【MLLM】字节BAGEL多模态理解和生成统一模型
Note
- 字节跳动发布BAGEL-7B-MoT混合专家多模态模型,支持视觉理解,文本到图像生成,图像编辑,并且思考模式可以选择开启。官方说要比 Qwen2.5-VL 和 InternVL-2.5 表现好。
- 这个模型本身是基于 Qwen2.5-7B-Instruct 和 siglip-so400m-14-980-flash-attn2-navit 模型微调的,并使用 FLUX.1-schnell VAE 模型。
- 多模态模型效果:seed_vl>qwenvl>internvl>kimivl>minicpm
文章目录
- Note
- 一、字节BAGEL多模态模型
- 二、训练数据和模型训练
- 1. 训练数据
- 2. 模型训练
- 三、效果分析
- Reference
一、字节BAGEL多模态模型
- BAGEL 在标准多模态理解排行榜上超越了当前顶级的开源VLMs,如Qwen2.5-VL和InternVL-2.5,并且提供了与强大的专业生成器如SD3竞争的文本到图像质量。
- BAGEL 在经典的图像编辑场景中展示了比领先的开源模型更好的定性结果。更重要的是,它扩展到了自由形式的视觉操作、多视图合成和世界导航,这些能力构成了超出以往图像编辑模型范围的“世界建模”任务。
使用MoE架构,有两个transformer expert,每个专家都通过共享的自注意力操作处理相同的token序列:
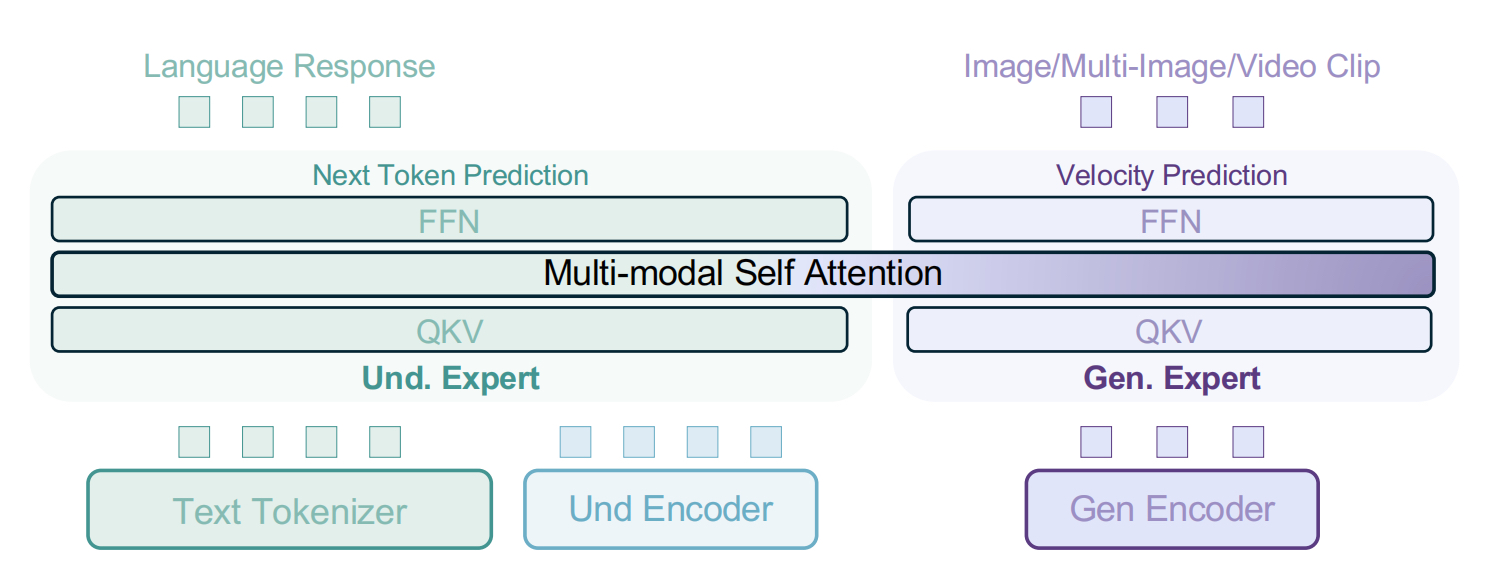
视觉编码器:
- 视觉理解:使用ViT编码器将图片像素转为token
- 视觉生成:使用Flux的预训练VAE模型将图片从像素空间转为latent空间
二、训练数据和模型训练
1. 训练数据
视频数据:从大规模网络视频中提取高质量训练片段,通过时间分割、空间裁剪和质量过滤来确保视频数据的质量。使用Koala36M和MVImgNet2.0等开源数据集来补充视频数据。
网页数据:从OmniCorpus等大规模网页文档中提取数据,采用两阶段过滤策略:首先使用LLM进行轻量级主题选择,然后进行细粒度过滤。过滤规则包括UI去除、分辨率限制、图像清晰度检查、文本密度检查和相关性检查等。
交错数据构建:从视频中生成时间对齐的文本描述,从网页文档中生成概念性的标题。此外,构建50万条推理增强的例子,涵盖文本到图像生成、自由形式图像编辑和抽象编辑四类任务。
2. 模型训练
- 对齐阶段(Alignment):在这个阶段,仅训练MLP连接器,保持视觉编码器和语言模型冻结。使用图像-文本对数据进行图像字幕生成,以初始化ViT编码器与Qwen2.5 LLM的对齐。
- 预训练阶段(Pre-training, PT):在这个阶段,除了VAE之外的所有模型参数都是可训练的。训练语料库包括2.5T令牌,涵盖文本、图像-文本对、多模态对话、网页交错和视频交错数据。采用原生分辨率策略,限制图像的最大长边和最小短边。
- 继续训练阶段(Continued Training, CT):在这个阶段,提高视觉输入分辨率,并增加交错数据的采样比例,以强调跨模态推理的学习。CT阶段消耗约2.6T令牌。
- 监督微调阶段(Supervised Fine-tuning, SFT):在这个阶段,构建高质量的图像-文本对子集和交错生成子集,分别用于多模态生成和多模态理解。SFT阶段的总训练令牌数为72.7亿。
三、效果分析
- 图像理解:在六个广泛使用的视觉理解基准上,BAGEL在大多数基准上超越了现有的统一模型。例如,在MM-Vet基准上,BAGEL比Janus-Pro提高了17.1个百分点。
- 图像生成:在GenEval基准上,BAGEL的综合得分为0.88,超过了所有现有的开源模型和私有模型,包括GPT-4o。
- 图像编辑:在GEdit-Bench基准上,BAGEL的表现与现有的专业图像编辑模型Step1X-Edit相当,并在IntelligentBench基准上显著优于现有开源模型。
- 推理增强生成:在WISE基准上,使用链式思维过程(CoT)的BAGEL得分提高了0.18,显著优于现有开源模型。
- 世界建模:通过增加视频和导航数据的训练比例,BAGEL展示了强大的世界理解和模拟能力,包括世界导航、旋转和多帧生成。
Reference
https://huggingface.co/papers/2505.14683,
https://huggingface.co/ByteDance-Seed/BAGEL-7B-MoT,
https://github.com/bytedance-seed/BAGEL