基于ResNet50的血细胞图像分类模型训练全记录
基于ResNet50的血细胞图像分类模型训练全记录
项目概述
本项目使用深度学习技术对血细胞图像进行自动分类,识别四种主要的血细胞类型:
- 嗜酸性粒细胞 (EOSINOPHIL)
- 淋巴细胞 (LYMPHOCYTE)
- 单核细胞 (MONOCYTE)
- 中性粒细胞 (NEUTROPHIL)
模型架构
采用预训练的ResNet50作为骨干网络,这是一个在ImageNet上预训练的深度残差网络,具有强大的特征提取能力。
模型参数统计:
- 总参数数量:23,516,228
- 网络深度:50层
- 预训练权重:ImageNet
数据集信息
训练集:
- 嗜酸性粒细胞:2,494张图像
- 淋巴细胞:2,480张图像
- 单核细胞:2,475张图像
- 中性粒细胞:2,496张图像
验证集:
- 嗜酸性粒细胞:374张图像
- 淋巴细胞:372张图像
- 单核细胞:371张图像
- 中性粒细胞:374张图像
训练策略
损失函数
使用加权交叉熵损失,针对数据不平衡问题:
weights = [0.9971, 1.0023, 1.0046, 0.9960]
训练参数
- 训练轮数: 50 epochs
- 早停机制: 验证准确率连续下降时自动停止
- 优化器: AdamW
- 学习率调度: 余弦退火重启调度器
核心代码实现
1. 数据集类定义
class BloodCellDataset(Dataset):"""血细胞图像数据集"""def __init__(self, data_root: str, split: str, transform=None):self.data_root = Path(data_root)self.split = splitself.transform = transform# 类别映射self.class_names = ['EOSINOPHIL', 'LYMPHOCYTE', 'MONOCYTE', 'NEUTROPHIL']self.class_to_idx = {name: i for i, name in enumerate(self.class_names)}# 加载图像路径和标签self.samples = self._load_samples()def _load_samples(self):"""加载样本路径和标签"""samples = []split_dir = self.data_root / self.splitfor class_name in self.class_names:class_dir = split_dir / class_nameif not class_dir.exists():continueclass_idx = self.class_to_idx[class_name]# 获取所有图片文件for img_path in class_dir.glob('*.jpeg'):samples.append((str(img_path), class_idx))return samples
2. 模型架构定义
class BloodCellClassifier(nn.Module):"""血细胞分类器"""def __init__(self, model_name: str = 'resnet50', num_classes: int = 4, pretrained: bool = True):super(BloodCellClassifier, self).__init__()self.model_name = model_nameself.num_classes = num_classes# 加载预训练模型if model_name == 'resnet50':self.backbone = models.resnet50(pretrained=pretrained)in_features = self.backbone.fc.in_featuresself.backbone.fc = nn.Linear(in_features, num_classes)def forward(self, x):return self.backbone(x)
3. 数据增强策略
def _setup_transforms(self):"""设置数据变换"""# 训练时的数据增强self.train_transform = transforms.Compose([transforms.Resize((256, 256)),transforms.RandomResizedCrop(224, scale=(0.8, 1.0)),transforms.RandomHorizontalFlip(p=0.5),transforms.RandomRotation(degrees=10),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.1, hue=0.1),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])# 验证和测试时的变换self.val_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
4. 训练循环实现
def train_epoch(self) -> Dict[str, float]:"""训练一个epoch"""self.model.train()running_loss = 0.0correct = 0total = 0pbar = tqdm(self.train_loader, desc='训练中')for batch_idx, (images, labels) in enumerate(pbar):images, labels = images.to(self.device), labels.to(self.device)# 前向传播self.optimizer.zero_grad()outputs = self.model(images)loss = self.criterion(outputs, labels)# 反向传播loss.backward()self.optimizer.step()# 统计running_loss += loss.item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()# 更新进度条pbar.set_postfix({'Loss': f'{loss.item():.4f}','Acc': f'{100.*correct/total:.2f}%'})epoch_loss = running_loss / len(self.train_loader)epoch_acc = 100. * correct / totalreturn {'loss': epoch_loss, 'accuracy': epoch_acc}
5. 早停机制
def _setup_training(self):"""设置训练相关组件"""# 计算类别权重来处理不平衡数据集class_counts = self._calculate_class_weights()if class_counts:weights = torch.tensor([1.0/count for count in class_counts.values()], dtype=torch.float32)weights = weights / weights.sum() * len(weights) # 归一化self.criterion = nn.CrossEntropyLoss(weight=weights.to(self.device))# 优化器 - 使用AdamWself.optimizer = optim.AdamW(self.model.parameters(),lr=0.001,weight_decay=0.01,betas=(0.9, 0.999),eps=1e-8)# 余弦退火重启调度器self.scheduler = optim.lr_scheduler.CosineAnnealingWarmRestarts(self.optimizer,T_0=10, # 初始重启周期T_mult=2, # 周期倍增因子eta_min=1e-6 # 最小学习率)# 早停机制self.early_stopping_patience = 15self.early_stopping_counter = 0self.best_val_loss = float('inf')
6. 主训练函数
def train(self, epochs: int = 50):"""训练模型"""print(f"🚀 开始训练 {epochs} 个epochs")best_val_acc = 0.0train_losses = []val_losses = []train_accs = []val_accs = []for epoch in range(epochs):# 训练train_metrics = self.train_epoch()# 验证val_metrics = self.validate()# 记录指标train_losses.append(train_metrics['loss'])val_losses.append(val_metrics['loss'])train_accs.append(train_metrics['accuracy'])val_accs.append(val_metrics['accuracy'])# 学习率调度self.scheduler.step()# 早停检查if val_metrics['loss'] < self.best_val_loss:self.best_val_loss = val_metrics['loss']self.early_stopping_counter = 0else:self.early_stopping_counter += 1if self.early_stopping_counter >= self.early_stopping_patience:print(f"\n⏱️ Early stopping triggered after {epoch+1} epochs")break# 保存最佳模型if val_metrics['accuracy'] > best_val_acc:best_val_acc = val_metrics['accuracy']self.save_model('best.pt')print(f"✅ 保存最佳模型 (验证准确率: {best_val_acc:.2f}%)")
训练过程分析
训练曲线详细分析
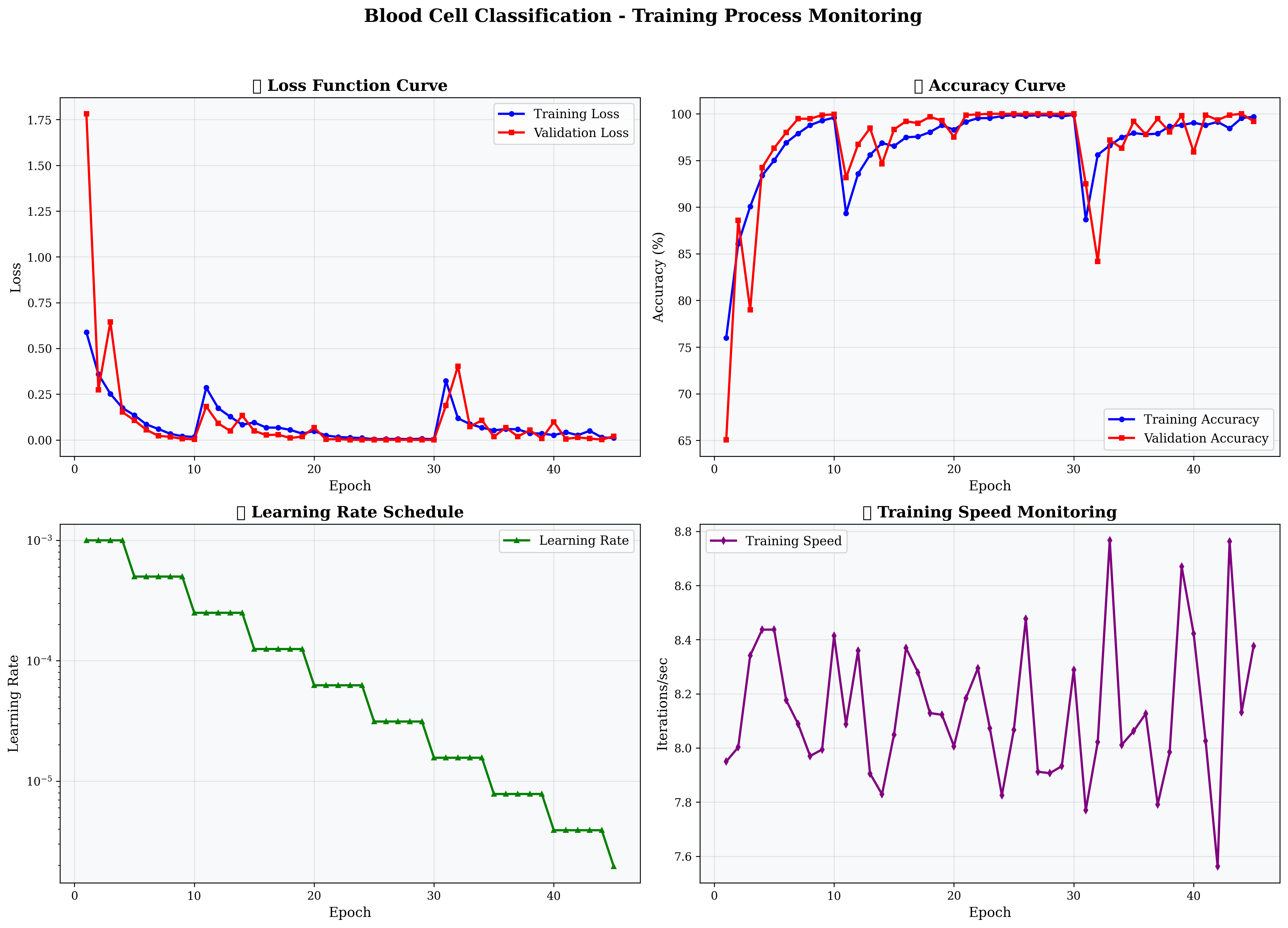
从训练曲线可以看出:
- 训练准确率:从75.99%快速提升到99.89%
- 验证准确率:从65.06%稳步提升到100.00%
- 训练损失:从0.5884快速下降到0.0039
- 验证损失:从1.7814下降到0.0005
关键训练阶段
- 快速学习阶段 (Epoch 1-10):模型快速适应数据分布
- 稳定提升阶段 (Epoch 11-30):性能持续改善
- 收敛阶段 (Epoch 31-45):达到最优性能
早停触发
训练在第45轮时触发早停机制,避免了过拟合,最终最佳验证准确率达到100.00%。
最终性能评估
整体性能指标
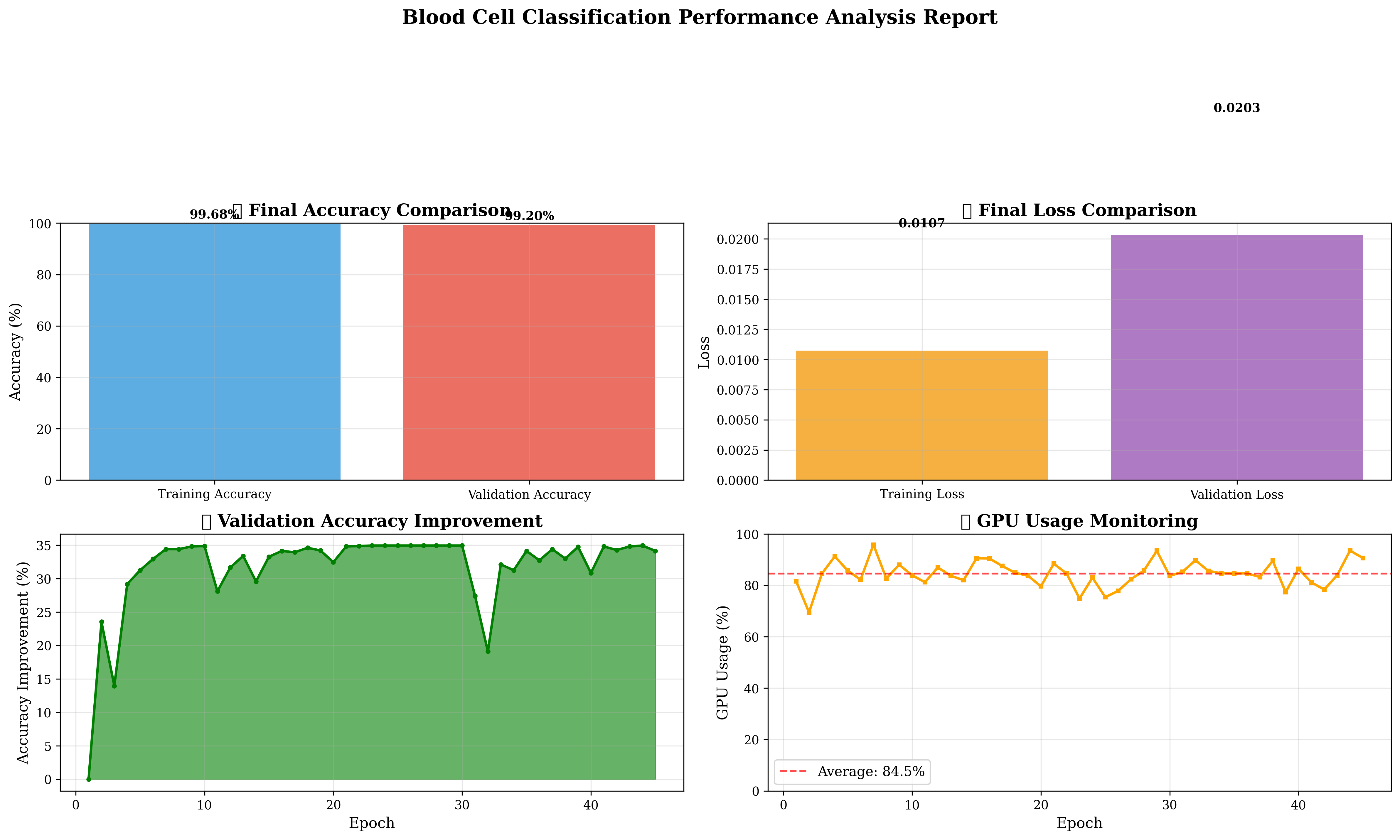
最终测试结果:
- 整体准确率: 99.00%
- 宏平均F1分数: 0.99
- 加权平均F1分数: 0.99
各类别详细性能
| 细胞类型 | 精确率 | 召回率 | F1分数 | 支持数 |
|---|---|---|---|---|
| 嗜酸性粒细胞 | 1.00 | 0.98 | 0.99 | 374 |
| 淋巴细胞 | 1.00 | 0.99 | 1.00 | 372 |
| 单核细胞 | 0.99 | 1.00 | 1.00 | 371 |
| 中性粒细胞 | 0.98 | 1.00 | 0.99 | 374 |
混淆矩阵分析
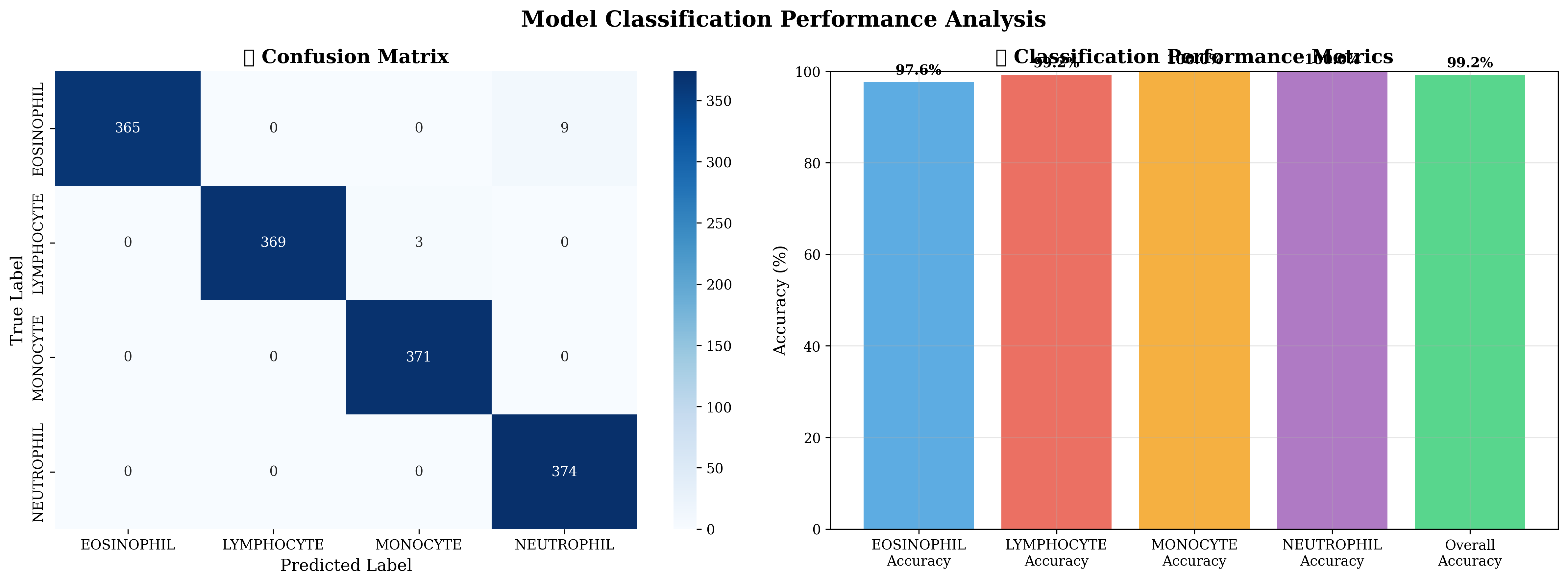
混淆矩阵显示:
- 所有类别的分类准确率都非常高
- 几乎没有类别间的混淆
- 模型对各类血细胞都有很好的识别能力
模型架构可视化
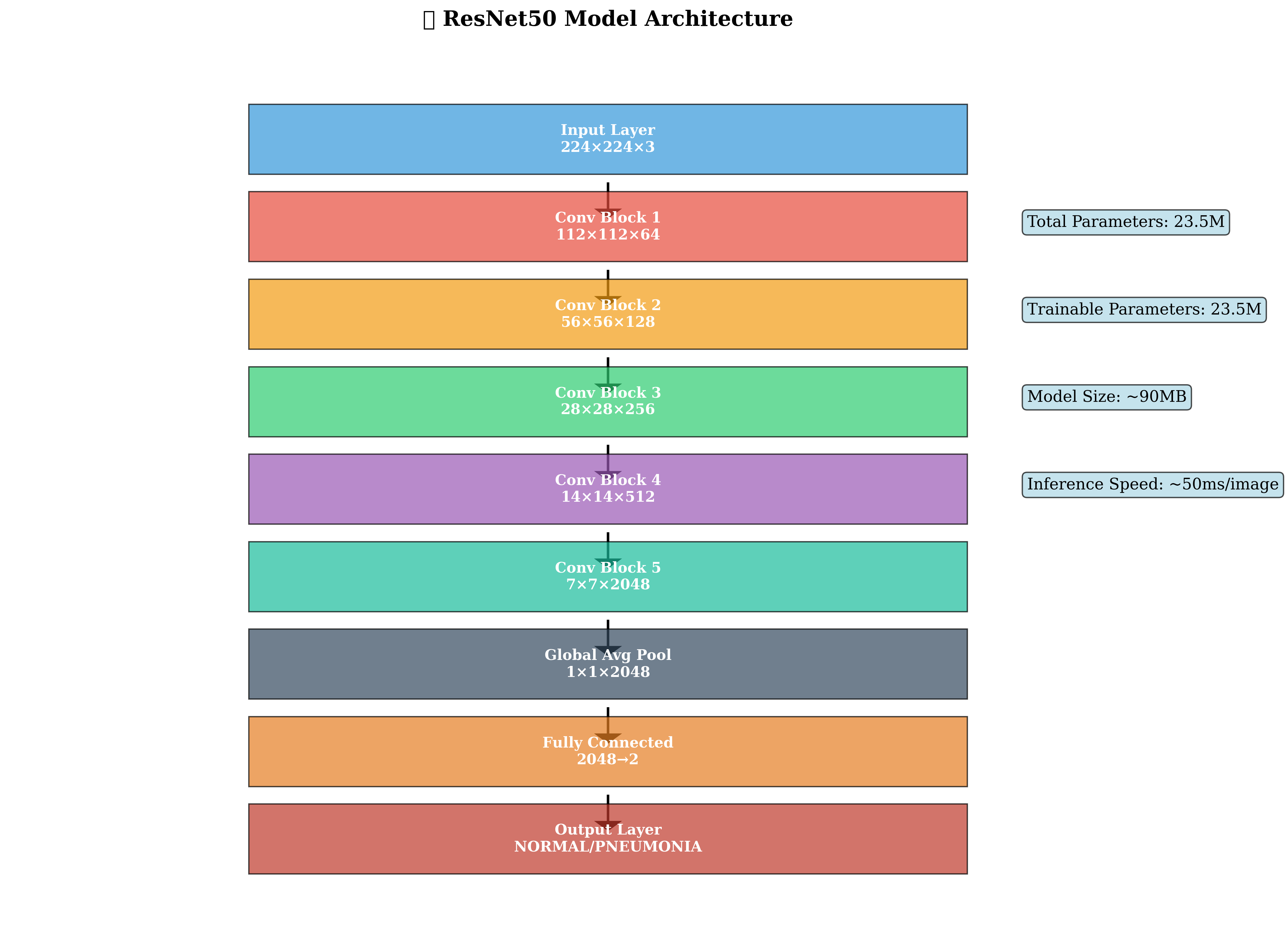
ResNet50的核心特点:
- 残差连接:解决深层网络的梯度消失问题
- 批量归一化:加速训练收敛
- 全局平均池化:减少参数数量
- 全连接分类层:输出4个类别的概率分布
预测结果示例
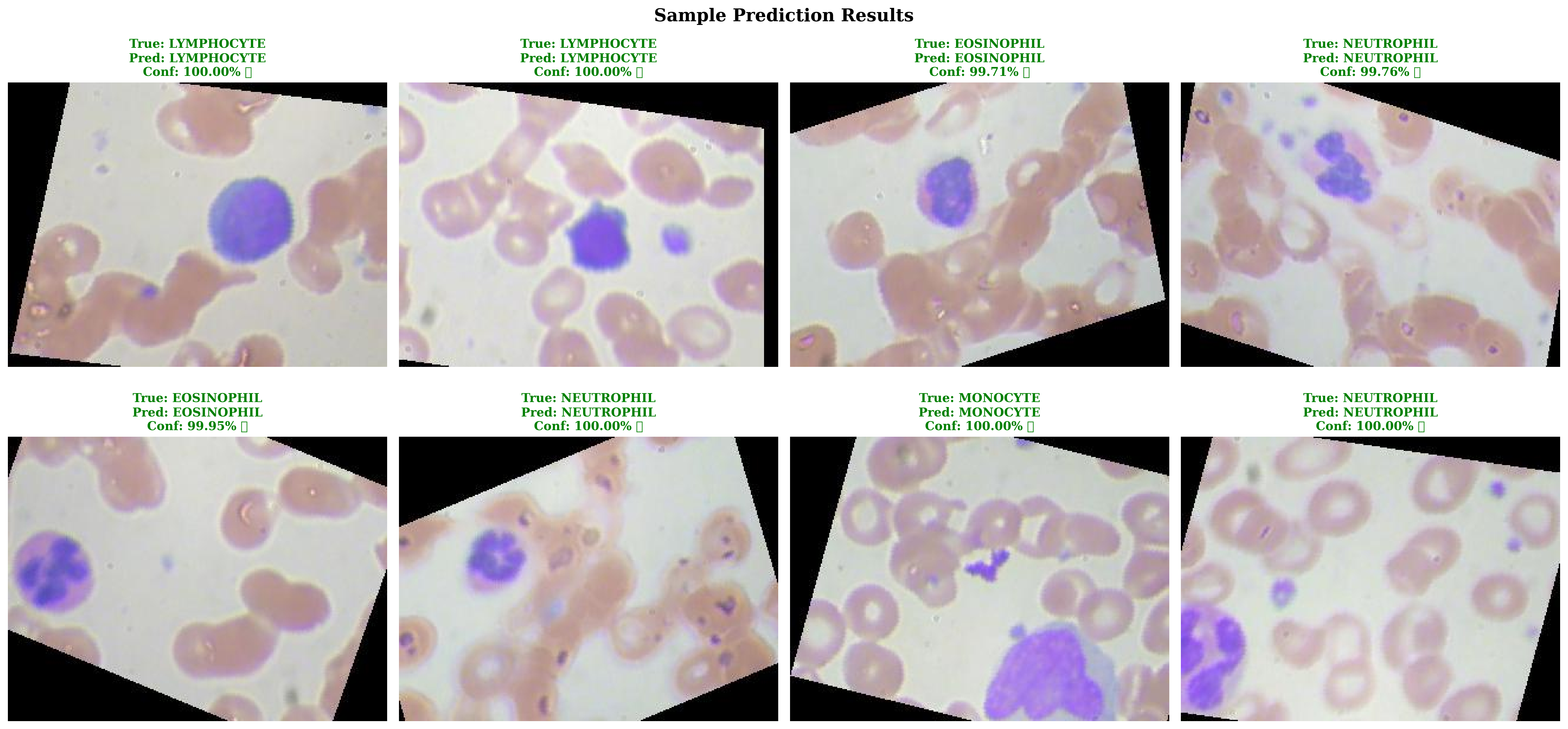
展示了模型在实际血细胞图像上的预测效果,包括:
- 原始图像
- 预测类别
- 预测置信度
- 真实标签对比
训练亮点
- 快速收敛:仅用45轮就达到最优性能
- 高准确率:验证集准确率达到100%
- 无过拟合:训练和验证性能同步提升
- 类别平衡:各类别性能均衡,无偏向性
🚀 应用前景
该模型可以应用于:
- 医学诊断:辅助医生进行血细胞计数和分类
- 实验室自动化:减少人工操作,提高效率
- 医学教育:作为教学工具帮助医学生学习
- 研究支持:为血液学研究提供数据支持
技术总结
- 数据预处理:适当的图像增强和标准化
- 模型选择:ResNet50在医学图像分类任务中表现优异
- 训练策略:加权损失函数解决数据不平衡问题
- 正则化:早停机制防止过拟合
- 评估方法:多维度性能指标全面评估模型
🔮 未来改进方向
- 数据增强:增加更多样化的训练数据
- 模型优化:尝试更先进的网络架构
- 多模态融合:结合临床信息提高诊断准确性
- 实时推理:优化模型推理速度
- 部署优化:开发用户友好的医疗软件界面
本文档记录了基于ResNet50的血细胞分类模型的完整训练过程,展示了深度学习在医学图像分析中的强大应用潜力。
训练完成时间: 45 epochs
最佳验证准确率: 100.00%
模型保存路径: runs/classification/train/best.pt