ELF文件,静态链接(Linux)
1.目标文件
在前面学习C/C++等编译语言时,都会使用编译器,或者集成开发环境,编译和链接这两个步骤,在Windows下被我们的IDE封装的很完美,我们一般都是一键构建非常方便。
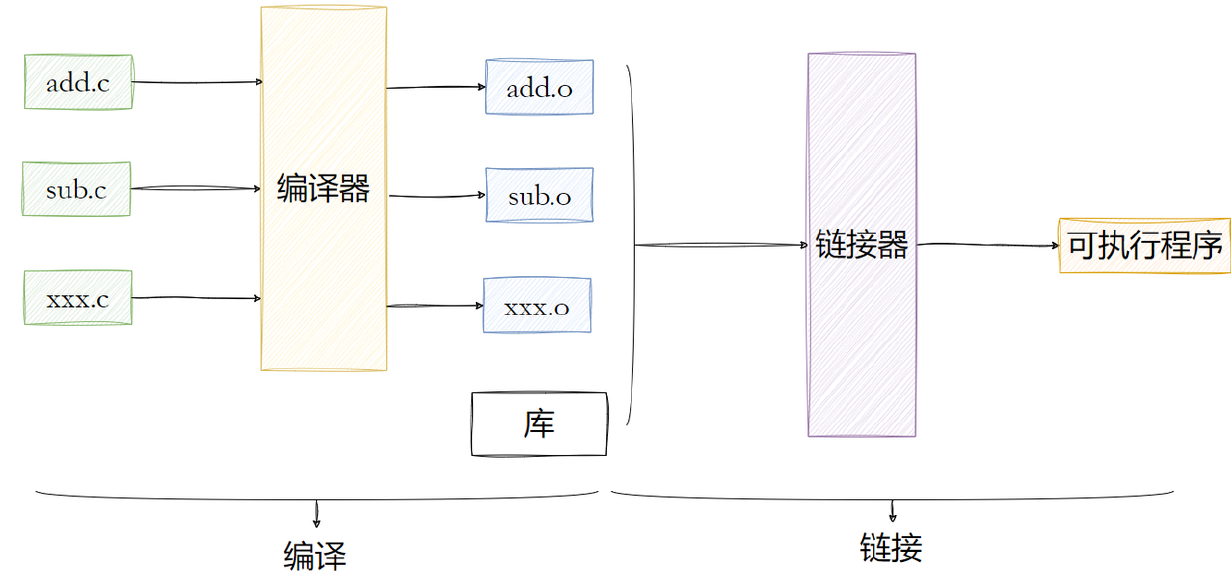
编译的过程其实就是将我们程序的源代码翻译成CPU能够直接运行的机器代码(也就是二进制文件)。
例如:
// test.c
#include<stdio.h>
void run();
int main() {printf("hello world!\n");run();return 0;
}// code.c
#include<stdio.h>
void run() {
printf("running...\n");
}这里有两个文件,可以gcc进行编译:
gcc -c test.c
gcc -c code.c//形成两个文件code.o test.o
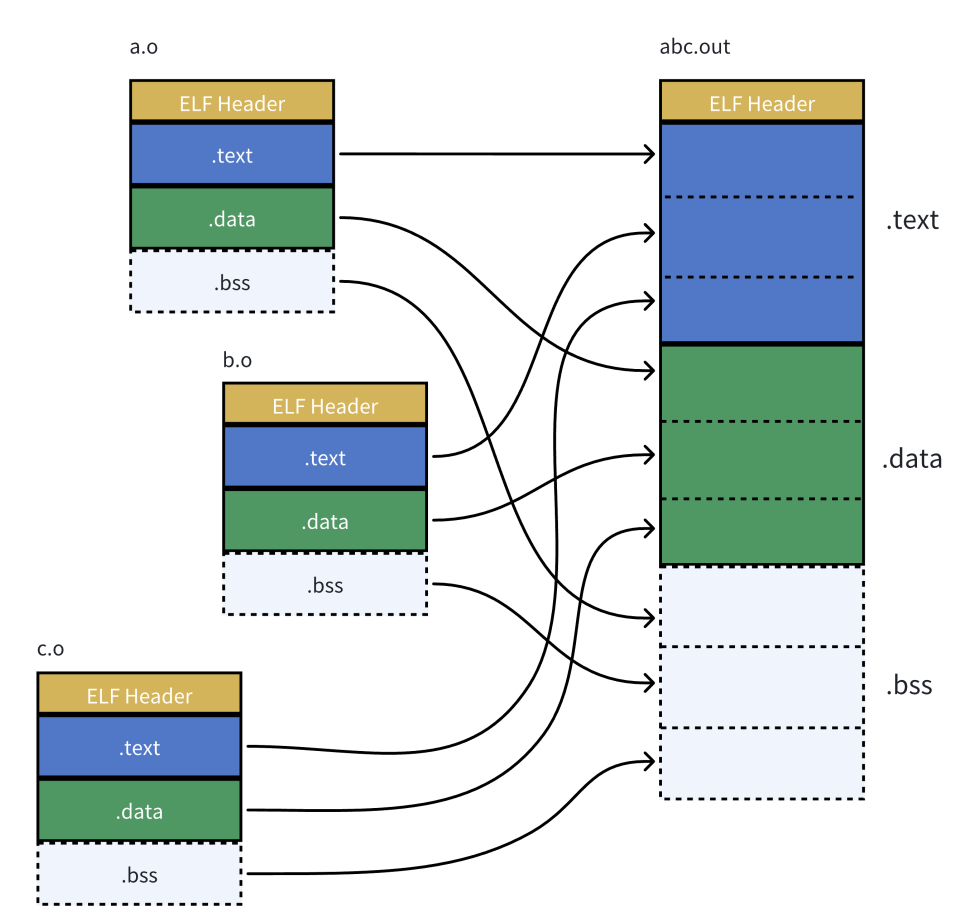
编译之后会生成两个扩展名为.o 的文件,它们被称作目标文件。最后再将两个文件进行链接在一起就可以形成可执行程序。
如果我们修改了一个原文件,那么只需要单独编译它这一个,而不需要浪费时间重新编译整个工程。目标文件是一个二进制的文件,文件的格式是ELF ,是对二进制代码的一种封装。
2. ELF文件
这里首先粗略理解一下ELF文件
主要有以下四种文件其实都是ELF文件:
1.可重定位文件(Relocatable File) :即 xxx.o 文件。包含适合于与其他目标文件链接来创
建可执行文件或者共享目标文件的代码和数据。2.可执行文件(Executable File) :即可执行程序。
3.共享目标文件(Shared Object File) :即 xxx.so文件。
4.内核转储(core dumps) ,存放当前进程的执行上下文,用于dump信号触发。
一个ELF文件由以下四部分组成:
1.ELF头(ELF header) :描述文件的主要特性。其位于文件的开始位置,它的主要目的是定位文件的其他部分。
2.程序头表(Program header table) :列举了所有有效的段(segments)和他们的属性。表里
记着每个段的开始的位置和位移(offset)、长度。
3.节头表(Section header table) :包含对节(sections)的描述。
4.节(Section ):ELF文件中的基本组成单位,包含了特定类型的数据。
ELF文件的各种信息和数据都存储在不同的节中,如代码节存储了可执行代码,数据节存储了全局变量和静态数据等。并且这些段,都是紧密的放在二进制文件中,需要段表(程序头表)的描述信息,才能把他们每个段分割开。
ELF格式:
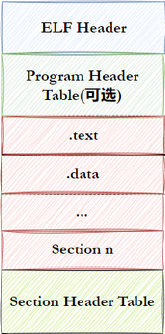
这里可以看到.text(代码节:用于保存机器指令,是程序的主要执行部分),.data(数据节:保存已初始化的全局变量和局部静态变量)等常见的节。
3. ELF从形成到加载大致过程
3.1 ELF形成可执行
先将多份C/C++ 源代码,翻译成为目标.o 文件(这里其实.o文件已经是一个ELF文件了)
再将多份.o 文件section进行合并

3.2ELF可执行文件加载
通过上述查看一个ELF文件有多种不通的Section,在加载到内存时进行Section合并,形成segment
所以这里就必须要有合并原则:
相同属性合并,比如:可读,可写,可执行,需要加载时申请空间等。因此不同的的Section也就能合并到一起(也是为内存节省了空间)
很显然,这个合并工作也已经在形成ELF的时候,合并方式已经确定了,具体合并原则被记录在了 ELF的程序头表(Program header table) 中
通过这个命令可以查看ELF文件的程序头表:
readelf -l 文件(ELF格式)
Elf file type is EXEC (Executable file)
Entry point 0x4003e0
There are 9 program headers, starting at offset 64
首先看到的是,文件类型可执行文件,其次是执行的入口地址 ,段的个数。

值得注意的是这里LOAD两个段,就是要加载到内存的代码段和数据段。
通过这个命令可以查看ELF文件的Section:
readelf -S 文件(ELF格式)

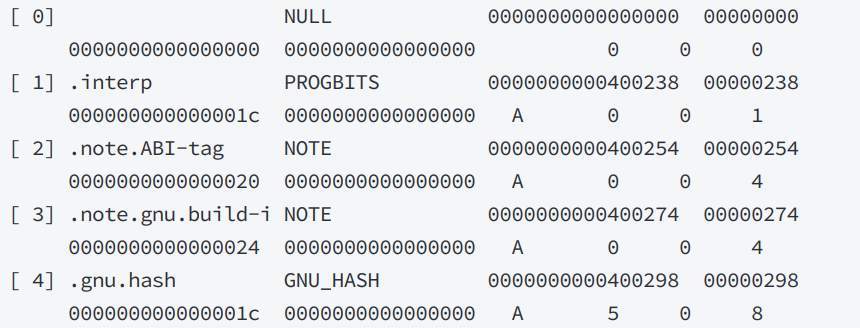
可以看到第一竖列表示这一节的大小,最后的一列表示起始地址。
接下来看看段(合并节):
通过以下指令:
readelf -l 文件(ELF格式)
这里和查看程序头表命令一样,在最后一部分就是段信息。

这里为什么要将section合并成segment:
1.Section合并的主要原因是为了减少页面碎片,提高内存使用效率。如果不进行合并, 假设页面大小为4096字节(内存块基本大小,加载,管理的基本单位),如果.text部分 为4097字节,.init部分为512字节,那么它们将占用3个页面,而合并后,它们只需2个页面。
2.操作系统在加载程序时,会将具有相同属性的section合并成⼀个⼤的 segment,这样就可以实现不同的访问权限,从⽽优化内存管理和权限访问控制。
3.3 程序头表和节头表的作用
ELF文件提供2个不同的视图/视角来让我们理解这两个部分:
链接视图:对应节头表
文件结构的粒度更细,将⽂件按功能模块的差异进行划分,静态链接分析的时候⼀般关注的是链接视图,能够理解ELF文件中包含的各个部分的信息。
为了空间布局上的效率,将来在链接目标文件时,链接器会把很多节(section)合并,规整成可执行的段(segment)、可读写的段、只读段等。所以,链接器趁着链接就把小块们都合并了。
从链接视图来看:
.text节:是保存了程序代码指令的代码节。
.data节:保存了初始化的全局变量和局部静态变量等数据。
.rodata节:保存了只读的数据,如一行C语言代码中的字符串。由于.rodata节是只读的,所以只能存在于⼀个可执行文件的只读段中。因此,只能是在text段(不是data段)中找到.rodata节。
.BSS节:为未初始化的全局变量和局部静态变量预留位置
.symtab节 :Symbol Table符号表,就是源码里面那些函数名、变量名和代码的对应关系。
got.plt节(全局偏移表-过程链接表):.got节保存了全局偏移表。.got节和.plt节⼀起提供了对导入的共享库函数的访问入口,由动态链接器在运行时进行修改。
执行视图:对应程序头表
告诉操作系统,如何加载可执行文件,完成进程内存的初始化。
从执行视图来看:
告诉操作系统哪些模块可以被加载进内存。
加载进内存之后哪些分段是可读可写,哪些分段是只读,哪些分段是可执行的。
结论:⼀个在链接时作用,⼀个在运行加载时作用。
4 链接与加载
4.1 静态链接
无论是自己的.o,还是静态库中的.o,本质都是把.o文件件进行连接的过程,所以:研究链接,就是理解.o是如何链接的。
下面通过以下代码来研究该过程:
//hello.c 文件
#include<stdio.h>
void run();
int main()
{ printf("hello world!\n"); run();10 return 0;
}//code.c 文件
#include<stdio.h>
void run()
{printf("run...\n");
}首先将两个文件编程.o目标文件。
这里介绍一个命令可以将代码段(.text)进行反汇编查看:
objdump -d 文件名

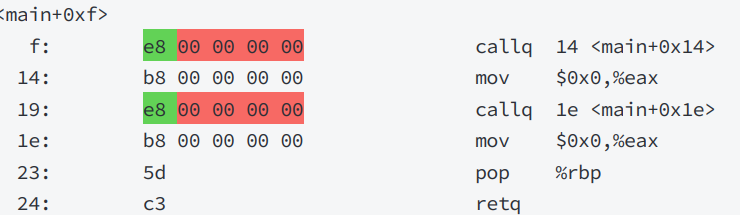 可以看到这里调用printf函数,和run时,call的地址为零。
可以看到这里调用printf函数,和run时,call的地址为零。
其实就是在编译hello.c的时候,编译器是完全不知道printf和run函数的存在的,(他们位于内存的哪个区块,代码长什么样都是不知道的)。因此,编辑器只能将这两个函数的跳转地址先暂时设为0。
这个地址什么时候被修正呢?其实是在链接时修正。
这里可以得到一个结论:.o文件彼此是不知道对方的存在的。
为了让链接器将来在链接时能够正确定位到这些被修正的地址,在代码块(.data)中还存在⼀个重定位表,这张表将来在链接的时候,就会根据表里记录的地址将其修正。
查看符号表的指令:
readelf -s 文件名

可以看到在hello.o文件中:
puts:就是printf的实现, run就是我们自己的方法在hello.o中未定义(因为在code.o中)
UND就是:undefine,表示未定义(就是本.o文件找不到)
最后将helle.o与code.o文件进行链接形成可执行程序,再来查看符号表

 两个.o进行合并之后,在最终的可执行程序中,就找到了run
两个.o进行合并之后,在最终的可执行程序中,就找到了run
0000000000001149:其实是地址
FUNC:表示run符号类型是个函数
16:就是run函数所在的section被合并最终的那⼀个section中了,16就是下标
读取可执行程序最终的所有的section清单

hello.o和code.o的.text被合并了,是main.exe的第16个section
这里再将可执行程序转到反汇编查看:
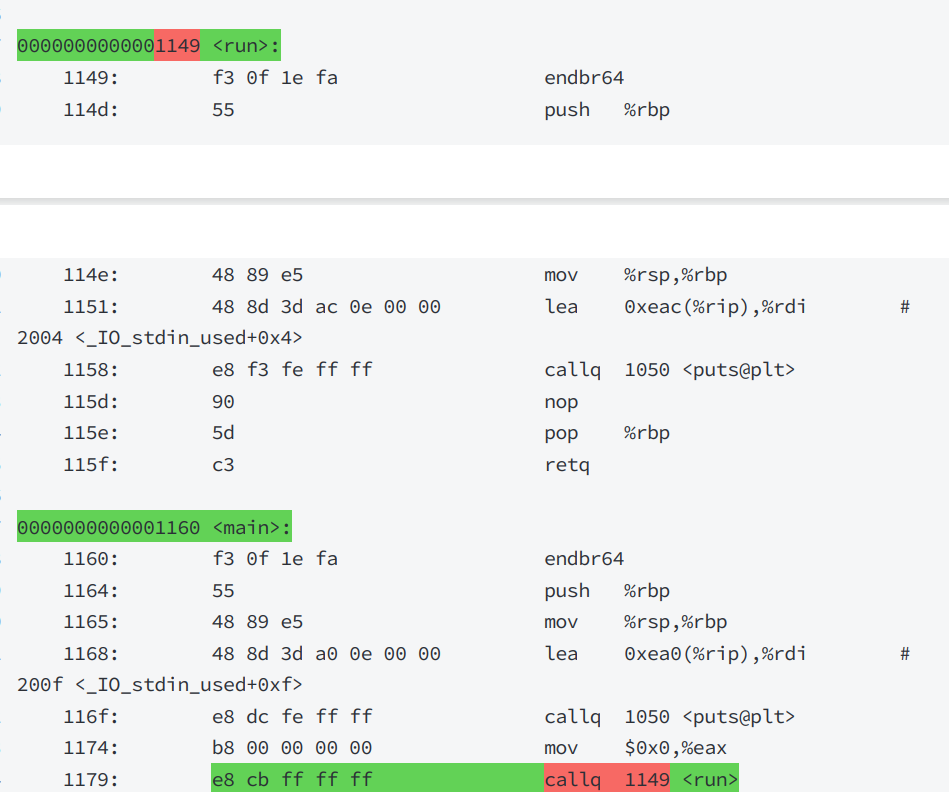
最终得出结论:两个.o的代码段合并到了⼀起,并进行了统⼀的编址,链接的时候,会修改.o中没有确定的函数地址,在合并完成之后,进行相关call地址,完成代码调用。
统一编制: