【Doris入门】Doris数据表模型:主键模型(Unique Key Model)详解
目录
前言
1 主键模型概述
1.1 什么是主键模型
1.2 主键模型的核心特性
1.3 主键模型与其他数据模型的对比
2 主键模型的实现方式
2.1 写时合并(Merge-on-Write)
2.1.1 实现原理
2.1.2 建表示例
2.1.3 性能特点
2.2 读时合并(Merge-on-Read)
2.2.1 实现原理
2.2.2 建表示例
2.2.3 性能特点
2.3 两种实现方式的对比
3 主键模型的数据更新机制
3.1 更新语义
3.1.1 整行更新(UPSERT)
3.1.2 部分列更新
3.2 底层实现机制
3.2.1 写时合并的底层架构
3.2.2 读时合并的底层架构
4 主键模型的使用场景
4.1 典型应用场景
4.1.1 高频数据更新场景
4.1.2 数据高效去重场景
4.1.3 部分列更新场景
4.2 场景选择建议
4.2.1 选择主键模型的情况
4.2.2 不适合主键模型的情况
5 主键模型的性能优化
5.1 写入性能优化
5.1.1 批量写入优化
5.1.2 合理设置BUCKET数量
5.1.3 使用合适的分区策略
5.2 查询性能优化
5.2.1 合理设计Key列
5.2.2 使用适当的索引
5.2.3 优化查询语句
5.3 存储优化
5.3.1 合理设置数据压缩
5.3.2 定期执行Compaction
6 主键模型的实践
6.1 建表实践
6.1.1 表结构设计原则
6.1.2 建表示例
6.2 数据导入实践
6.3 查询优化实践
6.3.1 查询语句优化
6.3.2 聚合查询优化
7 主键模型的监控与维护
7.1 性能监控指标
7.1.1 关键监控指标
7.1.2 监控查询示例
7.2 日常维护操作
7.2.1 数据清理
7.2.2 统计信息收集
7.2.3 表维护
8 总结
前言
在当今大数据时代,实时数据分析和数据更新能力成为现代数据仓库系统的核心需求。Apache Doris作为一款高性能的分布式分析型数据库,提供了多种数据模型来满足不同的业务场景需求。其中,主键模型(Unique Key Model)是Doris中专门为支持数据实时更新而设计的重要数据模型。
1 主键模型概述
1.1 什么是主键模型
- 主键模型(Unique Key Model)是Apache Doris中的一种数据模型,其主要特点是保证Key列的唯一性
- 当插入或更新数据时,如果新数据的Key值与表中已存在的Key值相同,新数据会覆盖具有相同Key的旧数据,确保数据记录始终是最新的
- 简单来说,主键模型实现了类似传统数据库中的主键约束,保证了数据的唯一性和最新性
1.2 主键模型的核心特性
主键模型具有以下几个核心特性:
- 基于主键进行UPSERT:在插入数据时,主键重复的数据会更新,主键不存在的记录会插入
- 基于主键进行去重:主键模型中的Key列具有唯一性,会对根据主键列对数据进行去重操作
- 高频数据更新支持:支持高频数据更新场景,同时平衡数据更新性能与查询性能
- 两种更新语义:支持整行更新和部分列更新两种不同的更新方式
1.3 主键模型与其他数据模型的对比
Doris提供了三种主要的数据模型:明细模型(Duplicate Key Model)、聚合模型(Aggregate Key Model)和主键模型(Unique Key Model)。它们的区别如下:
| 数据模型 | 特点 | 适用场景 | 更新方式 |
| 明细模型 | 保留所有导入数据,包括重复数据 | 需要存储完整原始数据的场景 | 直接追加 |
| 聚合模型 | 按Key列聚合,Value列按指定函数聚合 | 需要预聚合统计的场景 | 聚合更新 |
| 主键模型 | 按Key列去重,保留最新数据 | 需要数据更新的场景 | 覆盖更新 |
2 主键模型的实现方式
Apache Doris的主键模型提供了两种实现方式,分别是写时合并(Merge-on-Write)和读时合并(Merge-on-Read)。这两种方式在性能特点、适用场景和实现机制上有显著差异。
2.1 写时合并(Merge-on-Write)
2.1.1 实现原理
写时合并的核心思想是在数据写入阶段就完成所有的数据去重工作。当数据写入时,系统会立即查找并标记相同Key的旧数据为删除状态,然后将新数据写入新的Rowset中。

- 新数据写入:客户端向Doris发起数据写入请求
- 查找相同Key的旧数据:系统根据Key值在Base数据中查找是否存在相同Key的记录
- 标记旧数据为删除:如果找到相同Key的记录,将该行数据在Delete Bitmap中标记为删除
- 写入新数据到新Rowset:将新数据写入新的Rowset文件中
- 完成事务,新数据可见:提交事务,使新数据对查询可见
2.1.2 建表示例
CREATE TABLE IF NOT EXISTS dwd_db.dwd_unique_tmp_0 (user_id LARGEINT NOT NULL COMMENT "用户id",username VARCHAR(50) NOT NULL COMMENT "用户昵称",city VARCHAR(20) COMMENT "用户所在城市",age SMALLINT COMMENT "用户年龄",sex TINYINT COMMENT "用户性别",phone LARGEINT COMMENT "用户电话",address VARCHAR(500) COMMENT "用户地址",register_time DATETIME COMMENT "用户注册时间",update_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT "数据更新时间"
)
UNIQUE KEY(user_id, username)
-- 使用更多分桶,并根据数据量调整
DISTRIBUTED BY HASH(user_id) BUCKETS 3
PROPERTIES ("replication_num" = "1", -- 生产环境建议3副本"storage_format" = "V2",-- 开启轻型Schema变更,方便后续添加列"light_schema_change" = "true","enable_unique_key_merge_on_write" = "true" -- 启用写时合并
);2.1.3 性能特点
优点:
- 查询性能优异,因为数据在写入时已经去重,查询时无需进行归并排序
- 支持高效的谓词下推和索引过滤
- 内存消耗相对较低
- 数据一致性更好
缺点:
- 写入性能相对较低,因为需要额外的查找和标记删除操作
- 存储空间开销相对较大
2.2 读时合并(Merge-on-Read)
2.2.1 实现原理
读时合并的核心思想是在数据写入时不进行去重操作,所有去重工作在查询或Compaction时进行。数据写入时以增量的方式被追加存储,在Doris内部保留多个版本。

- 新数据写入:客户端向Doris发起数据写入请求
- 直接追加到新Rowset:系统将新数据直接写入新的Rowset,不进行去重操作
- 保留多个版本数据:相同Key的不同版本数据都被保留
- 查询时进行版本合并:查询时系统对多个版本的数据进行归并排序和合并
- 返回最新版本数据:只返回每个Key的最新版本数据给用户
2.2.2 建表示例
CREATE TABLE IF NOT EXISTS dwd_db.dwd_unique_tmp_1(user_id LARGEINT NOT NULL COMMENT "用户id",username VARCHAR(50) NOT NULL COMMENT "用户昵称",city VARCHAR(20) COMMENT "用户所在城市",age SMALLINT COMMENT "用户年龄",sex TINYINT COMMENT "用户性别",phone LARGEINT COMMENT "用户电话",address VARCHAR(500) COMMENT "用户地址",register_time DATETIME COMMENT "用户注册时间"
)UNIQUE KEY(user_id, username)
DISTRIBUTED BY HASH(user_id) BUCKETS 3
PROPERTIES ("replication_num" = "1", -- 生产环境建议3副本"enable_unique_key_merge_on_write" = "false" --指定了Unique模型的工作模式为Merge-on-Read (MoR)
);2.2.3 性能特点
优点:
- 写入性能优异,因为不需要进行复杂的去重操作
- 适合写多读少的场景
缺点:
- 查询性能较差,需要实时进行归并排序和版本合并
- 内存消耗较高
- 无法进行有效的谓词下推
- 可能导致查询性能抖动
2.3 两种实现方式的对比
| 特性 | 写时合并 | 读时合并 |
| 默认版本 | 2.1+ | 1.2- |
| 写入性能 | 较低 | 较高 |
| 查询性能 | 较高 | 较低 |
| 内存消耗 | 较低 | 较高 |
| 谓词下推 | 支持 | 不支持 |
| 适用场景 | 读多写少 | 写多读少 |
| 数据一致性 | 好 | 一般 |
3 主键模型的数据更新机制
3.1 更新语义
