DriveDreamer-2
paper原文
DriveDreamer-2: LLM-Enhanced World Models for Diverse Driving Video Generation
论文的总体目的
该论文旨在解决为自动驾驶系统训练生成真实且多样化驾驶视频这一难题。目前的方法往往依赖结构化数据或真实世界图像作为输入,这在交互性和多样性方面存在局限。DriveDreamer-2 提出了一个可根据用户友好型文本提示生成定制化驾驶视频的系统。这一系统能够创建罕见或长尾场景,而这些场景对于打造稳健的自动驾驶训练体系至关重要。
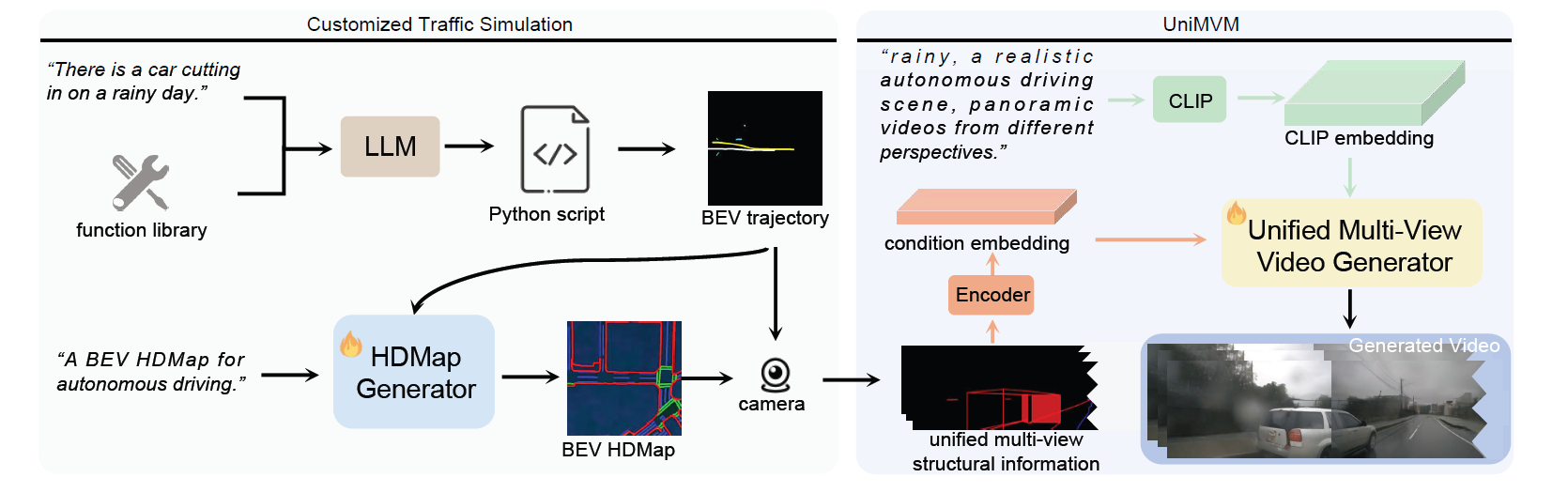
核心方法:三阶段流程
DriveDreamer-2 的核心在于一个三阶段流程:
- 定制化交通模拟:该阶段接收用户的文本提示,并将其转化为模拟驾驶场景。具体包括生成以下内容:
- 智能体轨迹(前景):主车(搭载摄像头的车辆)和其他智能体(其他车辆、行人)的行驶路径。
- 高清地图(背景):一种高清地图,用于呈现道路结构,包括车道边界、车道分隔线和人行横道。
- 统一多视图模型(UniMVM):该阶段接收模拟交通场景(智能体轨迹和高清地图),并生成多视图驾驶视频。此过程包括:
- 条件控制:将高清地图和智能体轨迹作为条件,整合到视频生成扩散模型中。
- 统一生成:统一多视图模型(UniMVM)确保生成的视频具备空间一致性(不同摄像头视图之间的一致性)和时间连贯性(随时间推移的平滑过渡)。
- 视频生成:利用结构化条件和摄像头 CLIP 嵌入技术,通过统一多视图模型(UniMVM)生成视频。
下面,我们将更深入地剖析每个阶段的技术细节。
第一阶段:定制化交通模拟(生成驾驶场景)
为轨迹生成微调大型语言模型(LLM)
-
目标:使大型语言模型(LLM)能够将用户友好型文本提示转化为真实的智能体轨迹。
-
方法:
- 构建函数库:该函数库包含 18 个函数,涵盖智能体函数(转向、匀速、加速和制动)、行人函数(行走方向和速度)以及其他实用函数(如轨迹保存函数)。
- 文本 - Python 脚本对:这些是人工创建的示例,将驾驶场景的文本描述与 Python 脚本配对。执行该 Python 脚本,即可生成相应的智能体轨迹。这些脚本会调用函数库中的函数。
- 大型语言模型(LLM)微调:在文本 - Python 脚本对上对大型语言模型(论文中使用的是 GPT-3.5)进行微调。通过这种方式,训练大型语言模型生成 Python 代码,使其能够根据文本提示实现所需的智能体行为。在推理阶段,我们按照文献 [37] 的方法,将提示输入扩展为预定义模板,经过微调的大型语言模型可直接输出轨迹数组。
-
示例:用户输入 “有车辆加塞”。经过微调后的大型语言模型可能会生成一段 Python 脚本,该脚本调用相关函数实现以下功能:
- 生成另一辆车辆切入主车车道的轨迹。
- 生成主车应对加塞行为的相应轨迹(如制动或变道)。
- 保存生成的轨迹。
高清地图(HDMap)生成
- 目标:生成与所生成的智能体轨迹一致的真实高清地图,确保道路布局和交通流在逻辑上相匹配。
- 方法:
- 条件图像生成:将高清地图的生成视为一个条件图像生成问题。这意味着模型会在给定条件的情况下生成高清地图图像。
- 轨迹图条件:该条件为 “轨迹图”,表示为 Tb ∈ R³×Hb×Wb。此轨迹图采用鸟瞰图(BEV)形式,对主车和其他智能体的位置及轨迹进行编码。通过不同颜色区分不同类型的智能体。
- 高清地图目标:目标是鸟瞰图(BEV)形式的高清地图,表示为 Hb ∈ R³×Hb×Wb。该地图的每个通道分别代表高清地图的不同元素,包括车道边界、车道分隔线和人行横道。
- 扩散模型:将扩散模型用作高清地图生成器的核心。高清地图生成器采用 2D 卷积层堆叠结构,以融入轨迹图条件。随后,利用文献 [68] 中的方法,将生成的特征图 CT 无缝整合到扩散模型中。使用轨迹 - 高清地图数据集 D = {Tb, Hb} 对扩散模型进行训练。
- 损失函数:训练高清地图生成器 ϕ,以最小化以下损失:
minϕ L = EZ₀,ε∼N (0,I),t,c [∥ε − εθ(Zt, t, c)∥₂²] (1)
其中,时间步长 t 从 [1, Tb] 中均匀采样。
- εθ:噪声预测模型
- Zt:潜在特征
- t:时间步长
第二阶段:统一多视图模型(UniMVM)
目标
生成具有空间一致性和时间连贯性的多视图驾驶视频,同时保证多样性和生成效率。以往的方法要么为了多样性牺牲了一致性,要么需要耗费大量资源的多步骤生成过程。
方法
- 问题构建:
统一多视图模型(UniMVM)并非独立(或按顺序)生成每个摄像头视图,而是将多视图视频视为单个统一图像块。按照 {前左(FL)、前(F)、前右(FR)、后右(BR)、后(B)、后左(BL)} 的顺序对多视图视频进行拼接,得到空间统一图像 x′ ∈ R^T׳×H×KW。
随后,将视频生成过程构建为:
p (x′) = p (x′・(1−m), x′・m) = p (x′・m) p (x′・(1−m)|x′・m)
其中,m 表示所有视图中的某个视图的掩码。
- x′・m:图像(视频帧)的可见部分。
- x′・(1−m):图像的隐藏(被掩码覆盖)部分。模型需要生成被掩码覆盖区域的内容。
-
该构建方式的优势:
- 空间一致性:将所有视图视为单个图像块的一部分,有助于模型生成相互一致的视图。
- 时间连贯性:视频生成过程在统一空间内进行,有助于实现帧间的平滑过渡。
- 灵活性:通过调整掩码 m,统一多视图模型(UniMVM)可处理多种任务:
- 未来视频预测(对未来帧进行掩码处理)。
- 多视图视频扩展生成(对特定视图进行掩码处理)。
- 从头生成完整多视图视频(对所有帧进行掩码处理)。
-
视频生成过程:
将统一多视图模型(UniMVM)整合到 DriveDreamer(基础模型)框架中。- 交通结构化条件:将高清地图和 3D 边界框(由智能体轨迹推导得出)视为 “结构化条件”。
- 统一条件:交通结构化条件会生成高清地图序列 {Hi}₀^(N−1) ∈ R^N׳×H×KW 和 3D 边界框序列 {Bi}₀^(N−1) ∈ R^N×C×H×KW。需要注意的是,3D 边界框序列可由智能体轨迹推导得出,且 3D 边界框的尺寸根据相应智能体类别确定。与 DriveDreamer 不同,DriveDreamer-2 中的 3D 边界框条件不再依赖位置嵌入和类别嵌入。相反,这些边界框直接投影到图像平面,起到控制条件的作用。
- 编码器:通过三个编码器,分别将高清地图、3D 边界框和初始图像帧(若提供)嵌入到潜在空间特征中。这些特征分别表示为 yH、yB 和 yI。随后,将空间对齐条件 yH、yB 与 Zt(通过前向扩散过程从 yI 生成的带噪声潜在特征)进行拼接,得到特征输入 Zin。
- 视频生成:利用视频扩散模型生成视频。通过去噪分数匹配优化所有参数。
第三阶段:视频生成
在视频生成器的训练过程中,通过去噪分数匹配 [27] 对所有参数进行优化。
这种方法避免了像文献 [59] 中那样引入额外的控制参数。
关键技术细节与创新点
- 文本到轨迹生成:利用经过微调的大型语言模型(LLM)直接从文本生成智能体轨迹,这是一种创新方法,简化了多样化驾驶场景的创建过程。
- 作为条件图像的高清地图:将高清地图生成视为条件图像生成问题,使模型能够学习智能体行为与道路布局之间的复杂关系。
- 统一多视图表示:统一多视图模型(UniMVM)是一项重要成果,解决了多视图视频生成中保持空间一致性和时间连贯性的难题。
- 端到端系统:DriveDreamer-2 将所有组件整合为一个完整的端到端系统,用于生成定制化驾驶视频。
实验与结果
该论文通过大量实验证明了 DriveDreamer-2 的有效性:
- 定性结果:表明 DriveDreamer-2 能够生成多样化的、用户定制化的驾驶视频,包括一些罕见场景。
- 定量结果:
- FID(弗雷歇 inception 距离)和 FVD(弗雷歇视频距离):DriveDreamer-2 在 FID 和 FVD 评分方面达到了最先进水平,体现出其卓越的视频生成质量。
- 下游任务性能:将 DriveDreamer-2 生成的视频用于 3D 目标检测和多目标跟踪的训练数据增强。这使得这些下游任务的性能得到显著提升,证明了 DriveDreamer-2 在自动驾驶系统训练中的价值。
- 消融研究:分析了 DriveDreamer-2 各个组件(如统一多视图模型 UniMVM)对整体性能的贡献。
总结
DriveDreamer-2 是自动驾驶模拟领域的一项重大进步。通过结合大型语言模型(LLM)、扩散模型的优势以及创新的统一多视图表示方法,DriveDreamer-2 能够生成高质量、多样化且用户定制化的驾驶视频,这些视频可用于提升自动驾驶系统的稳健性和安全性。其核心创新点在于……