Linux文本处理工具
文章目录
- Linux 文本处理四剑客:cut、sort、uniq、tr 实用指南
- 1. cut —— 按列或字符截取
- 常用选项
- 示例
- 字节与字符的区别
- 2. sort —— 文本排序工具
- 常用选项
- 示例
- 3. uniq —— 去除连续重复行
- 常用选项
- 示例
- 实战应用:查看登录用户
- 4. tr —— 字符转换工具
- 基本语法
- 常用选项
- 示例
- 5. 组合命令实战
- ① 统计当前连接的主机数
- ② 统计当前主机的连接状态
- ③ 查看当前登录用户
- ④ 查看登录过系统的用户
- 6. 总结口诀
Linux 文本处理四剑客:cut、sort、uniq、tr 实用指南
在 Linux 系统管理和文本处理中,cut、sort、uniq 和 tr 是四个非常实用的命令行工具。它们各自有着独特的功能,又能灵活组合,轻松应对各种文本处理场景。本文将详细介绍这四个命令的用法和实战技巧。
1. cut —— 按列或字符截取
cut 命令主要用于从文本中抽取需要的字段,特别适合处理结构化的文本数据。
常用选项
-b:按字节截取-c:按字符截取(处理中文推荐使用)-d:指定分隔符(默认使用 TAB 键)-f:指定要提取的字段(需配合-d使用)
示例
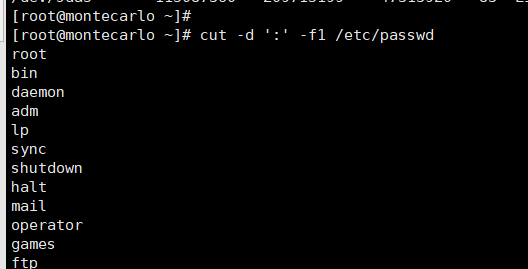
# 从/etc/passwd文件中截取第1列(用户名)
cut -d':' -f1 /etc/passwd
# 截取第3列(UID)
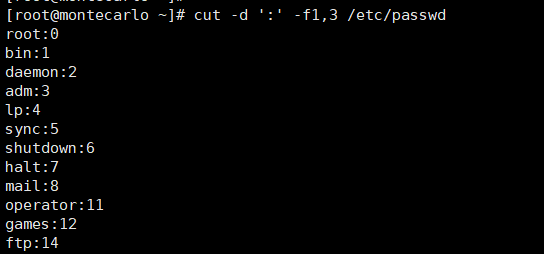
cut -d':' -f3 /etc/passwd
# 同时截取第1和3列
cut -d':' -f1,3 /etc/passwd
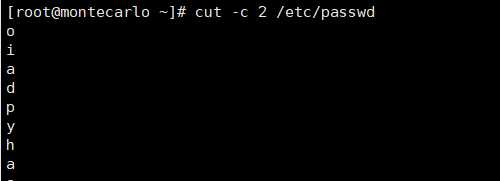
# 截取每行的第2个字符
cut -c 2 name.txt
字节与字符的区别
处理英文时,-b 和 -c 效果通常一致,但处理多字节字符(如中文)时差异明显:
who | cut -b 3 # 按字节截取,可能导致中文乱码
who | cut -c 3 # 按字符截取,适合中文# 处理中文示例
cat name | cut -b 2 # 可能只截取了中文字符的一半字节
cat name | cut -c 2 # 正确截取第二个字符(无论是中文还是英文)


注意:
cut只擅长处理以单个字符作为分隔符的文本。
2. sort —— 文本排序工具
sort 命令用于对文本内容进行排序,默认按行首字符升序排列。
常用选项
-t:指定字段分隔符-k:指定排序的字段-n:按数值大小排序(默认是字典序)-r:降序排列-u:去除重复行(效果等同于uniq)-o:将排序结果输出到指定文件
示例
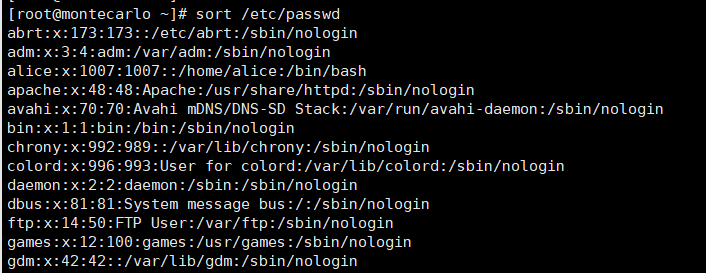
# 按默认方式(第一列升序)排序passwd.txt
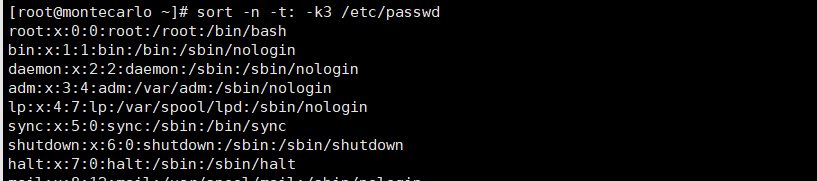
sort passwd.txt # 以冒号为分隔符,按第3列数值升序排序
sort -n -t: -k3 passwd.txt # 以冒号为分隔符,按第3列数值降序排序
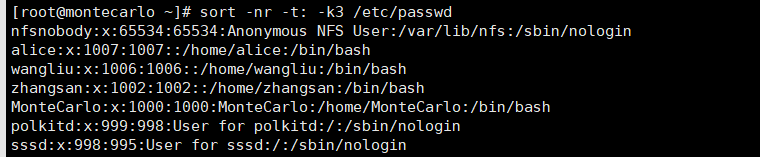
sort -nr -t: -k3 passwd.txt # 排序并去除重复行
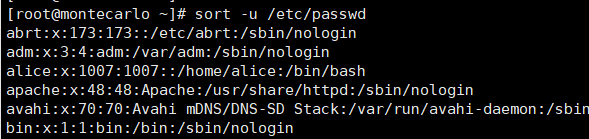
sort -u passwd.txt # 排序结果保存到out.txt文件
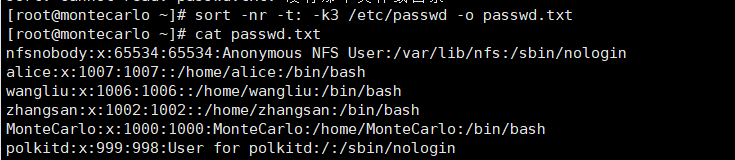
sort -nr -t: -k3 passwd.txt -o out.txt
3. uniq —— 去除连续重复行
uniq 命令用于处理重复行,但只能去掉相邻的重复行,因此通常与 sort 配合使用以实现全局去重。
常用选项
-c:对重复的行进行计数-d:只显示重复行-u:只显示不重复的行
示例
假设我们有一个 fruit.txt 文件,内容如下:
apple
apple
peache
pear
banana
cherry
cherry
banana
orange
# 去掉相邻的重复行
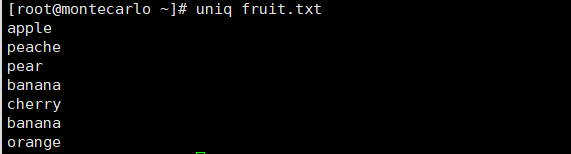
uniq fruit.txt # 先排序使重复行相邻,再去重(全局去重)
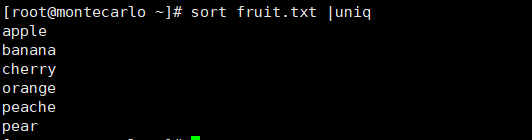
sort fruit.txt | uniq # 统计每行出现的次数
sort fruit.txt | uniq -c # 统计每行出现次数# 只显示重复行
sort fruit.txt | uniq -d # 只显示重复行# 只显示不重复的行
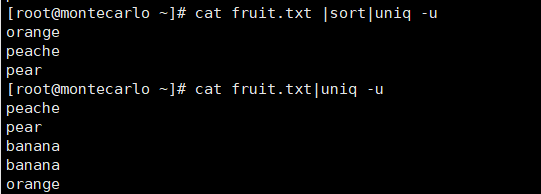
sort fruit.txt | uniq -u # 只显示不重复行
# 也可以这样写
cat fruit.txt | sort | uniq -u


实战应用:查看登录用户
# 查看当前登录的用户(去重)
who | awk '{print $1}'| uniq# 查看曾经登录过系统的用户
last | awk '{print $1}' | sort | uniq | grep -v "^$" | grep -v wtmp

4. tr —— 字符转换工具
tr 命令主要用于字符级别的处理,包括替换、删除和压缩重复字符等操作,不适合字段级别的处理。
基本语法
tr [选项]... SET1 [SET2]
从标准输入中替换、缩减和/或删除字符,并将结果写到标准输出。
常用选项
-d:删除指定的字符-s:压缩重复字符,只保留一个
示例
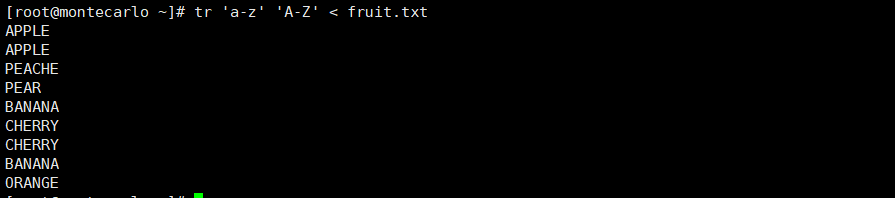
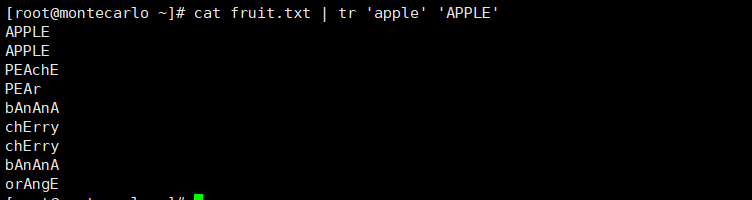
# 将fruit.txt中的小写字母转换为大写
tr 'a-z' 'A-Z' < fruit.txt
# 或者
cat fruit.txt | tr 'a-z' 'A-Z'# 字符替换是一一对应的
cat fruit | tr 'apple' 'APPLE' # 将所有'a'替换为空格
cat fruit | tr 'a' ' ' # 替换规则:a→s,p→a,l→r,e→r
cat fruit | tr 'apple' 'star' # 将所有'a'替换为'/'
tr 'a' '/' < fruit.txt # 删除所有'a'字符
tr -d 'a' < fruit.txt # 删除所有换行符
tr -d '\n' < fruit.txt # 将连续的'p'压缩成一个
tr -s 'p' < fruit.txt
5. 组合命令实战
这些命令单独使用时已经很强大,组合起来更是能解决复杂的文本处理问题。
① 统计当前连接的主机数
ss -nt | tr -s " " | cut -d " " -f5 | cut -d ":" -f1 | sort | uniq -c
命令解析:
ss -nt:查看 TCP 连接,不解析服务名-n:不解析服务名,直接显示端口号-t:只显示 TCP 连接
tr -s " ":将多个空格压缩成一个,方便后续处理cut -d " " -f5:以空格为分隔符,取第 5 列(对端地址:端口)cut -d ":" -f1:以冒号为分隔符,取第 1 段(仅保留 IP 地址)sort:排序,使相同的 IP 地址连续排列uniq -c:统计每个 IP 出现的次数(即连接数)
② 统计当前主机的连接状态
ss -nta | grep -v '^State' | cut -d" " -f1 | sort | uniq -c
③ 查看当前登录用户
who | awk '{print $1}' | uniq
④ 查看登录过系统的用户
last | awk '{print $1}' | sort | uniq | grep -v "^$" | grep -v wtmp
6. 总结口诀
- cut —— 截列取段
- sort —— 排序整理
- uniq —— 去重计数(需连续,常与 sort 联用)
- tr —— 替换删除压缩
掌握这四个命令的用法和组合技巧,能极大提高你在 Linux 系统下处理文本数据的效率,无论是日常管理还是数据分析都能游刃有余。