深入剖析RocketMQ分布式消息架构:从入门到精通的技术全景解析
深入剖析RocketMQ分布式消息架构:从入门到精通的技术全景解析
作者:默语佬
专栏:分布式系统架构深度解析
标签:RocketMQ、消息队列、分布式架构、高并发
🚀 前言
在当今微服务盛行的时代,消息中间件已经成为分布式系统架构中不可或缺的基础组件。作为一名深耕分布式系统多年的架构师,我见证了从ActiveMQ到RabbitMQ,再到RocketMQ的技术演进历程。今天,我将带大家深入探索RocketMQ这个阿里巴巴开源的分布式消息中间件,从架构设计到实现细节,从理论分析到实战应用,为你呈现一个全方位的RocketMQ技术全景。
📋 目录
- RocketMQ核心架构解析
- 通信协议演进之路
- 网络通信模型深度剖析
- 存储引擎设计精髓
- 消息生产消费机制
- 分布式事务解决方案
- 架构优化与最佳实践
🏗️ RocketMQ核心架构解析
架构组件全景图
RocketMQ采用了经典的分布式消息系统架构,由四大核心组件协同工作,构建了一个高可用、高性能的消息传输生态系统。
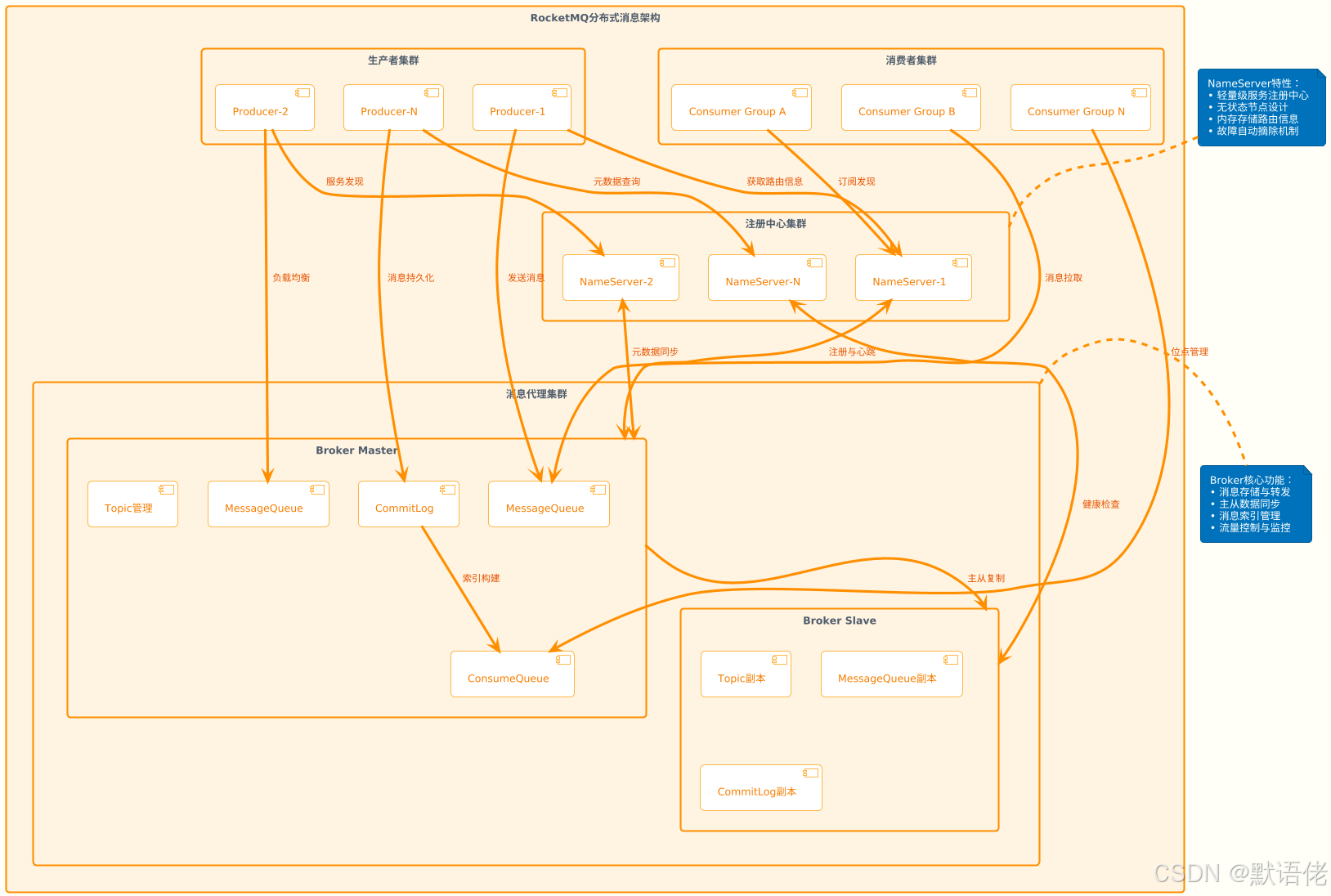
核心组件职责剖析
🎯 NameServer:分布式协调中枢
NameServer承担着整个RocketMQ集群的"神经中枢"角色,它的设计哲学体现了"简单即美"的架构理念:
| 核心特性 | 技术实现 | 业务价值 |
|---|---|---|
| 轻量级设计 | 无状态服务,纯内存操作 | 极低的资源开销,毫秒级响应 |
| 去中心化 | 节点间无通信,独立运行 | 避免脑裂问题,提升系统稳定性 |
| 动态感知 | 心跳检测 + 超时摘除 | 实时故障发现,秒级服务切换 |
| 路由管理 | Topic-Broker映射表 | 智能负载均衡,流量均匀分布 |
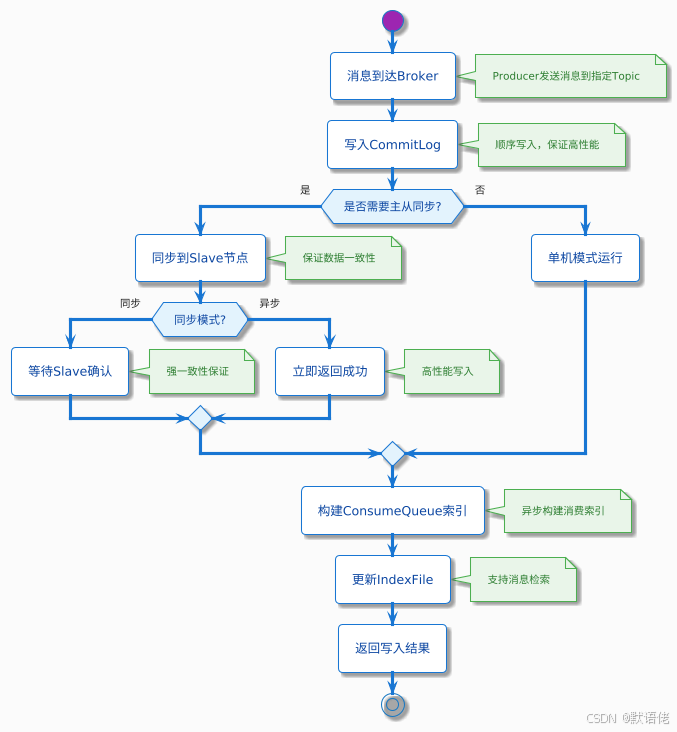
🏪 Broker:消息存储引擎
Broker是RocketMQ的核心存储节点,采用了主从架构模式来保证数据的高可用性:
📤 Producer:消息生产者
