适用于 Windows 和 Linux 的 Yolo全栈算法之开源项目学习
适用于 Windows 和 Linux 的 Yolo v4、v3 和 v2
- 阅读常见问题解答:Programming Comments - Darknet FAQ
- 加入 Darknet/YOLO Discord:https://discord.gg/zSq8rtW
- Darknet/YOLO 的推荐 GitHub 仓库:https://github.com/hank-ai/darknetcv/
- Hank.ai 和 Darknet/YOLO:HANK - Darknet Welcomes Hank.ai as Official Sponsor!
(用于对象检测的神经网络)
-
论文 YOLOv7:[2207.02696] YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
-
源代码 YOLOv7 - Pytorch(用于重现结果):https://github.com/WongKinYiu/yolov7
-
论文 YOLOv4:[2004.10934] YOLOv4: Optimal Speed and Accuracy of Object Detection
-
源代码 YOLOv4 - 暗网(用于重现结果):https://github.com/AlexeyAB/darknet
-
论文缩放 YOLOv4 (CVPR 2021):CVPR 2021 Open Access Repository
-
源代码 Scaled-YOLOv4 - Pytorch(用于重现结果):https://github.com/WongKinYiu/ScaledYOLOv4
YOLOv7:可训练的免费赠品袋为实时对象检测器设定了新的技术水平
-
论文:[2207.02696] YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
-
源代码 - Pytorch(用于重现结果):https://github.com/WongKinYiu/yolov7
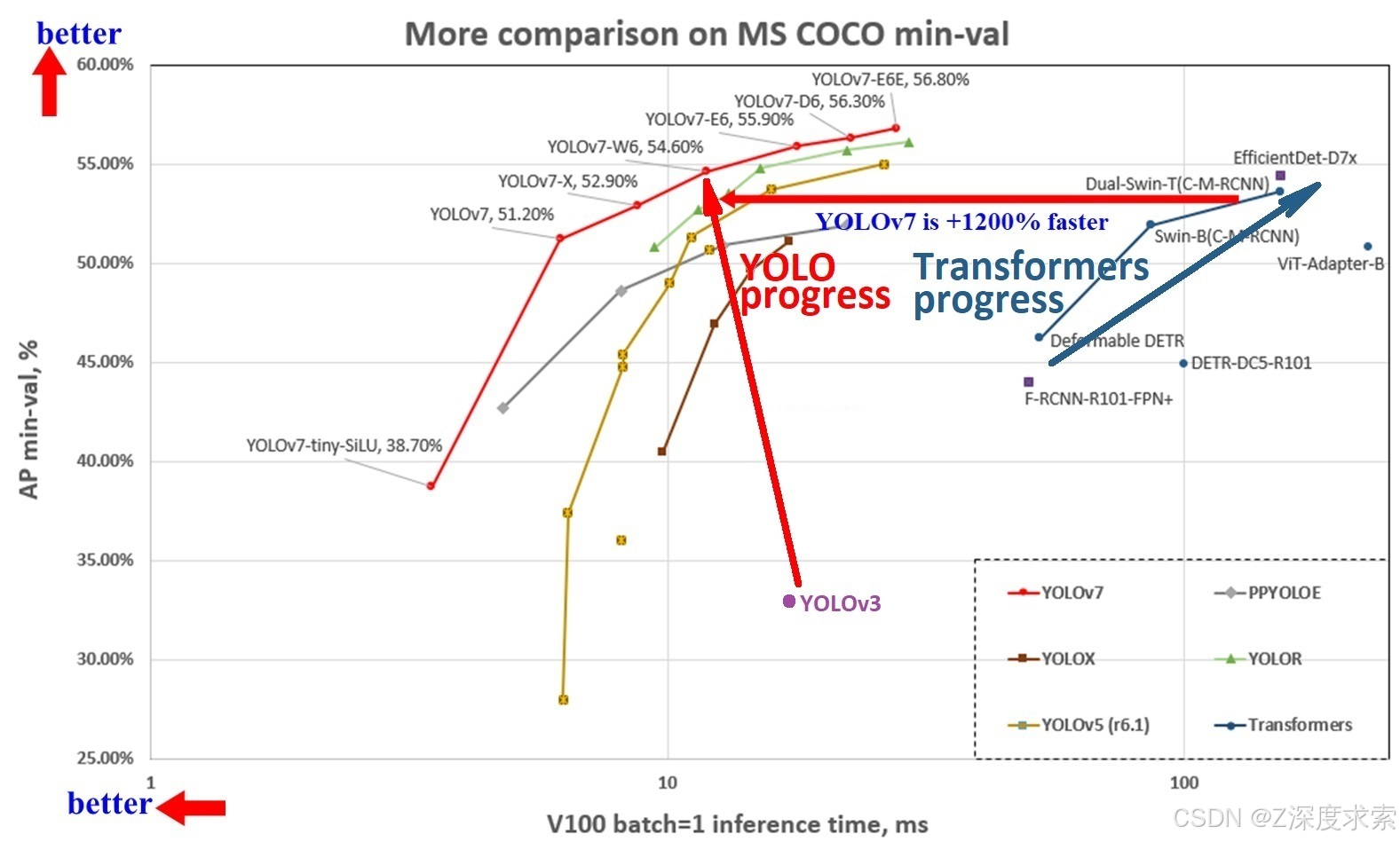
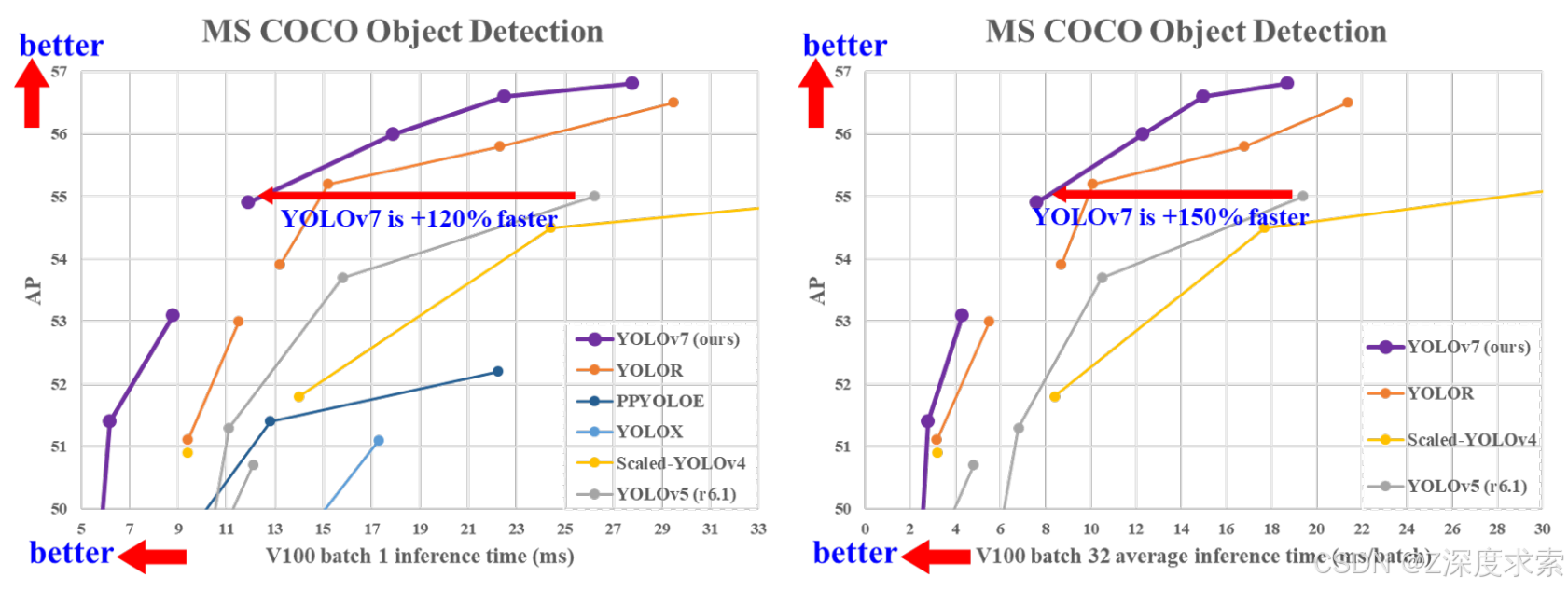
YOLOv7 比 YOLOv5 更准确、更快 120% FPS,比 YOLOX 高 180% FPS,比 Dual-Swin-T 高 1200% FPS,比 ConvNext 高 550% FPS,比 SWIN-L 高 500% FPS,比 PPYOLOE-X 高 150% FPS。
YOLOv7 在 5 FPS 到 160 FPS 的范围内在速度和精度上都超过了所有已知的对象检测器,并且在 GPU V100 上具有 30 FPS 或更高的所有已知实时对象检测器中最高的准确率 56.8% AP,batch=1。
- YOLOv7-e6(55.9% AP,56 FPS V100 b=1)的 FPS 比 SWIN-L C-M-RCNN(53.9% AP,9.2 FPS A100 b=1)快
+500% - YOLOv7-e6(55.9% AP,56 FPS V100 b=1)的 FPS 比 ConvNeXt-XL C-M-RCNN(55.2% AP,8.6 FPS A100 b=1)快
+550% - YOLOv7-w6(54.6% AP,84 FPS V100 b=1)的 FPS 比 YOLOv5-X6-r6.1(55.0% AP,38 FPS V100 b=1)快
+120% - YOLOv7-w6(54.6% AP,84 FPS V100 b=1)比 Dual-Swin-T C-M-RCNN(53.6% AP,6.5 FPS V100 b=1)快 FPS
+1200% - YOLOv7x(52.9% AP,114 FPS V100 b=1)比 PPYOLOE-X(51.9% AP,45 FPS V100 b=1)快 FPS
+150% - YOLOv7(51.2% AP,161 FPS V100 b=1)比 YOLOX-X(51.1% AP,58 FPS V100 b=1)快 FPS
+180%
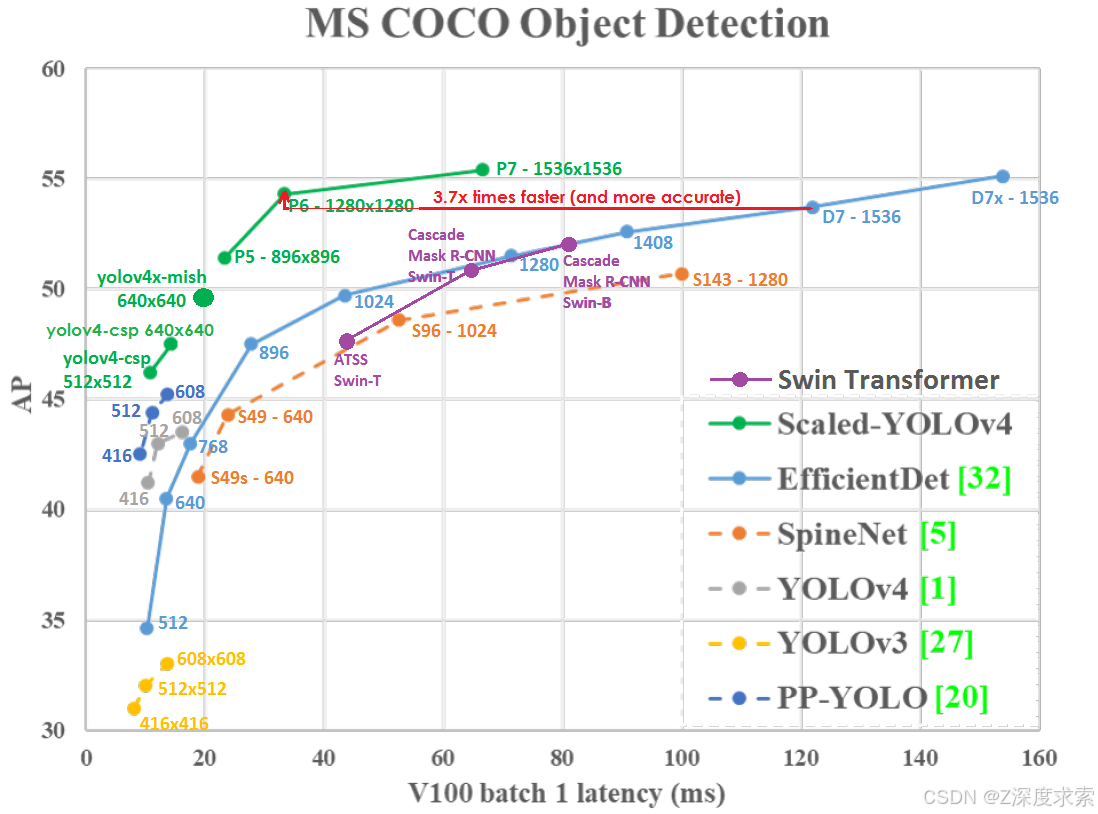
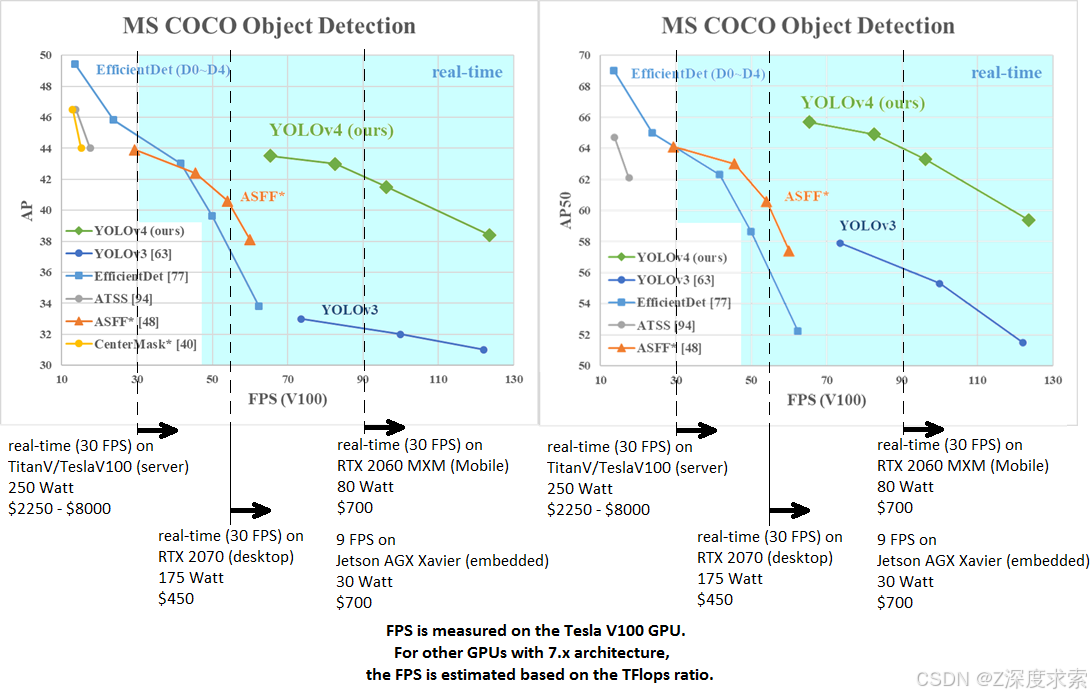
在 medium 上的文章中了解更多详情:
- Scaled_YOLOv4
- YOLOv4
手册:https://github.com/AlexeyAB/darknet/wiki
讨论:
- 不和
关于 Darknet 框架:Darknet: Open Source Neural Networks in C

-
YOLOv4 model zoo
-
Requirements (and how to install dependencies)
-
Pre-trained models
-
FAQ - frequently asked questions
-
Explanations in issues
-
Yolo v4 in other frameworks (TensorRT, TensorFlow, PyTorch, OpenVINO, OpenCV-dnn, TVM,...)
-
Datasets
-
Yolo v4, v3 and v2 for Windows and Linux
- (neural networks for object detection)
- GeForce RTX 2080 Ti
- Youtube video of results
- How to evaluate AP of YOLOv4 on the MS COCO evaluation server
- How to evaluate FPS of YOLOv4 on GPU
- Pre-trained models
- Requirements for Windows, Linux and macOS
- Yolo v4 in other frameworks
- Datasets
- Improvements in this repository
- How to use on the command line
- For using network video-camera mjpeg-stream with any Android smartphone
- How to use on the command line
- How to compile on Linux/macOS (using CMake)
- Using also PowerShell
- How to compile on Linux (using make)
- How to compile on Windows (using CMake)
- How to compile on Windows (using vcpkg)
- GeForce RTX 2080 Ti
- How to train with multi-GPU
- How to train (to detect your custom objects)
- How to train tiny-yolo (to detect your custom objects)
- When should I stop training
- Custom object detection
- How to improve object detection
- How to mark bounded boxes of objects and create annotation files
- How to use Yolo as DLL and SO libraries
- Citation
- (neural networks for object detection)
AP50:95 - FPS (Tesla V100) Paper: [2011.08036] Scaled-YOLOv4: Scaling Cross Stage Partial Network
AP50:95 / AP50 - FPS (Tesla V100) Paper: [2004.10934] YOLOv4: Optimal Speed and Accuracy of Object Detection
tkDNN-TensorRT accelerates YOLOv4 ~2x times for batch=1 and 3x-4x times for batch=4.
- tkDNN: https://github.com/ceccocats/tkDNN
- OpenCV: https://gist.github.com/YashasSamaga/48bdb167303e10f4d07b754888ddbdcf
GeForce RTX 2080 Ti
| Network Size | Darknet, FPS (avg) | tkDNN TensorRT FP32, FPS | tkDNN TensorRT FP16, FPS | OpenCV FP16, FPS | tkDNN TensorRT FP16 batch=4, FPS | OpenCV FP16 batch=4, FPS | tkDNN Speedup |
|---|---|---|---|---|---|---|---|
| 320 | 100 | 116 | 202 | 183 | 423 | 430 | 4.3x |
| 416 | 82 | 103 | 162 | 159 | 284 | 294 | 3.6x |
| 512 | 69 | 91 | 134 | 138 | 206 | 216 | 3.1x |
| 608 | 53 | 62 | 103 | 115 | 150 | 150 | 2.8x |
| Tiny 416 | 443 | 609 | 790 | 773 | 1774 | 1353 | 3.5x |
| Tiny 416 CPU Core i7 7700HQ | 3.4 | - | - | 42 | - | 39 | 12x |
- Yolo v4 Full comparison: map_fps
- Yolo v4 tiny comparison: tiny_fps
- CSPNet: paper and map_fps comparison: https://github.com/WongKinYiu/CrossStagePartialNetworks
- Yolo v3 on MS COCO: Speed / Accuracy (mAP@0.5) chart
- Yolo v3 on MS COCO (Yolo v3 vs RetinaNet) - Figure 3: https://arxiv.org/pdf/1804.02767v1.pdf
- Yolo v2 on Pascal VOC 2007: https://hsto.org/files/a24/21e/068/a2421e0689fb43f08584de9d44c2215f.jpg
- Yolo v2 on Pascal VOC 2012 (comp4): https://hsto.org/files/3a6/fdf/b53/3a6fdfb533f34cee9b52bdd9bb0b19d9.jpg
Youtube video of results

其他: https://www.youtube.com/user/pjreddie/videos
如何在 MS COCO 评估服务器上评估 YOLOv4 的 AP
- 从 MS COCO 服务器下载并解压缩 test-dev2017 数据集:http://images.cocodataset.org/zips/test2017.zip
- 下载 Detection 任务的图像列表,并将路径替换为您的路径:https://raw.githubusercontent.com/AlexeyAB/darknet/master/scripts/testdev2017.txt
- 下载文件 245 MB: yolov4.weights (Google-drive 镜像 yolov4.weights
yolov4.weights) - 文件内容应为
cfg/coco.data
classes= 80
train = <replace with your path>/trainvalno5k.txt
valid = <replace with your path>/testdev2017.txt
names = data/coco.names
backup = backup
eval=coco
- 使用可执行文件在 附近创建文件夹
/results/./darknet - 运行验证:
./darknet detector valid cfg/coco.data cfg/yolov4.cfg yolov4.weights - 将文件重命名为 and compress it to
/results/coco_results.jsondetections_test-dev2017_yolov4_results.jsondetections_test-dev2017_yolov4_results.zip - 将文件提交到 MS COCO 评估服务器,以便
detections_test-dev2017_yolov4_results.ziptest-dev2019 (bbox)
如何在 GPU 上评估 YOLOv4 的 FPS
- 编译暗网
GPU=1 CUDNN=1 CUDNN_HALF=1 OPENCV=1Makefile - 下载文件 245 MB: yolov4.weights (Google-drive 镜像 yolov4.weights
yolov4.weights) - 获取任意 .avi/.mp4 视频文件(最好不超过 1920x1080,以避免 CPU 性能瓶颈)
- 运行以下两个命令之一并查看 AVG FPS:
- 包括 video_capturing + NMS + drawing_bboxes:
./darknet detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights test.mp4 -dont_show -ext_output - 排除 video_capturing + NMS + drawing_bboxes:
./darknet detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights test.mp4 -benchmark
预训练模型
有用于不同 cfg 文件的 weights-file(针对 MS COCO 数据集进行训练):
RTX 2070 (R) 和 Tesla V100 (V) 上的 FPS:
-
yolov4-p6.cfg - 1280x1280 - 72.1% mAP@0.5 (54.0% AP@0.5:0.95) - 32(V) FPS - xxx BFlops (xxx FMA) - 487 MB: yolov4-p6.weights
- 用于训练的预训练权重:https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-p6.conv.289
-
yolov4-p5.cfg - 896x896 - 70.0% mAP@0.5 (51.6% AP@0.5:0.95) - 43(V) FPS - xxx BFlops (xxx FMA) - 271 MB: yolov4-p5.weights
- 用于训练的预训练权重:https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-p5.conv.232
-
yolov4-csp-x-swish.cfg - 640x640 - 69.9% mAP@0.5 (51.5% AP@0.5:0.95) - 23(R) FPS / 50(V) FPS - 221 BFlops (110 FMA) - 381 MB: yolov4-csp-x-swish.weights
- 用于训练的预训练权重:https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-csp-x-swish.conv.192
-
yolov4-csp-swish.cfg - 640x640 - 68.7% mAP@0.5 (50.0% AP@0.5:0.95) - 70(V) FPS - 120 (60 FMA) - 202 MB: yolov4-csp-swish.weights
- 用于训练的预训练权重:https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-csp-swish.conv.164
-
yolov4x-mish.cfg - 640x640 - 68.5% mAP@0.5 (50.1% AP@0.5:0.95) - 23(R) FPS / 50(V) FPS - 221 BFlops (110 FMA) - 381 MB: yolov4x-mish.weights
- 用于训练的预训练权重:https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4x-mish.conv.166
-
yolov4-csp.cfg - 202 MB: yolov4-csp.weights 论文缩放版 Yolo v4
只需更改文件中的 and 参数,并在所有情况下使用相同的文件:
width=height=yolov4-csp.cfgyolov4-csp.weightswidth=640 height=640在 CFG 中:67.4% mAP@0.5 (48.7% AP@0.5:0.95) - 70(V) FPS - 120 (60 FMA) BFlopswidth=512 height=512在 CFp 中:64.8% mAP@0.5 (46.2% AP@0.5:0.95) - 93(V) FPS - 77 (39 FMA) BFlops- 用于训练的预训练权重:https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-csp.conv.142
-
yolov4.cfg - 245 MB: yolov4.weights (Google-drive 镜像 yolov4.weights ) 纸质 Yolo v4 只需更改文件中的参数,并在所有情况下使用相同的文件:
width=height=yolov4.cfgyolov4.weightswidth=608 height=608在 cfg 中:65.7% mAP@0.5 (43.5% AP@0.5:0.95) - 34(R) FPS / 62(V) FPS - 128.5 BFlopswidth=512 height=512在 cfg 中:64.9% mAP@0.5 (43.0% AP@0.5:0.95) - 45(R) FPS / 83(V) FPS - 91.1 BFlopswidth=416 height=416在 cfg 中:62.8% mAP@0.5 (41.2% AP@0.5:0.95) - 55(R) FPS / 96(V) FPS - 60.1 BFlopswidth=320 height=320在 cfg 中:60% mAP@0.5 ( 38% AP@0.5:0.95) - 63(R) FPS / 123(V) FPS - 35.5 BFlops
-
yolov4-tiny.cfg - 40.2% mAP@0.5 - 371(1080Ti) FPS / 330(RTX2070) FPS - 6.9 BFlops - 23.1 MB: yolov4-tiny.weights
-
enet-coco.cfg (EfficientNetB0-Yolov3) - 45.5% mAP@0.5 - 55(R) FPS - 3.7 BFlops - 18.3 MB: enetb0-coco_final.weights
-
yolov3-openimages.cfg - 247 MB - 18(R) FPS - OpenImages 数据集:yolov3-openimages.weights
