TorchDynamo - API
简介
TorchDynamo 负责捕获 Python 字节码,并将其转换为 FX Graph:
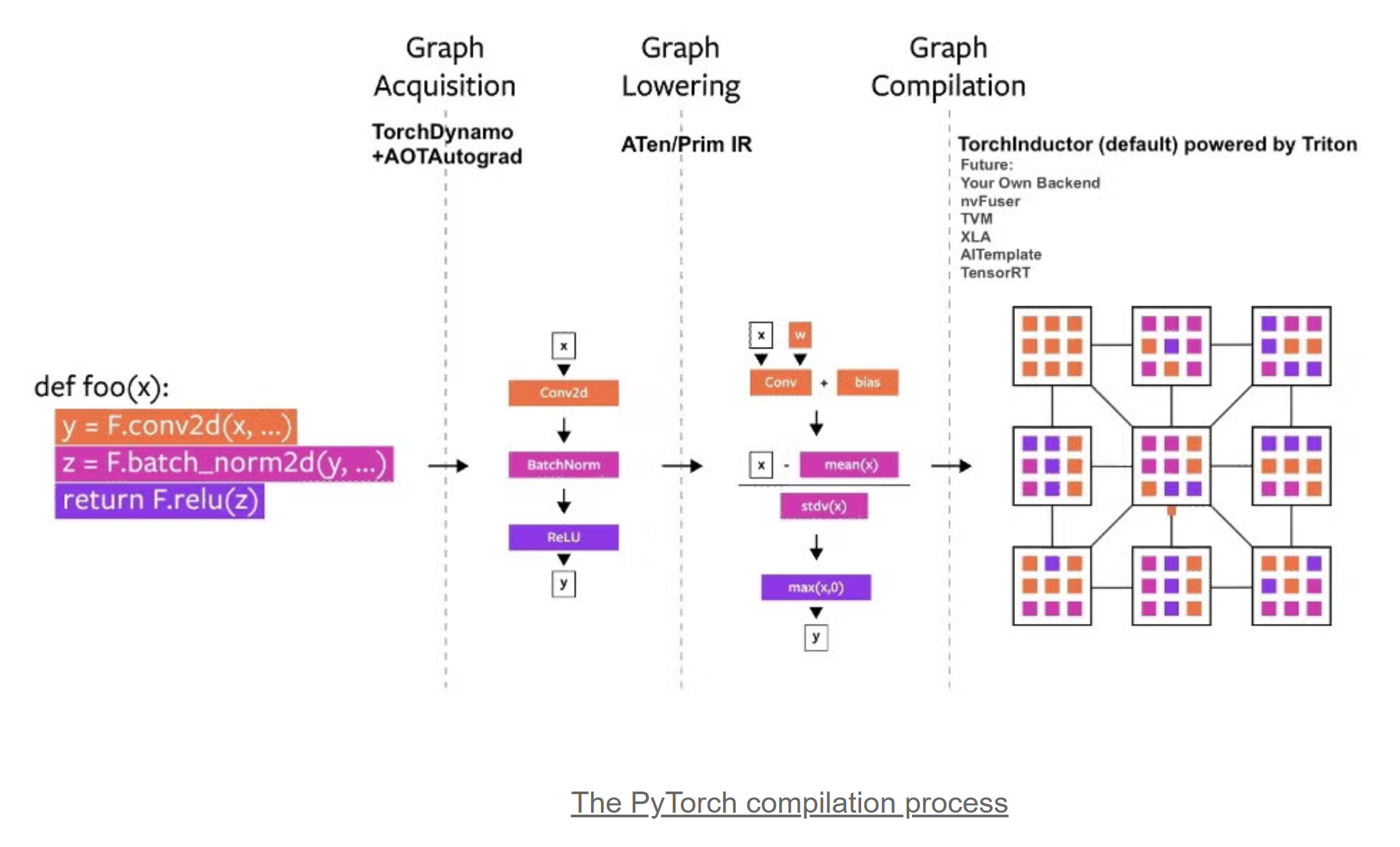
torch.compile
在pytorch中,通过torch.compile使用Dynamo,有两种使用方式:
1 函数调用:
import torchdef add(x1, x2):return x1 + x2x1 = torch.randn(4096, 390, device='cuda')
x2 = torch.randn(4096, 390, device='cuda')
add_fn = torch.compile(add, backend='inductor')
out1 = add_fn(x1, x2)
print(out1.shape)2 装饰器
import torch@torch.compile(backend='inductor')
def add(x1, x2):return x1 + x2x1 = torch.randn(4096, 390, device='cuda')
x2 = torch.randn(4096, 390, device='cuda')
out1 = add(x1, x2)
print(out1.shape)查看源代码"torch/__init__.py"中,torch.compile的定义:
def compile(model: _Optional[_Callable] = None,*,fullgraph: builtins.bool = False,dynamic: _Optional[builtins.bool] = None,backend: _Union[str, _Callable] = "inductor",mode: _Union[str, None] = None,options: _Optional[_Dict[str, _Union[str, builtins.int, builtins.bool]]] = None,disable: builtins.bool = False,
) -> _Union[_Callable[[_Callable[_InputT, _RetT]], _Callable[_InputT, _RetT]],_Callable[_InputT, _RetT],
]:参数说明:
model (Callable): 待优化的Module(forward Function)或Function。
fullgraph (bool): 如果是False, torch.compile会尝试在Function中发现可编译的区域;如果为True, 则要求整个Function都可以被捕获为一张图(既不包含graph break:不支持的操作或函数/动态控制流/禁用Dynamo等),否则会报错。
dynamic(bool or None):使用动态形状跟踪。如果是True,则会首先尝试生成一个尽可能动态的Kernel,避免在shape变化时重新编译。如果是False,则不会生成动态Kernel。如果是None,则自动检测是否存在动态性,并在重编译时生成一个更动态的Kernel。
backend (str or Callable):使用的backend。其中inductor是默认的backend,可用的inductor:
![]()
mode (str):
"default":平衡编译额外开销和性能。
"reduce-overhead":使用CUDA graphs(图模式)减少Python额外开销。
"max-autotune":使用Triton的矩阵乘和卷积模板,并使用CUDA graphs。
"max-autotune-no-cudagraphs":和"max-autotune"类似但不使用CUDA graphs。
mode和option的映射关系:
![]()
options (dict): 传递给backend的选项。
"epilogue_fusion":尾融合,把矩阵乘或卷积与后面的pointwise算子融合。 要求打开:max_autotune。
"max_autotune":采用profile的方法来选取最佳的矩阵乘配置。
"fallback_random":调试精度使用,确保 PyTorch 和 Triton 中生成的随机数相同。
"shape_padding": 填充矩阵形状,以更好地在 GPU 上对齐加载,特别是tensor core。
"triton.cudagraphs":打开CUDA graphs,减少Python额外开销。
"trace.enabled": 启用详细的追踪功能,生成日志和调试信息来分析代码的编译过程和性能优化。
"trace.graph_diagram":生成融合之后的计算图。
disable (bool): torch.compile不生效。
自定义Backend
通过如下代码,我们可以自定义一个Backend,输出捕获到的Fx Graph。不进行rewrite即fall back到原始的Fx Graph执行:
# fx.py
import torchdef backend(fx, inputs):print('FX IR:')print(fx.graph)print('Code:')print(fx.code)print('Inputs:')print(inputs)return fx.forward@torch.compile(backend=backend)
def add(x, y):return x + yx1 = torch.randn(4096, 390, device='cuda')
x2 = torch.randn(4096, 390, device='cuda')
out = add(x1, x2)
print(out)执行代码的输出:
(pytorch) vincent@vivi:~$ python fx.py
FX IR:
graph():%l_x_ : torch.Tensor [num_users=1] = placeholder[target=L_x_]%l_y_ : torch.Tensor [num_users=1] = placeholder[target=L_y_]%add : [num_users=1] = call_function[target=operator.add](args = (%l_x_, %l_y_), kwargs = {})return (add,)
Code:def forward(self, L_x_ : torch.Tensor, L_y_ : torch.Tensor):l_x_ = L_x_l_y_ = L_y_add = l_x_ + l_y_; l_x_ = l_y_ = Nonereturn (add,)Inputs:
[tensor([[ 1.3673, -0.3392, -1.6010, ..., 0.1647, -0.0407, 1.4280],[ 0.6986, 2.0218, -0.2573, ..., 0.0246, -0.8617, -0.7064],[-2.1198, -0.0134, -0.7237, ..., -1.2393, 0.3852, -0.2306],...,[ 0.1273, -0.5287, -0.4426, ..., -0.8578, -0.3714, -0.0530],[-0.0650, -1.4217, 2.4850, ..., -1.1343, -1.9656, -0.3294],[ 0.3080, -1.1508, 1.3278, ..., 1.1502, -0.3561, 2.0209]],device='cuda:0'), tensor([[ 0.3932, -0.7923, -0.6297, ..., 0.4287, -0.8496, 0.1566],[ 1.1430, 1.4724, 0.1836, ..., -1.4647, 0.7462, -0.0034],[ 0.3743, 0.7919, -0.2916, ..., -0.5444, -0.8867, -0.3316],...,[-0.3090, -0.5599, -0.1380, ..., -0.6273, -0.4960, -0.5486],[ 0.2018, 0.2352, -1.6057, ..., 0.2082, -0.0753, -0.8244],[ 0.1912, 0.9109, 0.3007, ..., -0.3968, -1.5722, 0.3168]],device='cuda:0')]
Output:
tensor([[ 1.7605, -1.1315, -2.2307, ..., 0.5934, -0.8904, 1.5846],[ 1.8417, 3.4943, -0.0737, ..., -1.4401, -0.1155, -0.7097],[-1.7455, 0.7784, -1.0153, ..., -1.7837, -0.5015, -0.5622],...,[-0.1817, -1.0886, -0.5806, ..., -1.4852, -0.8674, -0.6016],[ 0.1368, -1.1866, 0.8793, ..., -0.9261, -2.0409, -1.1537],[ 0.4992, -0.2399, 1.6284, ..., 0.7534, -1.9284, 2.3378]],device='cuda:0')可以看到:
- TorchDynamo成功捕获到了Fx Graph和输入。
- 函数执行并计算出正确结果。