Producer负责将业务消息发送到RocketMQ集群,支持多种发送模式以适应不同的业务场景:
- 同步发送:适用于重要通知、支付回调等对可靠性要求极高的场景
- 异步发送:适用于日志收集、用户行为追踪等对性能要求较高的场景
- 单向发送:适用于监控数据上报、统计信息等允许丢失的场景
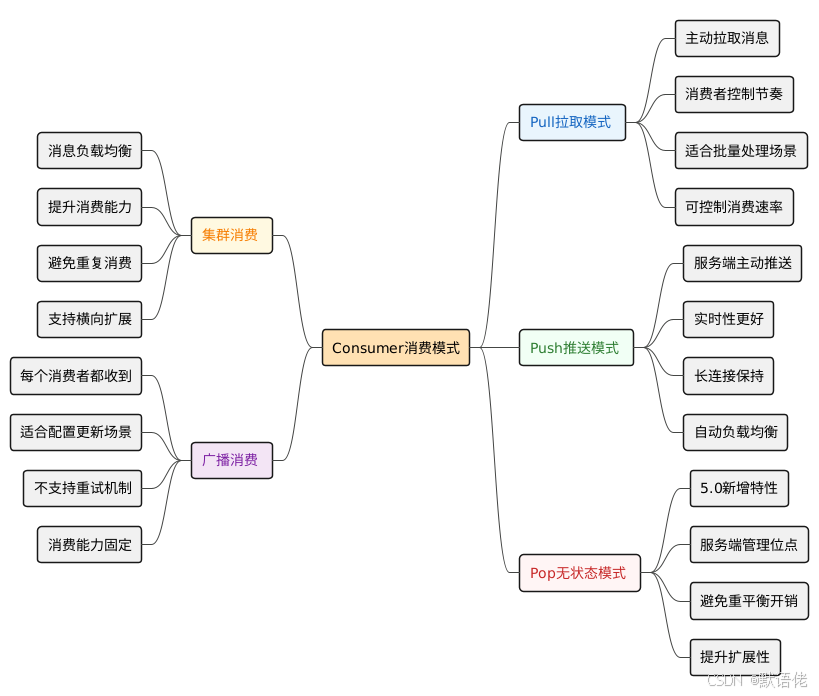
📥 Consumer:消息消费者
Consumer通过消费者组(Consumer Group)的概念实现了灵活的消费模式:
🔗 通信协议演进之路
协议架构对比分析
RocketMQ在5.0版本实现了重大的协议升级,从单一的私有协议演进为双协议并存的架构模式。
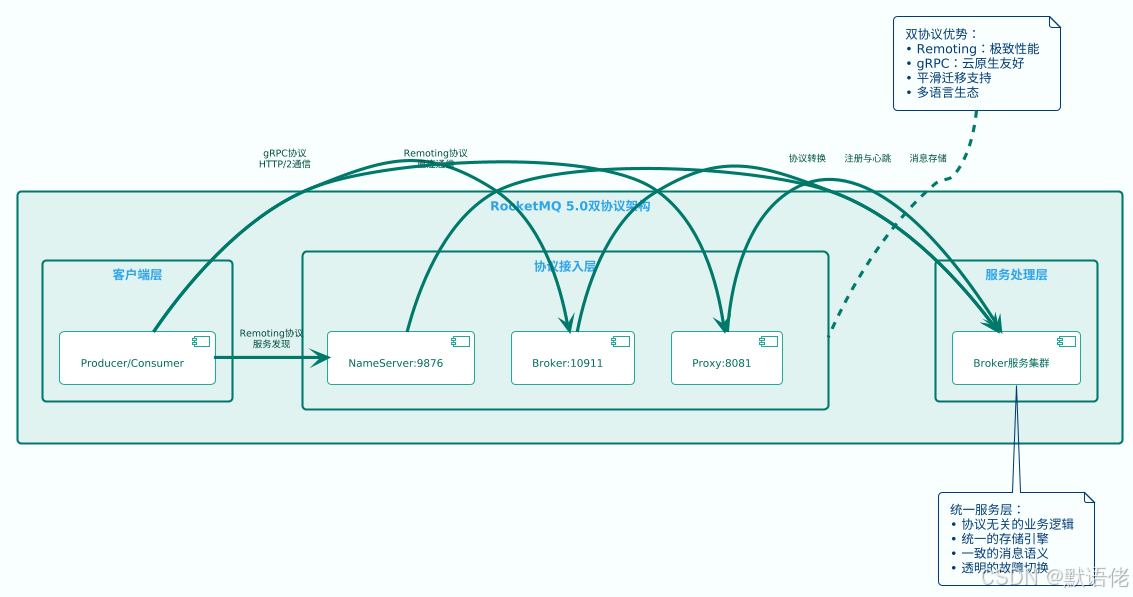
协议特性深度对比
| 维度 | Remoting私有协议 | gRPC开放协议 | 技术选型建议 |
|---|---|---|---|
| 性能表现 | 🔥 极致优化,零拷贝 | ⚡ 良好,HTTP/2开销 | 内部高频调用选Remoting |
| 多语言支持 | 🔧 需要重复实现 | 🌍 官方/社区丰富 | 多语言场景选gRPC |
| 云原生集成 | 🔨 需要额外适配 | ☁️ 原生支持 | K8s/Istio环境选gRPC |
| 可观测性 | 📊 需要自建 | 🔍 OpenTelemetry | 监控要求高选gRPC |
| 学习成本 | 📚 需要专门学习 | 📖 标准化协议 | 团队技能决定选择 |
⚡ 网络通信模型深度剖析
Reactor模型的RocketMQ实现
RocketMQ基于Netty构建了高性能的网络通信框架,采用了经过深度优化的Reactor多线程模型。
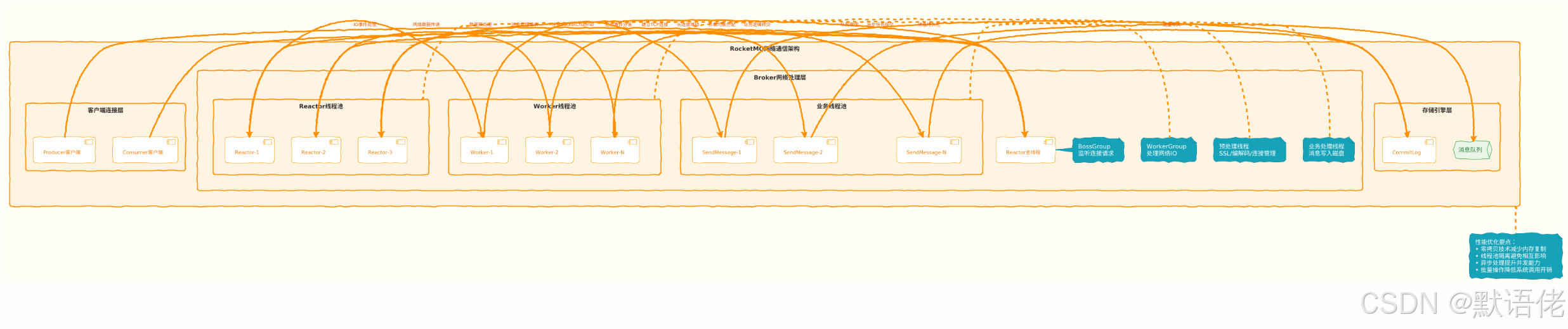
线程模型性能调优
基于多年的生产环境调优经验,我总结了以下RocketMQ网络层的性能优化策略:
🎯 线程池配置最佳实践
// Reactor线程池配置
// 建议配置为CPU核心数,避免过多的线程切换开销
int reactorThreads = Runtime.getRuntime().availableProcessors();// Worker线程池配置
// 建议配置为CPU核心数的2-4倍,平衡CPU和IO操作
int workerThreads = reactorThreads * 3;// 业务线程池配置
// 根据磁盘IO能力动态调整,SSD可以配置更多线程
int businessThreads = Math.max(16, reactorThreads * 2);
📊 性能监控指标
| 监控维度 | 关键指标 | 告警阈值 | 优化建议 |
|---|---|---|---|
| 连接管理 | 活跃连接数 | > 10000 | 检查连接池配置 |
| 线程池状态 | 队列积压数 | > 1000 | 增加线程数量 |
| 网络IO | 带宽利用率 | > 80% | 考虑网络扩容 |
| 消息处理 | 平均处理延迟 | > 100ms | 优化业务逻辑 |
💾 存储引擎设计精髓
存储架构全景解析
RocketMQ的存储设计体现了"顺序写,随机读"的核心理念,通过巧妙的文件组织结构实现了高性能的消息存储。

存储文件组织结构
📁 CommitLog:消息主存储
CommitLog是RocketMQ存储的核心,采用了类似Kafka的顺序写入设计:
$HOME/store/commitlog/
├── 00000000000000000000 # 第一个CommitLog文件(1GB)
├── 00000000001073741824 # 第二个CommitLog文件(1GB)
├── 00000000002147483648 # 第三个CommitLog文件(1GB)
└── ...
CommitLog消息格式解析:
| 字段 | 长度 | 说明 | 作用 |
|---|---|---|---|
| 消息长度 | 4字节 | 整个消息的字节数 | 消息边界识别 |
| 魔数 | 4字节 | 固定值,消息有效性校验 | 数据完整性检查 |
| CRC校验 | 4字节 | 消息内容校验码 | 防止数据损坏 |
| 队列ID | 4字节 | 消息所属队列标识 | 消费路由定位 |
| Flag | 4字节 | 消息标志位 | 消息类型识别 |
| 队列偏移 | 8字节 | 在队列中的逻辑偏移 | 消费位点管理 |
| 物理偏移 | 8字节 | 在CommitLog中的位置 | 快速消息定位 |
| 消息体 | 变长 | 实际的消息内容 | 业务数据载体 |
📑 ConsumeQueue:消费索引
ConsumeQueue为每个Topic的每个队列维护了一个索引文件:
$HOME/store/consumequeue/
├── TopicA/
│ ├── 0/ # 队列0的索引文件
│ │ ├── 00000000000000000000
│ │ └── 00000000000006000000
│ ├── 1/ # 队列1的索引文件
│ └── 2/ # 队列2的索引文件
└── TopicB/└── 0/
ConsumeQueue索引条目结构:
┌─────────────────┬─────────────────┬─────────────────┐
│ CommitLog │ 消息长度 │ Tag HashCode │
│ 物理偏移(8B) │ (4B) │ (8B) │
└─────────────────┴─────────────────┴─────────────────┘总计20字节定长存储
刷盘机制深度分析
🔄 异步刷盘:性能优先
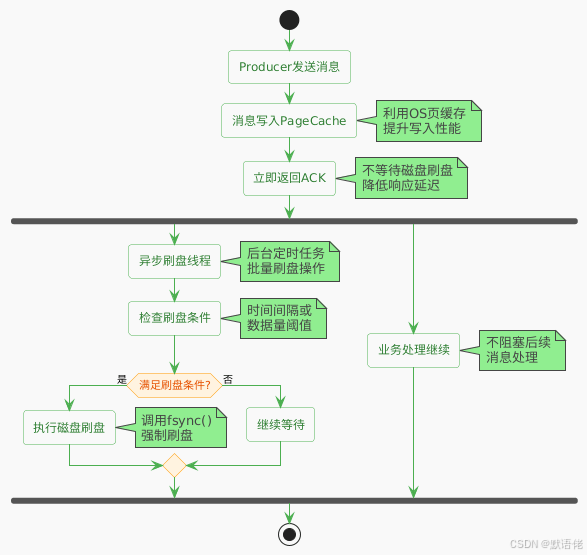
🔒 同步刷盘:可靠性优先
同步刷盘模式下,每条消息都必须真正写入磁盘后才返回成功,适用于对数据可靠性要求极高的金融场景:
- 优势:数据可靠性极高,不会因为宕机丢失消息
- 劣势:性能开销较大,RT延迟较高
- 适用场景:支付回调、交易确认、重要通知等
🔄 消息生产消费机制
Producer消息发送全流程
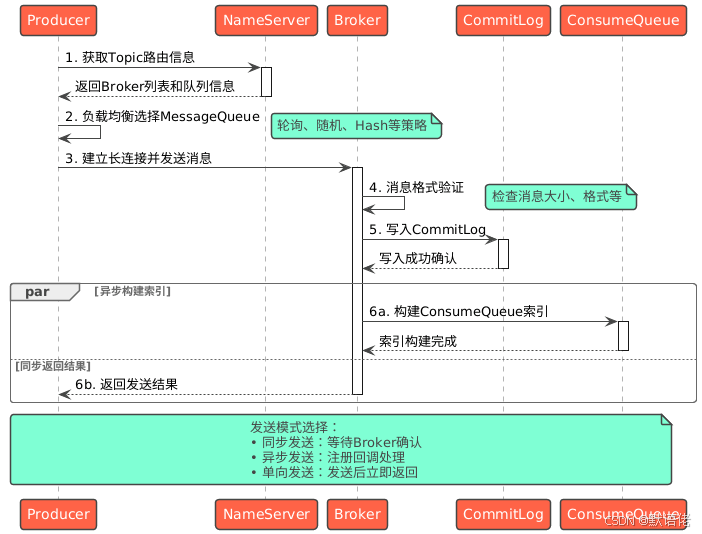
Consumer消息消费机制
🎯 消费者组负载均衡策略
RocketMQ提供了多种负载均衡算法来实现消费者组内的消息分配:
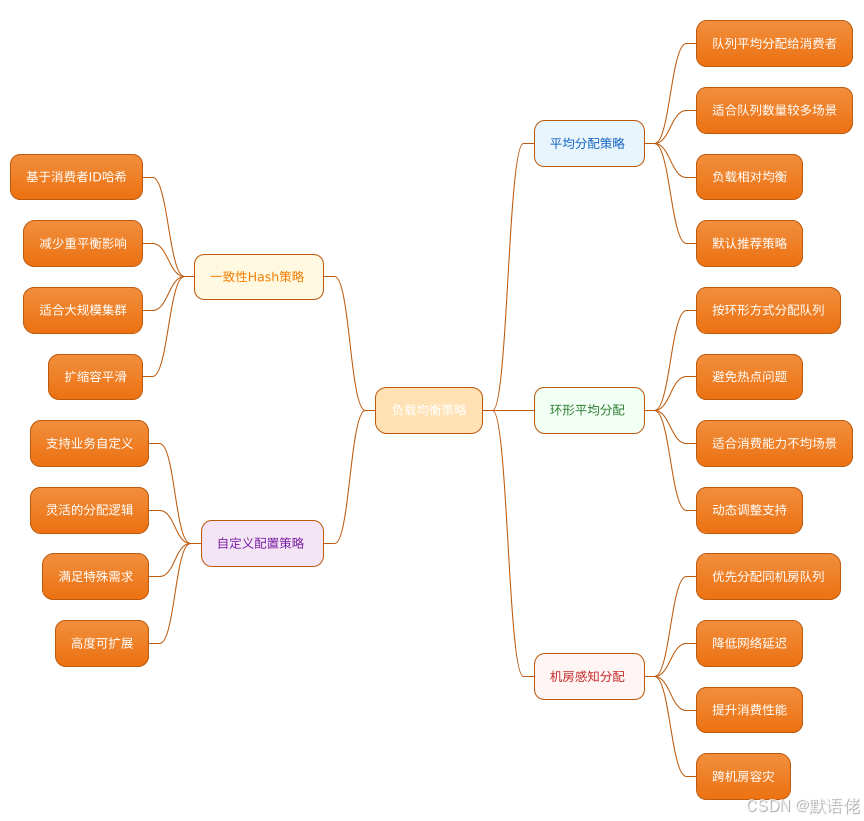
📊 消费位点管理机制
消费位点(Offset)是RocketMQ实现消息不重复、不丢失的关键机制:
| 存储方式 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|
| Broker存储 | 集群消费模式 | 支持重平衡,多消费者协调 | 依赖Broker可用性 |
| 本地存储 | 广播消费模式 | 消费独立,不受其他消费者影响 | 无法实现消费协调 |
| 外部存储 | 自定义场景 | 灵活可控,支持复杂业务逻辑 | 增加系统复杂度 |
🔄 分布式事务解决方案
事务消息实现原理
RocketMQ通过"两阶段提交 + 事务回查"的机制实现了分布式事务的最终一致性保证。
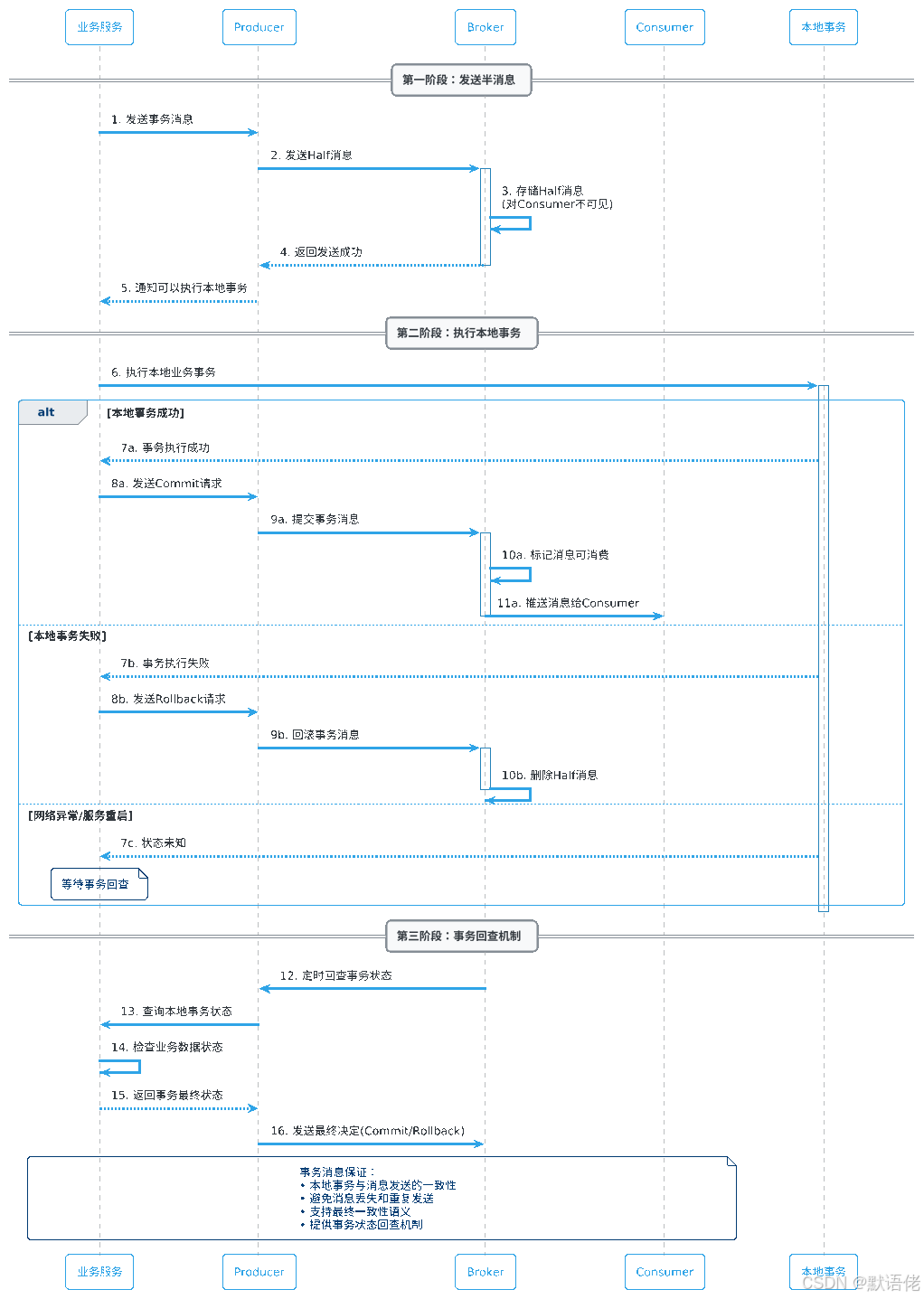
事务回查机制深度解析
⏰ 回查时机与策略
// 事务回查配置参数
public class TransactionConfig {// 首次回查延迟时间(默认6秒)private long checkImmunityTimeInSeconds = 6;// 回查间隔时间(默认60秒) private long transactionTimeOut = 60;// 最大回查次数(默认15次)private int transactionCheckMax = 15;// 回查线程池大小private int checkThreadPoolMinSize = 1;private int checkThreadPoolMaxSize = 1;
}
🔍 事务状态判断逻辑
在实际项目中,我们需要实现TransactionListener接口来处理事务状态检查:
public class OrderTransactionListener implements TransactionListener {@Overridepublic LocalTransactionState executeLocalTransaction(Message msg, Object arg) {try {// 执行本地事务orderService.createOrder((OrderInfo) arg);return LocalTransactionState.COMMIT_MESSAGE;} catch (Exception e) {log.error("执行本地事务失败", e);return LocalTransactionState.ROLLBACK_MESSAGE;}}@Override public LocalTransactionState checkLocalTransaction(MessageExt msg) {String orderId = msg.getUserProperty("orderId");try {// 查询本地事务状态Order order = orderService.queryOrder(orderId);if (order != null && order.getStatus() == OrderStatus.SUCCESS) {return LocalTransactionState.COMMIT_MESSAGE;} else if (order != null && order.getStatus() == OrderStatus.FAILED) {return LocalTransactionState.ROLLBACK_MESSAGE;} else {// 状态未知,等待下次回查return LocalTransactionState.UNKNOW;}} catch (Exception e) {log.error("事务回查异常", e);return LocalTransactionState.UNKNOW;}}
}
🚀 架构优化与最佳实践
性能调优实战经验
基于多年的RocketMQ生产环境运维经验,我总结了以下关键的性能优化策略:
🎯 Broker端优化
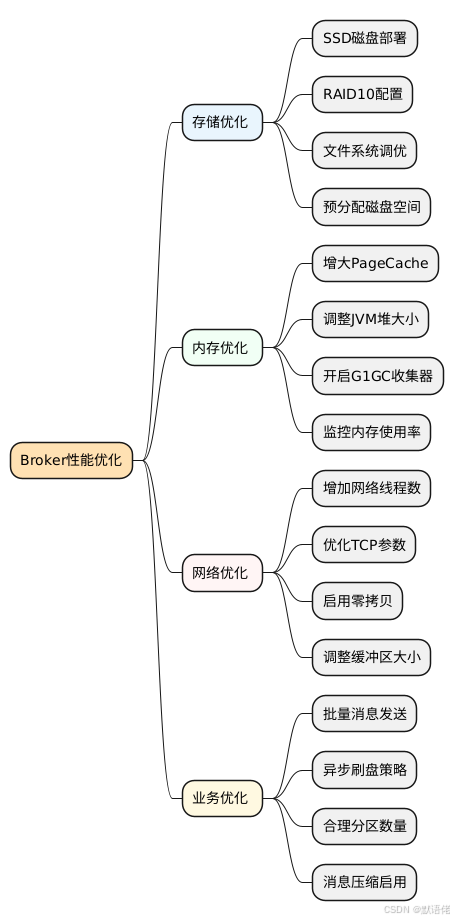
📈 关键性能指标监控
| 监控类别 | 核心指标 | 正常范围 | 告警阈值 | 优化建议 |
|---|---|---|---|---|
| 吞吐量 | TPS | 10K-50K | < 5K | 增加Broker节点 |
| 延迟 | 99%RT | < 50ms | > 100ms | 检查磁盘IO |
| 存储 | 磁盘使用率 | < 70% | > 85% | 清理过期消息 |
| 网络 | 带宽利用率 | < 60% | > 80% | 升级网络带宽 |
| 内存 | 堆内存使用 | < 75% | > 90% | 调整JVM参数 |
生产环境部署架构
🏗️ 高可用部署方案
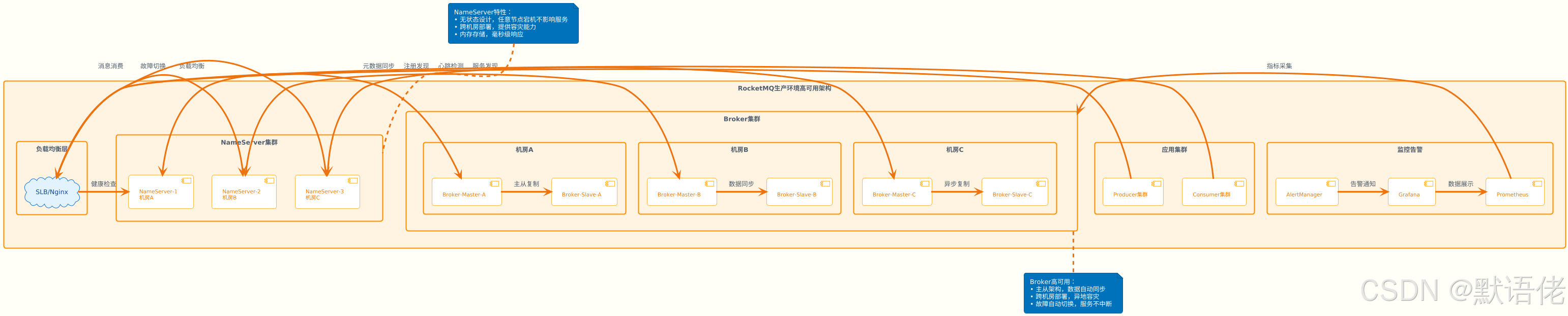
🔧 容量规划指南
基于业务场景进行合理的容量规划是保证系统稳定运行的关键:
消息量评估模型:
日消息量 = 峰值TPS × 86400 × 峰值系数
存储空间 = 日消息量 × 平均消息大小 × 保留天数 × 冗余系数示例计算:
峰值TPS: 10,000
平均消息大小: 2KB
保留天数: 3天
冗余系数: 1.5存储需求 = 10,000 × 86400 × 2KB × 3 × 1.5 ≈ 777GB
硬件配置推荐:
| 业务规模 | CPU配置 | 内存配置 | 磁盘配置 | 网络配置 |
|---|---|---|---|---|
| 小型 | 8核 | 16GB | 500GB SSD | 千兆网卡 |
| 中型 | 16核 | 32GB | 1TB SSD | 万兆网卡 |
| 大型 | 32核 | 64GB | 2TB SSD | 万兆网卡 |
| 超大型 | 64核 | 128GB | 4TB SSD | 25G网卡 |
🎯 总结与展望
技术架构总结
通过本文的深度解析,我们可以看到RocketMQ作为一款企业级的分布式消息中间件,在架构设计上体现了以下几个核心理念:
🎨 设计哲学
- 简单性:NameServer的无状态设计,避免了复杂的一致性协议
- 可靠性:主从复制 + 事务消息,保证了数据的强一致性
- 高性能:顺序写 + 零拷贝 + 异步处理,实现了极致的性能优化
- 可扩展:水平分片 + 动态扩容,支持海量消息处理
📊 技术特色对比
| 特性维度 | RocketMQ | Kafka | RabbitMQ |
|---|---|---|---|
| 性能 | 🔥 极高 | 🔥 极高 | ⚡ 中等 |
| 可靠性 | 🛡️ 很强 | ⚖️ 中等 | 🛡️ 很强 |
| 功能丰富度 | 🌟 丰富 | 🔧 基础 | 🌟 丰富 |
| 运维复杂度 | 📚 中等 | 📖 简单 | 📚 中等 |
| 生态成熟度 | 🌱 发展中 | 🌳 成熟 | 🌳 成熟 |
未来发展趋势
🔮 技术演进方向
- 云原生化:更好的Kubernetes集成,支持Operator模式部署
- 多协议融合:gRPC协议的进一步优化,支持更多标准协议
- 智能化运维:基于AI的性能调优和故障预测
- 边缘计算:轻量化版本,支持边缘场景部署
- Serverless集成:与函数计算平台的深度整合
🚀 应用场景拓展
- 实时数据流处理:与流计算引擎深度集成
- IoT消息处理:支持海量设备的消息接入
- 跨云消息同步:多云环境下的消息一致性
- 区块链集成:支持区块链场景的消息可信传输
最佳实践建议
作为一名从业多年的架构师,我给大家几点实战建议:
💡 选型决策
- 业务场景分析:根据消息量、可靠性要求、实时性需求选择合适的MQ
- 团队技术栈:考虑团队的技术储备和运维能力
- 生态兼容性:评估与现有技术栈的集成难度
- 成本考量:综合考虑硬件、人力、维护成本
🔧 实施策略
- 渐进式迁移:从非核心业务开始,逐步扩展应用范围
- 监控先行:建立完善的监控体系,及时发现问题
- 容量规划:根据业务增长预期,合理规划集群规模
- 灾备方案:制定完善的容灾和数据恢复策略
📚 参考资料与延伸阅读
- Apache RocketMQ官方文档
- RocketMQ源码解析系列
- 分布式系统架构设计实践
- 高性能消息队列设计原理
关于作者
默语佬,资深分布式系统架构师,专注于高并发、高可用系统设计,CSDN博客专家。在大型互联网公司有多年的分布式系统架构经验,对消息中间件、缓存系统、存储引擎等技术有深入研究。
如果这篇文章对你有帮助,请点赞👍、收藏⭐、关注🔔,你的支持是我持续创作的动力!
本文为原创技术文章,转载请注明出处。如有技术问题欢迎在评论区讨论交流。