科学研究系统性思维的方法体系:质量控制
8.1 导论:研究的可信度基石
8.1.1 质量控制:科学研究的“良心”与“免疫系统”
一项科学研究的最终价值,并非由其主题的新颖性、理论的宏大性,或是数据的复杂性单独决定,而是最终取决于一个更为根本的属性:其结果的可信度(Credibility)。如果一项研究的结论无法令人信服,那么无论其过程多么精巧,都无异于在沙上建塔,瞬间便会崩塌。质量控制(Quality Control, QC),正是确保这项可信度的核心机制,是贯穿于科学探索全程的“良心”与“免疫系统”。
它绝非研究设计、数据收集、分析和报告流程走完之后的一个附加检查或事后补救,而是一种内化于心的思维模式和一套渗透于研究全生命周期的系统性策略。它像一个严谨的监督者,时刻警惕着可能侵蚀研究结论真实性的各种威胁。其核心目标可以概括为两个方面:最小化偏差(Bias)和误差(Error)。通过系统性地识别、预防和控制这两大“敌人”,我们得以最大化研究结果的两个关键指标:有效性(Validity),即研究结果在多大程度上反映了真实世界;以及可靠性(Reliability),即研究结果在重复操作下的一致性和稳定性。
如果说本方法体系篇的前面几章,为我们提供了从提出问题到分析数据的“工具箱”和“路线图”,那么本章旨在构建一个 “元框架(Meta-Framework)”。这个框架并非教我们如何使用某个具体的统计方法或访谈技巧,而是监督和保障所有这些工具和流程都得到正确、严谨的执行。它要求我们从研究的“操作者”提升为研究的“架构师”和“审计师”,不断地以批判性的眼光审视自己的每一个决策。
我们将踏上一段通往严谨科学的深度旅程。我们将首先系统性地解剖研究质量的两大核心敌人——偏差与误差,深入探讨它们的定义、来源及其对研究效度和信度的不同影响。随后,我们将分门别类,详细阐述在定量研究和定性研究这两种不同范式下,如何部署一系列精密的质量控制策略。在定量研究中,我们将聚焦于随机化、盲法、标准化操作等“硬核”技术;而在定性研究中,我们将深入探讨三角验证、成员核查、反思性等确保“可信性”的精妙艺术。
进一步,我们将视野拓宽至整个科学共同体,探讨可重复性(Reproducibility)与可复制性(Replicability)这一现代科学自我修正机制的核心议题,并关联到影响深远的“开放科学”运动。最后,我们将审视作为学术界传统“守门人”的同行评审机制,分析其功能、挑战与未来发展。
最终,我们希望达成的目标是,让每一位研究者认识到,对严谨性的不懈追求,不仅是对单个研究项目最终成果的负责,更是对积累人类知识这一宏伟事业的敬畏,以及对整个科学共同体和公众信任的庄严承诺。一个缺乏严格质量控制的研究,其产出的可能不仅是无用的信息垃圾,更可能是误导公共政策、危害社会福祉的有害信息。因此,将质量控制的原则内化为一种思维习惯和行为准-则,是每一位研究者从“新手”走向“思想成熟的专家”的必经之路。
8.2 偏差与误差:质量控制的核心敌人
在追求科学真理的道路上,偏差(Bias)与误差(Error)是我们必须时刻警惕并与之斗争的核心敌人。它们如同潜伏在研究过程中的幽灵,不断试图扭曲我们的观察、污染我们的数据、误导我们的结论。虽然这两个术语在日常用语中有时被混用,但在研究方法论中,它们具有截然不同且至关重要的含义。清晰地理解二者的区别,并主动地识别与防范它们,是实施有效质量控制的逻辑起点。
我们可以用一个射击的例子来形象化地区分它们:
- 想象一位射手在打靶。如果他的所有子弹都紧密地聚集在一起,但整体偏离了靶心(例如,全部打在靶心的左上方),这便是系统性偏差(Systematic Bias)。射击的结果可靠(Reliable)——因为每次射击的结果都非常一致,但无效(Invalid)——因为它系统性地错失了真正的目标。这通常源于瞄准镜的校准问题、射手一贯的错误姿势等系统性因素。
- 现在想象另一位射手,他的子弹散布在靶心的周围,没有明显的偏向,但分布范围很广。这就是随机误差(Random Error)。射击结果的平均位置可能接近靶心,因此在某种程度上是无偏的(Unbiased),但不可靠(Unreliable)——因为每次射击的结果都相差很大,缺乏一致性。这可能源于风的微小扰动、每次呼吸的细微差别、子弹质量的微小差异等偶然性因素。
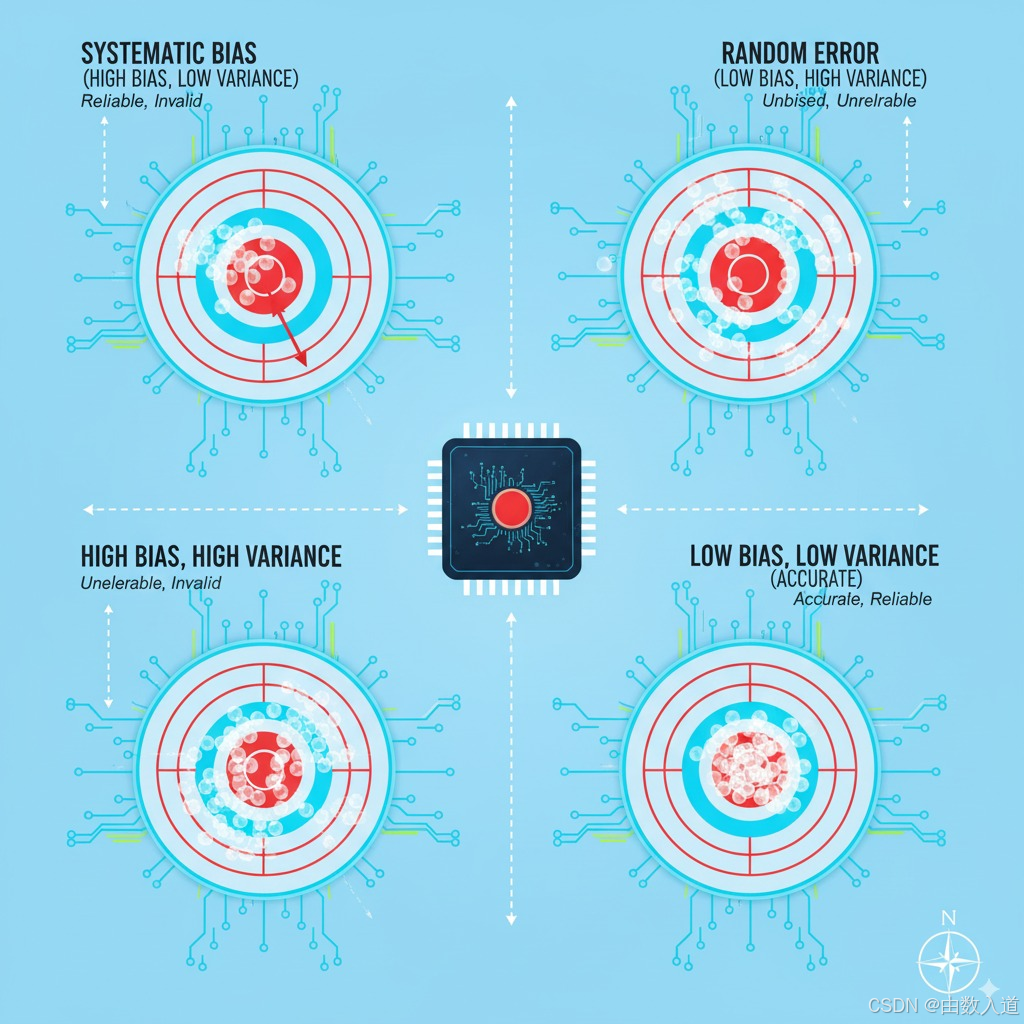
我们的终极目标,是成为一名低偏差、低误差的“神枪手”——所有子弹都紧密地聚集在靶心。质量控制的全部努力,正是为了校准我们的“瞄准镜”(消除偏差),并稳定我们的“射击动作”(减小误差)。
8.2.1 系统性偏差 (Systematic Bias): 效度的致命杀手
定义:
系统性偏差,简称偏差(Bias),是指在研究的设计、执行或分析阶段,由于存在系统性的、非随机的缺陷,导致研究结果一致性地、单方向地偏离“真值”(True Value)的现象。偏差直接损害的是研究的内部效度(Internal Validity)——即研究结论在多大程度上准确地反映了研究变量之间的真实因果关系,以及外部效度(External Validity)——即研究结果在多大程度上可以被推广到目标总体。偏差是比随机误差更危险的敌人,因为即使拥有再大的样本量,也无法消除其影响;相反,大样本量只会让一个被偏差污染的错误结论看起来更“精确”而已。
主要来源与类型:
偏差的来源多种多样,可以发生在研究的任何一个环节。理解这些来源是预防偏差的第一步。最主要的偏差类型包括选择性偏差、信息偏差和混淆偏差。
A. 选择性偏差 (Selection Bias)
选择性偏差是研究质量控制中最常见也最根本的挑战之一。它发生在研究样本的选择或保留过程中,导致最终进入分析的样本无法真实地代表我们希望研究的“目标总体”(Target Population)。这种样本与总体的系统性差异,使得基于样本得出的任何结论都难以、甚至完全不能安全地推广到总体,从而严重损害研究的外部效度。
-
核心机制: 选择性偏差的根源在于,被选入研究的个体(或他们的数据被保留下来的个体)在某些关键特征上(这些特征通常与研究的结局变量相关)与那些未被选入(或数据丢失)的个体存在系统性差异。
-
主要亚型与实例:
-
抽样偏差 (Sampling Bias): 这是最直接的选择性偏差形式,指抽样方法本身存在缺陷,导致某些特定子群体的成员比其他成员有更高或更低的概率被选中。
- 便利抽样 (Convenience Sampling): 研究者仅仅选择最容易接触到的个体作为样本。例如,在大学校园里对路过的学生进行关于“公众对核能态度”的调查。这个样本显然不能代表全体国民,因为学生的年龄、教育水平、社会经济地位等都与总体存在巨大差异。
- 志愿者偏差 (Volunteer Bias): 依赖志愿者参与的研究常常受此困扰。愿意主动参与研究的人,可能比普通人更健康、更关注某个议题、教育水平更高或更外向。例如,一项关于新型节食效果的研究,招募的志愿者可能本身就比普通人更有减肥动机和自制力,从而高估了节食方案的普适效果。
- 幸存者偏差 (Survivorship Bias): 我们在分析中只关注那些“幸存”下来的案例,而忽略了那些因某种原因未能坚持到最后的案例,这些被忽略的案例可能携带了与“幸存者”截然不同的重要信息。一个经典的例子是二战期间,研究人员分析返航战机上的弹孔分布,发现机翼和机尾弹孔最多,而驾驶舱和引擎部位很少。如果因此决定加固弹孔最多的部位,那就犯了致命错误。因为这恰恰说明,这些部位中弹了飞机还能飞回来,而驾驶舱或引擎中弹的飞机则很可能已经坠毁,未能成为“幸存”样本。真正需要加固的,正是那些返航战机上“看起来”最完好的部位。
-
无应答偏差 (Non-response Bias): 在问卷调查或队列研究中,即使初始抽样是随机的,如果有一大部分人选择不回应,且这些不回应的人与回应的人在关键特征上存在差异,就会产生无应答偏差。
- 实例: 一项关于社区居民收入水平的邮件调查,回收率只有30%。回应者很可能是那些对社区事务更关心、收入较高或生活较稳定的人。而那些收入极低或极高、生活不稳定的人可能更不愿意或没有时间回应,导致调查结果低估了收入的两极分化程度。
-
损失随访偏差 (Loss to Follow-up Bias) / 耗损偏差 (Attrition Bias): 在需要长期追踪研究对象的纵向研究(如队列研究或临床试验)中,如果在研究过程中部分参与者失联或退出,且这种“失访”并非随机发生,就会产生此偏差。
- 实例: 一项为期五年的关于某种新药治疗慢性病的临床试验。如果在试验过程中,那些病情加重或出现严重副作用的患者更倾向于退出试验,而坚持下来的大多是那些药物效果良好或副作用轻微的患者。那么,在研究结束时分析这批“幸存者”的数据,无疑会高估药物的疗效和安全性。
-
-
预防与控制策略:
- 严格的抽样设计: 尽可能使用概率抽样方法(如简单随机抽样、分层抽样、整群抽样),确保总体中的每个成员都有已知且非零的被选中概率。
- 提高应答率: 在调查研究中,通过发送提醒、提供小额激励、优化问卷设计、提供多种提交方式(线上、电话、邮寄)等手段,尽最大努力提高应答率。
- 最小化失访: 在纵向研究中,在研究开始前就建立详细的随访计划,与参与者保持良好沟通,收集多种联系方式,理解并尽力解决他们退出的原因。
- 分析阶段的调整: 如果偏差无法完全避免,可以在数据分析阶段采用一些统计方法进行事后调整,如权重法(给应答率较低的子群体更高的权重)或敏感性分析(评估不同失访率假设下结论的稳健性)。但这些方法都是补救措施,效果远不如在设计阶段就预防偏差。
B. 信息偏差 (Information Bias) / 测量偏差 (Measurement Bias)
信息偏差发生在数据收集阶段,指由于测量工具、访谈技巧、或参与者回忆等方面的系统性缺陷,导致收集到的信息本身就是不准确或不一致的。这种偏差污染了数据源头,使得后续的分析无论多么精妙,都无法得出真实的结果。它与选择性偏差不同,后者是“选错了人”,而信息偏差是“问错了问题”或“记错了答案”。
-
核心机制: 收集到的数据在不同组别之间(例如,实验组与对照组,或病例组与对照组)存在系统性的质量差异,或者数据系统性地偏离了其真实值。
-
主要亚型与实例:
-
回忆偏差 (Recall Bias): 当研究依赖参与者对过去事件、暴露或经历的回忆来收集数据时,这种偏差尤其普遍。人们的回忆往往是不准确的,且会受到当前状态的系统性影响。
- 经典实例: 在探索“怀孕期间服用某种药物是否会导致新生儿畸形”的病例对照研究中,研究者会询问已分娩的母亲们在孕期是否服用过该药物。那些生下畸形儿的母亲(病例组),为了寻找原因,可能会比那些生下健康婴儿的母亲(对照组)更仔细、更痛苦地回忆自己的孕期经历,从而更可能“回忆起”自己服用过某种药物,即使事实并非如此或记忆模糊。这会导致药物与畸形之间的关联被错误地高估。
-
观察者偏差 (Observer Bias) / 评估者偏差 (Assessor Bias): 当研究者或数据收集者对研究假设或参与者的分组情况有预先了解时,他们的期望可能会无意识地影响他们观察、记录和解释信息的方式。
- 实例: 一位研究者相信某种新的教学方法能提高学生成绩。在评估期末论文时,如果他知道哪些学生接受了新方法(实验组),哪些没有(对照组),他可能会无意识地对实验组学生的论文给出更高的分数,或者更倾向于在他们的答案中寻找支持其假设的证据。
-
访谈者偏差 (Interviewer Bias): 访谈者的个人特质(如语气、措辞、非语言行为)或提问方式系统性地影响了受访者的回答。
- 实例: 在一项关于种族歧视的访谈研究中,如果访谈员是一位白人,受访的少数族裔成员可能会因为社会期望或不信任感,而倾向于淡化自己遭受歧视的经历,导致研究低估了歧视的严重程度。
-
测量工具偏差 (Instrument Bias): 使用的测量工具(如问卷、天平、血压计)本身存在系统性误差。
- 问卷设计缺陷: 问卷中的问题措辞具有诱导性(“您难道不同意增加环保投入是至关重要的吗?”)、存在社会期许性(导致人们回答得更“政治正确”而非真实想法)、或选项设置不全面。
- 仪器未校准: 一台长期未校准的体重秤,可能总是比真实体重高出0.5公斤。如果用这台秤来测量节食干预前后的体重,虽然体重的“变化量”可能仍然准确,但所有绝对值都是错误的。
-
-
预防与控制策略:
- 使用标准化、经验证的测量工具: 尽可能采用在先前研究中已被证明具有良好信度和效度的问卷量表或仪器。
- 对数据收集人员进行严格培训: 确保所有观察者和访谈员都遵循标准化的操作流程(SOP),以相同的方式提问、观察和记录。
- 实施盲法 (Blinding): 这是对抗观察者偏差和回忆偏差的“王牌”。让数据收集者、评估者,甚至参与者都不知道分组情况(详见8.3.1节)。
- 使用客观、可核实的记录: 尽可能不依赖参与者的长期记忆,而是使用客观记录,如病历、用药记录、销售数据等。
- 精心设计问卷: 采用中性、无诱导性的措辞,进行预测试(Pilot Test)以发现潜在的问题。
C. 混淆偏差 (Confounding Bias)
混淆偏差是一种更为复杂和隐蔽的偏差,它发生在数据分析和解释阶段。当一个我们未加控制的外部变量(即混淆变量)同时与自变量(我们研究的“原因”)和因变量(我们观察的“结果”)都有关联时,它就会扭曲我们观察到的自变量与因变量之间的真实关系,造成“假性关联”或掩盖“真实关联”。
-
混淆变量的三个特征:
- 它必须是因变量的一个独立危险因素(或保护因素)。
- 它必须与自变量相关联。
- 它不能处于自变量到因变量的因果链条上(即它不能是中介变量)。
-
经典实例:咖啡与心脏病
早期的一些观察性研究发现,喝咖啡的人患心脏病的风险似乎更高。然而,这个结论可能受到了混淆偏差的污染。这里的混淆变量是“吸烟”。- 吸烟是心脏病的独立危险因素(满足特征1)。
- 在当时的人群中,喝咖啡的人通常也更可能吸烟(满足特征2)。
- 吸烟并非喝咖啡导致的(满足特征3)。
因此,即使咖啡本身对心脏无害,但由于它总是与“吸烟”这个真正的“凶手”同时出现,导致我们错误地将心脏病的罪过归咎于咖啡。我们观察到的“咖啡-心脏病”关联,实际上是“吸烟-心脏病”关联的伪装。
-
预防与控制策略:
- 设计阶段的控制:
- 随机化 (Randomization): 在实验研究中,随机分配是控制所有已知和未知混淆变量的最强有力方法。通过随机化,我们可以期望各种混淆变量(如年龄、性别、吸烟习惯)在实验组和对照组中被均匀分布,从而消除其混淆效应。
- 限制 (Restriction): 在招募研究对象时,只纳入混淆变量处于某个特定水平的个体。例如,在研究某个因素对女性的影响时,可以只招募女性,从而完全消除“性别”的混淆。
- 匹配 (Matching): 在病例对照研究中,为每一个病例(如患有某病的人),都从对照组中寻找一个或多个在关键混淆变量(如年龄、性别)上与他/她相同或非常相似的个体进行匹配。
- 分析阶段的控制:
- 分层分析 (Stratification): 按照混淆变量的不同水平(“层”)将数据分开,在每一层内部分别分析自变量与因变量的关系。如果各层内的关联度一致,且与未分层前的总关联度不同,就说明存在混淆。
- 多变量统计模型 (Multivariable Models): 使用多元回归、逻辑回归、Cox回归等统计模型,可以将混淆变量作为协变量(covariate)放入模型中进行“调整”(adjust for),从而在统计学上控制其影响,得到一个剔除了混淆效应后,“纯净”的自变量与因变量之间的关联估计。
- 设计阶段的控制:
8.2.2 随机误差 (Random Error): 信度的挑战者
定义:
随机误差,又称“机会”(Chance)或“噪音”(Noise),是指由各种不可预测的、偶然的因素所引起的、在测量中没有固定方向的误差。它围绕着一个中心值(通常是“真值”)随机波动,有时偏高,有时偏低。随机误差直接损害的是研究的信度(Reliability)或精确性(Precision)。信度高的研究,意味着如果重复进行测量,每次得到的结果都会非常接近。
与系统性偏差的区别:
| 特征 | 系统性偏差 (Systematic Bias) | 随机误差 (Random Error) |
|---|---|---|
| 方向性 | 单向的、一致的偏离 | 无固定方向、随机波动 |
| 对均值的影响 | 使测量均值偏离真值 | 不改变测量均值的长期期望值,但增加其不确定性 |
| 对结果的影响 | 损害效度(准确性) | 损害信度(精确性、可重复性) |
| 与样本量的关系 | 增加样本量无法消除,反而会使其更“显著” | 增加样本量可以减小其对结果估计的影响(大数定律) |
来源:
随机误差的来源无处不在,几乎不可能完全消除,它们是测量过程中的固有“背景噪音”。
- 生物学变异 (Biological Variation): 个体内部的生理指标(如血压、心率、血糖)在不同时间点会自然波动。
- 测量工具的精度限制 (Instrument Precision): 任何仪器都有其固有的精度极限。例如,一把普通尺子无法精确测量微米级别的长度,其读数会包含随机的估读误差。
- 环境的微小波动 (Environmental Fluctuations): 实验室的温度、湿度、光照、噪音等微小变化,都可能对测量结果产生随机影响。
- 操作者的细微差异 (Operator Variability): 即使是同一个研究人员,在重复进行相同的操作时,每次的动作也无法做到100%完全一致。
- 被试的瞬时状态变化 (Subject’s Momentary State): 参与者的注意力、情绪、疲劳程度等瞬时状态的波动,会影响他们在回答问卷或完成任务时的表现。
控制策略:
虽然随机误差无法被彻底根除,但我们可以通过一系列策略来有效地减小其影响,提高研究的信度和精确性。
