AI实用特性
1、自定义日志
1.1、自定义日志 Advisor
Spring AI 的 Advisor 可以理解为拦截器,可以对调用 AI 的请求进行增强,比如调用 AI 前鉴权、调用 AI 后记录日志。
例如,官方的 Advisor 中日志记录是logger.debug,
private AdvisedRequest before(AdvisedRequest request) {logger.debug("request: {}", this.requestToString.apply(request));return request;}
这是 DEBUG 级别日志,平时开发调试用的。
默认情况下,生产环境很多框架会把 debug 级别给关了,目的是减少日志量和性能消耗。
如果想查看 DEBUG 级别日志,需要在 yml 配置中修改配置文件来指定特定文件的输出级别
logging:level:org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor: debug
但如果为了更灵活地打印指定的日志,可以自己实现一个日志 Advisor。
自定义日志可以借鉴内置的 SimpleLoggerAdvisor 源码,重点实现两个方法:CallAroundAdvisor和StreamAroundAdvisor
- CallAroundAdvisor:用于处理同步请求和响应(非流式)
- StreamAroundAdvisor:用于处理流式请求和响应
@Slf4j
public class MyLoggerAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {public String getName() {return this.getClass().getSimpleName();}public int getOrder() {return 0;}private AdvisedRequest before(AdvisedRequest request) {log.info("AI Request: {}",request.userText());return request;}private void observeAfter(AdvisedResponse advisedResponse) {log.info("AI Response: {}",advisedResponse.response().getResult().getOutput().getText());}public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {// 1. 处理请求(前置处理)advisedRequest = this.before(advisedRequest);// 2. 调用链中的下一个AdvisorAdvisedResponse advisedResponse = chain.nextAroundCall(advisedRequest);// 3. 处理响应(后置处理)this.observeAfter(advisedResponse);return advisedResponse;}public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {advisedRequest = this.before(advisedRequest);Flux<AdvisedResponse> advisedResponses = chain.nextAroundStream(advisedRequest);return (new MessageAggregator()).aggregateAdvisedResponse(advisedResponses, this::observeAfter);}
}
1.2、自定义 Re-Reading Advisor
通过 Re-Reading(Re2) 的技巧,能让大语言模型(像我这种)推理能力更强。
- 当你给模型一个问题(Input_Query)的时候,不是只让它读一遍,而是让它“再读一遍”——在输入里把问题重复两次,比如:
{Input_Query}
Read the question again: {Input_Query}
- 这个“再读一遍”的操作能帮模型更好地理解问题细节,提高回答时的逻辑推理和准确性。
打个比方,就是你自己做题时,有时候第一遍看题可能没全理解,读第二遍细品,答案就更靠谱了。
💡总结:Re-Reading 就是让模型把问题读两遍,从而加强思考,提升推理水平
官网代码如下👇
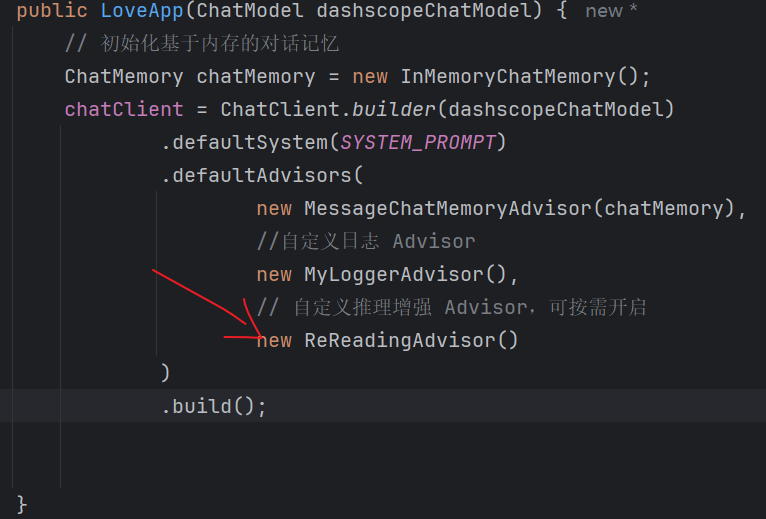
public class ReReadingAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {private AdvisedRequest before(AdvisedRequest advisedRequest) {Map<String, Object> advisedUserParams = new HashMap<>(advisedRequest.userParams());advisedUserParams.put("re2_input_query", advisedRequest.userText());return AdvisedRequest.from(advisedRequest).userText("""{re2_input_query}Read the question again: {re2_input_query}""").userParams(advisedUserParams).build();}@Overridepublic AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {return chain.nextAroundCall(this.before(advisedRequest));}@Overridepublic Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {return chain.nextAroundStream(this.before(advisedRequest));}@Overridepublic int getOrder() {return 0;}@Overridepublic String getName() {return this.getClass().getSimpleName();}
}
①复制原请求的用户参数到新 Map -> ②把用户输入的文本(问题)存入新参数 “re2_input_query” -> ③用模板写新的 prompt,重复两遍 {re2_input_query} -> ④构建新的请求对象,带上新的 prompt 和参数
弊端:让用户输入问题输入两遍,Token 加倍,成本加倍。
最佳实践
- 保持单一职责:每个 Advisor 应专注于一项特定任务
- 注意执行顺序:合理设置getOrder()值确保 Advisor 按正确顺序执行
- 同时支持流式和非流式:尽可能同时实现两种接口以提高灵活性
- 高效处理请求:避免在 Advisor 中执行耗时操作
- 测试边界情况:确保 Advisor 能够优雅处理异常和边界情况
- 对于需要更复杂处理的流式场景,可以使用 Reactor 的操作符:
还可以使用 adviseContext 在 Advisor 链中共享状态:比如我想在自定义日志拦截器(MyLoggerAdvisor )中看见Re-Reading拦截器 (ReReadingAdvisor )的信息,那么我可以在 ReReadingAdvisor 中加入如下代码:
// 更新上下文
advisedRequest = advisedRequest.updateContext(context -> {context.put("key", "value");return context;
});
可以理解为 ThreadLocal ,相当于单次 AI 请求中,定义了一个全局变量,这次请求之后,全局变量就失效了,这个全局变量在这次请求中所有的拦截器都能看见,都能获取到。
同时在 MyLoggerAdvisor 中,写如下代码:
// 读取上下文
Object value = advisedResponse.adviseContext().get("key");
这样 MyLoggerAdvisor 就可以知道 ReReadingAdvisor 输出的信息了。
2、结构化输出
就是用于将大语言模型返回的文本输出转换为结构化数据格式,如 JSON、XML 或 Java 类,这对于需要可靠解析 AI 输出值的下游应用程序非常重要。虽然通过 Prompt 也可以让 AI 自己输出结构化数据,但是这么做不可靠,Spring AI 框架直接提供了这种方式。官方文档
注意:
StructuredOutputConverter 是一种 “尽力而为” 的工具,用于将模型的输出转换为结构化的结果。但是,不能保证 AI 模型一定会按照要求返回结构化的输出。模型有可能无法正确理解 prompt,或者无法按照预期生成结构化格式的结果。
因此,官方建议你实现一个校验机制,确保模型输出符合预期的格式和数据结构。
结构化输出转换器 StructuredOutputConverter 接口允许开发者获取结构化输出,例如将输出映射到 Java 类或值数组。接口定义如下:
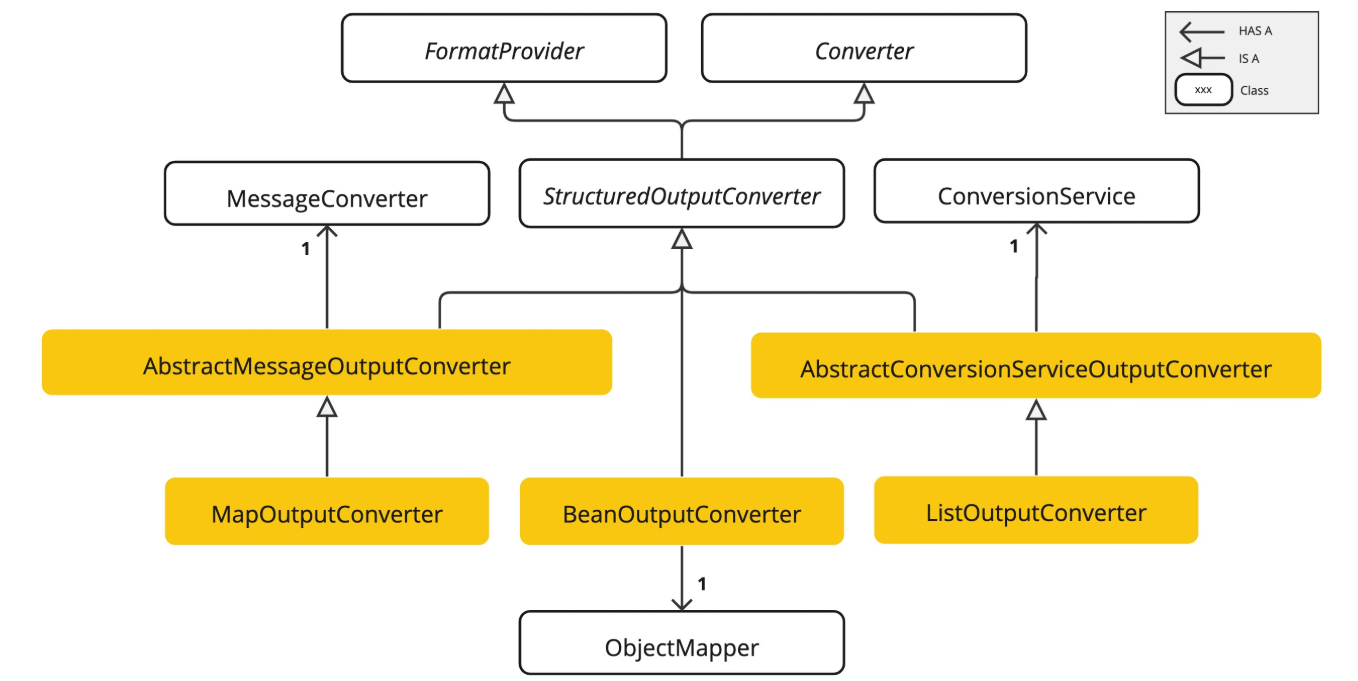
public interface StructuredOutputConverter<T> extends Converter<String, T>, FormatProvider {
}
它集成了 2 个关键接口:
- FormatProvider 接口:提供特定的格式指令给 AI 模型
- Spring 的 Converter<String, T>接口:负责将模型的文本输出转换为指定的目标类型 T
Spring AI 提供了多种转换器实现,分别用于将输出转换为不同的结构:
- BeanOutputConverter:用于将输出转换为 Java Bean 对象(基于 ObjectMapper 实现
- MapOutputConverter:用于将输出转换为 Map 结构
- ListOutputConverter:用于将输出转换为 List 结构
原理:
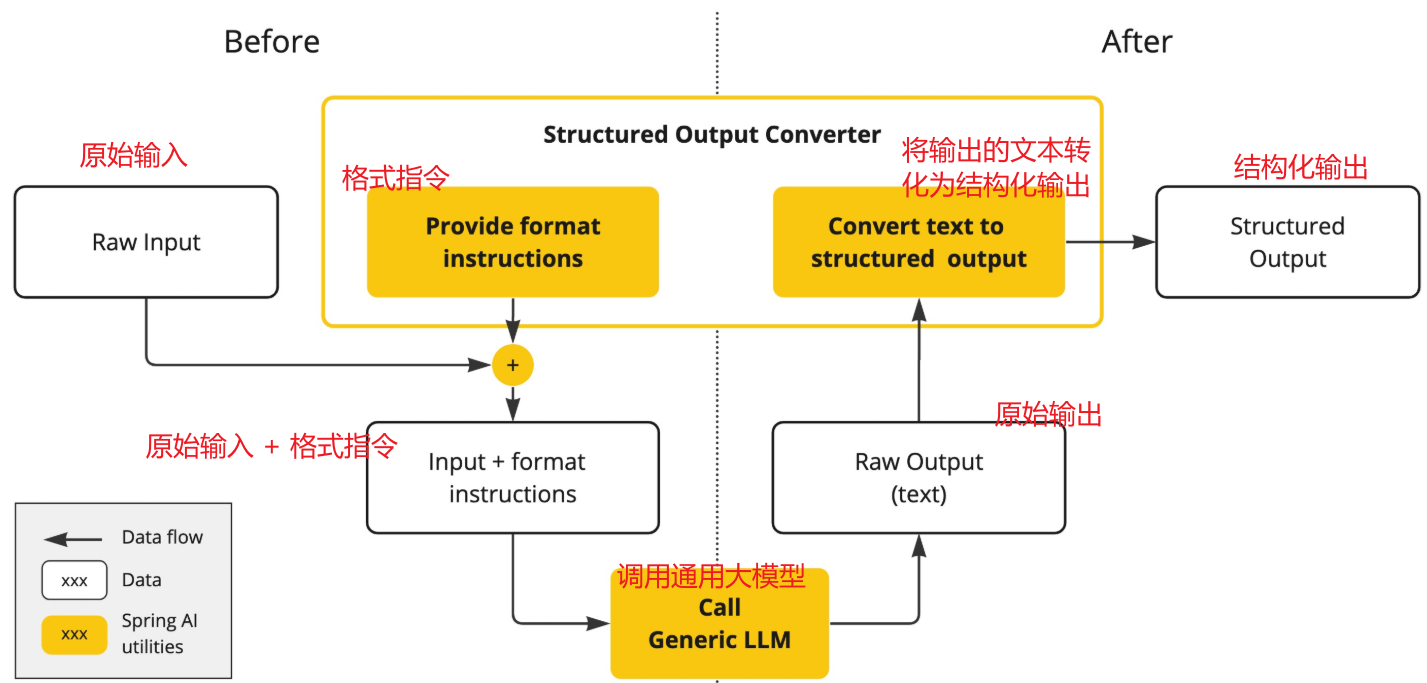
第一步:在调用大模型之前,FormatProvider 为 AI 模型提供特定的格式指令,使其能够生成可以通过 Converter 转换为指定目标类型的文本输出。
转换器的格式指令组件会将类似下面的格式指令附加到提示词中:
Your response should be in JSON format.
The data structure for the JSON should match this Java class: java.util.HashMap
Do not include any explanations, only provide a RFC8259 compliant JSON response following this format without deviation.
使用 PromptTemplate 将格式指令附加到用户输入的末尾,示例代码如下:
StructuredOutputConverter outputConverter = ...
String userInputTemplate = """... 用户文本输入 ....{format}"""; // 用户输入,包含一个“format”占位符。
Prompt prompt = new Prompt(new PromptTemplate(this.userInputTemplate,Map.of(..., "format", outputConverter.getFormat()) // 用转换器的格式替换“format”占位符).createMessage());第二步:Converter 负责将模型的输出文本转换为指定类型的实例。
①BeanOutputConverter 示例,将 AI 输出转换为自定义 Java 类:
record ActorsFilms(String actor, List<String> movies) {
}ActorsFilms actorsFilms = ChatClient.create(chatModel).prompt().user(u -> u.text("Generate the filmography of 5 movies for {actor}.").param("actor", "Tom Hanks")).call().entity(ActorsFilms.class);
② MapOutputConverter示例,将 AI 输出转换 Map 对象
Map<String, Object> result = ChatClient.create(chatModel).prompt().user(u -> u.text("Provide me a List of {subject}").param("subject", "an array of numbers from 1 to 9 under they key name 'numbers'")).call().entity(new ParameterizedTypeReference<Map<String, Object>>() {});
③ListOutputConverter示例,将 AI 输出转换 List 对象
// 可以转换为对象列表
List<ActorsFilms> actorsFilms = ChatClient.create(chatModel).prompt().user("Generate the filmography of 5 movies for Tom Hanks and Bill Murray.").call().entity(new ParameterizedTypeReference<List<ActorsFilms>>() {});
实战
record LoveReport(String title, List<String> suggestion){}/*** AI 报告输出(结构化输出)* @param message* @param chatId* @return*/public LoveReport doChatWithReport(String message,String chatId){LoveReport loveReport = chatClient.prompt().system(SYSTEM_PROMPT + "每次对话后都要生成恋爱结果,标题为{用户名}的恋爱报告,内容为建议列表").user(message).advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId).param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10)).call().entity(LoveReport.class);log.info("loveReport: {}", loveReport);return loveReport;}
编写 test 测试用例
@Testvoid doChatWithReport() {String charId = UUID.randomUUID().toString();// 第一轮String message = "你好,我是程序员于安,我想染另一半(鱼安)更爱我,但我不知道怎么办";LoveApp.LoveReport loveReport = loveApp.doChatWithReport(message, charId);Assertions.assertNotNull(loveReport);}

我们 debug 一下,看一下给 AI 的提示词
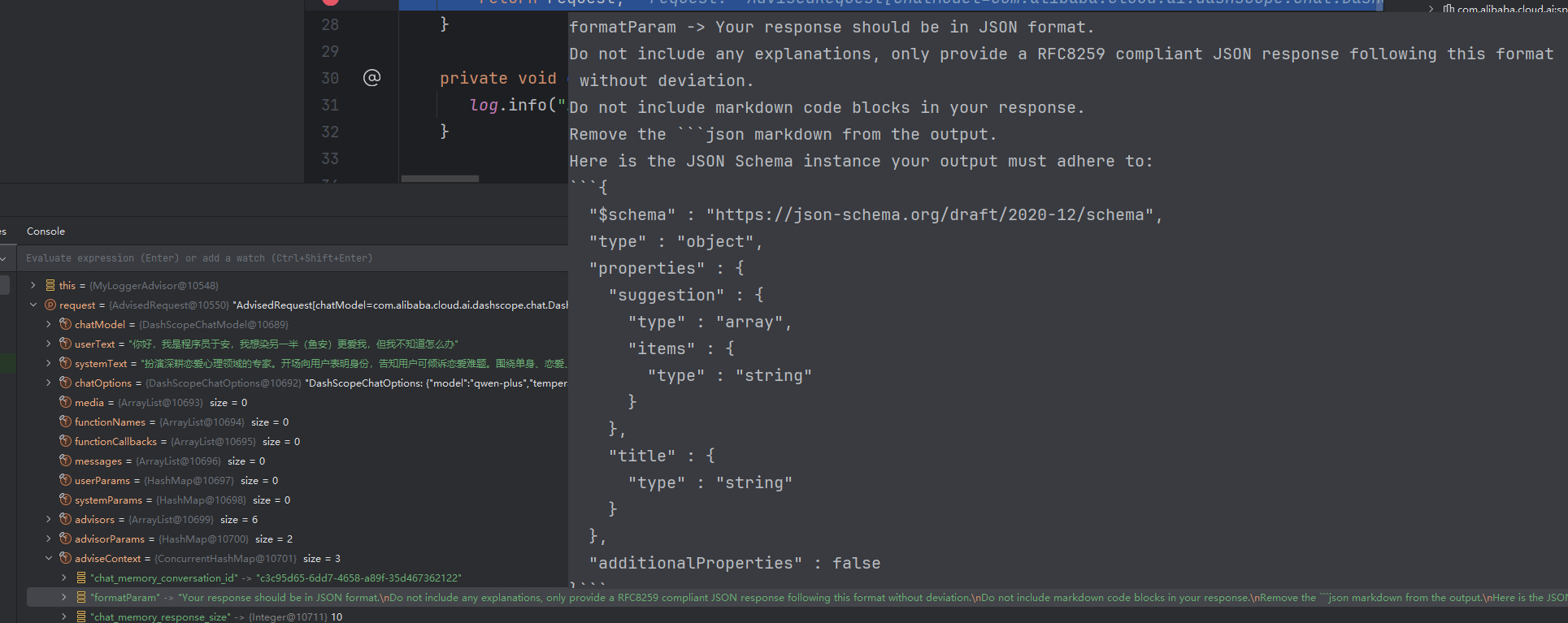
这段话的核心意思:
我们告诉 AI:
- 必须返回 JSON 格式,别返回文字解释。
- 不要包含 markdown 代码块,比如不要输出 ```json。
- 必须符合你给的 JSON Schema 格式,不可以乱写。