CLICK ME - Yolo v3 模型
CLICK ME - Yolo v2 模型
放在 Near: compiled: darknet.exe
你可以通过路径获取 cfg-files:darknet/cfg/
Windows、Linux 和 macOS 的要求
- CMake >= 3.18: Download CMake
- Powershell(已在 Windows 上安装):Install PowerShell on Windows, Linux, and macOS - PowerShell | Microsoft Learn
- CUDA >= 10.2 :CUDA Toolkit Archive | NVIDIA Developer(在 Linux 上执行安装后作))
- OpenCV >= 2.4:使用你喜欢的包管理器(brew、apt),使用 vcpkg 从源代码构建或从 OpenCV 官方网站下载(在 Windows 上设置系统变量 = - where are the and folders image
OpenCV_DIRC:\opencv\buildincludex64) - cuDNN >= 8.0.2 cuDNN Archive | NVIDIA Developer(在 Linux 上,请按照此处描述的步骤作 https://docs.nvidia.com/deeplearning/sdk/cudnn-install/index.html#installlinux-tar,在 Windows 上,请遵循此处描述的步骤 https://docs.nvidia.com/deeplearning/sdk/cudnn-install/index.html#installwindows)
- CC >= 3.0 的 GPU:https://en.wikipedia.org/wiki/CUDA#GPUs_supported
其他框架中的 Yolo v4
- Pytorch - Scaled-YOLOv4:https://github.com/WongKinYiu/ScaledYOLOv4
- TensorFlow 的: TensorFlow 2.0 / TFlite / Android 上的 YOLOv4:https://github.com/hunglc007/tensorflow-yolov4-tflite 官方 TF 模型:https://github.com/tensorflow/models/tree/master/official/vision/beta/projects/yolo 对于 YOLOv4 - 使用 TNTWEN 项目将 / 文件转换为 TensorFlow-lite
pip install yolov4yolov4.weightscfgyolov4.pbyolov4.tflite - OpenCV 是 CPU(x86/ARM-Android)最快的 YOLOv4 实现,OpenCV 可以使用 OpenVINO 后端编译以运行在(Myriad X / USB 神经计算棒 / Arria FPGA)上,使用 / 与:C++ 示例或 Python 示例
yolov4.weightscfg - Intel OpenVINO 2021.2:支持 YOLOv4(NPU Myriad X / USB 神经电脑棒 / Arria FPGA):https://devmesh.intel.com/projects/openvino-yolov4-49c756 阅读本手册(旧手册)(对于 Scaled-YOLOv4 型号使用 https://github.com/Chen-MingChang/pytorch_YOLO_OpenVINO_demo )
- PyTorch > ONNX的:
- 黄健尧/PyTorch_YOLOv4
- maudzung/3D-YOLOv4
- 天小陌/pytorch-YOLOv4
- YOLOv5
- 适用于 YOLOv4 的 Jetson 上的 ONNX:Announcing ONNX Runtime Availability in the NVIDIA Jetson Zoo for High Performance Inferencing | NVIDIA Technical Blog 和 https://github.com/ttanzhiqiang/onnx_tensorrt_project
- nVidia 迁移学习工具包 (TLT>=3.0)训练和检测 YOLOv4 — Transfer Learning Toolkit 3.0 documentation
- TensorRT+tkDNN:https://github.com/ceccocats/tkDNN#fps-results
- DeepStream 4.0 和 PDF 原生支持适用于 YOLOv4 https://github.com/NVIDIA-AI-IOT/yolov4_deepstream 或 https://github.com/marcoslucianops/DeepStream-Yolo 读取 Yolo 的 Deepstream 5.0 / TensorRT。此外,jkjung-avt/tensorrt_demos 或 wang-xinyu/tensorrtx
- Triton 推理服务器 / TensorRT https://github.com/isarsoft/yolov4-triton-tensorrt
- DirectML https://github.com/microsoft/DirectML/tree/master/Samples/yolov4
- OpenCL (适用于macOS和GNU/Linux的Intel, AMD, Mali GPU) https://github.com/sowson/darknet
- HIP 在 AMD GPU https://github.com/os-hackathon/darknet 上用于训练和检测
- ROS(机器人作系统)https://github.com/engcang/ros-yolo-sort
- Xilinx Zynq Ultrascale+ 深度学习处理器 (DPU) ZCU102/ZCU104:https://github.com/Xilinx/Vitis-In-Depth-Tutorial/tree/master/Machine_Learning/Design_Tutorials/07-yolov4-tutorial
- 使用 Keras URL,对于基于 TensorFlow 的 YOLOv4 模型,Amazon Neurochip/Amazon EC2 Inf1 实例的吞吐量提高了 1.85 倍,每张图像的成本降低了 37%
- TVM - 将深度学习模型(Keras、MXNet、PyTorch、Tensorflow、CoreML、DarkNet)编译成各种硬件后端(CPU、GPU、FPGA 和专用加速器)上的最小可部署模块:Redirecting…
- Tencent/ncnn:YOLOv4 在手机端推理最快的 CPU:https://github.com/Tencent/ncnn
- OpenDataCam - 它使用 YOLOv4 检测、跟踪和计数移动的物体:https://github.com/opendatacam/opendatacam#-hardware-pre-requisite
- Netron - 神经网络可视化工具:https://github.com/lutzroeder/netron
数据
- MS COCO:用于获取标记的 MS COCO 检测数据集
./scripts/get_coco_dataset.sh - OpenImages:用于标记训练检测数据集
python ./scripts/get_openimages_dataset.py - Pascal VOC:用于标记 Train/Test/Val 检测数据集
python ./scripts/voc_label.py - ILSVRC2012 (ImageNet 分类):使用(也用于标记有效集)
./scripts/get_imagenet_train.shimagenet_label.sh - 用于检测的德语/比利时/俄语/LISA/MASTIF 交通标志数据集 - 使用以下解析器:https://github.com/angeligareta/Datasets2Darknet#detection-task
- 其他数据集列表:https://github.com/AlexeyAB/darknet/tree/master/scripts#datasets
此存储库中的改进
- 开发最先进的物体检测器 YOLOv4
- 添加了最先进的模型:CSP、PRN、EfficientNet
- 添加的图层:[conv_lstm]、[scale_channels] SE/ASFF/BiFPN、[local_avgpool]、[sam]、[Gaussian_yolo]、[reorg3d](固定的 [reorg])、固定的 [batchnorm]
- 添加了训练递归模型(使用层 CONV-LSTM/CONV-RNN)以准确检测视频的功能
[conv_lstm][crnn] - 添加了数据增强: 。新增激活:SWISH、MISH、NORM_CHAN NORM_CHAN_SOFTMAX
[net] mixup=1 cutmix=1 mosaic=1 blur=1 - 增加了使用 CPU-RAM 通过 GPU 处理进行训练的功能,以提高mini_batch_size并提高准确性(而不是批量规范同步)
- 如果您使用此 XNOR-net 模型(bit-1 推理)训练自己的权重,则在 CPU 和 GPU 上将二进制神经网络检测性能提高了 2 到 4 倍:https://github.com/AlexeyAB/darknet/blob/master/cfg/yolov3-tiny_xnor.cfg
- 通过将 2 层融合为 1 层,将神经网络性能提高 ~7%:卷积 + 批量范数
- 改进的性能:在 GPU Volta/Turing(Tesla V100、GeForce RTX 等)上使用 Tensor Core(如果在 或 中定义)进行 2 次检测
CUDNN_HALFMakefiledarknet.sln - 将全高清性能提高 ~1.2 倍,在 4K 上提高 ~2 倍,用于视频(文件/流)检测...
darknet detector demo - 性能提升 3.5 倍的训练数据增强(使用 OpenCV SSE/AVX 函数而不是手写函数)- 消除了在多 GPU 或 GPU Volta 上训练的瓶颈
- 使用 AVX 提高了 Intel CPU 上的检测和训练性能 (Yolo v3 ~85%))
- 优化了 when 网络大小调整期间的内存分配
random=1 - 优化了用于检测的 GPU 初始化 - 我们最初使用 batch=1 而不是使用 batch=1 重新初始化
- 添加了使用命令 ...
darknet detector map - 添加了训练期间平均损失和准确率 mAP(标志)图表的绘制
-map - 作为 JSON 和 MJPEG 服务器运行,以使用您的软件或 Web 浏览器通过网络在线获取结果
./darknet detector demo ... -json_port 8070 -mjpeg_port 8090 - 添加了用于训练的锚点计算
- 添加了检测和跟踪对象示例:https://github.com/AlexeyAB/darknet/blob/master/src/yolo_console_dll.cpp
- 运行时提示和警告(如果使用不正确的 cfg 文件或数据集)
- 添加了对 Windows 的支持
- 许多其他代码修复...
并添加了手册 - 如何训练 Yolo v4-v2 (检测您的自定义对象)
此外,您可能对使用实现 INT8 量化的简化存储库感兴趣(+加速 30% 和 -1% mAP):https://github.com/AlexeyAB/yolo2_light
如何在命令行上使用
如果您使用 script 或 makefile(仅限 Linux),您将在根目录中找到。build.ps1darknet
如果使用已弃用的 Visual Studio 解决方案,则可以在目录中找到 .darknet\build\darknet\x64
如果您使用 CMake GUI 自定义构建,暗网可执行文件将安装在您的首选文件夹中。
- Yolo v4 COCO - 图片:
./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights -thresh 0.25 - 对象的输出坐标:
./darknet detector test cfg/coco.data yolov4.cfg yolov4.weights -ext_output dog.jpg - Yolo v4 COCO - 视频:
./darknet detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights -ext_output test.mp4 - Yolo v4 COCO - 网络摄像头 0:
./darknet detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights -c 0 - Yolo v4 COCO for net-videocam - 智能网络摄像头:
./darknet detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights http://192.168.0.80:8080/video?dummy=param.mjpg - Yolo v4 - 保存结果视频文件 res.avi:
./darknet detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights test.mp4 -out_filename res.avi - Yolo v3 Tiny COCO - 视频:
./darknet detector demo cfg/coco.data cfg/yolov3-tiny.cfg yolov3-tiny.weights test.mp4 - JSON 和 MJPEG 服务器,允许从您的软浏览器或 Web 浏览器和 8090 进行多个连接:
ip-address:8070./darknet detector demo ./cfg/coco.data ./cfg/yolov3.cfg ./yolov3.weights test50.mp4 -json_port 8070 -mjpeg_port 8090 -ext_output - GPU #1 上的 Yolo v3 Tiny:
./darknet detector demo cfg/coco.data cfg/yolov3-tiny.cfg yolov3-tiny.weights -i 1 test.mp4 - 替代方法 Yolo v3 COCO - 图片:
./darknet detect cfg/yolov4.cfg yolov4.weights -i 0 -thresh 0.25 - 在Amazon EC2上进行训练,使用URL查看mAP和损失图表,例如:在Chrome/Firefox中(Darknet应使用OpenCV编译:
http://ec2-35-160-228-91.us-west-2.compute.amazonaws.com:8090./darknet detector train cfg/coco.data yolov4.cfg yolov4.conv.137 -dont_show -mjpeg_port 8090 -map - 186 MB Yolo9000 - 图片:
./darknet detector test cfg/combine9k.data cfg/yolo9000.cfg yolo9000.weights - 如果您使用 cpp api 构建应用程序,请记住将 data/9k.tree 和 data/coco9k.map 放在应用程序的同一文件夹下
- 要处理图像列表并将检测结果保存到文件,请使用:
data/train.txtresult.json./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights -ext_output -dont_show -out result.json < data/train.txt - 要处理图像列表并保存检测结果以供使用:
data/train.txtresult.txt./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights -dont_show -ext_output < data/train.txt > result.txt - 要处理视频并将结果输出到 json 文件,请使用:
darknet.exe detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights file.mp4 -dont_show -json_file_output results.json - 伪标记 - 要处理图像列表并以 Yolo 训练格式将每个图像的检测结果保存为标签(这样您可以增加训练数据量),请使用:
data/new_train.txt<image_name>.txt./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights -thresh 0.25 -dont_show -save_labels < data/new_train.txt - 要计算锚点:
./darknet detector calc_anchors data/obj.data -num_of_clusters 9 -width 416 -height 416 - 要检查准确性 mAP@IoU=50:
./darknet detector map data/obj.data yolo-obj.cfg backup\yolo-obj_7000.weights - 要检查准确性 mAP@IoU=75:
./darknet detector map data/obj.data yolo-obj.cfg backup\yolo-obj_7000.weights -iou_thresh 0.75
用于将网络摄像机 mjpeg-stream 与任何 Android 智能手机一起使用
-
下载适用于 Android 手机的 mjpeg-stream 软:IP 网络摄像头/智能网络摄像头
- 智能网络摄像头 - 最好:https://play.google.com/store/apps/details?id=com.acontech.android.SmartWebCam2
- IP 网络摄像头:https://play.google.com/store/apps/details?id=com.pas.webcam
-
通过 WiFi(通过 WiFi 路由器)或 USB 将您的 Android 手机连接到计算机
-
在手机上启动 Smart WebCam
-
替换手机应用程序 (Smart WebCam) 中显示的以下地址并启动:
- Yolo v4 COCO 模型:
./darknet detector demo data/coco.data yolov4.cfg yolov4.weights http://192.168.0.80:8080/video?dummy=param.mjpg -i 0
如何在 Linux/macOS 上编译(使用CMake)
将尝试查找已安装的可选依赖项,如 CUDA、cudnn、ZED 并针对这些依赖项进行构建。它还将创建一个共享对象库文件以用于代码开发。CMakeLists.txtdarknet
要在 Ubuntu 上更新 CMake,最好按照此处的指南进行作: Kitware APT Repository 或 Download CMake
git clone https://github.com/AlexeyAB/darknet
cd darknet
mkdir build_release
cd build_release
cmake ..
cmake --build . --target install --parallel 8
还使用 PowerShell
安装: , , 如何安装依赖CmakeCUDAcuDNN
为您的作系统(Linux 或 MacOS)安装 powershell(此处提供指南)。
打开 PowerShell,键入以下命令
git clone https://github.com/AlexeyAB/darknet
cd darknet
./build.ps1 -UseVCPKG -EnableOPENCV -EnableCUDA -EnableCUDNN
- 删除选项,例如 OR 如果您对此不感兴趣
-EnableCUDA-EnableCUDNN - remove 选项(如果您计划手动向暗网提供 OpenCV 库,或者您不想启用 OpenCV 集成)
-UseVCPKG - 如果您想构建支持 CUDA 的 OpenCV,请添加选项 - 构建速度非常慢!(需要
-EnableOPENCV_CUDA-UseVCPKG)
如果您在开始时打开脚本,您将找到所有可用的开关。build.ps1
如何在 Linux 上编译(使用make)
只需在 darknet 目录中执行即可。(您可以尝试在 Google Colab 的云链接中编译和运行它(按左上角的 “在 Playground 中打开”按钮)并观看视频链接 ) 在 make 之前,您可以在 : 链接中设置此类选项makeMakefile
GPU=1使用 CUDA 构建以使用 GPU 进行加速(CUDA 应该在/usr/local/cuda)CUDNN=1使用 cuDNN v5-v7 进行构建,以使用 GPU 加速训练(cuDNN 应在/usr/local/cudnn)CUDNN_HALF=1为 Tensor Core 构建(在 Titan V / Tesla V100 / DGX-2 及更高版本上)将检测速度提高 3 倍,训练速度提高 2 倍OPENCV=1使用 OpenCV 4.x/3.x/2.4.x 进行构建 - 允许检测来自网络摄像机或网络摄像头的视频文件和视频流DEBUG=1构建 Yolo 的调试版本OPENMP=1使用 OpenMP 支持进行构建,以使用多核 CPU 加速 YoloLIBSO=1构建使用此库的库和二进制可运行文件。或者你可以尝试从你自己的代码中运行 so 如何使用这个 SO 库 - 你可以看C++示例:https://github.com/AlexeyAB/darknet/blob/master/src/yolo_console_dll.cpp 或以这种方式使用:darknet.souselibLD_LIBRARY_PATH=./:$LD_LIBRARY_PATH ./uselib test.mp4LD_LIBRARY_PATH=./:$LD_LIBRARY_PATH ./uselib data/coco.names cfg/yolov4.cfg yolov4.weights test.mp4ZED_CAMERA=1构建支持 ZED-3D 相机的库(应安装 ZED SDK),然后运行LD_LIBRARY_PATH=./:$LD_LIBRARY_PATH ./uselib data/coco.names cfg/yolov4.cfg yolov4.weights zed_camera- 您还需要指定为哪个显卡生成代码。这是通过设置 来完成的。如果您使用的版本比 CUDA 11 更新,则还需要从 Makefile 中编辑第 20 行并删除,因为 CUDA 11 中已删除 Kepler GPU 支持。您也可以删除常规并取消对图形卡的注释。
ARCH=-gencode arch=compute_30,code=sm_30 \ARCH=ARCH=
如何在 Windows 上编译(使用CMake)
需要:
- MSVC:Thank You for Downloading Visual Studio Community Edition
- CMake GUI:Download CMake
Windows win64-x64 Installer - 下载包含最新提交的 Darknet zip 存档并解压缩:master.zip
在 Windows 中:
-
开始(按钮) -> 所有程序 -> CMake -> CMake (gui) ->
-
查看图像在 CMake 中:输入暗网源的输入路径和二进制文件的输出路径 -> 配置(按钮) -> 生成器的可选平台: -> 完成 -> 生成 -> 打开项目 ->
x64 -
在 MS Visual Studio 中:选择:x64 并发布 -> Build -> Build 解决方案
-
在 Output PATH (输出路径) 中找到您指定的二进制文件的可执行文件
darknet.exe

如何在 Windows 上编译(使用vcpkg)
这是在 Windows 上构建 Darknet 的推荐方法。
-
安装 Visual Studio 2017 或 2019。如果您需要下载,请访问此处:Visual Studio Community。记得安装英文语言包,这是 vcpkg 的强制性要求!
-
安装 CUDA 在安装过程中启用 VS 集成。
-
打开 Powershell(开始 -> 所有程序 -> Windows Powershell)并键入以下命令:
Set-ExecutionPolicy unrestricted -Scope CurrentUser -Force
git clone https://github.com/AlexeyAB/darknet
cd darknet
.\build.ps1 -UseVCPKG -EnableOPENCV -EnableCUDA -EnableCUDNN
(如果您想构建支持 CUDA 的 OpenCV,请添加选项 - 构建速度非常慢!- 或者如果您对它们不感兴趣,请删除 OR 等选项)。如果您在开始时打开脚本,您将找到所有可用的开关。-EnableOPENCV_CUDA-EnableCUDA-EnableCUDNNbuild.ps1
如何使用多 GPU 进行训练
-
首先在 1 个 GPU 上训练它,大约 1000 次迭代:
darknet.exe detector train cfg/coco.data cfg/yolov4.cfg yolov4.conv.137 -
然后停止并使用部分训练的模型运行多 GPU(最多 4 个 GPU)的训练:
/backup/yolov4_1000.weightsdarknet.exe detector train cfg/coco.data cfg/yolov4.cfg /backup/yolov4_1000.weights -gpus 0,1,2,3
如果你得到一个 Nan,那么对于某些数据集来说,最好降低学习率,设置 4 个 GPU(即 learning_rate = 0.00261 / GPU)。在这种情况下,在 cfg 文件中也增加 4 倍。即 use 而不是 .learning_rate = 0,00065burn_in =burn_in = 40001000
https://groups.google.com/d/msg/darknet/NbJqonJBTSY/Te5PfIpuCAAJ
如何训练(检测自定义对象)
(训练旧的 Yolo v2 , , , , ...点击链接yolov2-voc.cfgyolov2-tiny-voc.cfgyolo-voc.cfgyolo-voc.2.0.cfg)
训练 Yolo v4(和 v3):
- 对于训练,请下载预训练的权重文件 (162 MB):yolov4.conv.137 (Google drive mirror yolov4.conv.137
cfg/yolov4-custom.cfg) - 创建内容与 中相同的文件(或复制到 and:
yolo-obj.cfgyolov4-custom.cfgyolov4-custom.cfgyolo-obj.cfg)
- 将 Line Batch 更改为 batch=64
- 将 Line Subdivisions 更改为 Subdivisions=16
- 将第 max_batches 行更改为 (,但不少于训练图像的数量,且不小于 ),例如,如果您训练 3 个类,则为 max_batches=6000
classes*20006000 - 将 Line steps 更改为 max_batches的 80% 和 90%,例如 steps=4800,5400
- 设置网络大小或 32 的任意值倍数:
width=416 height=416暗网/cfg/yolov3.cfg
第 8 至 9 号线 在编号 0039FD2
宽度 = 416 身高 = 416 - 将 line 更改为 3 个图层中每个图层中的对象数量:
classes=80[yolo]-
暗网/cfg/yolov3.cfg
610 号线 在编号 0039FD2
类 = 80 -
暗网/cfg/yolov3.cfg
第 696 行 在编号 0039FD2
类 = 80 -
暗网/cfg/yolov3.cfg
783 号线 在编号 0039FD2
类 = 80
-
- 将 [] 更改为 filters=(classes + 5)x3 在每层之前的 3 中,请记住,它只需要是每层之前的最后一个。
filters=255[convolutional][yolo][convolutional][yolo]-
暗网/cfg/yolov3.cfg
603 行 在编号 0039FD2
筛选器 = 255 -
暗网/cfg/yolov3.cfg
线路 689 在编号 0039FD2
筛选器 = 255 -
暗网/cfg/yolov3.cfg
776 行 在编号 0039FD2
筛选器 = 255
-
- 使用 [Gaussian_yolo] 图层时,更改每个图层前 3 中的 [] filters=(classes + 9)x3
filters=57[convolutional][Gaussian_yolo]-
暗网/cfg/Gaussian_yolov3_BDD.cfg
604 号线 在6e5bdf1
过滤器 = 57 -
暗网/cfg/Gaussian_yolov3_BDD.cfg
第 696 行 在6e5bdf1
过滤器 = 57 -
暗网/cfg/Gaussian_yolov3_BDD.cfg
789 号线 在6e5bdf1
过滤器 = 57
-
所以如果 then 应该是 。如果 then 写入 .(不要在 cfg 文件中写入: filters=(classes + 5)x3)classes=1filters=18classes=2filters=21
(通常取决于 和 s 的数量,即 filters=,其中 是锚点的索引。如果 是 absent,则 filters=filtersclassescoordsmask(classes + coords + 1)*<number of mask>maskmask(classes + coords + 1)*num)
因此,例如,对于 2 个对象,您的文件应与 3 个 [yolo] 图层中每个图层中的这些行不同:yolo-obj.cfgyolov4-custom.cfg
[convolutional]
filters=21[region]
classes=2
- 在目录中创建文件,其中包含对象名称 - 每个名称都在新行中
obj.namesbuild\darknet\x64\data\ - 在目录中创建文件,其中包含 (其中 classes = 对象数):
obj.databuild\darknet\x64\data\
classes = 2
train = data/train.txt
valid = data/test.txt
names = data/obj.names
backup = backup/
- 将对象的 image-files (.jpg) 放在目录中
build\darknet\x64\data\obj\ - 您应该标记数据集中图像上的每个对象。使用这个可视化的GUI软件来标记对象的边界框,并为Yolo v2和v3生成注释文件:https://github.com/AlexeyAB/Yolo_mark
它将在同一目录中为每个 -image-file - 创建-file,具有相同的名称,但带有 -extension,并为此图像上的每个对象创建新-file: 对象编号和对象坐标,对于新行中的每个对象:.txt.jpg.txt
<object-class> <x_center> <y_center> <width> <height>
哪里:
-
<object-class>- 整数对象编号 from to0(classes-1) -
<x_center> <y_center> <width> <height>- 相对于图像宽度和高度的浮点值,它可以等于(0.0 to 1.0] -
例如:或
<x> = <absolute_x> / <image_width><height> = <absolute_height> / <image_height> -
注意: - 是矩形的中心(不是左上角)
<x_center> <y_center>例如,将为您创建包含以下内容:
img1.jpgimg1.txt<span style="background-color:#e6eaef"><span style="color:#010409"><span style="background-color:#e6eaef"><code>1 0.716797 0.395833 0.216406 0.147222 0 0.687109 0.379167 0.255469 0.158333 1 0.420312 0.395833 0.140625 0.166667 </code></span></span></span>
- 在目录中创建文件 ,其中包含图像的文件名,每个文件名另起一行,路径相对于 ,例如包含:
train.txtbuild\darknet\x64\data\darknet.exe
<span style="background-color:#e6eaef"><span style="color:#010409"><span style="color:#010409"><span style="background-color:#e6eaef"><code>data/obj/img1.jpg
data/obj/img2.jpg
data/obj/img3.jpg
</code></span></span></span></span>-
下载卷积层的预训练权重,并将其放入目录
build\darknet\x64- 对于 (162 MB): yolov4.conv.137 (Google drive mirror yolov4.conv.137)
yolov4.cfgyolov4-custom.cfg) - 对于 , , (19 MB):yolov4-tiny.conv.29
yolov4-tiny.cfgyolov4-tiny-3l.cfgyolov4-tiny-custom.cfg - 对于 (133 MB):csresnext50-panet-spp.conv.112
csresnext50-panet-spp.cfg - 适用于 (154 MB):darknet53.conv.74
yolov3.cfg, yolov3-spp.cfg - 对于 (6 MB):yolov3-tiny.conv.11
yolov3-tiny-prn.cfg , yolov3-tiny.cfg - for (14 MB): enetb0-coco.conv.132
enet-coco.cfg (EfficientNetB0-Yolov3)
- 对于 (162 MB): yolov4.conv.137 (Google drive mirror yolov4.conv.137)
-
使用命令行开始训练:
darknet.exe detector train data/obj.data yolo-obj.cfg yolov4.conv.137要在 Linux 上训练,请使用命令:(只需使用
./darknet detector train data/obj.data yolo-obj.cfg yolov4.conv.137./darknetdarknet.exe)- (文件将保存到 for each 100 iterations)
yolo-obj_last.weightsbuild\darknet\x64\backup\ - (文件将保存到 for each 1000 iterations)
yolo-obj_xxxx.weightsbuild\darknet\x64\backup\ - (禁用 Loss-Window 使用,如果您在没有显示器的计算机上训练,例如云 Amazon EC2)
darknet.exe detector train data/obj.data yolo-obj.cfg yolov4.conv.137 -dont_show - (要在没有GUI的远程服务器上查看mAP和损失图表,请使用命令,然后在Chrome/Firefox浏览器中打开URL)
darknet.exe detector train data/obj.data yolo-obj.cfg yolov4.conv.137 -dont_show -mjpeg_port 8090 -maphttp://ip-address:8090
- (文件将保存到 for each 100 iterations)
8.1. 对于每 4 个 Epochs(设置或在文件中)计算的 mAP(平均精度)训练并运行:valid=valid.txttrain.txtobj.datadarknet.exe detector train data/obj.data yolo-obj.cfg yolov4.conv.137 -map
8.2. 如果需要更少或更频繁的 mAP 计算,也可以在训练命令中设置 。例如,为了计算每 2 个 Epochs 运行的 mAP-mAP_epochsdarknet.exe detector train data/obj.data yolo-obj.cfg yolov4.conv.137 -map -mAP_epochs 2
-
训练完成后 - 从路径获取结果
yolo-obj_final.weightsbuild\darknet\x64\backup\- 在每 100 次迭代之后,您可以停止,然后从此点开始训练。例如,在 2000 次迭代后,您可以停止训练,然后使用以下方法开始训练:
darknet.exe detector train data/obj.data yolo-obj.cfg backup\yolo-obj_2000.weights
(在原始存储库中 https://github.com/pjreddie/darknet 权重文件每 10 000 次迭代仅保存一次
if(iterations > 1000))- 此外,您还可以在所有 45000 次迭代之前获得结果。
- 在每 100 次迭代之后,您可以停止,然后从此点开始训练。例如,在 2000 次迭代后,您可以停止训练,然后使用以下方法开始训练:
注意:如果在训练期间您看到 (loss) 字段的值 - 则训练出错,但如果 在其他一些行中 - 则训练进行顺利。nanavgnan
注意:如果你在 cfg 文件中更改了 width= 或 height=,那么新的 width 和 height 必须能被 32 整除。
注意:训练后,使用以下命令进行检测:darknet.exe detector test data/obj.data yolo-obj.cfg yolo-obj_8000.weights
注意:如果发生错误,则应在 -file 中增加 、 32 或 64:链接Out of memory.cfgsubdivisions=16
如何训练 tiny-yolo(检测您的自定义对象)
如上所述,执行与完整 yolo 模型相同的所有步骤。除了:
- 下载 yolov4-tiny 前 29 个卷积层的文件:https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-tiny.conv.29(或使用命令从 yolov4-tiny.weights 文件中获取此文件:
darknet.exe partial cfg/yolov4-tiny-custom.cfg yolov4-tiny.weights yolov4-tiny.conv.29 29 - 使您的自定义模型基于 而不是
yolov4-tiny-obj.cfgcfg/yolov4-tiny-custom.cfgyolov4.cfg - 开始培训:
darknet.exe detector train data/obj.data yolov4-tiny-obj.cfg yolov4-tiny.conv.29
对于基于其他模型(DenseNet201-Yolo 或 ResNet50-Yolo)训练 Yolo,您可以下载并获取预训练权重,如以下文件所示:https://github.com/AlexeyAB/darknet/blob/master/build/darknet/x64/partial.cmd 如果您制作的自定义模型不基于其他模型,那么您可以在没有预训练权重的情况下训练它,然后将使用随机初始权重。
何时应停止训练
通常每个类(对象)的迭代次数足够 2000 次,但不少于训练图像的数量,总共不少于 6000 次迭代。但是,要更准确地定义何时应停止训练,请使用以下手册:
- 在训练期间,您将看到不同的误差指标,当平均误差不再降低 0.XXXXXXX 时,您应该停止:
区域平均 IOU: 0.798363, 类: 0.893232, 对象: 0.700808, 无对象: 0.004567, 平均召回率: 1.000000, 计数: 8 区域平均 IOU: 0.800677, 类: 0.892181, 物镜: 0.701590, 无物镜: 0.004574, 平均召回率: 1.000000, 计数: 8
9002:0.211667、0.60730 平均值、0.001000 速率、3.868000 秒、576128图像 已加载:0.000000 秒
-
9002 - 迭代编号(批次数)
-
0.60730 avg - 平均损失(误差) - 越低越好
当您看到平均损失 0.xxxxxx 平均在多次迭代中不再减少时,您应该停止训练。最终的平均损失可以从 (对于小模型和简单的数据集) 到 (对于大模型和困难的数据集)。
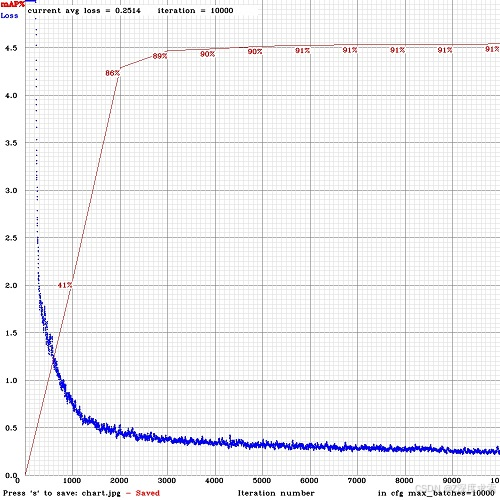
0.053.0或者,如果您使用 flag 进行训练,那么您会在控制台中看到 mAP 指标 - 这个指标比 Loss 更好,因此在 mAP 增加时进行训练。
-mapLast accuracy mAP@0.5 = 18.50%
- 停止训练后,您应该从中获取一些 last -files 并选择其中最好的:
.weightsdarknet\build\darknet\x64\backup
例如,您在 9000 次迭代后停止了训练,但最佳结果可以给出之前的权重之一 (7000、8000、9000)。这可能是由于过度拟合而发生的。过度拟合 - 是指您可以从训练数据集中检测图像上的对象,但无法检测任何其他图像上的对象。您应该从 Early Stopping Point 获得权重:
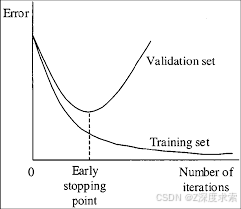
要从 Early Stopping Point 获取权重:
2.1. 首先,您必须在文件中指定验证数据集的路径(格式为 as in ),如果您没有验证图像,只需复制到 。obj.datavalid = valid.txtvalid.txttrain.txtdata\train.txtdata\valid.txt
2.2 如果在 9000 次迭代后停止训练,要验证以前的一些权重,请使用以下命令:
(如果您使用其他 GitHub 存储库,请使用 ...而不是 ...)darknet.exe detector recalldarknet.exe detector map
darknet.exe detector map data/obj.data yolo-obj.cfg backup\yolo-obj_7000.weightsdarknet.exe detector map data/obj.data yolo-obj.cfg backup\yolo-obj_8000.weightsdarknet.exe detector map data/obj.data yolo-obj.cfg backup\yolo-obj_9000.weights
并比较每个权重 (7000, 8000, 9000) 的最后输出行:
选择具有最高 mAP (平均精度均值) 或 IoU (并集相交) 的权重文件
例如,较大的 mAP 会给出权重 - 然后使用此权重进行检测。yolo-obj_8000.weights
或者只是用国旗训练:-map
darknet.exe detector train data/obj.data yolo-obj.cfg yolov4.conv.137 -map
因此,您将在 Loss-chart (亏损图表) 窗口中看到 mAP 图表(红线)。将使用 file 中指定的 file ( iterations) 计算每 4 个 Epoch 的 mAPvalid=valid.txtobj.data1 Epoch = images_in_train_txt / batch
(要更改 Max x axis 值 - 将 max_batches= 参数更改为 , f.e. 3 个课程)2000*classesmax_batches=6000
自定义对象检测示例:darknet.exe detector test data/obj.data yolo-obj.cfg yolo-obj_8000.weights
-
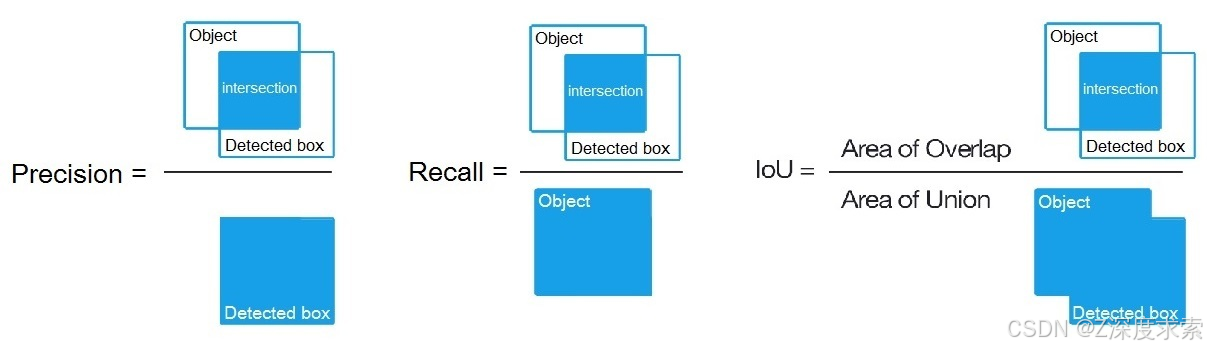
IoU (intersect over union) - 特定阈值下对象和检测的并集的平均相交 = 0.24
-
mAP(平均精度均值)- 每个类的平均值,其中是同一类(以帕斯卡VOC表示的精度-召回率,其中精度=TP/(TP+FP)和召回率=TP/(TP+FN))的每个可能阈值(每个检测概率)的PR曲线上11个点的平均值,第11页:http://homepages.inf.ed.ac.uk/ckiw/postscript/ijcv_voc09.pdf
average precisionsaverage precision
mAP 是 PascalVOC 竞赛中的默认精度指标,这与 MS COCO 竞赛中的 AP50 指标相同。 就 Wiki 而言,指标 Precision 和 Recall 的含义与 PascalVOC 竞赛中的含义略有不同,但 IoU 始终具有相同的含义。
自定义对象检测
自定义对象检测示例:darknet.exe detector test data/obj.data yolo-obj.cfg yolo-obj_8000.weights

如何改进对象检测
- 训练前:
-
set 标志 - 它将通过训练 Yolo 以获得不同的分辨率来提高精度:链接
random=1.cfg -
提高 -file 中的网络分辨率(或 32 的任意值的倍数)- 它将提高精度
.cfgheight=608width=608 -
检查要检测的每个对象在数据集中是否都是必需的 - 数据集中的任何一个对象都不应没有标签。在大多数训练问题中 - 数据集中存在错误的标签(使用一些转换脚本获取标签,使用第三方工具标记,......始终使用以下方法检查数据集:GitHub - AlexeyAB/Yolo_mark: GUI for marking bounded boxes of objects in images for training neural network Yolo v3 and v2
-
我的 Loss 非常高,而 mAP 非常低,训练是错误的吗?在训练命令结束时使用标志运行训练,您是否看到正确的对象边界框(在窗口或文件中)?如果否 - 您的训练数据集是错误的。
-show_imgsaug_...jpg -
对于要检测的每个对象 - 训练数据集中必须至少有 1 个相似的对象,其形状、对象侧面、相对大小、旋转角度、倾斜度、照明度。因此,您的训练数据集应包含具有不同对象的图像:比例、旋转、照明、来自不同侧面、不同背景的图像 - 最好每个类有 2000 张或更多不同的图像,并且您应该训练迭代或更多
2000*classes -
希望您的训练数据集包含您不想检测的未标记对象的图像 - 没有边界框的负样本(空文件)- 使用与包含对象的图像一样多的负样本图像
.txt -
标记对象的最佳方法是什么:只标记对象的可见部分,或者标记对象的可见和重叠部分,或者标记比整个对象多一点(有一点间隙)?随心所欲地标记 - 您希望如何检测它。
-
对于每张图像中大量对象的训练,请在 cfg 文件的最后一个 -layer 或 -layer 中添加参数或更高的值(YoloV3 可以检测到的全局最大对象数是其中 width 和 height 是 cfg 文件中部分的参数)
max=200[yolo][region]0,0615234375*(width*height)[net] -
用于训练小对象(在将图像大小调整为 416x416 后小于 16x16)- set 而不是 set
layers = 23暗网/cfg/yolov4.cfg
895 行 在6F718C2
图层 = 54 - set 而不是
stride=4暗网/cfg/yolov4.cfg
892 行 在6F718C2
步幅 = 2 - set 而不是
stride=4暗网/cfg/yolov4.cfg
线路 989 在6F718C2
步幅 = 2
- set 而不是
-
对于小型和大型对象的训练,请使用修改后的模型:
- 完整模型:5 个 yolo 层:https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov3_5l.cfg
- Tiny-model:3 yolo 层:https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov4-tiny-3l.cfg
- YOLOv4:3 个 YOLO 层:https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov4-custom.cfg
-
如果您训练模型将 Left 和 Right 对象区分为单独的类(左/右手、路标上的左/右转等),那么要禁用翻转数据增强 - 请在此处添加:
flip=0暗网/cfg/yolov3.cfg
17 号线 在3d2d0a7
-
一般规则 - 您的训练数据集应包含要检测的一组对象的相对大小:
train_network_width * train_obj_width / train_image_width ~= detection_network_width * detection_obj_width / detection_image_widthtrain_network_height * train_obj_height / train_image_height ~= detection_network_height * detection_obj_height / detection_image_height
即,对于 Test 数据集中的每个对象,Training 数据集中必须至少有 1 个对象具有相同的class_id和大致相同的相对大小:
object width in percent from Training dataset~=object width in percent from Test dataset也就是说,如果训练集中只存在占据图像 80-90% 的对象,那么训练的网络将无法检测到占据图像 1-10% 的对象。
-
为了加快训练速度(检测精度降低),在 cfg-file 中为 layer-136 设置 param
stopbackward=1 -
每个:转弯和倾斜角度 - 从神经网络的内部角度来看,这些是不同的对象。因此,要检测的不同对象越多,应使用的网络模型就越复杂。
model of object, side, illumination, scale, each 30 grad -
为了使检测到的有界框更准确,你可以为每个层添加 3 个参数并训练,它将增加 mAP@0.9,但减少 mAP@0.5。
ignore_thresh = .9 iou_normalizer=0.5 iou_loss=giou[yolo] -
仅当你是神经检测网络专家时 - 为 cfg-file 重新计算数据集的锚点:然后在 cfg-file 的 3 个 -layers 中分别设置相同的 9。但是您应该更改每个 [yolo] 图层的锚点索引,因此对于 YOLOv4,第 1 个 [yolo] 图层的锚点小于 30x30,第 2 个图层小于 60x60,剩余第 3 个,反之亦然。此外,您应该更改每个 [yolo] 图层之前的 。如果许多计算的锚点不适合适当的图层 - 那么只需尝试使用所有默认锚点。
widthheightdarknet.exe detector calc_anchors data/obj.data -num_of_clusters 9 -width 416 -height 416anchors[yolo]masks=filters=(classes + 5)*<number of mask>
- 训练后 - 用于检测:
-
通过在 -file ( 和 ) 或 ( 和 ) 或 (32 的任意倍数) 中设置来提高网络分辨率 - 这可以提高精度并可以检测小物体:link
.cfgheight=608width=608height=832width=832 -
无需再次训练网络,只需使用 -file already trained for 416x416 resolution
.weights -
为了获得更高的准确性,您应该使用更高分辨率的 608x608 或 832x832 进行训练,注意:如果发生错误,则应在 -file 中增加、32 或 64:链接
Out of memory.cfgsubdivisions=16
如何标记对象的边界框并创建注释文件
在这里,您可以找到带有 GUI 软件的存储库,用于标记对象的边界框并为 Yolo v2 - v4 生成注释文件:GitHub - AlexeyAB/Yolo_mark: GUI for marking bounded boxes of objects in images for training neural network Yolo v3 and v2
示例为:、、、、1-6、1-4 用于 2 类对象(空气、鸟),并举例说明如何使用 Yolo v2 - v4 训练此图像集train.txtobj.namesobj.datayolo-obj.cfgair.txtbird.txttrain_obj.cmd
在图像中标记对象的不同工具:
- C++ 中: GitHub - AlexeyAB/Yolo_mark: GUI for marking bounded boxes of objects in images for training neural network Yolo v3 and v2
- 在 Python 中:GitHub - HumanSignal/labelImg: LabelImg is now part of the Label Studio community. The popular image annotation tool created by Tzutalin is no longer actively being developed, but you can check out Label Studio, the open source data labeling tool for images, text, hypertext, audio, video and time-series data.
- 在 Python 中:GitHub - Cartucho/OpenLabeling: Label images and video for Computer Vision applications
- C++: DarkMark: DarkMark
- 在 JavaScript 中:GitHub - cvat-ai/cvat: Annotate better with CVAT, the industry-leading data engine for machine learning. Used and trusted by teams at any scale, for data of any scale.
- C++:GitHub - jveitchmichaelis/deeplabel: A cross-platform desktop image annotation tool for machine learning
- 在 C# 中:GitHub - BMW-InnovationLab/BMW-Labeltool-Lite: This repository provides you with an easy-to-use labeling tool for State-of-the-art Deep Learning training purposes. It supports Auto-Labeling.
- 适用于 Windows 的 DL-Annotator(30 美元):url
- V7Labs - 最出色的云标记工具(每小时 1.5 美元):V7 | AI Document Processing & Data Labelling
如何将 Yolo 用作 DLL 和 SO 库
- 在 Linux 上
- using 或
build.sh - 使用 或
darknetcmake - 在 和 do 中设置
LIBSO=1Makefilemake
- using 或
- 在 Windows 上
- using 或
build.ps1 - 使用 或
darknetcmake - 编译 Solution 或 Solution
build\darknet\yolo_cpp_dll.slnbuild\darknet\yolo_cpp_dll_no_gpu.sln
- using 或
有 2 个 API:
-
C API:darknet/include/darknet.h at master · AlexeyAB/darknet · GitHub
- 使用 C API 的 Python 示例:
- darknet/darknet.py at master · AlexeyAB/darknet · GitHub
- darknet/darknet_video.py at master · AlexeyAB/darknet · GitHub
- 使用 C API 的 Python 示例:
-
C++ API:darknet/include/yolo_v2_class.hpp at master · AlexeyAB/darknet · GitHub
- C++ API C++示例:darknet/src/yolo_console_dll.cpp at master · AlexeyAB/darknet · GitHub
-
要将 Yolo 编译为C++ DLL 文件 - 打开解决方案,设置 x64 和 Release,然后执行以下作:Build > Build yolo_cpp_dll
yolo_cpp_dll.dllbuild\darknet\yolo_cpp_dll.sln- 您应该已经安装了 CUDA 10.2
- 要使用 cuDNN,请执行以下作:(右键单击项目) -> properties -> C/C++ -> Preprocessor -> Preprocessor Definitions,并在行首添加:
CUDNN;
-
要在 C++ 控制台应用程序中将 Yolo 用作 DLL 文件 - 打开解决方案,设置 x64 和 Release,然后执行:Build -> Build yolo_console_dll
build\darknet\yolo_console_dll.sln-
您可以使用以下命令从 Windows 资源管理器运行控制台应用程序:
build\darknet\x64\yolo_console_dll.exeyolo_console_dll.exe data/coco.names yolov4.cfg yolov4.weights test.mp4 -
启动控制台应用程序并输入图像文件名后,您将看到每个对象的信息:
<obj_id> <left_x> <top_y> <width> <height> <probability> -
要使用简单的 OpenCV-GUI,您应该取消注释 -file: link 中的行
//#define OPENCVyolo_console_dll.cpp -
您可以查看视频文件上用于检测的简单示例的源代码:链接
-
yolo_cpp_dll.dll-API:链接