- 增加样本量 (Increasing Sample Size): 这是对抗随机误差最根本、最有效的武器。根据中心极限定理,随着样本量的增加,样本均值的抽样分布会越来越集中在总体均值周围,即标准误(Standard Error)会减小。一个更大的样本能够更好地“稀释”掉个体层面的随机波动,从而得到一个更稳定、更精确的对总体参数的估计。
- 重复测量 (Repeated Measurements): 对同一个研究对象进行多次测量然后取平均值,可以有效地抵消单次测量中的随机误差。这在仪器测量和行为观察中非常常见。例如,测量血压时通常会连续测量三次取平均值。
- 使用更精密的仪器和技术 (Using More Precise Instruments): 选择精度更高、稳定性更好的测量工具,可以从源头上减小测量工具带来的随机误差。
- 标准化操作流程 (Standardizing Procedures): 制定并严格遵守SOP,确保每次测量的环境条件、操作步骤、时间安排等都尽可能保持一致,从而减少由环境和操作者变异引入的随机误差。
- 对研究人员进行严格培训 (Rigorous Training of Researchers): 通过充分的培训和练习,确保所有数据收集人员都能熟练、一致地执行操作,减少人为引入的随机变异。
质量控制的核心,就是一场与偏差和误差的持久战。偏差如同一个狡猾的骗子,会系统性地将我们引向错误的方向;而误差则像一阵持续不断的噪音,干扰我们倾听真实的信号。一个严谨的研究者,必须在研究的每一个环节都戴上批判性的眼镜,像侦探一样审视所有可能引入偏差的漏洞,并像工程师一样设计 robust 的流程来最大限度地抑制随机误差的干扰。只有这样,我们才能自信地宣称,我们的研究结果不仅是精确的,更是准确的,是向科学真理迈出的坚实一步。
8.3 定量研究中的质量控制策略
在定量研究的范式中,其核心追求是客观性(Objectivity)、可测量性(Measurability)和可概括性(Generalizability)。这个范式建立在实证主义哲学基础上,认为存在一个独立于研究者意识之外的、可通过系统观察和测量来认识的客观现实。因此,定量研究的质量控制策略,其核心目标便是最大限度地逼近这种客观真实性,通过一系列高度结构化和标准化的程序,系统性地消除研究者主观性、情境变异性以及前文所述的各种偏差和误差。
这些策略并非孤立的技术点,而是构成了一个从理论构思到数据产出的完整防御体系。这个体系的设计哲学是“预防为主,控制为辅”,即在研究的萌芽阶段就预先识别潜在的质量威胁,并通过精妙的设计将其扼杀在摇篮里,而非等到数据污染后再进行无力的补救。本节将详细剖析这一防御体系在设计阶段、执行阶段和分析阶段的关键策略。
8.3.1 设计阶段的控制:构建研究的坚固骨架
研究的设计阶段是质量控制的“黄金时期”,此阶段的决策具有基础性和决定性,其影响将贯穿整个研究过程。一个在设计上存在根本缺陷的研究,无论在执行和分析阶段投入多少资源,都难以挽救。如同建造一座大厦,地基的质量决定了其最终的高度和稳固性。
A. 清晰的操作化定义 (Clear Operationalization)
这是连接抽象理论与具体测量的第一座,也是最重要的一座桥梁。科学研究始于理论构念(Theoretical Constructs),这些构念是抽象的、无法直接观察的概念,如“幸福感”、“社会资本”、“组织创新能力”、“认知负荷”等。如果不对这些构念进行清晰的定义和转化,研究将变得含糊不清,不同研究者之间无法对话,研究结果也无从验证。
操作化定义(Operational Definition),就是将这些抽象构念转化为一系列具体的、可观察、可测量的指标或操作程序的过程。一个优秀的操作化定义,必须具备明确性、可重复性和有效性。
-
过程与挑战:
- 概念定义(Conceptual Definition): 首先,必须清晰地界定构念的理论内涵和边界。例如,要研究“幸福感”,我们首先要明确我们指的是“主观幸福感”(包含生活满意度、积极情感和消极情感),而非其他类型的幸福(如亚里士多德的“实现论”幸福)。
- 维度分解(Dimensionalization): 许多复杂构念是多维度的。例如,“社会资本”可以分解为“社会网络”、“社会规范”和“社会信任”三个维度。每个维度都需要被单独操作化。
- 指标选择(Indicator Selection): 为每个维度选择一个或多个具体的、可量化的指标。例如,对于“生活满意度”维度,我们可以使用经过验证的“生活满意度量表(SWLS)”,其指标就是参与者在该量表上的总得分。对于“社会网络”,指标可以是“过去一个月内联系过的朋友数量”。
- 操作规程制定: 如果操作化定义涉及一个实验程序,那么必须详细描述这个程序。例如,操作化“认知负荷”,可以通过测量参与者在完成一项主要任务的同时,对次要任务(如声音探测)的反应时和准确率来实现。这个程序的所有细节——任务难度、刺激呈现时间、设备参数等——都必须被精确规定。
-
质量控制的意义:
- 确保构念效度(Construct Validity): 这是衡量一个操作化定义好坏的根本标准,即我们的测量在多大程度上真实地反映了我们意图测量的那个抽象构念。一个糟糕的操作化定义,比如用“年收入”来测量“幸福感”,其构念效度显然很低,因为它忽略了幸福感的非物质层面。
- 保证可重复性(Reproducibility): 清晰的操作化定义使得其他研究者能够精确地重复我们的研究,这是科学知识积累的基础。如果定义模糊, replication 将无从谈起。
- 促进学术交流: 它为不同研究者提供了一个共同的语言基础,使得关于同一构念的研究结果可以被比较和整合(如在Meta分析中)。
-
实践指南:
- 文献先行: 在自行创建操作化定义之前,务必对现有文献进行详尽的回顾,优先采用那些已被广泛使用并经过信效度检验的成熟量表或实验范式。
- 预测试(Pilot Testing): 在大规模研究开始前,对你的操作化定义(特别是新开发的问卷或实验程序)进行小范围的预测试,以检查其清晰度、可行性以及参与者的理解情况。
- 明确报告: 在研究报告的方法部分,必须详尽、清晰地描述你的操作化定义,包括所使用的量表、具体的实验程序、计分规则等,以便他人评估和重复。
B. 随机化 (Randomization):对抗混淆的终极武器
在探究因果关系的实验设计中,随机化是迄今为止人类发明的最强大、最优雅的控制混淆偏差的工具。它的力量在于,它不仅能控制我们已知的混淆变量(如年龄、性别),更能平均化我们未知或无法测量的混淆变量(如遗传倾向、生活习惯的微小差异)。
**随机化(Randomization)**是指将被试(或其他实验单元)通过一个纯粹的概率过程(如抛硬币、使用随机数表、计算机生成随机数)分配到不同的研究组别(如实验组和对照组)。
-
核心原理:
随机化的核心逻辑是“破除关联”。它斩断了任何潜在混淆变量与分组变量之间的系统性联系。由于分组是完全随机的,从长期来看(即样本量足够大时),任何一个特征(无论是可观察的还是不可观察的)在各个组之间的分布都将趋于一致。例如,通过随机分配,实验组和对照组中老年人和年轻人、男性和女性、高收入和低收入人群的比例将会非常接近。这样,在研究结束时,如果我们观察到两组在结果变量上存在差异,我们就可以更有信心地将其归因于我们施加的实验干预(自变量),而非两组之间本来就存在的系统性差异。 -
随机化的类型:
- 简单随机化(Simple Randomization): 每个被试都有完全相等的机会被分到任何一组。这是最基本的形式,但当样本量较小时,可能偶然导致组间人数不均或某些关键特征分布不均。
- 区组随机化(Blocked Randomization): 为了确保在研究的任何阶段,各组的人数都保持大致相等,可以将参与者分成小的“区组”(例如,每4个人一个区组),然后在每个区组内部进行随机分配(例如,2个去实验组,2个去对照组)。
- 分层随机化(Stratified Randomization): 如果我们知道某个或某几个变量是重要的潜在混淆变量(如疾病严重程度、年龄分段),我们可以先按照这些变量将被试分成不同的“层”,然后在每一层内部独立进行随机化。这能确保这些关键的已知混淆变量在各组之间是绝对均衡的。
-
实践中的挑战与对策:
- 随机分配的隐藏(Allocation Concealment): 仅仅生成了随机序列还不够,必须确保负责招募被试的研究人员在将被试纳入研究之前,完全无法预知该被试将被分到哪一组。否则,他们可能会有意识或无意识地将某些特定类型的被试(如病情更重的)安排到他们认为“更好”的组别中,从而破坏随机化的根基。实现隐藏的方法包括:使用中心化的、由第三方控制的随机分配服务(电话或网络),或者使用密封、不透明、按顺序编号的信封。
- 伦理限制: 在许多情况下,对人类进行随机分配是不道德或不可行的。例如,我们不能随机地让一组人吸烟,另一组人不吸烟,来研究吸烟对健康的影响。在这些情况下,我们只能退而求其次,使用观察性研究设计,并依赖分析阶段的统计方法来尽力控制混淆。
C. 盲法 (Blinding / Masking):偏见的“眼罩”
盲法是消除信息偏差(特别是观察者偏差和被试期望效应)的“金标准”。它的核心思想是,通过对研究中的一个或多个关键参与方(被试、研究执行者、数据分析者等)隐藏分组信息,来防止他们的期望或信念影响研究数据的收集和解释。
-
盲法的层次:
- 单盲(Single-Blind): 通常指被试不知道自己被分配到哪一组(例如,他们不知道自己服用的是真药还是外观、味道完全相同的安慰剂)。这主要用于控制安慰剂效应(Placebo Effect)——即被试仅仅因为相信自己正在接受有效治疗而产生的生理或心理改善。
- 双盲(Double-Blind): 这是更严格的形式,指被试和直接与被试接触并进行干预或评估的研究人员(如医生、护士、评估员)都不知道分组情况。这在控制安慰剂效应的同时,也消除了研究人员的“期望效应(Expectancy Effect)”——即他们可能无意识地对实验组被试给予更多关注,或在评估结果时更倾向于看到积极变化。
- 三盲(Triple-Blind): 在双盲的基础上,负责数据分析和解释的研究人员也不知道分组信息(他们拿到的数据可能被标记为“A组”和“B组”)。这可以防止他们在数据清理、统计模型选择或结果解释时,有意识或无意识地做出偏向其假设的决策。
-
“金标准”的地位:
在临床试验领域,随机双盲对照试验(Randomized Double-Blind Controlled Trial, RCT)被公认为检验干预措施有效性的“金标准”。它同时运用了随机化和双盲两大武器,最大限度地控制了混淆偏差和信息偏差,从而提供了关于因果关系的最强证据。 -
实践中的考量:
- 盲法的可行性: 并非所有研究都能实施盲法。例如,一项比较“手术治疗”与“药物治疗”的研究,显然无法对被试和医生进行盲法。一项比较“线上学习”与“线下教学”的研究也是如此。在这种情况下,研究者必须想办法对结果的评估者进行盲法。例如,让一位不知道学生分组情况的独立评分者来评阅他们的期末考试卷。
- 破盲(Unblinding): 在研究过程中,需要有严格的程序来处理紧急情况下的“破盲”(例如,被试出现严重不良反应,需要知道他/她服用的是什么)。同时,在研究结束后,揭盲的过程也必须严谨记录。
D. 样本量估算与统计功效分析 (Sample Size Estimation & Power Analysis)
在研究开始之前,科学地回答“我需要多少参与者?”这个问题,是避免浪费资源和得出错误结论的关键一步。过小的样本量可能导致我们错失一个真实存在的效应,而过大的样本量则会造成不必要的伦理和经济成本。
**统计功效(Statistical Power)**是指在一项研究中,当一个真实的效应确实存在时,我们能够成功地通过假设检验探测到它(即正确地拒绝零假设)的概率。通常,研究者希望功效至少达到80%(即有80%的机会发现真实存在的效应)。
**功效分析(Power Analysis)**是一个统计过程,它在以下四个变量之间建立了一个数学关系:
- 样本量(Sample Size, N): 我们需要招募的参与者数量。
- 效应量(Effect Size): 我们期望探测到的效应的强度或大小。这通常基于先前的研究或理论,是一个预先设定的值。
- 显著性水平(Significance Level, α): 我们愿意承担的“犯第一类错误”(假阳性,即错误地拒绝一个为真的零假设)的风险,通常设定为0.05。
- 统计功效(Power, 1-β): 我们希望达到的探测到真实效应的概率,通常设定为0.80。(β是犯第二类错误,即假阴性的概率)。
-
质量控制的意义:
- 避免第二类错误(假阴性): 功效不足(underpowered)的研究是科学文献中的一个主要问题。如果一项研究因为样本量太小而未能发现一个真实存在的、有临床或实践意义的效应,它会得出“无效果”的错误结论。这不仅浪费了研究资源,还可能误导后续研究方向,甚至让一个有潜力的疗法被过早放弃。
- 资源与伦理考量: 样本量估算确保我们只招募“足够”的参与者,不多也不少。招募过多参与者会让他们承担不必要的研究风险(如在临床试验中)并浪费经费,而招募过少则会让所有参与者的贡献都因为研究结论无效而白费。
- 提高研究设计的严谨性: 进行功效分析的过程,迫使研究者在研究开始前就清晰地定义其主要假设、主要结果变量,并对预期的效应量做出一个有根据的估计。这本身就极大地促进了研究设计的清晰化和严谨性。
-
实施流程:
- 明确主要研究假设和统计检验方法(如t检验、ANOVA、卡方检验)。
- 设定α(通常0.05)和Power(通常0.80)。
- 估计效应量: 这是最关键也最困难的一步。可以通过查阅相关主题的文献(特别是Meta分析)、进行预实验,或者根据理论确定一个“具有实际意义的最小效应量”(Smallest Effect Size of Interest, SESOI)。
- 使用专门的软件(如G*Power)或统计包中的函数(如R语言的
pwr包)输入上述参数,计算出所需的最小样本量。
8.3.2 执行阶段的控制:将设计蓝图精确落地
设计阶段的完美蓝图,需要执行阶段的精确施工才能变为现实。执行阶段的质量控制,核心在于标准化(Standardization)和监控(Monitoring),确保研究的每一个步骤都严格按照预设方案执行,最大限度地减少人为和环境引入的变异。
A. 标准化操作流程 (Standard Operating Procedure, SOP)
SOP是一份详尽的、书面化的“操作手册”,它为研究团队的每一个人提供了关于如何执行特定任务的清晰、一致的指令。它是将研究设计转化为可重复行动的蓝图,是确保研究过程**可靠性(Reliability)**的基石。
-
SOP应涵盖的内容:
- 被试招募与知情同意: 详细的纳入和排除标准,如何接触潜在被试,知情同意书的解释流程等。
- 实验干预的实施: 如果是实验研究,需要详细描述干预措施的每一个细节(如药物的剂量和给药方式,培训课程的内容和时长)。
- 数据收集流程: 访谈或问卷的发放方式,访谈员的开场白和标准提问脚本,生理指标的测量步骤(如测量血压前需静坐5分钟),样品的采集、处理和存储规程。
- 设备操作与校准: 每台仪器的开机、设置、操作和关机流程,以及定期校准的时间表和方法。
- 数据管理: 数据的命名规则、存储位置、备份计划、以及下面将要详述的数据录入核对流程。
-
制定与实施:
- 集体制定: SOP的制定应该是团队协作的结果,确保其内容既科学严谨又切实可行。
- 严格培训: 所有参与数据收集的研究人员都必须接受关于SOP的严格培训,并通过考核,确保他们完全理解并能熟练操作。
- 动态更新: SOP并非一成不变,如果在研究过程中发现有需要改进的地方,应通过正式的修订程序进行更新,并通知所有相关人员。
B. 仪器校准与维护 (Instrument Calibration & Maintenance)
对于依赖物理或生物测量的研究,测量仪器的准确性和稳定性至关重要。仪器偏差是信息偏差的一个重要来源。
- 校准(Calibration): 定期使用一个已知的标准(“标准品”或“标准源”)来检查仪器的读数,并根据需要进行调整,以确保其测量结果与“真值”一致。例如,用标准砝码校准天平,用标准pH缓冲液校准pH计。
- 维护(Maintenance): 遵循制造商的建议,对仪器进行定期的清洁、保养和更换易损件,以保持其最佳工作状态。
- 记录: 所有的校准和维护活动都必须有详细的记录,包括日期、操作人员、使用的标准品、校准前后的读数等。这些记录是研究质量审计的重要组成部分。
C. 数据录入双人核对 (Double Data Entry & Validation)
从纸质问卷、访谈记录或实验记录本上手动将数据录入到电子数据库(如Excel, SPSS, RedCap)是极易出错的环节,常见的错误包括数字输错、选项点错、文本录入错误等。这些错误会引入测量误差,甚至可能改变研究结论。
-
双人录入核对法:
- 独立录入: 由两个人(操作员A和操作员B)背对背地将同一批原始数据独立录入到两个不同的电子文件中。
- 程序比对: 使用专门的软件(如EpiData)或编写简单的脚本,对这两个文件进行逐个单元格的比对。
- 差异核查: 软件会生成一份“不一致报告”,列出所有存在差异的条目。
- 原始数据核对与修正: 由第三个人(或由A和B共同)根据原始数据记录,对报告中的每一项差异进行核对,找出并纠正错误录入,最终形成一个“干净”的最终数据集。
-
优越性:
这种方法虽然耗时耗力,但被公认为最大限度减少录入错误率的“金标准”。它远比单人录入后自己再检查一遍(因为人们很难发现自己犯的错误)要有效得多。
D. 过程监控与审计 (Process Monitoring & Auditing)
对于大型、复杂或高风险的研究(特别是多中心临床试验),建立一个独立的监控和审计机制是必要的。
- 监控(Monitoring): 由研究团队内部或申办方指定的人员(监查员, Monitor),定期检查研究的进展,核对原始数据与病例报告表(CRF),确保研究严格遵守方案和SOP,及时发现并解决问题。
- 审计(Auditing): 由一个完全独立于研究团队的第三方(审计员, Auditor),对研究的全过程(从设计、伦理报批到数据分析和报告)进行系统性的、独立的检查,以评估研究的合规性和数据质量。
通过在设计和执行阶段实施这一系列严密的质量控制策略,定量研究得以构建一个坚固的、可信的证据基础。这些策略共同作用,系统性地将偏差和误差的潜在影响降至最低,为最终得出有效且可靠的科学结论铺平了道路。
8.4 定性研究中的质量控制策略:严谨性与可信性
当我们从定量研究的实证主义世界,步入定性研究的解释主义或建构主义领域时,关于“质量”的定义和保障方式也发生了根本性的转变。定性研究的核心目的,并非像定量研究那样去测量和验证一个客观、普适的“真理”,而是致力于深入、整体性地理解特定情境下个体的生活体验、主观意义建构和社会文化现象。它探究的是“为什么”和“怎么样”,而非“有多少”或“是否相关”。
因此,将定量研究中以“客观性”、“信度”、“效度”为核心的质量控制标准生搬硬套到定性研究上,是削足适履,甚至是完全错误的。这并不意味着定性研究缺乏严谨性,恰恰相反,高质量的定性研究拥有一套同样严格甚至更为复杂的质量标准和保障策略。这个体系的核心词汇,不再是“ объективности (objectivity) ”,而是**“可信性”(Trustworthiness)**。
“可信性”这一概念,旨在回答一个核心问题:我们凭什么相信这项定性研究的发现是值得关注、有价值且非研究者凭空杜撰的? 为了系统性地建立和评估这种可信性,学者们提出了多个理论框架,其中最被广泛引用和接受的,是由**伊冯娜·林肯(Yvonna Lincoln)和艾根·古巴(Egon Guba)**在其里程碑著作《自然主义探究》(Naturalistic Inquiry, 1985)中提出的四维标准模型。这个模型巧妙地与定量研究的传统标准进行了类比,为两个不同范式之间的对话搭建了一座桥梁,同时又深刻地阐明了定性研究的独特追求。
8.4.1 确保可信性的四大支柱(林肯与古巴模型)
林肯与古巴提出的可信性框架包含四个核心标准:可信度 (Credibility)、可转移性 (Transferability)、可靠性 (Dependability) 和 可确认性 (Confirmability)。它们共同构成了一个评估定性研究严谨性的综合体系。
A. 可信度 (Credibility):探寻内在的真实
- 类比定量研究标准: 内部效度 (Internal Validity)
- 核心问题: 研究的发现和解释在多大程度上是真实可信的,是否准确地捕捉和呈现了研究参与者(participants)的主观现实、真实观点和生活经历?换言之,研究描绘的图景,参与者自己会认可吗?
可信度是定性研究可信性框架中最为重要的基石。如果一项研究的发现连被研究者本人都觉得不真实、不准确,那么其他一切质量标准都将失去意义。它要求研究者不仅仅是记录,更是深度共情、准确理解和忠实呈现。
- 提升可信度的核心策略:
-
长期持续的田野参与 (Prolonged Engagement):
- 内容: 研究者需要在研究场域中投入足够长的时间,与参与者进行持续、深入的互动。这不仅仅是时间的堆砌,更是与研究情境和参与者建立信任(rapport)、减少陌生感、融入文化的过程。
- 作用: 首先,长期参与有助于研究者克服最初的表面印象和偏见,看到更为真实和复杂的日常实践。其次,它能让参与者逐渐放下戒备,展示出更自然、更真实的行为和想法,减少“霍桑效应”(即被观察者因知晓自己被观察而改变行为)。最后,它使研究者能够识别和理解情境中的特殊事件和异常信息,而非轻易将其忽略。
- 实例: 一位人类学家为了研究某个偏远部落的婚姻习俗,在村庄里居住了整整一年,与村民同吃同住,参与他们的日常劳动和节庆活动。这种沉浸式的体验,使其最终的研究发现远比短暂的几次访谈要深刻和可信得多。
-
持续的观察 (Persistent Observation):
- 内容: 在长期参与的基础上,研究者需要有意识地、系统性地对那些与研究问题最相关的现象、互动和细节进行深入、细致的观察。这是一种从“广泛扫描”到“深度聚焦”的转变。
- 作用: 持续观察有助于研究者识别出情境中真正具有典型性和关键性的特征,避免被大量无关信息淹没。它要求研究者不断地反思:“哪些事件和行为是理解这个现象的核心?”
- 实例: 在研究急诊室医护人员决策过程的民族志中,研究者在初期广泛观察所有活动后,逐渐将观察焦点集中在“交接班”、“危重病人抢救”和“与家属沟通”这几个关键时刻,因为这些时刻最能凸显决策的压力和复杂性。
-
三角验证 (Triangulation):
- 内容: 这是提升可信度最常用也最强大的策略之一。它指的是从多个不同角度来审视同一个现象,以获得更全面、更稳健的理解。如果来自不同角度的信息能够相互印证、汇合(converge),那么研究的发现就更具可信度。
- 三角验证的类型:
- 数据来源三角验证 (Data Triangulation): 使用不同来源的数据。例如,在研究一所学校的教学改革时,同时访谈校长、教师、学生和家长,并查阅学校的官方文件和学生的作业。
- 研究者三角验证 (Investigator Triangulation): 由多位研究者(通常来自不同背景)组成团队,共同收集和分析数据。他们可以定期开会讨论各自的观察和解释,相互质询,减少个人偏见的影响。
- 理论三角验证 (Theory Triangulation): 使用多个不同的理论视角来分析和解释同一组数据。例如,用“组织文化理论”和“权力关系理论”来同时解读一家公司的内部冲突。
- 方法论三角验证 (Methodological Triangulation): 在一项研究中同时使用多种不同的定性(甚至定量)方法。例如,结合使用深度访谈、参与式观察和焦点小组来探讨社区居民对某个公共项目的看法。
-
成员核查 (Member Checking / Respondent Validation):
- 内容: 这被林肯和古巴称为“确立可信度的最关键技术”。它指的是研究者将自己收集到的数据(如访谈转录稿)、初步的分析结果、解释或最终的研究报告,返回给提供信息的参与者本人,征求他们的确认、反馈、修正或进一步阐释。
- 作用: 成员核查直接检验了研究者的理解是否与参与者的自我感知相符,是确保研究“忠实性”的终极测试。这个过程本身也可能成为一个新的数据收集机会,激发参与者提供更深入的见解。
- 实践形式: 可以在单次访谈结束后,将转录稿发给受访者确认其准确性;可以在数据分析的中间阶段,与几位核心参与者开一个小会,向他们呈现初步的主题和理论框架,听取他们的意见;也可以在最终报告撰写前,将相关章节发给参与者审阅。
-
寻找反面案例 (Negative Case Analysis):
- 内容: 在数据分析过程中,研究者在初步形成一个主题或理论解释后,必须有意识地、努力地去寻找那些与这个解释不符、甚至完全矛盾的“反面案例”或“例外情况”。
- 作用: 这个过程强迫研究者不断地审视和修正自己正在形成的理论。如果找到了反面案例,研究者不能简单地忽略它,而必须回到数据中,重新思考自己的解释,直到能够发展出一个更加精细、更具包容性,能够同时解释正面和反面案例的理论模型为止。这是一个动态的、迭代的理论建构过程,极大地增强了最终理论的严谨性和说服力。
-
B. 可转移性 (Transferability):探寻外在的共鸣
- 类比定量研究标准: 外部效度 (External Validity) / 概括性 (Generalizability)
- 核心问题: 这项研究的发现,在多大程度上可以应用于或 resonates with 其他的情境或群体?
定性研究通常是基于小样本、特定情境的深度探究,因此它不追求定量研究那种基于概率抽样的统计学意义上的“概括性”。我们不可能说,对美国硅谷5位创业者的研究发现,可以被统计推断到全世界所有的创业者。但是,这不代表定性研究的发现是孤立的、毫无普适价值的。定性研究追求的是一种分析性概括(Analytic Generalization)或理论性概括(Theoretical Generalization),即通过深度揭示特定案例的内在机制和模式,为理解其他相似情境提供理论洞见和参考框架。
可转移性的责任,最终并不完全落在研究者身上,而是由研究者和读者共同承担。研究者的责任,不是去宣称“我的结论适用于何处”,而是提供足够的信息,让读者自己能够做出明智的判断:“这个研究的发现,对我所关心的那个情境是否有启发和借鉴意义?”
- 提升可转移性的核心策略:
- 提供厚重描述 (Thick Description):
- 内容: 这是由人类学家克利福德·格尔茨(Clifford Geertz)提出的核心概念,也是实现可转移性的唯一且最重要的策略。厚重描述不仅仅是简单地记录事实(“那个人举起了手”——此为“薄描述”),而是要深入地、丰富地、多层次地描绘研究发生的具体情境、参与者的特征、社会文化背景、互动的过程以及这些行为在特定文化脉络中的深层意义(“那位在激烈辩论中,为了强调自己的观点并获得发言权,果断地举起了他的右手,这是一个在该文化中表示强烈请求注意的姿态”——此为“厚重描述”)。
- 具体要素: 厚重描述应包含对研究场域的物理环境、历史背景、社会结构、人际关系、参与者的语言和非语言行为、研究者本人的观察和感受等方面的详细刻画。
- 作用: 通过提供一幅生动、立体、细节丰富的“图画”,厚重描述使得读者仿佛身临其境,能够充分理解研究发现是在何种具体的“土壤”中生长出来的。这样,读者就可以将自己所关心的情境与研究中描绘的情境进行比较,评估二者的相似性,并进而判断研究发现的可转移程度。
- 提供厚重描述 (Thick Description):
C. 可靠性 (Dependability):探寻过程的稳定
- 类比定量研究标准: 信度 (Reliability)
- 核心问题: 研究过程是否是清晰、一致、可追溯的?如果另一位研究者在尽可能相同的条件下(虽然在变化的社会世界中“完全相同”是不可能的)重复这项研究,他/她能否理解并遵循你的研究路径,并有可能得出相似的(而非完全相同的)发现?
定性研究的世界是动态变化的,研究者本人也是研究工具的一部分,因此,定量研究中那种“重复测量得到完全相同结果”的信度概念在此并不适用。定性研究的可靠性,强调的不是结果的绝对一致,而是过程的稳定性和可审计性(Auditability)。它关注的是研究过程的逻辑性、严谨性和透明度。
- 提升可靠性的核心策略:
- 建立审计追踪 (Audit Trail):
- 内容: 这是确保可靠性的核心策略。审计追踪指的是研究者系统性地、详细地记录从研究启动到结束的所有决策、过程和产出。它就像一本详尽的“研究航海日志”。
- 审计追踪应包含的材料:
- 原始数据: 所有的访谈录音、转录稿、田野笔记、照片、文档、备忘录(Memos)等。
- 过程记录: 研究计划书的历次版本、研究日志(记录每天的活动和进展)、访谈提纲、数据收集的时间和地点记录。
- 分析过程记录: 描述数据如何从原始文本一步步被编码、分类、形成主题和理论的详细备忘录,包括编码本的演变过程、主题形成的逻辑图等。
- 研究者反思记录: 即下面将要详述的“反思性日志”。
- 作用: 一个完整的审计追踪,使得一位外部的审查者(或“审计员”)可以清晰地追溯研究者从原始数据到最终结论的整个心路历程和操作路径。这使得他们能够评估研究过程是否合乎逻辑、决策是否合理、结论是否扎根于数据。可靠性与下一节的可确认性紧密相连,审计追踪是评估二者的共同基础。
- 建立审计追踪 (Audit Trail):
D. 可确认性 (Confirmability):探寻数据的根基
- 类比定量研究标准: 客观性 (Objectivity)
- 核心问题: 研究的发现和结论在多大程度上是植根于数据(grounded in the data),而非仅仅是研究者个人的偏见、想象或主观臆断?换言之,我们能否确认,这些结论确实是从参与者的声音和行为中“生长”出来的?
定性研究承认研究者不可能完全“价值中立”,研究者本人就是研究工具,其个人背景、理论偏好和情感必然会影响研究过程。因此,定性研究不追求一种虚幻的“客观性”,而是追求“可确认性”,即通过程序化的严谨,确保研究结果可以被独立地确认其数据来源。
- 提升可确认性的核心策略:
-
审计追踪 (Audit Trail) 的应用:
- 可确认性的评估,在很大程度上依赖于对前述“审计追踪”的审查。审查者通过检查审计追踪,可以判断研究者的解释与原始数据之间是否存在清晰、可辩护的逻辑联系。审计追踪使得研究的“黑箱”变得透明。
-
反思性 (Reflexivity):
- 内容: 这是确保可确认性的灵魂所在。反思性是研究者的一种持续的自我意识和自我批判过程。它要求研究者不断地审视和反思自己的角色、假设、价值观、情感、社会地位以及与参与者的关系,是如何可能影响到研究的每一个环节——从问题的提出、与参与者的互动、数据的解读,到最终报告的撰写。
- 实践工具:反思性日志 (Reflexivity Journal / Diary): 研究者应该保持一个与研究日志平行的反思性日志。在这个日志中,他们记录的不是“发生了什么”,而是“我如何思考和感受所发生的一切”。
- 日志内容示例: “今天访谈李先生时,我感到很不舒服,因为他的观点与我的价值观严重冲突。我必须警惕自己不要因此在提问时带有偏见,或者在分析时过分批判他的言论。”“我发现我特别同情王女士的遭遇,这可能会让我无意识地在报告中过多地放大她的故事,而忽略了其他参与者的不同视角。我需要平衡这一点。”
- 作用: 通过系统性的反思并将其公开化(通常在研究报告的方法论章节或附录中),研究者向读者展示了他们是如何积极地管理自身主观性的。这非但没有削弱研究的可信度,反而通过其诚实和透明,极大地增强了研究的可确认性。它向读者表明,这项研究是由一个有自我意识、负责任的“研究工具”完成的。
-
定性研究的质量控制,是一门围绕“可信性”展开的精深艺术。它通过长期参与和成员核查来确保研究的“内在真实”(可信度);通过厚重描述来构建与读者情境对话的桥梁(可转移性);通过审计追踪来保证过程的透明与稳定(可靠性);并通过审计追踪和深刻的反思性来确认结论的数据根基,管理研究者的主观性(可确认性)。这一整套策略,共同构成了一个严谨、系统且深刻的定性研究质量保障体系,确保其在探寻人类丰富内心世界和社会复杂现象的道路上,能够行稳致远。
8.5 可重复性与可复制性:科学的自我修正机制
在前几节中,我们深入探讨了如何在单个研究项目(无论是定量的还是定性的)内部构建严密的质量控制体系。然而,科学知识的进步并非依赖于孤立的、一次性的研究发现,而是建立在一个累积、验证和自我修正的宏大过程之上。一项研究的真正价值,不仅在于其内部的严谨性,更在于其结果能否被其他独立的科学家所验证和扩展。这就将我们引向了质量控制的更高层面,一个关乎整个科学共同体健康运作的核心议题:可重复性(Reproducibility)与可复制性(Replicability)。
近年来,从心理学、医学到经济学等多个领域,都相继曝出了所谓的**“可重复性危机”(Reproducibility Crisis)或“可复制性危机”(Replication Crisis)**。一系列备受瞩目的研究发现,在后续的独立重复或复制尝试中都未能重现,这严重动摇了公众对科学的信任,也促使科学界进行深刻的自我反思。这场危机凸显了一个事实:即使一项研究在发表时看起来天衣无缝,通过了同行评审,但如果其结果无法被他人重现,那么它对科学知识大厦的贡献就值得怀疑,甚至可能是一块有毒的“砖石”。
因此,理解并积极践行促进可重复性和可复制性的原则,已不再是少数追求极致严谨的科学家的个人选择,而是每一位负责任的研究者都必须承担的时代责任。这不仅是技术层面的操作,更是科学文化和伦理层面的深刻变革。
8.5.1 核心概念的精确辨析
在讨论这一议题时,精确地区分几个关键术语至关重要。尽管在日常交流中有时被混用,但“可重复性”、“可复制性”以及相关的“稳健性”和“可推广性”在方法论上有着截然不同的含义。
A. 可重复性 (Reproducibility):分析过程的透明度
- 定义: 可重复性指的是,使用原始研究作者提供的完全相同的数据、代码和分析流程,另一位研究者能够重新计算出完全相同的结果(例如,相同的统计值、表格、图表)。
- 核心检验对象: 分析过程的透明度和准确性。 它回答的问题是:“作者声称的分析,真的能从他们的数据中得出他们声称的结果吗?”
- 实现基础: 计算的可重复性。这本质上是一个计算问题,而非科学发现的验证。
- 失败的原因:
- 数据或代码未公开。
- 代码存在bug或依赖于特定版本的软件环境。
- 分析步骤的描述过于模糊,关键的决策(如数据清洗规则、变量转换方式)未被记录。
- 简单的人为错误。
- 价值: 可重复性是科学透明度的最低门槛。如果一项计算研究连自身的可重复性都无法保证,那么其结论的有效性就无从谈起。它能够有效地发现分析过程中的诚实性错误,甚至是学术不端行为(如数据造假)。
B. 可复制性 (Replicability):科学发现的稳健性
- 定义: 可复制性指的是,由一个全新的、独立的研究团队,遵循原始研究中描述的方法论,独立收集全新的数据,并对新数据进行分析,能够得出与原始发现相一致的结论。
- 核心检验对象: 原始科学发现的真实性和稳健性。 它回答的问题是:“原始研究揭示的那个现象或效应,是真实存在的,还是仅仅是原始样本或研究情境中的一次偶然?”
- 实现基础: 方法论的清晰性和效应的真实性。这是一个科学验证问题。
- 失败的原因(“复制失败”):
- 原始研究结果是假阳性(第一类错误): 原始发现本身就是一次统计上的偶然,效应并不真实存在。这是“可复制性危机”的核心担忧。
- 发表偏见(Publication Bias): 学术期刊更倾向于发表具有统计显著性(p < 0.05)的“阳性”结果,而大量“阴性”结果被束之高阁(所谓的“文件抽屉问题”)。这导致已发表的文献中效应量被系统性高估,使得后续的复制研究(通常基于更准确的效应量估计)更难重现显著结果。
- 方法论描述不充分: 原始研究的方法部分写得不够详细,导致复制团队无法精确地“复制”其操作。
- 情境依赖性(Context Dependence): 原始效应是真实存在的,但它高度依赖于某些未被识别或报告的特定情境因素(如文化背景、被试群体特征、实验者的微小行为差异)。复制研究在不同的情境下进行,自然无法重现结果。这并不意味着原始研究错了,而是揭示了其结论的边界条件。
- 复制研究的功效不足: 复制研究自身的样本量不够大,没有足够的统计功效来检测一个真实但较小的效应。
- 价值: 可复制性是科学知识得以确立的核心基石。只有那些能够被不同研究者在不同地方、不同时间反复复制的发现,才能被认为是可靠的科学事实。
C. 其他相关概念
- 稳健性 (Robustness): 指当对原始研究的分析方法进行一些细微、合理的改动时(例如,改变数据清洗的规则、使用不同的统计模型、增删一些协变量),研究的主要结论是否依然保持不变。这是对分析方法选择非任意性的检验。
- 可推广性 (Generalizability / External Validity): 指一项研究的结果能够被推广到不同的人群、不同的情境、不同的测量方法或不同的时间的程度。可复制性关注的是在“相同”条件下的重现,而可推广性则关注在“不同”条件下的适用范围。
关系总结:
一项研究首先需要可重复(分析透明),然后其发现在新数据下需要可复制(效应真实),接着其结论需要稳健(对分析细节不敏感),最终我们希望它具有广泛的可推广性(适用范围广)。
8.5.2 促进策略:开放科学运动 (Open Science Movement) 的兴起
面对“可重复性危机”,科学界并未陷入绝望,而是催生了一场深刻的、旨在提升科学研究透明度、诚信度和效率的全球性文化转型——开放科学运动。这场运动倡导通过一系列具体的实践,将科学研究从一个封闭的、基于信任的“黑箱”过程,转变为一个开放的、可验证的、协作的生态系统。
A. 预注册 (Preregistration):在博弈开始前公布规则
预注册是开放科学运动中对抗“可疑研究操作”(Questionable Research Practices, QRPs)的最强力武器之一。
-
定义: 预注册是指研究者在开始数据收集之前(或对于已有数据的探索性研究,在开始正式的假设检验分析之前),将一个详细的研究计划提交到一个公开的、有时间戳的、不可篡改的在线注册平台(如AsPredicted.org, Open Science Framework (OSF))。
-
注册内容: 一个完整的预注册计划应详细说明:
- 研究假设: 清晰、明确地陈述你要检验的主要假设。
- 研究设计: 变量的操作化定义、被试的纳入和排除标准、实验流程等。
- 抽样计划: 目标样本量、抽样方法、停止收集数据的规则。
- 分析计划: 数据清洗和预处理的步骤、变量的转换和合成方式、用于检验每个主要假设的具体统计模型。
-
核心作用:
- 区分“验证性研究”与“探索性研究”: 这是预注册最核心的功能。它清晰地划分了研究中哪些是事先计划好的“假设检验”(验证性),哪些是基于数据观察后产生的“意外发现”(探索性)。两者都有价值,但前者提供了更强的证据支持。
- 防止HARKing(Hypothesizing After the Results are Known,事后择优假设): HARKing是一种严重的研究不端行为,指研究者在看到分析结果后,假装自己一开始就预测到了这个结果,并将其作为研究的主要假设来报告。预注册使得这种“事后诸葛亮”式的行为无所遁形。
- 防止p-hacking(p值操纵): p-hacking指研究者通过不断尝试不同的分析方法(如随意增删数据点、尝试多种统计模型、只报告显著的结果),直到获得一个p值小于0.05的“显著”结果为止。预注册锁定了分析方案,使得这种“数据拷问”变得非常困难,或者至少是透明的。
- 促进思考,提高设计质量: 撰写预注册计划的过程,本身就迫使研究者在研究开始前,对研究的每一个细节进行深入、系统的思考,从而极大地提高了研究设计的质量。
-
注册报告(Registered Reports): 这是预注册的“终极形式”。研究者在数据收集前,仅提交研究的引言、方法和分析计划部分给期刊进行同行评审。如果计划被接受,期刊原则上承诺,无论最终的研究结果是阳性的、阴性的还是模糊的,只要作者严格按照预注册的计划执行了研究,论文都将被发表。这彻底打破了“发表偏见”,激励研究者去研究重要的问题,而非仅仅是那些容易出“漂亮”结果的问题。
B. 开放数据 (Open Data) 与 开放材料 (Open Materials)
这是实现可重复性和促进可复制性的实践基础。
-
定义:
- 开放数据: 指在研究发表后,将研究所依据的原始数据(经过匿名化处理以保护参与者隐私)存放在一个公开可及的在线数据库中(如OSF, Zenodo, Figshare,或机构知识库)。
- 开放材料: 指公开分享研究所使用的所有工具和材料,这可能包括:
- 完整的问卷量表。
- 实验程序中使用的刺激材料(如图片、视频、文本)。
- 详细的实验仪器型号和设置参数。
- 访谈提纲。
- 完整的伦理审查文件和知情同意书模板。
-
价值与作用:
- 实现可重复性: 开放数据和与之配套的开放代码(Open Code/Script),是他人验证你研究可重复性的必要前提。没有这些,可重复性就是一句空话。
- 促进可复制性: 开放材料为其他研究者提供了精确复制你研究方法所需的一切信息,大大提高了复制研究的保真度(fidelity)。
- 加速科学发现: 公开的数据可以被其他研究者用于新的目的,如进行二次分析、Meta分析、或用于教学。这避免了重复性的数据收集工作,最大化了数据的价值。
- 提高数据质量: 知道自己的数据将被公开,会激励研究者在数据收集、整理和注释阶段更加认真细致。
- 增加透明度和信任: 开放数据和材料是对研究过程透明度的最直接承诺,极大地增强了研究结论的公信力。
-
实践考量:
- FAIR原则: 优秀的数据开放实践应遵循FAIR原则——可发现(Findable)、可获取(Accessible)、可互操作(Interoperable)、可重用(Reusable)。这要求数据不仅是公开的,还要有丰富的元数据(metadata)描述、使用开放的格式、有清晰的授权许可。
- 隐私与伦理: 开放数据必须以保护参与者隐私为最高前提。所有可能识别个人身份的信息都必须被彻底移除或进行技术处理(匿名化)。对于高度敏感的数据,可能需要建立一个受控的访问机制。
C. 开放代码 (Open Code) 与 开放工作流 (Open Workflow)
- 定义:
- 开放代码: 分享用于数据处理、分析和可视化的所有计算机代码或脚本(如R, Python, Stata脚本)。
- 开放工作流: 不仅分享代码,还分享整个计算环境和工作流程的信息,例如使用的软件版本、依赖的软件包、随机数种子等,确保他人可以一键复现整个分析环境。这通常通过Docker, Code Ocean等容器化技术或
renv,conda等环境管理工具实现。
- 作用: 开放代码是实现可重复性的“最后一公里”。
- 最佳实践:
- 代码注释: 编写清晰、详尽的注释,解释代码的每一步是做什么的。
- 代码整洁: 遵循良好的编码规范,使代码易于阅读和理解。
- 版本控制: 使用Git等版本控制系统来追踪代码的修改历史。
- 动态文档: 使用R Markdown或Jupyter Notebook等工具,将代码、输出结果和文字解释无缝地整合在一个文档中,生成一份“可执行的论文”。
D. 开放获取 (Open Access, OA)
- 定义: 指研究成果(主要是最终发表的论文)可以被任何人通过互联网免费获取,没有任何订阅壁垒。
- 作用:
- 促进知识传播: 确保全球的研究者、政策制定者、从业者和公众都能无障碍地获取最新的科学知识,打破了知识获取的不平等。
- 提高研究影响力: 开放获取的论文通常有更高的引用率和更广泛的读者群。
- 支持审查与复制: 只有当原始研究论文本身是开放获取时,其他研究者才能方便地获取其方法论细节,从而进行有效的审查和复制尝试。
可重复性和可复制性不仅是一套技术实践,更是一种科学文化的体现。它要求研究者从“成果的生产者”转变为“可信知识的贡献者”,将透明度、谦逊和协作精神置于个人荣誉之上。通过拥抱预注册、开放数据、开放代码和开放获取等开放科学实践,我们不仅能够逐步克服“可重复性危机”,更能构建一个更健康、更高效、更值得信赖的科学未来。这套宏观层面的质量控制机制,与前面讨论的微观层面的研究设计与执行策略相辅相成,共同构成了现代科学研究严谨性的完整图景。
8.6 同行评审:外部质量把关
在科学知识从个体研究者的实验室走向公共知识领域的漫长旅程中,同行评审(Peer Review)扮演着至关重要的“守门人”(Gatekeeper)角色。自17世纪诞生于学术期刊的实践以来,它已成为现代学术出版和科研基金资助体系的基石。如果说前文讨论的质量控制策略大多是研究者内部的、主动的自我约束与规范,那么同行评审则是科学共同体施加的一种外部的、集体的质量把关机制。它旨在通过领域内专家的匿名或公开审查,对一项研究的价值和严谨性进行独立评估,从而维护整个学术文献的质量标准。
尽管同行评审制度饱受争议且并非完美无瑕,但至今仍是科学界筛选、验证和改进研究成果最核心、最被广泛接受的程序。理解其功能、正视其挑战、并积极参与其改革,是每一位研究者融入学术共同体、并为其健康发展贡献力量的必修课。
8.6.1 同行评审的核心功能
同行评审并非旨在全盘否定或吹捧一篇稿件,其理想的功能是一个建设性的、旨在提升科学质量的对话过程。其核心功能可以概括为以下几个方面:
-
质量筛选与过滤 (Filtration):
- 核心任务: 帮助期刊编辑判断一篇稿件是否达到了该期刊的发表标准。这包括评估研究是否解决了重要问题、是否具有足够的原创性、是否存在严重的方法论缺陷或伦理问题。
- 作用: 阻止那些质量低下、存在明显谬误、或毫无新意的研究进入正式的学术文献库,从而节省广大读者的宝贵时间,维护学术记录的整体可信度。
-
改进与提升 (Improvement):
- 核心任务: 为作者提供具体的、建设性的反馈意见,帮助他们改进稿件的质量。这可能是同行评审最重要、最具有建设性的功能。
- 具体方面: 评审人可能会建议作者:
- 补充额外的实验或分析来增强结论的说服力。
- 澄清模糊的概念定义或逻辑论证。
- 更全面地回顾相关文献,将研究置于更广阔的学术背景中。
- 改进图表的呈现方式,使其更清晰易懂。
- 修正统计分析中的错误或不当之处。
- 更审慎、更准确地解读研究结果,避免过度推广。
- 作用: 一个高质量的评审过程,即使最终稿件被拒,也能让作者受益匪-浅。它将个人化的研究工作,转化为一个由共同体智慧参与打磨的协作过程。
-
原创性与重要性评估 (Assessment of Originality and Significance):
- 核心任务: 评估研究的“新颖性”(是否提出了新的观点、方法或发现了新的现象)和“重要性”(其发现在多大程度上能够推动该领域的知识边界,或具有潜在的应用价值)。
- 作用: 这有助于期刊定位其发表内容,确保其对学术界具有吸引力和影响力。同时,也引导科研资源流向更具开创性和影响力的研究方向。
-
方法论严谨性审查 (Methodological Scrutiny):
- 核心任务: 动用评审人的专业知识,对研究的设计、数据收集、分析方法和结果解释进行深入的技术性审查。这是评审过程中技术含量最高的部分。
- 审查内容: 是否存在前文讨论的各种偏差?样本量是否充足?统计方法是否得当?定性研究的可信性策略是否到位?结论是否超越了数据的支持范围?
- 作用: 这是防止含有严重方法论缺陷的研究得以发表的关键防线。
8.6.2 同行评审的内在挑战与局限性
尽管同行评审在理想状态下功能强大,但在现实操作中,它面临着诸多深刻的、系统性的挑战,这些挑战有时会严重削弱其作为质量控制机制的有效性。
-
评审过程的缓慢与低效 (Slowness and Inefficiency):
- 问题: 从投稿到最终发表,一篇论文经历多轮评审可能耗时数月甚至数年。这严重拖慢了科学知识传播的速度,尤其是在快速发展的领域。
- 原因: 寻找合适且愿意审稿的专家越来越难。评审工作通常是无偿的志愿服务,在学者日益繁重的教学和科研压力下,很难保证及时、高质量的评审。
-
评审过程中的偏见 (Bias in the Review Process):
- 同行评审是一个由人类执行的过程,因此无法完全摆脱人类固有的认知偏见。
- 发表偏见 (Publication Bias): 这是最著名也最有害的偏见。评审人和编辑普遍更倾向于那些报告了“阳性”结果(即发现了显著效应)的研究,而对“阴性”结果(即未发现显著效应)的研究缺乏兴趣。这导致已发表的文献充满了可能被高估的效应,并严重阻碍了科学的自我修正。
- 确认偏见 (Confirmation Bias): 评审人可能更容易接受那些与自己已有理论观点一致的研究,而对那些挑战主流范式、具有颠覆性创新的研究持有更苛刻、更具敌意的态度。这可能扼杀真正具有突破性的思想。
- 声誉偏见 (Prestige Bias): 评审人可能会因为作者的知名度或其所属机构的声望而影响其判断(无论是在单盲评审中,还是通过参考文献猜出作者身份)。
- 地域与语言偏见: 对来自非英语国家或不知名研究机构的稿件,可能存在潜在的歧视。
-
评审人能力与精力的局限性 (Limited Reviewer Expertise and Effort):
- 专业知识不匹配: 现代科学高度跨学科,一篇稿件可能涉及多种复杂的方法。期刊编辑很难总能找到对稿件所有方面都具备精深知识的评审人。一个统计专家可能无法评判研究的理论贡献,反之亦然。
- 时间投入不足: 如前所述,由于评审是无偿的,许多评审人无法或不愿投入足够的时间进行深入、细致的审查。这可能导致一些深层次的问题(如数据造假、分析流程中的微妙错误)被轻易放过。
- 未能发现学术不端: 同行评审通常无法接触到原始数据,因此对于巧妙的数据伪造、篡改或p-hacking等不端行为,几乎无能为力。它主要是一个基于信任的系统。
8.6.3 同行评审的改革与未来发展
为了应对上述挑战,学术界和出版界正在积极探索一系列改革措施,旨在提高同行评审过程的透明度、公正性、效率和有效性。
-
评审模式的创新:
- 双盲评审 (Double-Blind Review): 作者和评审人互不知晓对方身份。这是目前许多人文社科和部分自然科学期刊采用的标准,旨在减少声誉偏见。然而,在一些小领域,通过研究主题和参考文献,评审人仍可能猜出作者身份。
- 开放式同行评审 (Open Peer Review, OPR): 这是一个涵盖多种实践的“总称”,其核心是增加透明度。具体形式包括:
- 公开评审人身份 (Open Identity): 评审报告与评审人姓名一同发表。这可以激励评审人提供更负责任、更具建设性的意见,但同时也可能让他们因担心得罪同行而不敢提出尖锐批评。
- 公开评审报告 (Open Reports): 无论评审人身份是否公开,将所有评审意见、作者的回复以及修订历史,与最终发表的论文一同公开。这使得整个学术对话过程对读者透明,有助于读者更全面地评判研究。
- 开放参与 (Open Participation): 在论文发表后,允许更广泛的学术社区成员(而不仅仅是期刊指定的几位评审人)对其进行评论和评估(有时被称为“发表后评审”)。
- 协作式评审 (Collaborative Review): 允许评审人之间相互讨论,或者评审人与作者进行直接对话,共同以协作的方式来改进稿件,而非传统的“背对背”审查。
-
技术与平台的赋能:
- 预印本服务器 (Preprint Servers): 平台如arXiv, bioRxiv, SocArXiv等,允许作者在同行评审之前,就将稿件的“预印本”公开发布。这极大地加速了科研成果的传播速度,并允许研究在正式发表前就接受整个社区的非正式审查。它将“传播”功能与“认证”功能(由期刊的同行评审完成)分离开来。
- AI辅助评审: 利用人工智能工具来辅助同行评审过程,例如,检查稿件是否符合期刊的格式要求、进行查重、识别统计分析方法是否恰当、甚至检查是否存在p-hacking的迹象。这可以将评审人从一些重复性的检查工作中解放出来,更专注于评估研究的科学内核。
-
激励与认可机制的变革:
- 认可评审工作: 越来越多的平台(如Publons)和机构开始记录和认证学者的评审工作,并将其作为学术贡献的一部分,在职称评定和项目申请中予以考虑。
- 评审报酬: 虽然仍有争议,但一些期刊或平台开始尝试为高质量的评审工作提供小额报酬或权益(如订阅折扣),以激励学者投入更多精力。
同行评审作为科学的外部质量控制机制,正处在一个深刻的转型期。它远非完美,但其核心精神——科学发现需要经过独立的、专业的、批判性的审查——是科学之所以能够自我修正、不断进步的根基所在。未来的同行评审,很可能会是一个更加透明、多元、高效、协作和技术赋能的生态系统。作为研究者,我们的责任不仅是作为作者去应对评审,更是作为评审人,以高度的责任心和专业精神,为维护我们共同的知识殿堂贡献一份严谨而公正的力量。
结语:对严谨性的不懈追求
我们踏上了一段系统性的旅程,探索了科学研究“质量控制”这一核心议题的广阔疆域。我们从辨析研究质量的核心敌人——系统性偏差与随机误差——出发,进而深入到定量研究和定性研究这两种不同范式内部,详细解构了它们各自为保障研究可靠性与有效性所构建的精妙防御体系。我们看到了,无论是定量研究中对客观性追求极致的随机化、盲法与标准化,还是定性研究中对深度理解孜孜以求的三角验证、成员核查与反思性,它们都源于同一种核心精神:以一种系统的、透明的、自我批判的方式,不断审视和加固从研究问题到最终结论的每一个逻辑环节。
随后,我们的视野从单个研究项目内部,拓展至整个科学知识的生产与验证生态。在可重复性与可复制性的讨论中,我们直面了当代科学的“自我修正”机制所面临的深刻挑战,并看到了以**“开放科学”为旗帜的改革浪潮如何通过预注册、开放数据和开放材料等实践,为重塑科学的透明度与公信力注入新的活力。最后,我们审视了同行评审**这一传统的外部质量把关机制,理解了它的重要功能、内在局限以及充满希望的未来演进方向。
至此,一个多层次、全方位的质量控制框架已然呈现:它既包含研究者内在的、方法论层面的自我约束,也涵盖了科学共同体外在的、制度层面的集体监督。
我们必须深刻认识到,质量控制并非一份可以按部就班完成的僵化清单,更不是为了满足期刊编辑或学位委员会要求而履行的表面文章。它的本质,是一种内化于心的思维习惯,一种对严谨性永不满足、对不确定性保持谦逊、对可能性错误时刻警惕的科学气质。它要求我们在研究的每一个瞬间,都扮演着自己最严苛的批评者。
对研究质量的不懈追求,其意义远超于单个研究项目的成败。首先,这是对研究参与者的伦理承诺。他们投入了宝贵的时间、分享了个人信息甚至承担了潜在风险,我们有责任确保他们的贡献被用于产生可信、有价值的知识,而非因低劣的设计或操作而付诸东流。其次,这是对整个科学共同体的责任。每一个公开发表的研究,都将成为他人研究的基石。一块有缺陷的砖石,可能会导致后续建立于其上的整个知识分支发生动摇。最后,这是对社会公众信任的守护。在信息爆炸、真伪难辨的时代,科学之所以仍是我们认识世界最可靠的灯塔,其根基正是建立在它拥有一套严格的、自我修正的质量控制体系之上。每一次对研究质量的妥协,都是对这一社会契约的侵蚀。