MySQL 索引
5.1什么是索引
-
日常生活中,经常会在电话号码簿中查阅“某人”的电话号码,按姓查询或者按字母排序查询; 在字典中查阅“某个词”的读音和含义等等,以快速的找到特定记录。在这里,“姓”和“字母”都可看作是索引, 而按“姓”或者“字母”查询则是按索引查询
a
-
索引(index)是帮助Mysql高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查询算法,这是数据结构就是索引。MySQL中,所有的数据类型都可以被索引。
-
索引是一种特殊的文件,用来快速查询数据库表中的特定记录,是提高数据库性能的重要方式
(schema)中的一个数据库对象
有序数据结构高效获取数据,加速对表的查询
与表独立存放,但不能独立存在,必须属于某个表
由数据库自动维护,表被删除时,该表上的索引自动被删除。
索引的作用类似于书的目录,几乎没有一本书没有目录,因此几乎没有一张表没有索引。
5.1.1 表有无索引的查询方式
没有索引的一张表执行执行一条sql语句是如何查询的?
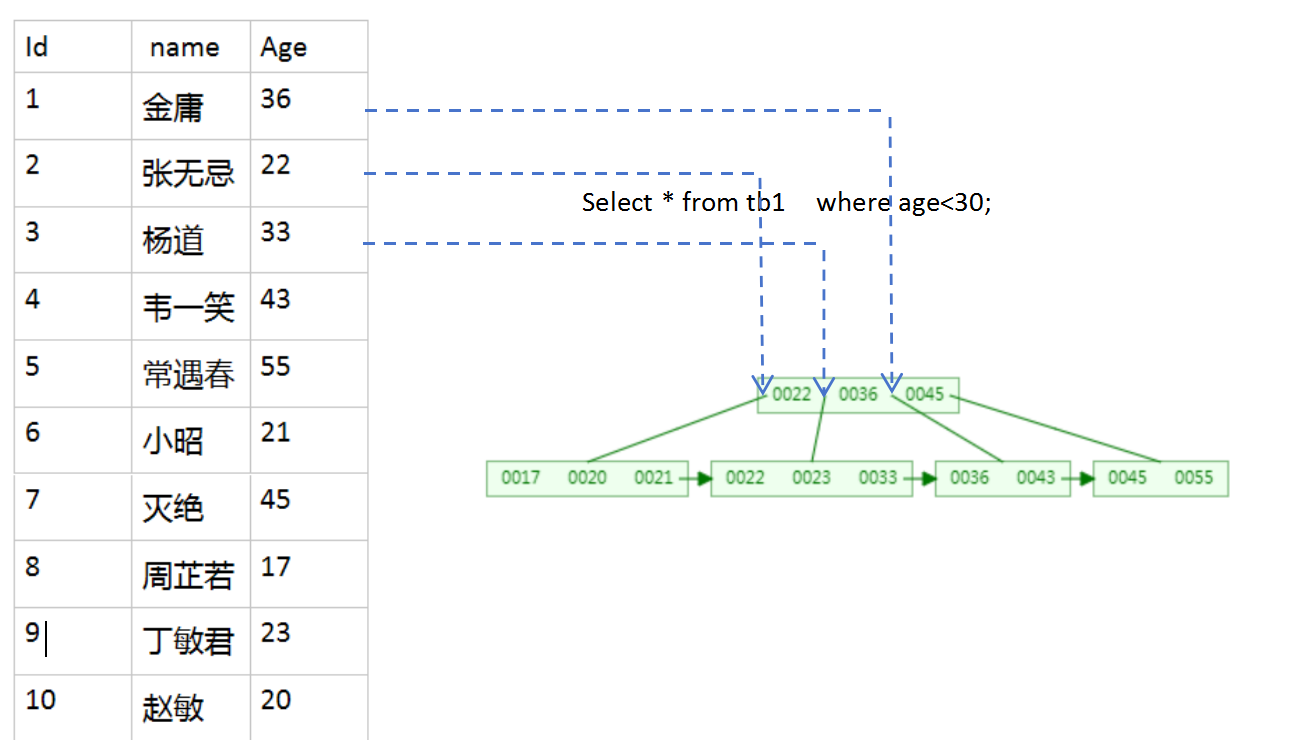
无索引是按照表格顺序遍历每一条数据获取查询的数据(全表扫描性能及低) <25
| id | name | age |
|---|---|---|
| 1 | 金庸 | 36 |
| 2 | 张无忌 | 22 |
| 3 | 杨道 | 33 |
| 4 | 韦一笑 | 43 |
| 5 | 常遇春 | 55 |
| 6 | 小昭 | 21 |
| 7 | 灭绝 | 45 |
| 8 | 周芷若 | 17 |
| 9 | 丁敏君 | 23 |
| 10 | 赵敏 | 20 |
那么当一张表如果有索引如对age列添加索引就需要对age设置数据结构。演示理解下什么是索引…
create table person(id int primary key auto_increment ,name varchar(20),age int);
insert into person (name,age) values('金庸',36),('张无忌',22),('杨道','33'),('韦一笑',43),('常遇春',55),("小昭",21),('灭绝',45),('周芷若',17),('丁敏君',23),('赵敏',20);5.1.2 有索引的查询方式
(1)b+tree数据结构
根节点 --子节点—叶子节点
一棵树最大度数(max-degree)为3阶,则根节点下可以有3个子节点,每个节点上做多存储2key,3个指针。
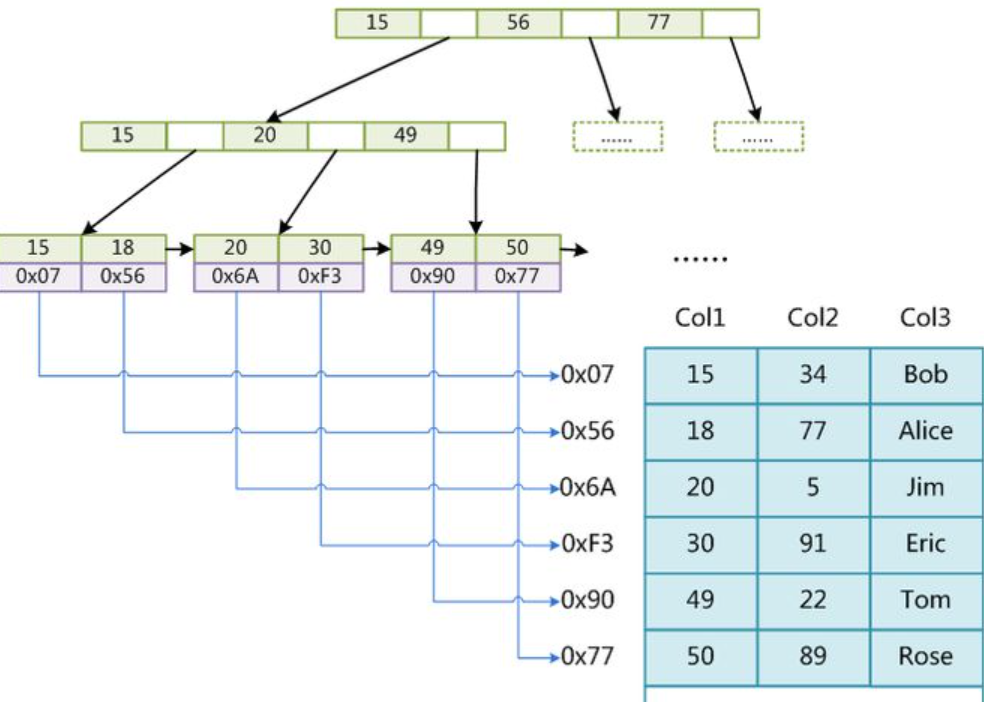
非叶子节点主要起到的索引的作用,叶子结点存放数据,并且叶子节点形成一颗单向链表,每个节点都会通过指针指向下一个节点。mysql中b+tree的结构对经典的B+tree进行了优化,在原B+tree的基础上,增加了一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的b+tree,提高区间访问的性能,利于数据库的数据排序操作。
根据B+tree的演变过程节点中key值不满足阶数要求时开始裂变,则将中间元素向上分裂的的同时将所有key值转化到叶子节点。当值小于key是在左节点,大于等于是在右结点。
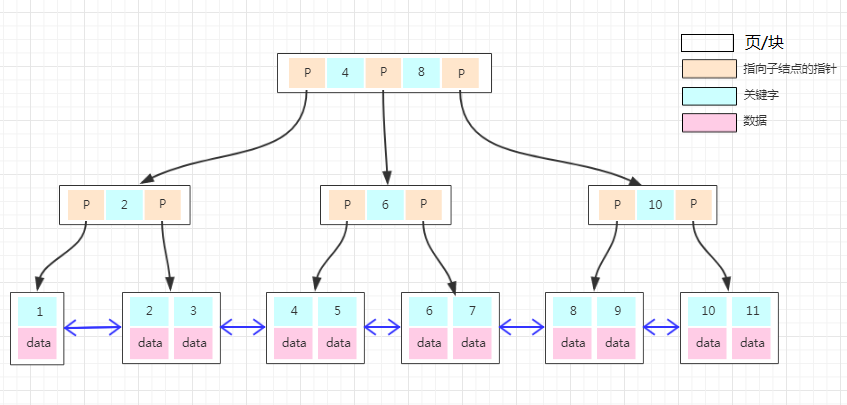
B+ Tree Visualization
(2)hash索引的原理
就是把无序的数据变成有序的查询
-
把创建的索引的列的内容进行排序
-
对排序结果生成倒排表
-
在倒排表内容上拼上数据地址链
-
在查询的时候,先拿到倒排表内容,再取出数据地址链,从而拿到具体数据
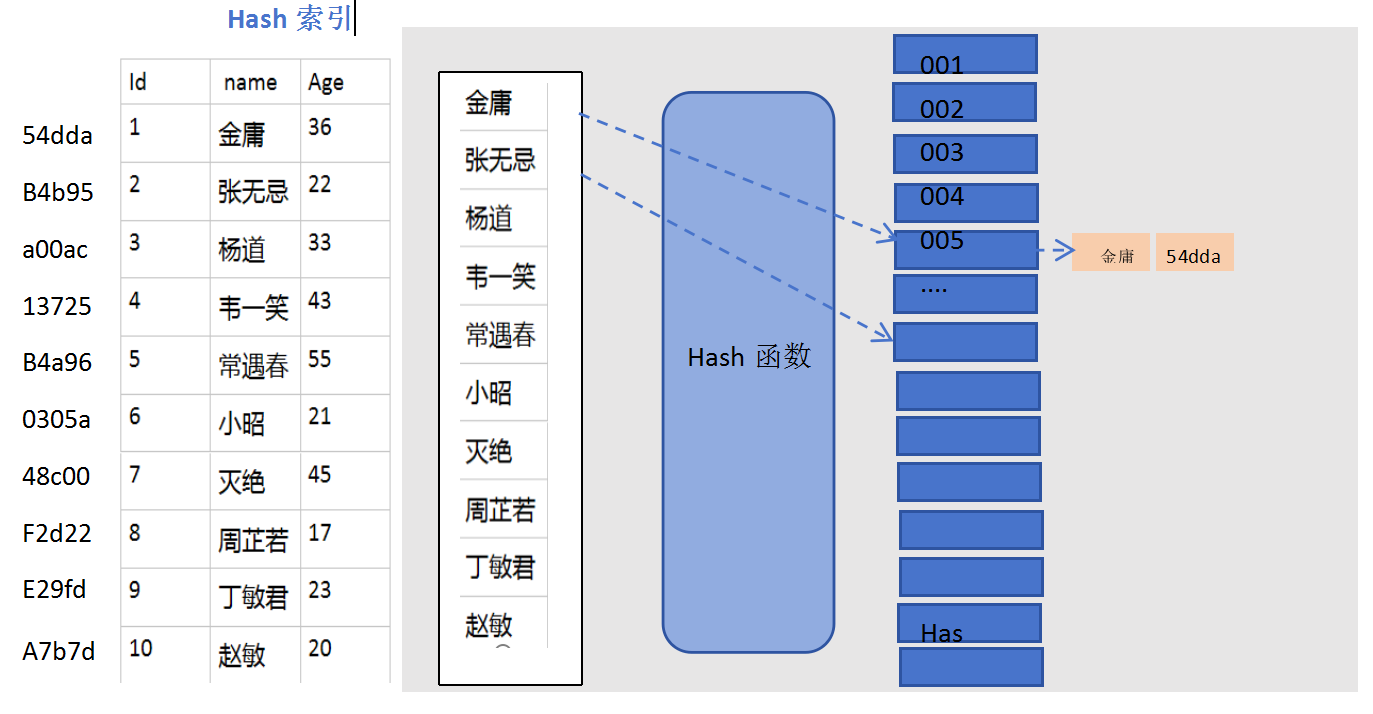
eg:对name字段创建hash索引的数据结构。
第一步:先通过hash算出该表中每一行数据的hash值
第二步:拿到name字段的所有值,根据所获取的所有值再次通过内部的hash函数来计算每一个name值应该对应在hash表的哪一个槽位中;
第三步:如金庸这个键值计算出所对应的槽位是005,则在该槽位中记录key值和该行的hash值。以此类推
还有一种情况是hash冲突:
当两个或者多个key值计算的是同一个槽位则出现了hash冲突(hash碰撞),解决方式通过hash链表来解决,在对应的值后添加链表。
hash索引的特点:
hash索引通过hash值在对应槽位查找对应元素,只能用于等值比较(=;in)不支持范围查询;
无法利用索引实现排序
查询效率高,通常只需要一次(没有hash碰撞的情况下)
(3)空间索引 r-tree
- MySQL在5.7之后的版本支持了空间索引,而且支持OpenGIS几何数据模型
- 空间索引一般是用的比较少,了解即可。
| 类型 | 含义 | 说明 |
|---|---|---|
| Geometry | 空间数据 | 任何一种空间类型INSERT INTO 表名 (字段名) VALUES (POINT(121.4737, 31.2304)) |
| Point | 点 | 坐标值INSERT INTO 表名 (字段名) VALUES (POINT(1, 2)) |
| LineString | 线 | 有一系列点连接而成 INSERT INTO 表名 (字段名) VALUES (LINESTRING(1 2, 3 4, 5 6)); 至少两个坐标点 |
| Polygon | 多边形 | 由多条线组成 INSERT INTO 表名 (字段名) VALUES (POLYGON((0 0, 0 10, 10 10, 10 0, 0 0))); |
操作
create table shop_info (id int primary key auto_increment comment 'id',shop_name varchar(64) not null comment '门店名称',geom_point geometry not null comment '经纬度',spatial key geom_index(geom_point)
);
create table shop_info (id int primary key auto_increment comment 'id',shop_name varchar(64) not null comment '门店名称',geom_point geometry not null comment '经纬度',spatial index geom_index(geom_point)
);
5.1.3 索引优缺点
| 优势 | 劣势 |
|---|---|
| 提高查询效率-提高数据检索的效率,降低数据库的IO成本 | 索引列也是要占用空间的 |
| 提高排序效率-通过索引列对数据进行排序,降低数据排序成本,降低CPU的消耗 | 索引大大提高了查询效率,同时却也降低更新表的速度,如对表进行insert update、delete时,效率降低 |
5.1.4索引分类
我们可以按照以下四个角度分类索引:
-
按数据结构分类: B+tree索引、[hash索引]、full-text索引、r-tree 空间索引
-
按物理存储分类:聚簇索引、二级索引(辅助索引)非聚簇索引
-
按字段特性分类:主键索引、唯一索引、普通索引、前缀索引,fulltext index,spatial index
-
按字段个数分类:单列索引、联合索引(多列)
索引结构 描述 B+tree 最常见的索引类型,大部分索引都支持B+tree hash索引 底层的数据结构是哈希表实现,只能精确匹配索引列的查询才有效,不支持范围查询 R-tree空间索引 是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少 Full-text全文索引 是一种通过建立倒排索引快速匹配文档的方式。 索引 INNODB MyISAM Memory B+tree 支持 支持 支持 Hash 不支持 不支持 支持 R-tree 5.7后支持 支持 不支持 Full-text 5.6版本后也支持 支持 不支持
5.1.5 索引的创建\查看\删除语法
方式一:创建表时创建索引
创建表的时候可以直接创建索引,这种方式最简单、方便。其基本形式如下:
CREATE TABLE 表名 ( 属性名 数据类型 [完整性约束条件],
属性名 数据类型 [完整性约束条件],
…
属性名 数据类型,
[UNIQUE | FULLTEXT | SPATIAL] INDEX | KEY
[别名] (属性名1[(长度)] [ASC | DESC])
);
# 创建表的时候同时创建索引
Create table 表名(Id int,Name varchar(20),Sex boolean,index [index_id](id(2)));
注:没有boolean值,默认将类型转换为tinyint
##################################create table 表名(
列名1 数据类型,
列名2 数据类型,
constraint 主键约束的名字 primary key(列名1,列名2)
);
create table 表名(
列名1 数据类型,
列名2 数据类型,
primary key (列名1,列名2)
);
create table 表名(
列名1 数据类型 primary key,
列名2 数据类型 unique key ,
);
###########################################方式二:
CREATE [ UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名
ON 表名 (字段名 [ (长度) ] [ ASC | DESC] );方式三:
ALTER TABLE 表名 ADD [ UNIQUE | FULLTEXT | SPATIAL ] INDEX
索引名(字段名 [ (长度) ] [ ASC | DESC]);查询索引
show create table table_name\G
desc table_name;
查询某张表中索引情况
show index from table_name; -- 字段看下表介绍
select * from information_schema.statistics where table_schema='db4' and 'table_name='表名';
使用计划查询SQL使用索引情况
desc|Explain select * from index1 where id=1 \G注意:
1. 如果Key是空的, 那么该列值的可以重复, 表示该列没有索引, 或者是一个非唯一的复合索引的非前导列;
2. 如果Key是PRI, 那么该列是主键的组成部分;
3. 如果Key是UNI, 那么该列是一个唯一值索引的第一列(前导列),并别不能含有空值(NULL);
4. 如果Key是MUL, 那么该列的值可以重复, 该列是一个非唯一索引的前导列(第一列)或者是一个唯一性索引的组成部分但是可以含有空值NULL。删除索引是指将表中已经存在的索引删除掉。一些不再使用的索引会降低表的更新速度,影响数据库的性能。
对于这样的索引,应该将其删除。本节将详细讲解删除索引的方法。
对应已经存在的索引,可以通过DROP语句来删除索引。基本形式如下:
alter table 表名 drop primary key;
DROP INDEX 索引名 ON 表名 ;
alter table 表名 drop index 索引名;
desc|Explain select * from index1 where id=1 \G
语法:explain select 字段列表 from 表名 where 条件;
(1)id id代表执行select子句或操作表的顺序;相同,执行顺序由上至下;不同时,id的序号会递增,id值越大,优先级越高,越先被执行
(2)2.select_type查询的类型,主要用于区别普通查询,联合查询,子查询等复杂查询simple:简单的select查询,查询中不包含子查询或union查询primary:查询中若包含任何复杂的子部分,最外层查询则被标记为primarysubquery 在select 或where 列表中包含了子查询derived (衍生)在from列表中包含的子查询结果标记为一张虚拟表, mysql会递归这些子查询,把结果放在临时表里也就是derivedunion 第二个select出现在union之后,则被标记为union,若union包含在from子句的子查询中,外层select将被标记为derivedunion result 从union表获取结果的select
(3)table 显示一行的数据时关于哪张表的
(4)partition 表分区的基本概念
表分区是将大表按规则拆分为多个物理存储单元的技术
(5)type
查询类型从最好到最差依次是:null>system>const>eq_ref>ref>range>index>All,一般情况下,得至少保证达到range级别,最好能达到ref
null 类型是查询不指定表查询显示为null 如select 123;
system :表中只有一条数据,且存储引擎可以准确的统计到这条数据。system一般出现在MyISAM、memory类型的表查询中。
由于我们一般使用的存储引擎都是InnoDB,所以system这种类型很少会用到。
const根据主键或者唯一索引显示const
ref 当连接条件使用了非唯一索引时,或者索引列与常量进行比较时EXPLAIN SELECT * FROM orders JOIN customers ON orders.customer_id = customers.id;EXPLAIN SELECT * FROM users WHERE age = 25;eq_ref:在进行多表连接查询时,表通过主键或唯一索引键进行等值查询。
all是全表扫描;
index表示用了索引但是还是会遍历整个索引树
range当where语句后面出现>或者<或者不等于等的时候会出现。
5.possible_keys
显示可能应用在这张表中的索引,一个或多个,查询到的索引不一定是真正被用到的
6.key
实际使用的索引,如果为null,则没有使用索引,因此会出现possible_keys列有可能被用到的索引,但是key列为null,表示实际没用索引。
7.key_len 不同类型占用的字节数不同(如 INT 占 4 字节,VARCHAR(10) 可能占 20+ 字节)
表示索引中使用的字节数,而通过该列计算查询中使用的 索引长度,在不损失精确性的情况下,长度越短越好,key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即,key_len是根据表定义计算而得不是通过表内检索出的
8.ref
ref 列表示索引查找时所使用的参考值来源
ref值 说明 示例场景
const 主键 /唯一键等值匹配常量 WHERE id = 123
table.column 跨表列引用 JOIN ON a.id = b.user_id
func() 函数或表达式结果 WHERE YEAR(birthday) = 1990
NULL 无外部参考值(索引扫描) WHERE age > 18
const,table.column 复合索引部分列使用常量,部分列使用列引用 WHERE a=1 AND b=table.c
理解 ref 值有助于分析查询如何利用索引,优化时应尽量让 ref 使用 const 或表列引用,避免 func() 或复杂表达式,以提升索引效率。9.rows
根据表统计信息及索引选用情况,大只估算出找到所需的记录所需要读取的行数
10.filtered 结合 Extra=Using where 时,filtered=100% 表示全表扫描且无有效过滤,filtered=10% 表示仅 10% 行满足条件。
11.Extra 如果是 Using index/where 不需要回表查询,如果是using index condiltion 表示需要回表查询。
select * from information_schema.statistics where table_schema=‘db3’ and table_name=‘index1’;
| Table_catalog | 表目录,逻辑分组的标识默认就是def |
|---|---|
| table_schema | 表所属模式(所属数据库) |
| Table_name | 表名 |
| Non_unique | 0表示有 1表示没有 |
| Index_schema | 索引的数据库 |
| Index_name | 索引的名称 |
| Seq_in_index | 索引列数,如果是联合索引显示几列 |
| Collation | 排序方式A表示升序 |
| cardinality | 基数,唯一值的估算数量(估计数可能和实际偏差大) |
| Sub_part | 是否只索引一部分字符 |
| packed | 索引列值存储格式是否压缩处理 |
| null | 字段是否为空 |
| Is_visible | 是否可见,优化是可见考虑该索引,不可见不考虑 |
| experssion | 索引基于表达式(支持函数索引类型的库中) |
(4)全文索引
- 全文索引的关键字是fulltext
- 全文索引主要用来查找文本中的关键字,而不是直接与索引中的值相比较,它更像是一个搜索引擎,基于相似度的查询,而不是简单的where语句的参数匹配。
- 用 like + % 就可以实现模糊匹配了,为什么还要全文索引?like + % 在文本比较少时是合适的,但是对于大量的文本数据检索,是不可想象的。全文索引在大量的数据面前,能比 like + % 快 N 倍,速度不是一个数量级,但是全文索引可能存在精度问题。
全文索引的版本、存储引擎、数据类型的支持情况:
-
MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引;
-
MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引;
-
只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引;
-
在数据量较大时候,现将数据放入一个没有全局索引的表中,然后再用create index创建fulltext索引,要比先为一张表建立fulltext然后再将数据写入的速度快很多;
-
测试或使用全文索引时,要先看一下自己的 MySQL 版本、存储引擎和数据类型是否支持全文索引。
MySQL 中的全文索引,有两个变量,最小搜索长度和最大搜索长度,对于长度小于最小搜索长度和大于最大搜索长度的词语,都不会被索引。通俗点就是说,想对一个词语使用全文索引搜索,那么这个词语的长度必须在以上两个变量的区间内。这两个的默认值可以使用以下命令查看:
show variables like '%ft%';
参数解释: 4
| # | 参数名称 | 默认值 | 最小值 | 最大值 | 作用 |
|---|---|---|---|---|---|
| 1 | ft_min_word_len | 4 | 1 | 3600 | MyISAM引擎表创建全文索引最小词和最大词长度 |
| 2 | ft_query_expansion_limit | 20 | 0 | 1000 | MyISAM引擎表使用 查询扩展进行全文搜索的最大匹配数 |
| 3 | innodb_ft_min_token_size | 3 | 0 | 16 | InnoDB 引擎表全文索引包含的最小词长度 |
| 4 | innodb_ft_max_token_size | 84 | 10 | 84 | InnoDB 引擎表全文索引包含的最大词长度 |
操作
-- 创建表的时候添加全文索引
create table t_article (id int primary key auto_increment ,title varchar(255) ,content varchar(1000) ,writing_date date,fulltext (content) -- 创建全文检索
);insert into t_article values(null,"Yesterday Once More","When I was young I listen to the radio",'2021-10-01');
insert into t_article values(null,"Right Here Waiting","Oceans apart, day after day,and I slowly go insane",'2021-10-02');
insert into t_article values(null,"My Heart Will Go On","every night in my dreams,i see you, i feel you",'2021-10-03');
insert into t_article values(null,"Everything I Do","eLook into my eyes,You will see what you mean to me",'2021-10-04');
insert into t_article values(null,"Called To Say I Love You","say love you no new year's day, to celebrate",'2021-10-05');
insert into t_article values(null,"Nothing's Gonna Change My Love For You","if i had to live my life without you near me",'2021-10-06');
insert into t_article values(null,"Everybody","We're gonna bring the flavor show U how.",'2021-10-07');-- 修改表结构添加全文索引
alter table t_article add fulltext index_content(content)
-- 直接添加全文索引
create fulltext index index_content on t_article(content);
使用全文索引和常用的模糊匹配使用 like + % 不同,全文索引有自己的语法格式,使用 match 和 against 关键字,格式:
match (col1,col2,...) against(expr [search_modifier])
select * from t_article where match(content) against('yo'); -- 没有结果 单词数需要大于等于3
select * from t_article where match(content) against('you'); -- 有结果
5.2.8 聚簇索引和非聚簇索引(二级索引)
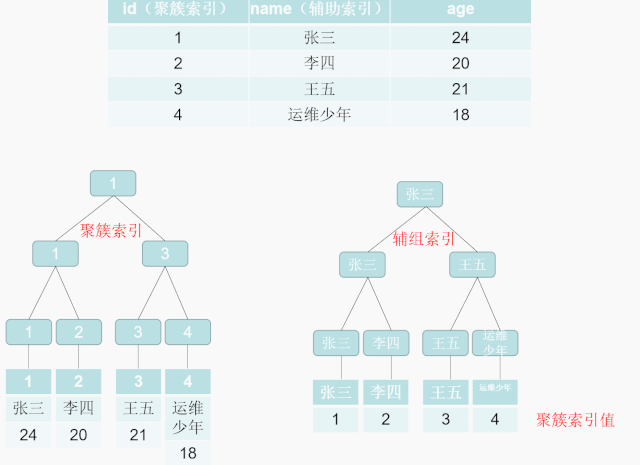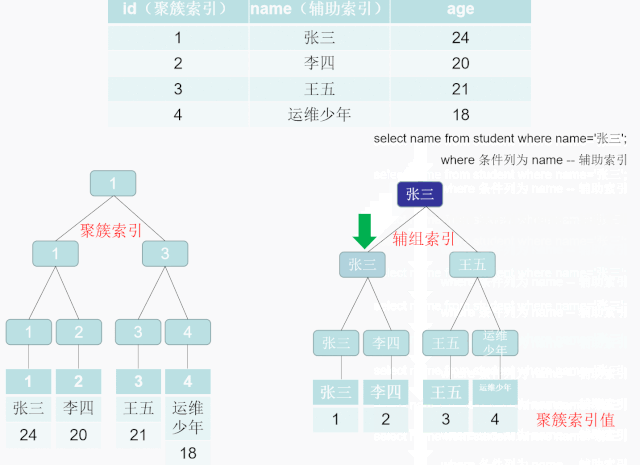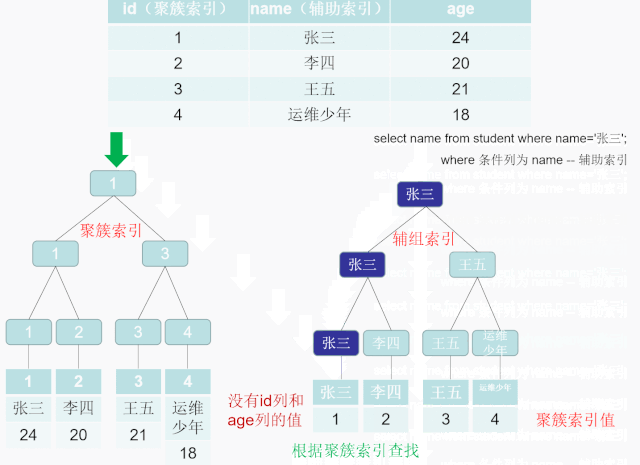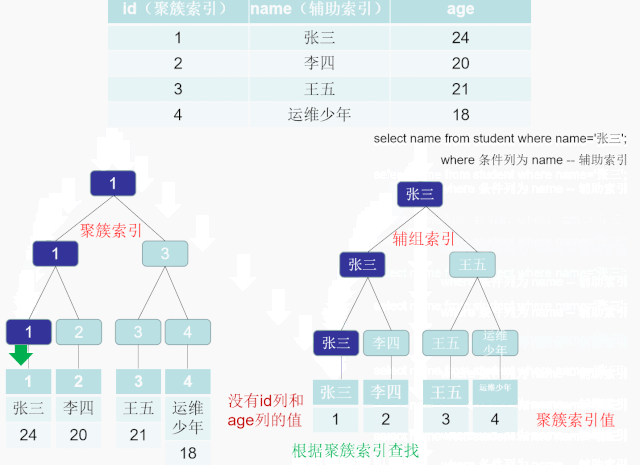
聚簇索引
索引 B+Tree 的叶子节点存储了整行数据的是主键索引,也被称之为聚簇索引。聚簇索引是对磁盘上实际数据重新组织以按指定的一个或多个列的值排序的算法。特点是存储数据的顺序和索引顺序一致。一般情况下主键会默认创建聚簇索引,且一张表只允许存在一个聚簇索引 , 因为数据一旦存储,顺序只能有一种。找到了索引就找到了需要的数据,那么这个索引就是聚簇索引,所以主键就是聚簇索引,修改聚簇索引其实就是修改主键。(not null ,unique)
一般来说,一个表一定有聚簇索引,就算不定义,InnoDB也会自动选择列生成索引:
1) 有主键时,根据主键创建聚簇索引
2) 没有主键时,会用一个唯一且不为空的索引列作为主键,成为此表的聚簇索引
3) 如果以上两个都不满足那innodb自己创建一个虚拟的聚集索引
聚簇索引查找过程:
>CREATE TABLE world.student(`id` INT AUTO_INCREMENT NOT NULL COMMENT 'id',`name` VARCHAR(10) NOT NULL COMMENT '姓名',`age` INT NOT NULL COMMENT '年龄',PRIMARY KEY(id),INDEX idx_name(NAME))ENGINE=INNODB DEFAULT CHARSET='utf8mb4';
\>INSERT INTO world.`student`(NAME,age) VALUES('张三',24),('李四',20),('王五',21),('运维少年',18);
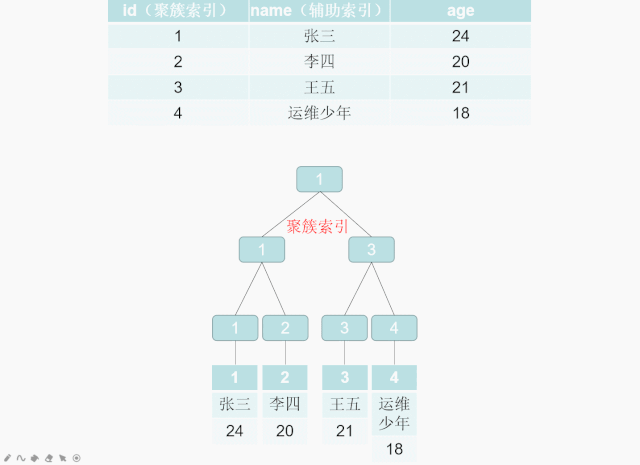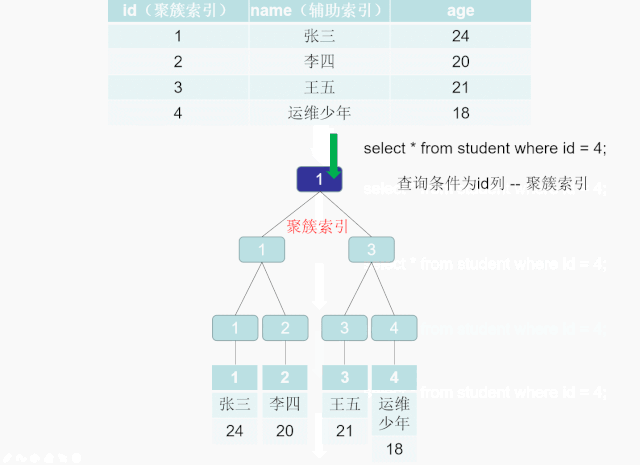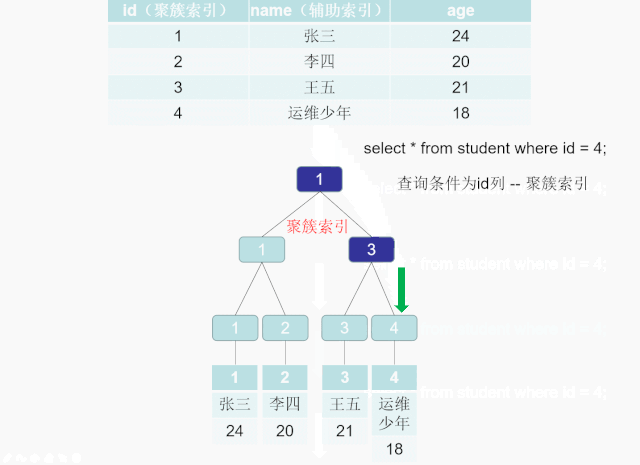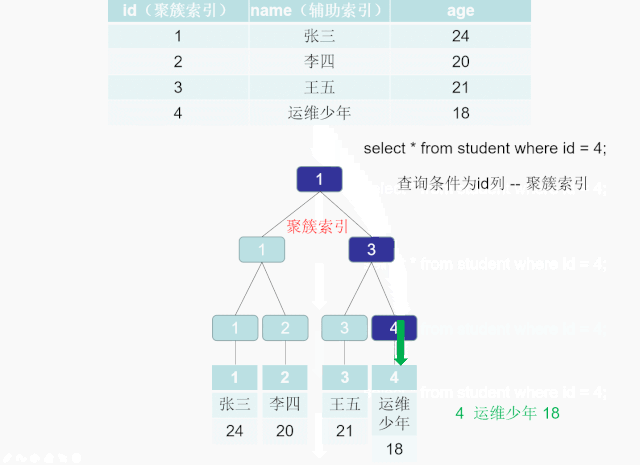
辅助索引,二级索引,非聚簇索引
索引B+Tree 的叶子节点只存储了键的值和索引列就是是非主键索引,也被称之为非聚簇索引。一个表可以有多个非聚簇索引 。 非聚簇索引的存储和数据的存储是分离的,也就是说可能找到了索引但没找到数据,需要根据索引上的值(主键)再次回表查询,非聚簇索引也叫做辅助索引。
乱建索引的后果?
按照业务语句的需求创建合适的索引,并不是将所有列都建立索引
1)每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大
2)修改表时,对索引的重构和更新很麻烦,越多的索引,会使表更新变得很浪费时间
3)优化器的负担会很重,有可能会影响到优化器的选择
索引失效
1.条件中索引列进行了运算操作包括函数运算索引失效。 tel varchar(20) index
2.字符串类型字段使用时不加单引号索引失效select * from t1 where tel=12345678902; 若tel是varchar类型查询有无单引号都可以但是无引号索引失效。
3.模糊查询仅仅在尾部模糊匹配索引不会失效,但是首部则会失效。 like ‘passwd%’ like ‘%passwd’
4.or连接条件如果前面条件中列有索引,但后面没有索引name涉及的索引都不会用到
5.mysql数据评估影响当全表扫描比index更快时,不选择索引,如查询的值整张表数据都(或大部分)满足要求
- 示例:新建表,插入大量数据,通过无索引查询及有索引查询来对比性能
mysql> create database mydb13_indexdb;
mysql> use mydb13_indexdb;
mysql> create table student(id int, name varchar(64), age int(2));
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int | YES | | NULL | |
| name | varchar(64) | YES | | NULL | |
| age | int | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+mysql> insert into student values(1,'das',20),(2,'dasdas',19),(3,'dsfsfsd',18),(4,'bbggbbg',22),(5,'eeeee',19);mysql> insert into student select * from student;
mysql> insert into student select * from student;
……
# 多次执行上述的自我复制,将数据量增加到百万级……
……
mysql> insert into student select * from student;
Query OK, 1310720 rows affected (13.59 sec)
Records: 1310720 Duplicates: 0 Warnings: 0# 插入一条新数据
mysql> insert into student values(666,'andy',40);# 查询刚插入的新数据
mysql> select * from student where id=666;
+------+------+------+
| id | name | age |
+------+------+------+
| 666 | andy | 40 |
+------+------+------+
1 row in set (2.75 sec) # 耗费2.75秒# 查看文件容量,student表占用120M
C:\ProgramData\MySQL\MySQL Server 8.0\Data\mydb13_indexdbmysql> create index id_index on student(id); # 给student表新建索引
Query OK, 0 rows affected (12.13 sec) # 耗时较长
Records: 0 Duplicates: 0 Warnings: 0mysql> select * from student where id=666; # 在有索引的情况下再次查询
+------+------+------+
| id | name | age |
+------+------+------+
| 666 | andy | 40 |
+------+------+------+
1 row in set (0.00 sec) # 有索引查询花费的时间mysql> select 2.75/0.000001; # 性能提升了
+----------------+
| 2.75/0.000001 |
+----------------+
| 2750000.000000 |
+----------------+# 再次查看文件容量,新建索引前为120m,新建索引后为164m,表容量增大
C:\ProgramData\MySQL\MySQL Server 8.0\Data\mydb13_indexdb# 总结:索引的本质就是以空间换时间,同时把随机的事件变成顺序的事件,日常项目开发中,读写比例在10:1左右,查询使用频率比较大,虽然损失点存储空间但两害取其轻,还是需要对关键字段新建索引提高查询性能,最后需要删除上述student表
mysql> drop table student;
mysql> show tables;
练习与作业
- 新建数据库mydb14_job,其下创建workinfo表,创建表的同时在id字段上创建名为index_id的唯一性索引,而且以降序的格式排列,workinfo表内容如下所示
| 字段描述 | 数据类型 | 主键 | 外键 | 非空 | 唯一 | 自增 |
|---|---|---|---|---|---|---|
| id 编号 | int(10) | 是 | 否 | 是 | 是 | 是 |
| name 职位名称 | varcahr(20) | 否 | 否 | 是 | 否 | 否 |
| type 职位类别 | varcahr(10) | 否 | 否 | 否 | 否 | 否 |
| address 工作地址 | varchar(50) | 否 | 否 | 否 | 否 | 否 |
| wage 工资 | int | 否 | 否 | 否 | 否 | 否 |
| contents 工作内容 | tinytext | 否 | 否 | 否 | 否 | 否 |
| extra附加信息 | text | 否 | 否 | 否 | 否 | 否 |
mysql> create database mydb14_job;
Query OK, 1 row affected (0.01 sec)
mysql> use mydb14_job;
Database changedmysql> create table workinfo( id int(10) not NULL unique primary key auto_increment, name varchar(20) not NULL, type varchar(10), address varchar(50), wage int, content tinytext, extra text, unique index index_id(id desc) );# 使用create index语句为name字段创建长度为10的索引index_name
mysql> create index index_name ON workinfo(name(10));
# 使用alter table语句在type和address上创建名为index_t的索引
mysql> alter table workinfo add index index_t(type,address);# 查看workinfo表的索引
mysql> show create table workinfo \G
# 删除workinfo表的唯一性索引index_t
mysql> drop index index_t ON workinfo;