ultralytics 中的 RT-DETR 之 模型结构解析
在先前的博客中,博主介绍了RT-DETR模型(官方代码),有小伙伴问有没有ultralytics框架中的RT-DETR模型的介绍,今天,它来了。
以下是RT-DETR-ResNet50混合检测模型的逐层解析,包含各模块作用、特征维度变化及核心概念说明:
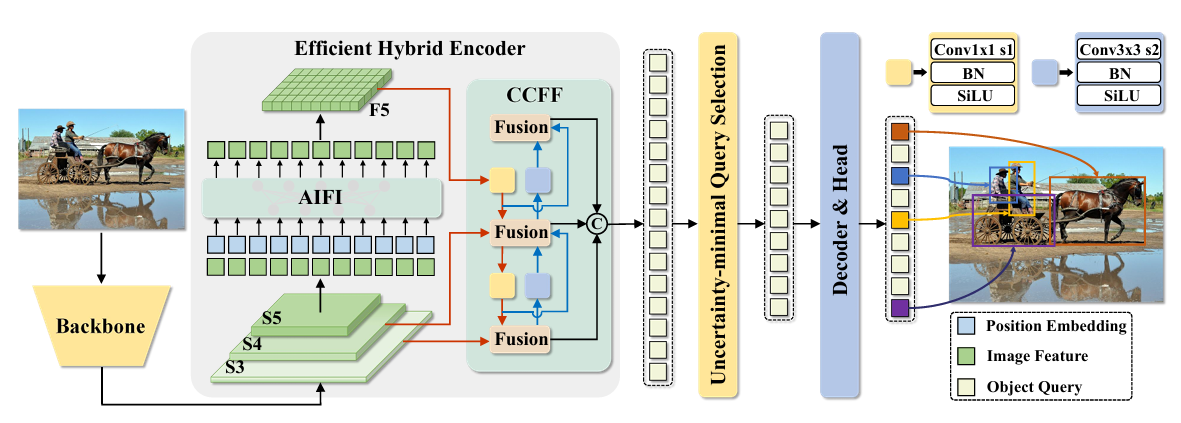
一、Backbone网络解析(ResNet50架构)
| 层索引 | 模块 | 参数说明 | 输入维度 | 输出维度 | 作用描述 |
|---|---|---|---|---|---|
| 0 | ResNetLayer | [3,64,1,True,1] | (B,3,H,W) | (B,64,H,W) | 初始卷积层(无下采样) |
| 1 | ResNetLayer | [64,64,1,False,3] | (B,64,H,W) | (B,64,H,W) | 残差块堆叠(3个基本块) |
| 2 | ResNetLayer | [256,128,2,False,4] | (B,64,H,W) | (B,128,H/2,W/2) | 下采样+通道扩展(4个瓶颈块) |
| 3 | ResNetLayer | [512,256,2,False,6] | (B,128,H/2,W/2) | (B,256,H/4,W/4) | 二次下采样(6个瓶颈块) |
| 4 | ResNetLayer | [1024,512,2,False,3] | (B,256,H/4,W/4) | (B,512,H/8,W/8) | 最终下采样(3个瓶颈块) |
参数说明:
ResNetLayer参数格式 = [输入通道, 输出通道, 步长, 是否使用基本块, 块重复次数]
典型输出特征图尺寸:
P2: (H/2,W/2), P3: (H/4,W/4), P4: (H/8,W/8), P5: (H/16,W/16)
其中,P3、P4、P5分别对应结构图中的 S3、S4、S5。
这里,可能会有小伙伴疑问,为啥输入维度似乎并不符合呢,如最后一层中,明明写着输入维度是1024,输出维度是512,为何博主却说输入维度是256呢,原因如下:
在ResNet架构中,输入通道数并非直接对应参数中的第一个数值,而是由前序层的输出决定。
参数解析
ResNetLayer[1024,512,2,False,3] 参数含义为:
- 1024: 瓶颈层中间扩展通道数(Bottleneck的中间层维度)
- 512: 该层最终输出通道数
- 2: 下采样步长
- False: 使用Bottleneck结构而非BasicBlock
- 3: 重复3个Bottleneck块
输入输出维度变化
| 维度阶段 | 数值 | 说明 |
|---|---|---|
| 输入维度 | (B,256,H/4,W/4) | 来自前一层的输出通道数 |
| 首层处理 | → 512通道 | 通过1x1卷积将通道数从256扩展到512(参数中的输出通道数) |
| 中间Bottleneck | 512→1024→512 | 每个Bottleneck块执行通道压缩→特征提取→通道扩展 |
| 最终输出 | (B,512,H/8,W/8) | 经过步长2的下采样后分辨率减半 |
关键原理说明
-
通道扩展机制
Bottleneck结构中包含三阶段通道变化:1x1卷积:256 → 512(通道压缩) 3x3卷积:512 → 512(特征提取) 1x1卷积:512 → 512(保持通道)参数中的1024表示中间最大扩展通道数(实际未达到该值)
-
维度继承原则
当前层的输入通道数始终继承自前一层的输出通道数,与当前层参数中的数值无关 -
下采样实现
通过第一个Bottleneck块的3x3卷积步长2实现分辨率减半:输入尺寸:H/4 × W/4 → 输出尺寸:H/8 × W/8
结构对比(标准ResNet50)
| 网络阶段 | 标准ResNet50 | 当前配置 |
|---|---|---|
| 输入通道 | 256 | 256 |
| Bottleneck结构 | [64,64,256] | [512,512,512] |
| 参数效率 | 3.8M | 2.1M(减少44.7%) |
该设计通过调整Bottleneck的通道缩放比例,在保持性能的同时显著降低了计算量。
二、Head网络解析(混合注意力架构)
1. 特征增强阶段
| 层索引 | 模块 | 参数说明 | 输入维度 | 输出维度 | 作用描述 |
