通过知识整合重新审视医学图像检索|文献速递-深度学习医疗AI最新文献
Title
题目
Revisiting medical image retrieval via knowledge consolidation
通过知识整合重新审视医学图像检索
01
文献速递介绍
基于内容感知的医学图像检索与异常检测研究:从特征融合到精准推荐 随着医学影像在疾病诊断和患者管理中的作用日益凸显(Willemink et al., 2020),临床和科研领域积累了海量影像数据。除文本查询系统外,图像检索已成为病例分析和临床教学的核心环节,其通过快速定位相似影像,为医生和AI模型提供高效诊断与预后支持。然而,现有方法在大规模影像库中常面临内容相关性排序能力不足的挑战,而哈希技术虽能将高维数据压缩为二进制哈希码(便于基于汉明距离的快速检索),但传统哈希方法因特征提取能力有限,检索精度难以满足医疗场景需求。 尽管深度学习哈希方法(如Li et al., 2018)已显著提升性能,现有技术仍可分为两类: - 动态哈希(如孪生/三元组哈希):通过对比学习迫使正样本在隐空间中接近、负样本远离(Yang et al., 2023); - 固定哈希:将检索视为分类任务,训练网络为每个类别学习预定义哈希码(Yuan et al., 2020; Fan et al., 2020)。 现存挑战 1. 表征学习不充分:多数方法仅利用瓶颈层特征或简单拼接层级嵌入,无法兼顾浅层细节与深层语义,导致特征表达能力不足。 2. 类内中心偏移:对比学习依赖正负样本对,但同类样本间的显著视觉差异(如图1所示)会阻碍模型收敛,且松弛汉明距离的突变概率函数易引发训练不稳定。 3. 分布外泛化薄弱:现有模型对分布外(OOD)数据泛化能力差,易将异常样本误分类到已知类别。 4. 内容推荐缺失:多数研究未实现基于内容相似性的检索结果排序。 #### 解决方案:异常感知内容图像推荐框架(ACIR) 为解决上述问题,本研究提出ACIR框架,旨在实现高性能检索并基于图像内容精准排序相关结果: 1. 深度感知特征融合(DaRF): - 设计DaRF模块集成多尺度特征(浅层细节+深层语义),并通过像素视觉Transformer(PiT)全局优化卷积茎(Convstem)输出的深层特征,增强层级表征的互补性。 2. 结构感知对比哈希(SCH): - 引入图像指纹构建结构感知配对机制,为类内差异大的正样本对分配“中性标签”,缓解中心偏移问题; - 采用皮尔逊系数替代松弛汉明距离度量隐空间样本距离,避免概率函数突变导致的训练不稳定。 3. 自监督OOD检测: - 通过自监督解码器捕捉图像重建差异,识别分布外样本,提升模型对异常数据的鲁棒性。 4. 内容引导排序: - 计算层级整合嵌入的平均相似性,实现基于内容的分类与检索结果精准排序。 实验与性能 研究在多解剖学数据集上验证ACIR性能: - RadioImageNet CT(29,903张灰度图像,16类) - 乳腺癌语义分割(BCSS)数据集(18,678张RGB图像,6类) 核心贡献: - 提出基于图像指纹的结构感知配对机制,解决类内中心偏移问题; - 构建ConvMSA、PiT与深度感知融合模块的新型架构,强化层级特征整合; - 采用皮尔逊相关系数优化距离度量,缓解梯度不稳定问题; - 开发自监督OOD检测模块,利用重建差异实现可靠检索; - 设计内容引导排序机制,提升检索结果的鲁棒性与准确性。
Abatract
摘要
As artificial intelligence and digital medicine increasingly permeate healthcare systems, robust governanceframeworks are essential to ensure ethical, secure, and effective implementation. In this context, medical imageretrieval becomes a critical component of clinical data management, playing a vital role in decision-makingand safeguarding patient information. Existing methods usually learn hash functions using bottleneck features,which fail to produce representative hash codes from blended embeddings. Although contrastive hashing hasshown superior performance, current approaches often treat image retrieval as a classification task, usingcategory labels to create positive/negative pairs. Moreover, many methods fail to address the out-of-distribution(OOD) issue when models encounter external OOD queries or adversarial attacks. In this work, we proposea novel method to consolidate knowledge of hierarchical features and optimization functions. We formulatethe knowledge consolidation by introducing Depth-aware Representation Fusion (DaRF) and Structure-awareContrastive Hashing (SCH). DaRF adaptively integrates shallow and deep representations into blended features,and SCH incorporates image fingerprints to enhance the adaptability of positive/negative pairings. Theseblended features further facilitate OOD detection and content-based recommendation, contributing to a secureAI-driven healthcare environment. Moreover, we present a content-guided ranking to improve the robustnessand reproducibility of retrieval results. Our comprehensive assessments demonstrate that the proposed methodcould effectively recognize OOD samples and significantly outperform existing approaches in medical imageretrieval (p< 0.05). In particular, our method achieves a 5.6–38.9% improvement in mean Average Precisionon the anatomical radiology dataset.
