一个日志量突增的问题分析处理经历
问题描述
周一早上,还是和往常一样的巡检。通过告警日志,发现了生产区集群上的一个实例周末出现了异常。
图片 1 Alert_With_Checkpoint_log
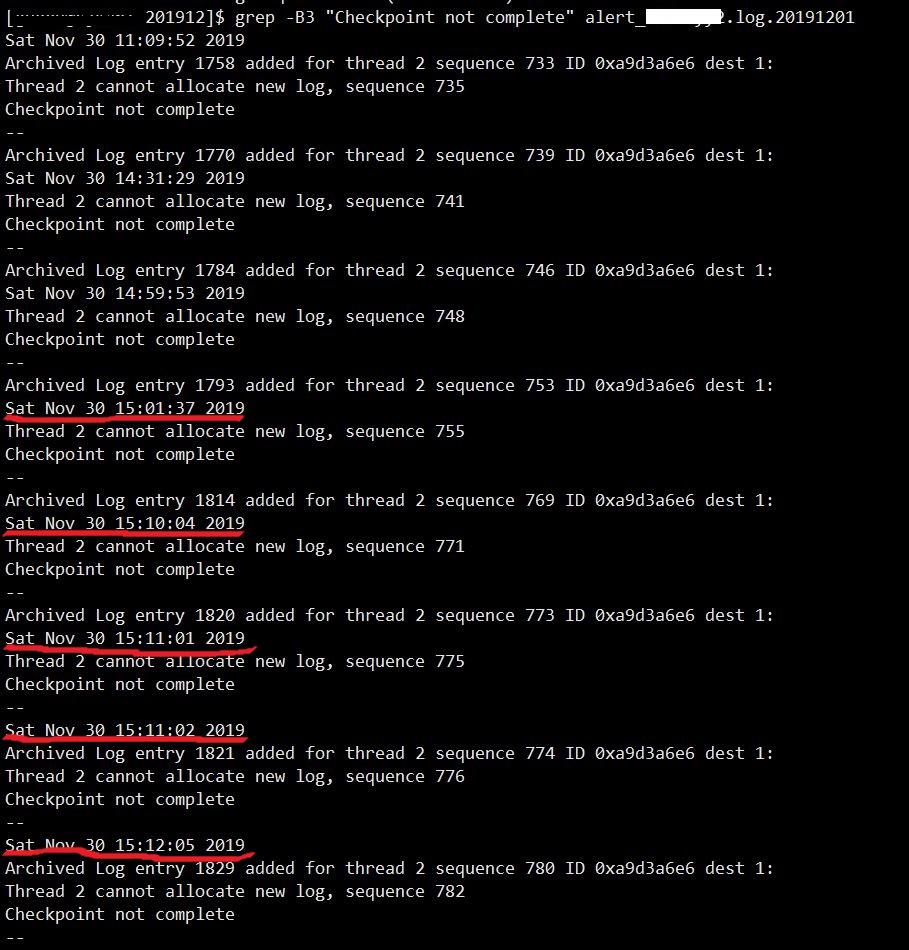
如图,周六下午15时开始,数据库在线联机日志组疯狂切换,检查点发生的频率也很高且一直处于未完成的状态。
该实例属于主业务的附加数据库系统,平时也就和主库交换一下数据,段总数据容量也不超过100G大小,如此频繁的检查点未完成(实际上通过grep命令检索出” Checkpoint not complete”关键字在当日告警日志中出现了200多次),是非常不正常的。
图片 2 Logfile_Switch_Rate
再次翻看日志切换频率记录,发现该实例自从周六下午15时开始一直到周一中午10时,每小时的平均日志切换45次,尤其是在周日一整天,日志一共切换了1047次。
初步分析
出现了这样的情况,怀疑是周六周日业务发生了异常突变,但开发那边的兄弟也并没有反应数据库运行缓慢。
对于目前采集的诊断数据,可有有以下俩种情况可以考虑。
- 虽然联机日志切换的很快,但数据库并未真实产生那么多日志。
我们先来探讨一下检查点未完成的情况,这个我们都知道,oracle联机日志组是可以手动切换的,如果切换的过于频繁或者说业务逻辑中存在大量的commit,都会造成大量的” Checkpoint not complete”;除此之外当系统IO性能不足时,dbwr不能及时写出buffer pool里的脏块也会产生检查点等待。
当然,以上几种猜测都是不能成立的,首先手动切换归档自少需要alter system 权限,这个一般不会轻易授权给业务用户,程序里也不会出现大量的”alter system archive log current”;其次即使程序里出现大量的commit操作,那也只会造成检查点问题,可通过告警日志我们发现检查点问题基本上是由于日志组切换造成的,而根据诊断日志组确实发生了大量的切换;最后,集群里的其他实例并没有出现这样大量的检查点问题。
由此,可以考虑一下第二种情况。
- 数据库在周末确实发生了大量的业务,产生了大量的日志。
图片 3 Archivelog_Detail

如图,通过对周末rman备份信息可以发现,12月2日一天的归档备份就有354G,这个值几乎是体积数据量的4倍,看来系统在周末是发生了一些特别的业务。
随后询问相关业务人员,得到的回复却是正常业务的进行,难怪业务在周末并没有反馈系统问题,但即使是业务正常运行,这个量级的日志量也是有很大的性能隐患的,好在系统还是比较健壮的,并未出现一些关键性的错误。
所以说,对于一个合格的数据库运维工程师,要想保障系统安全稳定长期高效运转,每日细心巡检还是非常重要的,好在之前有把告警日志按天分割归档的习惯。
那么下一步就是要把这个安全隐患给找出来,先来个AWR看看指标。
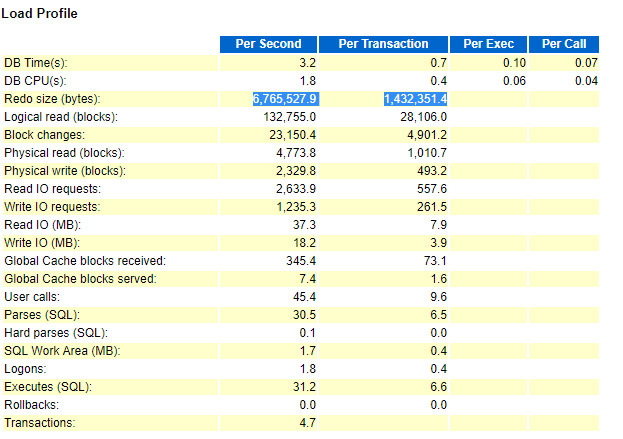
图片 4 Awr's_Load_Profile
图片 5 Awr's_IO_Profile
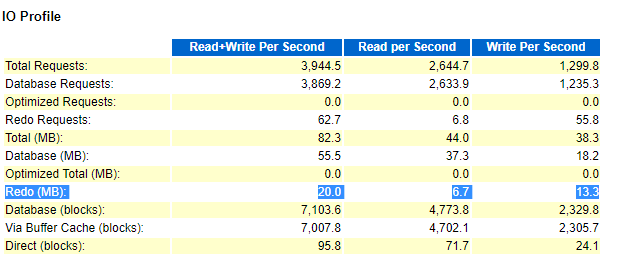
首先,系统负载中,redo size的统计项每秒钟近6m的日志条目产生,每事务日志量也高于平常值,IO profile中对于redo每秒读写统计也是很高。
关于这俩项统计指标,到底多少算高或者说多少算低呢?这个是没有固定的标准,主要取决于系统数据体量和业务繁忙程度,那么到底怎么去衡量呢?本例中我们采用了对比不同时刻AWR方法,关于业务正常时刻的AWR和业务出现异常时刻的AWR统计项对比如下:
图片 6 Awr's_LoadProfile_Difference
| 异常时刻 | 正常时刻 | |||
| Redosize(bytes) | Per Second | Per Transaction | Per Second | Per Transaction |
| 6,765,527.9 | 1,432,351.4 | 54,610.4 | 4,873.7 | |
| Redo(MB)) | Read per Second | Write Per Second | Read per Second | Write Per Second |
| 6.7 | 13.3 | 0.0 | 0.1 | |
图片 7 Awr's_Top_Events
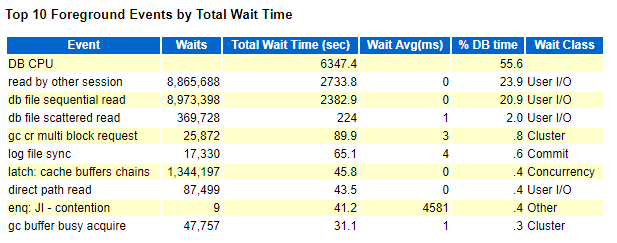
