CAR:推理长度自适应新框架,提升精度同时还降低推理token数!!
摘要:近期在推理领域的进展显著提升了大型语言模型(LLMs)和多模态大型语言模型(MLLMs)在多样化任务中的能力。然而,过度依赖链式思维(CoT)推理可能会削弱模型性能,并带来不必要的冗长输出,从而降低效率。我们的研究表明,过度的推理并不总能提高准确性,甚至在简单任务上可能会降低性能。为了解决这一问题,我们提出了基于确定性的自适应推理(CAR),这是一个新颖的框架,能够根据模型的困惑度动态地在简短回答和长篇推理之间切换。CAR首先生成一个简短的回答,并评估其困惑度,仅在模型表现出低置信度(即高困惑度)时才触发推理。在多样化的多模态视觉问答(VQA)/关键信息提取(KIE)基准测试和文本推理数据集上的实验表明,CAR在准确性和效率之间达到了最佳平衡,优于单纯的简短回答和长篇推理方法。
本文目录
一、背景动机
二、核心贡献
三、实现方法
3.1 模型训练
3.2 获取短答案的困惑度 (PPL)
3.3 高斯分布建模
3.4 推理流程
四、实验结论
4.1 长篇推理的局限性
4.2 CAR框架有效性
4.3 PPL指标可靠性
五、总结
一、背景动机
论文题目:Prolonged Reasoning Is Not All You Need: Certainty-Based Adaptive Routing for Efficient LLM/MLLM Reasoning
论文地址:https://arxiv.org/pdf/2505.15154
大语言模型和多模态大模型在多种任务中表现出色,尤其是在复杂推理任务中。然而,过度依赖链式思考(CoT)推理可能会降低模型性能,并导致输出过长,从而降低效率。研究表明,长形式推理主要在数学和符号任务中提高 LLM 性能,而在其他类型的任务中收益甚微,甚至在某些简单任务中会损害模型性能。
基于此,文章针对LLM/MLLM 是否可以自适应地决定何时进行推理,仅在简单答案不足以满足需求时选择性地激活推理,以平衡计算效率和任务性能这个问题进行了研究,提出一种自适应推理框架。
二、核心贡献
1、提出了 CAR 框架,这是一个基于模型置信度动态切换短答案和长形式推理的新方法,实现了准确性和计算效率之间的最佳平衡。
2、通过广泛的初步研究,验证了困惑度(PPL)可以作为模型置信度的可靠指标,并通过高斯建模建立了其与答案正确性的关系。
3、在 LLM 和 MLLM 上进行的广泛实验表明,CAR 在保持推理准确性的同时,显著减少了推理标记的使用,优于短答案和长形式推理方法。
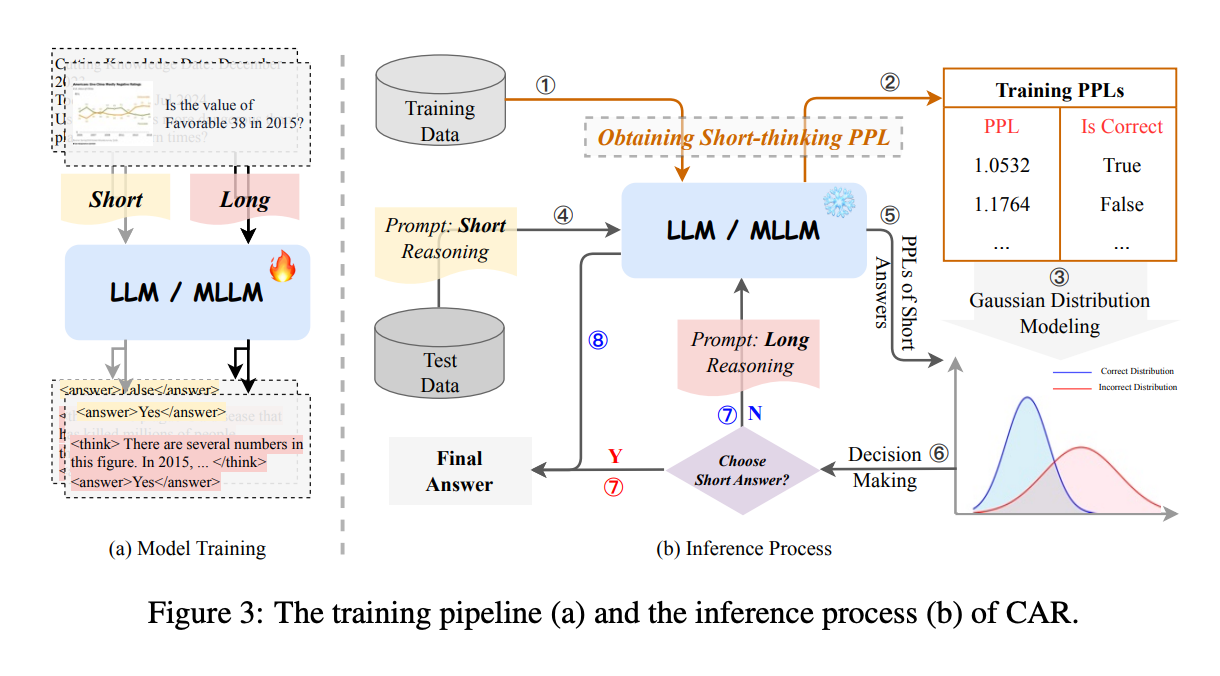
三、实现方法
3.1 模型训练
-
训练数据集包含两种类型的注释:短答案和长形式推理答案。短答案是直接输出的答案,而长形式推理答案则包含逐步的推理过程和最终答案。
-
使用标准的指令调整过程(instruction tuning)对模型进行训练。模型通过优化交叉熵损失函数来学习生成短答案和长形式推理答案。
3.2 获取短答案的困惑度 (PPL)
- 在训练完成后,模型对训练数据集中的每个示例进行短答案推理,并计算每个短答案的困惑度(PPL)。
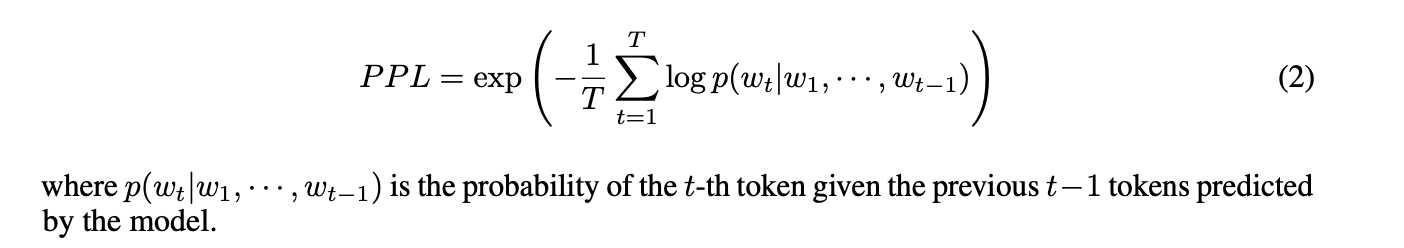
3.3 高斯分布建模
- 为了根据 PPL 值判断短答案的正确性,文章假设正确和错误短答案的 PPL 分布分别遵循高斯分布。
-
正确答案的 PPL 分布:假设为
-
错误答案的 PPL 分布:假设为
-
-
通过训练数据集中的短答案 PPL 值,估计这两个高斯分布的参数:

3.4 推理流程
- 短答案生成:模型首先为输入问题生成一个短答案,并计算其 PPL 值。
- 概率计算:根据高斯分布模型,计算短答案属于正确和错误分布的概率

- 决策:如果 P(C=1∣PPLnew)>P(C=0∣PPLnew),则认为短答案是准确的,直接输出该短答案;否则,模型将执行长形式推理以获得更准确的答案。
四、实验结论
4.1 长篇推理的局限性
-
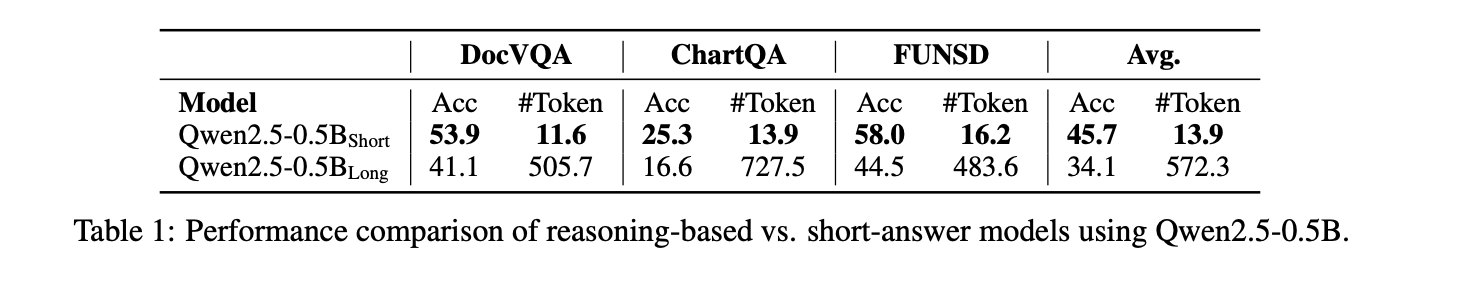
长篇推理(CoT)并非在所有任务中都能提高模型性能。在一些简单的任务中,长篇推理反而会降低准确率,并且显著增加输出长度,导致效率低下。
-
在文本丰富的视觉问答(VQA)和关键信息抽取(KIE)数据集上,短答案模型的准确率高于长篇推理模型(45.7% vs. 34.1%),且长篇推理模型的输出长度平均为572.3个token,而短答案模型仅为13.9个token。
4.2 CAR框架有效性
-
CAR框架通过评估模型对短答案的困惑度(PPL)来动态决定是否需要进行长篇推理。如果模型对短答案的置信度低(即PPL高),则触发长篇推理。
-
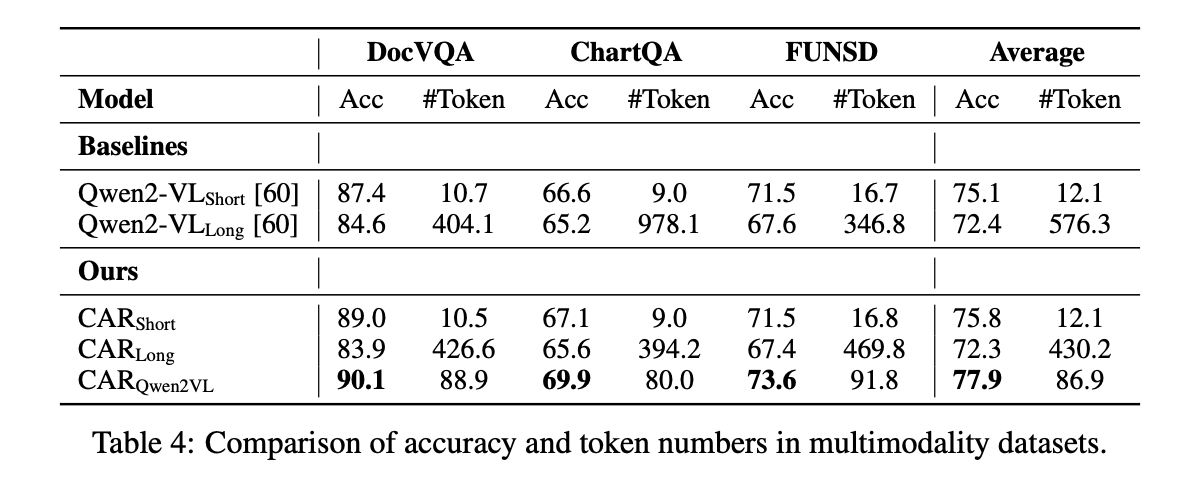
CAR在多种多模态VQA/KIE基准测试和文本推理数据集上的表现优于纯短答案和纯长篇推理方法,同时在保持高准确率的同时显著减少了推理所需的token数量。
-
在多模态数据集上,CARQwen2VL的平均准确率为77.9%,比短答案和长篇推理基线分别提高了2.8%和5.5%,且平均token使用量仅为86.9,仅为长篇推理的15%。
- 在文本推理数据集上,CARQwen2.5的平均准确率为81.1%,比短答案和长篇推理分别提高了25.3%和6.1%,同时token使用量减少了45.1%。
-
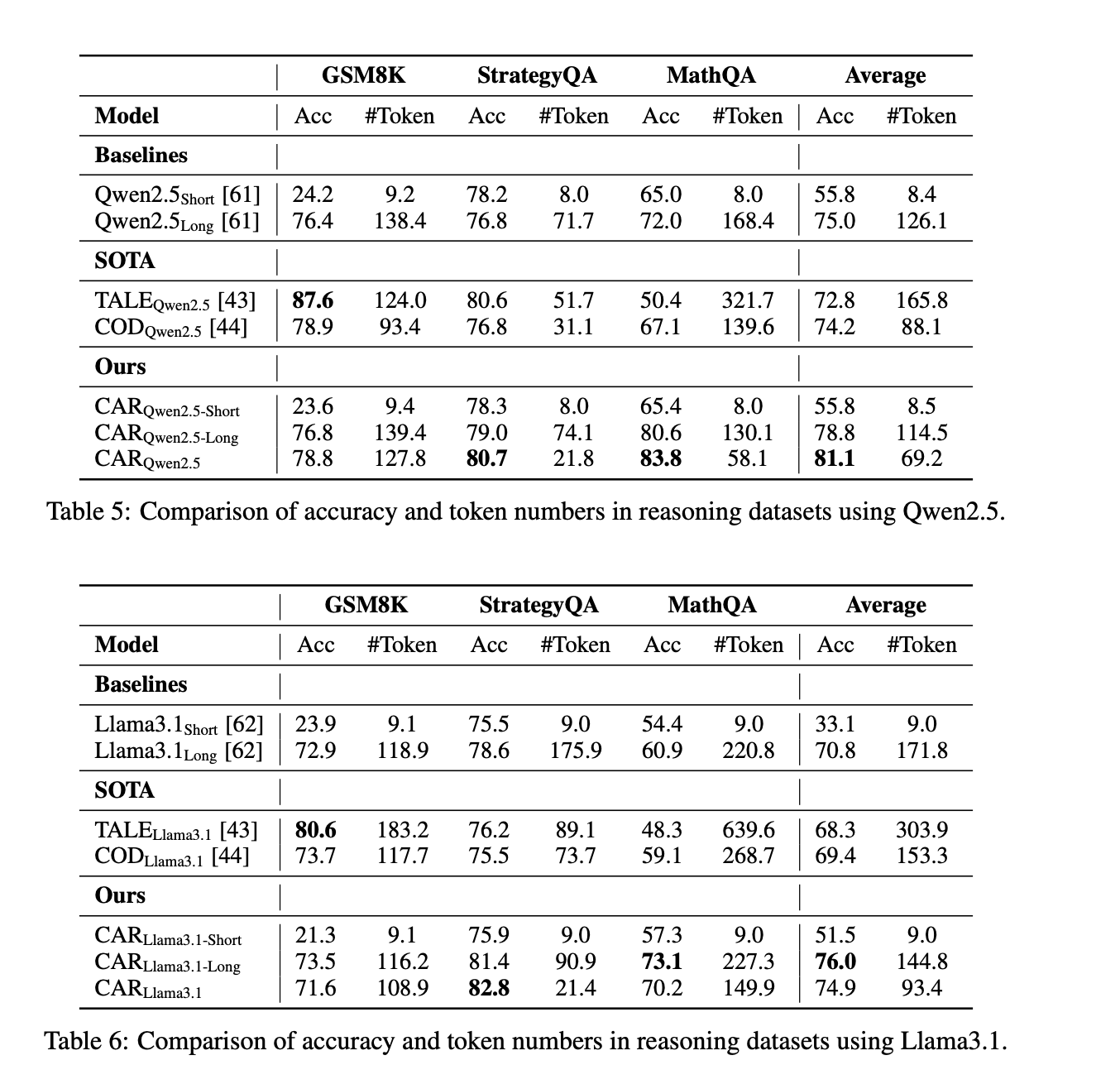
4.3 PPL指标可靠性
-
文章验证了PPL可以作为模型置信度的可靠指标,正确答案的PPL显著低于错误答案,表明低PPL与高置信度和高准确率相关。
-
在多个数据集上,正确答案的平均PPL为1.15,而错误答案的平均PPL为1.28。
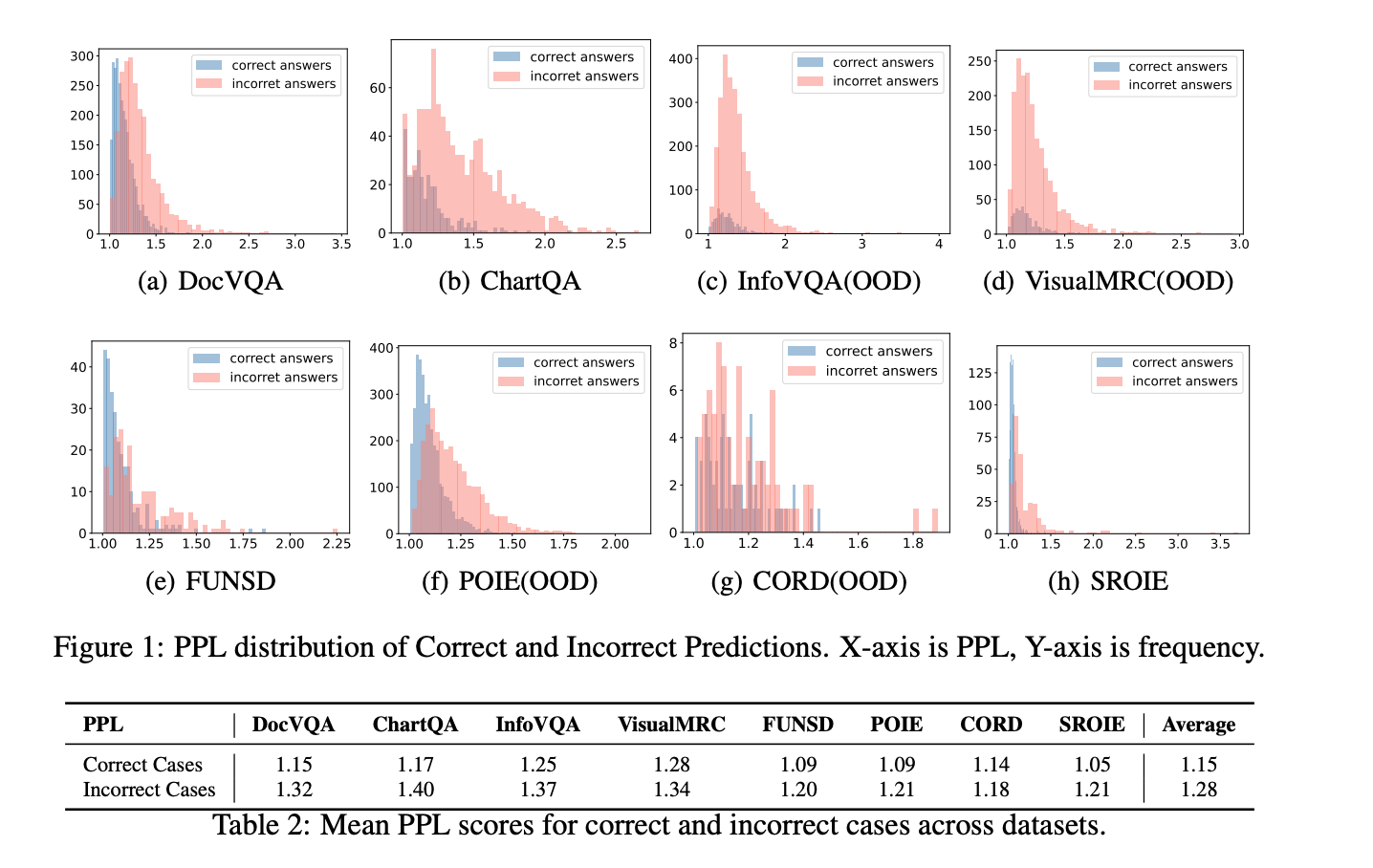
五、总结
文章提出了 CAR 框架,这是一个基于模型置信度动态切换短答案和长形式推理的新方法。CAR 通过使用 PPL 作为置信度指标,有效地平衡了准确性和计算效率。在多种多模态和文本数据集上的实验表明,CAR 在保持推理准确性的同时,显著减少了推理标记的使用,优于现有的短答案和长形式推理方法。