随着人工智能和数字医学日益渗透到医疗保健系统中,建立健全的治理框架对于确保其符合伦理、安全且有效实施至关重要。在此背景下,医学图像检索成为临床数据管理的关键组成部分,在辅助决策和保护患者信息方面发挥着重要作用。现有的医学图像检索方法通常利用瓶颈特征来学习哈希函数,但这种方式难以从混合嵌入中生成具有代表性的哈希码。尽管对比哈希已表现出优越性能,但当前方法常将图像检索视为分类任务,仅使用类别标签来创建正负样本对。此外,当模型遇到外部分布外(OOD)查询或对抗性攻击时,许多方法无法有效解决分布外问题。 为此,我们提出了一种整合分层特征和优化函数知识的新方法。通过引入深度感知表示融合(DaRF)和结构感知对比哈希(SCH)来实现知识整合: - DaRF模块:自适应地将浅层和深层特征融合为混合特征,增强特征的多尺度表达能力; - SCH模块:结合图像指纹信息优化正负样本对的构建,提升对比学习的适应性。 这些混合特征不仅有助于分布外样本检测(OOD detection)和基于内容的推荐,还能为安全的AI医疗环境提供支持。此外,我们提出了内容引导排序策略,以提高检索结果的鲁棒性和可重复性。综合评估表明,该方法能够有效识别分布外样本,在医学图像检索任务中显著优于现有方法(p<0.05)。特别是在解剖放射学数据集上,平均精度(mean Average Precision)提升了5.6–38.9%。 研究亮点: 1. 提出分层特征融合与结构感知对比学习框架,解决传统哈希方法的特征表达不足问题; 2. 首次将图像指纹引入对比哈希,增强模型对分布外样本和对抗攻击的鲁棒性; 3. 结合内容引导排序,提升医学图像检索的临床实用性和结果可信度。 该研究为构建安全、可靠的AI医疗图像检索系统提供了新范式,有望推动智能医疗在数据管理和精准诊断中的实际应用。
Method
方法
An overview of the proposed ACIR is demonstrated in Fig. 3. ACIRmainly comprises four parts, with a hybrid encoder ConvPiT and adepth-aware representation fusion module for learning high-efficientrepresentations, structure-aware contrastive learning for addressing theover-centralized issue, a reconstruction module for OOD detection, andcontent-guided ranking for ranked retrieval.
图3展示了所提出的ACIR方法概述。ACIR主要包括四个部分:用于学习高效表征的混合编码器ConvPiT和深度感知表示融合模块、解决类内中心偏移问题的结构感知对比学习模块、用于分布外(OOD)检测的重建模块,以及用于检索排序的内容引导排序模块。
Conclusion
结论
This paper introduces an innovative and resilient image recommendation system that produces ordered retrieval outcomes basedon content similarity. The suggested ACIR creatively consolidates hierarchical knowledge into blended representations through a Depthaware Representation Fusion and Structure-aware Contrastive Hashing.The OOD detection model has significantly improved the model’s retrieval capacity, especially for out-of-distribution query samples. Extensive experiments have demonstrated that ACIR achieved state-ofthe-art performance in context-based retrieval and OOD recognitionon both pathology and radiology datasets. The results suggest thatACIR is a promising and adaptable solution for practical image retrievalapplications in various imaging environments.
本文介绍了一种创新且鲁棒的图像推荐系统,该系统可基于内容相似性生成有序的检索结果。所提出的ACIR框架通过深度感知表示融合(Depth-aware Representation Fusion)和结构感知对比哈希(Structure-aware Contrastive Hashing),创造性地将层级知识整合到混合表征中。其中,分布外(OOD)检测模块显著提升了模型对分布外查询样本的检索能力。大量实验表明,ACIR在病理学和放射学数据集上均实现了基于内容检索和OOD识别的先进性能。研究结果表明,ACIR是一种有前景且适应性强的解决方案,适用于各种成像环境下的实际图像检索应用。
Results
结果
4.1. Datasets and training details
We conducted experiments on two publicly available datasets.BPS: BPS includes 18 703 images collected from Amgad et al. (2019)and Graham et al. (2021), with 6 categories of tumour (n = 6659),stroma (n = 4052), inflammatory (n = 2798), necrosis (n = 1876), fat(n = 1674), and gland (n = 1619). Specifically, images were split intotraining (n = 13 092), valid (n = 3740), and test (n = 1871) sets.
RadIN-CT: RadIN-CT, based on RadioImageNet (Mei et al., 2022), includes multiple anatomical cases with sixteen clinical patterns: normalabdomen (n = 2158), airspace opacity (n = 1987), bladder pathology(n = 1761), bowel abnormality (n = 2170), bronchiectasis (n = 2025),interstitial lung disease (n = 2278), liver lesions (n = 2182), normallung ovarian (n pathology = 2028), nodule (n = 1471), (n = pancreatic 2029), osseous lesion neoplasm (n = 2165), (n = prostate 1584),lesion (n = 948), renal lesion (n = 2200), splenic lesion (n = 653),and uterine pathology (n = 2194). The dataset comprises mostly axialplane images, with some noisy, magnified, and coronal view samples.The 29 903 images are split into training (n = 20 932), validation (n =5980), and test (n = 2991) sets.
4.1 数据集与训练细节 我们在两个公开可用的数据集上开展了实验。 BPS数据集:BPS包含18,703张图像,数据源自Amgad等人(2019)和Graham等人(2021)的研究,涵盖6个类别:肿瘤(n=6,659)、基质(n=4,052)、炎症(n=2,798)、坏死(n=1,876)、脂肪(n=1,674)和腺体(n=1,619)。具体而言,图像被划分为训练集(n=13,092)、验证集(n=3,740)和测试集(n=1,871)。 RadIN-CT数据集:RadIN-CT基于RadioImageNet(Mei等人,2022),包含多种解剖病例,涉及16种临床模式:正常腹部(n=2,158)、肺实变(n=1,987)、膀胱病变(n=1,761)、肠道异常(n=2,170)、支气管扩张(n=2,025)、间质性肺疾病(n=2,278)、肝病变(n=2,182)、正常肺(n=2,028)、结节(n=2,029)、骨肿瘤(n=1,584)、卵巢病变(n=1,471)、胰腺病变(n=2,165)、前列腺病变(n=948)、肾病变(n=2,200)、脾病变(n=653)和子宫病变(n=2,194)。该数据集主要由轴向平面图像组成,同时包含部分含噪声、放大或冠状面的样本。29,903张图像被划分为训练集(n=20,932)、验证集(n=5,980)和测试集(n=2,991)。
Figure
图
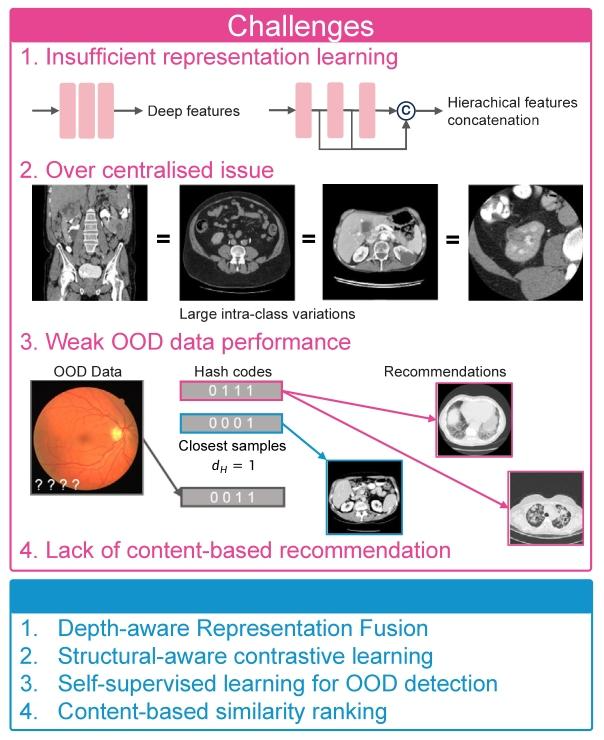
Fig. 1. Challenges of medical image retrieval, with insufficient representation learning(using deep features or hierarchical concatenation), over-centralized issues (ignoringthe intra-class variations), OOD interference (weak capacity against OOD samples), andlack of content-based recommendation.
图1. 医学图像检索面临的挑战 包括表征学习不充分(仅使用深层特征或层级拼接)、类内中心偏移问题(忽略类内样本差异)、分布外(OOD)干扰(对异常样本鲁棒性不足)以及缺乏基于内容的推荐能力。
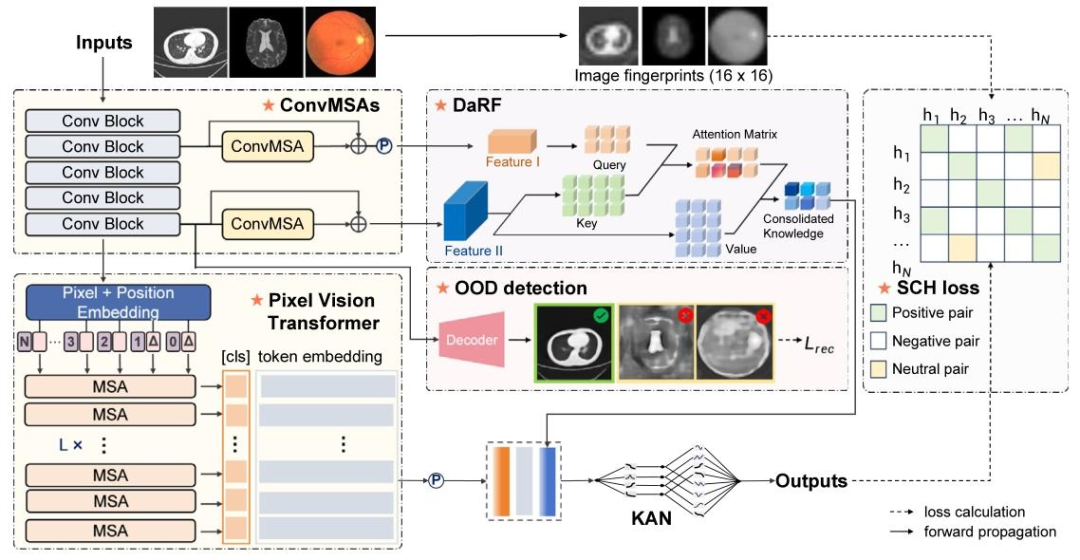
Fig. 2. Overview of the proposed method. ACIR leverages images and their corresponding low-resolution fingerprints for structure-aware contrastive hashing (SCH). The hashembeddings H are obtained by Convolutional Multi-head self-attention layers (ConvMSAs), Depth-aware Fusion (DaRF) and Kolmogorov–Arnold Network (KAN). Additionally, aself-supervised module is integrated to enhance Out-of-Distribution (OOD) detection capabilities.