等待事件中DB cpu ,read by other session 首当其冲,此外还有一个特别的enq:JL-contention等待事件值得注意一下,所占DB Time比率较小,但是平均等待时间就有4.5秒左右。
对于enq:JL-contention 等待事件,查阅MOS给出以下解释:
图片 8 enq:jl-Contntion

提出怀疑
大概是和物化视图刷新有关系,看到这不禁想起来之前关于物化视图的介绍。物化视图不同于视图,其具有实体的段来进行数据存储,在OLAP数据仓库系统中对避免热块争用,SQL语句查询性能有很大的提升,甚至分布式物化视图还能提供类似于OGG单表数据同步功能。
既然是基表的同步表,那一定涉及到和基表数据同步的问题,Oracle定义了物化视图四种刷新方法和三种刷新方式,其中刷新方法中最常用的俩种FAST(即增量刷新方法)、COMPLETE(即完全刷新方法)。
关于刷新方法,最高效的就是FAST刷新,对于基表数据的变更通过基表对应的物化视图日志进行增量同步,而不是基表数据表更,对物化视图同步的方式是先TRUNCATE整个物化视图再重新插入的COMPLETE 同步方式,这样以来不仅高效而且产生了日志量也不是一个级别的。
再结合一下之前的日志切换频率有一定的规律性,单节点基本是每个小时45次左右,有理由怀疑是业务作了一个完全刷新的物化视图表并定时刷新。
图片 9 Awr_Segment's_Orderby
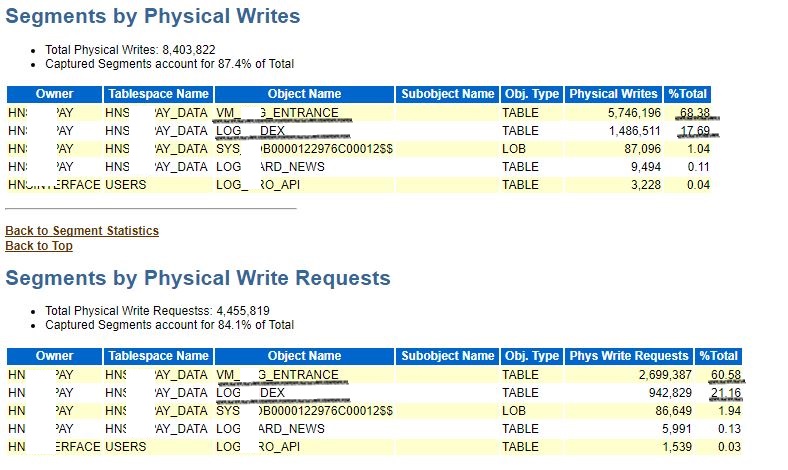
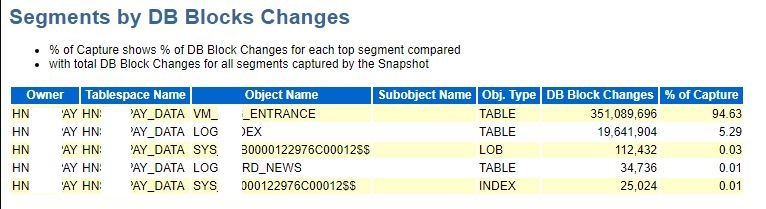
翻阅了一下AWR中关于segment统计的部分,基本上都是这俩张表占用了快照时间内85%左右的段统计比率。重点关注一下这个物理写和块变更统计。尤其是块变更统计中VM_xxxxx_ENTRANCE所占比率95%左右,DB Block Changes更是达到了3.5亿次,这个变更量可以说是非常大了,高频率的块变更就会导致大量的日志产生。
论证猜想
嗯,下一步就应该好好查查这张表,没准还真是一个物化视图。
图片 10 Materialized_view's_Detail
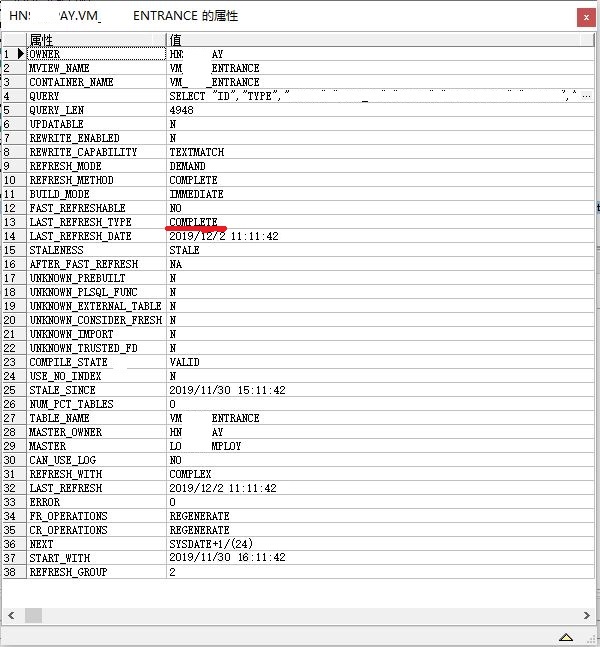
