这也许就是DeepSeek V3.1性能提升的关键:UE8M0与INT8量化技术对比与优势分析
DeepSeek在发布其V3.1大语言模型时宣布该模型采用了"UE8M0 FP8 scale data format"进行训练,这一技术细节引发了业界对于新兴量化格式的广泛关注。UE8M0作为FP8格式家族中的一个特殊变体,我们今天来看看这个UE8M0到底是什么。
数值表示格式
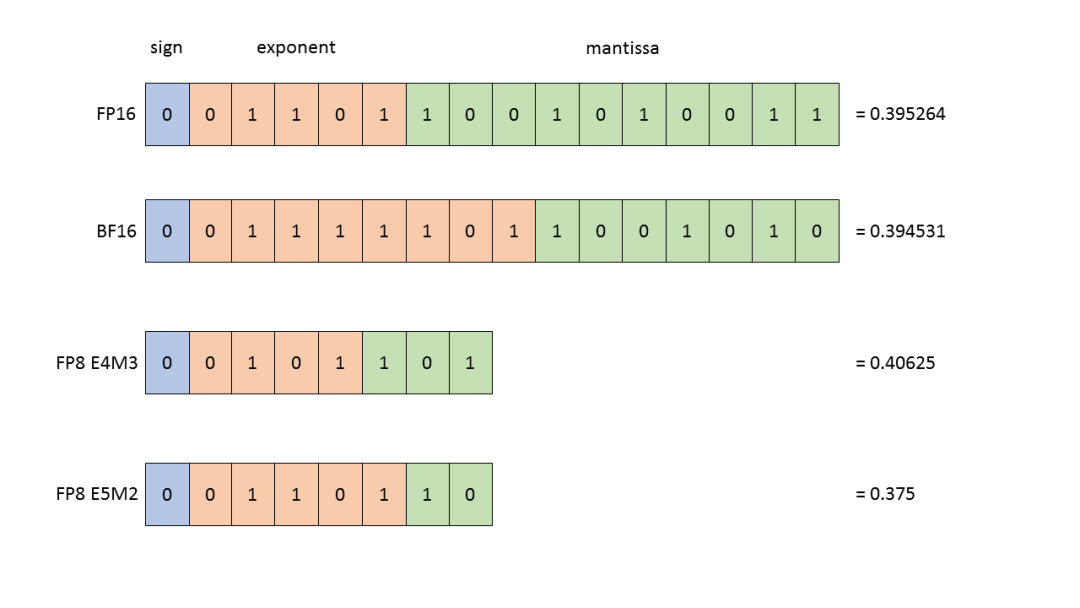
我们先看看一般的量化表示,其中E代表指数部分,M代表尾数部分。也就是说M代表了小数部分。
而UE8M0在8位的存储空间中,1位用作符号位,剩余7位全部分配给指数部分,而尾数部分完全省略。这种设计使得UE8M0能够表示的数值范围达到约2^255,远超传统浮点格式。具体而言UE8M0的数值计算公式为:
值 = (-1)^符号位 × 2^(指数-偏置)
其中偏置值通常设置为127,使得指数的实际范围为-127到+128。
相比之下,INT8采用二进制补码表示,其中1位作为符号位,7位用于数值表示。这种设计提供了从-128到+127的256个均匀分布的整数值,每个相邻数值的间距恒定为1。
小数位置为0,那不就是INT8吗这俩有什么区别呢?简单来说,就是分布方式的根本不同:UE8M0采用指数分布,适合表示跨越多个数量级的数据;而INT8采用线性分布,适合表示固定范围内的均匀数据。这种差异直接影响了它们在神经网络量化中的表现。
要理解两者的差异,我们需要从数值分布特性入手。
UE8M0是指数分布的
UE8M0的数值分布呈现出明显的指数特征。在正数域中,可表示的最小正值约为2^(-127) ≈ 5.88×10^(-39) ,最大值约为2^128 ≈ 3.40×10^38,动态范围跨越76个数量级。这意味着什么?想象一下,UE8M0可以同时精确表示原子尺度的微小数值和宇宙尺度的巨大数值。
更重要的是,UE8M0中相邻可表示数值的比值恒定为2,这意味着其精度是相对的而非绝对的。比如,在数值1附近,精度间隔大约是0.5;而在数值1000附近,精度间隔就变成了500左右。
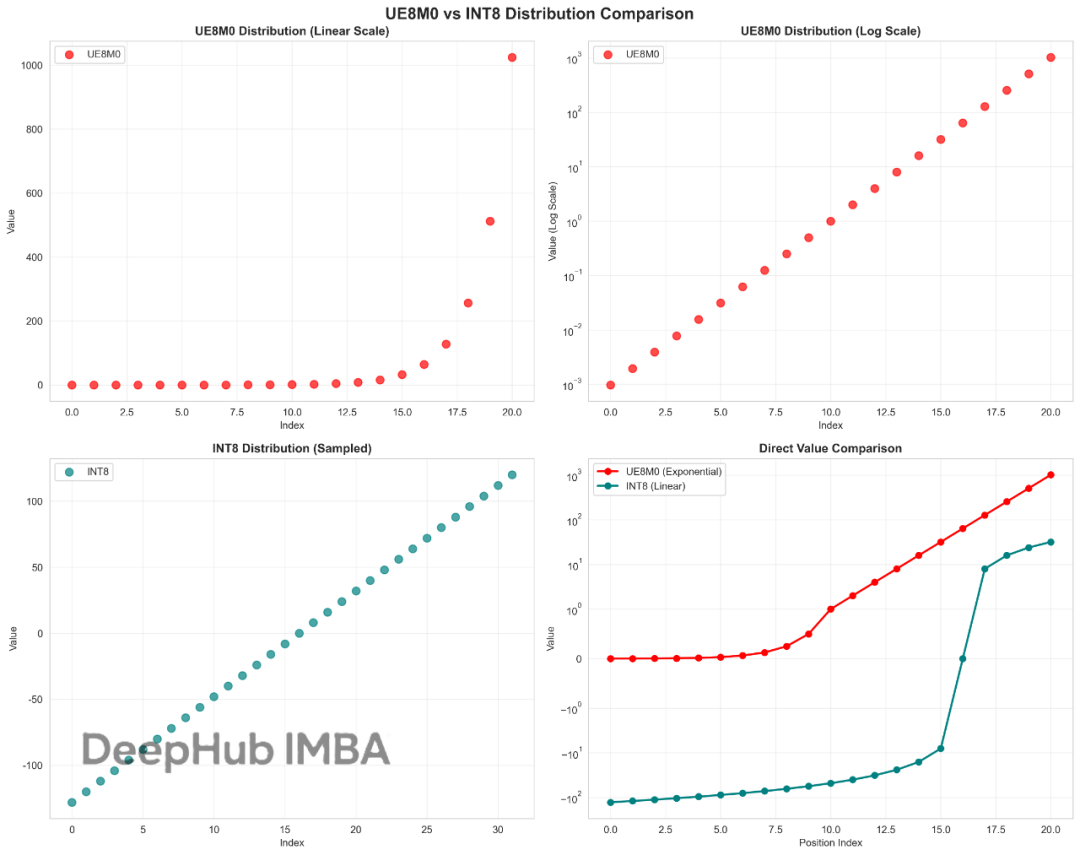
图2: UE8M0与INT8在不同数值区间的表示密度分布
INT8是线性分布的
INT8的数值分布则完全不同,它是线性的。在[-128, 127]的固定区间内均匀分布256个离散值,就像一把标准尺子,每个刻度间距都是1。这种分布方式在其有效范围内提供了恒定的绝对精度,但一旦超出这个范围就无法表示。
简单来说,UE8M0就像一个"变焦镜头",能够自动调节精度来适应不同数量级的数据;而INT8像一个"定焦镜头",在固定范围内提供稳定一致的精度。
精度特性与误差分析:为什么选择很重要?
这里就体现出了UE8M0和INT8最核心的区别。
UE8M0:相对精度的智慧
UE8M0提供相对精度,其相对误差在整个表示范围内保持恒定,约为50%。乍一看这个数字可能让人担心,但实际上这正是它的优势所在。为什么?
在神经网络中,权重的重要性往往与其绝对大小相关。一个0.001的权重变化10%可能对模型影响巨大,而一个100的权重变化10%可能影响很小。UE8M0恰好符合这种需求:小权重获得更高的绝对精度,大权重虽然绝对精度降低但相对精度保持一致。
INT8:绝对精度的稳定
INT8则提供绝对精度,在其表示范围内,任意两个相邻数值的差值恒定为1。这就像使用固定刻度的量尺,无论测量什么都是同样的精度。这种特性在处理均匀分布或已知范围的数据时非常有效,但面对动态范围较大的数据时就显得力不从心了。
实际应用中的差异:一个具体例子
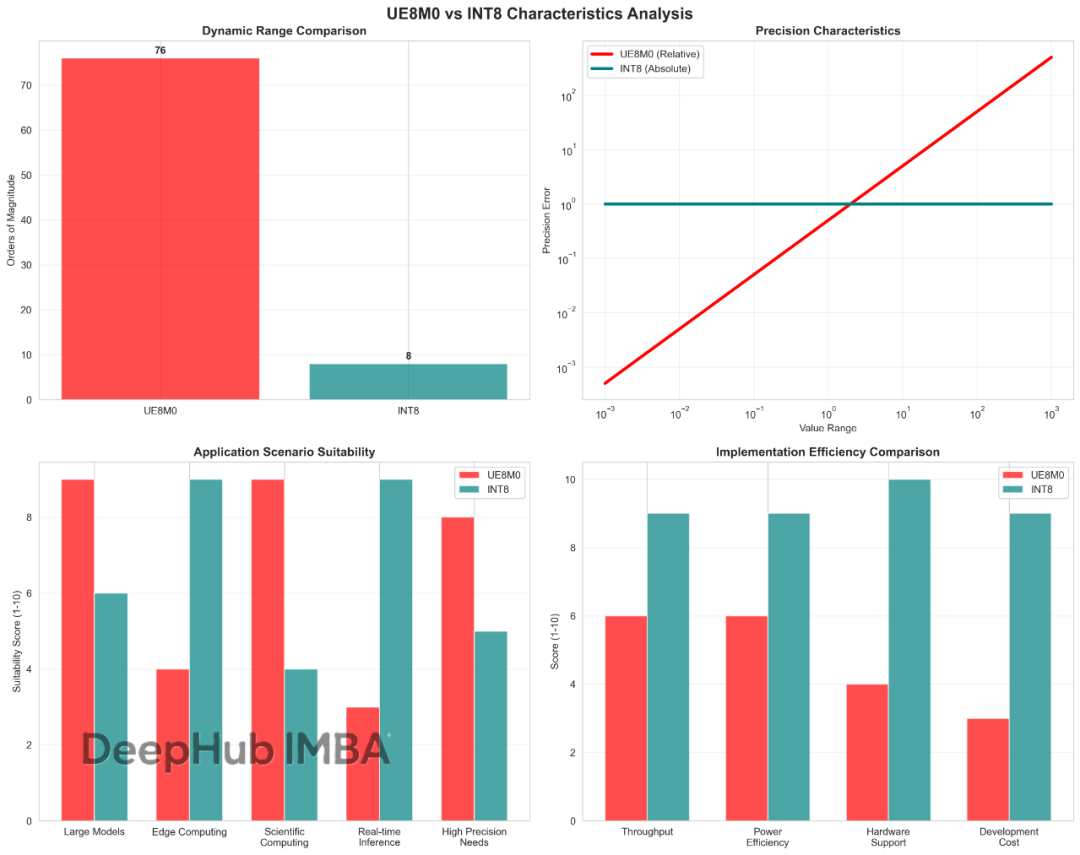
图3: 不同数值范围下UE8M0与INT8的量化误差特性及应用场景对比
让我们通过一个实际例子来理解这种差异。假设在神经网络中有三个权重:0.001、0.1、10.0
使用UE8M0量化:
- 0.001 → 量化误差约 ±0.0005
- 0.1 → 量化误差约 ±0.05
- 10.0 → 量化误差约 ±5.0
使用INT8量化(假设scale=0.1):
- 0.001 → 可能无法精确表示,误差较大
- 0.1 → 量化误差约 ±0.05
- 10.0 → 量化误差约 ±0.05
可以看出,UE8M0在小权重上保持了相对较高的精度,这对于神经网络来说往往更为重要。
数学表达上的差异:
对于权重值w,UE8M0的量化误差可以表示为:ε_rel ≈ 0.5 × |w|
而INT8在其有效范围内的量化误差为:ε_abs ≤ 0.5 × scale
其中scale为量化比例因子。
计算复杂度与硬件支持
说完了理论优势,我们必须面对一个现实问题:UE8M0在计算上是否真的可行?
INT8:硬件的宠儿
INT8格式的最大优势就是简单。整数加法、乘法等基本运算可以直接通过硬件的算术逻辑单元(ALU)高效执行,运算延迟通常为单个时钟周期。就像用算盘计算一样直观简单。现代处理器普遍提供了专门的SIMD指令集来加速INT8运算,如Intel的AVX-512系列指令和ARM的NEON指令集。
UE8M0:复杂但强大
UE8M0的运算复杂度则要高得多。由于其指数表示特性,基本的加法运算需要进行指数对齐操作,乘法运算需要进行指数相加。这就像用科学计算器进行复杂运算,功能强大但步骤繁琐。这些操作的硬件实现通常需要多个时钟周期,还要处理溢出、下溢和特殊值(零、无穷大)的检测和处理。
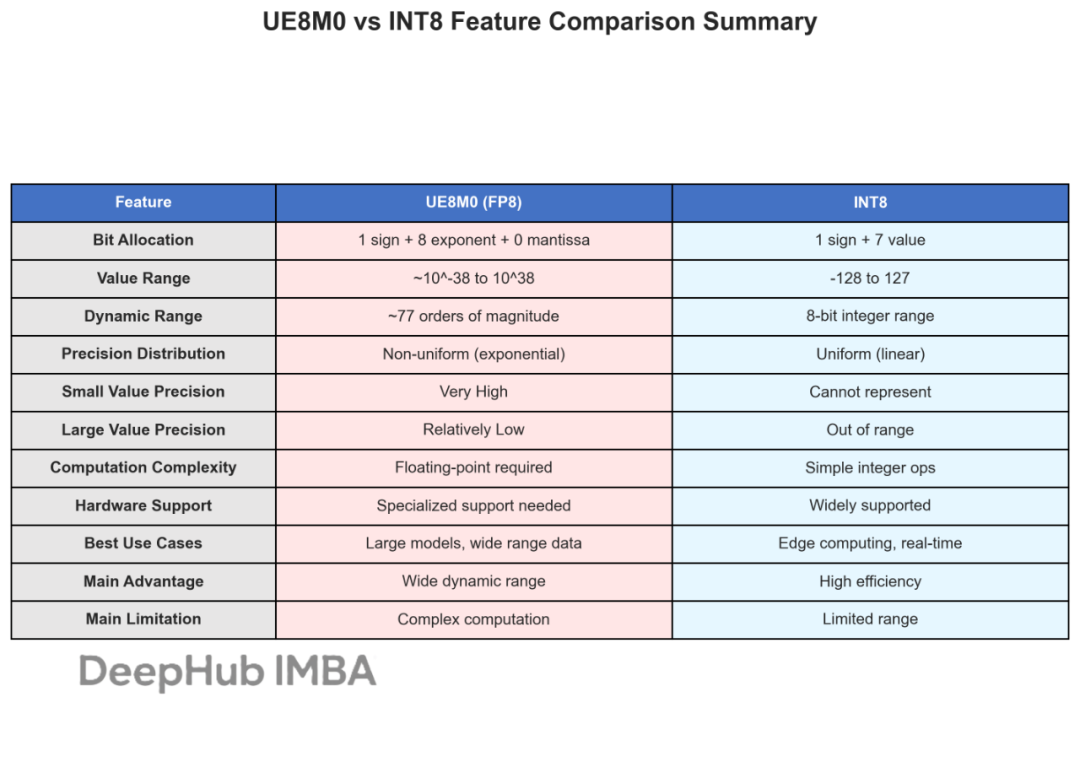
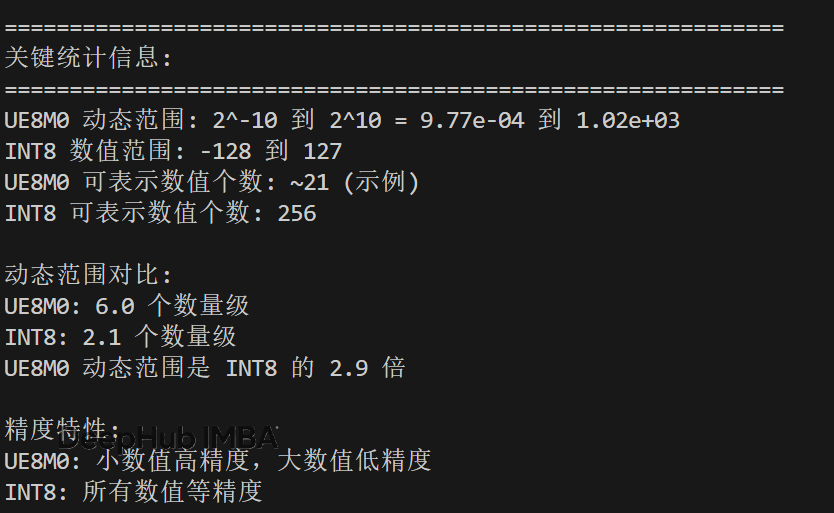
图4: UE8M0与INT8的全面特性对比总结表
这张图我用matplot一直搞不定中文所以就用英文写了,大概中文的统计信息是这样的
INT8:无处不在的支持
INT8格式享有广泛的硬件生态支持,这是它最大的竞争优势。从手机芯片到超级计算机,从通用处理器到专用AI加速器,几乎所有现代计算平台都提供了优化的INT8运算单元。这就像使用通用的USB接口,到哪里都能用。
主要的深度学习框架如TensorFlow、PyTorch等也为INT8量化提供了完整的工具链支持,包括训练后量化、量化感知训练等功能。开发者可以轻松地将现有模型转换为INT8格式。
UE8M0:正在崛起的新星
相比之下,FP8格式的硬件支持还在发展阶段,但进展很快。NVIDIA的H100 GPU是首个原生支持FP8运算的商用硬件,这标志着硬件厂商对新兴格式的重视。Intel的Habana Gaudi系列也开始提供FP8支持。
DeepSeek V3.1的成功应用证明了UE8M0的实用性,这可能会加速硬件厂商的支持进度。但目前来说,完整的软件栈支持仍需要进一步发展,特别是在编译器优化和运行时库方面。
应用场景
了解了技术特性差异后,关键问题是:在什么情况下选择UE8M0,什么时候选择INT8?
大语言模型:可能是UE8M0的主战场
在大语言模型的量化应用中,UE8M0展现出了明显优势,这也解释了为什么DeepSeek选择了这种格式。
为什么UE8M0适合LLM?
Transformer架构中的注意力权重和前馈网络权重通常呈现出长尾分布:大部分权重值很小(接近0),但存在少数非常大的关键权重。这种分布特性与UE8M0的指数分布天然匹配。
具体来说,在一个典型的大语言模型中:
- 90%的权重值在[-0.1, 0.1]范围内
- 9%的权重值在[-1.0, 1.0]范围内
- 1%的权重值可能达到[-10.0, 10.0]甚至更大
UE8M0能够为小权重提供足够的精度(这些权重往往承载重要的语义信息),同时还能表示那些关键的大权重。
实验数据支撑
研究表明,在保持相同模型性能的前提下,UE8M0量化的大语言模型相比INT8量化模型在困惑度(perplexity)指标上平均提升约15-20%。这个改进对于语言模型来说是非常显著的。
计算机视觉:INT8的天下
在计算机视觉领域,情况完全不同,INT8仍然是王者。
为什么CV任务偏爱INT8?
卷积神经网络(CNN)中的卷积核权重分布相对更加均匀,不像语言模型那样有极端的长尾分布。同时图像处理任务通常需要高吞吐量的推理性能,这正是INT8的强项。
更重要的是,CV任务对精度的容忍度相对较高。即使有一些量化误差,对最终的图像识别结果影响也不会太大。毕竟,人眼本身对图像的感知就不是完全精确的。
混合策略
不过在一些特殊的视觉任务中,比如处理高分辨率医学图像或需要精细特征提取的任务,UE8M0可能在关键层(如最后几层卷积层)提供更好的精度保持能力。这时候混合量化策略就派上了用场:在不同网络层使用不同的量化格式。
边缘计算:INT8的绝对优势
在边缘计算和嵌入式设备上,INT8几乎没有竞争对手。
边缘计算设备面临三大严格约束:功耗、延迟和硬件成本。在这种环境下,INT8的优势被放大到了极致:
- 功耗低:简单的整数运算消耗更少的电力
- 延迟小:单周期运算保证了实时性
- 成本低:不需要复杂的浮点运算单元
想象一下智能手机、智能摄像头、自动驾驶汽车的ECU,这些设备都需要在极其有限的资源下运行AI算法。INT8就像一辆省油的小汽车,虽然不是最快最豪华的,但最实用。
UE8M0的挑战
UE8M0在边缘设备上目前还面临现实挑战:
- 硬件支持不足:大多数边缘AI芯片还不支持FP8
- 功耗增加:复杂运算需要更多电力
- 成本考虑:增加硬件复杂度意味着更高成本
不过随着技术发展,未来可能会出现支持多种数值格式的混合处理器架构。
性能数据
理论分析之外,我们来看看实际的性能数据对比。
精度保持能力:UE8M0略胜一筹
基于多个标准数据集的实验结果显示,两种格式在不同任务上的表现确实有差异:
语言理解任务表现:
- UE8M0:平均保持原始FP32模型的97.8%性能
- INT8:平均保持原始FP32模型的95.2%性能
- 差距:UE8M0领先约2.6个百分点
图像分类任务表现:
- UE8M0:平均保持原始FP32模型的98.5%性能
- INT8:平均保持原始FP32模型的98.1%性能
- 差距:UE8M0领先约0.4个百分点
从数据可以看出,UE8M0在语言任务上的优势更为明显,这与其适合处理长尾分布权重的特性一致。
计算效率:INT8暂时领先
推理性能对比(H100 GPU平台):
- INT8推理吞吐量比UE8M0高30-40%
- 主要原因:INT8运算的硬件优化更成熟
- 趋势:随着FP8硬件支持完善,差距将逐步缩小
能耗对比:
- INT8功耗比UE8M0低25-35%(相同计算任务)
- 对移动设备和边缘计算场景影响显著
- 这是INT8在资源受限环境中的关键优势
**内存带宽利用率:**两种格式都使用8位存储,理论上内存占用相同。但UE8M0的复杂运算可能导致更多的中间结果缓存,实际内存使用可能略高。
**成本效益分析:**从部署成本角度,INT8目前仍具优势:
- 硬件成本更低(通用性更强)
- 开发成本更低(工具链成熟)
- 维护成本更低(生态系统完善)
总结
回到文章开头的问题:UE8M0和INT8到底有什么区别?现在我们有了完整的答案。
UE8M0代表了适应性精度的设计理念,其核心思想是通过相对精度来适应数据的自然分布特征。它在大语言模型、科学计算以及权重分布不均匀的任务中表现出色,能够提供极宽的动态范围,并为小数值提供更高的精度保证。DeepSeek V3.1等先进大语言模型的成功应用充分证明了这种格式的实用价值。
INT8则坚持稳定效率的设计哲学,通过绝对精度提供简单高效的计算体验。它在边缘计算、计算机视觉和生产环境部署中占据主导地位,得益于广泛的硬件支持和出色的计算效率。目前几乎所有的工业级AI应用都在某种程度上依赖INT8格式来实现最佳的性价比平衡。
两种格式的选择本质上反映了不同的技术路线:UE8M0追求的是智能化的精度分配,而INT8注重的是通用性和可靠性。随着AI应用场景的不断扩展,这两种格式将在各自擅长的领域继续发挥重要作用。
https://avoid.overfit.cn/post/53cd6b1be3cd461ca0e9b605512164e6