谷粒商城-分布式微服务 -集群部署篇[一]
十九、k8s 集群部署
19.1 k8s 快速入门
19.1.1 简介
Kubernetes 简称 k8s。是用于自动部署,扩展和管理容器化应用程序的开源系统。
中文官网
中文社区
官方文档
社区文档
概述 | Kubernetes
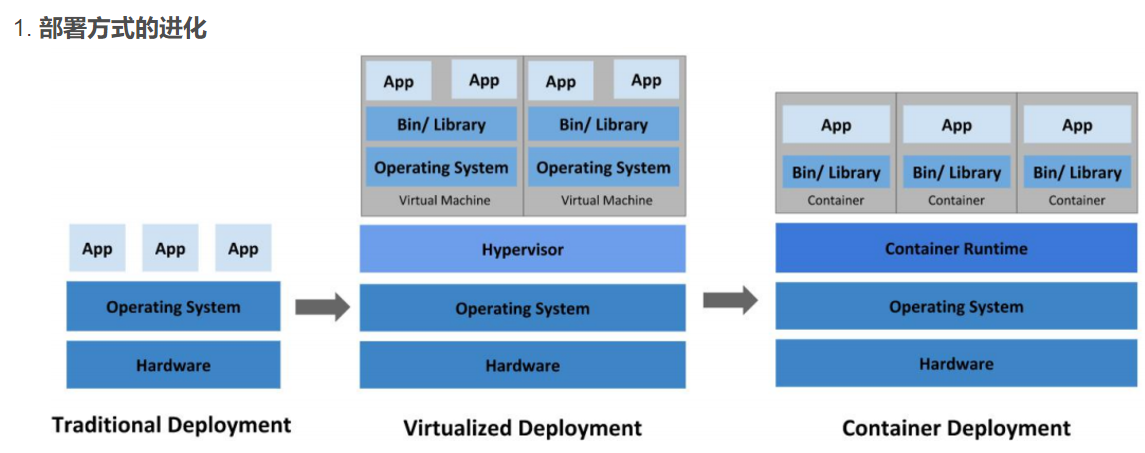
传统部署时代:
早期,各个组织是在物理服务器上运行应用程序。 由于无法限制在物理服务器中运行的应用程序资源使用,因此会导致资源分配问题。 例如,如果在同一台物理服务器上运行多个应用程序, 则可能会出现一个应用程序占用大部分资源的情况,而导致其他应用程序的性能下降。 一种解决方案是将每个应用程序都运行在不同的物理服务器上, 但是当某个应用程序资源利用率不高时,剩余资源无法被分配给其他应用程序, 而且维护许多物理服务器的成本很高。
虚拟化部署时代:
因此,虚拟化技术被引入了。虚拟化技术允许你在单个物理服务器的 CPU 上运行多台虚拟机(VM)。 虚拟化能使应用程序在不同 VM 之间被彼此隔离,且能提供一定程度的安全性, 因为一个应用程序的信息不能被另一应用程序随意访问。
虚拟化技术能够更好地利用物理服务器的资源,并且因为可轻松地添加或更新应用程序, 而因此可以具有更高的可扩缩性,以及降低硬件成本等等的好处。 通过虚拟化,你可以将一组物理资源呈现为可丢弃的虚拟机集群。
每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
容器部署时代:
容器类似于 VM,但是更宽松的隔离特性,使容器之间可以共享操作系统(OS)。 因此,容器比起 VM 被认为是更轻量级的。且与 VM 类似,每个容器都具有自己的文件系统、CPU、内存、进程空间等。 由于它们与基础架构分离,因此可以跨云和 OS 发行版本进行移植。
容器因具有许多优势而变得流行起来,例如:
- 敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
- 持续开发、集成和部署:通过快速简单的回滚(由于镜像不可变性), 提供可靠且频繁的容器镜像构建和部署。
- 关注开发与运维的分离:在构建、发布时创建应用程序容器镜像,而不是在部署时, 从而将应用程序与基础架构分离。
- 可观察性:不仅可以显示 OS 级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。
- 跨开发、测试和生产的环境一致性:在笔记本计算机上也可以和在云中运行一样的应用程序。
- 跨云和操作系统发行版本的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、 Google Kubernetes Engine 和其他任何地方运行。
- 以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。
- 松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分, 并且可以动态部署和管理 - 而不是在一台大型单机上整体运行。
- 资源隔离:可预测的应用程序性能。
- 资源利用:高效率和高密度。
2.为什么需要 Kubernetes,它能做什么?
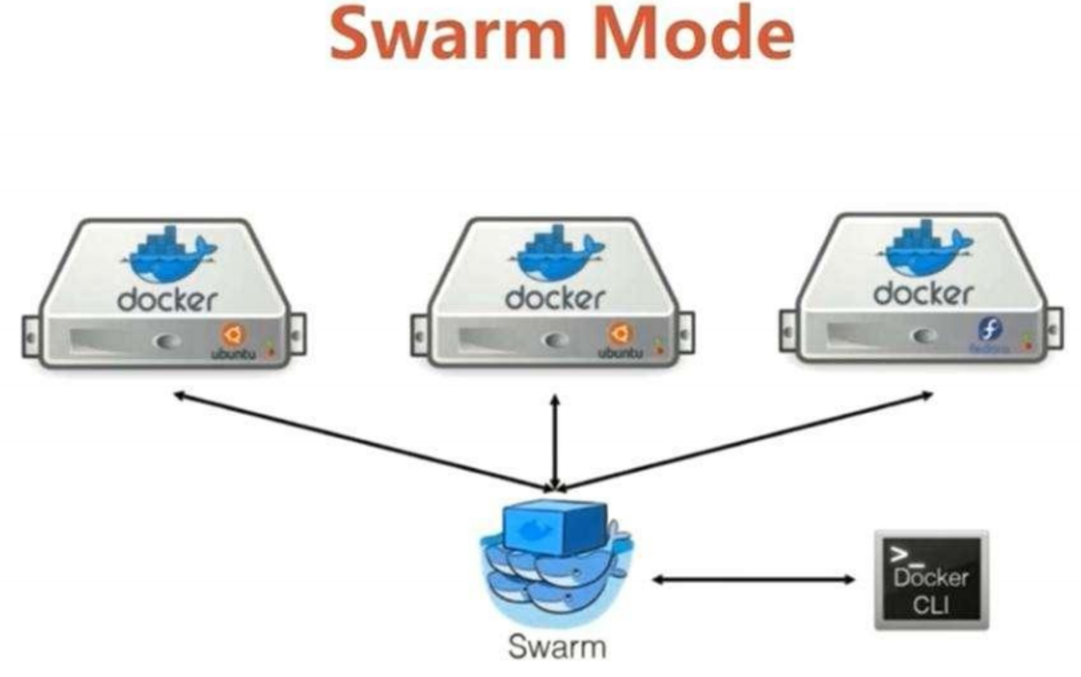
以前使用Swarm Mode方式调度,功能简单,现在使用Kubernetes
容器是打包和运行应用程序的好方式。在生产环境中, 你需要管理运行着应用程序的容器,并确保服务不会下线。 例如,如果一个容器发生故障,则你需要启动另一个容器。 如果此行为交由给系统处理,是不是会更容易一些?
这就是 Kubernetes 要来做的事情! Kubernetes 为你提供了一个可弹性运行分布式系统的框架。 Kubernetes 会满足你的扩展要求、故障转移你的应用、提供部署模式等。 例如,Kubernetes 可以轻松管理系统的 Canary (金丝雀) 部署。
Kubernetes 为你提供:
-
服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址来暴露容器。 如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。 -
存储编排
Kubernetes 允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。 -
自动部署和回滚
你可以使用 Kubernetes 描述已部署容器的所需状态, 它可以以受控的速率将实际状态更改为期望状态。 例如,你可以自动化 Kubernetes 来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。 -
自动完成装箱计算
你为 Kubernetes 提供许多节点组成的集群,在这个集群上运行容器化的任务。 你告诉 Kubernetes 每个容器需要多少 CPU 和内存 (RAM)。Kubernetes 可以将这些容器按实际情况调度到你的节点上,以最佳方式利用你的资源。 -
自我修复
Kubernetes 将重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器, 并且在准备好服务之前不将其通告给客户端。 -
密钥与配置管理
Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 SSH 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。 -
批处理执行 除了服务外,Kubernetes 还可以管理你的批处理和 CI(持续集成)工作负载,如有需要,可以替换失败的容器。
-
水平扩缩 使用简单的命令、用户界面或根据 CPU 使用率自动对你的应用进行扩缩。
-
IPv4/IPv6 双栈 为 Pod(容器组)和 Service(服务)分配 IPv4 和 IPv6 地址。
-
为可扩展性设计 在不改变上游源代码的情况下为你的 Kubernetes 集群添加功能。
3.Kubernetes 不是什么
Kubernetes 不是传统的、包罗万象的 PaaS(平台即服务)系统。 由于 Kubernetes 是在容器级别运行,而非在硬件级别,它提供了 PaaS 产品共有的一些普遍适用的功能, 例如部署、扩展、负载均衡,允许用户集成他们的日志记录、监控和警报方案。 但是,Kubernetes 不是单体式(monolithic)系统,那些默认解决方案都是可选、可插拔的。 Kubernetes 为构建开发人员平台提供了基础,但是在重要的地方保留了用户选择权,能有更高的灵活性。
Kubernetes:
- 不限制支持的应用程序类型。 Kubernetes 旨在支持极其多种多样的工作负载,包括无状态、有状态和数据处理工作负载。 如果应用程序可以在容器中运行,那么它应该可以在 Kubernetes 上很好地运行。
- 不部署源代码,也不构建你的应用程序。 持续集成(CI)、交付和部署(CI/CD)工作流取决于组织的文化和偏好以及技术要求。
- 不提供应用程序级别的服务作为内置服务,例如中间件(例如消息中间件)、 数据处理框架(例如 Spark)、数据库(例如 MySQL)、缓存、集群存储系统 (例如 Ceph)。这样的组件可以在 Kubernetes 上运行,并且/或者可以由运行在 Kubernetes 上的应用程序通过可移植机制(例如开放服务代理)来访问。
- 不是日志记录、监视或警报的解决方案。 它集成了一些功能作为概念证明,并提供了收集和导出指标的机制。
- 不提供也不要求配置用的语言、系统(例如 jsonnet),它提供了声明性 API, 该声明性 API 可以由任意形式的声明性规范所构成。
- 不提供也不采用任何全面的机器配置、维护、管理或自我修复系统。
- 此外,Kubernetes 不仅仅是一个编排系统,实际上它消除了编排的需要。 编排的技术定义是执行已定义的工作流程:首先执行 A,然后执行 B,再执行 C。 而 Kubernetes 包含了一组独立可组合的控制过程,可以持续地将当前状态驱动到所提供的预期状态。 你不需要在乎如何从 A 移动到 C,也不需要集中控制,这使得系统更易于使用且功能更强大、 系统更健壮,更为弹性和可扩展。
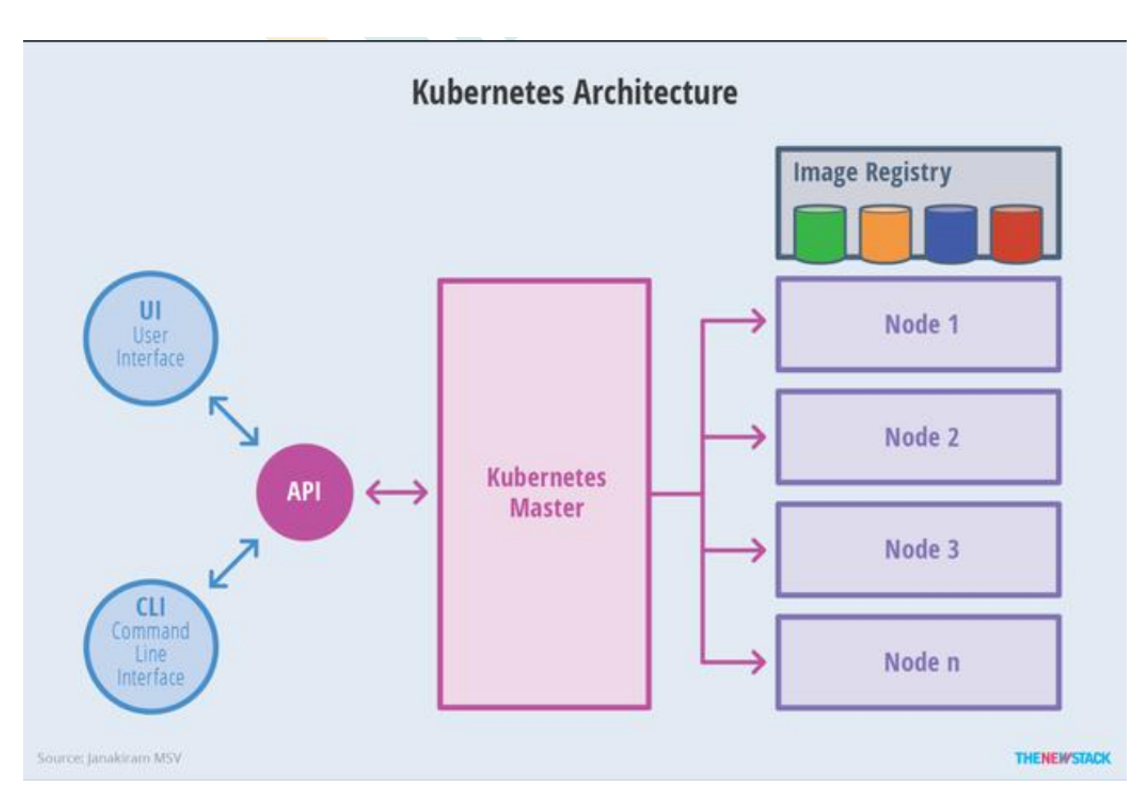
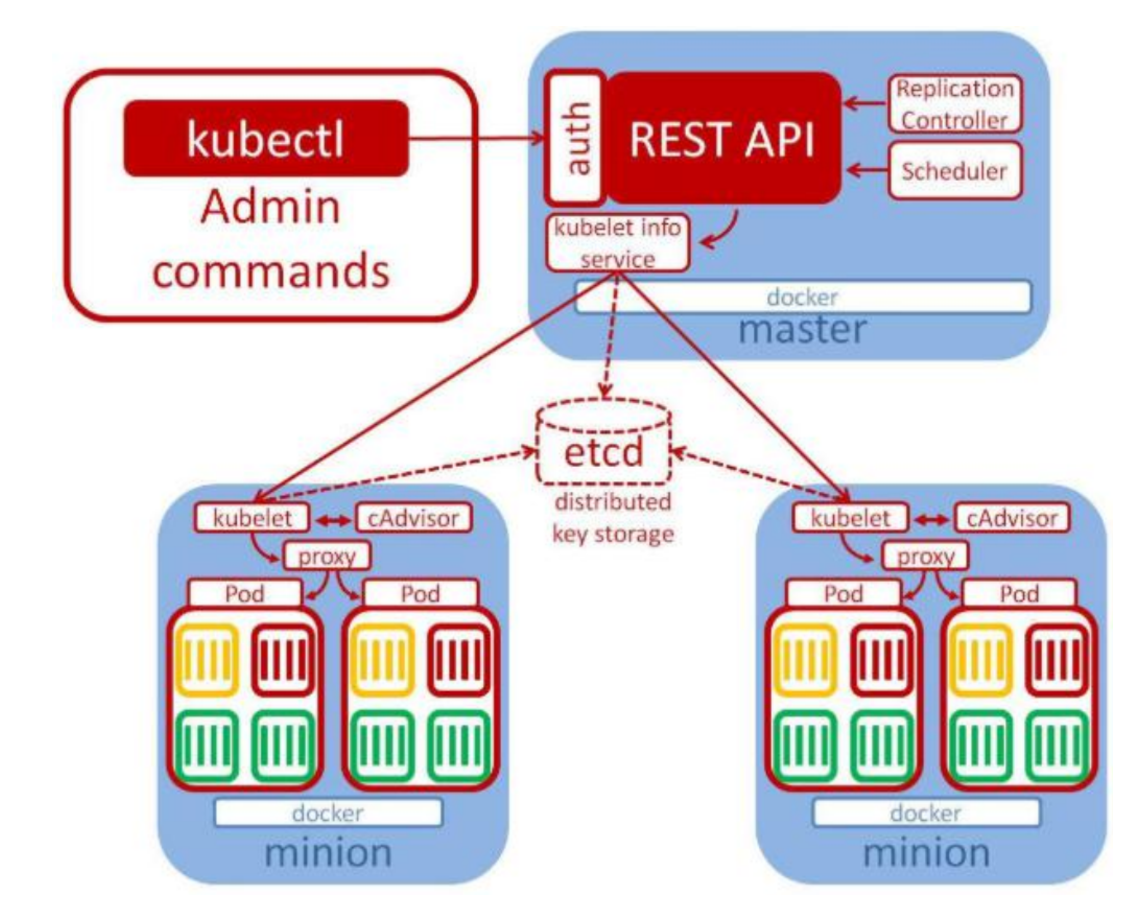
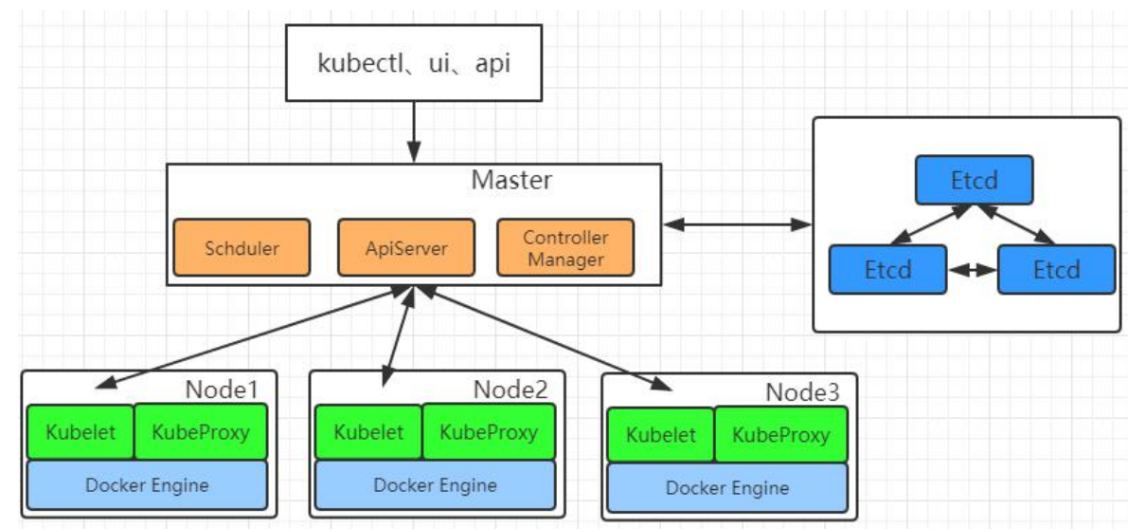
19.1.2 架构
1.整体主从方式
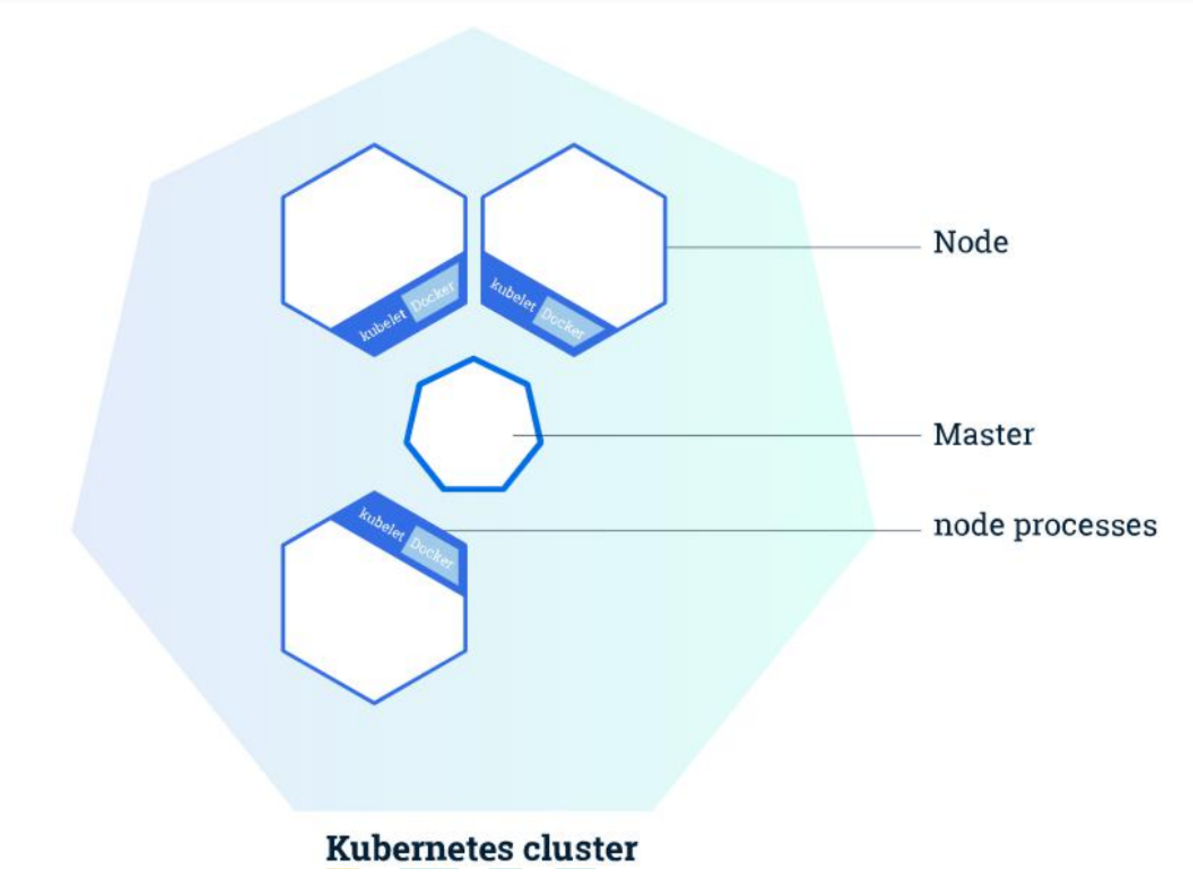
2.Master 节点架构
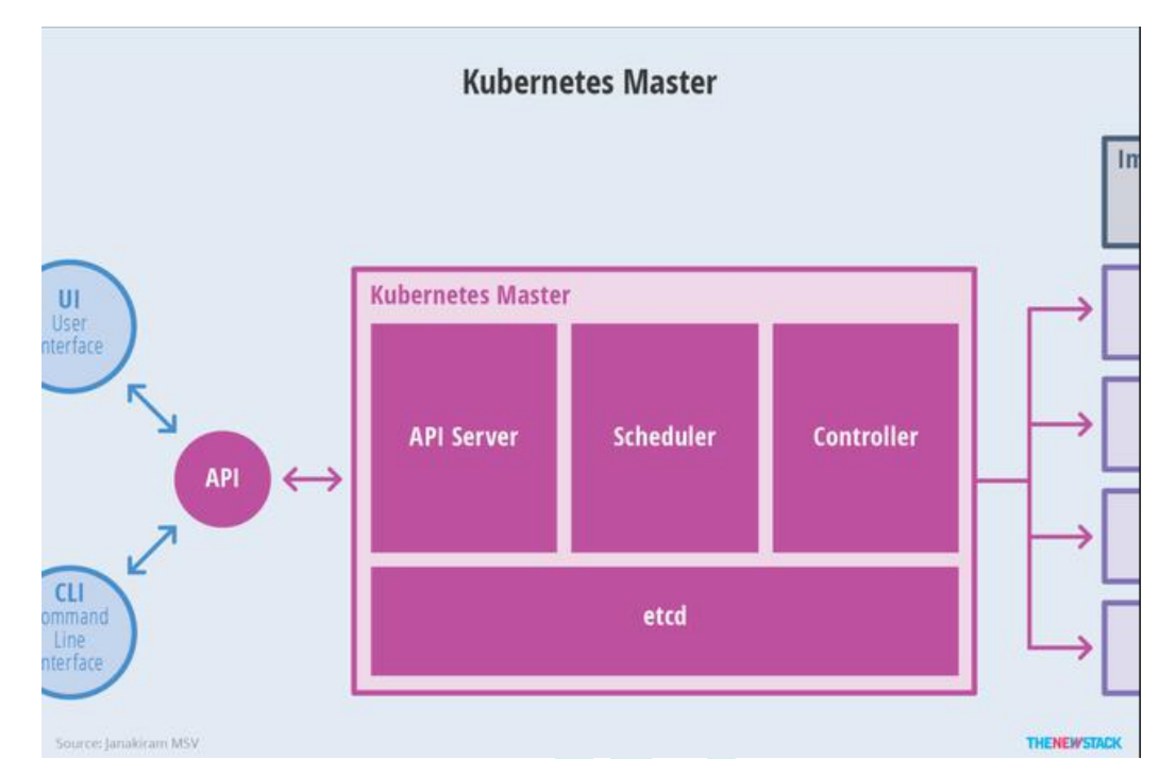
- kube-apiserver
- 对外暴露 K8S 的 api 接口,是外界进行资源操作的唯一入口
- 提供认证、授权、访问控制、API 注册和发现等机制
- etcd
- etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。
- Kubernetes 集群的 etcd 数据库通常需要有个备份计划
- kube-scheduler
- 主节点上的组件,该组件监视那些新创建的未指定运行节点的 Pod,并选择节点让 Pod 在上面运行。
- 所有对 k8s 的集群操作,都必须经过主节点进行调度
- kube-controller-manager
- 在主节点上运行控制器的组件
- 这些控制器包括:
- 节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应。
- 副本控制器(Replication Controller): 负责为系统中的每个副本控制器对象维护正确数量的 Pod。
- 端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service与 Pod)。
- 服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌
3.Node 节点架构
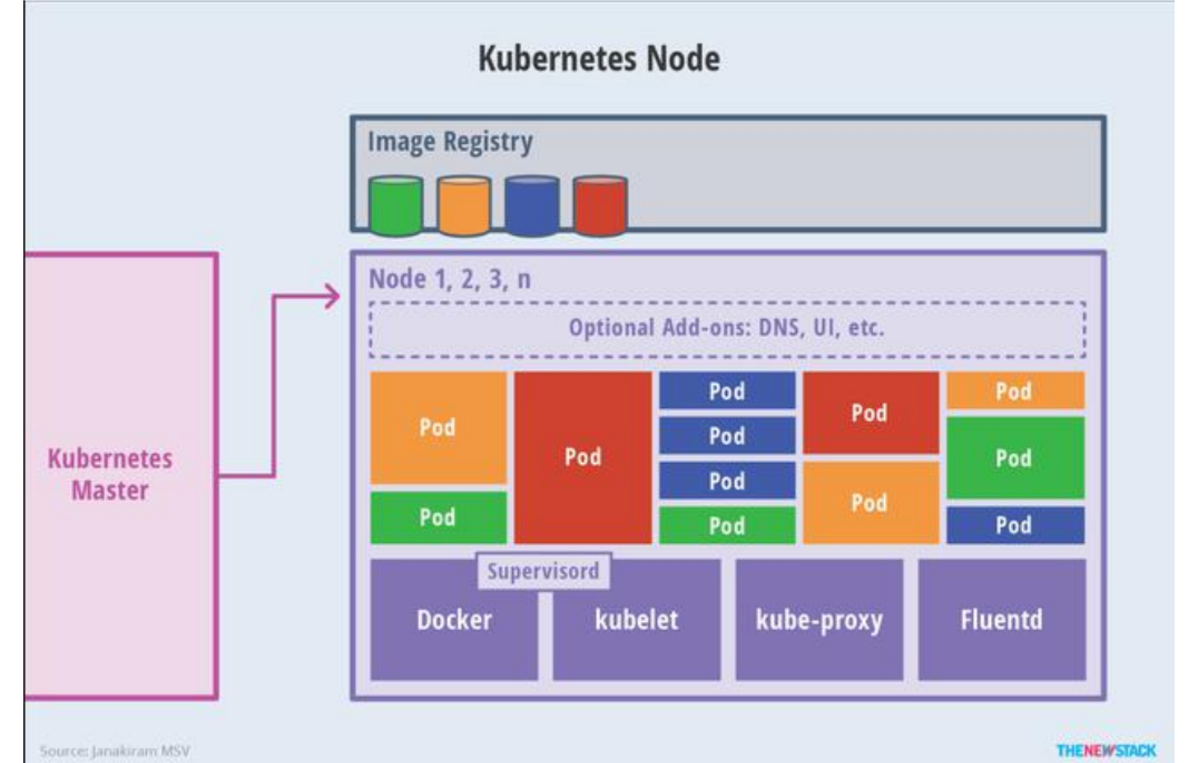
- kubelet
- 一个在集群中每个节点上运行的代理。它保证容器都运行在 Pod 中。
- 负责维护容器的生命周期,同时也负责 Volume(CSI)和网络(CNI)的管理;
- kube-proxy
- 负责为 Service 提供 cluster 内部的服务发现和负载均衡;
- 容器运行环境(Container Runtime)
- 容器运行环境是负责运行容器的软件。
- Kubernetes 支持多个容器运行环境: Docker、 containerd、cri-o、 rktlet 以及任何实现 Kubernetes CRI (容器运行环境接口)。
- fluentd
- 是一个守护进程,它有助于提供集群层面日志 集群层面的日志
19.1.3 概念
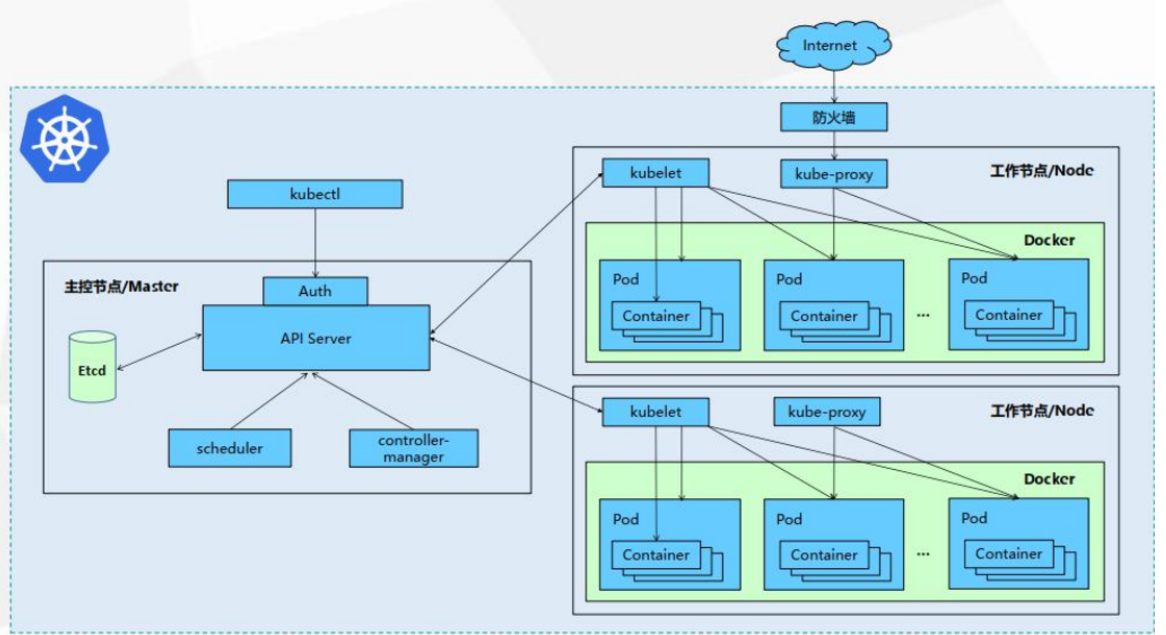
-
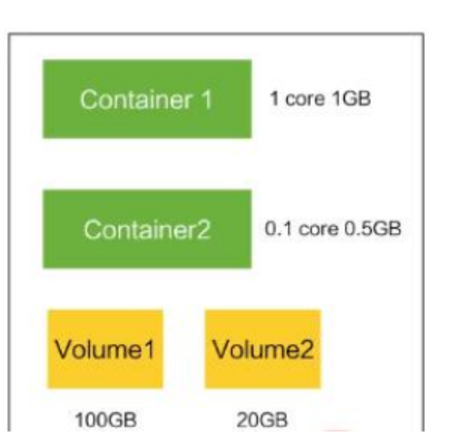
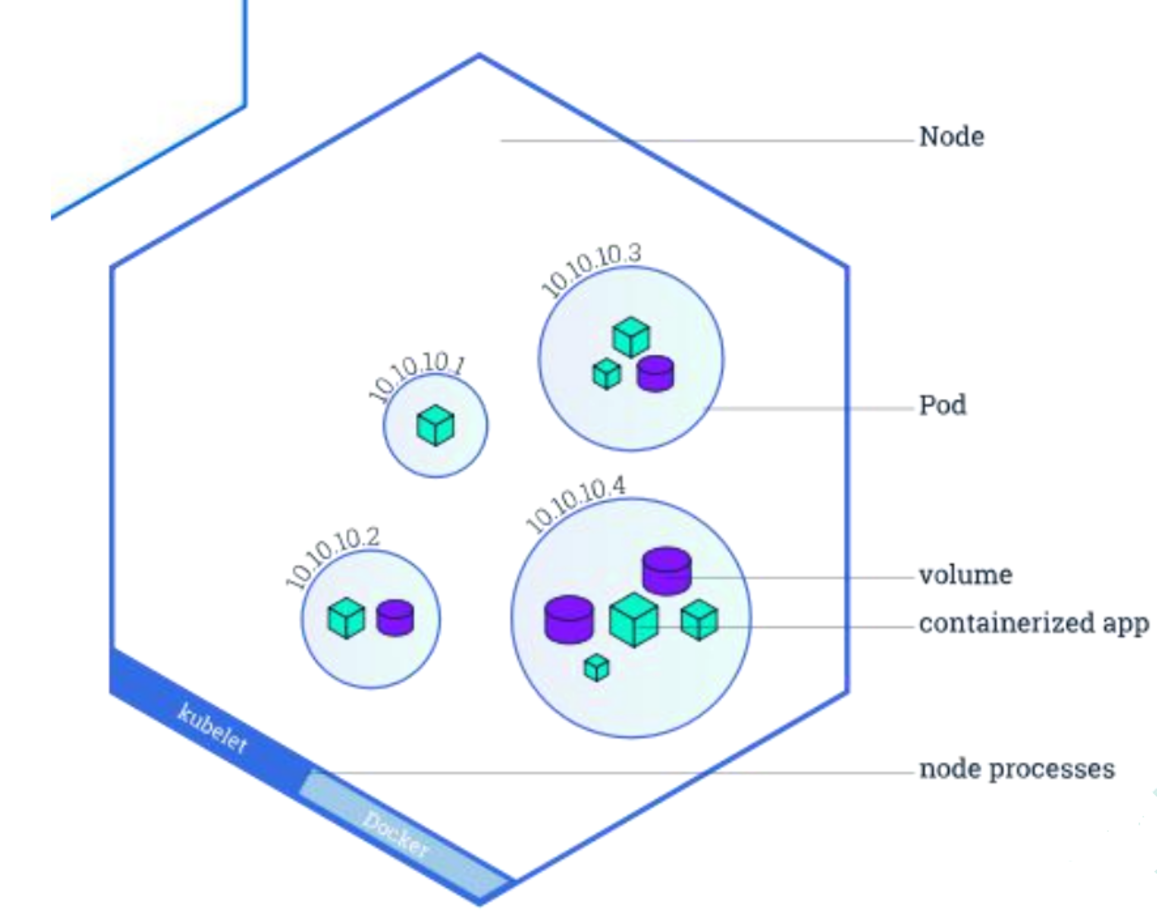
Container:容器,可以是 docker 启动的一个容器
-
Pod:
- k8s 使用 Pod 来组织一组容器
- 一个 Pod 中的所有容器共享同一网络。
- Pod 是 k8s 中的最小部署单元
-
Volume
- 声明在 Pod 容器中可访问的文件目录
- 可以被挂载在 Pod 中一个或多个容器指定路径下
- 支持多种后端存储抽象(本地存储,分布式存储,云存储…)
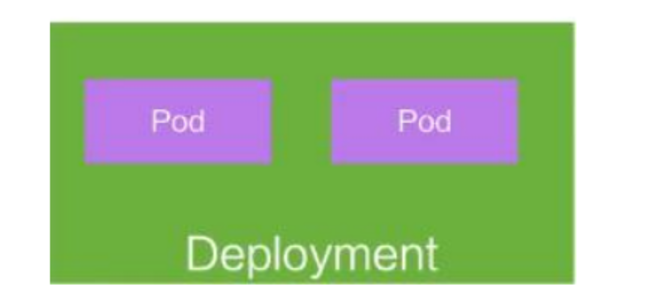
Controllers:更高层次对象,部署和管理 Pod;
- ReplicaSet:确保预期的 Pod 副本数量
- Deplotment:无状态应用部署
- StatefulSet:有状态应用部署
- DaemonSet:确保所有 Node 都运行一个指定 Pod
- Job:一次性任务
- Cronjob:定时任务
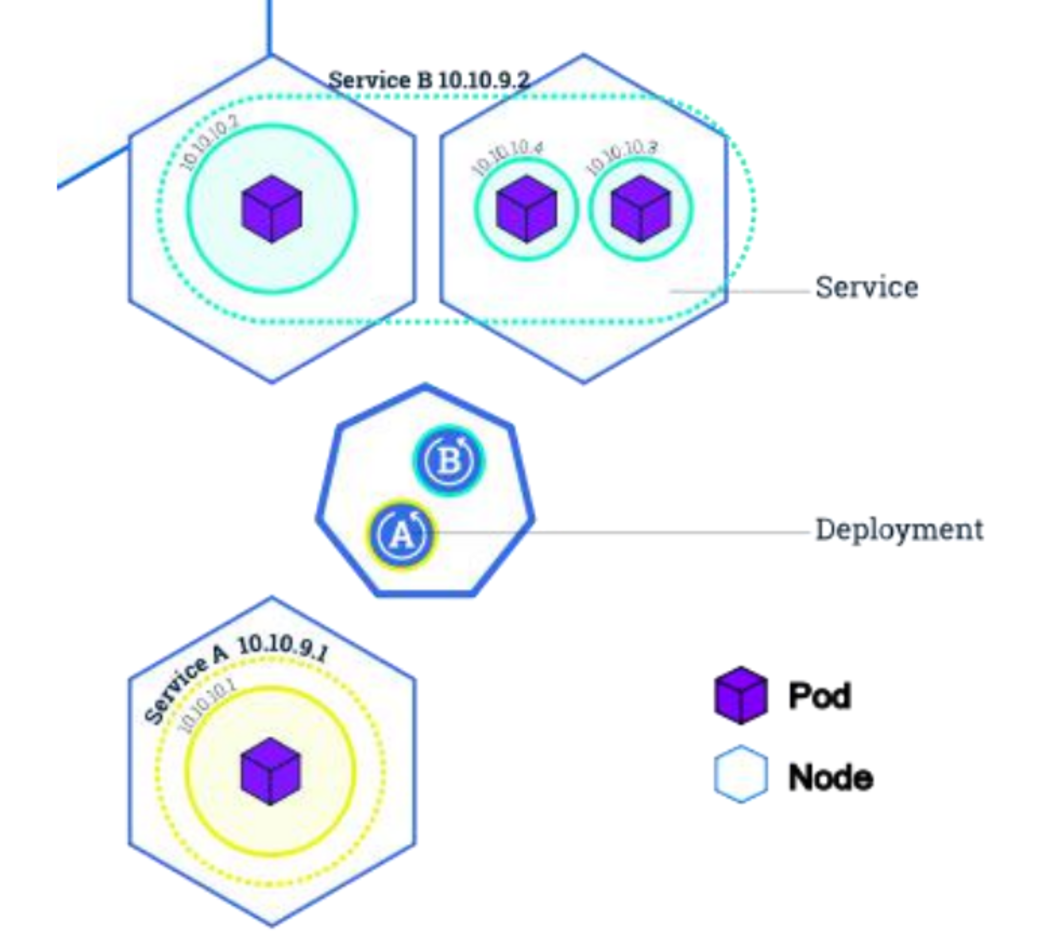
Deployment:
- 定义一组 Pod 的副本数目、版本等
- 通过控制器(Controller)维持 Pod 数目(自动回复失败的 Pod)
- 通过控制器以指定的策略控制版本(滚动升级,回滚等)
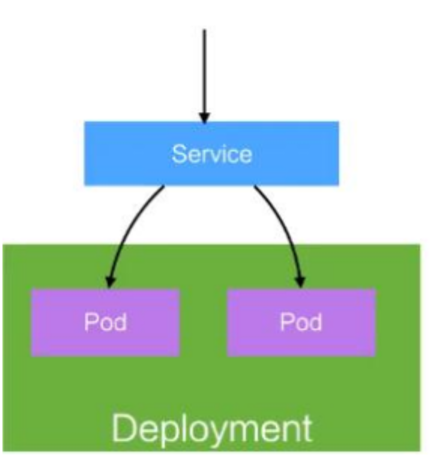
Service
- 定义一组 Pod 的访问策略
- Pod 的负载均衡,提供一个或者多个 Pod 的稳定访问地址
- 支持多种方式(ClusterIP、NodePort、LoadBalance)
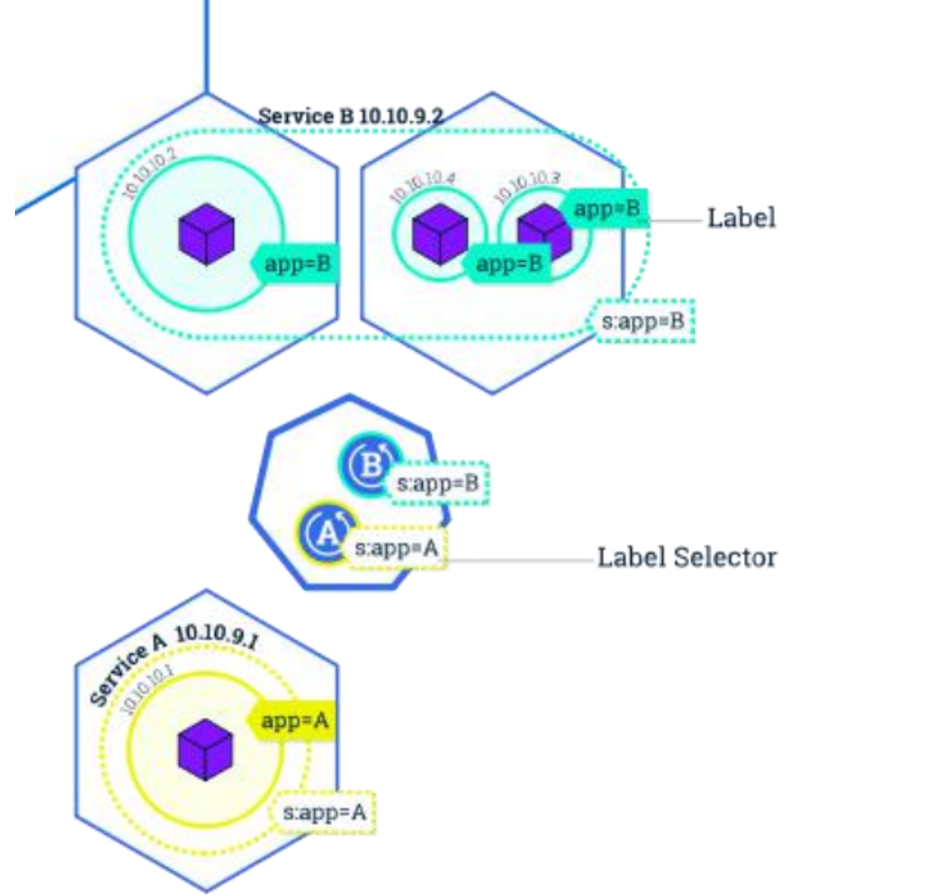
Label:标签,用于对象资源的查询,筛选

Namespace:命名空间,逻辑隔离
- 一个集群内部的逻辑隔离机制(鉴权,资源)
- 每个资源都属于一个 namespace
- 同一个 namespace 所有资源名不能重复
- 不同 namespace 可以资源名重复
API:
我们通过 kubernetes 的 API 来操作整个集群。
可以通过 kubectl、ui、curl 最终发送 http+json/yaml 方式的请求给 API Server,然后控制 k8s集群。k8s 里的所有的资源对象都可以采用 yaml 或 JSON 格式的文件定义或描述。

19.1.4 快速体验
1、安装 minikube
https://github.com/kubernetes/minikube/releases
下载 minikube-windows-amd64.exe 改名为 minikube.exe
打开 VirtualBox,打开 cmd,
运行
minikube start --vm-driver=virtualbox --registry-mirror=https://registry.docker-cn.com
等待 20 分钟左右即可
2、体验 nginx 部署升级

19.1.5 流程叙述
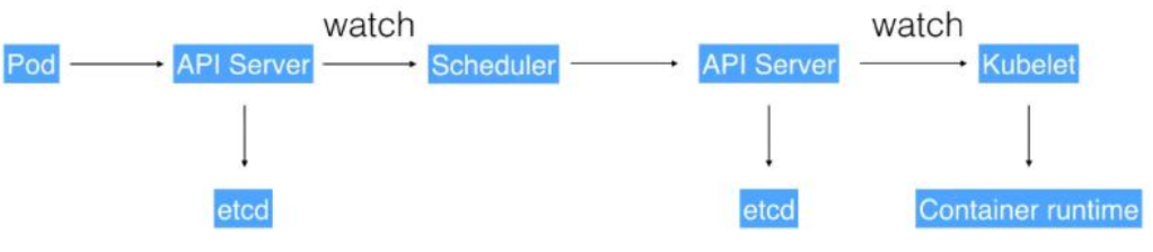
- 通过 Kubectl 提交一个创建 RC(Replication Controller)的请求,该请求通过 APIServer被写入 etcd 中
- 此时 Controller Manager 通过 API Server 的监听资源变化的接口监听到此 RC 事件
- 分析之后,发现当前集群中还没有它所对应的 Pod 实例,
- 于是根据 RC 里的 Pod 模板定义生成一个 Pod 对象,通过 APIServer 写入 etcd
- 此事件被 Scheduler 发现,它立即执行一个复杂的调度流程,为这个新 Pod 选定一个落户的 Node,然后通过 API Server 讲这一结果写入到 etcd 中,
- 目标 Node 上运行的 Kubelet 进程通过 APIServer 监测到这个“新生的”Pod,并按照它的定义,启动该 Pod 并任劳任怨地负责它的下半生,直到 Pod 的生命结束。
- 随后,我们通过 Kubectl 提交一个新的映射到该 Pod 的 Service 的创建请求
- ControllerManager 通过 Label 标签查询到关联的 Pod 实例,然后生成 Service 的Endpoints 信息,并通过 APIServer 写入到 etcd 中,
- 接下来,所有 Node 上运行的 Proxy 进程通过 APIServer 查询并监听 Service 对象与其对应的 Endpoints 信息,建立一个软件方式的负载均衡器来实现 Service 访问到后端Pod 的流量转发功能。
k8s 里的所有的资源对象都可以采用 yaml 或 JSON 格式的文件定义或描述
19.2 k8s 集群安装
19.2.1 kubeadm
kubeadm 是官方社区推出的一个用于快速部署 kubernetes 集群的工具。
这个工具能通过两条指令完成一个 kubernetes 集群的部署:
-
创建一个 Master 节点
$ kubeadm init -
将一个 Node 节点加入到当前集群中
$ kubeadm join <Master 节点的 IP 和端口 >
19.2.2 前置要求
一台或多台机器,操作系统 CentOS7.x-86_x64
硬件配置:2GB 或更多 RAM,2 个 CPU 或更多 CPU,硬盘 30GB 或更多
集群中所有机器之间网络互通
可以访问外网,需要拉取镜像
禁止 swap 分区
19.2.3 部署步骤
- 在所有节点上安装 Docker 和 kubeadm
- 部署 Kubernetes Master
- 部署容器网络插件
- 部署 Kubernetes Node,将节点加入 Kubernetes 集群中
- 部署 Dashboard Web 页面,可视化查看 Kubernetes 资源
19.2.4 环境准备
1、准备工作
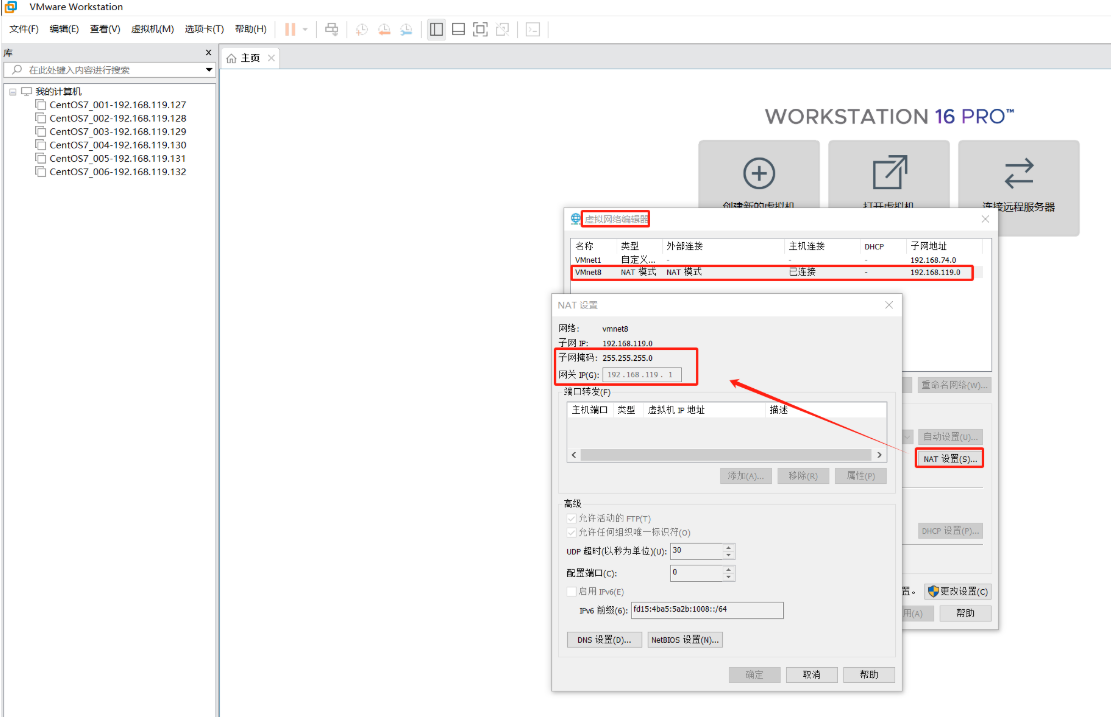
- 我们可以使用 VMware 快速创建三个虚拟机。虚拟机启动前先设置 VMware 的主机网络。现全部统一为 192.168.119.1,以后所有虚拟机都是 119.x 的 ip 地址
-
设置虚拟机存储目录,防止硬盘空间不足
2、启动三个虚拟机
- 使用我们提供的 vagrant 文件,复制到非中文无空格目录下,运行 vagrant up 启动三个虚拟机。其实 vagrant 完全可以一键部署全部 k8s 集群。https://github.com/rootsongjc/kubernetes-vagrant-centos-cluster
-
进入三个虚拟机,开启 root 的密码访问权限。
所有虚拟机设置为 node1分配 4g、4C;node2、node3 分配 16g,16C设置好 NAT 网络
3、设置 linux 环境(三个节点都执行)
关闭防火墙:
systemctl stop firewalld
systemctl disable firewalld
关闭 selinux:
sed -i 's/enforcing/disabled/' /etc/selinux/config
setenforce 0
关闭 swap:
swapoff -a #临时
sed -ri 's/.*swap.*/#&/' /etc/fstab #永久
free -g #验证,swap 必须为 0;
添加主机名与 IP 对应关系
vi /etc/hosts
192.168.119.133 k8s-node1
192.168.119.134 k8s-node2
192.168.119.135 k8s-node3hostnamectl set-hostname <newhostname>:指定新的 hostname
su 切换过来
wq保存,然后重启每台服务
- 将桥接的 IPv4 流量传递到 iptables 的链:
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF# 加载参数
sysctl --system
19.2.5 所有节点安装 Docker、kubeadm、kubelet、kubectl
Kubernetes 默认 CRI(容器运行时)为 Docker,因此先安装 Docker。
1、安装 docker
1.卸载系统之前的 docker
# 安装前先更新yum,不然有可能出现本机无法连接虚拟机的mysql、redis等
sudo yum update
# 卸载系统之前的docker,以及 docker-cli
sudo yum remove docker-ce docker-ce-cli containerd.io
# 卸载系统之前的docker
sudo yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine
2.安装 Docker-CE
(1)、安装必须的依赖
sudo yum install -y yum-utils \
device-mapper-persistent-data \
lvm2
(2)、设置 docker repo 的 yum 位置
# 配置镜像
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
(3)、安装 docker,以及 docker-cli
该命令安装docker以后,kubeadm初始化时会报错,提示版本不兼容
sudo yum install -y docker-ce docker-ce-cli containerd.io
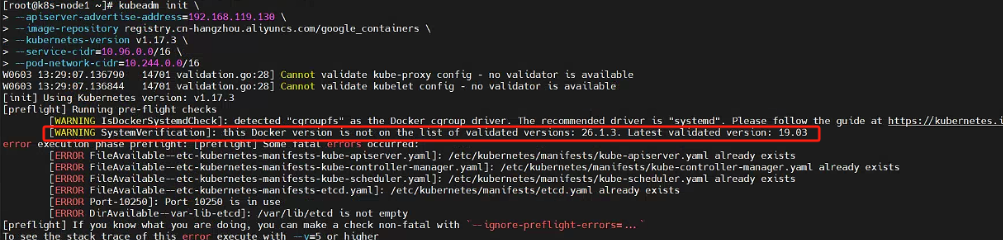
所以我们使用推荐docker版本
sudo yum install docker-ce-3:19.03.15-3.el7.x86_64 docker-ce-cli-19.03.15-3.el7.x86_64 containerd.io
3.配置 docker 加速
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{"registry-mirrors": ["https://chqac97z.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
4.启动 docker & 设置 docker 开机自启
systemctl start docker
systemctl enable docker
基础环境准备好,可以给三个虚拟机备份一下;为 node1分配 4g、4C;gnode2、node3 分配 16g,16C。方便未来侧测试
2、添加阿里云 yum 源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
3、安装 kubeadm,kubelet 和 kubectl
yum list|grep kube
yum install -y kubelet-1.17.3 kubeadm-1.17.3 kubectl-1.17.3
systemctl enable kubelet
systemctl start kubelet
19.2.6 部署 k8s-master(master节点)
1.下载镜像
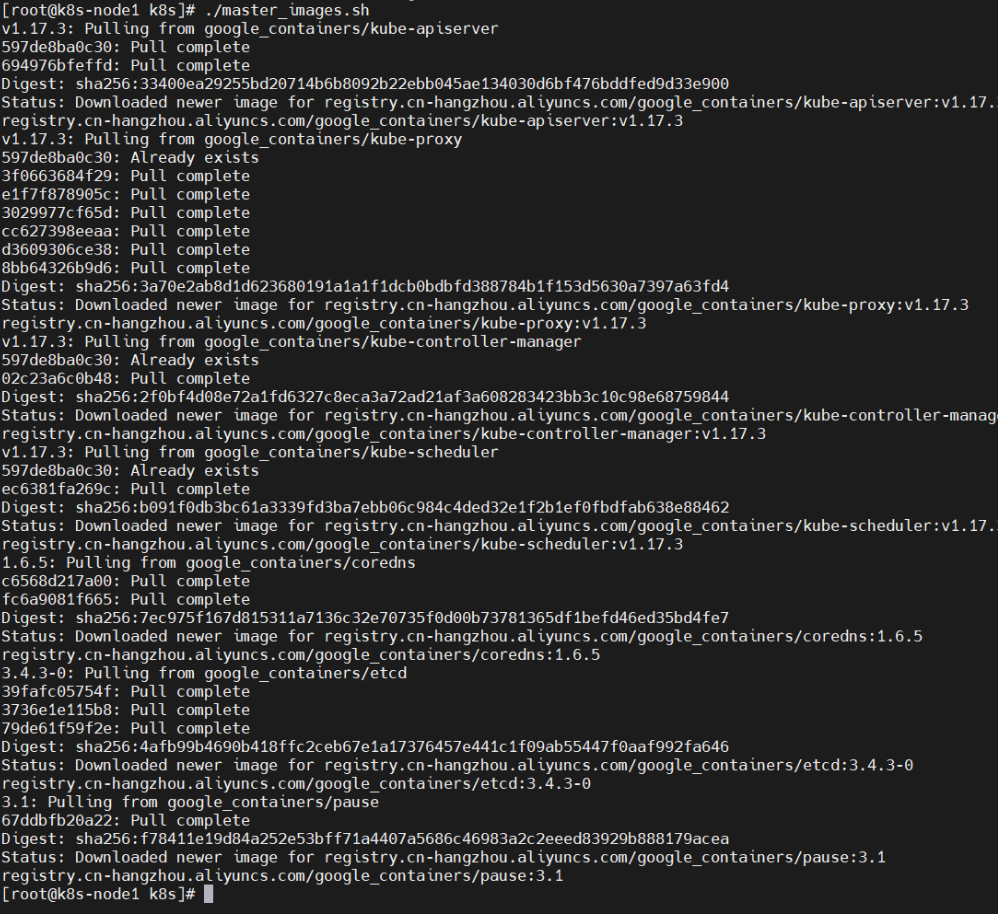
由于需要下载好多镜像,我们也不知道下载进入如何,此时我们通过运行提供的脚本来下载镜像,可以看到下载进度
(1)、上传k8s文件到主节点
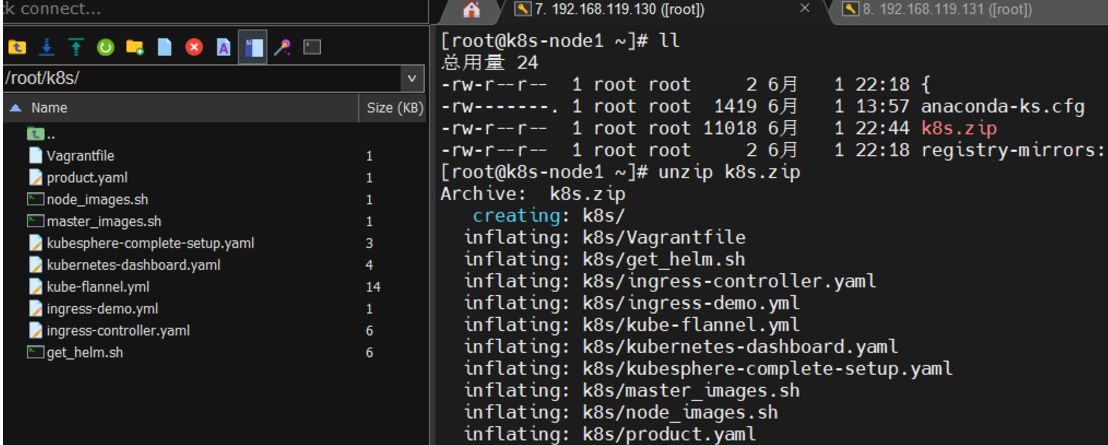
解压发现没有该命令unzip,安装unzip命令
sudo yum update
sudo yum install unzip
(2)、可以看到master_images.sh脚本内容
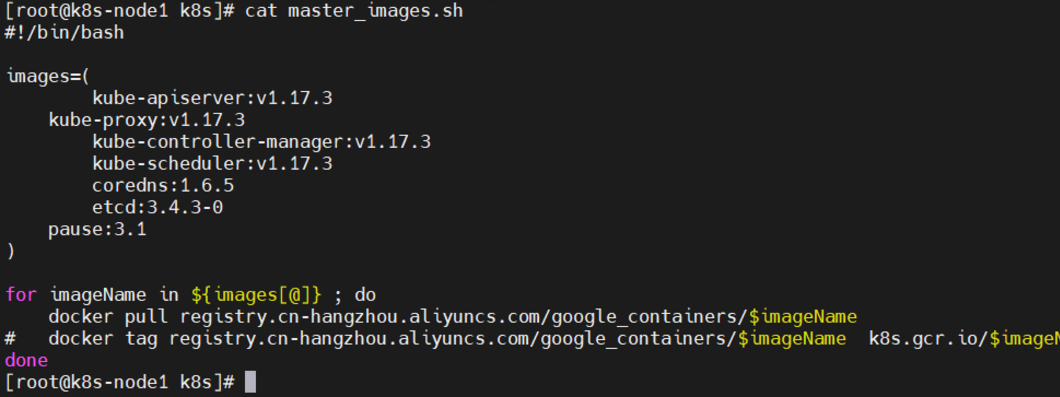
我们只需要启动该脚本就可以了
(3)、我们看到master_images.sh脚本没有执行权限,我们这个时候还不能启动脚本下载镜像,修改权限
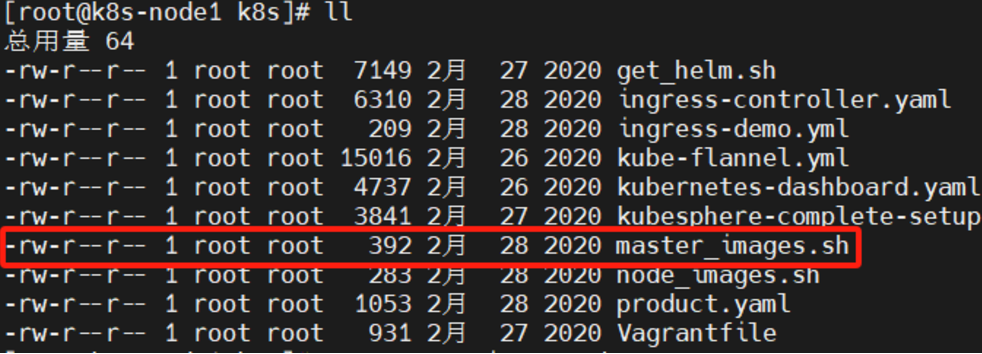
chmod 700 master_images.sh
(4)、启动脚本
./master_images.sh
2.master 节点初始化
kubeadm init \
--apiserver-advertise-address=192.168.119.133 \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--kubernetes-version v1.17.3 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=10.244.0.0/16
由于默认拉取镜像地址 k8s.gcr.io 国内无法访问,这里指定阿里云镜像仓库地址。可以手动
按照我们的 images.sh 先拉取镜像,地址变为 registry.aliyuncs.com/google_containers 也可以。
科普:无类别域间路由(Classless Inter-Domain Routing、CIDR)是一个用于给用户分配 IP
地址以及在互联网上有效地路由 IP 数据包的对 IP 地址进行归类的方法。
拉取可能失败,需要下载镜像。
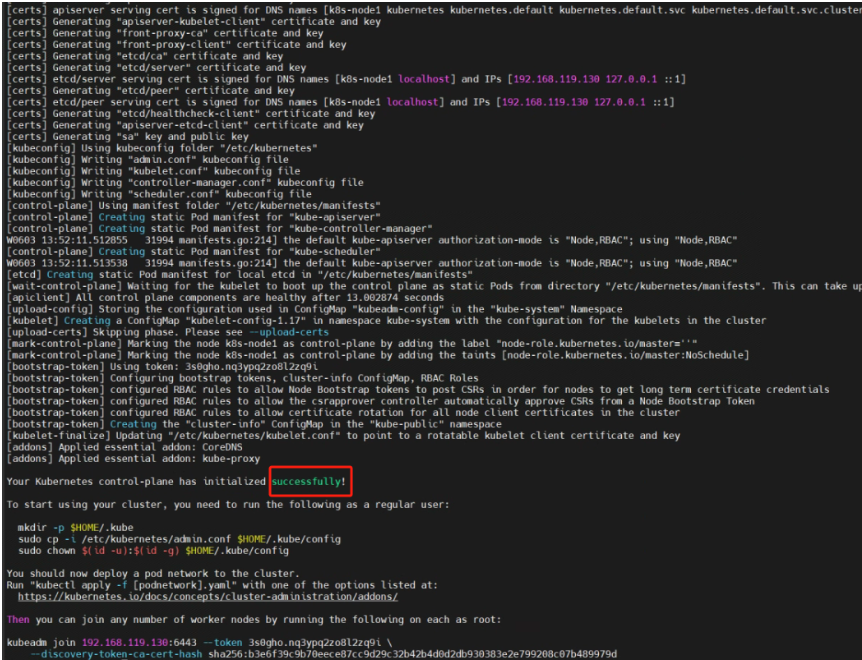
运行完成提前复制:加入集群的令牌
【注意】
初始化的时候报错
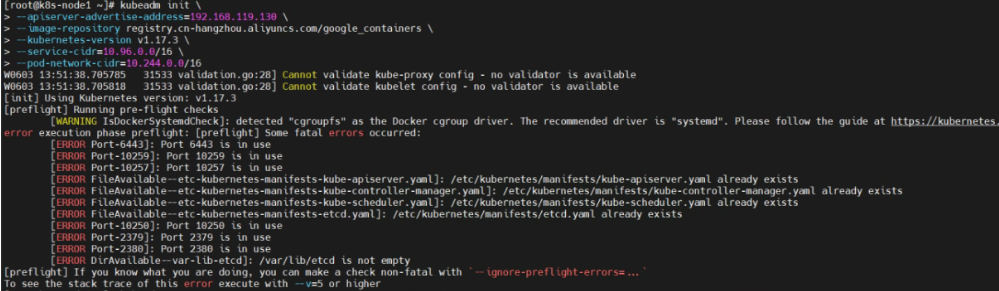
尝试推倒重来,重置k8s集群
kubeadm reset

提示是否确认,是。然后成功重置
3.测试 kubectl(主节点执行)
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
获取所有节点
kubectl get nodes
目前 master 状态为 notready。等待网络加入完成即可。
查看 kubelet 日志
journalctl -u kubelet
先记录下来,等网络加入完成才可以在从节点操作
kubeadm join 192.168.119.130:6443 --token qyc2xb.1ygxll0plko0te5n \
--discovery-token-ca-cert-hash sha256:6bfd3aeba6116f586b39f15428e6f358055fb14b819414785f7b4499da9255fb
19.2.7 安装 Pod 网络插件(CNI)(master节点)
初始化完成后,对集群进行网络配置
kubectl apply -f k8s/kube-flannel.yml
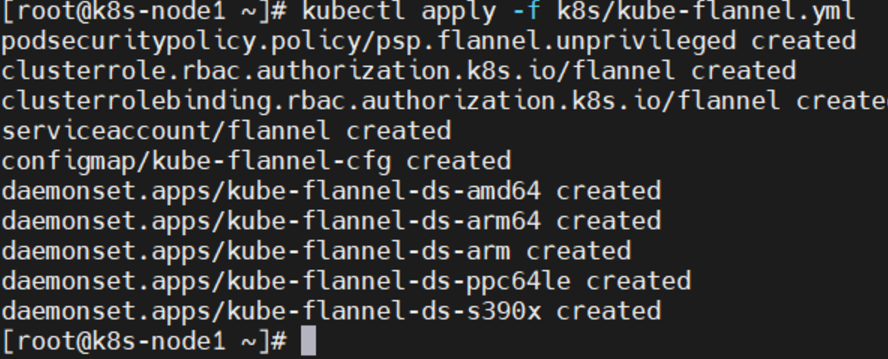
kubectl apply -f \
https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
以上地址可能被墙,大家获取上传我们下载好的 flannel.yml 运行即可,同时 flannel.yml 中
指定的 images 访问不到可以去 docker hub 找一个
wget yml 的地址
vi 修改 yml 所有 amd64 的地址都修改了即可。
等待大约 3 分钟
kubectl get pods -n kube-system 查看指定名称空间的 pods
kubectl get pods --all-namespaces 查看所有名称空间的 pods
ip link set cni0 down 如果网络出现问题,关闭 cni0,重启虚拟机继续测试
执行 watch kubectl get pod -n kube-system -o wide 监控 pod 进度
等 3-10 分钟,完全都是 running 以后继续

【注意】
问题一:(主节点)
k8s应用flannel状态为Init:ImagePullBackOff
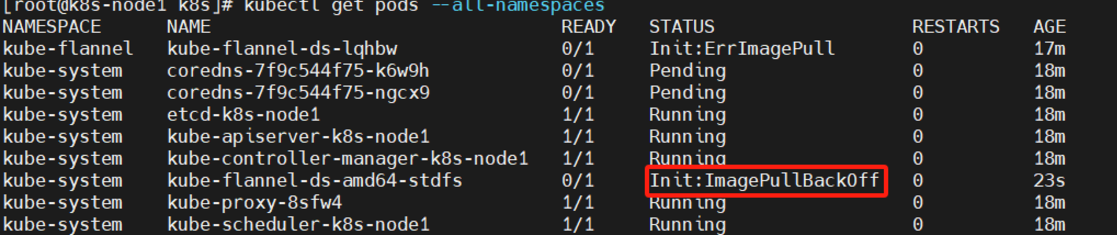
查看kube-flannel.yml文件时发现quay.io/coreos/flannel:v0.11.0-amd64
quay.io网站目前国内无法访问
解决方法:
查看kube-flannel.yml需要什么image
[root@k8s-node1 k8s]# grep image kube-flannel.ymlimage: quay.io/coreos/flannel:v0.11.0-amd64image: quay.io/coreos/flannel:v0.11.0-amd64image: quay.io/coreos/flannel:v0.11.0-arm64image: quay.io/coreos/flannel:v0.11.0-arm64image: quay.io/coreos/flannel:v0.11.0-armimage: quay.io/coreos/flannel:v0.11.0-armimage: quay.io/coreos/flannel:v0.11.0-ppc64leimage: quay.io/coreos/flannel:v0.11.0-ppc64leimage: quay.io/coreos/flannel:v0.11.0-s390ximage: quay.io/coreos/flannel:v0.11.0-s390x
下载flannel:v0.11.0-amd64导入到docker中
可以去https://github.com/flannel-io/flannel/releases/tag/v0.11.0官方仓库下载镜像
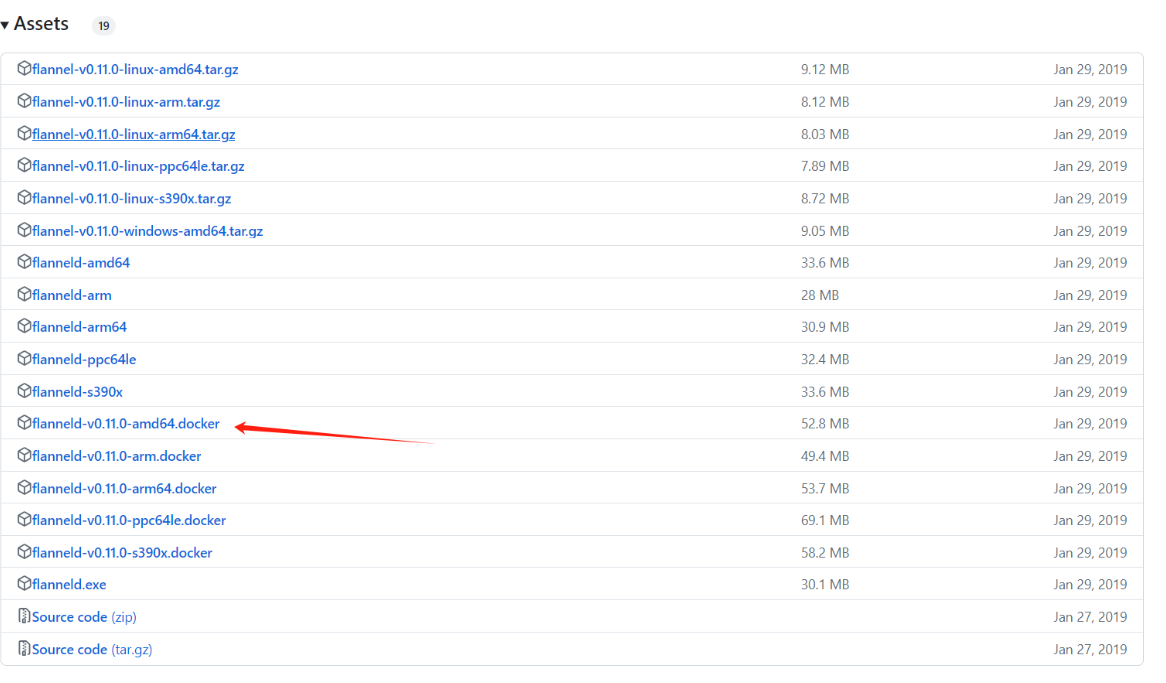
mkdir /opt/cni-plugins
[root@k8s-node1 cni-plugins]# docker load < flanneld-v0.11.0-amd64.docker
7bff100f35cb: Loading layer [==================================================>] 4.672MB/4.672MB
5d3f68f6da8f: Loading layer [==================================================>] 9.526MB/9.526MB
9b48060f404d: Loading layer [==================================================>] 5.912MB/5.912MB
3f3a4ce2b719: Loading layer [==================================================>] 35.25MB/35.25MB
9ce0bb155166: Loading layer [==================================================>] 5.12kB/5.12kB
Loaded image: quay.io/coreos/flannel:v0.11.0-amd64
[root@k8s-node1 cni-plugins]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy v1.17.3 ae853e93800d 4 years ago 116MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver v1.17.3 90d27391b780 4 years ago 171MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager v1.17.3 b0f1517c1f4b 4 years ago 161MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler v1.17.3 d109c0821a2b 4 years ago 94.4MB
registry.cn-hangzhou.aliyuncs.com/google_containers/coredns 1.6.5 70f311871ae1 4 years ago 41.6MB
registry.cn-hangzhou.aliyuncs.com/google_containers/etcd 3.4.3-0 303ce5db0e90 4 years ago 288MB
quay.io/coreos/flannel v0.11.0-amd64 ff281650a721 5 years ago 52.6MB
registry.cn-hangzhou.aliyuncs.com/google_containers/pause 3.1 da86e6ba6ca1 6 years ago 742kB
修改本地Linux上的kube-flannel.yml文件:
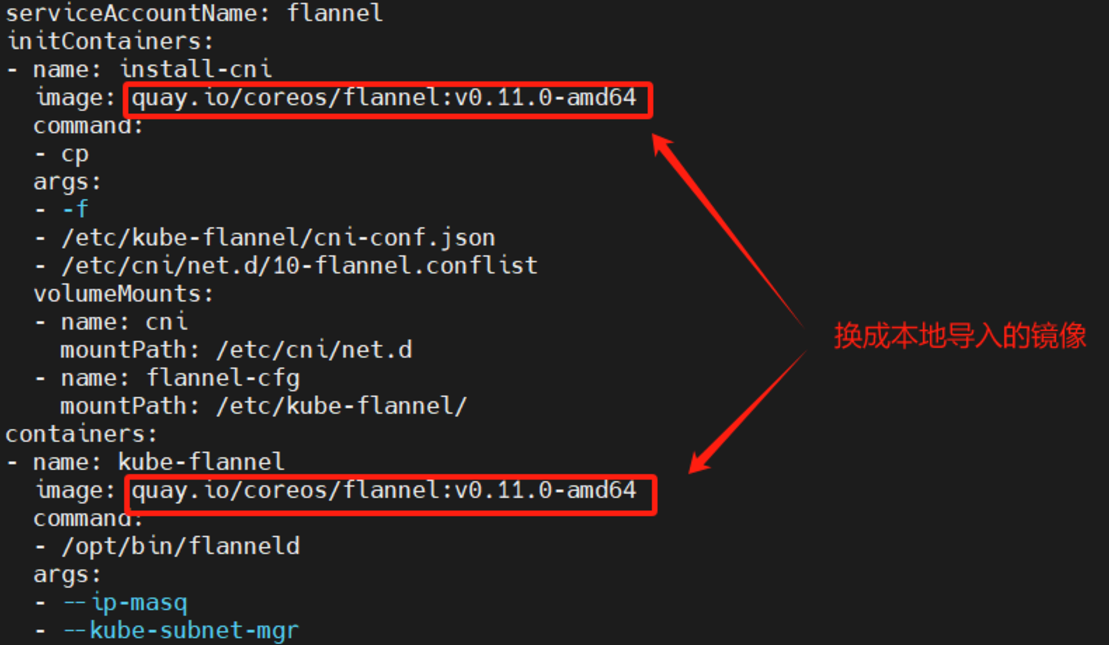
最后刷新pod
kubectl apply -f kube-flannel.yml
结果:
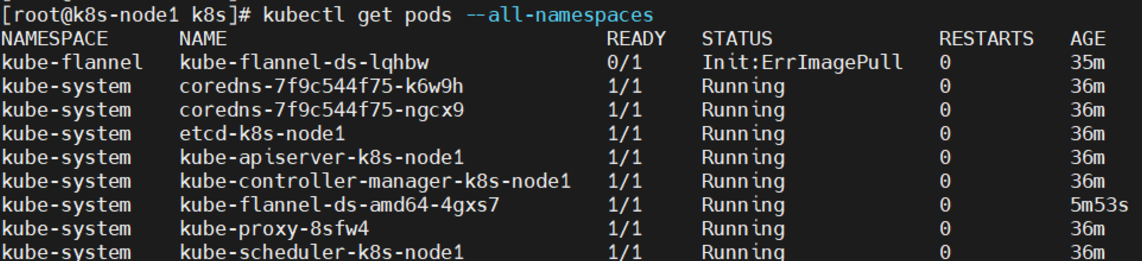
问题二:(所有节点)
执行完毕后,问题表现为coredns无法启动,master与node1处于NotReady状态,如图所示:
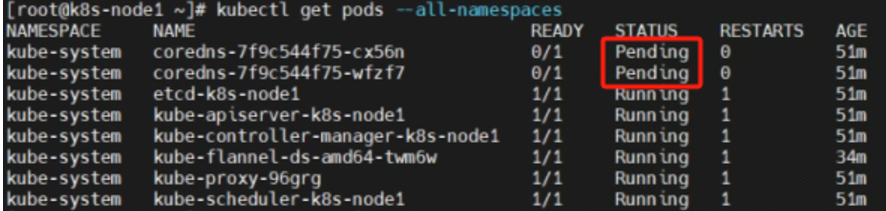
原因排查:
-
对有问题的pod进行describe
报错显示:2个节点都有污点,因此无法调度,于是对k8s-node1进行排查

kubectl describe po coredns-7f9c544f75-cx56n -n kube-system|less -
对node1进行describe
kubectl describe nodes k8s-node1|less发现错误如下:
KubeletNotReady runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized由此推断是Kubelet没有部署好,并且是网络插件导致的,因此对Kubelet进行打印
journalctl -u kubelet --since today | less6月 16 22:18:26 k8s-node1 kubelet[49627]: : [failed to find plugin "flannel" in path [/opt/cni/bin]] 6月 16 22:18:26 k8s-node1 kubelet[49627]: W0616 22:18:26.884471 49627 cni.go:237] Unable to update cni config: no valid networks found in /etc/cni/net.d 6月 16 22:18:28 k8s-node1 kubelet[49627]: E0616 22:18:28.582488 49627 pod_workers.go:191] Error syncing pod 815f19d1-da0d-467f-a16b-79193ccbae39 ("kube-flannel-ds-lqhbw_kube-flannel(815f19d1-da0d-467f-a16b -79193ccbae39)"), skipping: failed to "StartContainer" for "install-cni-plugin" with ImagePullBackOff: "Back-off pulling image \"docker.io/flannel/flannel-cni-plugin:v1.4.1-flannel1\"" 6月 16 22:18:31 k8s-node1 kubelet[49627]: W0616 22:18:31.887401 49627 cni.go:202] Error validating CNI config list { 6月 16 22:18:31 k8s-node1 kubelet[49627]: "name": "cbr0", 6月 16 22:18:31 k8s-node1 kubelet[49627]: "cniVersion": "0.3.1", 6月 16 22:18:31 k8s-node1 kubelet[49627]: "plugins": [ 6月 16 22:18:31 k8s-node1 kubelet[49627]: { 6月 16 22:18:31 k8s-node1 kubelet[49627]: "type": "flannel", 6月 16 22:18:31 k8s-node1 kubelet[49627]: "delegate": { 6月 16 22:18:31 k8s-node1 kubelet[49627]: "hairpinMode": true, 6月 16 22:18:31 k8s-node1 kubelet[49627]: "isDefaultGateway": true 6月 16 22:18:31 k8s-node1 kubelet[49627]: } 6月 16 22:18:31 k8s-node1 kubelet[49627]: }, 6月 16 22:18:31 k8s-node1 kubelet[49627]: { 6月 16 22:18:31 k8s-node1 kubelet[49627]: "type": "portmap", 6月 16 22:18:31 k8s-node1 kubelet[49627]: "capabilities": { 6月 16 22:18:31 k8s-node1 kubelet[49627]: "portMappings": true 6月 16 22:18:31 k8s-node1 kubelet[49627]: } 6月 16 22:18:31 k8s-node1 kubelet[49627]: } 6月 16 22:18:31 k8s-node1 kubelet[49627]: ] 6月 16 22:18:31 k8s-node1 kubelet[49627]: }最终定位问题至flannel问题
报错:failed to find plugin “flannel” in path /opt/cni/bin
又在网上差了一些资料,得到解决方案
解决方法:
Github 手动下载 cni plugin v0.8.6
地址如下:https://github.com/containernetworking/plugins/releases/download/v0.8.6/cni-plugins-linux-amd64-v0.8.6.tgz
mkdir /opt/cni-plugins tar -zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni-plugins/ cp flannel /opt/cni/bin/容器瞬间启动,master节点处于Ready状态。同理,k8s-node2,k8s-node3进行同样操作。问题解决。
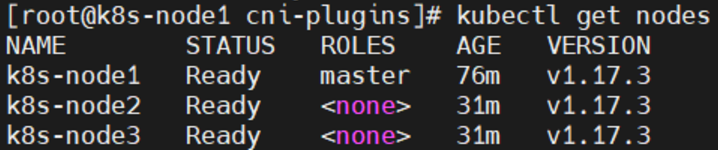
19.2.8 加入 Kubernetes Node(从节点)
在 Node 节点执行。
向集群添加新节点,执行在 kubeadm init 输出的 kubeadm join 命令:
确保 node 节点成功
token 过期怎么办
kubeadm token create --print-join-command
kubeadm token create --ttl 0 --print-join-command
kubeadm join 192.168.119.130:6443 --token oqnc6s.wiqeib0osvp37yxg --discovery-token-ca-cert-hash sha256:b3e6f39c9b70eece87cc9d29c32b42b4d0d2db930383e2e799208c07b489979d
执行 watch kubectl get pod -n kube-system -o wide 监控 pod 进度
等 3-10 分钟,完全都是 running 以后使用 kubectl get nodes 检查状态
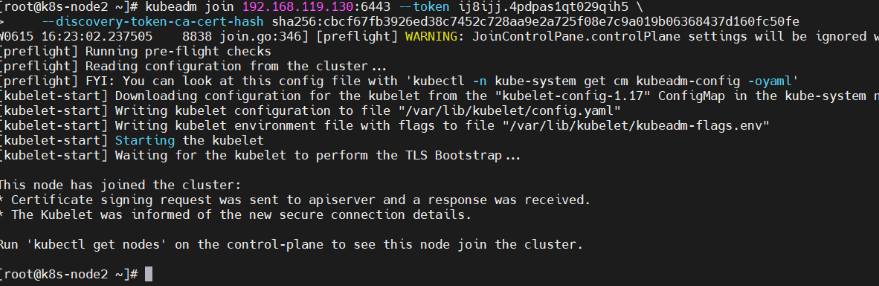
执行命令报错
[root@k8s-node1 k8s]# kubeadm join 192.168.119.130:6443 --token enj3vg.fikkr30njmptrtem \
> --discovery-token-ca-cert-hash sha256:b7b3baf3082e0d9acd3a0a4f2352224ecb007da583bcc02861f36956c9f017c1
W0605 11:06:13.897366 36607 join.go:346] [preflight] WARNING: JoinControlPane.controlPlane settings will be ignored when control-plane flag is not set.
[preflight] Running pre-flight checks[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
error execution phase preflight: [preflight] Some fatal errors occurred:[ERROR DirAvailable--etc-kubernetes-manifests]: /etc/kubernetes/manifests is not empty[ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists[ERROR Port-10250]: Port 10250 is in use[ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
- 问题一
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/报错原因:
在kubeadm join 添加工作节点时出现docker 驱动cgroup的问题。检测到"cgroupfs"作为Docker的cgroup驱动程序,推荐使用systemd驱动。解决办法:
-
修改前先查看驱动信息
docker info | grep Cgrou
-
修改/etc/docker/daemon.json文件
vi /etc/docker/daemon.json #添加以下信息 {"exec-opts":["native.cgroupdriver=systemd"] }
-
重启docker
systemctl restart docker -
确认下修改后的驱动信息

- 问题二
[ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists [ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists报错原因:
有残留文件
解决办法
#删除k8s配置文件和证书文件 rm -rf /etc/kubernetes/kubelet.conf /etc/kubernetes/pki/ca.crt -
问题三
端口占用提示:[ERROR Port-10250]: Port 10250 is in usesudo yum install -y net-tools -q #安装相关工具(-q:静默安装)然后查看端口
 可以看出,是K8S占用了,那就尝试重启服务看看能不能解决
可以看出,是K8S占用了,那就尝试重启服务看看能不能解决
19.2.9 入门操作 kubernetes 集群
1、部署一个 tomcat
kubectl create deployment tomcat6 --image=tomcat:6.0.53-jre8
kubectl get pods -o wide #可以获取到 tomcat 信息

2、暴露 tomcat 访问
kubectl expose deployment tomcat6 --port=80 --target-port=8080 --type=NodePort
现在我们使用NodePort的方式暴露,这样访问每个节点的端口,都可以访问各个Pod,如果节点宕机,就会出现问题。
Pod 的 80 映射容器的 8080;service 会代理 Pod 的 80
kubectl get svc

3、动态扩容测试
kubectl get deployment

应用升级 kubectl set image (–help 查看帮助)
扩容:
kubectl scale --replicas=3 deployment tomcat6
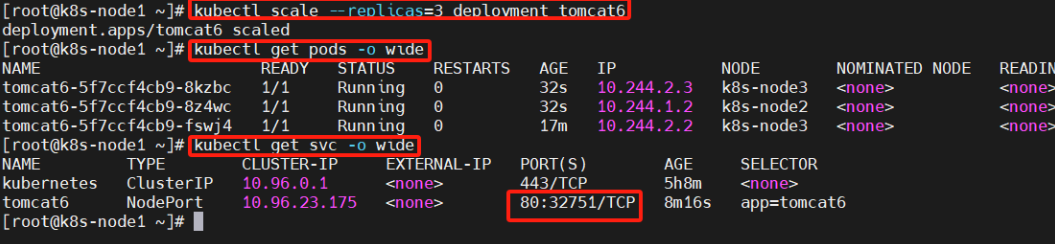
扩容了多份,所有无论访问哪个 node 的指定端口,都可以访问到 tomcat6
4、以上操作的 yaml 获取
参照 k8s 细节
5、删除
kubectl get all
kubectl delete deployment.apps/tomcat6
kubectl delete service/tomcat6
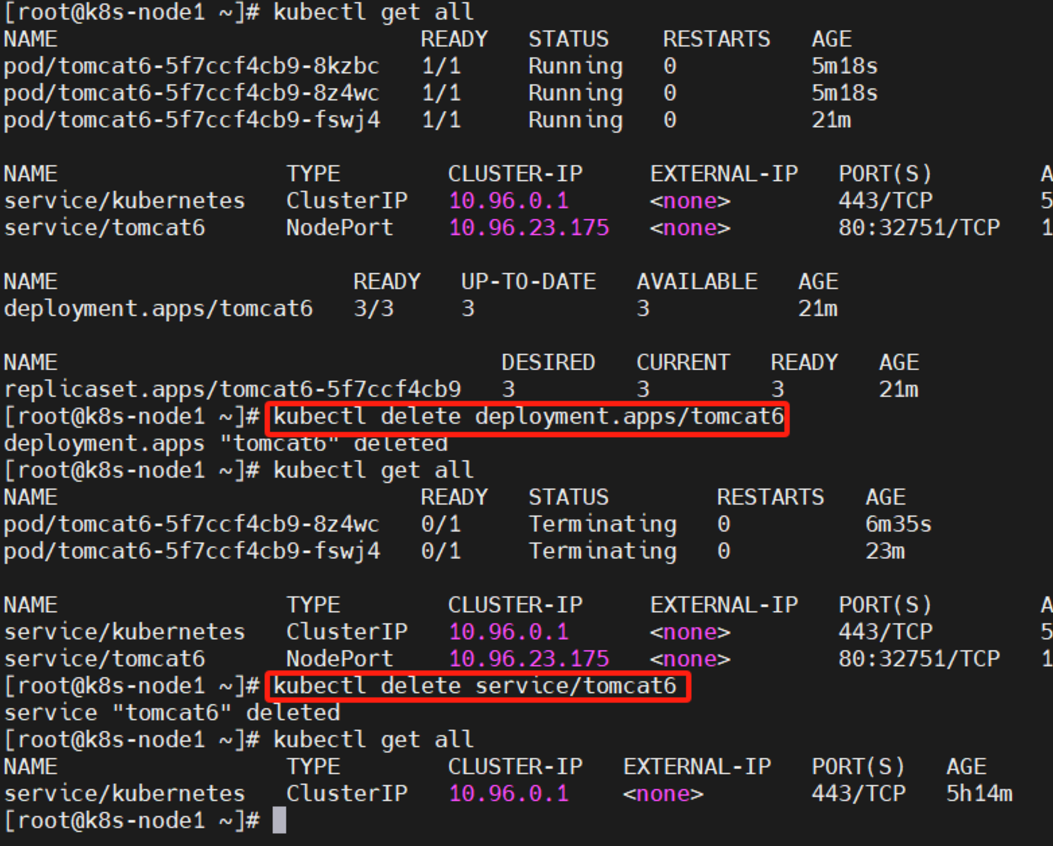
流程;创建 deployment 会管理 replicas,replicas 控制 pod 数量,有 pod 故障会自动拉起新的 pod
19.2.10 安装默认 dashboard
1、部署 dashboard
kubectl apply -f \
https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommende
d/kubernetes-dashboard.yaml
墙的原因,文件已经放在我们的 code 目录,自行上传
文件中无法访问的镜像,自行去 docker hub 找
2、暴露 dashboard 为公共访问
默认 Dashboard 只能集群内部访问,修改 Service 为 NodePort 类型,暴露到外部:
kind: Service
apiVersion: v1
metadata:
labels:k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
type: NodePort
ports:- port: 443targetPort: 8443nodePort: 30001
selector:k8s-app: kubernetes-dashboard
访问地址:http://NodeIP:30001
3、创建授权账户
kubectl create serviceaccount dashboard-admin -n kube-system
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk
'/dashboard-admin/{print $1}')
使用输出的 token 登录 Dashboard。
20、K8S 细节
20.1 kubectl
-
kubectl 文档
命令行工具 (kubectl) | Kubernetes -
资源类型
命令行工具 (kubectl) | Kubernetes -
格式化输出
命令行工具 (kubectl) | Kubernetes -
常用操作
命令行工具 (kubectl) | Kubernetes -
命令参考
Kubectl Reference Docs
20.2 yaml 语法
1.yml 模板

2.yaml 字段解析
参照官方文档:
命令行工具 (kubectl) | Kubernetes
3.yaml输出
在此示例中,以下命令将单个 pod 的详细信息输出为 YAML 格式的对象:
kubectl get pod web-pod-13je7 -o yaml
–dry-run:
–dry-run=‘none’: Must be “none”, “server”, or “client”. If client strategy, only print the object that would be sent, without sending it. If server strategy, submit server-side request without persisting the resource. 值必须为,或。
none
server:提交服务器端请求而不持久化资源。
client:只打印该发送对象,但不发送它。
也就是说,通过–dry-run选项,并不会真正的执行这条命令。
输出yaml案例
kubectl create deployment tomcat6 --image=tomcat:6.0.53-jre8 --dry-run -o yaml > tomact6-deployment.yaml
查看yaml:cat tomact6-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:creationTimestamp: nulllabels:app: tomcat6name: tomcat6
spec:replicas: 1selector:matchLabels:app: tomcat6strategy: {}template:metadata:creationTimestamp: nulllabels:app: tomcat6spec:containers:- image: tomcat:6.0.53-jre8name: tomcatresources: {}
status: {}
20.3 入门操作
1.Pod 是什么,Controller 是什么
Pod | Kubernetes
Pod和控制器
控制器可以为您创建和管理多个 Pod,管理副本和上线,并在集群范围内提供自修复能力。
例如,如果一个节点失败,控制器可以在不同的节点上调度一样的替身来自动替换 Pod。
包含一个或多个 Pod 的控制器一些示例包括:
Deployment
StatefulSet
DaemonSet
控制器通常使用您提供的 Pod 模板来创建它所负责的 Pod
2.Deployment&Service 是什么
3.Service 的意义
- 部署一个 nginx
kubectl create deployment nginx --image=nginx -
暴露 nginx 访问
kubectl expose deployment nginx --port=80 --type=NodePort
统一应用访问入口;
Service 管理一组 Pod。
防止 Pod 失联(服务发现)、定义一组 Pod 的访问策略
现在 Service 我们使用 NodePort 的方式暴露,这样访问每个节点的端口,都可以访问到这个 Pod,如果节点宕机,就会出现问题。
4.labels and selectors
5.Ingress
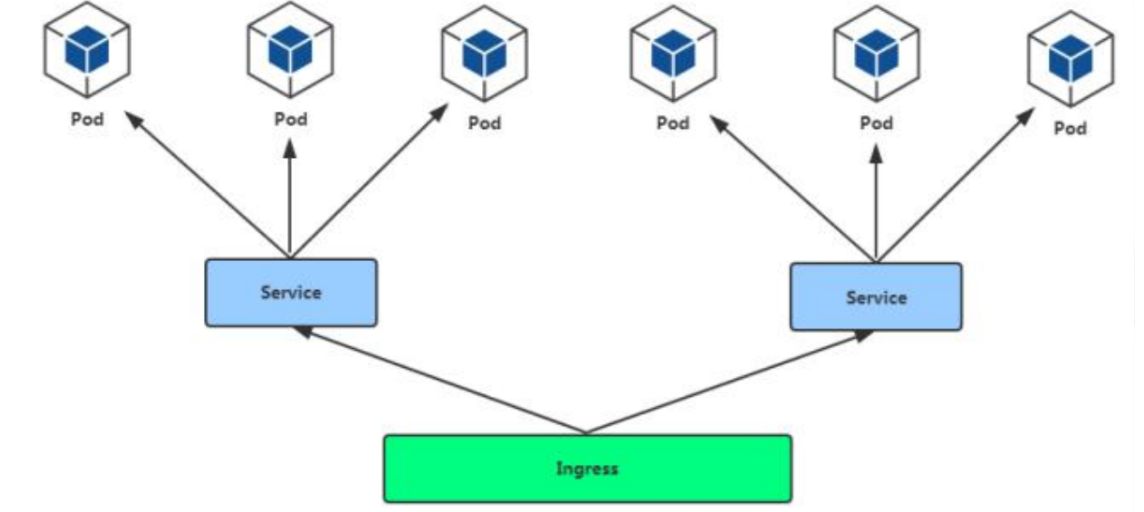
通过 Service 发现 Pod 进行关联。基于域名访问。
通过 Ingress Controller 实现 Pod 负载均衡
支持 TCP/UDP 4 层负载均衡和 HTTP 7 层负载均衡
步骤:
1)、部署 Ingress Controller
2)、创建 Ingress 规则
apiVersion: extensions/v1beta1
kind: Ingress
metadata:name: web
spec:rules:- host: tomcat6.atguigu.comhttp:paths:- backend:serviceName: tomcat6servicePort: 80
如果再部署了 tomcat8;看效果;
kubectl create deployment tomcat8 --image=tomcat:8.5.51-jdk8
kubectl expose deployment tomcat8 --port=88 --target-port=8080 --type=NodePort
kubectl delete xxx #删除指定资源
随便配置域名对应哪个节点,都可以访问 tomcat6/8;因为所有节点的 ingress-controller 路由表是同步的。
6.网络模型
Kubernetes 的网络模型从内至外由四个部分组成:
- Pod 内部容器所在的网络
- Pod 所在的网络
- Pod 和 Service 之间通信的网络
- 外界与 Service 之间通信的网络
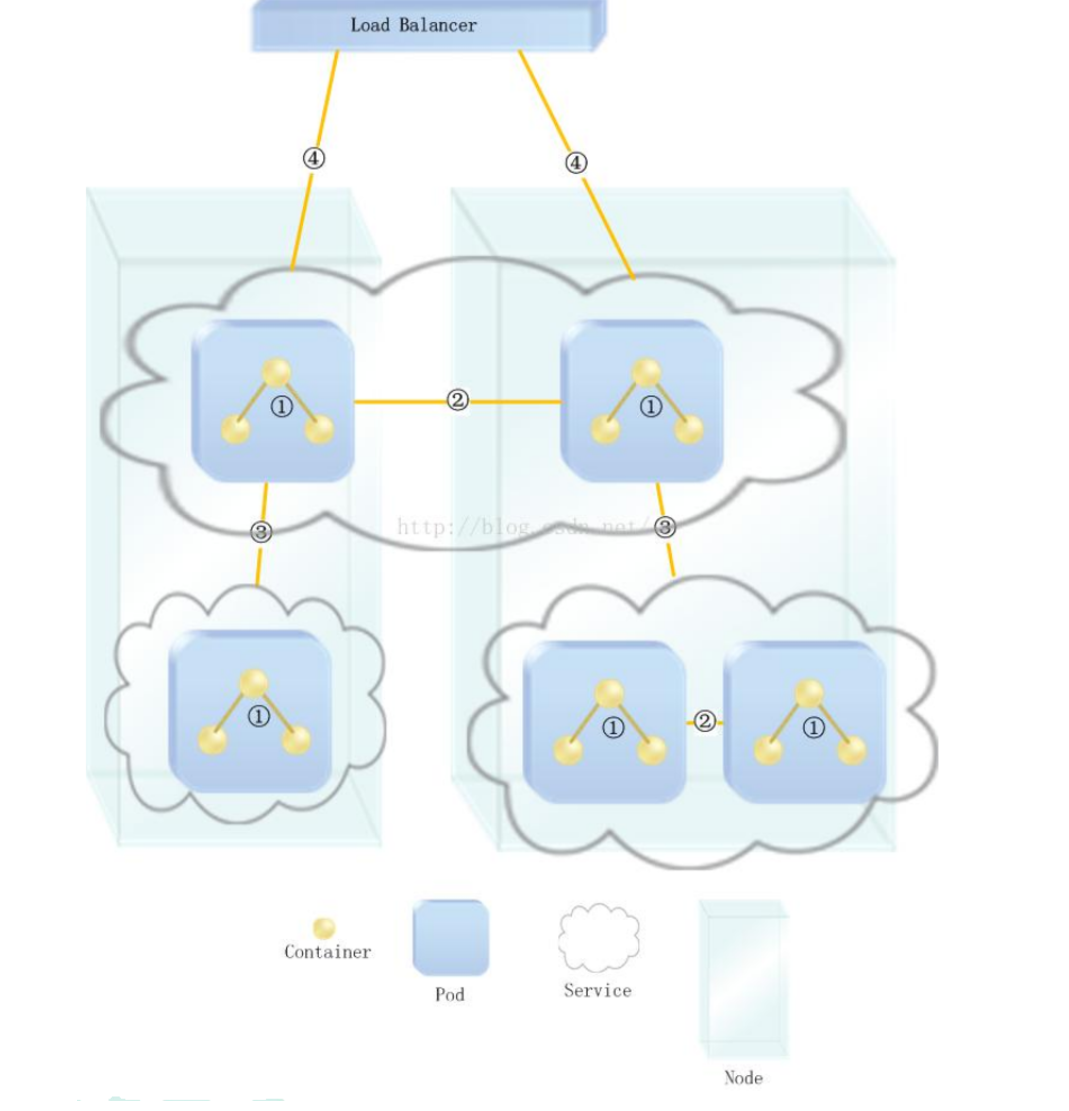
20.4 项目部署
项目部署流程:
- 制作项目镜像(将项目制作为 Docker 镜像,要熟悉 Dockerfile 的编写)
- 控制器管理 Pod(编写 k8s 的 yaml 即可)
- 暴露应用
- 日志监控
接下来我们还是以原先部署tomact6为实例
创建yaml
kubectl create deployment tomcat6 --image=tomcat:6.0.53-jre8 --dry-run -o yaml > tomact6-deployment.yaml
 修改yaml
修改yaml
vi tomact6-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: tomcat6name: tomcat6
spec:replicas: 3selector:matchLabels:app: tomcat6template:metadata:labels:app: tomcat6spec:containers:- image: tomcat:6.0.53-jre8name: tomcat
- 应用 tomact6-deployment.yaml 部署tomact6
kubectl apply -f tomact6-deployment.yaml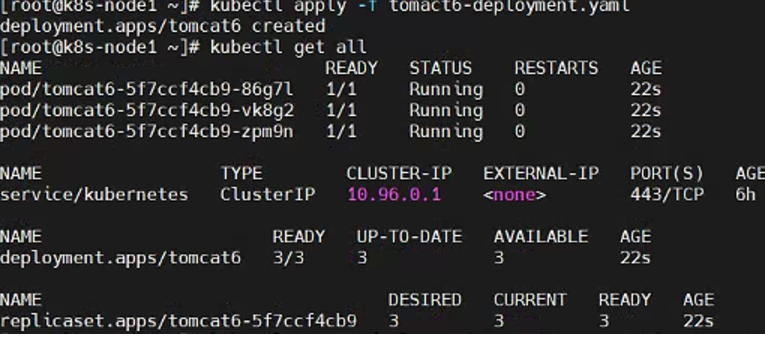 查看某个pod的具体信息:
查看某个pod的具体信息:[root@k8s-node1 k8s]# kubectl get pods NAME READY STATUS RESTARTS AGE tomcat6-5f7ccf4cb9-qrnvh 1/1 Running 0 11h tomcat6-5f7ccf4cb9-sb6jg 1/1 Running 0 11h tomcat6-5f7ccf4cb9-xsxsx 1/1 Running 0 11h [root@k8s-node1 k8s]# kubectl get pods tomcat6-5f7ccf4cb9-qrnvh -o yaml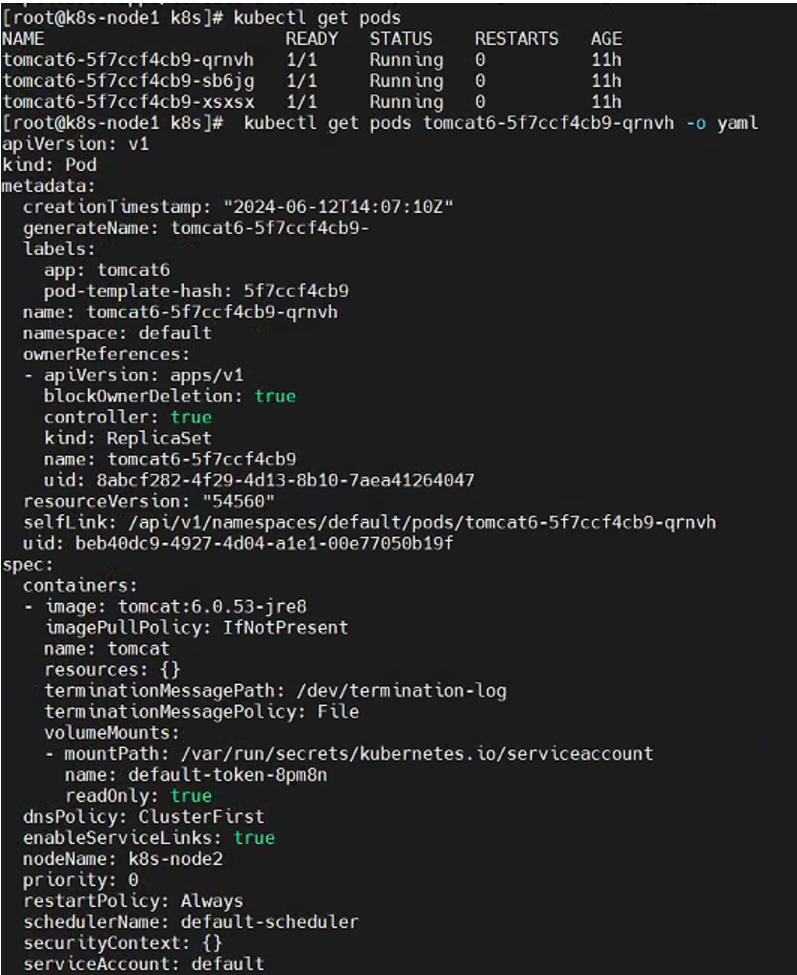
-
暴露 tomcat6 访问
前面我们通过命令行的方式,部署和暴露了tomcat,实际上也可以通过yaml的方式来完成这些操作。暴露端口也通过yaml,生成yaml,并部署kubectl expose deployment tomcat6 --port=80 --target-port=8080 --type=NodePort --dry-run -o yaml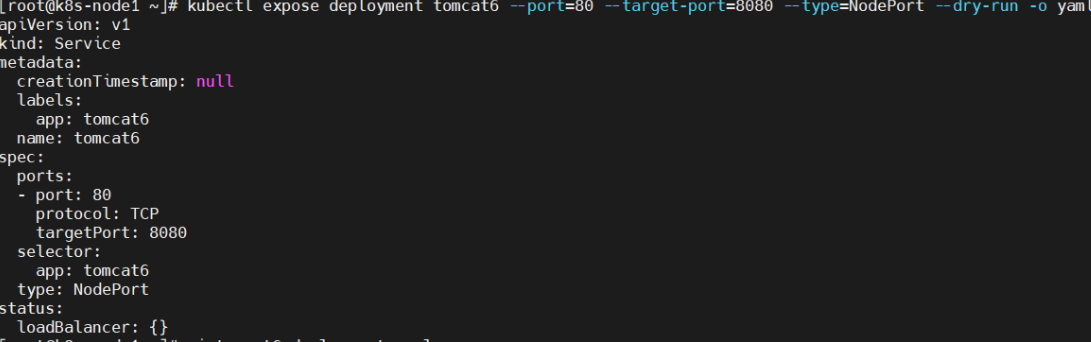
-
整合 tomact6-deployment.yaml - 关联部署和service
将这段输出和“tomcat6-deployment.yaml”用—进行拼接,表示部署完毕并进行暴露服务:
vi tomact6-deployment.yamlapiVersion: apps/v1 kind: Deployment #部署 metadata:labels:app: tomcat6 #标签name: tomcat6 spec:replicas: 3 #副本数selector:matchLabels:app: tomcat6template:metadata:labels:app: tomcat6spec:containers:- image: tomcat:6.0.53-jre8name: tomcat --- apiVersion: v1 kind: Service metadata:labels:app: tomcat6 #标签name: tomcat6 spec:ports:- port: 80protocol: TCPtargetPort: 8080selector:app: tomcat6 #标签type: NodePort
上面类型一个是Deployment,一个是Service
- 删除以前的部署
kubectl get all kubectl delete deployment.apps/tomcat6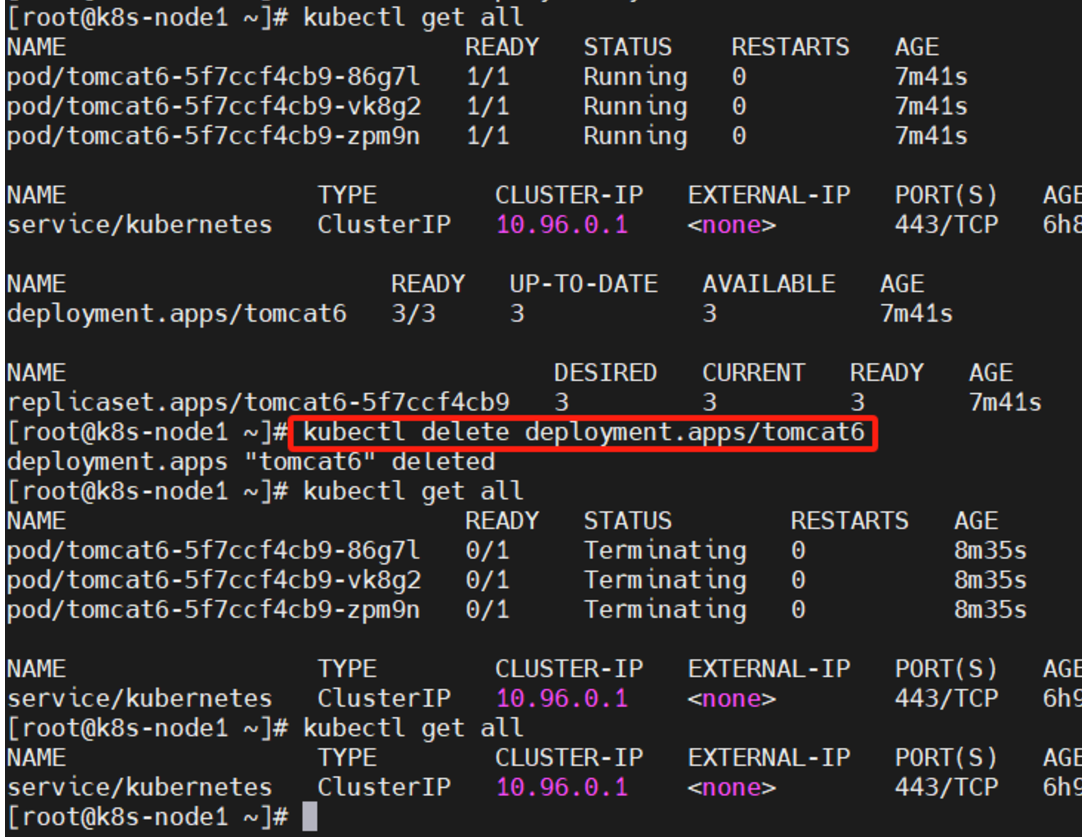
-
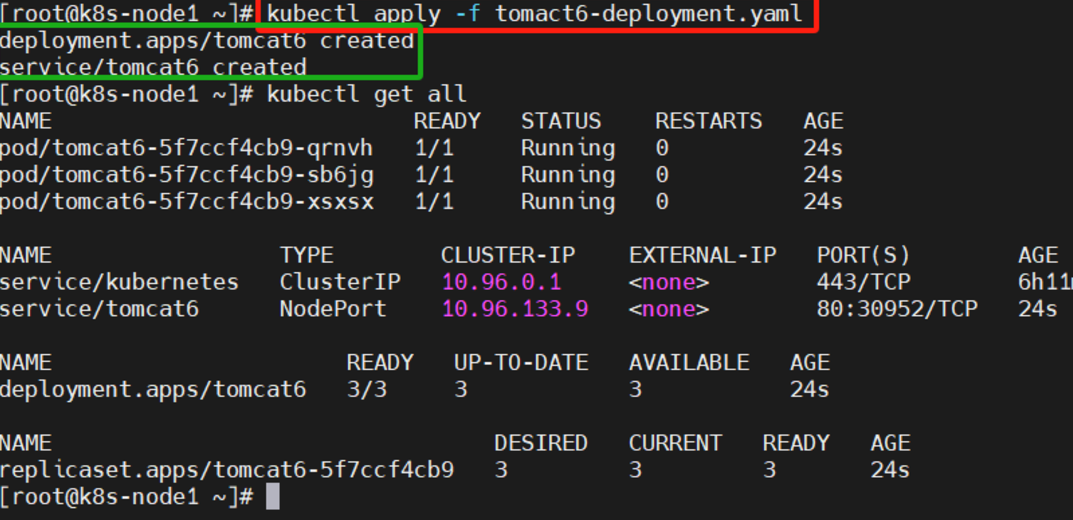
部署并暴露服务
kubectl apply -f tomact6-deployment.yaml查看服务和部署信息
 测试
测试
访问k8s-node1,k8s-node1和k8s-node3的30952端口:随便访问一个地址:http://192.168.119.132:30952/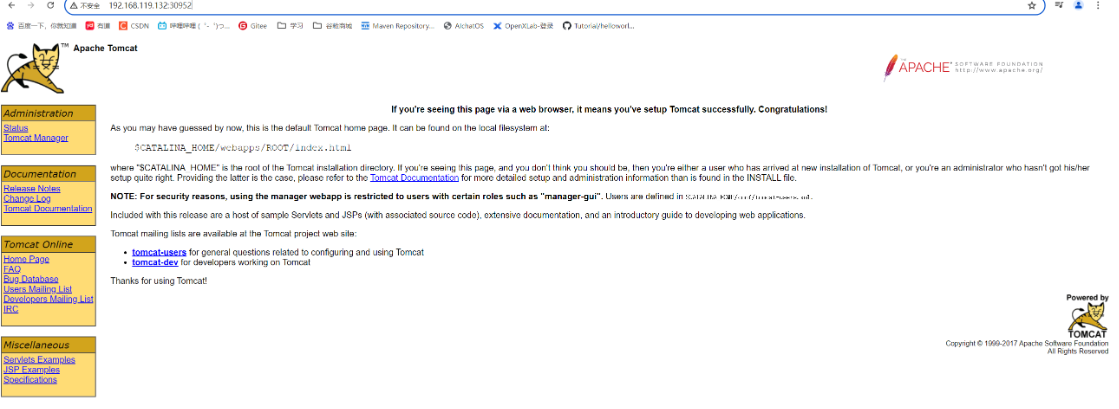 现在的问题是service的3个pod都可以访问,但怎么创建个总的管理者,以便负载均衡
现在的问题是service的3个pod都可以访问,但怎么创建个总的管理者,以便负载均衡 -
部署Ingeress
通过Ingress发现pod进行关联。基于域名访问
通过Ingress controller实现POD负载均衡
支持TCP/UDP 4层负载均衡和HTTP 7层负载均衡
可以把ingress理解为nginx,通过域名访问service端口
- Ingress管理多个service
- service管理多个pod
步骤:
1)、部署Ingress controller主节点执行“k8s/ingress-controller.yaml”,
cd k8s kubectl apply -f ingress-controller.yaml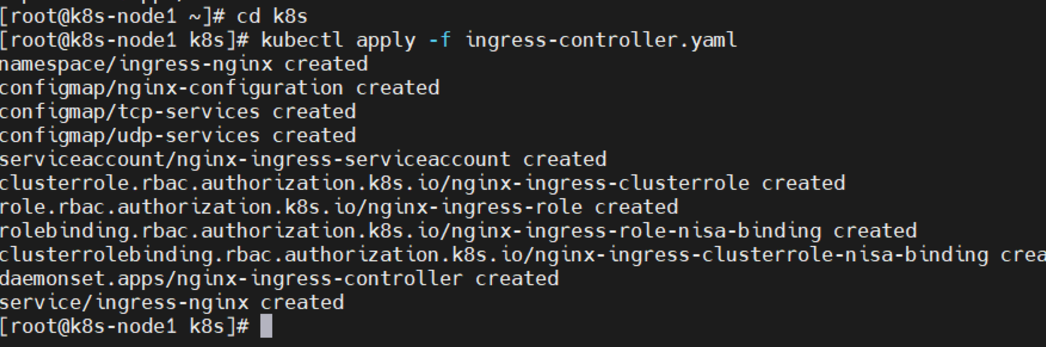 查看
查看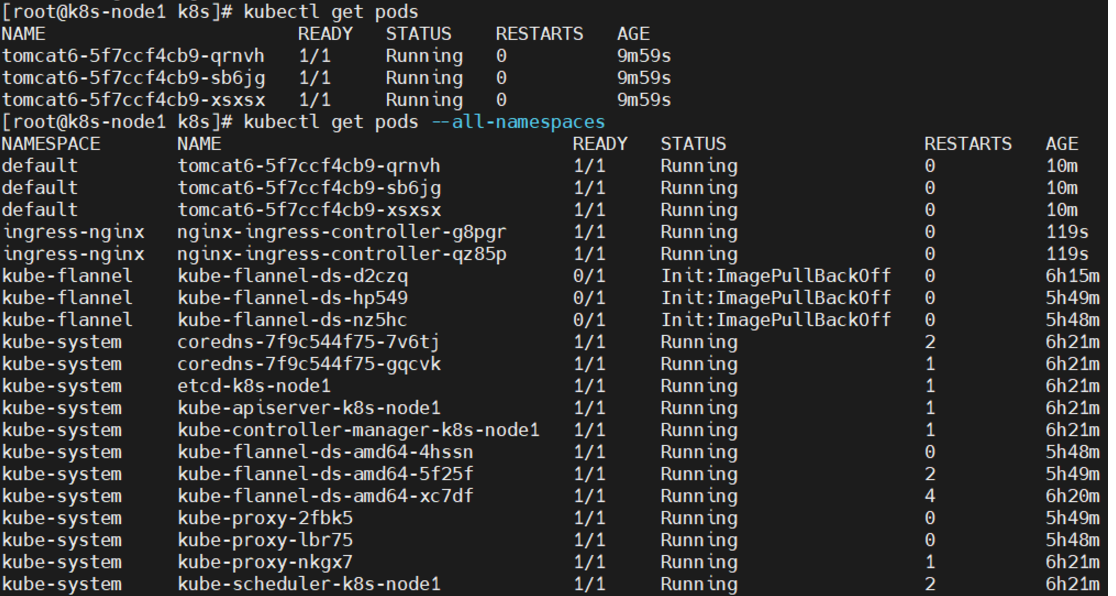
这里master节点负责调度,具体执行交给node2和node3来完成
2)、创建Ingress规则
vi ingress-tomact6.yamlapiVersion: extensions/v1beta1 kind: Ingress metadata:name: web spec:rules:- host: tomcat6.atguigu.comhttp:paths:- backend:serviceName: tomcat6servicePort: 80执行
kubectl apply -f ingress-tomact6.yaml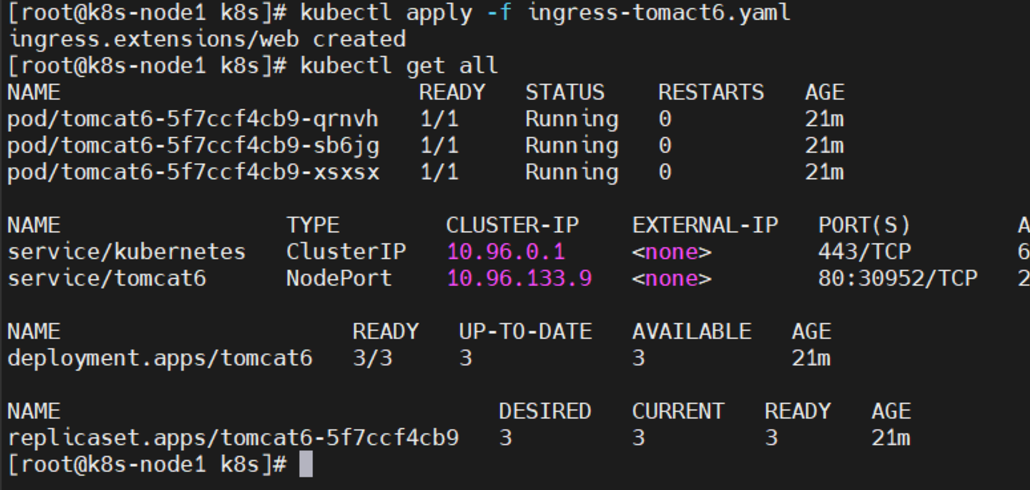 修改本机的hosts文件,添加如下的域名转换规则:
修改本机的hosts文件,添加如下的域名转换规则:
修改“C:\Windows\System32\drivers\etc\hosts”192.168.56.100 tomact6.atguigu.com 192.168.56.101 tomact6.atguigu.com 192.168.56.102 tomact6.atguigu.com访问:http://tomact6.atguigu.com:30952/
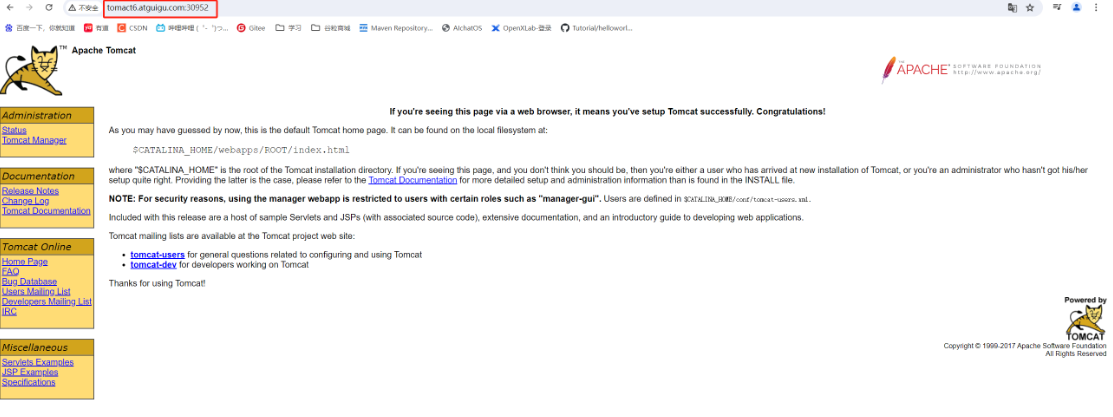 并且集群中即便有一个节点不可用,也不影响整体的运行。
并且集群中即便有一个节点不可用,也不影响整体的运行。
21、KubeSphere
默认的 dashboard 没啥用,我们用 kubesphere 可以打通全部的 devops 链路。
Kubesphere 集成了很多套件,集群要求较高
https://kubesphere.io/
Kuboard 也很不错,集群要求不高
https://kuboard.cn/support/
21.1 简介
KubeSphere 是一款面向云原生设计的开源项目,在目前主流容器调度平台 Kubernetes 之上构建的分布式多租户容器管理平台,提供简单易用的操作界面以及向导式操作方式,在降低用户使用容器调度平台学习成本的同时,极大降低开发、测试、运维的日常工作的复杂度。
21.2 安装
21.2.1 前提条件
https://v2-1.docs.kubesphere.io/docs/zh-CN/installation/prerequisites/
21.2.2 安装前提环境
Helm 是 Kubernetes 的包管理器。包管理器类似于我们在 Ubuntu 中使用的 apt、Centos中使用的 yum 或者 Python 中的 pip 一样,能快速查找、下载和安装软件包。Helm 由客户端组件 helm 和服务端组件 Tiller 组成, 能够将一组 K8S 资源打包统一管理, 是查找、共享和使用为 Kubernetes 构建的软件的最佳方式
1)、安装