【一天一个知识点】RAG(Retrieval-Augmented Generation,检索增强生成)构建的第一步
RAG(Retrieval-Augmented Generation,检索增强生成)构建的第一步通常是 准备知识库(构建索引)。
✅ 准备知识库(构建索引)
也就是说,在 RAG 系统中,最重要的起点是建立可供检索的“外部知识源”,并将其转化为模型可以高效查询的形式。
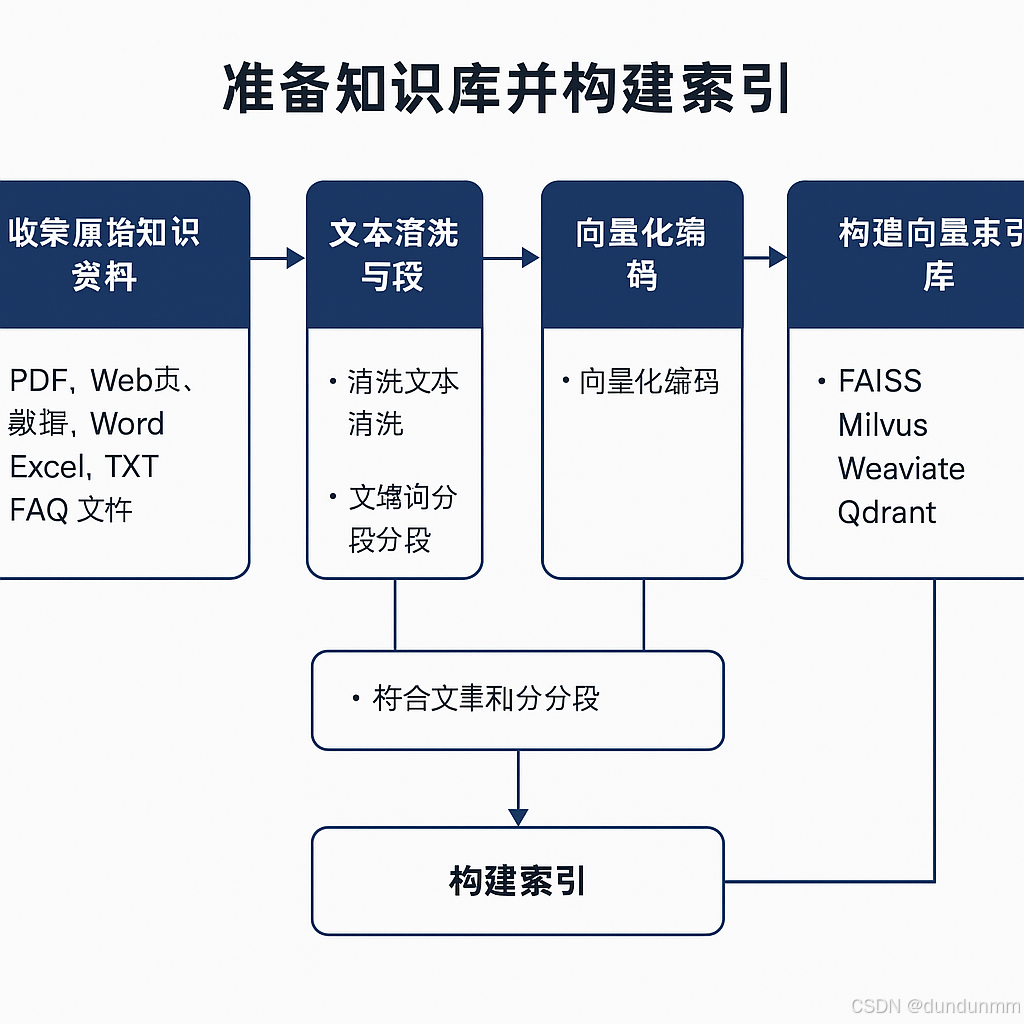
🔍 步骤1:准备知识库并构建索引
目标:将原始文本资源处理成可供 LLM 检索和调用的向量化知识库。
📁 1. 收集原始知识资料
数据来源:
-
📄 文本类:PDF、Word、TXT、网页爬虫内容
-
📊 结构类:Excel、CSV、数据库记录
-
💬 问答类:FAQ文档、客服记录
-
📚 行业文档:法规、标准、产品说明、年报等
金融举例:收集银保监会监管文件、理财产品说明书、基金合同、公司章程、业务操作手册等。
✂️ 2. 文本清洗与分段(chunking)
常见处理:
-
去除HTML标签、空白符、乱码字符
-
分段规则:
-
按段落(语义完整优先)
-
按Token长度(如每段不超过300 tokens)
-
加入标题、索引、章节号等“元信息”
-
【第3条】本行客户需完成KYC审查…… (文档:《银行客户识别制度操作细则》)
🔢 3. 向量化编码(Text Embedding)
将每个文本段转换为“向量”,表示其语义。
推荐中文模型:
-
bge-base-zh(讯飞):适配中文问答、中文搜索 -
m3e-base(ModelScope):性能优秀 -
text-embedding-3-large(OpenAI):通用、跨语言 -
GTE-large-zh(百度):金融项目中常见
from langchain.embeddings import HuggingFaceEmbeddingsembedding_model = HuggingFaceEmbeddings(model_name="bge-base-zh")
embedding_vector = embedding_model.embed_query("什么是反洗钱监管要求?")
🧠 4. 构建向量索引库(Vector Store)
向量数据库选型:
| 库名 | 特点 | 是否推荐 |
|---|---|---|
| FAISS | 本地轻量,适合原型开发 | ✅ |
| Qdrant | 支持 metadata filter,高性能 | ✅ |
| Milvus | 海量数据支持,适合生产级部署 | ✅ |
| Weaviate | 内建知识图谱支持,支持多租户 | ✅ |
| ElasticSearch | 可融合关键词+向量混合检索 | ✅(需插件) |
from langchain.vectorstores import FAISSvectorstore = FAISS.from_texts(texts=chunks, embedding=embedding_model)
vectorstore.save_local("faiss_index")
🗂️ 5. 添加元信息(metadata,可选但推荐)
这样后续检索的内容可以带上来源、章节、发布日期等信息,便于“引用可溯源”。
{"text": "客户需遵守反洗钱相关法律。","metadata": {"source": "《银行客户操作规范》","section": "第3章-合规管理","date": "2023-10-01"}
}
✅ 最终产出
你将得到一个可供 RAG 检索模块使用的结构化“知识向量库”:
[chunk_text_1] → [vector_1]
[chunk_text_2] → [vector_2]
…
📌 金融场景补充注意:
| 要素 | 注意点 |
|---|---|
| 💼 安全性 | 敏感数据需脱敏;内网部署更安全 |
| 📚 法规更新 | 自动同步策略建议(定期刷新索引) |
| 🔍 检索精度 | 使用 rerank 模型提升匹配度 |
| 🎯 问题类型 | 明确场景(客服问答 vs. 投资分析 vs. 合规审查)决定数据来源类型 |
| 📌 审计追踪 | metadata 中加入文档版本与来源路径,便于合规审查 |