基于YOLO8的番茄成熟度检测系统(数据集+源码+文章)
文末附下载地址
1.系统开发的目的
近年来,随着现代农业对智能化与精准化需求的不断提升,番茄作为全球广泛种植的重要经济作物,其成熟度判定直接关系到采摘效率、产品品质及市场价值。传统成熟度检测主要依赖人工经验,存在主观性强、效率低下以及大规模种植场景下难以实时覆盖等问题,极易导致采收时机不当、果实损耗增加,影响整体生产效益。为应对这一挑战,本研究基于先进的YOLOv8目标检测模型,致力于开发一套高效、准确的番茄成熟度智能检测系统。YOLOv8凭借其卓越的实时性能、多尺度识别能力以及优异的泛化性,可精准区分番茄的未熟、成熟与过熟状态,有效克服复杂田间环境下的光照变化、遮挡及果实重叠等干扰因素。该系统的实现不仅大幅提升了番茄采收的自动化水平,降低对人工的依赖,减少果实损失,还有助于推动农业生产向数据驱动、智能决策转型,进一步优化资源利用效率,增强农业竞争力,为智慧农业的发展提供关键技术支撑。
2.YOLO8网络
YOLOv8的整体架构依然遵循了YOLO系列经典的 Backbone(骨干网络) - Neck(颈部) - Head(检测头) 设计范式,但每个部分都进行了显著升级。
2.1 Backbone(骨干网络)
骨干网络负责从输入图像中提取多层次的特征图。YOLOv8的Backbone是在YOLOv5的CSPDarknet基础上进化而来。
-
核心组件:C2f模块
- YOLOv8用 C2f (Cross Stage Partial fractional) 模块全面替代了YOLOv5中的 C3 模块。
- C2f 的设计灵感来源于更高效的梯度流思想。它借鉴了ELAN(Efficient Layer Aggregation Network,来自YOLOv7)的思想,通过更多的分支跨层连接来丰富梯度信息。
- 与C3模块相比,C2f模块在结构上包含了更多的短路连接(shortcut)和更多的并行卷积分支,在不显著增加计算成本的前提下,获取了更丰富的特征表达,提升了模型的精度。
-
SPPF(Spatial Pyramid Pooling - Fast): 继续使用了YOLOv5中的SPPF模块,用于将不同尺度的特征图进行池化并融合,从而增强网络对不 同大小目标的感受野。
总结:Backbone的关键创新在于用梯度流更丰富的C2f模块替换了C3模块,提升了特征提取能力。
2.2 Neck(颈部)
颈部网络负责对Backbone提取的特征进行进一步融合和分发,为检测头提供强语义且多尺度的特征图。
- 结构:PAN-FPN(Path Aggregation Network + Feature Pyramid Network)
- YOLOv8继续使用了YOLOv5和YOLOv7中成熟的PAN-FPN结构。这是一种“自顶向下”和“自底向上”的双向融合路径,能够将深层的语义信息与浅 层的定位信息有效结合。
- 创新点:
- YOLOv8在Neck部分同样使用了最新的 C2f模块 来代替原有的C3模块,使得特征融合的过程也更加充分和高效。
- 其连接方式和卷积模块的调整使得特征金字塔的构建更加优化。
总结:Neck部分的核心改进是同样引入了C2f模块,增强了多尺度特征融合的能力。
2.3 Head(检测头)
这是YOLOv8变化最大、最具创新性的部分,它彻底移除了YOLO系列沿用多年的“Anchor-Based(基于锚框)”机制。
-
Anchor-Free(无锚框)
- YOLOv5和YOLOv7都是Anchor-Based的,需要预先设定一大堆不同大小、比例的锚框(anchor boxes),模型负责预测这些锚框的偏移量和置信度。
- YOLOv8转向了Anchor-Free范式。检测头直接预测目标框的中心点距离网格左上角的偏移量以及宽高。这简化了训练过程,省去了聚类Anchor和设计Anchor超参数的繁琐步骤,同时也减少了对初始框设计的依赖。
-
解耦头(Decoupled Head)
- YOLOv5使用的是耦合头(Coupled Head),即用一个卷积同时预测分类和回归(边框)结果。
- YOLOv8采用了解耦头,将分类(Class)和回归(Box)任务分离开,使用两个不同的分支进行预测。这种做法借鉴了更先进的检测器(如RetinaNet),让两个任务各司其职,避免了任务间的冲突,通常能带来精度上的提升。
-
损失函数
- 分类损失(Class Loss): 通常使用二元交叉熵(BCE Loss),支持多标签分类(一个目标可以属于多个类别)。
- 回归损失(Box Loss): 使用了 DFL(Distribution Focal Loss) + CIoU Loss 的组合。
- DFL: 让网络更快地聚焦于目标边界附近概率分布的学习,提升回归精度。
- CIoU: 考虑了重叠面积、中心点距离和长宽比的回归损失函数,比传统的IoU Loss收敛更好。
总结:Head部分从Anchor-Based变为Anchor-Free,并采用了解耦头设计和更先进的DFL+CIoU损失函数,这是其性能飞跃的关键。
2.4 YOLOv5、YOLOv7、YOLO8对比
| 特性 | YOLOv5 | YOLOv7 | YOLOv8 | 优势和意义 |
|---|---|---|---|---|
| Head架构 | 耦合头 (Anchor-Based) | 解耦头 (Anchor-Based) | 解耦头 (Anchor-Free) | YOLOv8: 简化设计,免调Anchor超参,训练更简单直接,精度更高。 |
| Backbone | CSPDarknet + C3模块 | ELAN架构 (高效层聚合) | CSPDarknet变体 + C2f模块 | YOLOv8: C2f在C3基础上引入更多分支,梯度流更丰富,特征提取能力更强。 |
| Neck | PAN-FPN + C3模块 | PAN-FPN + ELAN模块 | PAN-FPN + C2f模块 | YOLOv8: 颈部特征融合也受益于C2f模块,融合更 充分。 |
| 损失函数 | CIoU Loss | CIOU Loss | DFL + CIoU Loss | YOLOv8: DFL让边界框定位更加精确,回归性能显著提升。 |
| 训练策略 | 较为传统 | "可训练袋"策略,模型缩放 | 更先进的训练配方 (Mosaic, LR等) | YOLOv8 & v7: 都使用了非常先进的 训练技巧,但v8的配方可能更优。 |
| 任务支持 | 检测、分割 | 检测、分割、姿态 | 检测、分割、姿态、分类 | YOLOv8: 官方原生支持图像分类任务,成为一个统一 的视觉框架。 |
| 易用性 | 非常高 | 高 | 极高 | YOLOv8: 提供极其简洁的API(如model.predict()),用户体验极佳,部署生态完善。 |
2.5 核心总结
- 架构现代化: YOLOv8吸收并融合了YOLOv5(工程化优秀)、YOLOv6(Rep结构)、YOLOv7(ELAN, 可训练袋)和最新检测器(如RT-DETR的DFL)的优点,进行了彻底的现代化重构。
- Anchor-Free是方向: 摒弃Anchor机制代表了目标检测领域的发展趋势,使得模型更简洁、更易于训练和调优。
- 精度与速度的平衡: 在几乎相同的推理速度下,YOLOv8的精度(mAP)相比YOLOv5和YOLOv7有显著提升,尤其是在小目标检测上。
- 开发者友好: Ultralytics公司将其与YOLOv5的生态完美结合,提供了从训练到部署的完整、高效且易于使用的工具链,极大地降低了使用门槛。
3.系统设计
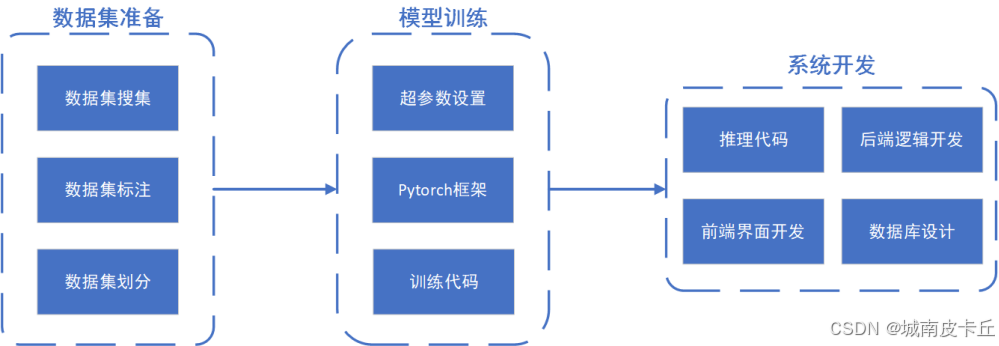
3.1 系统总体设计
