FDD损失函数 损失函数和梯度的关系
| 度量 | 公式 | 关注点 |
|---|---|---|
| 余弦相似度 | 方向差异 | |
| 欧式距离 | 绝对距离 |
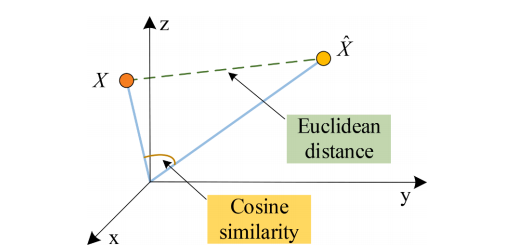
角度的余弦=向量点积/向量模长乘积
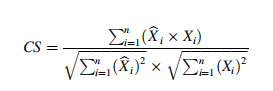
论文中的公式如上图所示,其中:
分子部分:计算两个向量的点积,表示两个向量在相同方向上的投影乘积和
分母部分::第一个向量的欧几里得范数 (模长)和第二个向量的欧几里得范数,相当于向量长度的乘积
因此,CS属于 [- 1, 1] ,值越小表示方向差异越大,CS 可以很好地考虑了数据间的距离和角度差异。
创新后的损失函数公式为:
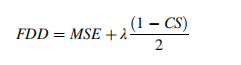
λ 是一个可调整的超参数,用于平衡数据间的距离和角度差的权重。
然后损失值被输入Adam优化器来自动优化网络的学习参数。
拓展学习:
损失值(Loss Value) = 最终目的地的“不满意程度”
梯度(Gradient) = 指路牌告诉你“往哪个方向、走多快”能降低不满意程度
梯度是什么?
定义:
梯度是一个向量(一个有序的数字集合)。简单来说(在机器学习/深度学习语境下),它是损失函数 L 相对于模型每一个可学习参数(如权重 w、偏置 b)的偏导数组成的向量 (∂L/∂wᵢ, ∂L/∂bᵢ)。
计算来源:
前提: 必须在计算出一个损失值 (loss_value) 之后才能计算梯度。
过程: 在损失值计算的基础上进行反向传播算法。这个算法从输出(损失值)反向应用链式法则,高效地计算出损失相对于所有模型参数的偏导数。
输出: gradients (一个向量或张量集合,与模型参数的形状一一对应)。
# 伪代码示例 (续上)
loss_value.backward() # 关键! 执行反向传播计算梯度
# 假设 w 是一个参数张量
w_gradient = w.grad # 获取损失L对w的梯度 (gradients of L w.r.t w)
所以损失函数与梯度的关系:
损失值是评估标准: 你需要知道当前表现有多差(损失值),才知道是否需要改进(更新参数)。
梯度的计算依赖于损失值: 必须首先执行前向传播计算出一个损失值 (loss_value),才能执行反向传播 (backward()) 来计算梯度 (gradients) 的。 没有损失值,就没有计算的起点。
梯度是更新指南: 光知道损失值还不够,梯度告诉你怎么有效地修改模型参数 (w, b) 来降低这个损失值。优化器(如亚当Adam)使用梯度 (gradients) 来决定具体的参数更新公式和步长(学习率),最终目标是减少下一个时刻的损失值 (loss_value)
损失值 (loss_value) --> 反向传播 --> 梯度 (gradients) --> 优化器 (如 Adam) --> 更新参数 --> 期望在新的损失值 (loss_value)
# 标准训练循环核心步骤:
optimizer.zero_grad() # 清除旧梯度
y_pred = model(X) # 1. 前向传播 -> 得到预测值
loss = criterion(y_pred, y) # 2. 计算损失值 (Loss Value 产生!)
loss.backward() # 3. 反向传播 -> 计算梯度 (利用loss_value生成gradients)
optimizer.step() # 4. 优化器用梯度更新参数 (Adam等在这里工作)
[输入数据 + 模型参数]⬇[模型前向传播 (Forward Pass)]⬇[预测值 (y_pred)]+真实标签 (y_true)⬇[损失函数 (Loss Function)]⬇**损失值 (Loss Value) (标量)** ⬅ 这是最终评价结果⬇(从这个值开始反向回溯)[反向传播 (Backward Pass) / 链式法则]⬇**梯度 (Gradients) (向量/张量)** ⬅ 这是更新参数的依据 (形状同参数)⬇[优化器 (如Adam)] ⬅ 使用梯度计算参数更新量⬇[更新模型参数 (w, b)]