event.id, event.action, emp_id
| LOOKUP JOIN employee_directory ON emp_id
| STATS failed_logins = COUNT(event.id) BY emp_department
| SORT failed_logins DESC
| KEEP emp_full_name, emp_department, failed_logins在正式发布版本中,我们让 LOOKUP JOIN 更加强大和灵活,以应对真实世界中数据的复杂性:
-
混合数值类型的 join:你的数据并不总是完美的。现在,你可以无缝地在不同但兼容的数值字段上进行 join,例如将 long 字段与 integer 字段进行 join。 ES|QL 的 LOOKUP JOIN 会自动处理类型转换。
-
索引别名支持:你现在可以使用索引别名作为 lookup 的目标,只要该别名指向有效的 lookup 索引即可。这让查询更简洁,数据管理更灵活。
-
高精度 date_nanos join:对于金融或高频可观测性等用例,lookup join 现在完全支持 date_nanos 字段类型,确保精度不丢失。
在底层,新优化让 join 更快,通过删除不必要的操作和重新排序查询执行。在数据节点上,只有执行 join 所需的字段才会从索引中加载;如果这些字段完全缺失,join 会被一个快速 no-op 替代,在 lookup 列中填充 null。为实现这一点, ES|QL 的查询优化器会进行多次查询重写。在这些优化中,我们将 KEEP / DROP / RENAME 命令的执行推迟到 join 之后,因为这些命令会触发从索引加载所有参与查询的字段。每个数据节点还会进行一次优化器 pass,使用索引分片的统计信息判断 join key 字段是否缺失,若缺失, LOOKUP JOIN 将被替换为一个快速的 EVAL,仅为 lookup 字段创建 null 值。
完整指南请查阅 LOOKUP JOIN 文档。敬请期待 —— 我们还有更多增强和其他 join 类型在开发中!
默认具备更强弹性的查询引擎
分布式系统必须具备弹性。在本次发布中, ES|QL 现在显著更加稳健。
我们引入了新的 allow_partial_results 设置,默认启用。这意味着如果某个分片暂时不可用,你的 ES|QL 查询将会成功返回来自所有可用分片的结果,而不是完全失败。
此外, skip_unavailable 设置(默认启用)现在涵盖大多数远程集群上的运行时错误,允许查询在某个远程集群无法返回结果时,从其他集群获取剩余结果。你可以检查响应中的 is_partial 标志,判断结果是部分还是完整。
此外, ES|QL 现在会自动在分片级失败时重试。这在执行滚动重启或节点暂时不可用等操作时非常有价值,因为查询成功完成的概率大大提高,无需任何人工干预。
显著的性能与可扩展性提升
在 8.19 和 9.1 版本中, ES|QL 更加智能、更快、更具可扩展性。超过 30 项增强合并后,查询引擎在执行规划和集群资源分配方面更加高效。
-
向 Lucene 的激进下推:通过将更多操作下推到 Lucene 存储引擎,实现了大幅性能提升。对于文本使用 == 的过滤器、 LIKE、 STARTS_WITH、 ENDS_WITH 现在在分片级由 Lucene 执行,9.1 还新增支持大小写不敏感的正则。这大幅减少了需要传输到协调节点处理的数据量,从而带来显著速度提升( == 的性能提升达 86 倍, ROUND_TO 比 CASE 快超 170 倍)。
更智能的查询规划与执行: ES|QL 现在使用更先进的启发式方法选择最高效的查询分区策略,并优先查询热点数据层,以更快返回结果。
- ES|QL 查询执行分为两个部分:协调节点(用于解析查询、分析、准备查询计划并合并/聚合结果)和数据节点(实际查询对应的 Lucene 数据结构)。从 8.19 和 9.1 开始,查询在数据节点上的路由方式有所不同。对于非聚合和非排序查询,我们会优先定位到热点数据节点。
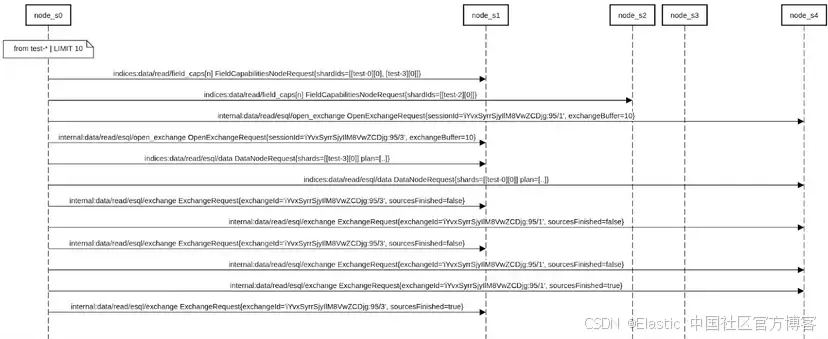
- 此外,我们一次只执行少量子请求。这使得简单查询如
FROM index WHERE @timestamp …或FROM index* WHERE @timestamp …的响应计算更快,整体减轻集群负载,也避免了访问冷节点和 frozen 节点,因为缓存为空时查询代价可能更高。对于更复杂的查询(如FROM index | STATS ..或FROM index | SORT ...,需要检查所有数据以计算正确结果),会立即将查询路由到所有包含相关数据的节点,以确保更好的并行性和更快的响应时间。
内存和 CPU 使用优化:我们优化了 ES|QL 中许多常见操作的内部实现,显著提升性能(一些改进甚至移植到 9.0)。
- 针对 ordinal 输入的 VALUES 聚合速度提升约 2.4 倍,基于之前的改进。字符串转换函数如 TO_LOWER 和 TO_UPPER 通过保持数据为 ordinal 形式进行了优化,在存在重复值的情况下减少了开销。基准测试显示,执行时间从约 30–35 ns/op 降至约 0.025–0.027 ns/op,但这是由于 ordinal 重用带来的摊销成本下降,而非每个值的实际执行时间。
- 我们还加快了 stored fields 的加载速度,极大降低了检索大量结果集时的查询延迟。在一个一百万文档的索引中,返回约 10% 文档的查询现在约需 55 ms(之前为 397 ms),加载约 99% 文档的速度提升近 10 倍。
- 最后,我们提升了内存和 CPU 效率: TO_IP 函数执行速度提升约 2 倍,节点间序列化更高效, REPLACE 函数行为更新,现在在 fold 阶段强制内存限制,防止查询执行前集群出现 OOM。
ES|QL 大规模支持:跨集群搜索(CCS)现已正式发布
对于企业用户来说, ES|QL 跨集群搜索(CCS)正式发布是一个重要里程碑。这个强大功能允许你运行单个 ES|QL 查询,轻松访问跨多个独立 Elasticsearch 集群的 PB 级数据。
这对管理大型分布式环境的组织至关重要。你现在可以跨地理位置分散的数据中心查询数据,打破用于不同工作负载(如安全与可观测性)的集群间数据孤岛,或者通过 ES|QL 从单一视图统一查询整个基础设施。
增强的可观测性:了解查询行为
理解查询行为是维护健康高效集群的关键。本次发布为 ES|QL 引入了强大的新可观测性功能。
-
ES|QL 查询日志:你现在可以启用所有 ES|QL 查询的日志记录,存入专用文件。将该日志文件导入 Elasticsearch 后,可以获得历史记录,帮助识别慢查询或高成本查询,并分析使用趋势。
-
实时监控与分析(技术预览):新增的 List Queries API 提供了查看集群中所有正在运行的 ES|QL 查询的简单直接方式。我们还增强了查询分析输出,提供更细粒度的细节,方便你和支持团队调试具体查询的性能。
以下是一个基本示例。(请注意, List Queries API 仍处于技术预览阶段,可能会有所变动。)
{"queries" : {"Fkl5bkNaSnVHUUNtNW5GRHRwRlZPM3ccMkF0amUzWS1SYUN3ZFNCZVBYUjVwZzoxMzIxOQ==" : {"start_time_millis" : 1753374493702,"running_time_nanos" : 1920294,"query" : "FROM ....."}}
}新功能与基础能力
本次发布还通过新功能和能力扩展了 ES|QL 的威力:
-
LLM completion 支持:9.1 版本技术预览新增 COMPLETION 命令,支持在查询中访问 LLM completion,开启强大新用例 —— 敬请期待后续关于 completions 的博客。
-
全文函数正式发布,新增 MATCH_PHRASE:强大的 MATCH、 QSTR 和 KQL 函数现已 GA。我们还新增了备受期待的 MATCH_PHRASE 函数,用于执行短语查询。
-
FORK:9.1 技术预览中新命令,允许你运行多个查询,对结果进行区分、变换和合并。
-
新命令与聚合:通过新命令 SAMPLE 实现对大规模数据集的随机抽样。新增的 ML Change Point 聚合帮助你自动检测时间序列数据中的异常变化。
-
新分析函数:新增一系列函数,包括灵活的 ROUND_TO、支持模式列表的增强 LIKE,以及数学函数 COPY_SIGN 和 SCALB。
立即开始
内容太多,单篇博客难以涵盖,建议查看 Elasticsearch 8.19 和 9.1 发布说明,获取所有改动的完整列表。
-
在 Elastic Cloud上开启免费试用或体验 Serverless。
-
下载 Elasticsearch,自行在基础设施上运行。
-
加入社区论坛交流,提出问题。
我们期待看到你用新 ES|QL 探索出哪些精彩内容。
原文:https://www.elastic.co/search-labs/blog/esql-elasticsearch-8-19-9-1