系统开发设计主要包含三个步骤:(1)数据集准备(2)模型训练(3)系统开发。首先准备电动车进电梯的图片数据集并利用labelimg标注软件对图片中的电动车进行标注,之后采用YOLO8目标检测网络对图片数据集进行训练,得到训练好的模型权重,最后编写模型推理代码并分别开发前端、后端,最终完成整套系统的开发。
3.2 数据集
使用的番茄成熟度数据集为自制数据集。数据集制作的具体步骤是,实地采集番茄图片,把图片划分好训练集(1014张图片)验证集(127张图片)。使用labelme对图片进行一一标注。图片均为实拍原图,番茄果实均为生长在果树之上,不含数据增强的图片。数据集共分为两类:成熟果实、未成熟果实数据集格式保存为YOLO格式,并按80%、20%的比例划分为训练集和验证集。数据集样张如下图所示。

数据集涉及到的数据增强方法主要有以下几种:
(1)对原图做数据增强
①像素级:HSV增强、旋转、缩放、平移、剪切、透视、翻转等
②图片级:MixUp、Cutout、CutMix、Mosaic等
(2)对标签做同样的增强
①变换后的坐标偏移量
②防止标签坐标越界
除了上述最基本的数据增强方法外,还使用了 Mosaic 数据增强方法,其主要思想就是将4张图片进行随机裁剪、缩放后,再随机排列拼接形成一张图片,实现丰富数据集的同时,增加了小样本目标,提升网络的训练速度。在进行归一化操作时会一次性计算4张图片的数据,因此模型对内存的需求降低。

3.3 模型训练
将标注后的数据集划分为训练集和验证集后,开始对我们搭建的yolo8深度学习网络进行训练。一般为了缩短网络的训练时间,并达到更好的精度,一般加载预训练权重进行网络的训练。而yolov8提供了多个预训练权重,我们可以对应我们不同的需求选择不同版本的预训练权重。预训练权重越大,训练出来的精度就会相对来说越高,但是其检测的速度就会越慢。本次训练自己的数据集用的预训练权重为yolov8s。我们借助ultralytics框架对yolo8模型进行训练,模型训练代码如下:
from ultralytics import YOLO# Load a model
# model = YOLO('./data/fall.yaml') # build a new model from YAML
model = YOLO('yolov8s.pt') # load a pretrained model (recommended for training)
# model = YOLO('./fall.yaml').load('yolov8n.pt') # build from YAML and transfer weights# Train the model
if __name__=='__main__':model.train(data='./data.yaml', epochs=250, batch=8,workers=0,imgsz=640)data.yaml 文件示例:
names:
- Ripped
- Unripped
nc: 2
path: E:\datasets\det_tomato_ripe
train: E:\streamlit_yolo_copyright_spec2_project_dataset_train\det_tomato_ripe_yolo8_streamlit_spec2\train\train\images
val: E:\streamlit_yolo_copyright_spec2_project_dataset_train\det_tomato_ripe_yolo8_streamlit_spec2\train\val\images
运行 python train.py 即可开始训练。训练结果和模型权重会保存在 runs/train目录下
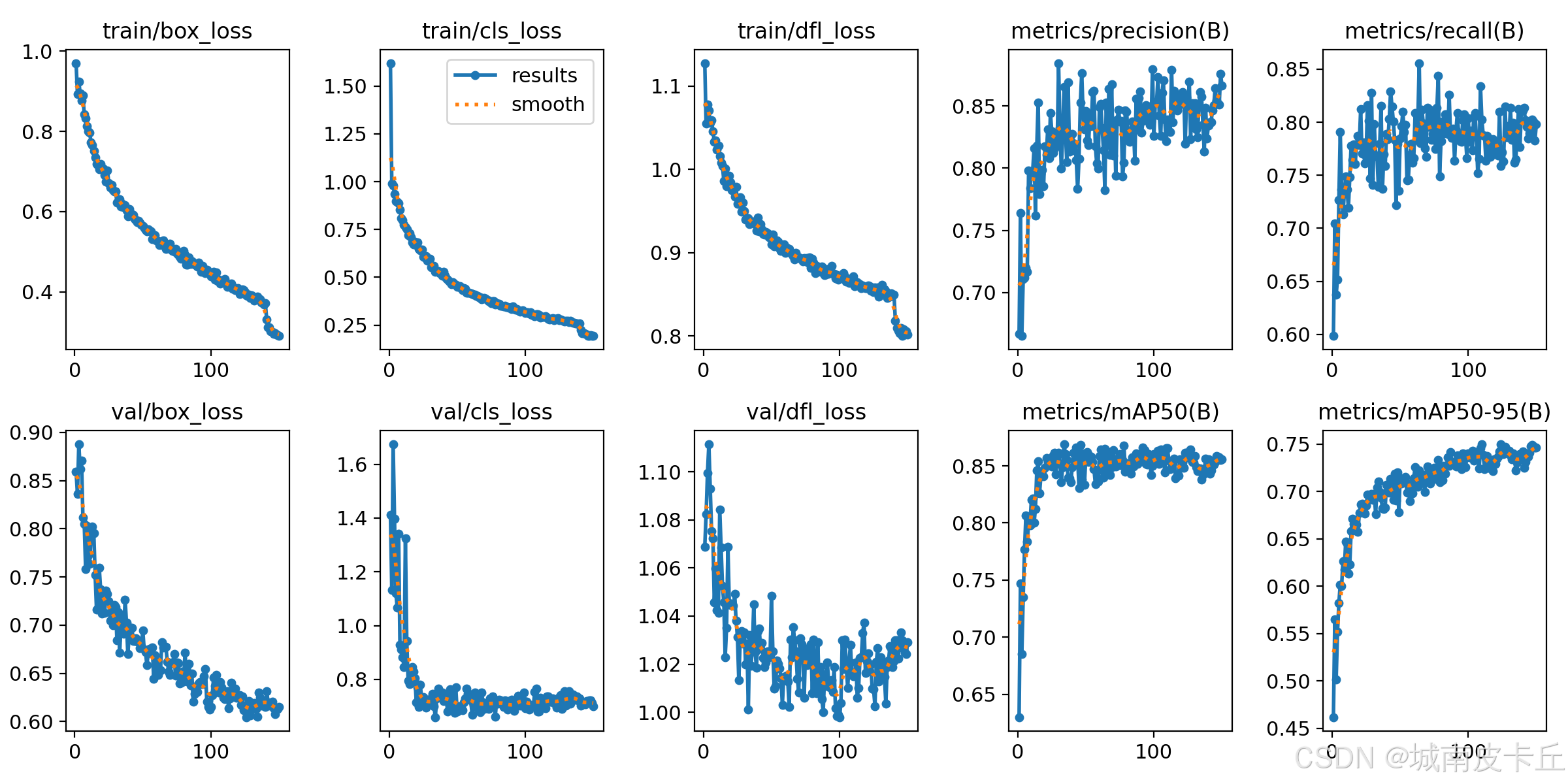
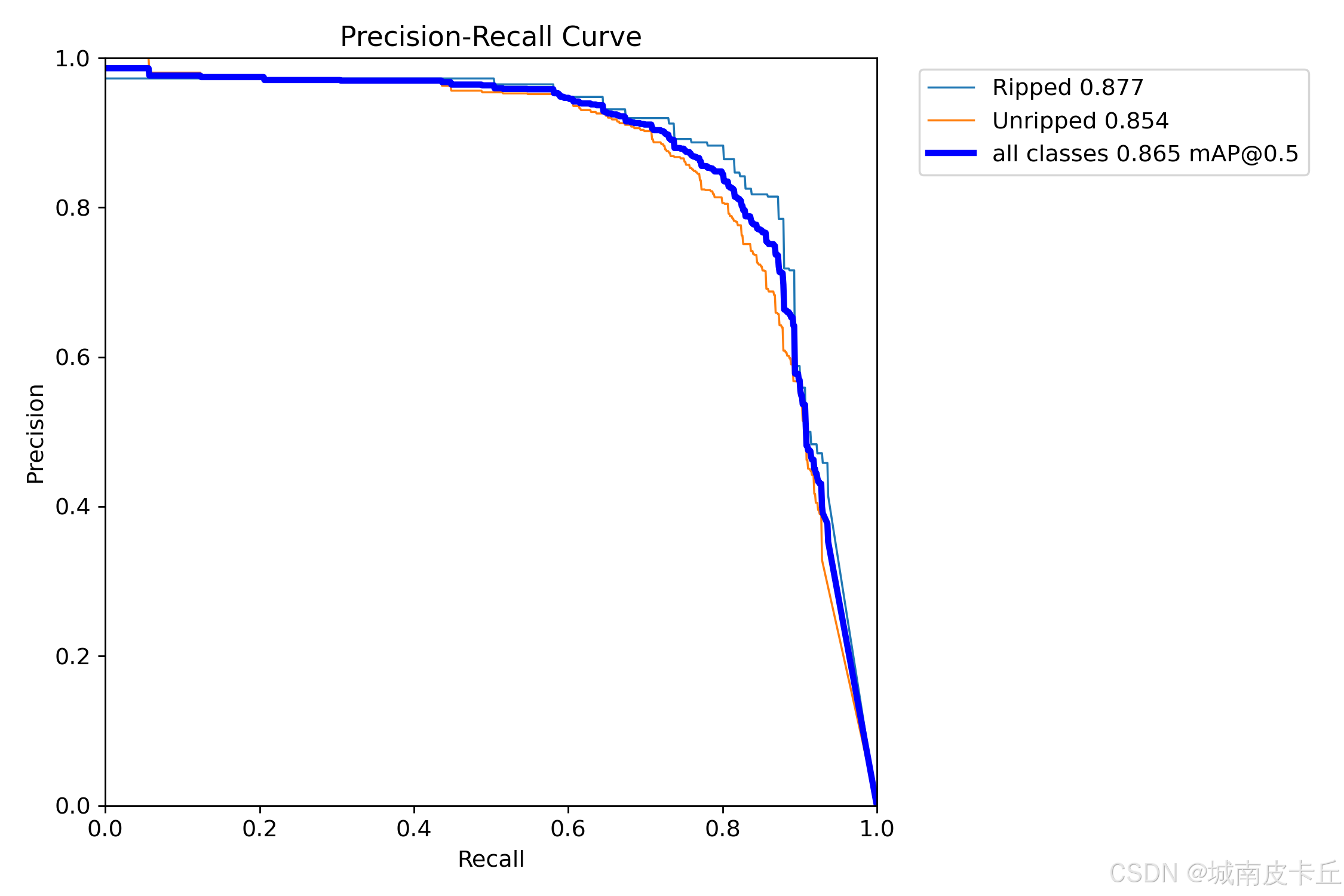
模型训练过程中,为了记录模型训练的情况,比如模型是否收敛、是否训练充分、模型当前精度等,我们会记录一系列的指标,包括loss曲线、map曲线等,如下图所示。
3.3 前后端开发
3.3.1 后端开发
后端基于Python语言开发,核心技术栈包含ultralytics深度学习推理框架与Streamlit轻量级应用框架。后端系统围绕模型推理流程设计了以下三个核心功能函数:
- 模型加载函数实现
采用
@st.cache_resource装饰器构建缓存机制,有效避免因重复调用导致的资源浪费问题;
函数内部会根据当前运行环境自动检测GPU可用性——若检测到GPU(CUDA)可用,则优先加载PyTorch原生模型(.pt格式)以提升推理速度;若仅支持CPU环境,则切换加载优化后的ONNX模型(.onnx格式),确保不同硬件条件下均能稳定运行。 - 图片推理函数实现
输入参数包含:预加载的模型对象、待推理的图片数据、置信度阈值(控制检测框的置信度筛选)、IoU阈值(控制非极大值抑制的交并比判断)、是否保存结果图片的布尔标记;
输出结果包含三部分:标注后的可视化图片(带检测框与类别标签)、各检测类别的数量统计字典(键为类别名称,值为对应数量)、检测结果的详细信息列表(每个元素为包含序号、类别名称、置信度分数、边界框坐标的元组)。 - 视频帧推理函数实现
输入参数包括:预加载的模型对象、视频拆分后的单帧图像数据、置信度阈值、IoU阈值;
输出为单帧图像的标注结果(与图片推理的标注逻辑一致,但仅针对当前视频帧),用于后续视频帧的连续拼接与播放。
3.3.2 前端开发
前端完全基于Streamlit框架构建。作为专为机器学习与数据科学场景设计的低代码开发工具,Streamlit的核心定位是帮助开发者(尤其是数据科学家)快速将算法模型或数据分析流程转化为可交互的Web应用,大幅缩短“研究-落地”的转化周期。
该框架的核心优势体现在以下方面:
- 极简开发体验:无需掌握HTML、CSS或JavaScript等前端技术,仅需通过Python脚本调用Streamlit提供的API即可完成交互式应用的搭建,显著降低开发门槛;
- 丰富的组件支持:内置滑动条、单选框、复选框、文件上传器等多种交互组件,并支持Pandas DataFrame、Matplotlib图表、Plotly可视化等常见数据类型的原生渲染,轻松实现复杂界面的搭建;
- 实时反馈机制:支持“代码修改-自动刷新”的实时预览模式,开发者调整代码后无需手动重启服务,即可立即查看界面更新效果,大幅提升调试效率;
- 响应式布局适配:自动根据终端设备(PC、平板、手机)的屏幕尺寸调整界面元素布局,确保不同设备下的显示效果一致;
- •数据科学生态兼容:深度集成了Python主流数据科学库(如Pandas用于数据处理、Numpy用于数值计算、Scikit-Learn用于模型训练),允许开发者直接在Streamlit应用中调用这些库的功能,实现“数据处理-模型推理-结果展示”的全流程闭环。
Streamlit的典型应用场景覆盖模型演示、数据可视化、自动化工具等多个领域,例如通过简单拖拽组件搭建预测模型的在线预测接口,或通过文件上传组件实现Excel数据的自动化清洗与分析。其价值在于将复杂的模型逻辑或数据处理流程“封装”为用户友好的Web界面,使非技术人员也能便捷地使用模型能力。
在本项目中,基于Streamlit框架具体实现了以下功能:
- 页面基础配置:通过
st.set_page_config()接口设置页面标题、图标及整体布局(如宽屏模式); - 界面元素优化:利用
st.markdown()配合自定义CSS隐藏Streamlit默认的页脚与侧边菜单,提升应用的专业感; - 侧边栏配置面板:在侧边栏区域添加交互组件,包括:
- 滑动条组件:用于动态调整置信度阈值与IoU阈值;
- 下拉选择框:用于切换检测类型(图片/视频/本地摄像头);
- 多输入源处理逻辑:根据所选检测类型,分别实现不同输入源的处理流程:
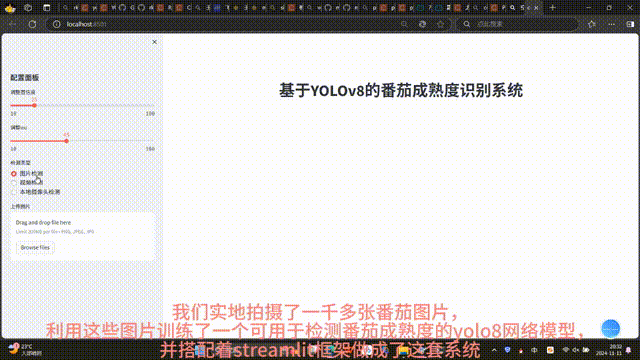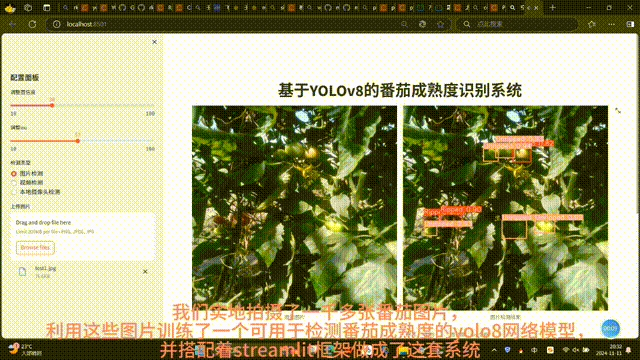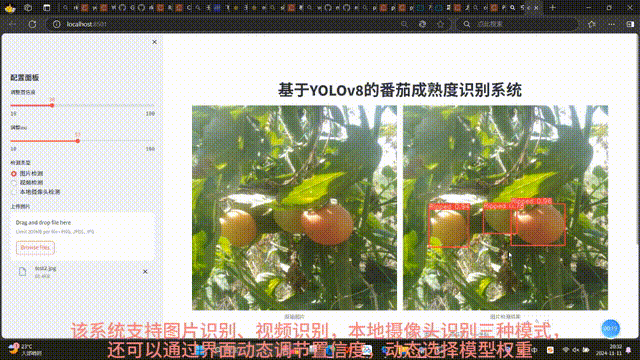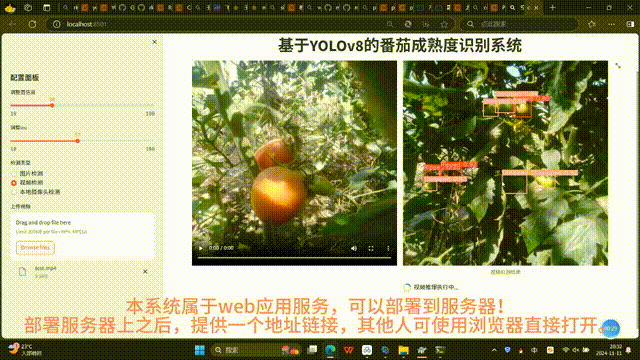
- 图片检测:用户上传图片后,前端同步显示原始图片与模型输出的检测结果图片,并在下方表格中展示检测目标的详细信息(如类别、置信度)及各类别统计数量;
- 视频检测:用户上传视频后,前端先播放原始视频片段,随后逐帧调用后端推理接口处理视频流,实时显示标注后的检测结果(视频文件临时存储于服务器指定目录);
- 本地摄像头检测:调用浏览器API访问本地摄像头,实时捕获视频流并逐帧推理,检测结果直接叠加在画面上显示,同时提供“终止检测”按钮用于停止视频流捕获。
4.总结
随着科技的不断进步,人工智能和深度学习技术已广泛应用于各行各业,尤其是在智慧农业方面。传统的番茄成熟度检测方法依赖于人工观察,但这种方法不仅耗时耗力,而且容易因人为因素导致误判或漏判。因此,开发一种能够自动、准确、快速地检测番茄成熟度的系统显得尤为重要。
YOLOv8作为一种尖端的、最先进的(SOTA)模型,具备在大型数据集上进行训练的能力,并能在各种硬件平台上运行,从CPU到GPU。它建立在先前YOLO系列模型的成功基础上,并引入了新功能和改进,以进一步提升性能和灵活性。这使得YOLOv8成为开发番茄成熟度检测系统的理想选择。
在农业智能化转型的关键时期,基于YOLOv8与Streamlit的番茄成熟度检测系统应运而生,其核心目的在于通过深度学习与交互式可视化技术的深度融合,突破传统农业依赖人工经验判断的局限。该系统利用YOLOv8强大的实时目标检测能力精准捕捉果实成熟特征,结合Streamlit构建的轻量化Web界面,将复杂的AI模型转化为田间地头可即时操作的智能工具。其意义不仅在于显著降低人工检测误差率、提升采收作业效率,更通过成熟度数据的动态积累与分析,为种植决策提供量化依据,推动采摘计划优化、物流资源调配和市场价格预判的精准化,最终实现从"经验农业"到"数据农业"的跨越,为农产品品质升级与产业链降本增效注入科技动能。
综上所述,基于YOLOv8的番茄成熟度检测系统具有重要的研究意义和应用价值,不仅可以提高检测的准确性和效率,还可以推动人工智能技术在智慧农业领域的应用。
另外,限于本篇文章的篇幅,无法一一细致讲解系统原理、项目代码、模型训练等细节,需要数据集、项目源码、训练代码、系统原理说明文章的小伙伴可以从下面的链接中下载:
基于YOLOv8的番茄成熟度识别系统