表VM_xxxx_ENTRANCE的确为11月30日创建的物化视图,最近一次刷新方法为完全刷新。再查询一下此物化视图的数据量为2000多万条,是一个不小的数据表。可以想象一下每小时对一个俩千万数据量表进行重新插入,日志量自然也是巨量的,而且这其中还有不少次手工调用DBMS_REFREASH包。
图片 11 Awr's_Sql_Orderby

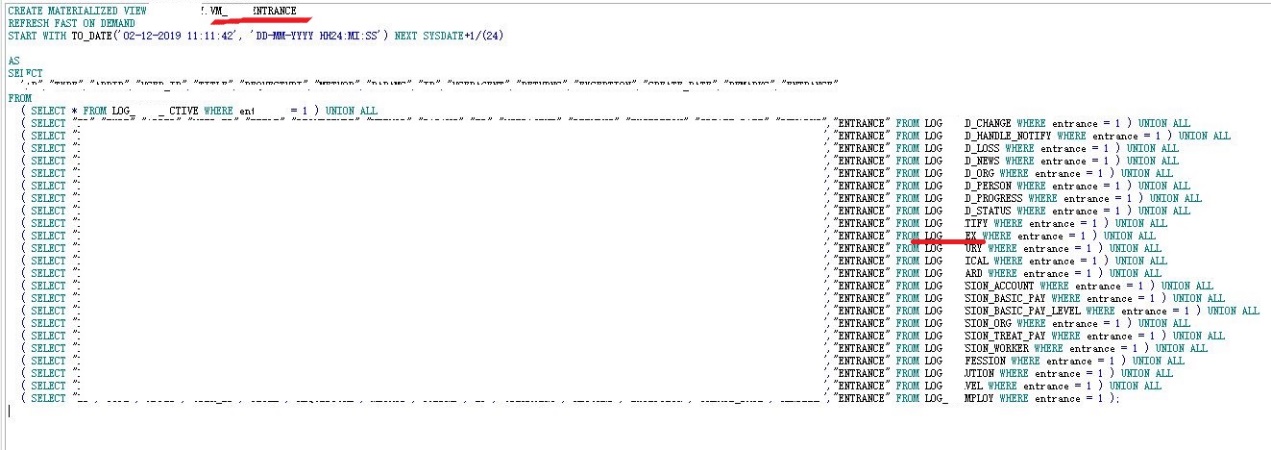
表LOGxxxxxxDEX确认为物化视图VM_xxxx_ENTRANCE的一张基表,并存在极大改动。仔细观察这个物化视图还是一个多表联立查询视图,怪不得业务想要把它作成一个物化视图。想法是好的,但是基表大多数都是频繁更新的日志表,而且FAST刷新方式对多表联立以及使用函数聚合后的物化视图限制也很多,如果没有正确的配置将不能实现增量刷新。这样一来虽然优化了多表联立长查询的SQL cpu消耗,但是物化视图和基表之间完全刷新却带来了更加严重的问题。
解决处理
随即告知业务对这个物化视图再次进行配置,这一次终于实现了FAST刷新,业务时间段内产生的日志量也恢复了正常。
图片 12 Materialized_view_Reconfig
图片 13 Logfile_Switch_Rate
问题排查到这里,我们再回头梳理一下。业务上应该是遇到了一个多表联立长查询SQL问题,直接把它做成了物化视图,由于所选用的基表很多,自然而然的物化视图就很大,由于不正确的配置导致物化视图刷新方式是完全刷新,与此同时基表本身的变动又很大,虽然指定了一个小时一次的刷新频率,但其中又有不少次手动调用包刷新的情况,最后整个系统每个小时才会出现这种非常的日志量。
最后的话
说到这里,很多小伙伴对物化视图不是那么的熟悉,我们平常在生产系统中也很少见有人用,但是Oracle既然给出了这个功能,它就一定能在某些特定的情形下发挥特别的作用。物化视图能带来很大的SQL优化收益,但在OLTP系统中所需要的资源代价无疑是巨大了,在OLAP系统中,由于基表数据大多数是不变的,在作一些数据分析时有些SQL性能提升是很明显的,类似的使用情形还有索引组织表,BITMAP索引等等。
回到本例,最后还是和业务说明了物化视图的利害,建议不要在生产系统里使用这个物化视图。Oracle的确提供了很多个不同于平常的功能或使用方式,我们不能一昧的说它不好或者好,重要的是对某个功能要了解它的利害,在正确的适用范围下使用,就能起到事半功倍的效果。