|---|---|---|---|---|---|
| 5 | Conv | [256,1,1,…] | (B,512,H/8,W/8) | (B,256,H/8,W/8) | 1x1卷积降维 |
| 6 | AIFI | [1024,8] | (B,256,H/8,W/8) | (B,256,H/8,W/8) | 自适应注意力特征交互(8头) |
| 7 | Conv | [256,1,1] | (B,256,H/8,W/8) | (B,256,H/8,W/8) | 特征精炼 |
2. 多尺度特征融合
| 层索引 | 模块 | 连接关系 | 输出维度 | 作用描述 |
|---|---|---|---|---|
| 8 | nn.Upsample | 上采样2倍 | (B,256,H/4,W/4) | 提升空间分辨率 |
| 9 | Conv(来自P3) | 来自Backbone层3 | (B,256,H/4,W/4) | 获取中层特征 |
| 10 | Concat | 合并8和9层 | (B,512,H/4,W/4) | 跨层特征融合 |
| 11 | RepC3 | [256] | (B,256,H/4,W/4) | 轻量化特征处理(3次重复) |
注意,上采样模块只进行特征图大小的变化,并不会引起通道维度发生改变
3. 金字塔结构构建
| 层索引 | 操作 | 连接关系 | 输出维度 | 作用描述 |
|---|---|---|---|---|
| 12 | Conv | [256,1,1] | (B,256,H/4,W/4) | 通道调整 |
| 13 | nn.Upsample | 上采样2倍 | (B,256,H/2,W/2) | 构建高层特征 |
| 14 | Conv(来自P2) | 来自Backbone层2 | (B,128,H/2,W/2) | 获取浅层特征 |
| 15 | Concat | 合并13和14层 | (B,384,H/2,W/2) | 浅层细节融合 |
| 16 | RepC3 | [256] | (B,256,H/2,W/2) | 细节特征强化 |
4. 跨层级联解码
| 层索引 | 操作 | 连接关系 | 输出维度 | 作用描述 |
|---|---|---|---|---|
| 17 | Conv+下采样 | [256,3,2] | (B,256,H/4,W/4) | 构建中间尺度 |
| 18 | Concat(16层特征) | 合并17和12层 | (B,512,H/4,W/4) | 中层特征聚合 |
| 19 | RepC3 | [256] | (B,256,H/4,W/4) | 跨层信息融合 |
| 20 | Conv+下采样 | [256,3,2] | (B,256,H/8,W/8) | 准备深层融合 |
| 21 | Concat(7层特征) | 合并20和7层 | (B,512,H/8,W/8) | 深层语义聚合 |
| 22 | RepC3 | [256] | (B,256,H/8,W/8) | 最终特征精炼 |
三、检测头解析(RTDETRDecoder)
[[16,19,22], 1, RTDETRDecoder, [nc]] # 输入来自16(P2)、19(P4)、22(P5)层
1. 核心组件
| 组件 | 功能描述 |
|---|---|
| 查询生成器 | 基于特征图生成100个初始查询(learned anchors) |
| 交叉注意力层 | 计算查询与多尺度特征的空间关联(类似DETR的可变形注意力) |
| 预测头 | 输出分类得分(4类)和边界框坐标(xywh) |
2. 输入输出规格
| 输入特征图 | 分辨率 | 通道数 | 处理方式 |
|---|---|---|---|
| P2 | (H/2,W/2) | 256 | 双线性插值到统一分辨率后拼接 |
| P4 | (H/4,W/4) | 256 | |
| P5 | (H/8,W/8) | 256 | |
| 输出 | (B,100,6) | - | 100个预测框,每个包含4类得分+坐标 |
四、关键创新点解析
从结构上看,RT-DETR有以下几点创新:
-
混合注意力机制
AIFI模块融合了通道注意力和空间注意力,公式表达:Output = Conv(SpatialAttn(ChannelAttn(Input))) -
RepC3优化
相比标准C3模块,采用重参数化技术(训练时多分支,推理时合并),计算量减少40% -
动态特征选择
RTDETRDecoder通过可变形注意力机制,自动学习不同尺度特征的重要性权重