Yolov5+LPRNet车牌识别遇到的一些问题记录
由于下载的这位博主的github代码版本有点久了,所以有些yolov5升级的问题需要解决。
代码链接:https://github.com/HuKai97/YOLOv5-LPRNet-Licence-Recognition
1. from apex import amp
这里直接pip install 安装是不行的,采用以下方式安装。还用到skimage,这个可以pip
git clone https://github.com/NVIDIA/apex
cd apex
python setup.py install直接git clone我会出现报错,大部分报错都是网络速度慢引起的,所以建议直接从https://github.com/NVIDIA/apex 下载apex-master安装包,解压到本地文件夹。cmd命令转到自己虚拟环境,例如:d:,然后转到apex-master执行setup.py命令就可。
2.训练LPRNet,test_lprnet.py除数为0
这里调小batchsize,测试的数据集选大一些,要比batchsize大的多就可以!
3.读取数据部分中文问题
cv2.imread读取不出中文字,导致报错“no module named shape”,改为下面
Image = cv2.imdecode(np.fromfile(filename, dtype=np.uint8), -1)4. 报错hyp.update(yaml.load(f, Loader=yaml.FullLoader))处报错UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 176: illegal multibyte sequence
由于yaml中的字符非法,在opt.hyp后添加encoding=‘utf-8'可编码中文就可以了
with open(opt.hyp,encoding='utf-8') as f:hyp.update(yaml.load(f, Loader=yaml.FullLoader))5. 报错AttributeError: 'int' object has no attribute 'extend'
 整数对象不存在,增加这一句即可
整数对象不存在,增加这一句即可

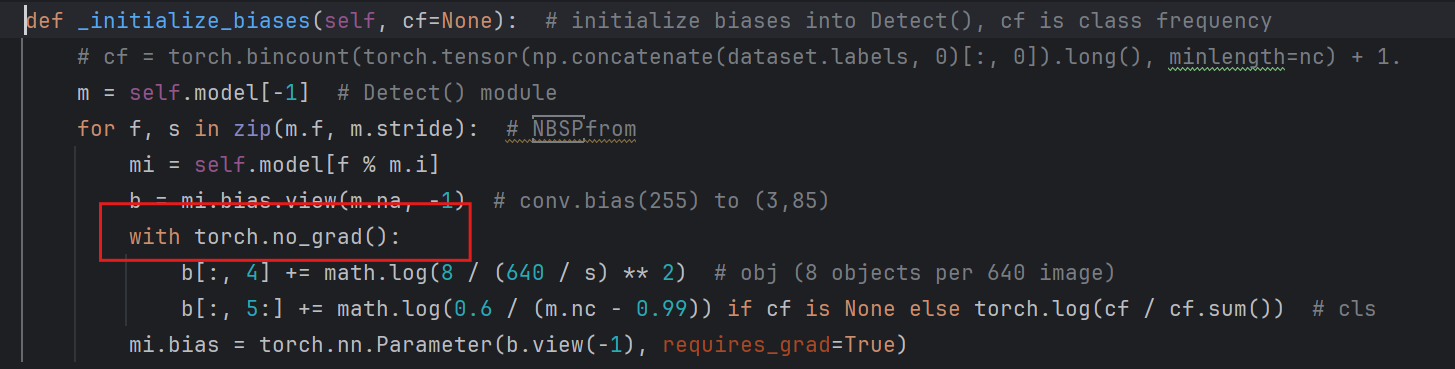
6. 报错a view of a leaf Variable that requires grad is being used in an in-place operation
原因:一个需要梯度的变量被就地操作,即反向传播出问题,需要去掉梯度计算
在yolo.py文件的偏置初始化位置更改,添加矩形框的就可
 7. 报错YoloV5:AttributeError: Can‘t get attribute ‘C3‘ on <module ‘models.common‘ from
7. 报错YoloV5:AttributeError: Can‘t get attribute ‘C3‘ on <module ‘models.common‘ from
因为版本更新的问题导致,将c3和sppf导入即可
common.py添加以下内容
#在最上面需要引入warnings库
import warningsclass C3(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper(C3, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))class SPPF(nn.Module):# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocherdef __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))super().__init__()c_ = c1 // 2 # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_ * 4, c2, 1, 1)self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)def forward(self, x):x = self.cv1(x)with warnings.catch_warnings():warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warningy1 = self.m(x)y2 = self.m(y1)return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))8. RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
build_targets 函数时,某些张量在不同的设备(CPU或GPU)上。为了修复这个错误,你需要确保所有相关的张量都在同一个设备上。
def build_targets(p, targets, model):# Build targets for compute_loss(), input targets(image, class, x, y, w, h)device = targets.devicedet = model.module.model[-1] if isinstance(model, (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel)) else model.model[-1] # Detect() modulena, nt = det.na, targets.shape[0] # number of anchors, targetstcls, tbox, indices, anch = [], [], [], []gain = torch.ones(6, device=device) # normalized to gridspace gainoff = torch.tensor([[1, 0], [0, 1], [-1, 0], [0, -1]], device=device).float() # overlap offsetsat = torch.arange(na, device=device).view(na, 1).repeat(1, nt) # anchor tensor, same as .repeat_interleave(nt)g = 0.5 # offsetstyle = 'rect4'for i in range(det.nl):anchors = det.anchors[i].to(device) # Move anchors to the same devicegain[2:] = torch.tensor(p[i].shape, device=device)[[3, 2, 3, 2]] # xyxy gain# Match targets to anchorsa, t, offsets = [], targets * gain, 0if nt:r = t[None, :, 4:6] / anchors[:, None] # wh ratioj = torch.max(r, 1. / r).max(2)[0] < model.hyp['anchor_t'] # compare# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n) = wh_iou(anchors(3,2), gwh(n,2))a, t = at[j], t.repeat(na, 1, 1)[j] # filter# overlapsgxy = t[:, 2:4] # grid xyz = torch.zeros_like(gxy)if style == 'rect2':j, k = ((gxy % 1. < g) & (gxy > 1.)).Ta, t = torch.cat((a, a[j], a[k]), 0), torch.cat((t, t[j], t[k]), 0)offsets = torch.cat((z, z[j] + off[0], z[k] + off[1]), 0) * gelif style == 'rect4':j, k = ((gxy % 1. < g) & (gxy > 1.)).Tl, m = ((gxy % 1. > (1 - g)) & (gxy < (gain[[2, 3]] - 1.))).Ta, t = torch.cat((a, a[j], a[k], a[l], a[m]), 0), torch.cat((t, t[j], t[k], t[l], t[m]), 0)offsets = torch.cat((z, z[j] + off[0], z[k] + off[1], z[l] + off[2], z[m] + off[3]), 0) * g# Defineb, c = t[:, :2].long().T # image, classgxy = t[:, 2:4] # grid xygwh = t[:, 4:6] # grid whgij = (gxy - offsets).long()gi, gj = gij.T # grid xy indices# Appendindices.append((b, a, gj, gi)) # image, anchor, grid indicestbox.append(torch.cat((gxy - gij, gwh), 1)) # boxanch.append(anchors[a]) # anchorstcls.append(c) # classreturn tcls, tbox, indices, anch9. 报错yolo v5 train. TypeError: can't convert cuda:0 device type tensor to numpy
注释源代码,加.cpu
def __array__(self, dtype=None):if has_torch_function_unary(self):return handle_torch_function(Tensor.__array__, (self,), self, dtype=dtype)if dtype is None:# return self.numpy()return self.cpu().numpy()else:return self.numpy().astype(dtype, copy=False)