主键模型支持两种更新语义:整行更新和部分列更新。
3.1.1 整行更新(UPSERT)
整行更新是主键模型的默认更新语义,即UPDATE OR INSERT。当插入数据时:
- 如果该行数据的Key已存在,则进行整行更新
- 如果该行数据的Key不存在,则进行新数据插入
-- 原始数据
INSERT INTO dwd_db.dwd_unique_tmp_0 (user_id, username, city, age, sex, phone, address, register_time)
VALUES (10007, 'chenjiu', '武汉', 29, 1, 13311223344, '武汉市江汉区解放大道128号', '2025-07-05 15:30:00');
INSERT INTO dwd_db.dwd_unique_tmp_0 (user_id, username, city, age, sex, phone, address, register_time)
VALUES (10008, 'zhou shi', '南京', 26, 2, 13255667788, '南京市玄武区中山陵路30号', '2025-07-12 09:15:00');
INSERT INTO dwd_db.dwd_unique_tmp_0 (user_id, username, city, age, sex, phone, address, register_time)
VALUES (10009, 'wuyi', '重庆', 33, 1, 13199887766, '重庆市渝中区解放碑88号', '2025-08-01 14:40:00');
INSERT INTO dwd_db.dwd_unique_tmp_0 (user_id, username, city, age, sex, phone, address, register_time)
VALUES (10010, 'zhengshi', '西安', 27, 2, 13044556677, '西安市雁塔区大雁塔南路15号', '2025-08-15 10:25:00');-- 更新数据(整行更新)
INSERT INTO dwd_db.dwd_unique_tmp_0 (user_id, username, city, age, sex, phone, address, register_time)
VALUES (10011, 'wangshiyi', '昆明', 28, 1, 18912345678, '昆明市盘龙区', '2025-08-03 08:50:00');-- 查询结果
select *from dwd_db.dwd_unique_tmp_0;- 执行结果:
mysql> select *from dwd_db.dwd_unique_tmp_0;
+---------+-----------+--------+------+------+-------------+----------------------------------------+---------------------+---------------------+
| user_id | username | city | age | sex | phone | address | register_time | update_time |
+---------+-----------+--------+------+------+-------------+----------------------------------------+---------------------+---------------------+
| 10008 | zhou shi | 南京 | 26 | 2 | 13255667788 | 南京市玄武区中山陵路30号 | 2025-07-12 09:15:00 | 2025-08-28 11:25:57 |
| 10009 | wuyi | 重庆 | 33 | 1 | 13199887766 | 重庆市渝中区解放碑88号 | 2025-08-01 14:40:00 | 2025-08-28 11:25:57 |
| 10010 | zhengshi | 西安 | 27 | 2 | 13044556677 | 西安市雁塔区大雁塔南路15号 | 2025-08-15 10:25:00 | 2025-08-28 11:25:58 |
| 10007 | chenjiu | 武汉 | 29 | 1 | 13311223344 | 武汉市江汉区解放大道128号 | 2025-07-05 15:30:00 | 2025-08-28 11:25:57 |
