用 SPL 编写阿里云 FC2.0 函数
前言
在数字化转型持续加速的背景下,企业越来越多地将业务逻辑以服务化方式部署至云端。阿里云函数计算(Function Compute,简称FC)作为一种无服务器计算平台,屏蔽了底层资源运维的复杂性,使开发者能够专注于核心逻辑的开发与交付。只需上传代码,即可通过HTTP请求或事件驱动灵活触发函数执行,实现弹性伸缩、按需计费的函数式计算能力。
在实际应用中,函数计算往往需要处理复杂的数据处理任务,如多源数据的汇聚、清洗与分析。然而,使用传统Java编写这类逻辑不仅代码冗长、调试困难,还缺乏灵活性,微小的逻辑变更通常也需要重新构建、打包并上传整个函数代码包。
SPL(Structured Process Language)专注于结构化数据处理,具备简洁的语法、丰富的计算函数,特别适合表达各类复杂的数据逻辑。更重要的是,SPL支持将数据处理逻辑以外部脚本形式运行,修改逻辑时只需替换脚本文件,无需重新构建或部署函数代码包,即可在下一次调用时自动生效。这种“轻量级热切换”特性,非常契合函数计算轻量、快速迭代的特性,有效提升了云端函数逻辑的可维护性与敏捷性。
此外,SPL原生支持多种数据源(如支持JDBC的数据源、NAS文件、JSON等),并具备可视化分步调试能力,是Serverless架构中应对动态数据逻辑、数据服务编排的高效利器。
本文将介绍如何结合Micronaut框架与SPL脚本,以Fat-JAR方式部署至阿里云FC2.0,构建一个通过RESTful API调用、支持逻辑热更新的无服务器计算服务。示例将展示SPL如何访问并分析MySQL数据库和NAS文件系统,帮助读者快速构建可扩展、易维护的Serverless数据服务方案。
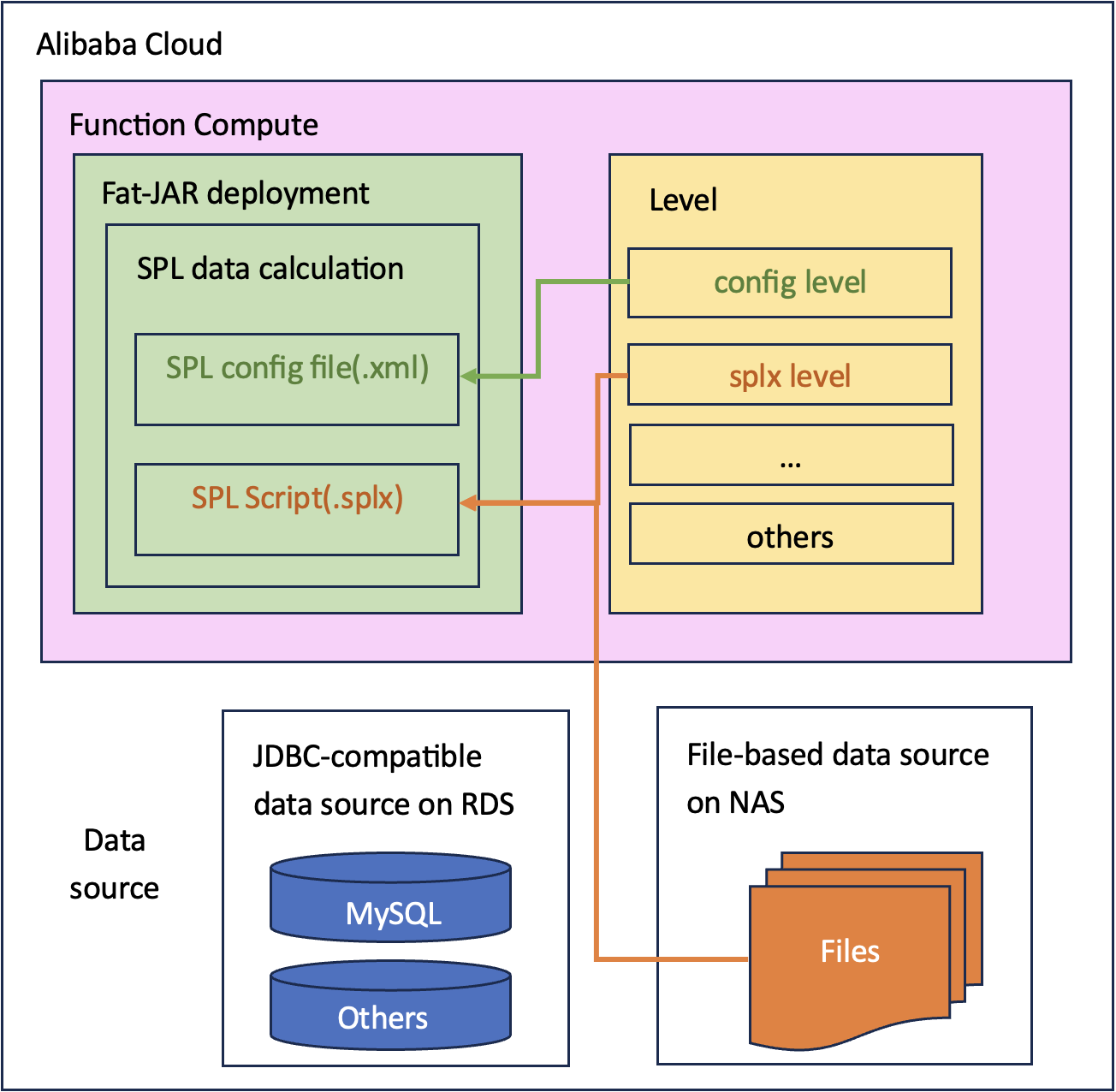
SPL在阿里云FC中的架构图
函数开发与部署
创建项目
使用 Micronaut CLI 快速创建 Maven 项目:
mn create-app micronaut-spl --build maven创建完成后,可在集成开发环境(如 IntelliJ IDEA)中打开项目继续开发。
集成SPL
添加依赖
在 pom.xml 中引入 SPL 与数据库驱动:
<dependency><groupId>com.scudata.esproc</groupId><artifactId>esproc</artifactId><version>20250605</version>
</dependency><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><version>8.3.0</version>
</dependency>提示:中央仓库的更新频率有限,推荐从[SPL 下载地址]下载标准版,并通过私有Maven仓库同步更新。
相关jar包位于安装目录esProc/lib/,其中两个基础jar包为:
· esproc-bin-xxxx.jar:SPL 引擎及 JDBC 驱动
· icu4j-60.3.jar:国际化支持库
准备SPL配置文件
raqsoftConfig.xml 为 SPL 的核心配置文件,负责数据源定义、脚本路径管理等。本文中RDS MySQL数据源与脚本路径的示例配置如下:
……
<DBList encryptLevel="0"><DB name="rds_mysql"><property name="url" value="jdbc:mysql://rm-xxx.mysql.rds.aliyuncs.com:3306/spltest?useCursorFetch=true"></property><property name="driver" value="com.mysql.cj.jdbc.Driver"></property><property name="type" value="10"></property><property name="user" value="dms_user"></property><property name="password" value="password"></property><property name="batchSize" value="0"></property><property name="autoConnect" value="true"></property><property name="useSchema" value="false"></property><property name="addTilde" value="false"></property><property name="caseSentence" value="false"></property></DB>
</DBList>
<esProc>
……<splPathList><splPath>/opt</splPath></splPathList>
……
</esProc>
……特别注意:需加上useCursorFetch=true,否则JDBC驱动可能将整个结果集加载至内存,容易在 FC 的内存限制下导致连接断开或错误。
与传统项目部署方式不同,这里我们先将raqsoftConfig.xml打成zip包(raqsoftConfig.xml.zip),以供后续作为自定义层上传使用。
SPL 通用接口实现
使用 SPL 提供的 JDBC 接口,在 Micronaut 中构建统一的函数调用入口。通过 HTTP POST 请求传入参数,执行指定 SPL 脚本,并将结果以 JSON 格式返回。
该接口接收两个参数:
· splxName:脚本文件名(不带扩展名)
· jsonParam:SPL脚本所需参数(JSON字符串)
返回值中包括状态码、消息提示及脚本执行结果数据。
package micronaut.spl;import io.micronaut.http.annotation.*;
import io.micronaut.http.MediaType;import java.sql.*;
import java.util.*;@Controller("/spl")
public class SPLExecutionController {@Post(uri = "/call", consumes = MediaType.APPLICATION_JSON, produces = MediaType.APPLICATION_JSON)public Map<String, Object> execute(@Body Map<String, String> request) {Map<String, Object> response = new HashMap<>();String splxName = request.get("splxName");String jsonParam = request.get("jsonParam");if (splxName == null || splxName.isBlank()) {response.put("code", 400);response.put("message", "Missing splxName");return response;}try {Class.forName("com.esproc.jdbc.InternalDriver");try (Connection con = DriverManager.getConnection("jdbc:esproc:local://?config=/opt/raqsoftConfig.xml");CallableStatement st = con.prepareCall("call " + splxName + "(?)")) {if (jsonParam != null && !jsonParam.isEmpty()) {st.setString(1, jsonParam);} else {st.setNull(1, Types.VARCHAR);}boolean hasResult = st.execute();List<List<Object>> allResults = new ArrayList<>();while (true) {if (hasResult) {try (ResultSet rs = st.getResultSet()) {ResultSetMetaData metaData = rs.getMetaData();int columnCount = metaData.getColumnCount();List<Object> currentResult = new ArrayList<>();while (rs.next()) {if (columnCount == 1) {currentResult.add(rs.getObject(1));} else {Map<String, Object> row = new LinkedHashMap<>();for (int i = 1; i <= columnCount; i++) {row.put(metaData.getColumnLabel(i), rs.getObject(i));}currentResult.add(row);}}if (!currentResult.isEmpty()) {allResults.add(currentResult);}}}if (!st.getMoreResults() && st.getUpdateCount() == -1) {break;}hasResult = true;}if (!allResults.isEmpty()) {response.put("code", 200);response.put("message", "success");response.put("data", allResults.size() == 1 ? allResults.get(0) : allResults);} else {response.put("code", 404);response.put("message", "No result data");}}} catch (Exception e) {e.printStackTrace();response.put("code", 500);response.put("message", "Execution failed: " + e.getMessage());}return response;}
}打包项目后,再打成zip包(micronaut-spl-0.1.jar.zip)
上传部署Fat-JAR
在阿里云 FC 控制台中创建函数,推荐配置如下:
· 创建方式:使用自定义运行时创建
· 运行环境:Java 21
· 上传方式:ZIP 上传(micronaut-spl-0.1.jar.zip)
· 启动命令:java -jar micronaut-spl-0.1.jar
· 认证方式:无需认证(测试用)
点击创建后,即可完成函数部署。
添加配置层
在函数详情中点击“编辑层”,上传打包好的 raqsoftConfig.xml.zip,新建名为 config 的自定义层。
编写SPL脚本
使用 MySQL 表数据计算
在阿里云 RDS 中创建 MySQL 实例及 orders 表,导入 TPC-H 示例数据(建库建表和导入过程略)。以下脚本 rds-mysql.splx 演示如何按订单年份与状态分组统计订单总额:
| A | |
| 1 | =connect("rds_mysql") |
| 2 | =A1.cursor@x("SELECT O_ORDERDATE, O_ORDERSTATUS, O_TOTALPRICE FROM ORDERS") |
| 3 | =A2.groups(year(O_ORDERDATE):year,O_ORDERSTATUS:status;sum(O_TOTALPRICE):amount) |
将脚本打zip包后,添加并创建自定义层(splx),即可在/opt下访问到该脚本。
调用示例
请求行
POST https://sss-fff-xxx.cn-xxx.fcapp.run/spl/call
Content-Type: application/json请求体
{"splxName": "rds-mysql","jsonParam": ""
}
返回
{"code": 200,"data": [{"year": 1992,"status": "F","amount": 34330674052.43},{"year": 1993,"status": "F","amount": 34340410079.03},{"year": 1994,"status": "F","amount": 34416369052.97},{"year": 1995,"status": "F","amount": 6614961429.26},{"year": 1995,"status": "O","amount": 20822054361.33},{"year": 1995,"status": "P","amount": 7109117393.01},{"year": 1996,"status": "O","amount": 34609364760.86},{"year": 1997,"status": "O","amount": 34373633413.04},{"year": 1998,"status": "O","amount": 20212721905.53}],"message": "success"
}使用 NAS 文件系统
通过阿里云函数配置挂载 NAS 路径(如 /mnt/nas),可在 SPL 中直接读写该路径下的文件,实现持久化与共享。
以下为 w.splx(写)和 r.splx(读)两个脚本,模拟数据生成与读取处理过程。
w.splx如下:
| A | |
| 1 | =path=json(jsonParams).path |
| 2 | =connect("rds_mysql") |
| 3 | =A2.cursor@x("SELECT O_ORDERDATE, O_ORDERSTATUS, O_TOTALPRICE FROM ORDERS") |
| 4 | =file(path/"orders.btx").export@b(A3) |
| 5 | return "btx exported." |
r.splx如下:
| A | |
| 1 | >p=json(jsonParam),path=p.path,n=p.n,m=p.m |
| 2 | =file(path/"orders.btx").cursor@b() |
| 3 | =A2.skip(n) |
| 4 | =A2.fetch(m) |
| 5 | >A2.close() |
| 6 | return A4 |
写脚本,通过数据库游标读取MySQL实例中的orders表,并写入orders.btx文件(path可使用配置的NAS路径,实现持久化或与其他服务共享数据)。
读脚本,通过读取指定路径文件的游标,跳过前n条记录,展示接下来的m条记录。
也可将脚本文件本身存放在 NAS 中,配合 raqsoftConfig.xml 中增加路径:
…
<splPathList><splPath>/opt;/mnt/nas</splPath>
</splPathList>
…写入调用示例
请求行
POST https://sss-fff-xxx.cn-xxx.fcapp.run/spl/call
Content-Type: application/json
请求体
POST https://sss-fff-xxx.cn-xxx.fcapp.run/spl/call
Content-Type: application/json返回
{"splxName": "w","jsonParam": "{path:/mnt/nas/}"
}
读取调用示例
请求行
POST https://sss-fff-xxx.cn-xxx.fcapp.run/spl/call
Content-Type: application/json
请求体
{"splxName": "r","jsonParam": "{path:/mnt/nas/,n:99,m:2}"
}返回
{"code": 200,"data": [{"O_ORDERDATE": "1992-12-16","O_ORDERSTATUS": "F","O_TOTALPRICE": 198800.71},{"O_ORDERDATE": "1994-02-17","O_ORDERSTATUS": "F","O_TOTALPRICE": 2519.40}],"message": "success"
}
业务逻辑变更
我们将“使用 MySQL 表数据计算”的“按订单年份与状态分组统计订单总额”改为“按订单年月与状态分组统计订单总额”,只需要将 A3 中的 year(O_ORDERDATE):year 改为 month@y(O_ORDERDATE):YearMonth 即可。由于 SPL 支持将数据逻辑以外部脚本形式运行,此类修改无需重新构建和部署函数代码包,只需更新脚本内容即可在下一次函数调用时自动生效。这种“轻量级热切换”方式完美契合 Serverless 架构短生命周期、按需执行的特点,显著提升了云端数据服务的响应速度与维护效率,尤其适合频繁调整的数据分析类场景。
总结
借助 Micronaut 的轻量级框架特性与 SPL 的灵活脚本执行能力,我们成功构建了一个具备结构化数据处理能力的 Serverless 应用,并以 Fat-JAR 方式部署至阿里云函数计算 FC2.0。函数启动后可通过 REST 接口按需触发,访问 MySQL 或 NAS 等多种数据源,执行复杂的计算逻辑。
相比传统 Java 开发,SPL 显著简化了数据处理过程,使业务逻辑更清晰、更易维护。尤其在 Serverless 架构下,SPL 的“脚本热切换”能力无需重构或重新部署函数,即可在下次调用中自动生效,极大提升了系统的灵活性和运维效率。结合 NAS 文件系统,还能实现函数之间的数据共享与持久化,满足更多元的业务场景需求。
这种架构适用于需要快速迭代、规则频繁调整的数据服务场景,是企业在 Serverless 架构下构建高效、可扩展数据计算服务的有力方案。