MiniCPM-V 4.5实战,实现图片、视频、多图的推理
MiniCPM-V 4.5
MiniCPM-V 4.5 是 MiniCPM-V 系列中最新且功能最强大的模型。该模型基于 Qwen3-8B 和 SigLIP2-400M 构建,总参数量为 80 亿。与之前的 MiniCPM-V 和 MiniCPM-o 模型相比,它在性能上有了显著提升,并引入了新的实用功能。MiniCPM-V 4.5 的主要特点包括:
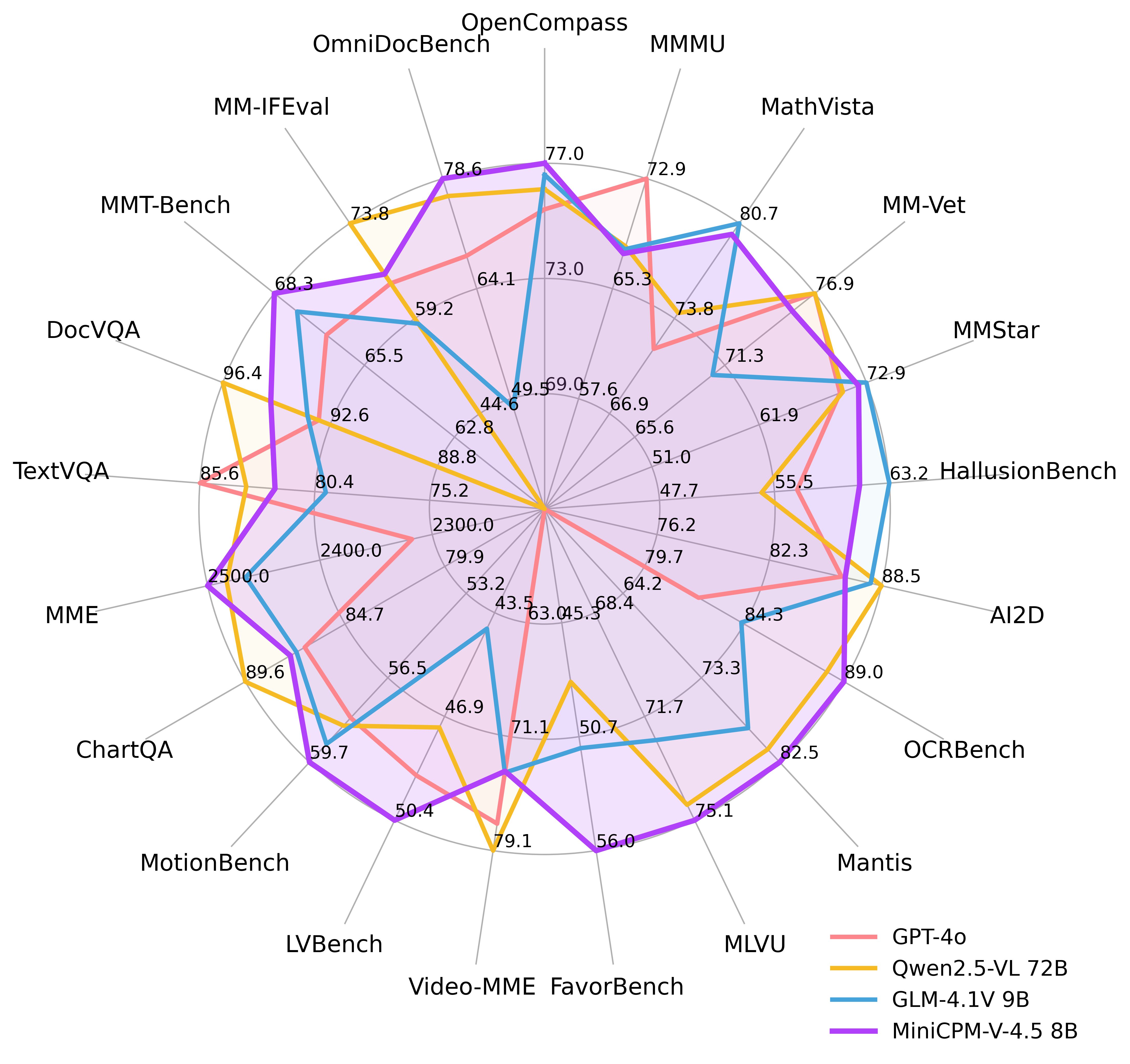
🔥 最先进的视觉-语言能力。 MiniCPM-V 4.5 在 OpenCompass 上的平均得分为 77.0,这是一个涵盖 8 个流行基准的综合评估。凭借仅 80 亿参数,它超越了广泛使用的专有模型如 GPT-4o-latest、Gemini-2.0 Pro 以及强大的开源模型如 Qwen2.5-VL 72B 的视觉-语言能力,使其成为 300 亿参数以下性能最佳的 MLLM。
🎬 高效的高帧率和长视频理解。 通过一种新的统一 3D-Resampler 对图像和视频进行处理,MiniCPM-V 4.5 可以实现 96 倍的视频令牌压缩率,其中 6 帧 448x448 视频可以被联合压缩成 64 个视频令牌(通常大多数 MLLMs 需要 1,536 个令牌)。这意味着模型可以在不增加 LLM 推理成本的情况下感知更多的视频帧。这带来了 Video-MME、LVBench、MLVU、MotionBench、FavorBench 等上的领先高帧率(高达 10FPS)视频理解和长视频理解能力。
⚙️ 可控的混合快速/深度思考。 MiniCPM-V 4.5 同时支持快速思考以高效频繁使用并保持竞争力,以及用于解决更复杂问题的深度思考。为了覆盖不同用户场景中的效率与性能权衡,这种快速/深度思考模式可以高度受控地切换。
💪 强大的 OCR、文档解析等功能。 基于 LLaVA-UHD 架构,MiniCPM-V 4.5 可以处理任何纵横比的高分辨率图像,最高可达 180 万像素(例如 1344x1344),并且使用的视觉令牌数量比大多数 MLLMs 少 4 倍。该模型在 OCRBench 上实现了领先表现,超越了 GPT-4o-latest 和 Gemini 2.5 等专有模型。它还在 OmniDocBench 上对通用 MLLMs 的 PDF 文档解析能力方面达到了最先进水平。基于最新的 RLAIF-V 和 VisCPM 技术,它具有可信行为,在 MMHal-Bench 上超越了 GPT-4o-latest,并支持超过 30 种语言的多语言能力。
💫 易于使用。 MiniCPM-V 4.5 可以通过多种方式轻松使用:(1) llama.cpp 和 ollama 支持在本地设备上进行高效的 CPU 推理,(2) 提供 16 种大小的 int4, GGUF 和 AWQ 格式的量化模型,(3) SGLang 和 vLLM 支持高吞吐量和内存高效的推理,(4) 使用 Transformers 和 LLaMA-Factory 对新领域和任务进行微调,(5) 快速 本地 WebUI 演示,(6) 优化后的 本地 iOS 应用 在 iPhone 和 iPad 上可用,(7) 在 服务器 上提供在线网页演示。请参阅我们的 Cookbook 获取完整使用方法!
安装环境
我本地用的cuda是12.6版本,新建虚拟环境,安装pytorch、transformers 等,执行命令如下:
conda create --name minicpm python=3.12 conda activate minicpm pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu126 pip install transformers pip install modelscope pip install decord
推理
推理图片
import torch
from PIL import Image
from modelscope import AutoModel, AutoTokenizertorch.manual_seed(100)model = AutoModel.from_pretrained('OpenBMB/MiniCPM-V-4_5', trust_remote_code=True, # or openbmb/MiniCPM-o-2_6attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('OpenBMB/MiniCPM-V-4_5', trust_remote_code=True) # or openbmb/MiniCPM-o-2_6image = Image.open('./assets/minicpmo2_6/show_demo.jpg').convert('RGB')enable_thinking=False # If `enable_thinking=True`, the thinking mode is enabled.
stream=True # If `stream=True`, the answer is string# First round chat
question = "What is the landform in the picture?"
msgs = [{'role': 'user', 'content': [image, question]}]answer = model.chat(msgs=msgs,tokenizer=tokenizer,enable_thinking=enable_thinking,stream=True
)generated_text = ""
for new_text in answer:generated_text += new_textprint(new_text, flush=True, end='')# Second round chat, pass history context of multi-turn conversation
msgs.append({"role": "assistant", "content": [answer]})
msgs.append({"role": "user", "content": ["What should I pay attention to when traveling here?"]})answer = model.chat(msgs=msgs,tokenizer=tokenizer,stream=True
)generated_text = ""
for new_text in answer:generated_text += new_textprint(new_text, flush=True, end='')
输出结果:
# round1
The landform in the picture is karst topography. Karst landscapes are characterized by distinctive, jagged limestone hills or mountains with steep, irregular peaks and deep valleys—exactly what you see here These unique formations result from the dissolution of soluble rocks like limestone over millions of years through water erosion.This scene closely resembles the famous karst landscape of Guilin and Yangshuo in China’s Guangxi Province. The area features dramatic, pointed limestone peaks rising dramatically above serene rivers and lush green forests, creating a breathtaking and iconic natural beauty that attracts millions of visitors each year for its picturesque views.# round2
When traveling to a karst landscape like this, here are some important tips:1. Wear comfortable shoes: The terrain can be uneven and hilly.
2. Bring water and snacks for energy during hikes or boat rides.
3. Protect yourself from the sun with sunscreen, hats, and sunglasses—especially since you’ll likely spend time outdoors exploring scenic spots.
4. Respect local customs and nature regulations by not littering or disturbing wildlife.By following these guidelines, you'll have a safe and enjoyable trip while appreciating the stunning natural beauty of places such as Guilin’s karst mountains.
推理视频
## The 3d-resampler compresses multiple frames into 64 tokens by introducing temporal_ids.
# To achieve this, you need to organize your video data into two corresponding sequences:
# frames: List[Image]
# temporal_ids: List[List[Int]].import torch
from PIL import Image
from modelscope import AutoModel, AutoTokenizer
from decord import VideoReader, cpu # pip install decord
from scipy.spatial import cKDTree
import numpy as np
import mathmodel = AutoModel.from_pretrained('OpenBMB/MiniCPM-V-4_5', trust_remote_code=True, # or openbmb/MiniCPM-o-2_6attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('OpenBMB/MiniCPM-V-4_5', trust_remote_code=True) # or openbmb/MiniCPM-o-2_6MAX_NUM_FRAMES=180 # Indicates the maximum number of frames received after the videos are packed. The actual maximum number of valid frames is MAX_NUM_FRAMES * MAX_NUM_PACKING.
MAX_NUM_PACKING=3 # indicates the maximum packing number of video frames. valid range: 1-6
TIME_SCALE = 0.1 def map_to_nearest_scale(values, scale):tree = cKDTree(np.asarray(scale)[:, None])_, indices = tree.query(np.asarray(values)[:, None])return np.asarray(scale)[indices]def group_array(arr, size):return [arr[i:i+size] for i in range(0, len(arr), size)]def encode_video(video_path, choose_fps=3, force_packing=None):def uniform_sample(l, n):gap = len(l) / nidxs = [int(i * gap + gap / 2) for i in range(n)]return [l[i] for i in idxs]vr = VideoReader(video_path, ctx=cpu(0))fps = vr.get_avg_fps()video_duration = len(vr) / fpsif choose_fps * int(video_duration) <= MAX_NUM_FRAMES:packing_nums = 1choose_frames = round(min(choose_fps, round(fps)) * min(MAX_NUM_FRAMES, video_duration))else:packing_nums = math.ceil(video_duration * choose_fps / MAX_NUM_FRAMES)if packing_nums <= MAX_NUM_PACKING:choose_frames = round(video_duration * choose_fps)else:choose_frames = round(MAX_NUM_FRAMES * MAX_NUM_PACKING)packing_nums = MAX_NUM_PACKINGframe_idx = [i for i in range(0, len(vr))] frame_idx = np.array(uniform_sample(frame_idx, choose_frames))if force_packing:packing_nums = min(force_packing, MAX_NUM_PACKING)print(video_path, ' duration:', video_duration)print(f'get video frames={len(frame_idx)}, packing_nums={packing_nums}')frames = vr.get_batch(frame_idx).asnumpy()frame_idx_ts = frame_idx / fpsscale = np.arange(0, video_duration, TIME_SCALE)frame_ts_id = map_to_nearest_scale(frame_idx_ts, scale) / TIME_SCALEframe_ts_id = frame_ts_id.astype(np.int32)assert len(frames) == len(frame_ts_id)frames = [Image.fromarray(v.astype('uint8')).convert('RGB') for v in frames]frame_ts_id_group = group_array(frame_ts_id, packing_nums)return frames, frame_ts_id_groupvideo_path="video_test.mp4"
fps = 5 # fps for video
force_packing = None # You can set force_packing to ensure that 3D packing is forcibly enabled; otherwise, encode_video will dynamically set the packing quantity based on the duration.
frames, frame_ts_id_group = encode_video(video_path, fps, force_packing=force_packing)question = "Describe the video"
msgs = [{'role': 'user', 'content': frames + [question]},
]answer = model.chat(msgs=msgs,tokenizer=tokenizer,use_image_id=False,max_slice_nums=1,temporal_ids=frame_ts_id_group
)
print(answer)
多图推理
import torch
from PIL import Image
from modelscope import AutoModel, AutoTokenizermodel = AutoModel.from_pretrained('OpenBMB/MiniCPM-V-4_5', trust_remote_code=True,attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('OpenBMB/MiniCPM-V-4_5', trust_remote_code=True)image1 = Image.open('image1.jpg').convert('RGB')
image2 = Image.open('image2.jpg').convert('RGB')
question = 'Compare image 1 and image 2, tell me about the differences between image 1 and image 2.'msgs = [{'role': 'user', 'content': [image1, image2, question]}]answer = model.chat(msgs=msgs,tokenizer=tokenizer
)
print(answer)
少样本学习
import torch
from PIL import Image
from modelscope import AutoModel, AutoTokenizermodel = AutoModel.from_pretrained('OpenBMB/MiniCPM-V-4_5', trust_remote_code=True,attn_implementation='sdpa', torch_dtype=torch.bfloat16)
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('OpenBMB/MiniCPM-V-4_5', trust_remote_code=True)question = "production date"
image1 = Image.open('example1.jpg').convert('RGB')
answer1 = "2023.08.04"
image2 = Image.open('example2.jpg').convert('RGB')
answer2 = "2007.04.24"
image_test = Image.open('test.jpg').convert('RGB')msgs = [{'role': 'user', 'content': [image1, question]}, {'role': 'assistant', 'content': [answer1]},{'role': 'user', 'content': [image2, question]}, {'role': 'assistant', 'content': [answer2]},{'role': 'user', 'content': [image_test, question]}
]answer = model.chat(msgs=msgs,tokenizer=tokenizer
)
print(answer)