| 10011 | wangshiyi | 苏州 | 31 | 1 | 18912345678 | 苏州市姑苏区观前街50号 | 2025-09-03 08:50:00 | 2025-08-28 11:26:01 |
+---------+-----------+--------+------+------+-------------+----------------------------------------+---------------------+---------------------+
5 rows in set (0.10 sec)mysql> INSERT INTO dwd_db.dwd_unique_tmp_0 (user_id, username, city, age, sex, phone, address, register_time) -> VALUES (10011, 'wangshiyi', '昆明', 28, 1, 18912345678, '昆明市盘龙区', '2025-08-03 08:50:00');
Query OK, 1 row affected (0.13 sec)
{'label':'label_28f0bc47a1f74c94_a41a75a7b1ba6f95', 'status':'VISIBLE', 'txnId':'10'}mysql> select *from dwd_db.dwd_unique_tmp_0;
+---------+-----------+--------+------+------+-------------+----------------------------------------+---------------------+---------------------+
| user_id | username | city | age | sex | phone | address | register_time | update_time |
+---------+-----------+--------+------+------+-------------+----------------------------------------+---------------------+---------------------+
| 10009 | wuyi | 重庆 | 33 | 1 | 13199887766 | 重庆市渝中区解放碑88号 | 2025-08-01 14:40:00 | 2025-08-28 11:25:57 |
| 10010 | zhengshi | 西安 | 27 | 2 | 13044556677 | 西安市雁塔区大雁塔南路15号 | 2025-08-15 10:25:00 | 2025-08-28 11:25:58 |
| 10008 | zhou shi | 南京 | 26 | 2 | 13255667788 | 南京市玄武区中山陵路30号 | 2025-07-12 09:15:00 | 2025-08-28 11:25:57 |
| 10007 | chenjiu | 武汉 | 29 | 1 | 13311223344 | 武汉市江汉区解放大道128号 | 2025-07-05 15:30:00 | 2025-08-28 11:25:57 |
| 10011 | wangshiyi | 昆明 | 28 | 1 | 18912345678 | 昆明市盘龙区 | 2025-08-03 08:50:00 | 2025-08-28 11:29:45 |
+---------+-----------+--------+------+------+-------------+----------------------------------------+---------------------+---------------------+
5 rows in set (0.08 sec)mysql> 3.1.2 部分列更新
部分列更新允许用户只更新表中的部分列,而不是整行更新。这种功能需要使用写时合并实现,并通过特定的参数来开启。
-- 开启部分列更新
SET enable_unique_key_partial_update = true;-- 部分列更新
INSERT INTO dwd_db.dwd_unique_tmp_1(user_id, username, age)
VALUES(10011, 'wangshiyi', 30);-- 查询结果(只有age列被更新,其他列保持不变)
SELECT * FROM dwd_db.dwd_unique_tmp_0;- 执行结果
mysql> select *from dwd_db.dwd_unique_tmp_0 where user_id='10011';
+---------+-----------+--------+------+------+-------------+--------------------+---------------------+---------------------+
| user_id | username | city | age | sex | phone | address | register_time | update_time |
+---------+-----------+--------+------+------+-------------+--------------------+---------------------+---------------------+
| 10011 | wangshiyi | 昆明 | 28 | 1 | 18912345678 | 昆明市盘龙区 | 2025-08-03 08:50:00 | 2025-08-28 12:00:00 |
+---------+-----------+--------+------+------+-------------+--------------------+---------------------+---------------------+
1 row in set (0.05 sec)mysql> INSERT INTO dwd_db.dwd_unique_tmp_1(user_id, username, age) -> VALUES(10011, 'wangshiyi', 30);
Query OK, 1 row affected (0.07 sec)
{'label':'label_925987b8094547d8_870365be998bd40f', 'status':'VISIBLE', 'txnId':'31'}mysql> select *from dwd_db.dwd_unique_tmp_0 where user_id='10011';
+---------+-----------+--------+------+------+-------------+--------------------+---------------------+---------------------+
| user_id | username | city | age | sex | phone | address | register_time | update_time |
+---------+-----------+--------+------+------+-------------+--------------------+---------------------+---------------------+
| 10011 | wangshiyi | 昆明 | 28 | 1 | 18912345678 | 昆明市盘龙区 | 2025-08-03 08:50:00 | 2025-08-28 12:00:00 |
+---------+-----------+--------+------+------+-------------+--------------------+---------------------+---------------------+
1 row in set (0.05 sec)mysql> 3.2 底层实现机制
3.2.1 写时合并的底层架构
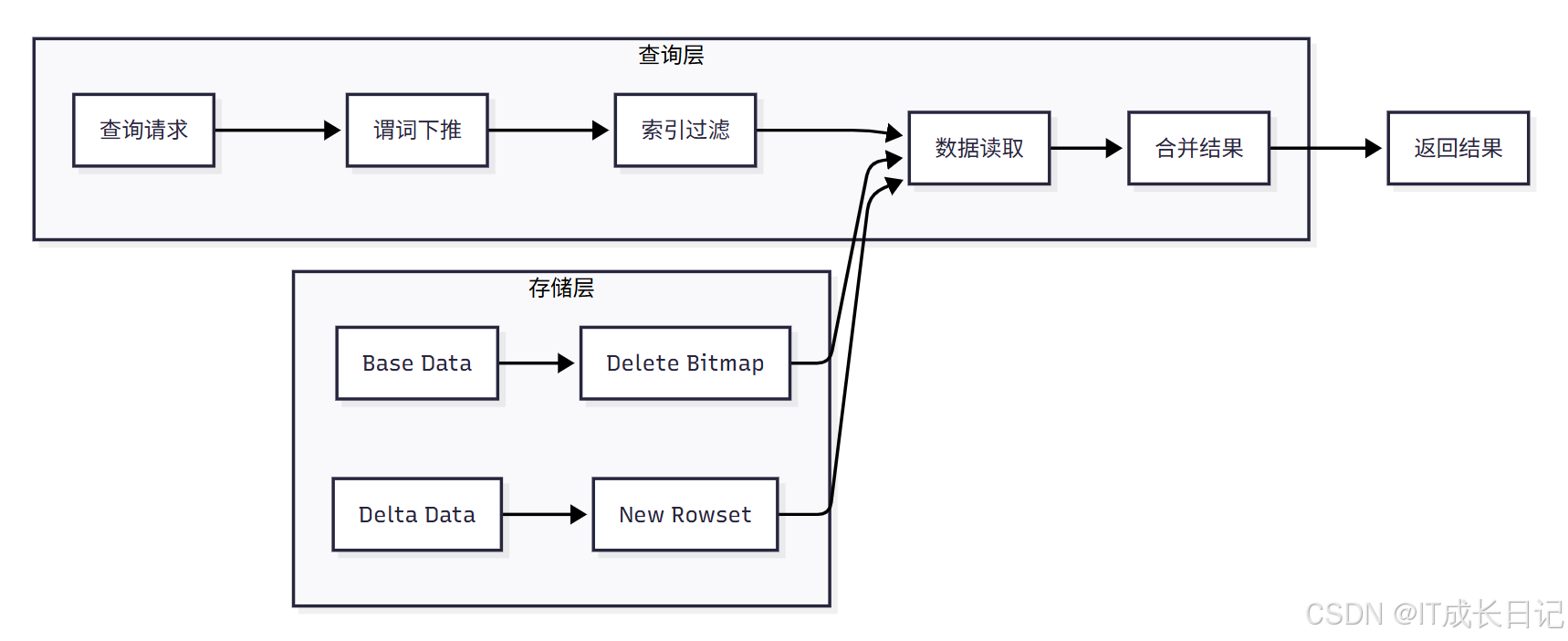
- 存储层:包含Base Data(基础数据)、Delete Bitmap(删除位图)、Delta Data(增量数据)和New Rowset(新行集)
- 查询层:处理查询请求,包括谓词下推、索引过滤、数据读取和结果合并
- 数据流向:查询时系统会读取Base Data和Delta Data,结合Delete Bitmap过滤掉已删除的数据,最终返回合并后的结果
3.2.2 读时合并的底层架构
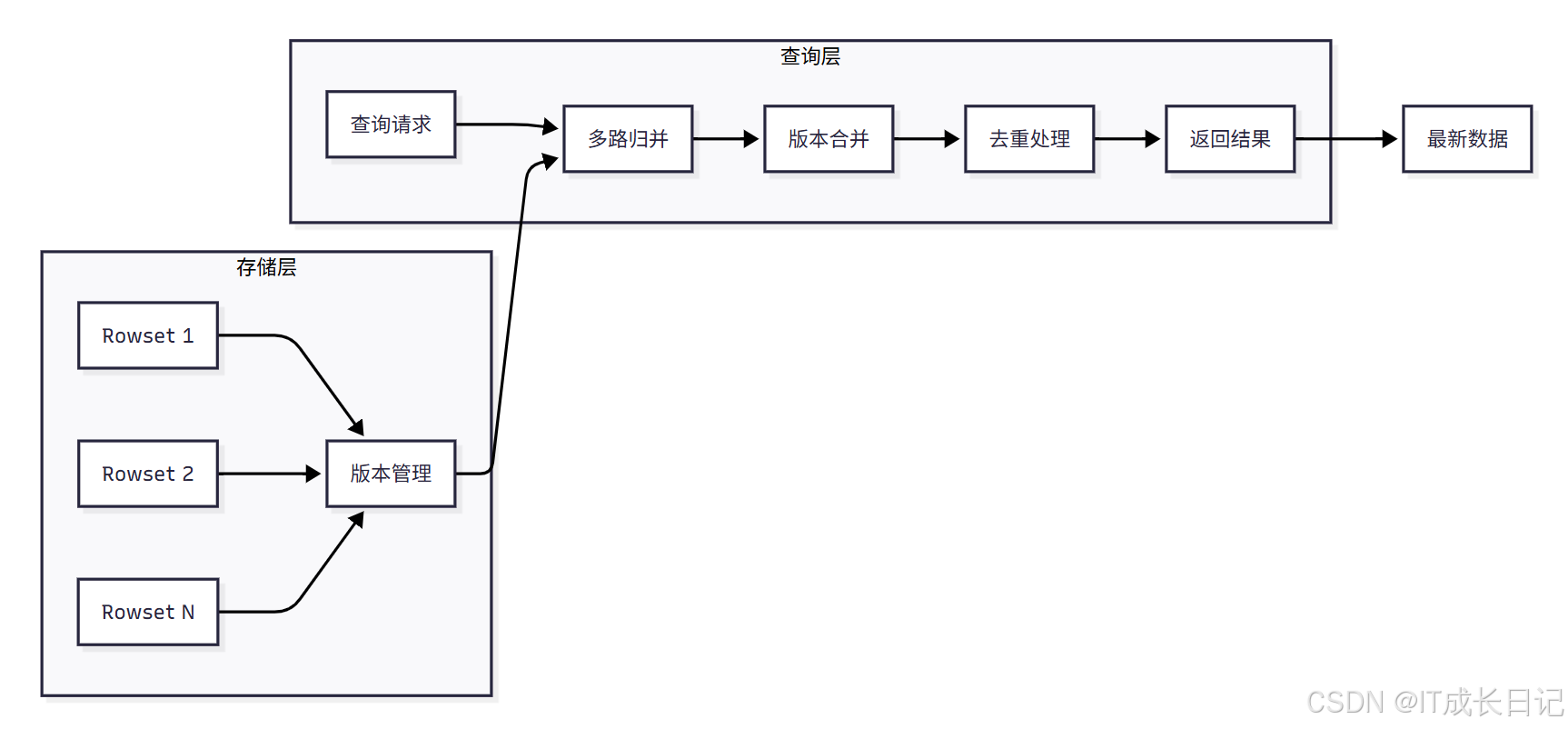
- 存储层:包含多个Rowset,每个Rowset保存数据的不同版本
- 查询层:处理查询请求,包括多路归并、版本合并、去重处理
- 数据流向:查询时系统需要读取所有Rowset,进行多路归并和版本合并,最终返回每个Key的最新版本
4 主键模型的使用场景
4.1 典型应用场景
4.1.1 高频数据更新场景
主键模型非常适合需要频繁更新数据的场景,如:
- OLTP数据库同步:通过CDC(Change Data Capture)从MySQL、PostgreSQL等OLTP数据库实时同步数据
- 电商交易订单:订单状态、支付信息等需要频繁更新的业务数据
- 用户画像系统:用户标签、偏好等需要动态更新的数据
- 广告投放系统:广告投放状态、效果数据等需要实时更新的场景
4.1.2 数据高效去重场景
在需要基于主键进行高效去重的场景中,主键模型表现出色:
- 用户行为分析:基于用户ID去重用户行为数据
- 设备日志处理:基于设备ID去重设备日志
- 客户关系管理:基于客户ID去重客户信息
4.1.3 部分列更新场景
在只需要更新部分字段的场景中,主键模型提供了灵活的解决方案:
- 订单状态更新:只需要更新订单状态,其他信息保持不变
- 用户标签更新:只需要更新用户标签,基本信息保持不变
- 商品价格更新:只需要更新商品价格,其他信息保持不变
4.2 场景选择建议
4.2.1 选择主键模型的情况
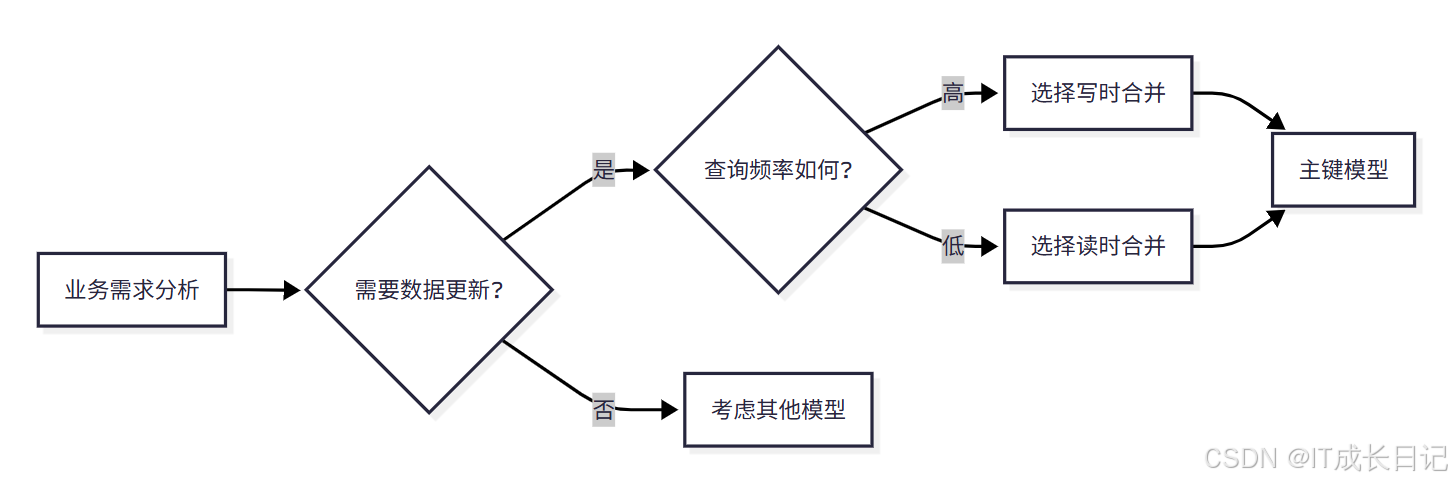
选择标准:
- 需要数据更新:业务场景中存在数据变更需求
- 查询频率高:查询操作频繁,对查询性能要求高
- 需要主键约束:业务逻辑要求保证主键唯一性
4.2.2 不适合主键模型的情况
以下场景不建议使用主键模型:
- 纯分析查询:只需要查询聚合结果,不需要更新数据
- 大量批量导入:数据导入后很少更新,适合使用明细模型
- 预聚合需求:需要预聚合统计,适合使用聚合模型
5 主键模型的性能优化
5.1 写入性能优化
5.1.1 批量写入优化
-- 推荐使用批量插入而不是单条插入
INSERT INTO dwd_db.dwd_unique_tmp_1 VALUES
(10010, 'zhengshi', '西安', 27, 2, 13044556677, '西安市雁塔区大雁塔南路15号', '2025-08-15 10:25:00'),
(10007, 'chenjiu', '武汉', 29, 1, 13311223344, '武汉市江汉区解放大道128号', '2025-07-05 15:30:00'),
(10008, 'zhou shi', '南京', 26, 2, 13255667788, '南京市玄武区中山陵路30号', '2025-07-12 09:15:00'),
(10009, 'wuyi', '重庆', 33, 1, 13199887766, '重庆市渝中区解放碑88号', '2025-08-01 14:40:00');5.1.2 合理设置BUCKET数量
-- 根据数据量和查询模式合理设置BUCKET数量
CREATE TABLE dwd_db.dwd_unique_tmp_1(-- 表结构定义
)UNIQUE KEY(user_id, username)
DISTRIBUTED BY HASH(user_id) BUCKETS 10 -- 根据数据量调整
PROPERTIES ("replication_allocation" = "tag.location.default: 3"
);5.1.3 使用合适的分区策略
-- 按时间分区,提高查询性能
CREATE TABLE dwd_db.dwd_unique_tmp_1(-- 表结构定义create_time DATETIME COMMENT "创建时间"
)UNIQUE KEY(user_id, username)
PARTITION BY RANGE(create_time) (PARTITION p202501 VALUES LESS THAN ('2025-02-01'),PARTITION p202502 VALUES LESS THAN ('2025-03-01'),PARTITION p202503 VALUES LESS THAN ('2025-04-01')
)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;5.2 查询性能优化
5.2.1 合理设计Key列
-- Key列应该包含常用的查询条件和过滤条件
CREATE TABLE dwd_db.dwd_unique_tmp_1(user_id LARGEINT NOT NULL,username VARCHAR(50) NOT NULL,city VARCHAR(20),age SMALLINT,sex TINYINT,-- 其他列...
)UNIQUE KEY(user_id, city, age) -- 包含常用查询条件
DISTRIBUTED BY HASH(user_id) BUCKETS 10;5.2.2 使用适当的索引
-- 创建列式索引提高查询性能
ALTER TABLE dwd_db.dwd_unique_tmp_1 ADD INDEX idx_city (city) COMMENT "城市索引";
ALTER TABLE dwd_db.dwd_unique_tmp_1 ADD INDEX idx_age (age) COMMENT "年龄索引";5.2.3 优化查询语句
-- 使用具体的查询条件而不是全表扫描
SELECT * FROM dwd_db.dwd_unique_tmp_1 WHERE city = '昆明' AND age > 25;-- 避免使用SELECT *
SELECT user_id, username, city FROM dwd_db.dwd_unique_tmp_1 WHERE city = '昆明';5.3 存储优化
5.3.1 合理设置数据压缩
-- 使用合适的数据压缩算法
CREATE TABLE dwd_db.dwd_unique_tmp_1(-- 表结构定义
)UNIQUE KEY(user_id, username)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES ("replication_allocation" = "tag.location.default: 3","storage_medium" = "SSD","compression" = "zstd" -- 使用ZSTD压缩
);5.3.2 定期执行Compaction
- 查看Tablet版本数量
SHOW TABLETS FROM dwd_db.dwd_unique_tmp_1\G- 触发单个Tablet的Compaction
# 触发累计Compaction (Cumulative Compaction)
curl -X POST "http://BE_IP:WEBSERVER_PORT/api/compaction/run?tablet_id=10221&compact_type=cumulative"# 触发基准Compaction (Base Compaction)
curl -X POST "http://BE_IP:WEBSERVER_PORT/api/compaction/run?tablet_id=TABLET_ID&compact_type=base"# 触发全量Compaction (Full Compaction) - 适用于数据恢复等场景
curl -X POST "http://BE_IP:WEBSERVER_PORT/api/compaction/run?tablet_id=TABLET_ID&compact_type=full"- 触发整个表的Full Compaction
curl -X POST "http://BE_IP:WEBSERVER_PORT/api/compaction/run?table_id=TABLE_ID&compact_type=full"6 主键模型的实践
6.1 建表实践
6.1.1 表结构设计原则
- 合理选择Key列:Key列应该包含业务主键和常用查询条件
- 适当冗余设计:对于高频查询的列,可以考虑适当冗余
- 数据类型选择:选择合适的数据类型,避免过度使用大类型
- 分区策略:根据查询模式选择合适的分区策略
6.1.2 建表示例
-- 推荐的主键模型建表示例
CREATE TABLE IF NOT EXISTS dwd_db.dwd_user_profile_unique(user_id BIGINT NOT NULL COMMENT "用户ID",username VARCHAR(100) NOT NULL COMMENT "用户名",create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT "创建时间", -- 移到前面phone VARCHAR(20) COMMENT "手机号",email VARCHAR(100) COMMENT "邮箱",city VARCHAR(50) COMMENT "城市",age INT COMMENT "年龄",gender TINYINT COMMENT "性别",register_time DATETIME COMMENT "注册时间",last_login_time DATETIME COMMENT "最后登录时间",user_level TINYINT COMMENT "用户等级",is_active TINYINT COMMENT "是否活跃",update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT "更新时间"
)
UNIQUE KEY(user_id, username, create_time) -- 现在都是前缀列
PARTITION BY RANGE(create_time) (PARTITION p202501 VALUES LESS THAN ('2025-02-01'),PARTITION p202502 VALUES LESS THAN ('2025-03-01'),PARTITION p202503 VALUES LESS THAN ('2025-04-01'),PARTITION p202504 VALUES LESS THAN ('2025-05-01')
)
DISTRIBUTED BY HASH(user_id) BUCKETS 3
PROPERTIES ("replication_allocation" = "tag.location.default: 1","storage_medium" = "HDD","compression" = "zstd","enable_unique_key_merge_on_write" = "true"
);6.2 数据导入实践
-- 使用LOAD DATA批量导入
LOAD DATA LOCAL INFILE '/data/tmp/user_data.csv'
INTO TABLE dwd_db.dwd_user_profile_unique
COLUMNS TERMINATED BY ','
LINES TERMINATED BY '\n'
(user_id,username,create_time,phone,email,city,age,gender,register_time,last_login_time,user_level,is_active
);- 导入结果查看
mysql> select * from dwd_db.dwd_user_profile_unique;
+---------+----------+---------------------+-------------+--------------------+--------+------+--------+---------------------+---------------------+------------+-----------+---------------------+
| user_id | username | create_time | phone | email | city | age | gender | register_time | last_login_time | user_level | is_active | update_time |
+---------+----------+---------------------+-------------+--------------------+--------+------+--------+---------------------+---------------------+------------+-----------+---------------------+
| 2 | 李四 | 2025-01-20 14:25:00 | 13900139000 | lisi@email.com | 上海 | 32 | 1 | 2025-01-20 14:25:00 | 2025-01-25 09:15:00 | 1 | 1 | 2025-08-28 16:44:42 |
| 7 | 吴九 | 2025-04-03 08:50:00 | 13300133000 | wujiu@email.com | 成都 | 27 | 2 | 2025-04-03 08:50:00 | 2025-04-08 17:15:00 | 3 | 1 | 2025-08-28 16:44:42 |
| 8 | 郑十 | 2025-04-15 15:40:00 | 13200132000 | zhengshi@email.com | 武汉 | 33 | 1 | 2025-04-15 15:40:00 | 2025-04-20 13:45:00 | 2 | 0 | 2025-08-28 16:44:42 |
| 3 | 王五 | 2025-02-05 09:10:00 | 13700137000 | wangwu@email.com | 广州 | 25 | 2 | 2025-02-05 09:10:00 | 2025-02-10 16:40:00 | 3 | 1 | 2025-08-28 16:44:42 |
| 5 | 孙七 | 2025-03-10 11:20:00 | 13500135000 | sunqi@email.com | 杭州 | 29 | 2 | 2025-03-10 11:20:00 | 2025-03-15 14:50:00 | 1 | 1 | 2025-08-28 16:44:42 |
| 6 | 周八 | 2025-03-25 13:35:00 | 13400134000 | zhouba@email.com | 南京 | 31 | 1 | 2025-03-25 13:35:00 | 2025-03-30 10:25:00 | 2 | 1 | 2025-08-28 16:44:42 |
| 1 | 张三 | 2025-01-15 10:30:00 | 13800138000 | zhangsan@email.com | 北京 | 28 | 1 | 2025-01-15 10:30:00 | 2025-01-20 15:20:00 | 2 | 1 | 2025-08-28 16:44:42 |
| 4 | 赵六 | 2025-02-18 16:45:00 | 13600136000 | zhaoliu@email.com | 深圳 | 35 | 1 | 2025-02-18 16:45:00 | 2025-02-22 11:30:00 | 2 | 0 | 2025-08-28 16:44:42 |
+---------+----------+---------------------+-------------+--------------------+--------+------+--------+---------------------+---------------------+------------+-----------+---------------------+
8 rows in set (0.07 sec)mysql> 6.3 查询优化实践
6.3.1 查询语句优化
-- 推荐的查询方式
SELECT
user_id,
username,
city,
age
FROM dwd_db.dwd_user_profile_unique
WHERE city IN ('北京', '上海', '广州') AND age BETWEEN 20 AND 30AND is_active = 1
ORDER BY last_login_time DESC;-- 避免的查询方式
SELECT * FROM dwd_db.dwd_user_profile_unique ; -- 避免使用SELECT *6.3.2 聚合查询优化
-- 推荐的聚合查询
SELECT
city,
gender,
COUNT(*) as user_count,
AVG(age) as avg_age
FROM dwd_db.dwd_user_profile_unique
WHERE create_time >= '2025-01-01' AND create_time < '2025-02-01'
GROUP BY city, gender
ORDER BY user_count DESC;7 主键模型的监控与维护
7.1 性能监控指标
7.1.1 关键监控指标

7.1.2 监控查询示例
-- 查看表的基本信息
SHOW TABLE STATUS FROM dwd_db LIKE 'dwd_user_profile_unique'\G-- 查看表的分区信息
SHOW PARTITIONS FROM dwd_user_profile_unique\G-- 查看表的列信息
DESC dwd_db.dwd_user_profile_unique;-- 查看表数据量和大小
SHOW DATA FROM dwd_db.dwd_user_profile_unique;7.2 日常维护操作
7.2.1 数据清理
-- 清理过期数据
DELETE FROM dwd_db.dwd_user_profile_unique
WHERE create_time < '2025-01-01';-- 或者使用分区清理
ALTER TABLE dwd_db.dwd_user_profile_unique DROP PARTITION p202501;7.2.2 统计信息收集
-- 为整个表收集统计信息
ANALYZE TABLE dwd_db.dwd_user_profile_unique;-- 查看所有分析任务
SHOW ANALYZE;-- 删除表的统计信息
DROP STATS dwd_db.dwd_user_profile_unique;7.2.3 表维护
-- 1. 检查副本状态
ADMIN SHOW REPLICA STATUS FROM dwd_db.dwd_user_profile_unique;-- 2. 修复不一致的副本
ADMIN REPAIR TABLE dwd_db.dwd_user_profile_unique;-- 3. 验证修复结果
ADMIN CHECK REPLICA CONSISTENCY FROM dwd_db.dwd_user_profile_unique;-- 查看数据倾斜情况
SHOW DATA FROM dwd_db.dwd_user_profile_unique;-- 查看每个tablet的大小和行数
SHOW TABLET FROM dwd_db.dwd_user_profile_unique;8 总结
Apache Doris的主键模型作为实时数据分析的重要工具,为用户提供了强大的数据更新和查询能力。通过本文的详细介绍,相信读者已经对主键模型有了全面的理解和掌握。在实际应用中,我们需要根据具体的业务需求和数据特点,选择合适的实现方式和优化策略,充分发挥主键模型的优势。同时,也要关注系统的性能监控和日常维护,确保系统的稳定运行。