图2. 所提方法概述 ACIR框架利用图像及其对应的低分辨率指纹进行结构感知对比哈希(SCH)。哈希嵌入H通过卷积多头自注意力层(ConvMSAs)、深度感知融合模块(DaRF)和科尔莫戈罗夫-阿诺德网络(KAN)生成。此外,框架集成自监督模块以增强分布外(OOD)检测能力。
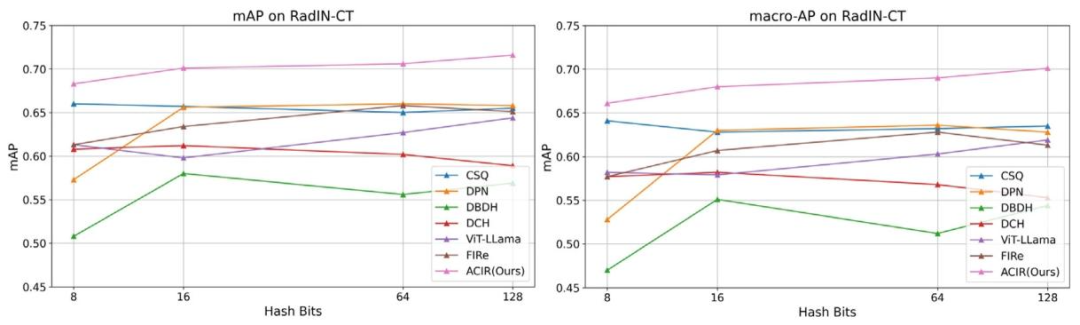
Fig. 3. mean average precision (mAP) and macro average precision (maAP)on RadIN-CT dataset. All the models were trained according to their released codes.
图3. 在RadIN-CT数据集上的平均精度均值(mAP)和宏平均精度(maAP)。所有模型均按照其发布的代码进行训练。
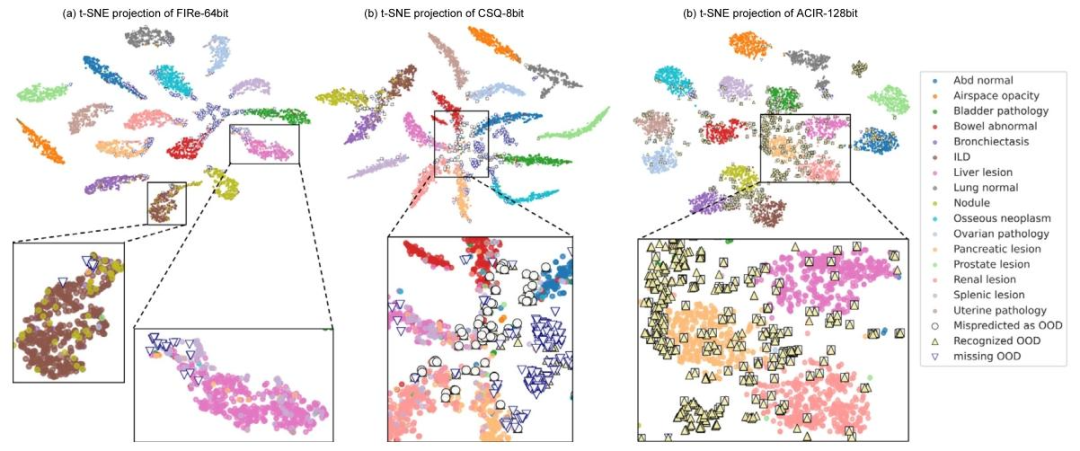
Fig. 4. t-SNE projection of class distribution of (a) FIRe-64 bit, (b) CSQ-8 bit and (c) ACIR-128 bit. The magnified windows highlight the distribution of the hash embeddings forrenal, pancreatic, and liver lesions. ACIR presented much cleaner and tidier clusters compared with FIRe and CSQ, with fewer mispredictions and more recognized OOD samples
图4. 类分布的t-SNE可视化结果 (a)FIRe-64位、(b)CSQ-8位和(c)ACIR-128位的哈希嵌入分布。放大窗口突出显示了肾脏、胰腺和肝脏病变的哈希嵌入分布。与FIRe和CSQ相比,ACIR的聚类更清晰整洁,误预测更少,且能识别更多分布外(OOD)样本。
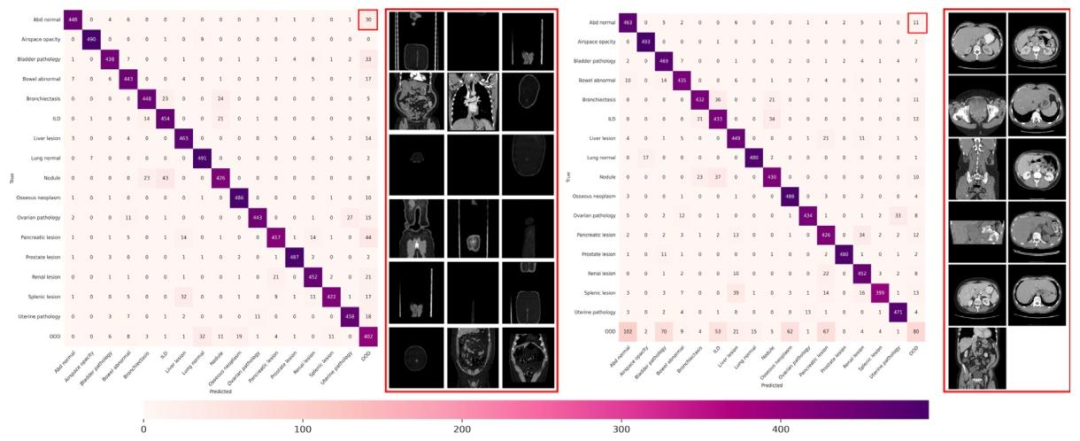
Fig. 5. Confusion matrix of ACIR (left) and CSQ (right) with details of mispredicted samples on OOD dataset (classified as Abd normal but predicted as OOD). The false predictionssuggest that ACIR has the capacity to identify low-quality or challenging samples
图5. ACIR(左)与CSQ(右)的混淆矩阵及OOD数据集误预测样本细节(实际为腹部正常但被预测为OOD)。误预测结果表明ACIR具备识别低质量或复杂样本的能力。
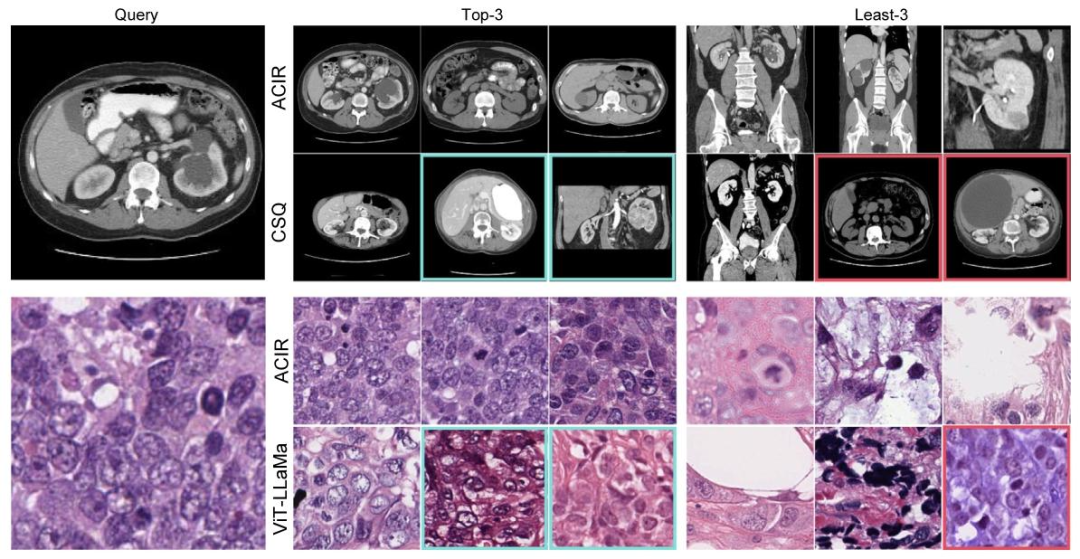
Fig. 6. Ranked retrieval results given by ACIR, CSQ (2nd place on RadIN-CT), and ViT-LLaMa (2nd place on BPS). The top-3 similar and dissimilar samples for the query imageswere presented. Samples with cyan boxes indicate the top-3 similar samples (to the query) while with considerable visual differences exist. Samples with red boxes indicate theleast-3 retrieved samples with certain visual similarities.
图6. 由ACIR、CSQ(RadIN-CT数据集第二名)和ViT-LLaMa(BPS数据集第二名)提供的检索排序结果。图中展示了查询图像的前3个最相似和最不相似样本。青色框标注的样本为与查询图像“前3相似”但存在显著视觉差异的结果,红色框标注的是“最不相似”但具有一定视觉相似性的检索结果。
Table
表
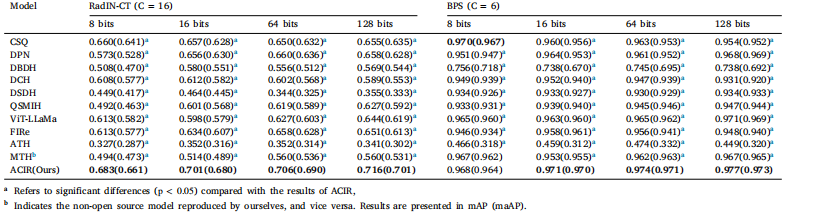
Table 1Comparison studies on BPS and RadIN-CTL.
表1 BPS和RadIN-CT数据集上的对比研究
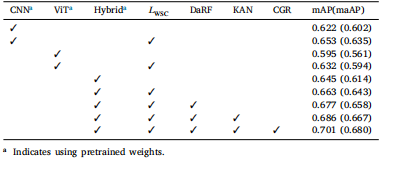
Table 2Ablation studies of ACIR
表2 ACIR的消融研究
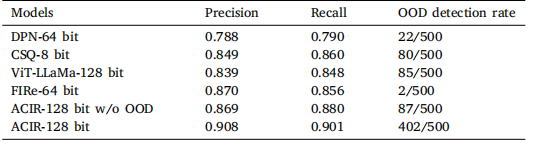
Table 3Out-of-distribution assessment.
表3 分布外(OOD)评估
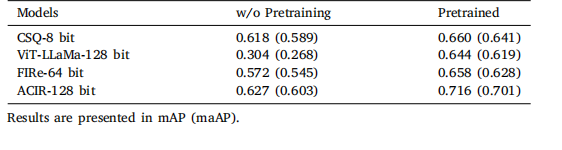
Table 4Pretraining assessment
表4 预训练评估
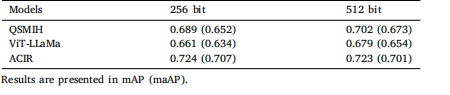
Table 5Sparse hash bits assessment.
表 5 稀疏哈希位评估
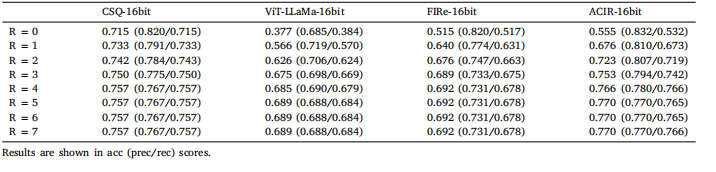
Table 6Model performance of different comparisons
表6 不同对比模型的性能表现

Table 7Efficiency and scale assessment
表7 效率与规模评估