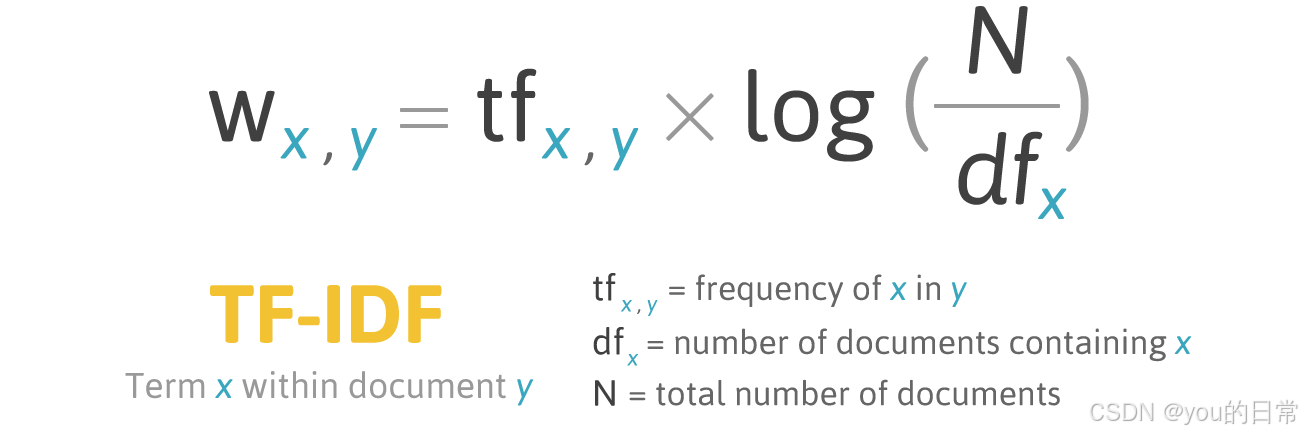自然语言处理 (NLP) 技术发展:从规则到大型语言模型的演进之路
自然语言处理 (NLP) 技术发展:从规则到大型语言模型的演进之路
自然语言处理(NLP)是人工智能领域中一个极具挑战性和活力的分支,其目标是赋予计算机理解、解释和处理人类语言的能力。从早期的基于规则的系统到当前由大型语言模型(LLM)引领的时代,NLP 技术经历了深刻的演变,并在机器翻译、情感分析、智能问答、文本生成等领域取得了令人瞩目的成就。
本文将回顾 NLP 技术发展的关键阶段,探讨其核心技术的演进,并展望未来的发展方向。
1. 早期阶段:基于规则和统计方法
在计算机科学的早期,NLP 研究主要依赖于语言学家构建的手工规则。通过定义大量的语法规则、词典和模板,尝试让计算机解析句子的结构和意义。这种方法的优点是可解释性强,但在面对语言的复杂性、不规则性以及不断变化的表达方式时显得力不从心,系统鲁棒性差,难以扩展到新的领域和语言。
随着可用的文本语料库的增长,研究者开始转向统计方法。这些方法通过对大量文本数据进行统计分析,计算词语、短语或句子出现的频率和概率,从而进行语言建模和任务处理。
代表性技术:
- N-gram 模型: 基于马尔可夫假设,通过统计词序列出现的频率来预测下一个词。
- 隐马尔可夫模型 (HMM): 常用于序列标注任务,如词性标注 (Part-of-Speech Tagging) 和命名实体识别 (Named Entity Recognition, NER)。
统计方法相对于规则方法更具鲁棒性,但其依赖于精确的统计数据,面临特征稀疏性(尤其是在处理未见过的词或序列时)和难以捕获长距离依赖的问题。
2. 机器学习时代:特征工程与传统模型
进入机器学习时代后,NLP 任务被重新定义为使用机器学习模型来解决分类、回归或序列标注等问题。这个阶段的关键在于人工设计和提取有效的特征。开发者需要凭借对语言学和具体任务的理解,从原始文本中抽取出能够代表其含义和结构的数值化特征。
代表性特征: