句法分析 自然语言处理
目录
一 概述
二 短语结构分析
三 线图分析法
自底向上的Chart 分析算法
四 CYK分析算法
五 概率上下文无关文法
六 PCFG的三个问题
1、内向算法或外向算法解决第一个问题——快速地计算句子的句法树概率
2、Viterbi 算法解决第二个问题最佳分析结果搜索
3、内外向算法解决第三个问题-参数估计
章节练习
一 概述
任务:句法分析(syntactic parsing)的任务就是 识别句子的句法结构(syntactic structure)。
类型:
短语结构分析(Phrase parsing):完全句法分析(Full parsing) 局部句法分析(Partial parsing)
依存句法分析(Dependency parsing)
二 短语结构分析
每一个词性都有一个英文缩写:
名词相关
- NN/N(Noun,名词):表示普通名词,像 “措施”“政策”“要点” ,都是具体或抽象的事物名称 。
- NP(Noun Phrase,名词短语 ):不是单个名词,是名词和修饰它的词组成的短语,比如 “具体措施”“政策要点” ,整体当名词用 。
代词
- PN(Pronoun,代词):用来指代人、事、物,例子里 “他” 就是代词,代替具体的人 。
动词
- VV/V(Verb,动词):表示动作或行为,“提出” 就是典型动词,说明主语的行为 。
副词
- AD(Adverb,副词):修饰动词、形容词等,“还” 用来修饰 “提出” ,说明动作的状态(这里是追加、补充的意思 ) 。
形容词
- JJ(Adjective,形容词):修饰名词,描述事物的性质、状态,“具体” 就是形容词,修饰 “措施” ,说明措施的性质 。
数词、量词 Det(限定词)
- CD(Cardinal Digit,数词 ):表示数量,“一” 就是数词 。
- M(Measure Word,量词 ):和数词搭配,“系列” 就是量词,“一系列” 就是数词 + 量词的组合 。
连词、标点
- CC(Coordinating Conjunction,连词 ):连接词语、短语等,“和” 就是连词,连接 “措施” 与 “政策要点” 。
- PU(Punctuation,标点 ):像句号 “。” ,就是标点 。
句法功能短语
- IP(Independent Clause,独立分句 / 句子 ):整个句子的大框架,把主语、谓语等都包含进去,代表完整的句子结构 。
- NP - SBJ(Noun Phrase - Subject,主语名词短语 ):句子里作主语的名词短语,“他” 所在的 (NP - SBJ (PN 他)) ,就是主语部分 。
- VP(Verb Phrase,动词短语 ):动词和相关修饰词、宾语等组成的短语,“还提出……” 整体是 VP ,包含动作和相关内容 。
- NP - OBJ(Noun Phrase - Object,宾语名词短语 ):句子里作宾语的名词短语,“一系列具体措施的政策要点” 整体是 NP - OBJ ,是 “提出” 这个动作的对象 。

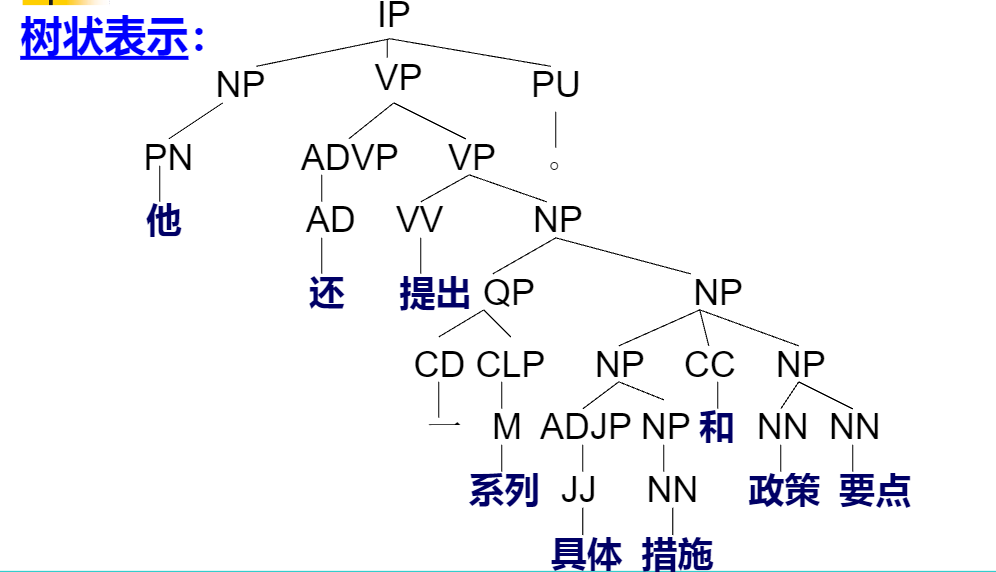
原句 “他还提出一系列具体措施的政策要点” ,后面蓝色的是把句子拆成单个词,还标了每个词的 “身份(词性)” : 他/PN : “他” 是代词(PN 就是代词的缩写 ) 还/AD: “还” 是副词(AD ),用来修饰动作。 提出/VV : “提出” 是动词(VV) 一/CD: “一” 是数词(CD ,计数用的 ),表示数量 ........简单说,句法分析就是把一句话拆成单个词,再给每个词 “贴标签(标词性)” ,方便搞清楚句子里谁是代词、谁是动词、谁是名词,还有这些词咋组合起来表达意思,就像把一堆积木分类,再看咋搭成句子这座 “房子” 。

这是给句子做 “结构拆解”,像剥洋葱一样,一层一层理清词语组合、谁是句子里的 “小部件” :
先看符号和层级
括号一堆,是把句子拆成不同 “模块”,括号里的英文是模块 “身份”,比如:
- IP:整个句子的大框架(句子层面),就像房子的 “整体结构” 。
- NP - SBJ:主语模块(NP 是名词短语,SBJ 是主语,合起来就是 “主语的名词短语” ),句子里 “谁” 干的事儿 。
- VP:谓语模块(动词短语),“干啥事儿” 的动作部分 。
- ADVP:状语模块(副词短语 ),修饰动作,说明 “咋干、啥时候干” 。
- NP - OBJ:宾语模块(宾语的名词短语 ),动作的对象 。
- QP:数量短语模块,管数量的 。
- CLP:量词短语模块,和数词配对(“一 + 系列” 里 “系列” 是量词 ) 。
- ADJP:形容词短语模块,修饰名词,让意思更具体 。
- CC:连词,连接并列的词 。
- PU:标点 。
再一层一层拆句子
原句是 “他还提出一系列具体措施的政策要点。” ,对应结构:
- 最外层(IP):整个句子的大包裹,把主语、谓语、标点全装进去,就是说 “这是完整一句话” 。
- 主语(NP - SBJ):(NP - SBJ (PN 他)) ,“他” 是代词(PN),当句子主语,就是 “干事儿的人是‘他’” 。
- 谓语(VP):(VP (ADVP (AD 还)) (VP (VV 提出 ))) , 这里是两层 VP(动词短语):
- 外层 ADVP 是状语,“还” 是副词(AD),修饰 “提出”,表示 “额外、补充做这个动作” ;
- 内层 VP 里 “提出” 是动词(VV),就是具体动作 。
- 宾语(NP - OBJ):这部分最复杂,是动作 “提出” 的对象,拆着看:
- 先看 (QP (CD 一) (CLP ( M 系列 ))) :“一” 是数词(CD),“系列” 是量词(M),组成 “一系列”,说数量 + 量词的搭配 。
- 再看 (NP (NP (ADJP ( JJ 具体) (NP (NN 措施)))) ( CC 和) ( NP ( NN 政策 ) ( NN 要点 )))) :
- “(ADJP ( JJ 具体) (NP (NN 措施)))” 里,“具体” 是形容词(JJ),修饰名词 “措施”(NN),就是 “具体的措施” ;
- “(CC 和)” 是连词 “和”,连接 “措施”“政策要点” ;
- “(NP ( NN 政策) ( NN 要点 ))” 里,“政策”“要点” 都是名词(NN),组合成 “政策要点” 。
合起来,宾语就是 “一系列具体的措施和政策要点” 。
- 标点(PU):(PU 。) ,句子结束的句号 。
这整套操作,就是把日常说的句子,用 “模块 + 层级” 的方式拆开,让我们清楚:谁(他) + 咋干(还 + 提出) + 干啥(一系列具体的措施和政策要点) + 结束(。) ,像给句子画 “结构地图”,能看透词语咋抱团、咋组成完整意思,方便电脑理解人类语言的结构逻辑 。
目标:实现高正确率、高鲁棒性 (robustness)、高速度的自动句法分析过程。
困难:自然语言中存在大量的复杂的结构歧 义(structural ambiguity)。


三 线图分析法
三种策略:自底向上 (Bottom-up),从上到下 (Top-down),从上到下和从下到上结合,这里只介绍第一种
自底向上的Chart 分析算法

咱就说这个 “自底向上的 Chart 分析算法”,可以这么理解:
准备材料
首先得有 CFG 规则 ,就好比是语法公式,规定啥样的组合能变成更大的语法单位,像 “XP(可以理解成一种语法块,比如名词短语、动词短语 )能由 α₁到 αₙ这些小部分组成(n 至少是 1,就是最少一个小部分凑成 )” 。
然后得有要分析的句子的 词性序列 ,把句子里每个词的词性排一排,比如句子是 “我吃饭”,词性序列可能就是 “代词 动词 名词” ,这里用 W₁、W₂…Wₙ代表这些词性 。
搭建 “地图”(线图)
接着要 构造线图 ,这就像画一条带节点的线,节点把线分成一段一段,每个节点对应词性序列里的位置,从 0 开始,到 n 结束(n 是词性数量 )。比如词性有 3 个,节点就是 0、1、2、3,把 W₁、W₂、W₃串起来 ,边就是节点之间的线段,用来记录语法分析过程中可能的组合。
记笔记的 “二维表”
还要 建立二维表 ,就像个表格,记着每条边从哪儿开始(起始位置)、到哪儿结束(终止位置),这样分析的时候,就能清楚每个语法组合在词性序列里占了哪一段,方便一步步从最基础的词性,按照 CFG 规则往上组合,最终分析出整个句子的语法结构啦,这就是从 “底”(单个词性)往 “上”(完整语法结构)分析的思路 。 简单说,就是用规则、词性序列,靠线图和二维表,从词的词性开始,一步步拼出句子的语法结构~
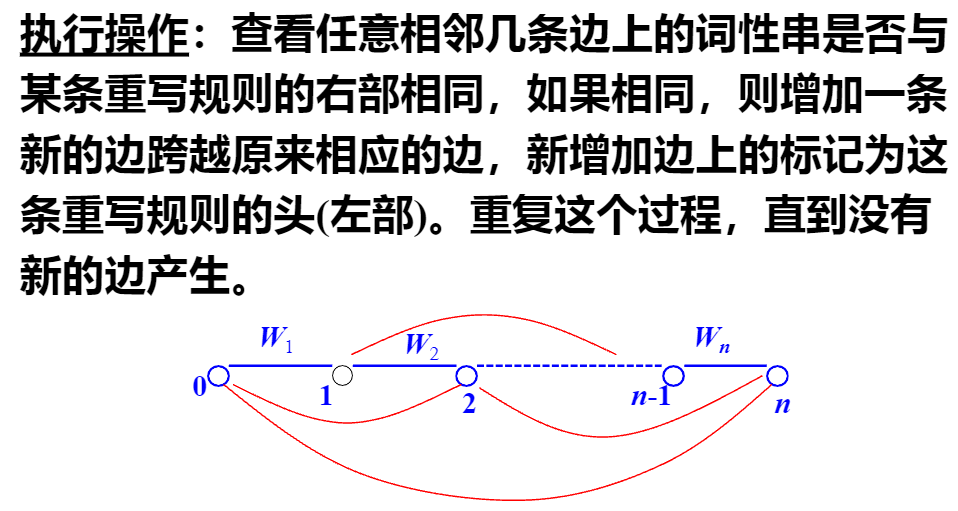
可以把这个过程想象成用 “语法拼图规则”,把零散的词性 “小块” 逐步拼出完整语法结构, 用大白话拆解:
前提:有 “拼图规则” 和 “词性小块”
咱们得先有 重写规则 ,就当是 “拼图说明书”,规定啥样的小词性组合,能拼成一个大的语法块(比如 “形容词 + 名词” 能拼成 “名词短语” ,规则就是 “名词短语 → 形容词 名词” )。
还有要分析的句子拆出来的 词性序列 ,像把 “美丽的花” 拆成 “形容词、助词、名词” ,这些单个词性就是拼图的 “小块” 。
核心操作:找匹配,拼新块
接着开始 执行操作 :
- 看相邻的 “词性小块”(对应图里相邻边上的词性串 ),能不能和 “拼图说明书”(重写规则)里右边的组合对上。
- 要是对上了,就像按说明书把小拼图拼成大拼图一样,新增一条 “大边” ,跨过原来那些小边,这条新边的标记,就是说明书左边的大语法块(比如用 “名词短语” 标记这条新边 )。
- 就这么一直重复,把能拼的都拼起来,直到再也拼不出新的大语法块(没新边产生 )。
举个例子更明白
假设规则有 “名词短语(NP)→ 形容词(ADJ) 名词(N)” ,句子词性序列是 “ADJ(美丽)、N(花)” :
- 先看相邻边的词性串 “ADJ、N” ,和规则右边 “ADJ N” 对上了。
- 那就新增一条边,从起始位置跨到结束位置,标记成 “NP” ,相当于把 “美丽” 和 “花” 拼成 “名词短语” 这个大语法块 。
要是还有其他规则,比如 “句子(S)→ 名词短语(NP) 动词短语(VP)” ,后续要是拼出 “VP” ,又能接着和 “NP” 拼出 “S” ,直到没新边,就把句子的语法结构拼出来啦~
简单说,就是用语法规则当说明书,把词性小零件逐步拼成更大的语法部件,直到拼不动,把句子的语法结构 “拼” 出来 ,这样整个句子的语法分析就完成咯!

1. “点规则” 是干啥的
打个比方,规则 “NP → Det A N” ,就是说 “名词短语(NP)” 这个大积木,得用 “限定词(Det) + 形容词(A) + 名词(N)” 这三个小积木拼出来。“点” 的位置,就记录拼到哪一步了。
2. 看例子里的规则和句子
- 规则:这里给了好几条拼 “NP(名词短语)” 大积木的规则,相当于不同的拼法:
- 可以用 “Det + A + N” 拼(NP → Det A N )
- 可以偷懒,用 “Det + N” 拼(NP → Det N )
- 也能简化成 “A + N” 拼(NP → A N )
- 句子:“The good book” ,拆成小积木(词性)就是 “Det(The )、A(good )、N(book )” ,要拿这些小积木,用上面的规则拼出 “NP” 大积木。
3. 点规则咋标记 “拼积木进度”
- NP → Det • A N :点在 “Det” 后面,意思是 “已经拼好了 Det 这个小积木,接下来要拼 A 和 N” 。就像玩积木,先放好了 “Det(The )” ,等着放 “A(good )” 和 “N(book )” 。
- NP → Det • N :点在 “Det” 后面,代表 “已经有 Det ,接下来直接拼 N” 。对应句子里,就是用 “Det(The ) + N(book )” 拼 NP ,不过句子里还有 A(good ),所以这条规则可能不是最终用的,但分析时会考虑。
- NP → Det A • N :点在 “A” 后面,说明 “Det 和 A 都拼好了,就差 N 了” 。对应句子里,就是已经放了 “Det(The ) + A(good )” ,就等 “N(book )” 。
- NP → Det A N • :点在最后,意味着 “右边(Det + A + N )的小积木全拼完了!成功拼出 NP 大积木” 。对应句子,就是把 “The(Det )、good(A )、book(N )” 全用上,按照这条规则拼出了 “NP(名词短语)” 。

- 线图:语法分析的 “进度地图”,记所有拼好的语法块和位置。
- 代理表:刚拼好的 “成品零件仓库”,存能完全匹配规则的新成分。
- 活动边集:“半成品清单”,记还没拼完、差一部分的规则。
1. 线图(Chart):语法分析的 “进度地图”
- 它保存着分析过程中,已经拼好的 “语法小块”(成分),不管是最小的词(终结符,比如 “苹果”“跑” ),还是 bigger 的语法块(非终结符,比如 “名词短语”“动词短语” )。
- 同时记着这些 “小块” 在句子里的位置(从第几个词开始,到第几个词结束 )。
- 形式上,它像一个 n×n 的表格(n 是句子的词数 ),比如句子有 3 个词,就是 3×3 的表格,每个格子能查某个区间的语法成分。
2. 代理表(Agenda,也叫待处理表 ):“刚拼好的零件仓库”
- 啥叫 “能用规则匹配”?比如有规则 “动词短语 → 动词 + 名词”,你刚拼出 “吃 + 饭 = 动词短语”,这个 “动词短语” 就会被放进代理表。
- 这些 “零件”(重写规则代表的成分 ),必须和句子里某一段词性 / 短语完全对上(比如 “吃” 是动词,“饭” 是名词,拼起来刚好符合规则右边 )。
- 它的形式像 “栈” 或者 “队列”,简单说就是 “先进先出” 或者 “后进先出” 的排队方式,方便按顺序处理这些新零件。
3. 活动边集(ActiveArc ):“正在拼的半成品清单”
- 啥叫 “没拼完”?比如规则是 “名词短语 → 形容词 + 名词”,你已经找到 “形容词”,但还没找到 “名词”,这时候这条规则就属于 “正在拼” 的状态,会被放进活动边集。
- 这些 “半成品”(重写规则 ),右边的符号串(比如 “形容词 + 名词” )已经和句子里某一段对上一部分,但还没完全对上(差个词 )。
- 它的形式像数组或者列表,就是把这些没拼完的规则记下来,方便后面继续找词来 “补完” 它们。

步骤拆解
(1)给待处理表 “填零件”
- 情况:如果 “待处理表(Agenda)” 里没东西了(空的),就去句子里找下一个位置的词。
- 操作:把这个词对应的 “词类(比如名词、动词,叫 X )”,加上它在句子里的位置(i 是起始位置,j 是结束位置,j - i 就是词的长度,肯定大于 0 ),打包成 “X (i,j)” ,丢进待处理表。
-
举例:句子是 “The book” ,处理到 “The” 时,它的词类是限定词(Det ),位置是 0 - 1(i=0,j=1 ),就把 “Det (0,1)” 放进待处理表,当 “积木零件” 备用。
(2)从待处理表 “取零件”
从待处理表(Agenda)里拿出一个 “零件”,也就是刚存进去的 “X (i,j)” ,比如上面的 “Det (0,1)” ,准备用它接着拼更大的积木。
(3)用规则 “拼积木”,记 “半成品”
- 找规则:看所有语法规则里,右边是 “X + 其他部分(γ )” 的规则(比如规则是 “A → X γ ” ,A 是要拼的大积木,X 是刚取的零件,γ 是还需要的其他零件 )。
- 记半成品:把这些规则标记成 “进度条” 形式(A → X・γ (i,j) ,点 “・” 表示 “X 已经拼好,接下来要拼 γ ” ),放进 “活动边集(ActiveArc)” ,相当于记下来 “这个大积木已经拼了一部分,还差 γ 没拼” 。
- 调用子程序:然后触发 “扩展弧子程序”,就是接着处理这些 “半成品”,看看能不能找到剩下的 γ ,把积木拼完。
-
举例:假设规则有 “NP → Det γ”(名词短语 NP 由限定词 Det + 其他 γ 组成 ),现在有零件 “Det (0,1)” ,就把 “NP → Det・γ (0,1)” 放进活动边集,记着 “要拼 NP ,已经有 Det ,还差 γ ” ,然后调用子程序找 γ (比如后面的 “book” 对应的词类 )
-

这个算法就是按顺序处理句子里的词,把词变成 “词类 + 位置” 的 “积木零件” 存起来,然后用语法规则,把这些零件往大了拼,过程中记录 “拼到一半的半成品”(活动边集 ),一步步从单词拼出完整的语法结构~ 就像玩积木,先准备小零件,再用说明书(规则)拼大积木,记着拼到哪一步,直到把整个句子的语法拼出来!
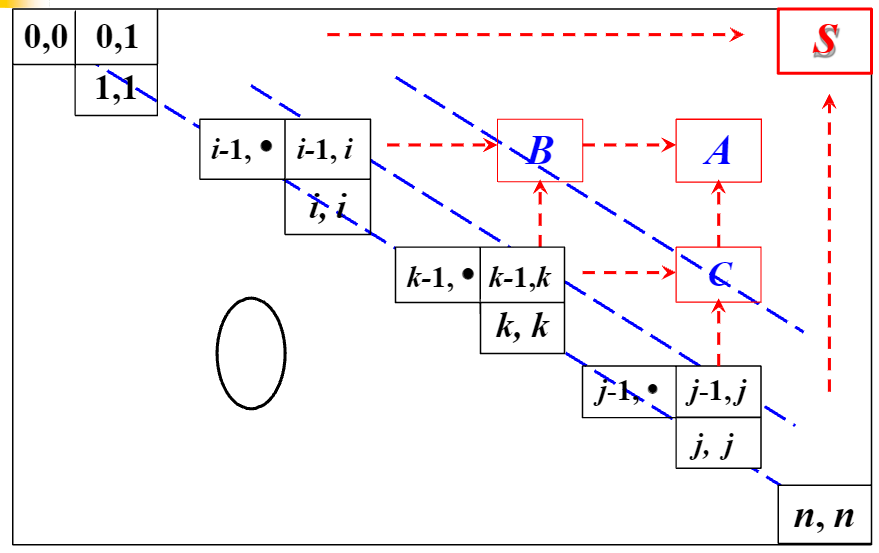
(a) 记 “拼好的积木” 到地图(Chart)录
操作:把刚处理的 “语法积木零件”(比如 A (1,2) ),记录到线图(Chart)的对应位置(i=1, j=2 )。
类比:你拼好了一个 “形容词(A)积木”,在 “语法地图” 上标记:位置 1 - 2 是 A 。
作用:让后续步骤知道 “这里已经有一个 A 积木可用”。
(b) 检查 “半成品清单”,拼新积木
操作:去活动边集(ActiveArc)里找所有 “位置是 (k, i)” 的点规则(i 是当前积木的起始位置,比如 A (1,2) 的 i=1 ,所以找 k < 1 的规则,这里 k=0 ,对应规则 AP → Det • A (0,1) )。
- 如果规则是 A→α•X (比如 AP → Det • A ,A 是要拼的大积木,这里 A=AP ),且 A 是句子起始符号 S(比如整个句子的规则是 S→… ),就把 S (1, n+1) 放进 Chart(表示拼出完整句子 );
- 否则,把新的大积木(比如 AP (0,2) ,因为 Det 在 0-1,A 在 1-2,拼起来是 0-2 )放进待处理表(Agenda),当新零件用。
类比:看 “半成品清单” 里,有没有 “等着 A 来凑的规则”(比如 AP 缺 A )。现在 A 有了,就把 “Det + A” 拼成 AP (0,2) ,丢进 “零件仓库”(Agenda),供后面拼更大的积木(比如 NP )用。
例子:规则 AP → Det • A (0,1) 匹配上了 A (1,2) ,所以把 AP(0,2) 放进待处理表,后续可以用它拼 NP 。
(c) 更新 “半成品清单”,推进进度
操作:对所有位置是 (k, i) 的点规则(比如 NP → AP • N (0,2) ,假设后面会处理 ),把点往后挪,生成新的半成品规则,放进活动边集。
类比:如果有规则 “NP → AP・N”(表示 “AP + N 拼 NP,已经有 AP,等 N” ),现在 AP 拼好了(AP (0,2) ),就把规则更新为 “NP → AP N・(0,3)”(等 N 来凑 ),或者如果有中间步骤,就更新点的位置,记录 “进度条”。
例子:假设后续处理 N (2,3) ,活动边集里有 NP → AP • N (0,2) ,执行这一步时,会把规则变成 NP → AP N • (0,3) ,表示 “AP + N 拼完了,NP 成型” ,并可能放进待处理表。
总结(用 “拼积木流水线” 理解 )
扩展弧子程序就是语法分析的 “推进器” :
- 先把刚拼好的小积木记到 “地图” 上(步骤 a );
- 然后检查 “半成品清单”,把能拼成的中积木丢进 “仓库”(步骤 b );
- 最后更新 “半成品清单”,记录新的拼搭进度(步骤 c )。
结合之前的流程,它的作用就是让 “小积木→中积木→大积木” 的拼接自动推进 ,直到拼出覆盖整个句子的大积木(比如完整的 NP 或句子 S ),最终完成句法分析!

四 CYK分析算法

1. 先做 “文法整形”(范式化)
- 套路 1:
A → w(单个词规则)→ 比如 “名词 → 苹果”,表示 A(名词)可以直接生成单词 w(苹果)。 - 套路 2:
A → BC(双词组合规则)→ 比如 “名词短语 → 形容词 名词”,表示 A(名词短语)可以由 B(形容词)和 C(名词)组合生成。
2. 自下而上 “拼积木”
- 先看每个单词能对应哪些语法成分(用
A → w规则)。 - 再看相邻的语法成分,能不能用
A → BC规则,组合成更大的语法块(比如用形容词 + 名词,拼成名词短语 )。
3. 用 “识别矩阵” 记进度
(n+1)×(n+1) 的表格(n 是句子单词数 ): - 表格的行和列对应句子中单词的位置(从 0 到 n )。
- 每个格子
(i,j),记录 “从第 i 个单词到第 j 个单词” 能组成的语法成分(比如名词、动词短语 )。
(0,1) 记录 “我” 的语法成分,(1,2) 记录 “爱” 的语法成分… 最终位置 (0,3) 会记录整个句子的语法结构(比如 “句子” )。 CYK 算法的核心逻辑
- 规则简化:把语法变成 “单词直接生成” 或 “两个成分组合生成” 的简单规则。
- 自底向上:从单词开始,从小到大拼语法块。
- 表格记录:用矩阵表格清晰记录每个区间能组成的语法成分,最终判断句子是否符合语法,或找出最优结构。



先理解 “识别矩阵” 是啥
就是一个 (n+1)×(n+1) 的表格(n 是句子单词数 ),行和列的数字代表单词在句子里的位置(从 0 开始数 )。每个格子 t[i,j] 记录 “从第 i 个位置到第 j 个位置的单词” 能组成的语法成分(比如名词、动词短语 )。
步骤拆解(结合句子 “我爱你”,n=3,位置 0-3 )
(1) 填 “主对角线”:放单个单词
- 操作:先把表格最中间的对角线(主对角线)填满。规定
t[0,0]=0(占位,不用管 ),然后从t[1,1]到t[3,3],依次填入句子里的单个单词。 - 类比:表格像棋盘,主对角线是 “从左上到右下” 的线,现在在这条线上的格子里,逐个放句子的单词。比如:
t[1,1]放 “我”t[2,2]放 “爱”t[3,3]放 “你”
- 作用:记录每个单词本身的位置,作为 “拼语法块” 的基础。
(2) 填 “紧邻主对角线”:拼两个单词的组合(从下往上一层一层的组合)
- 操作:填主对角线 “上方紧邻” 的格子(比如
t[0,1]、t[1,2]、t[2,3]),这些格子对应 “相邻两个单词的区间”(比如t[0,1]是位置 0-1,对应 “我 + 爱” )。然后从第一个单词开始,分析这些相邻区间能组成的语法成分。 - 类比:在主对角线的 “正上方一排” 格子里,填 “两个相邻单词” 能拼成的语法块。比如看 “我 + 爱”(位置 0-1 ),用语法规则判断它们能组成啥(比如 “主谓短语” ),就填到
t[0,1]里。 - 作用:开始 “拼小语法块”,把相邻单词组合成更大的成分(比如短语 )。
总结:识别矩阵的搭建顺序
- 主对角线:先填单个单词,作为最基础的 “积木零件”。
- 紧邻主对角线:再填相邻两个单词的组合,开始 “拼小积木”。
后续还会继续填更上方的格子(比如 t[0,2]、t[1,3] ),直到填满整个表格,最终 t[0,n](比如 t[0,3] )会记录整个句子的语法结构~
简单说,就是先填单个单词的 “基础格”,再填相邻单词的 “组合格”,一步步把表格填满,拼出句子的语法结构 ,像玩数独一样,按顺序填格子,不过填的是语法成分!

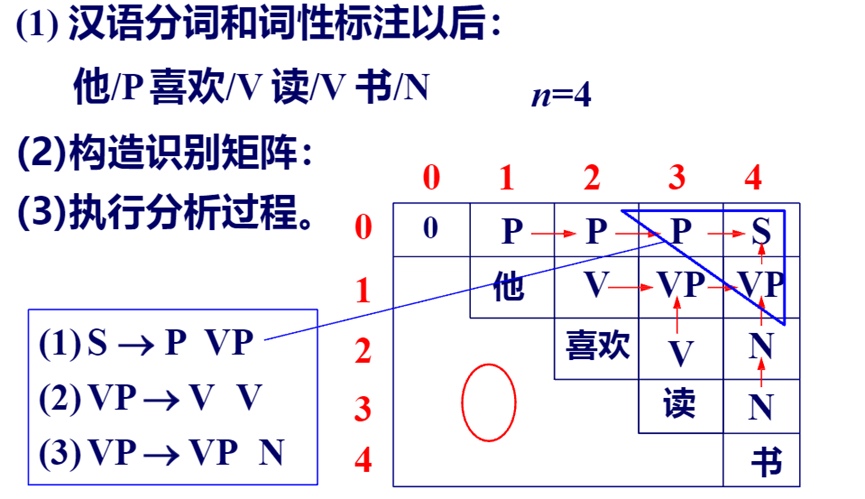
注意这里一定是要从下往上,一行一行的完成!

五 概率上下文无关文法

简单来讲就是给语法规则加上概率,让它们更智能地分析句子结构。
形式(规则长啥样)
“A → α, p” 里:
A是个语法成分(比如名词短语NP、数量词CD这类),就像句子里的 “部门经理” 得归类成名词短语。α是A能拆成的结构(可以是词,也能是短语组合 ),比如NP能拆成 “NN NN(名词 + 名词,像‘苹果 手机’)” 。p是这条拆分规则的概率,代表 “A拆成α” 这种情况有多常见。
约束(必须遵守的规矩)
意思是:对于同一个 A(比如 NP),把它所有可能的拆分规则概率加起来,结果得是 1 。 就像所有 “把 NP 拆成别的结构” 的规则概率,加一起肯定是 100%,这样才合理,不然概率总和乱套,没法选最可能的拆分方式啦。
例子(看明白咋用)
-
NP的拆分:NP → NN NN, 0.60:名词短语NP拆成 “名词 + 名词”(比如 “水果 沙拉” )的概率是 60% 。NP → NN CC NN, 0.40:NP拆成 “名词 + 连词 + 名词”(比如 “苹果 和 香蕉” )的概率是 40% 。 这俩概率加起来0.6 + 0.4 = 1,符合约束~
-
CD的拆分:CD → QP, 0.99:数量词CD拆成QP(像 “三个” 这类数量短语 )的概率是 99% ,超常见。CD → LST, 0.01:CD拆成LST(可能是特殊数量表达 )的概率只有 1% ,很少见。 加起来0.99 + 0.01 = 1,也符合约束~
说白了,PCFG 规则就是给语法拆分配上概率,让电脑分析句子时,能选概率高、更常见的结构,就像人说话时,也会选更顺口、常用的表达方式一样

位置不变性
不管一个子树(可以理解成句子里某部分语法结构 )在句子的啥位置,它的概率都一样。比如句子 “我吃饭” 里,“吃饭” 这个子树(假设是谓语部分 ),不管它在 “我吃饭” 里,还是在 “你知道我吃饭” 里,只要还是 “吃饭” 这个结构,概率就不变,不因为位置变了就影响它自己的概率 。
上下文无关性
子树的概率只和自己管辖范围内的词有关,范围外的词不影响它。还是拿 “我吃饭在食堂” 举例,“吃饭” 这个子树的概率,和 “在食堂” 这些范围外的内容没关系,只看 “吃饭” 内部的结构和词,就算把 “在食堂” 换成 “在家”,“吃饭” 自身概率该咋算还咋算 。
祖先无关性
子树的概率,和它 “祖宗”(推导它的上层结构 )没啥关系。比如从 “动作” 这个大结构推导出 “吃饭”,又从 “句子” 推导出 “动作”,但 “吃饭” 这个子树的概率,不 care 是从啥 “祖宗” 结构来的,自己该啥概率就是啥概率 ,不管上层咋变,自己内部概率计算不受牵连 。
简单说,就是为了能算出分析树概率,假设子树概率不受位置、外面的词、上层结构干扰,把复杂情况简化,方便计算~ 这样在处理句子语法结构概率时,不用考虑一堆额外复杂因素,能更 straightforward(直来直去 )地算啦 。
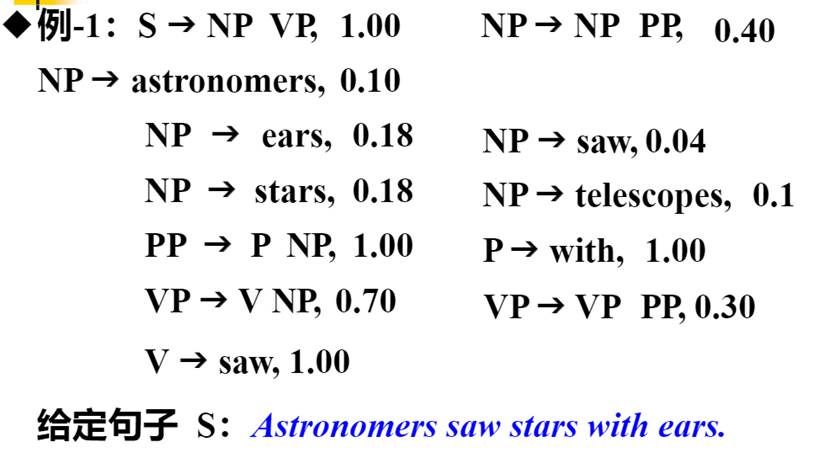
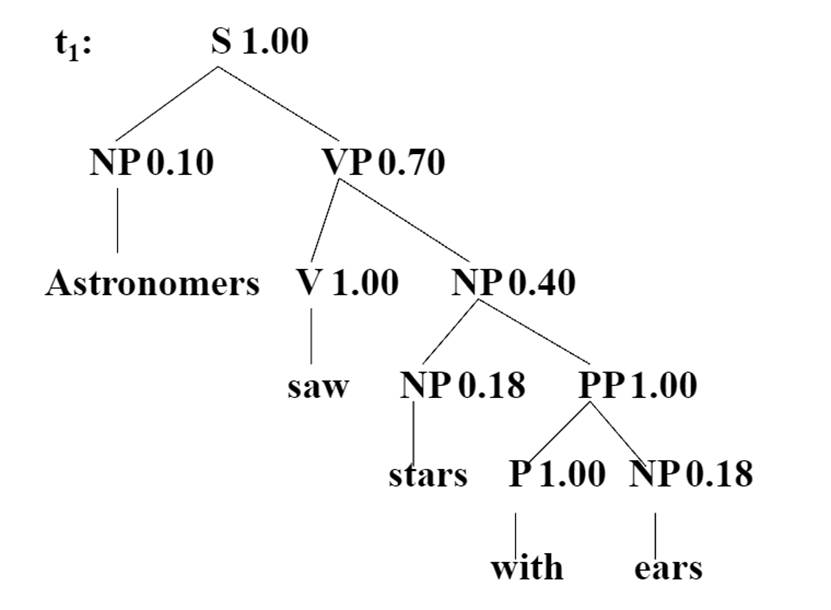
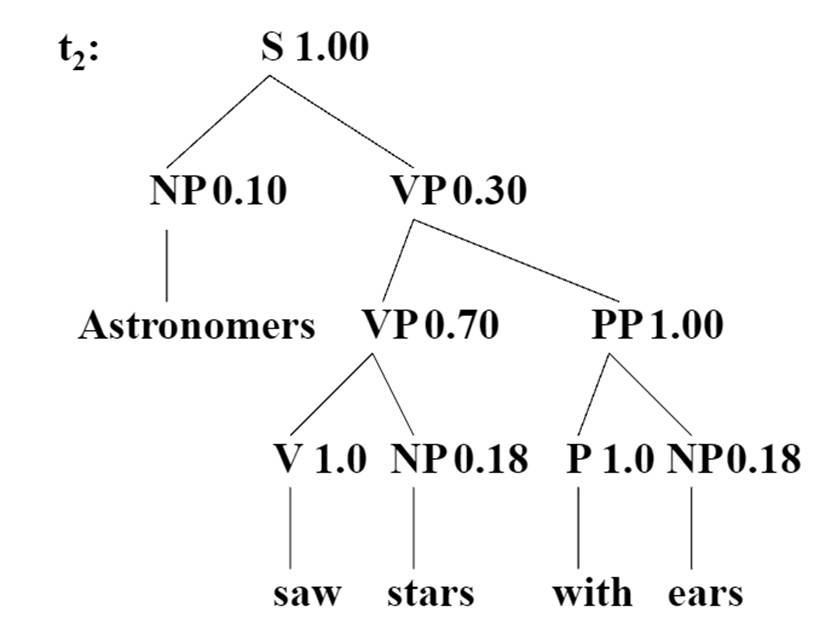
接下来我们算一下上面的那个例子


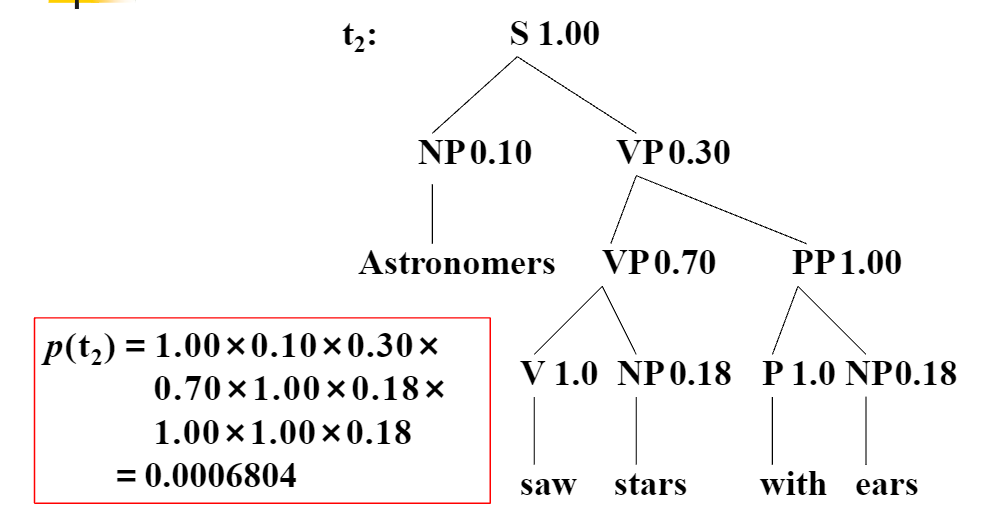

六 PCFG的三个问题

 “文法 G (S) 的规则形式”
“文法 G (S) 的规则形式”
-
第一种规则
A → w(w ∈ V_T):
可以理解成,有个语法成分(用A代表,比如 “名词短语”“动词” 这些语法类别 ),它能直接变成一个实际的单词(w就是单词,像 “苹果”“跑” ,V_T就是所有实际单词组成的集合 )。
举个例子:假设A是 “名词”,那规则名词 → 苹果,就是说 “名词” 这个语法成分,能直接生成 “苹果” 这个单词 。 -
第二种规则
A → BC(B,C ∈ V_N):
意思是,一个语法成分A,能拆成另外两个语法成分B和C(V_N是语法成分的集合,像 “名词短语”“动词短语” 这些 )。
比如句子 → 名词短语 动词短语,就是把 “句子” 这个大的语法成分,拆成 “名词短语” 和 “动词短语” 这俩小的语法成分 ,后续还能接着拆这俩,直到拆成实际单词 。
“乔姆斯基范式(CNF)”
就是说,不管原来的上下文无关文法(CFG)规则多复杂,都能通过 “范式化处理”,把规则改成上面那两种简单形式 。这样做的好处是,后续分析句子结构(比如算分析树概率、判断句子是否符合文法 )时,规则更规整、更好处理 。
打个比方,就像把一堆形状各异的积木,规整成两种标准块,用这两种块就能搭出原来那些复杂结构,而且搭的时候更清晰、不容易乱 。
乔姆斯基范式就是给文法规则定了个简单 “模板”,规则要么是一个语法成分直接变单词,要么是一个语法成分拆成俩语法成分,这样处理后分析句子结构更方便~ 就像把复杂事儿归成简单套路,好操作 。
1、内向算法或外向算法解决第一个问题——快速地计算句子的句法树概率



2、Viterbi 算法解决第二个问题最佳分析结果搜索
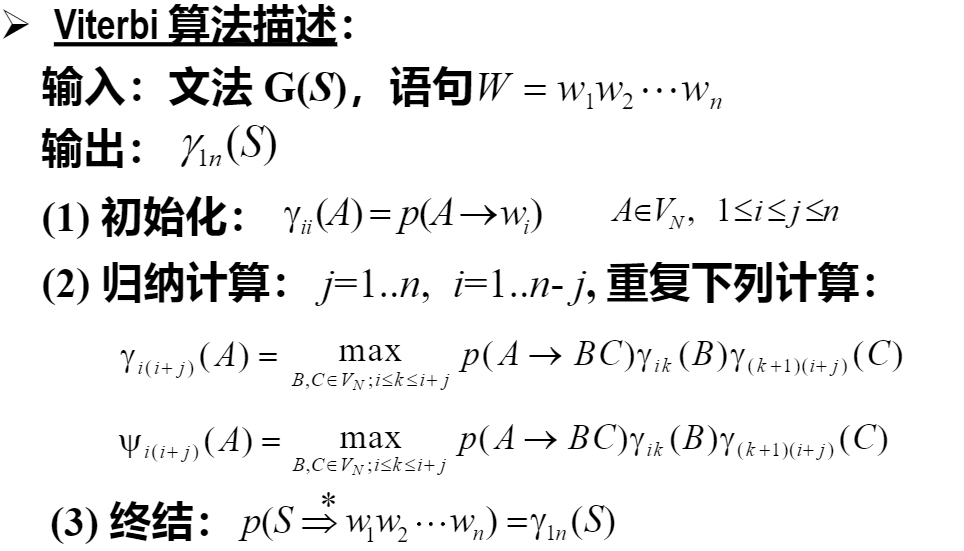
3、内外向算法解决第三个问题-参数估计


章节练习
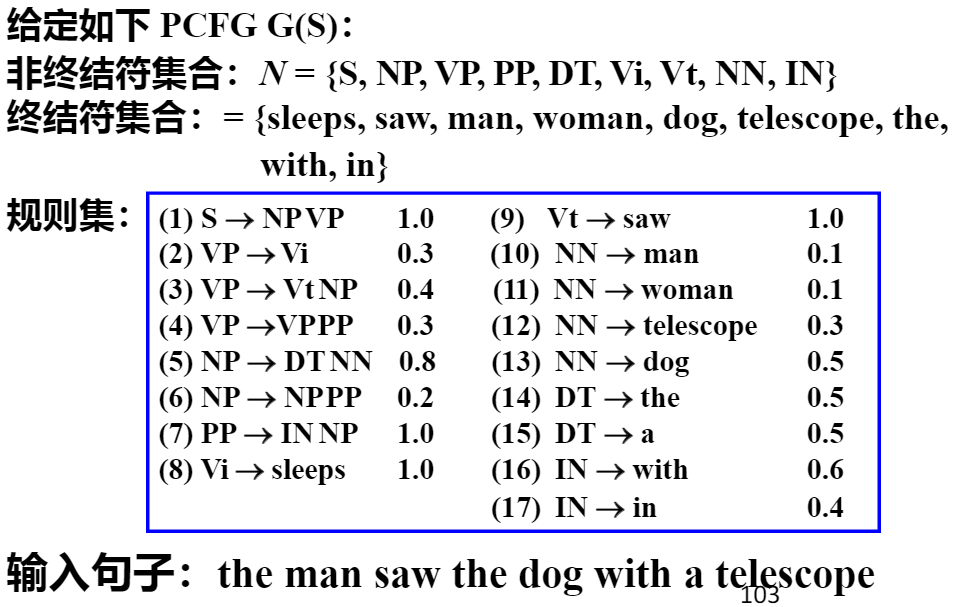
- 非终结符(N):像
S(句子)、NP(名词短语)、VP(动词短语)… 这些是 “语法成分”,类似 “句子的零件分类” 。 - 终结符(T):像
sleeps、saw、man… 这些是 “实际单词”,是句子里的具体词汇 。 - 规则集:每条规则是 “零件怎么组合”,还带概率。比如:
NP → DT NN(概率 0.8 ):名词短语(NP)80% 是 “限定词(DT,比如 the、a ) + 名词(NN,比如 man、dog )” 组成,像 “the man”“a dog” 。Vt → saw(概率 1.0 ):及物动词(Vt)只能是 “saw”(因为概率 100% ),所以看到saw就知道是 Vt 。
