python爬虫之数据存储
1.文本存储
文件打开模式
python中所有open()打开一个文件,文件的打开有很多模式:
-
r:以只读方式打开文件,文件的指针将会放在文件的开头,这是默认模式。
-
rb:以二进制只读方式打开一个文件,文件指针将会放在文件的开头。
-
r+:以读写方式打开一个文件,文件指针将会放在文件的开头。
-
rb+: 以二进制读写方式打开一个文件,文件指针将会放在文件的开头。
-
w:以写入方式打开一个文件。如果该文件已存在,则将其瞿盖;如果该文件不存在,则创建新文件。
-
wb:以二进制写入方式打开一个文件。如果该文件已存在,则将其覆盖;如果该文件不存在,则创建新文件。
-
w+:以读写方式打开一个文件。如果该文件已存在,则将其覆盖;如果该文件不存在,则创建新文件。
-
wb+:以二进制读写格式打开一个文件。如果该文件已存在,则将其覆盖;如果该文件不存在, 则创建新文件。
-
a:以追加方式打开一个文件。如果该文件已存在,文件指针将会放在文件结尾。也就是说,新的内容将会被写入到已有内容之后;如果该文件不存在, 则创建新文件来写入。
-
ab:以二进制追加方式打开一个文件。如果该文件已存在,则文件指针将会放在文件结尾。也就是说,新的内容将会被写入到己有内容之后;如果该文件不存在,则创建新文件来写入。
-
a+:以读写方式打开一个文件。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式;如果眩文件不存在,则创建新文件来读写。
-
ab+:以二进制追加方式打开一个文件。如果该文件已存在,则文件指针将会放在文件结尾;如果该文件不存在,则创建新文件用于读写。TXT 文本的操作非常简单,且其几乎兼容任何平台,但是它有个缺点,那就是不利于检索。
TXT 文本存储
以这个网站为例
第一章我要成为“龙骑士” _《诸天:从神雕开始长生不死!》小说在线阅读 - 起点中文网

一个简单的反调式例子,注入代码即可解决
 经调试数据在网页上
经调试数据在网页上
有cookie效验,cookie会过期
import requests
from scrapy import Selectorheaders = {"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7","accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6","referer": "https://www.qidian.com/book/1044888053/","user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0"
}
cookies = {"_csrfToken": "p2zf6E8KXIBiku6iReLy5rOCBpdpNYOcVw2Dv9I9","e1": "%7B%22l6%22%3A%22%22%2C%22l7%22%3A%22%22%2C%22l1%22%3A3%2C%22l3%22%3A%22%22%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22qd_A73%22%7D","e2": "%7B%22l6%22%3A%22%22%2C%22l7%22%3A%22%22%2C%22l1%22%3A8%2C%22l3%22%3A%22%22%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22qd_A103%22%7D","w_tsfp": "ltvuV0MF2utBvS0Q7aPtkU6mHjolfTA4h0wpEaR0f5thQLErU5mB2IJ/u8P/MnLX6sxnvd7DsZoyJTLYCJI3dwNGRZ6Wcd8Z2AXBxokj1NodAxFgF5/YXgEfJ7JxvjkTL3hCNxS00jA8eIUd379yilkMsyN1zap3TO14fstJ019E6KDQmI5uDW3HlFWQRzaLbjcMcuqPr6g18L5a5W7Ztg+teFNzUbJD2BCT1isfXS4n4RK8IOBUPUqscMarSqA="
}
url = "https://www.qidian.com/chapter/1044888053/842546862/"
response = requests.get(url, headers=headers, cookies=cookies)
print(response.text)把cookie和请求头一起拿过来请求,请求成功
接下来提取数据
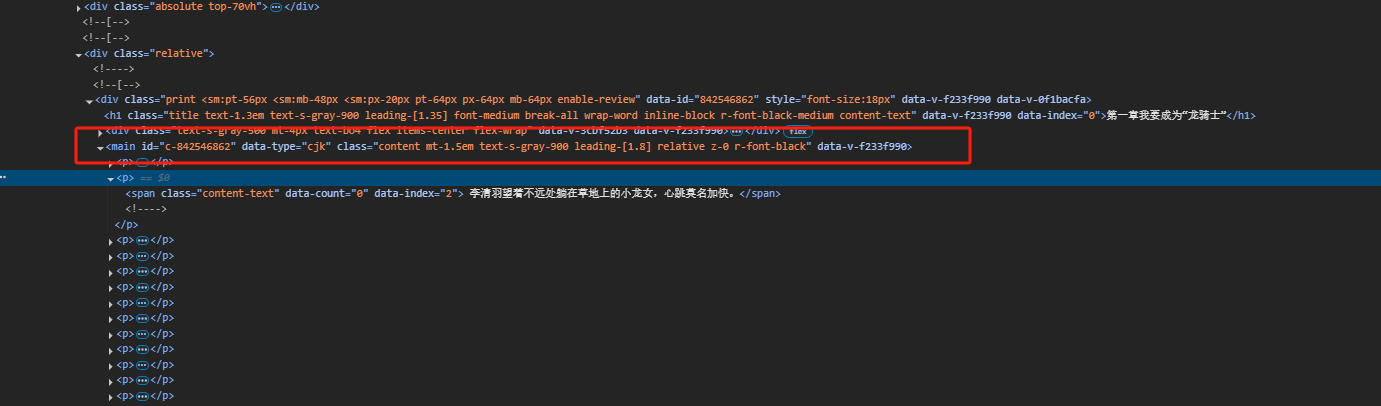
我用scrapy的Css选择去提取,如果你想用xpath或者beautifulsoup也行
selector = Selector(text=response.text)
text_list = selector.css('[data-type = "cjk"]>p::text')
for txt in text_list:print(txt.get())得出结果

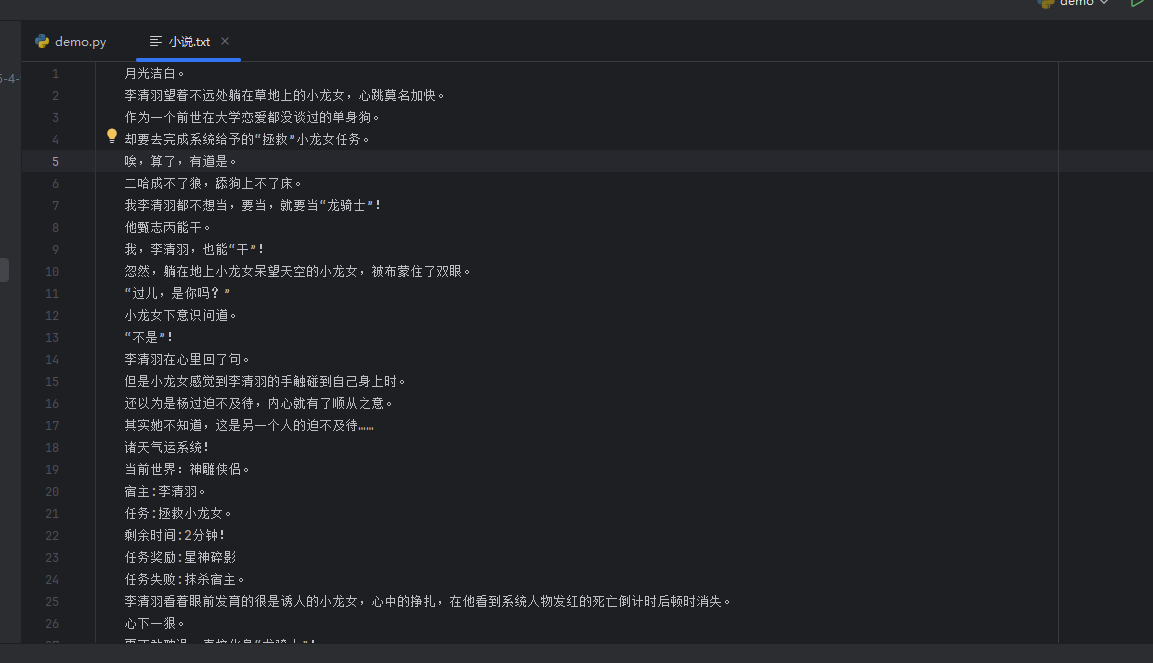
接下来读入文本,模式采用a模式。以追加方式打开一个文件。如果该文件已存在,文件指针将会放在文件结尾。也就是说,新的内容将会被写入到已有内容之后;如果该文件不存在, 则创建新文件来写入。
发现好像没分行,所以读入前加一个换行符·

中文编码为utf-8
response = requests.get(url, headers=headers, cookies=cookies)
selector = Selector(text=response.text)
text_list = selector.css('[data-type = "cjk"]>p::text')
for txt in text_list:with open('小说.txt', 'a', encoding='utf-8') as f:f.write(txt.get()+'\n')结果如下:
2.json文件存储
JSON,全称为 JavaScript Object Notation, 也就是 JavaScript 对象标记,它通过对象和数组的组合来表示数据,构造简洁但是结构化程度非常高,是一种轻量级的数据交换格式。本节中,我们就来了解如何利用 Python 保存数据到 JSON 文件。
json模块方法
| 方法 | 作用 |
|---|---|
| json.dumps() | 把python对象转换成json对象的一个过程,生成的是字符串。 |
| json.dump() | 用于将dict类型的数据转成str,并写入到json文件中 |
| json.loads() | 将json字符串解码成python对象 |
| json.load() | 用于从json文件中读取数据。 |
以这个网站为例影片总票房排行榜

影片总票房排行榜,这网站很好爬的
import requests
from scrapy import Selector
import json
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0"
}
cookies = {
}
