实训云上搭建分布式Hadoop集群[2025] 实战笔记
文章目录
- 一、实战目标
- 二、集群规划
-
- 1. 集群拓扑结构
- 2. 角色分配
- 说明:
- 三、环境准备
-
- 1. 修改 SSH 端口(安全加固)
- 操作步骤(所有节点执行):
- 2. FinalShell 连接配置
- 3. 防火墙配置
- 启动并配置 firewalld:
- 关闭并禁用防火墙(生产环境建议精细配置,测试环境可关闭):
- 四、系统基础配置(所有节点)
-
- 1. 设置主机名
- 2. 配置 hosts 映射
- 3. 关闭防火墙(再次确认)
- 4. 关闭 SELinux
- 五、配置免密登录(关键步骤)
-
- 1. 生成密钥对(在 master 节点执行)
- 2. 分发公钥到所有节点
- 3. 验证免密登录
- 4. 查看密钥文件(可选)
- 六、安装与配置 JDK
-
- 1. 上传并解压 JDK
- 2. 配置环境变量
- 3. 验证安装
- 七、安装与配置 Hadoop
-
- 1. 上传并解压 Hadoop
- 2. 配置环境变量
- 3. 配置 Hadoop 环境文件
- 4. 配置 core-site.xml
- 5. 配置 hdfs-site.xml
- 6. 配置 mapred-site.xml
- 7. 配置 yarn-site.xml
- 8. 配置 workers 文件(原 slaves)
- 八、分发配置到从节点
-
- 1. 分发 JDK
- 2. 分发 Hadoop
- 3. 分发系统配置文件
- 4. 从节点刷新配置
- 九、格式化 NameNode
- 十、启动 Hadoop 集群
-
- 1. 启动所有服务
- 2. 查看进程
- 十一、访问 Web UI 验证集群状态
-
- 1. HDFS Web UI(9870端口)
- 2. YARN Web UI(8088端口)
- 十二、关闭 Hadoop 集群
- 十三、常见问题与解决方案
- 十四、总结
一、实战目标
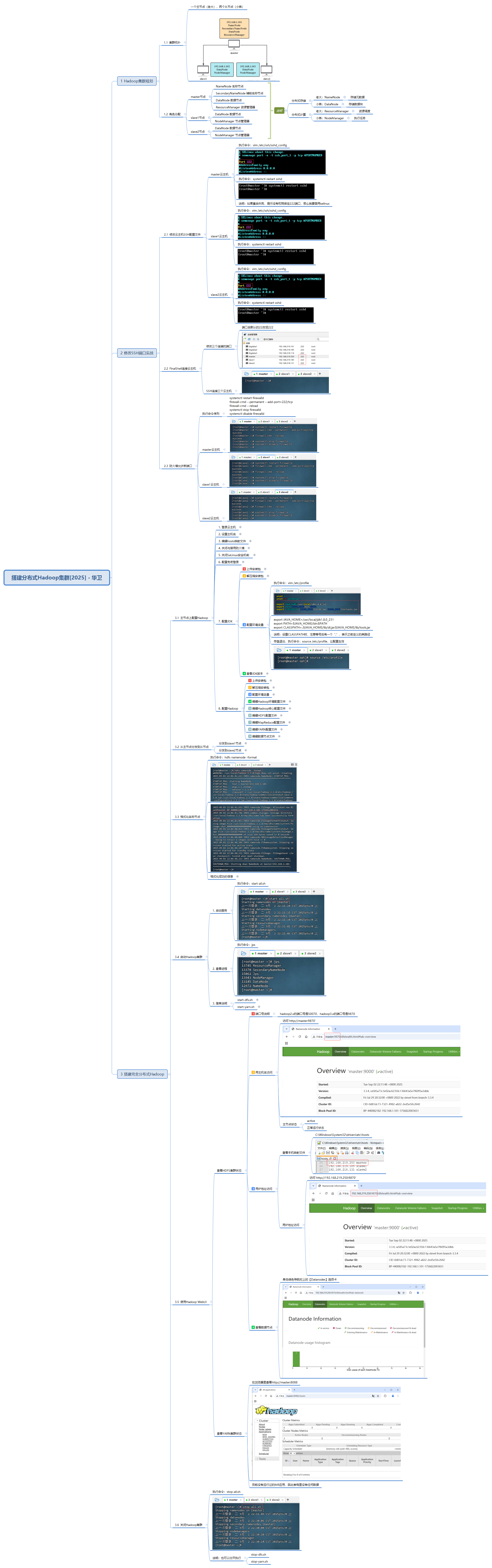
搭建一个高可用的完全分布式 Hadoop 集群,基于 Hadoop 3.3.4 版本,包含 1 个主节点(master)和 2 个从节点(slave1、slave2),实现 HDFS 分布式存储与 YARN 分布式资源调度,支持后续大数据应用开发与部署。
二、集群规划
1. 集群拓扑结构
| 节点类型 | 主机名 | IP 地址 |
|---|---|---|
| 主节点(Master) | master | 192.168.1.101 |
| 从节点(Slave) | slave1 | 192.168.1.102 |
| 从节点(Slave) | slave2 | 192.168.1.103 |