并发编程实战(生产者消费者模型)
在并发编程中使用生产者和消费者模式能够解决绝大多数的并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序整体处理数据的速度。
生产者和消费者模式:
在线程的世界中生产者就是产生数据的线程,而消费者则是消费数据的线程。在多线程开发中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完才能继续生产数据。同理,如果消费者处理速度很快,而生产者生产速度很慢,那么消费者就得等待生产者。为了解决这种生产消费能力不均衡的问题,便有了生产者和消费者模式。
在没有使用生产者和消费者模式之前,往往生产者和消费者都是高耦合的。生产者每次生产一个数据后的逻辑处理都依赖于消费者的处理能力。而采用这种模式之后通过一个容器来解决了强耦合的问题,生产者与消费者之间不再进行通信,所以生产者生产后的数据无需依赖于消费者进行处理而是直接扔到阻塞队列中,消费者同理。阻塞队列相当于一个缓冲区,平衡了生产者和消费者的处理能力。
纵观大多数的设计模式都会采用第三者来给双方进行解耦,工厂模式的第三方是工厂类,模板模式的第三方是模板类。。。因此在一些实际业务场景中我们也可以通过添加第三者的方式来将整个业务进行解耦的处理操作。
实际应用场景:
邮件分类:
在一个场景中假设我们需要从一个邮箱中将该邮箱的所有邮件进行分类处理。对于最简单的方法就是采用单线程不断轮询获取到该邮箱的所有邮件并且进行循环处理邮件将其进行。这种方式则最简单的方式但是这样做的缺点显而易见,如果邮箱中突然出现大量的邮件进行处理则会造成处理时间过长而造成性能下降。
那么我们想要提升处理吞吐量最简单的则是采用多线程的模式来进行处理。那么采用什么样方式处理最简单呢。提到多线程处理我们肯定是要保证同步的,那么有没有现成的线程安全的方案可以直接使用的呢,答案是阻塞队列。采用生产者消费者的模式来使用阻塞队列不仅能保证线程安全而且也提高了吞吐量更为重要的则是实现方式非常简单。
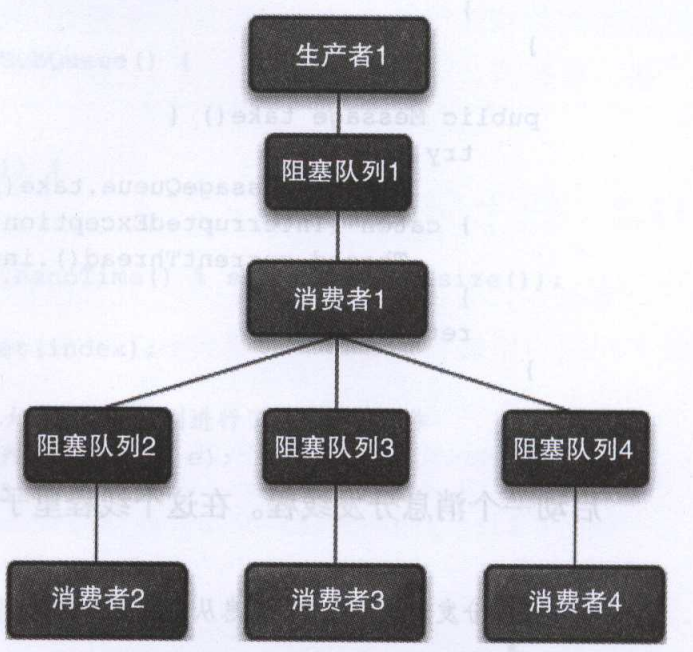
接下来我们将说一说设计思路,就如上图所示这是整个设计的架构图。生产者则是无论种类不断向阻塞队列里投放邮件,而第一个消费者则是取出邮件后进行分类处理投放到不同的阻塞队列中去,这个操作是cpu密集型操作而不是io密集型操作因此速度较快,而下面的几个消费者则是专门进行处理这种类型的邮件的。采用上述的方式不仅提高了吞吐量更为重要的是解耦并且实现简单。这就是生产者消费者模式。在实际的许多业务场景中使用这种方式进行处理则是很常见的。
线程池:
实际上我们最常使用的线程池它的内部本身就是采用的生产者消费者的模型机制。而这个模型设计的更加巧妙。
我们都知道线程池主要是由工作线程和任务队列以及任务组成的。在最常见的生产者消费者模型中则是生产者将任务丢给队列中,消费者从队列中取出。但是对于线程池则是如果有空闲线程则可以将任务直接交给空闲线程去处理这样做就省下了放到队列中的步骤。
异步线程池:

线程池固然好用但是有两个缺点:
1.线程池中的任务无法持久保存,如果主机宕机则会导致任务全部丢失
2.线程池只能处理本机的任务在集群中则无法去处理
因此对于以上缺点,异步线程池则能解决此类问题。结构如上图所示。
可以看出,当有任务来到的时候生产者将任务放入到数据库中,这次不再是阻塞队列中去。原因很简单:1.任务持久化处理,2.适用与分布式架构的模式。同时每个机器中开辟多个线程池,这多个线程池从数据库中取出任务,同时我们赋予任务状态来保证同步,状态值:创建,执行中,重试,挂起,中止,完成。
创建:这个状态则是生产者刚把任务放入数据库中等待消费者处理
执行中:消费者拿到任务后修改状态值表示这个任务以及被消费者处理中,其他消费者则在此过程中无法处理该任务
重试:消费者处理过程中发生异常情况则将此状态为设置为重试,根据不同任务的类型对应不同重试的策略
挂起:当前任务等待某个前置任务的完成之后才能执行本任务那么就需要将其设置为挂起,业务员自己设置挂起后的策略
中止:由于某种原因本任务则无需执行则会将其设置为中止状态
完成:完成了本任务的执行
那么异步线程池需要注意哪些地方呢
任务隔离:异步任务往往是有多种类型的,但是系统的资源是有限的。如果采用优先级的方式那么很有可能会造成某些高优先级的任务永远无法执行,因此我们采用的策略则是根据不同的任务我们采用不同的线程池进行处理,也就是任务类型分组处理,我们可以通过控制分组线程池的多少来进行进行控制处理的速率以及资源的部署。这样就不会造成某些任务永远无法处理的情况顶多是那些分配的资源少的任务类型处理速度上较慢。
重试策略:根据不同的任务类型设置不同的重试策略,有些任务可能要求实时性高。那么每次的重试间隔就会非常短,如果对实时性要求不高,可以采用默认的重试策略来对其进行重试。每个类型可以设置不同的重试次数
勿本机存储:对于不同机器上的线程池不要采用本机存储的方式因为整个项目采用的是集群部署,如果采用本机存储,某些后续任务可能有着上一个任务存储资源的存储路径,如果前置任务在机器A中完成那么后置任务将会无法找到这个资源
异步属性:对于所有任务都必须要带有任务的状态,名称,下次执行时间,执行次数,任务类型,报错类型等等任务属性。这样对于后续任务的进展将会有很大的帮助简化了不少的业务复杂度