url = "https://piaofang.maoyan.com/rankings/year"
response = requests.get(url, headers=headers, cookies=cookies)
# print(response.text)
selector = Selector(text=response.text)
json_list = selector.css('#ranks-list>ul')
json_arr =[]
for json_str in json_list:json_obj = {}json_obj['movie_name'] = json_str.css('.first-line::text').get()json_obj['create_time'] = json_str.css('.second-line::text').get()json_obj['box_office'] = json_str.css('.col2.tr::text').get()print(json_obj)运行成功
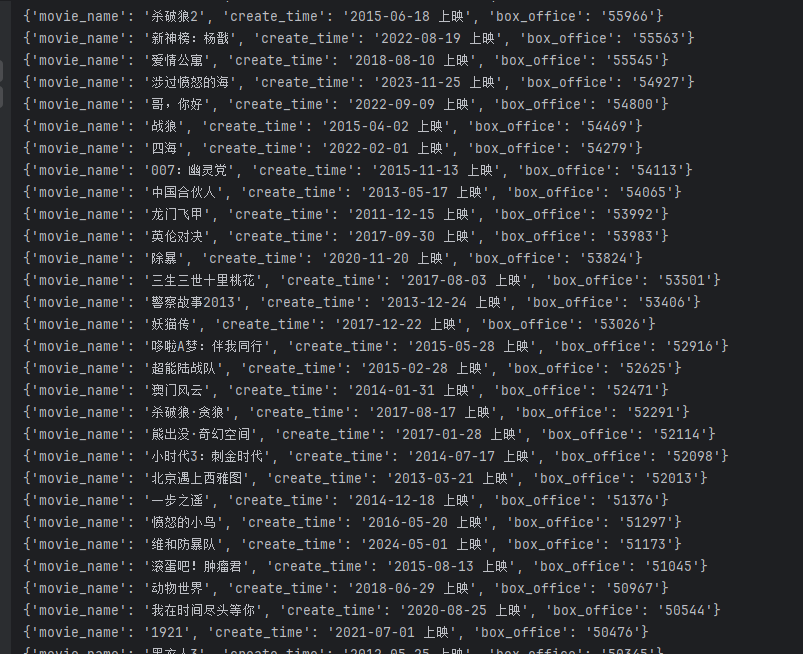
正常读入的话,中文字符都变成了 Unicode 字符,而且没换行非常不美观

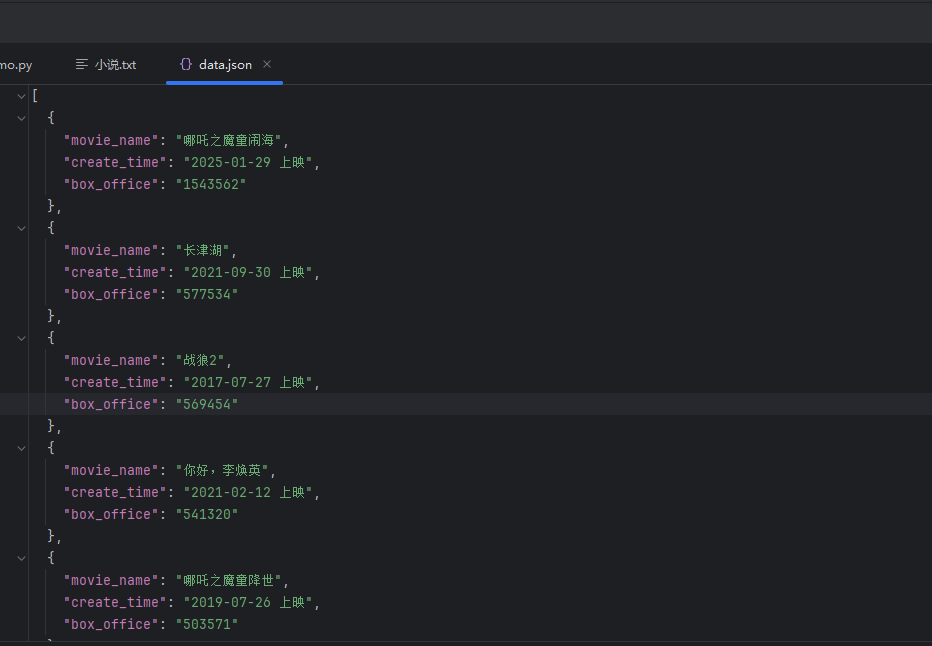
为了让他美观可以指定参数 ensure_ascii 为 False,indent设为2
json_arr =[]
for json_str in json_list:json_obj = {}json_obj['movie_name'] = json_str.css('.first-line::text').get()json_obj['create_time'] = json_str.css('.second-line::text').get()json_obj['box_office'] = json_str.css('.col2.tr::text').get()print(json_obj)json_arr.append(json_obj)
with open('data.json', 'a', encoding='utf-8') as file:file.write(json.dumps(json_arr,indent=2, ensure_ascii=False),)结果如下:
3.表格文件数据存储
CSV,全称为 Comma-Separated Values,中文可以叫作逗号分隔值或字符分隔值,其文件以纯文本形式存储表格数据。该文件是一个字符序列,可以由任意数目的记录组成,记录间以某种换行符分隔。每条记录由字段组成,字段间的分隔符是其他字符或字符串,最常见的是逗号或制表符。不过所有记录都有完全相同的字段序列,相当于一个结构化表的纯文本形式。它比 Excel 文件更加简洁,XLS 文本是电子表格,它包含了文本、数值、公式和格式等内容,而 CSV 中不包含这些内容,就是特定字符分隔的纯文本,结构简单清晰。所以,有时候用 CSV 来保存数据是比较方便的。本节中,我们来讲解Python 读取和写入 CSV 文件的过程。
这里先看一个最简单的例子:
import csv
with open('data.csv', 'w') as csvfile: writer = csv.writer(csvfile) writer.writerow(['id', 'name', 'age']) writer.writerow(['10001', 'Mike', 20]) writer.writerow(['10002', 'Bob', 22]) writer.writerow(['10003', 'Jordan', 21])writer = csv.writer(csvfile)为定义csv写入对象
首先,打开 data.csv 文件,然后指定打开的模式为 w(即写入),获得文件句柄,随后调用 csv 库的writer 方法初始化写入对象,传入该句柄,然后调用 writerow 方法传入每行的数据即可完成写入。效果如下:
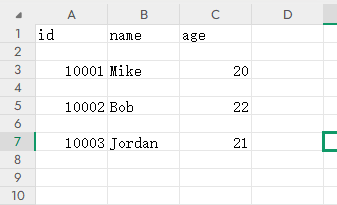
如果想修改列与列之间的分隔符,可以传入 delimiter 参数,其代码如下:
import csv
with open('data.csv', 'w') as csvfile: writer = csv.writer(csvfile, delimiter=' ') writer.writerow(['id', 'name', 'age']) writer.writerow(['10001', 'Mike', 20]) writer.writerow(['10002', 'Bob', 22]) writer.writerow(['10003', 'Jordan', 21])效果如下:
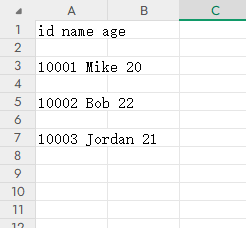
多行写入
import csv
with open('data.csv', 'w') as csvfile: writer = csv.writer(csvfile) writer.writerow(['id', 'name', 'age']) writer.writerows([['10001', 'Mike', 20], ['10002', 'Bob', 22], ['10003', 'Jordan', 21]])字典写入
import csv
with open('data.csv', 'w') as csvfile: fieldnames = ['id', 'name', 'age'] writer = csv.DictWriter(csvfile, fieldnames=fieldnames) writer.writeheader() writer.writerow({'id': '10001', 'name': 'Mike', 'age': 20}) writer.writerow({'id': '10002', 'name': 'Bob', 'age': 22}) writer.writerow({'id': '10003', 'name': 'Jordan', 'age': 21}) fieldnames = ['id', 'name', 'age'] 写入表格
writer = csv.DictWriter(csvfile, fieldnames=fieldnames) ,定义写入对象,为字典写入
用以上网站为例子
import requests
from scrapy import Selector
import csv
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0"
}
cookies = {
}
url = "https://piaofang.maoyan.com/rankings/year"
response = requests.get(url, headers=headers, cookies=cookies)
# print(response.text)
selector = Selector(text=response.text)
json_list = selector.css('#ranks-list>ul')
json_arr =[]for json_str in json_list:json_obj = {}json_obj['movie_name'] = json_str.css('.first-line::text').get()json_obj['create_time'] = json_str.css('.second-line::text').get()json_obj['box_office'] = json_str.css('.col2.tr::text').get()json_arr.append(json_obj)
with open('data.csv', 'a', encoding='utf-8') as csvfile:fieldnames = ['movie_name', 'create_time', 'box_office']writer = csv.DictWriter(csvfile, fieldnames=fieldnames)writer.writeheader()writer.writerows(json_arr)效果如下:
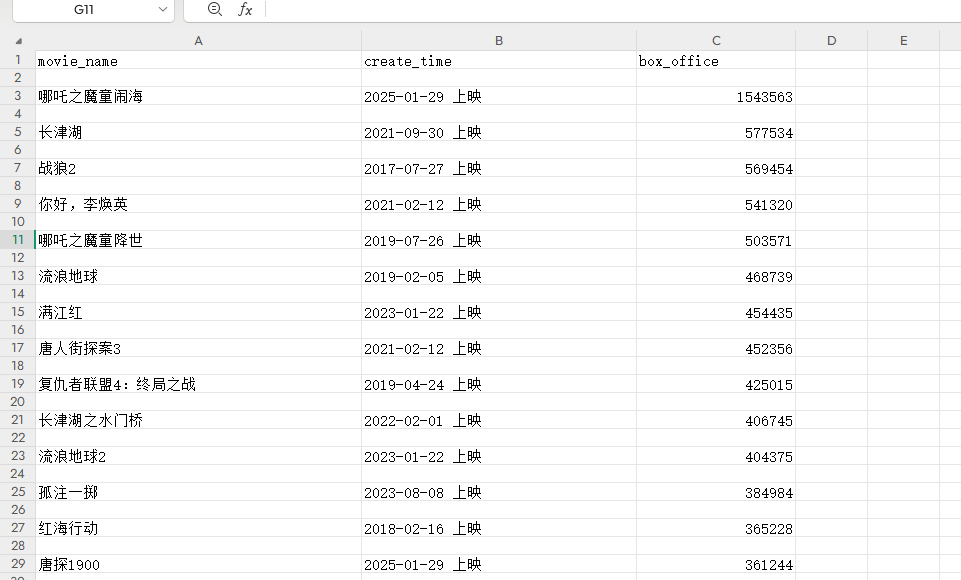
注意,字典的键和表的头要一致,如果你自定义标头,可以这样做
# 自定义表头
custom_headers = ['影片名称', '上映时间', '票房收入(万元)']with open('data.csv', 'a', encoding='utf-8', newline='') as csvfile:writer = csv.DictWriter(csvfile, fieldnames=custom_headers)writer.writeheader()for item in json_arr:writer.writerow({'影片名称': item['movie_name'],'上映时间': item['create_time'],'票房收入(万元)': item['box_office']}) 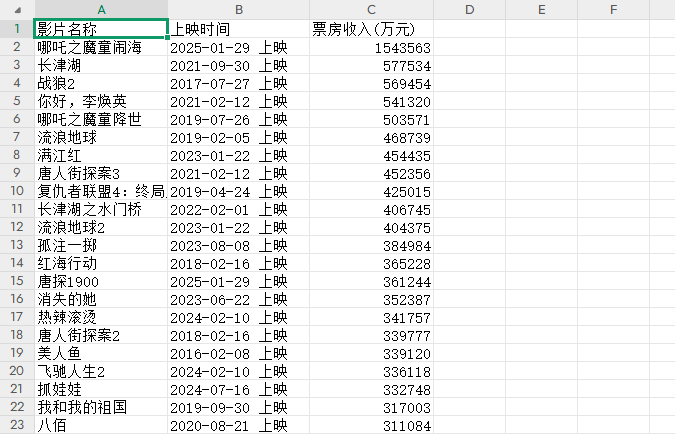
4. MySQL存储
首要工作,创建数据库,建表,id为主键,自增长
def create_table():db = pymysql.connect(host="localhost", user="root", password="12345", db="spider2")# 使用 cursor() 方法创建一个游标对象cursorcursor = db.cursor()# 使用预处理语句创建表sql = '''CREATE TABLE IF NOT EXISTS movie_list (idINT NOT NULL AUTO_INCREMENT, movie_name VARCHAR(255) NOT NULL, create_time VARCHAR(255) NOT NULL, box_office VARCHAR(255) NOT NULL, PRIMARY KEY (id))'''try:cursor.execute(sql)print("CREATE TABLE SUCCESS.")except Exception as ex:print(f"CREATE TABLE FAILED,CASE:{ex}")finally:# 关闭数据库连接db.close()
create_table()创建成功
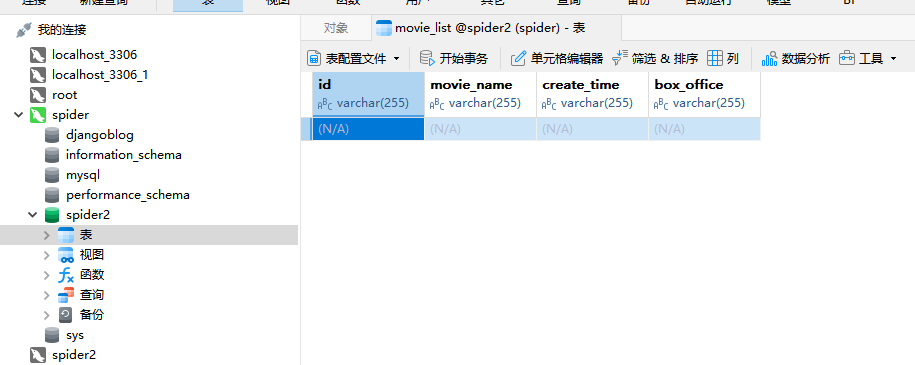
第二步准备插入数据
def save_data(movie_name, create_time, box_office):db = pymysql.connect(host="localhost", user="root", password="12345", db="spider2")# 使用 cursor() 方法创建一个游标对象cursorcursor = db.cursor()# SQL 插入语句sql = 'INSERT INTO movie_list(id, movie_name, create_time, box_office) values(%s, %s, %s, %s)'# 执行 SQL 语句try:cursor.execute(sql, (0, movie_name, create_time, box_office))# 提交到数据库执行db.commit()print('数据插入成功...')except Exception as e:print(f'数据插入失败: {e}')# 如果发生错误就回滚db.rollback()结果如下:
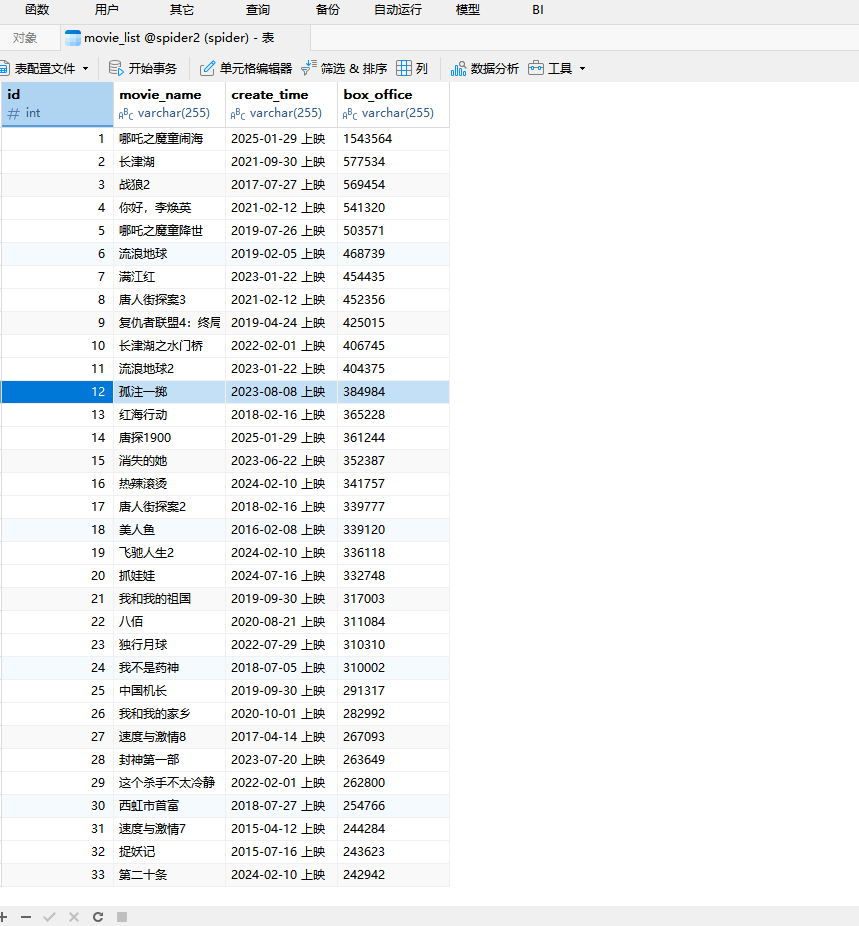
不过在插入数据我发现了一个问题 ,插入数据太慢了,最后发现,再插入数据的时候,还要链接一次,可以单独把连接数据库功能拿出来,这样优化。
def save_data(cursor,db,movie_name, create_time, box_office):# SQL 插入语句sql = 'INSERT INTO movie_list(id, movie_name, create_time, box_office) values(%s, %s, %s, %s)'# 执行 SQL 语句try:cursor.execute(sql, (0, movie_name, create_time, box_office))# 提交到数据库执行db.commit()print('数据插入成功...')except Exception as e:print(f'数据插入失败: {e}')# 如果发生错误就回滚db.rollback()db = pymysql.connect(host="localhost", user="root", password="12345", db="spider2")
# 使用 cursor() 方法创建一个游标对象cursor
cursor = db.cursor()
for json_str in json_list:json_obj = {}json_obj['movie_name'] = json_str.css('.first-line::text').get()json_obj['create_time'] = json_str.css('.second-line::text').get()json_obj['box_office'] = json_str.css('.col2.tr::text').get()save_data(cursor,db,json_obj['movie_name'],json_obj['create_time'],json_obj['box_office'])在面向对象里会比较方便,直接设置公有属性就好了
self.db = pymysql.connect(host="localhost", user="root", password="12345", db="spider2")
# 使用 cursor() 方法创建一个游标对象cursor
self.cursor = db.cursor()完整案例:
import requests
from scrapy import Selector
import pymysql
#准备工作def create_table():db = pymysql.connect(host="localhost", user="root", password="12345", db="spider2")# 使用 cursor() 方法创建一个游标对象cursorcursor = db.cursor()# 使用预处理语句创建表sql = '''CREATE TABLE IF NOT EXISTS movie_list (id INT AUTO_INCREMENT NOT NULL, movie_name VARCHAR(255) NOT NULL, create_time VARCHAR(255) NOT NULL, box_office VARCHAR(255) NOT NULL, PRIMARY KEY (id))'''try:cursor.execute(sql)print("CREATE TABLE SUCCESS.")except Exception as ex:print(f"CREATE TABLE FAILED,CASE:{ex}")finally:# 关闭数据库连接db.close()def save_data(cursor,db,movie_name, create_time, box_office):# SQL 插入语句sql = 'INSERT INTO movie_list(id, movie_name, create_time, box_office) values(%s, %s, %s, %s)'# 执行 SQL 语句try:cursor.execute(sql, (0, movie_name, create_time, box_office))# 提交到数据库执行db.commit()print('数据插入成功...')except Exception as e:print(f'数据插入失败: {e}')# 如果发生错误就回滚db.rollback()
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0"
}
cookies = {
}
url = "https://piaofang.maoyan.com/rankings/year"
response = requests.get(url, headers=headers, cookies=cookies)
# print(response.text)
selector = Selector(text=response.text)
json_list = selector.css('#ranks-list>ul')
json_arr =[]
db = pymysql.connect(host="localhost", user="root", password="12345", db="spider2")
# 使用 cursor() 方法创建一个游标对象cursor
cursor = db.cursor()
for json_str in json_list:json_obj = {}json_obj['movie_name'] = json_str.css('.first-line::text').get()json_obj['create_time'] = json_str.css('.second-line::text').get()json_obj['box_office'] = json_str.css('.col2.tr::text').get()save_data(cursor,db,json_obj['movie_name'],json_obj['create_time'],json_obj['box_office'])
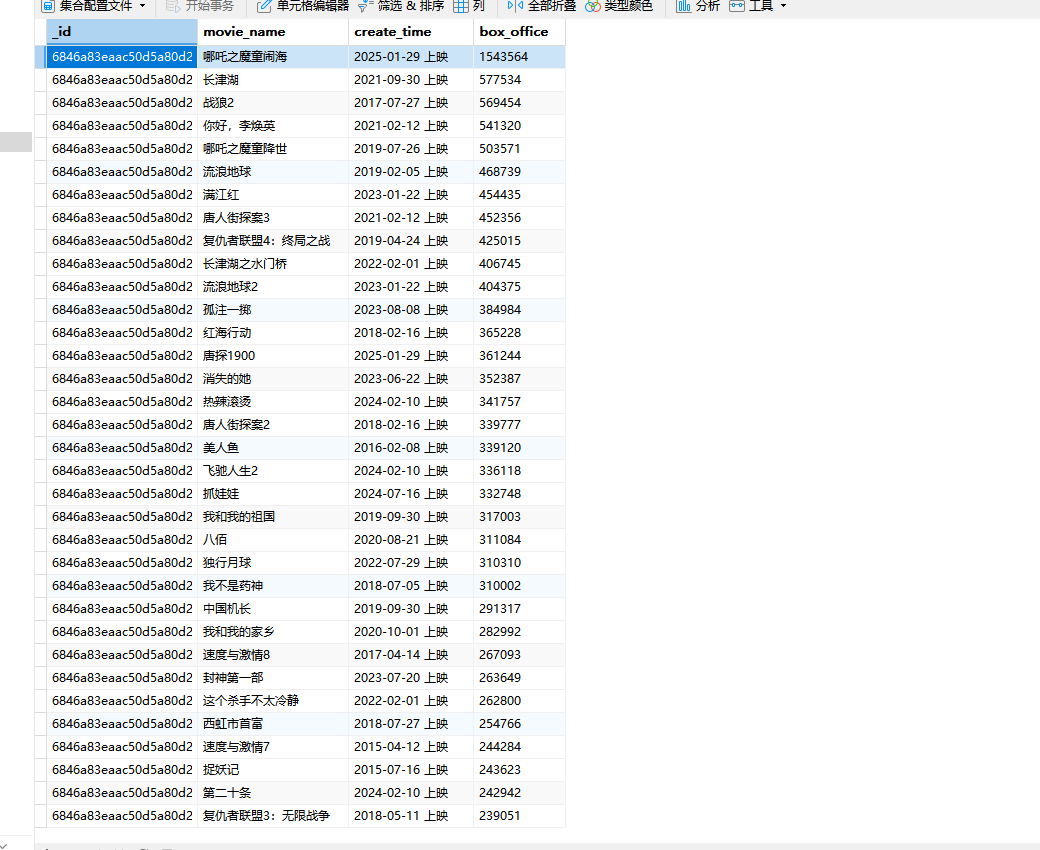
5.Mongodb存储
准备工作,连接数据库,指定数据库和表
import pymongo # 如果是云服务的数据库 用公网IP连接
client = pymongo.MongoClient(host='localhost', port=27017)
collection = client['spider']['movie_list']在Mongodb里不需要建库和建表,直接存储,可以一次性全部插入,也可以一条一条插入
import pymongo # 如果是云服务的数据库 用公网IP连接
client = pymongo.MongoClient(host='127.0.0.1', port=27017)
collection = client['spider']['movie_list']# 插入单条数据
student = {'id': '20170101', 'name': 'Jordan', 'age': 20, 'gender': 'male' }
result = collection.insert_one(student)
print(result)# 插入多条数据
student1 = { 'id': '20170101', 'name': 'Jordan', 'age': 20, 'gender': 'male' }
student2 = { 'id': '20170202', 'name': 'Mike', 'age': 21, 'gender': 'male' }
collection.insert_many([student1, student2])效果如下:
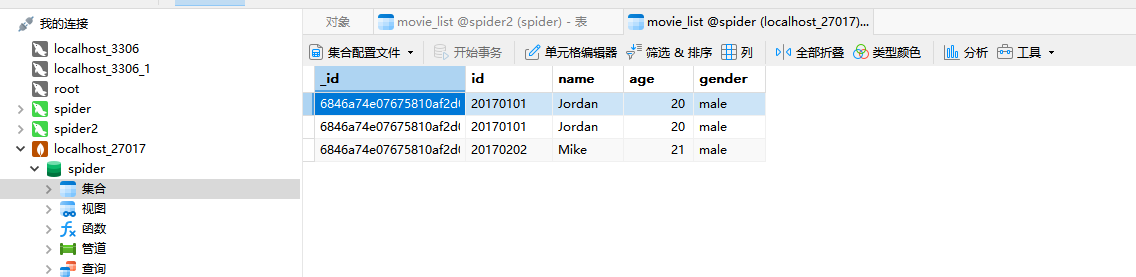
案例如下:
import requests
from scrapy import Selector
import pymysql
import pymongo
#准备工作
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0"
}
cookies = {
}
url = "https://piaofang.maoyan.com/rankings/year"
response = requests.get(url, headers=headers, cookies=cookies)
# print(response.text)
selector = Selector(text=response.text)
json_list = selector.css('#ranks-list>ul')
json_arr =[]
import pymongo # 如果是云服务的数据库 用公网IP连接
client = pymongo.MongoClient(host='127.0.0.1', port=27017)
collection = client['spider']['movie_list']
for json_str in json_list:json_obj = {}json_obj['movie_name'] = json_str.css('.first-line::text').get()json_obj['create_time'] = json_str.css('.second-line::text').get()json_obj['box_office'] = json_str.css('.col2.tr::text').get()json_arr.append(json_obj)collection.insert_many(json_arr)
结果如下: