软件测试—学习Day10
1.能否在PC上模拟移动端客户端的页面?如何做到?可以代替真机测试吗?
在 PC 上可以模拟移动端客户端的页面,以下是一些常见的方法:
- 使用浏览器开发者工具1:主流的桌面浏览器如 Chrome、Firefox、Safari、Edge 等都具备开发者工具来模拟移动端页面。以 Chrome 浏览器为例,具体操作步骤如下:
- 打开 Chrome 浏览器并访问要测试的网站。
- 右键点击网页任意位置,选择 “审查元素”,或者使用快捷键 F12 打开开发者工具。
- 在开发者工具中,找到左上角的一个小手机图标,点击它。
- 在偏左上角的 “选择模式” 下拉菜单中,有许多设备可供选择,选择相应设备后,浏览器会模拟该设备的显示方式。此外,顶部还有选择网速的选项,可以模拟不同的网络速度。
- 使用专门的模拟工具:
- 安卓模拟器:如 Genymotion、BlueStacks 等。这些模拟器可以在 PC 上模拟安卓手机的环境,包括不同的安卓系统版本和设备型号。你可以在模拟器中安装安卓应用程序或直接访问网页,以查看移动端页面的显示效果。
- iOS 模拟器:在 Mac 系统上,Xcode 自带了 iOS 模拟器,可以模拟不同型号的 iPhone、iPad 等设备。不过,Windows 系统上要模拟 iOS 相对复杂一些,可能需要借助一些第三方工具或虚拟机来实现,但使用体验可能不如在 Mac 上原生的 iOS 模拟器。
虽然在 PC 上模拟移动端页面可以提供一些便利,但它不能完全代替真机测试,原因如下:
- 硬件差异:模拟器无法完全精确地模拟真实设备的硬件特性,如 CPU、GPU 性能、内存大小、传感器(如重力传感器、摄像头、指纹识别等)。在一些对硬件性能有要求的应用或页面中,可能会出现与真机不同的表现,例如动画卡顿、加载速度差异等。
- 系统和软件环境:即使模拟器可以模拟特定的操作系统版本,但与真实设备上的系统和软件环境仍可能存在细微差别。例如,系统更新、预装软件、字体渲染等方面的差异,可能导致页面布局、字体显示等方面的不一致。
- 网络环境:虽然可以在模拟器中模拟不同的网络速度,但真实设备在不同的网络环境(如 4G、5G、Wi-Fi)下,以及不同的信号强度下,其网络连接的稳定性、延迟、丢包率等实际情况更加复杂,模拟器难以完全复现。
- 用户体验:真机测试能够提供更真实的用户操作体验,包括触摸屏幕的手感、设备的尺寸和重量、屏幕的显示效果等。这些因素对于评估用户在实际使用过程中的满意度和操作便捷性非常重要,而模拟器在这方面无法完全替代真机。
2.哪些性能问题是用户可见的?
用户可见的性能问题通常直接影响使用体验,甚至导致功能不可用。以下从 页面展示、交互操作、系统资源占用 三个维度,结合具体场景说明:
一、页面展示相关的性能问题
用户直接通过视觉感知的异常,常见于网页、应用界面加载或渲染过程中。
1. 加载速度慢
- 表现:
- 页面空白时间长,加载动画(如进度条、 spinner )持续过久。
- 图片、视频、字体等资源加载延迟,导致页面 “骨架” 先出现,内容后填充(俗称 “跳屏”)。
- 案例:电商首页商品列表加载缓慢,用户需等待数秒才能看到商品图片。
2. 渲染异常 / 卡顿
- 表现:
- 页面元素闪烁、错位(如字体模糊、布局混乱)。
- 复杂页面(如大数据表格、地图)滚动时卡顿,帧率明显下降(低于 30fps 时用户感知明显)。
- 案例:新闻 App 长图文滑动时出现 “掉帧”,操作不流畅。
3. 资源加载失败
- 表现:
- 图片、视频显示为 broken link 图标或空白区域。
- 脚本加载失败导致功能按钮失效(如 “提交” 按钮无响应)。
- 案例:视频网站播放页因视频资源加载失败,显示 “加载错误” 提示。
二、交互操作相关的性能问题
用户与界面互动时感受到的延迟、卡顿或异常反馈。
1. 操作响应延迟
- 表现:
- 点击按钮后无即时反馈(如按钮高亮延迟、弹窗弹出缓慢)。
- 输入框输入时文字显示滞后(尤其在移动端或低配置设备上)。
- 案例:社交 App 发送消息时,点击 “发送” 按钮后数秒才显示消息已发出。
2. 动画 / 过渡效果卡顿
- 表现:
- 页面切换动画(如左右滑动、淡入淡出)不流畅,出现 “撕裂” 或停顿。
- 交互动画(如按钮涟漪效果)帧率低,视觉体验差。
- 案例:游戏界面技能释放动画卡顿,影响战斗连贯性。
3. 功能无响应或崩溃
- 表现:
- 操作后界面冻结(如 “假死” 状态),需强制关闭应用重启。
- 高频操作(如快速点击按钮)导致应用闪退或报错。
- 案例:金融类 App 连续点击 “刷新” 按钮后,应用崩溃并弹出错误日志。
三、系统资源占用相关的性能问题
用户虽不直接看到,但通过设备状态感知的性能异常。
1. 设备发热 / 耗电快
- 表现:
- 使用应用时,手机 / 电脑温度明显升高(如烫手)。
- 电池续航骤减,后台应用未关闭时电量消耗异常。
- 案例:导航 App 长时间使用后,手机发热严重且电量快速下降。
2. 内存 / CPU 占用过高
- 表现:
- 多任务切换时设备卡顿(如手机杀后台、电脑风扇狂转)。
- 低配置设备因资源不足导致应用频繁闪退。
- 案例:视频剪辑软件导出视频时,电脑 CPU 占用率达 100% ,其他程序无法正常运行。
3. 网络流量异常
- 表现:
- 非下载场景下,流量消耗远超预期(如后台偷跑流量)。
- 弱网环境下加载失败或重复请求,浪费用户流量。
- 案例:资讯类 App 未提示用户的情况下,自动播放视频消耗大量流量。
四、如何区分用户可见与不可见的性能问题?
| 维度 | 用户可见 | 用户不可见(需技术监测) |
|---|---|---|
| 感知方式 | 视觉、触觉(操作延迟)、设备状态(发热) | 后台接口响应时间、数据库查询效率等 |
| 典型场景 | 页面卡顿、按钮无响应、发热耗电 | 服务器日志错误、缓存命中率低、代码内存泄漏 |
| 影响优先级 | 直接影响用户体验,需优先修复 | 长期影响系统稳定性,需持续优化 |
总结:用户可见性能问题的核心影响
- 体验层面:导致用户烦躁、流失(如加载超时率超过 3 秒,跳出率显著上升)。
- 口碑层面:影响产品评分(如 App Store 因卡顿被用户差评)。
- 商业层面:电商类场景中,加载速度每慢 1 秒,转化率可能下降 7% 。
因此,测试和优化时需优先关注用户直接感知的性能问题,结合 真机测试、用户行为埋点、性能监控工具(如 Lighthouse、PerfMon) 定位根源,确保体验与功能的平衡。
3.如何设计客户端自动化测试框架,可以满足易维护、易配置、易添加的需求?
以下是设计满足易维护、易配置、易扩展的客户端自动化测试框架的系统化方法,结合分层架构、模块化设计和最佳实践:
一、架构设计:分层解耦,降低维护成本
采用四层架构模型,将测试逻辑与实现细节分离:
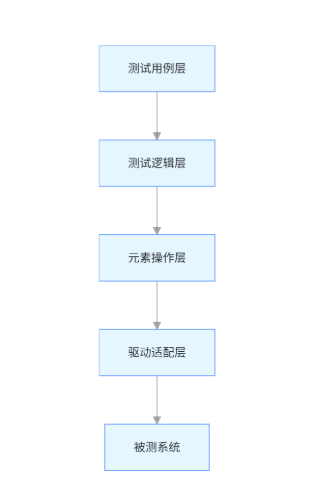
-
测试用例层
- 用例以数据驱动方式定义(如 YAML/JSON),避免硬编码:
# login_test.yaml - test_case: 正常登录steps:- action: input_usernameparams: { username: "test_user" }- action: input_passwordparams: { password: "123456" }- action: click_login- verify: element_existsparams: { element: "home_page" }
- 用例以数据驱动方式定义(如 YAML/JSON),避免硬编码:
-
测试逻辑层
- 将业务流程封装为关键字驱动的 API:
# keywords.py class LoginKeywords:def input_username(self, username):self.element_op.input_text("username_field", username)def click_login(self):self.element_op.click("login_button")
- 将业务流程封装为关键字驱动的 API:
-
元素操作层
- 统一管理元素定位与基础操作,屏蔽底层差异:
# element_operations.py class ElementOperations:def __init__(self, driver):self.driver = driverdef click(self, element_id):element = self._find_element(element_id)element.click()def _find_element(self, element_id):# 从元素映射表获取定位方式locator = self.element_map.get(element_id)return self.driver.find_element(*locator)
- 统一管理元素定位与基础操作,屏蔽底层差异:
-
驱动适配层
- 支持多平台 / 多浏览器切换:
# driver_factory.py class DriverFactory:@staticmethoddef create_driver(platform, config):if platform == "web":return WebDriver(config["browser"])elif platform == "android":return AndroidDriver(config["device_id"])elif platform == "ios":return IOSDriver(config["udid"])
- 支持多平台 / 多浏览器切换:
二、配置管理:集中化、参数化、环境隔离
1. 配置文件分层设计
config/
├── global_config.yaml # 全局配置
├── env/ # 环境配置
│ ├── dev.yaml
│ ├── test.yaml
│ └── prod.yaml
└── platforms/ # 平台配置├── web.yaml├── android.yaml└── ios.yaml
2. 动态加载配置
# config_loader.py
class ConfigLoader:def __init__(self, env="dev", platform="web"):self.global_config = self._load_yaml("config/global_config.yaml")self.env_config = self._load_yaml(f"config/env/{env}.yaml")self.platform_config = self._load_yaml(f"config/platforms/{platform}.yaml")def get(self, key, default=None):# 按优先级合并配置:平台 > 环境 > 全局return (self.platform_config.get(key) or self.env_config.get(key) or self.global_config.get(key, default))
3. 敏感信息加密
使用环境变量或加密工具(如 Vault)管理密码:
# CI环境设置
export DB_PASSWORD=$(vault read -field=password secret/db_creds)
三、扩展机制:插件化、钩子系统、数据驱动
1. 插件系统
# plugin_manager.py
class PluginManager:def __init__(self):self.plugins = []def register_plugin(self, plugin):self.plugins.append(plugin)def before_test(self, test_case):for plugin in self.plugins:plugin.before_test(test_case)
2. 数据驱动测试
使用 CSV/Excel/ 数据库作为测试数据来源:
# test_data.csv
username,password,expected_result
test_user,123456,success
invalid_user,wrong_pwd,failure# data_provider.py
class DataProvider:@staticmethoddef from_csv(file_path):with open(file_path, "r") as f:reader = csv.DictReader(f)return list(reader)
3. 自定义断言库
封装业务相关断言:
# custom_assertions.py
class CustomAssertions:def assert_element_text(self, element_id, expected_text):actual_text = self.element_op.get_text(element_id)assert actual_text == expected_text, f"文本不匹配: {actual_text} != {expected_text}"def assert_http_status(self, response, status_code):assert response.status_code == status_code, f"HTTP状态码错误: {response.status_code}"
四、维护策略:元素管理、版本控制、文档自动化
1. 元素映射管理
使用独立文件维护元素定位信息:
// elements/web_elements.json
{"login_button": ["xpath", "//button[text()='登录']"],"username_field": ["id", "username"],"password_field": ["id", "password"]
}
2. 自动生成测试报告
集成 Allure/Pytest 生成可视化报告:
# 执行测试并生成报告
pytest --alluredir=./test-results
allure generate ./test-results -o ./reports --clean
3. 文档自动化
从测试用例自动生成操作手册:
# doc_generator.py
class DocGenerator:def generate_test_steps(self, test_case_file):test_data = self._load_test_case(test_case_file)steps = []for step in test_data["steps"]:steps.append(f"1. {step['action']}({step['params']})")return "\n".join(steps)
五、技术选型推荐
| 维度 | 推荐工具 / 框架 | 理由 |
|---|---|---|
| Web 自动化 | Selenium + WebDriverManager | 跨浏览器支持,社区活跃,文档完善 |
| 移动应用自动化 | Appium + UiAutomator2 (Android)/XCUITest (iOS) | 跨平台统一 API,支持原生、混合应用 |
| 测试框架 | Pytest + Allure | 灵活的测试发现机制,强大的插件生态,美观的测试报告 |
| 数据驱动 | Pytest parametrize + YAML/CSV | 简单易用,支持复杂数据结构 |
| CI/CD 集成 | Jenkins/GitLab CI + Docker | 自动化执行测试,环境隔离,快速部署 |
六、实施路径建议
-
原型验证(2 周)
- 实现基础框架结构,验证核心功能(如 Web 登录流程测试)。
-
分层开发(4 周)
- 完善各层功能,添加错误处理和日志记录。
-
扩展支持(3 周)
- 集成移动平台、API 测试,添加数据驱动和插件系统。
-
文档与培训(2 周)
- 编写使用指南,对测试团队进行培训。
-
灰度上线(1 周)
- 在小范围项目中试用,收集反馈并优化。
七、避坑指南
- 过度设计:避免引入不必要的抽象层,保持简单直接。
- 元素定位脆弱性:优先使用 ID/Name,避免硬编码 XPath,定期维护元素映射。
- 忽略并发与异步:使用显式等待替代固定休眠,处理 AJAX / 动画加载。
- 缺乏错误恢复:实现重试机制和测试状态重置,避免用例间污染。
通过以上设计,框架可达到:
- 易维护:修改一处影响范围小,代码结构清晰。
- 易配置:通过 YAML 文件快速切换环境和平台。
- 易扩展:插件系统支持无缝添加新功能(如性能监控、UI 比对)。
4.客户端的自动化测试中有哪些问题可以影响稳定性?如何提高自动化测试的稳定性?
在客户端自动化测试中,稳定性受多因素影响,需从环境、定位、数据等多维度优化。以下是具体问题分析及解决方案:
一、影响稳定性的核心问题
1. 环境不一致性
- 设备碎片化:不同机型 / 系统版本(如 iOS 16 vs 17、Android 12 vs 13)导致界面布局、交互逻辑差异。
- 网络波动:弱网、断网场景下,请求超时或数据加载不完整引发断言失败。
- 数据污染:测试数据未隔离(如共用账号、未清理缓存),导致用例间互相干扰。
2. 元素定位脆弱性
- 动态属性:动态生成的 ID、类名(如
item_123)或随机布局,导致定位表达式(XPath/CSS)失效。 - 加载延迟:异步渲染(如懒加载图片、AJAX)时,脚本提前操作未就绪元素,抛出
NoSuchElement异常。 - 遮挡元素:弹窗、浮层未完全消失时,点击事件被上层元素拦截。
3. 操作时序问题
- 线程竞争:多线程执行时,共享资源(如数据库连接、文件句柄)未加锁,导致数据不一致。
- 动画影响:滑动、切换 Tab 等操作受过渡动画干扰,坐标映射在模拟器与真机间存在偏差。
- 依赖顺序:用例需按固定顺序执行(如先注册后登录),某环节失败导致链式反应。
4. 框架与工具缺陷
- 版本兼容性:自动化工具(如 Appium 1.22 不支持 iOS 16 的新 API)与被测应用版本不匹配。
- 自定义代码 bug:封装的工具类(如滑动手势、断言方法)存在隐性缺陷,偶发运行时异常。
- 报告丢失:测试报告生成工具不稳定,导致结果漏记或统计错误。
二、提升稳定性的关键策略
1. 环境标准化与隔离
- 容器化部署:
- 使用 Docker 管理模拟器 / 真机环境,确保系统版本、APP 版本一致。
- 示例:通过 Docker Compose 启动多台 Android 模拟器,指定镜像版本为
android:29。
- 网络模拟工具:
- 用 Charles 或 Postman 模拟弱网(如 2G 网络延迟 300ms),测试脚本添加重试机制:
# 带重试的点击操作 from tenacity import retry, stop_after_attempt, wait_exponential @retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=2, max=10)) def safe_click(element):element.click()
- 用 Charles 或 Postman 模拟弱网(如 2G 网络延迟 300ms),测试脚本添加重试机制:
- 数据沙箱:
- 为每个测试用例分配独立数据库事务,执行后自动回滚(如使用 Spring @Transactional)。
- 用 Faker 生成随机测试数据(如唯一手机号
fake.phone_number()),避免重复冲突。
2. 健壮的元素定位方案
- 分层定位策略:
- 首选语义化属性:
accessibilityId(iOS)、content-desc(Android)、testId(Web)。 - 次选稳定属性:
resource-id或组合定位(如class="Button" and contains(text(), "提交"))。 - 兜底方案:相对 XPath(避免绝对路径),如
//*[@text="登录"]/following-sibling::input。
- 首选语义化属性:
- 显式等待替代固定休眠:
// WebDriver等待元素可点击(最多10秒) WebDriverWait wait = new WebDriverWait(driver, 10); WebElement button = wait.until(ExpectedConditions.elementToBeClickable(By.id("submitBtn"))); - 元素库(Element Repository)管理:
- 将定位表达式集中存储在 JSON/XML 文件中,如:
{"loginPage": {"usernameField": "//input[@name='username']","passwordField": "//input[@name='password']"} }
- 将定位表达式集中存储在 JSON/XML 文件中,如:
3. 操作防抖与同步控制
- 事件监听与状态验证:
- 点击前检查元素可见性与可用性:
element.isDisplayed() && element.isEnabled()。 - 针对异步操作,通过监听网络请求结束或加载状态(如 Toast 提示)确保完成:
# 等待接口返回数据 def wait_for_api_response(driver, endpoint, timeout=10):start_time = time.time()while time.time() - start_time < timeout:if endpoint in driver.logs.get('performance'):return Trueraise TimeoutError("API请求未完成")
- 点击前检查元素可见性与可用性:
- 并发测试隔离:
- 对共享资源(如全局变量、文件)加锁,使用
threading.Lock()或分布式锁(如 Redis)。 - 用测试框架并行执行无依赖的用例(如 JUnit 5 的
@ParallelGroup),避免竞争。
- 对共享资源(如全局变量、文件)加锁,使用
4. 数据管理与清理机制
- 数据工厂模式:
- 封装数据生成类,统一管理测试数据格式与唯一性:
public class TestDataFactory {public static String generateUniqueEmail() {return "user_" + System.currentTimeMillis() + "@example.com";} }
- 封装数据生成类,统一管理测试数据格式与唯一性:
- 自动化清理流程:
- 在
tearDown阶段通过 API 或数据库脚本删除测试数据:# 删除测试创建的用户 def teardown(self):response = requests.delete(f"https://api.example.com/users/{self.user_id}")assert response.status_code == 200, "数据清理失败" - 使用数据库快照或 Docker Volume 快速重置环境,避免残留数据影响后续用例。
- 在
5. 框架分层与持续优化
- 三层架构设计:
- 基础设施层:封装驱动管理(如 Appium 初始化)、日志记录、异常处理。
- 业务逻辑层:通过页面对象模式(POM)封装页面操作,隐藏元素定位细节。
- 用例层:组合业务逻辑,聚焦测试场景(如 “购物车结算流程”)。
- CI/CD 集成与监控:
- 将测试套件接入 Jenkins/GitHub Actions,每次代码提交后自动运行冒烟测试。
- 配置监控指标(如用例成功率、执行时长),通过 Grafana 实时展示趋势,设置失败率 > 10% 时报警。
- 定期兼容性测试:
- 维护工具与平台的兼容性矩阵(如Appium 支持列表),每季度升级工具版本并验证核心用例。
三、实践步骤:稳定性提升路线图
| 阶段 | 目标 | 关键动作 |
|---|---|---|
| 基础建设 | 搭建稳定的测试底座 | 1. 统一环境配置(Docker + 模拟器镜像) 2. 建立元素库与数据工厂 |
| 优化迭代 | 降低偶发失败率 | 1. 为所有点击操作添加显式等待 2. 实现数据自动清理 3. 引入重试机制 |
| 持续改进 | 建立稳定性保障体系 | 1. 集成 CI/CD 并设置质量门禁 2. 每周分析失败报告,修复高频问题 |
5.xpath和css selector的差别?怎样用css selector访问第n个子节点?
XPath 与 CSS Selector 的核心差异
XPath 和 CSS Selector 是前端自动化测试中定位元素的两种主要方式,它们的核心差异体现在语法设计、定位逻辑和性能表现上:
| 维度 | XPath | CSS Selector |
|---|---|---|
| 语法类型 | 路径表达式语言,支持完整的 XML 节点查询 | 基于 CSS 规则的选择器语法 |
| 定位方向 | 支持双向定位(向前 / 向后 / 同级) | 仅支持向前定位(父→子→孙) |
| 层级表示 | 使用/表示直接子节点,//表示任意层级子节点 | 使用>表示直接子节点,空格表示任意层级子节点 |
| 轴选择器 | 支持丰富的轴(如parent::、following-sibling::) | 仅支持简单的兄弟选择器(+、~) |
| 性能 | 需遍历 DOM 树,性能较低(尤其复杂表达式) | 直接映射 CSS 规则,性能较高 |
| 浏览器兼容性 | 所有现代浏览器支持,但旧版 IE 可能有差异 | 几乎 100% 兼容,但部分高级选择器(如:has())需注意 |
| 示例 | //div[@class='container']/ul/li[3] | div.container > ul > li:nth-child(3) |
CSS Selector 访问第 n 个子节点的方法
在 CSS 中,可以通过以下方式精确定位第 n 个子节点:
1. :nth-child(n)
匹配父元素下的第 n 个任意类型子节点(无论标签名):
/* 选择父元素下的第3个子节点(无论是什么标签) */
.parent :nth-child(3) {color: red;
}/* 选择第偶数个子节点(2、4、6...) */
.parent :nth-child(even) {background: lightgray;
}/* 选择从第5个开始的所有子节点 */
.parent :nth-child(n+5) {font-weight: bold;
}
2. :nth-of-type(n)
匹配父元素下的第 n 个特定类型子节点(只计算同标签名的元素):
/* 选择父元素下的第2个div子节点 */
.parent div:nth-of-type(2) {border: 1px solid blue;
}/* 选择父元素下的第1个p标签 */
.parent p:nth-of-type(1) {text-decoration: underline;
}
3. :first-child与:last-child
匹配第一个和最后一个子节点:
/* 选择第一个子节点 */
.parent :first-child {font-size: 20px;
}/* 选择最后一个子节点 */
.parent :last-child {margin-bottom: 0;
}
4. 组合使用:精确定位嵌套层级
结合元素类型、类名和位置选择器:
/* 选择class为"item"的第3个div子节点 */
.container div.item:nth-child(3) {opacity: 0.8;
}/* 选择第2个section下的第1个button */
body section:nth-of-type(2) button:first-child {background-color: green;
}
实战场景示例
假设存在以下 HTML 结构:
<div class="shopping-list"><h3>商品列表</h3><ul><li class="item">苹果</li><li class="item">香蕉</li><li class="item sale">橙子(促销)</li><li class="item">西瓜</li></ul>
</div>
需求对应的 CSS 选择器:
-
选择第 3 个商品(橙子):
.shopping-list ul li:nth-child(3) -
选择倒数第 2 个商品(橙子):
.shopping-list ul li:nth-last-child(2) -
选择第 1 个促销商品:
.shopping-list ul li.sale:nth-of-type(1)
性能与最佳实践建议
-
优先使用 CSS Selector:在自动化测试中,CSS Selector 的执行效率通常比 XPath 高 3-5 倍,尤其在复杂 DOM 结构中。
-
避免过度依赖位置选择器:如果元素有稳定的 ID、类名或语义化属性(如
data-testid),优先使用这些特征直接定位,而非依赖其在 DOM 中的位置。 -
结合浏览器开发者工具验证:在 Chrome/Firefox 中,可通过开发者工具的 Elements 面板右键复制元素的 CSS 路径,或使用
$()函数实时验证选择器:// 在浏览器控制台中测试 $('div.shopping-list > ul > li:nth-child(3)') -
注意伪类与伪元素的限制:
:nth-child()等伪类可用于定位,但伪元素(如::before、::after)无法直接被选中,需通过其父元素间接操作。
通过合理选择定位策略和熟练运用 CSS Selector 的位置选择器,可以显著提升自动化测试的稳定性和可维护性。
6.selenium中如何处理staleElementReferenceException?
在 Selenium 自动化测试中,StaleElementReferenceException是常见的错误之一,通常发生在元素被加载到 DOM 后又被修改或重新加载的场景。以下是处理该异常的系统性方法:
一、异常产生的根本原因
- 元素被重新渲染:页面局部刷新(如 AJAX 请求后)导致元素节点被替换。
- 页面跳转或重载:操作后页面 URL 变化,原 DOM 失效。
- 动态内容加载:异步加载的内容(如懒加载图片、无限滚动)导致元素状态变化。
- 元素被隐藏或移除:弹窗关闭、动画过渡等操作使元素暂时不可用。
二、解决方案与最佳实践
1. 重新定位元素
每次使用前重新查找元素,避免使用缓存的元素引用:
# 错误示例:缓存元素引用
element = driver.find_element(By.ID, "dynamic-element")
driver.refresh()
element.click() # 抛出StaleElementReferenceException# 正确示例:每次使用前重新定位
def click_dynamic_element():element = driver.find_element(By.ID, "dynamic-element")element.click() # 确保使用时元素是最新的
2. 使用显式等待确保元素就绪
结合WebDriverWait和ExpectedConditions等待元素状态稳定:
// Java示例:等待元素可点击且未过期
WebDriverWait wait = new WebDriverWait(driver, 10);
WebElement element = wait.until(ExpectedConditions.elementToBeClickable(By.id("dynamic-element"))
);
element.click();
3. 实现重试机制
封装重试逻辑,捕获异常后重新执行操作:
# Python示例:使用tenacity库实现重试
from tenacity import retry, stop_after_attempt, wait_fixed, retry_if_exception_type@retry(stop=stop_after_attempt(3),wait=wait_fixed(2),retry_if_exception_type=StaleElementReferenceException
)
def safe_click(element_locator):element = driver.find_element(*element_locator)element.click()# 使用示例
safe_click((By.ID, "dynamic-button"))
4. 避免长链式操作
将复杂操作拆分为独立步骤,减少元素引用的生命周期:
// 避免:长链式操作
driver.findElement(By.id("parent")).findElement(By.className("child")).click();// 推荐:分步骤执行
const parent = driver.findElement(By.id("parent"));
const child = parent.findElement(By.className("child"));
child.click(); // 每个步骤独立处理可能的异常
5. 处理动态内容加载
针对 AJAX 请求或动态渲染,使用自定义等待条件:
# 等待元素属性变化(如class变更)
def wait_for_attribute_change(element_locator, attribute, expected_value, timeout=10):start_time = time.time()while time.time() - start_time < timeout:element = driver.find_element(*element_locator)if element.get_attribute(attribute) == expected_value:return elementtime.sleep(0.5)raise TimeoutError(f"元素属性未在{timeout}秒内变化")
6. 页面跳转后刷新上下文
在页面导航后重置元素引用:
// 页面跳转后重新定位元素
String currentUrl = driver.getCurrentUrl();
driver.navigate().to("https://example.com/new-page");// 等待新页面加载完成
wait.until(ExpectedConditions.urlToBe("https://example.com/new-page"));// 重新查找元素
WebElement newElement = driver.findElement(By.id("new-element"));
三、避坑指南
- 不要忽略异常:简单的
time.sleep()无法根本解决问题,反而会增加测试执行时间。 - 避免过度重试:设置合理的重试次数(建议 3 次),防止无限循环。
- 检查元素是否在视图内:某些元素需要先滚动到可视区域才能操作:
element = driver.find_element(By.ID, "hidden-element") driver.execute_script("arguments[0].scrollIntoView();", element) - 调试技巧:在捕获异常时打印元素信息(如
element.get_attribute('outerHTML')),帮助定位问题。
四、实战案例
假设存在一个动态更新的表格,点击 "刷新" 按钮后表格内容会重新加载:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import StaleElementReferenceExceptiondriver = webdriver.Chrome()
driver.get("https://example.com/dynamic-table")# 定义元素定位器
REFRESH_BUTTON = (By.ID, "refresh-button")
TABLE_ROWS = (By.CSS_SELECTOR, "#data-table tr")# 点击刷新按钮并获取新数据
def refresh_table():wait = WebDriverWait(driver, 10)# 点击刷新按钮refresh_btn = wait.until(EC.element_to_be_clickable(REFRESH_BUTTON))refresh_btn.click()# 等待表格刷新完成(通过检查loading状态消失)wait.until(EC.invisibility_of_element_located((By.CSS_SELECTOR, ".loading-indicator")))# 重新获取表格行(避免StaleElementReferenceException)rows = wait.until(EC.presence_of_all_elements_located(TABLE_ROWS))return rows# 使用示例
rows = refresh_table()
for row in rows:print(row.text)
五、总结
处理StaleElementReferenceException的核心原则是:保持元素引用的时效性。通过重新定位、显式等待和合理的重试机制,可以有效解决 90% 以上的此类异常。在复杂场景中,建议结合页面生命周期管理和元素状态监控,构建健壮的自动化测试框架。
7.什么是同源准则?它如何影响selenium?
一、同源准则(同源策略)的定义
** 同源策略(Same-Origin Policy)** 是 Web 安全领域的核心机制之一,由浏览器实现,用于限制不同源的文档或脚本之间的交互,防止跨站请求伪造(CSRF)、跨域数据窃取等安全攻击。
核心定义:
- ** 源(Origin)** 由以下三个要素共同决定:
- 协议(Protocol):如
http、https。 - 域名(Domain):如
example.com、api.example.com。 - 端口(Port):默认端口(如 HTTP 的 80、HTTPS 的 443)可能被浏览器隐式处理,但显式端口(如
8080)会影响源的判断。
- 协议(Protocol):如
- 同源要求:两个 URL 的协议、域名、端口完全一致时,才属于同一个源,否则视为不同源。
典型场景:
- 不同协议:
http://example.com与https://example.com不同源。 - 不同域名:
example.com与sub.example.com不同源(尽管属于同一域名体系,但域名部分不同)。 - 不同端口:
http://example.com:8080与http://example.com:80不同源。
二、同源策略对 Selenium 的影响
Selenium 是用于自动化浏览器操作的工具,其行为受浏览器的同源策略限制,具体影响体现在以下方面:
1. 跨窗口 / 标签页交互限制
- 场景:当 Selenium 打开多个窗口或标签页时,若不同窗口的页面属于不同源,脚本无法直接操作其他窗口的元素或获取其数据。
- 例:窗口 A(
http://site1.com)和窗口 B(http://site2.com)不同源,Selenium 无法通过driver.switch_to.window()切换后直接读取另一窗口的 DOM 内容。
- 例:窗口 A(
- 原因:浏览器禁止不同源的窗口之间直接交互,防止数据泄露。
2. 跨域请求限制
- 场景:当 Selenium 在某个源的页面中执行 JavaScript 脚本(如
driver.execute_script()),试图向不同源的 URL 发送请求(如 AJAX)时,会触发浏览器的跨域限制(CORS 策略)。- 例:在
http://example.com的页面中通过 JS 请求http://api.example.org的数据,若目标服务器未配置 CORS 响应头(如Access-Control-Allow-Origin),请求会被浏览器阻止。
- 例:在
- 对 Selenium 的影响:
- 无法直接通过 Selenium 绕过浏览器的跨域限制,需依赖目标服务器配置 CORS 或使用其他代理机制。
- 若测试场景需要跨域请求,需提前与后端开发人员协调配置。
3. Cookie 和 LocalStorage 的隔离
- 同源策略对存储的影响:
- Cookie:不同源的页面无法读写彼此的 Cookie,除非通过
document.cookie显式操作且目标 Cookie 未设置HttpOnly属性。 - LocalStorage/SessionStorage:不同源的页面无法访问同一存储对象。
- Cookie:不同源的页面无法读写彼此的 Cookie,除非通过
- Selenium 的应用场景:
- 若测试需要在不同源之间共享 Cookie(如模拟单点登录),需通过 Selenium 手动复制 Cookie 并注入到目标页面,但需满足:
- 目标页面与源页面属于同源或目标域名是源域名的子域名(需浏览器支持
document.domain策略,现代浏览器对此限制严格)。 - Cookie 未设置
SameSite属性为Strict或Lax,且协议(如 HTTPS)符合要求。
- 目标页面与源页面属于同源或目标域名是源域名的子域名(需浏览器支持
- 若测试需要在不同源之间共享 Cookie(如模拟单点登录),需通过 Selenium 手动复制 Cookie 并注入到目标页面,但需满足:
4. iframe 跨域限制
- 场景:当页面包含
iframe标签且其源与主页面不同时,Selenium 无法直接操作iframe中的元素,需先通过driver.switch_to.frame()切换上下文。- 例:主页面(
http://main.com)嵌入http://iframe.com的iframe,若两者不同源,Selenium 切换到iframe后可能无法读取其内容,甚至抛出 “无法定位元素” 的错误。
- 例:主页面(
- 限制原因:浏览器禁止不同源的
iframe与主页面交互,防止恶意iframe窃取主页面数据。
5. 绕过同源策略的特殊情况
- 浏览器内核的特殊模式:
- 在 “无痕模式” 或 “开发者模式” 下,部分浏览器可能放宽同源策略限制,但这仅用于开发调试,不可用于生产环境的自动化测试。
- Selenium 与浏览器扩展:
- 通过浏览器扩展(如 Chrome Extension)可能间接绕过同源策略,但需扩展本身具备跨域权限(如声明
webRequest、webRequestBlocking等权限),且需与 Selenium 配合注入扩展代码。 - 此方法复杂且依赖浏览器政策,可能存在安全风险。
- 通过浏览器扩展(如 Chrome Extension)可能间接绕过同源策略,但需扩展本身具备跨域权限(如声明
三、应对同源策略限制的测试策略
- 合理设计测试用例:
- 避免在自动化测试中跨源操作,若需测试跨域功能(如 API 接口),优先使用后端测试工具(如 Postman)而非前端自动化。
- 利用浏览器开发者工具:
- 通过 Selenium 执行 JavaScript 代码,利用
window.postMessage实现跨窗口通信(需双方页面配合)。
- 通过 Selenium 执行 JavaScript 代码,利用
- 配置 CORS 响应头:
- 在开发环境中,要求后端为目标接口添加
Access-Control-Allow-Origin: *或指定允许的源,以支持跨域请求。
- 在开发环境中,要求后端为目标接口添加
- 使用代理服务器:
- 将不同源的请求转发到同一域名下,规避同源策略限制(如通过 Nginx 反向代理)。
四、总结
同源策略是浏览器保障 Web 安全的基石,Selenium 作为浏览器自动化工具,其行为必须遵循这一机制。在自动化测试中,需注意以下要点:
- 跨源操作受限:不同源的窗口、
iframe、存储数据无法直接交互,需通过合理的测试设计或后端配置规避。 - 安全与测试的平衡:避免在测试中强行绕过同源策略,以免引入安全漏洞,优先通过合法渠道(如 CORS 配置)实现跨域需求。
8.xpath中的单斜杠和双斜杠的区别
| 场景 | 单斜杠(/) | 双斜杠(//) |
|---|---|---|
| 路径起始 | 从根节点开始(绝对路径) | 从当前节点开始(相对路径) |
| 节点层级 | 只选择直接子节点 | 选择任意深度的后代节点 |
| 匹配范围 | 更精确,范围小 | 更宽泛,可能匹配多个层级的节点 |
| 性能影响 | 通常更快(路径明确) | 可能较慢(需递归遍历所有后代) |
9.appinum有哪些局限性
Appium 作为一款跨平台的自动化测试框架,虽然功能强大,但在实际应用中也存在一些局限性,主要体现在以下几个方面:
一、性能与稳定性问题
-
执行速度较慢
- Appium 通过 JSON Wire Protocol 与移动设备通信,中间存在序列化和网络传输开销,导致测试执行速度比原生测试框架(如 Android 的 Espresso 或 iOS 的 XCTest)慢 30-50%。
- 影响场景:大规模自动化测试(如全量回归测试)时耗时显著增加。
-
设备兼容性差异
- 不同品牌、型号、系统版本的设备可能存在驱动适配问题,例如:
- 部分 Android 定制 ROM(如 MIUI、EMUI)可能导致元素定位失败。
- iOS 设备需通过 WebDriverAgent 通信,在某些机型上可能出现连接不稳定。
- 应对方案:需维护多版本驱动或针对特定设备编写适配代码。
- 不同品牌、型号、系统版本的设备可能存在驱动适配问题,例如:
-
复杂 UI 交互支持有限
- 对复杂手势(如双指缩放、多点触控)的支持不够流畅,需通过组合操作模拟,例如:
# Appium 模拟双指缩放需多次操作 action1 = TouchAction(driver).press(x=100, y=100).move_to(x=200, y=200).release() action2 = TouchAction(driver).press(x=300, y=300).move_to(x=200, y=200).release() MultiAction(driver).add(action1, action2).perform() - 相比原生测试框架(如 iOS 的 XCTest 可直接调用
pinchWithScale),代码复杂度更高且可靠性较低。
- 对复杂手势(如双指缩放、多点触控)的支持不够流畅,需通过组合操作模拟,例如:
二、跨平台兼容性挑战
-
平台差异化适配成本高
- Android 和 iOS 的 UI 组件实现机制不同,同一测试用例可能需要编写两套定位逻辑:
// Android 定位方式 driver.findElement(By.id("android:id/button1"));// iOS 定位方式 driver.findElement(By.xpath("//XCUIElementTypeButton[@name='OK']")); - 需维护两份测试代码,增加开发成本。
- Android 和 iOS 的 UI 组件实现机制不同,同一测试用例可能需要编写两套定位逻辑:
-
混合应用与 WebView 支持不足
- 对于混合应用(Hybrid App)中的 WebView 元素,Appium 依赖设备浏览器内核(如 Android 的 WebView 组件),可能存在以下问题:
- 不同版本 WebView 对 JavaScript 注入支持不一致。
- 需手动切换上下文(
driver.context("WEBVIEW")),增加代码复杂度。
- 对于混合应用(Hybrid App)中的 WebView 元素,Appium 依赖设备浏览器内核(如 Android 的 WebView 组件),可能存在以下问题:
-
平台特性覆盖不全
- 部分原生功能(如 iOS 的 Face ID、Android 的指纹识别)在 Appium 中难以模拟,需通过第三方工具(如 XCTest 或 UI Automator)补充。
三、元素定位与自动化稳定性
-
动态 UI 元素定位困难
- 对于动态生成的元素(如加载中的进度条、动画元素),Appium 的隐式等待机制可能失效,需额外编写复杂的等待逻辑:
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as ECelement = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, 'dynamicElement')) )
- 对于动态生成的元素(如加载中的进度条、动画元素),Appium 的隐式等待机制可能失效,需额外编写复杂的等待逻辑:
-
复杂布局下的定位失败
- 在嵌套层级深、元素重叠的场景(如复杂表单、滑动控件)中,Appium 的坐标定位可能不准确,需结合多种定位策略(如 XPath、Accessibility ID)。
-
iOS 系统限制
- Apple 的安全机制导致 Appium 在 iOS 上的权限受限,例如:
- 无法直接访问应用沙盒内的文件。
- 部分系统级操作(如修改网络设置)需通过 XCTest 扩展实现。
- Apple 的安全机制导致 Appium 在 iOS 上的权限受限,例如:
四、并行测试与分布式执行瓶颈
-
设备管理复杂度高
- Appium 原生不支持多设备并行测试,需借助第三方工具(如 Appium Grid、TestNG)实现,但配置复杂:
// TestNG 配置多设备并行 <suite name="Parallel Tests" parallel="tests" thread-count="2"><test name="Android Test"><parameter name="deviceName" value="AndroidEmulator"/>...</test><test name="iOS Test"><parameter name="deviceName" value="iPhoneSimulator"/>...</test> </suite>
- Appium 原生不支持多设备并行测试,需借助第三方工具(如 Appium Grid、TestNG)实现,但配置复杂:
-
资源消耗大
- 每个 Appium 会话需独立启动 WebDriverAgent(iOS)或 UIAutomator2(Android)服务,占用大量系统资源,限制了单机可同时运行的设备数量(通常不超过 4-6 台)。
五、与 CI/CD 集成的局限性
-
环境配置复杂
- Appium 依赖 Java、Node.js、Android SDK、Xcode 等多环境,CI/CD 环境搭建成本高,例如:
# GitHub Actions 配置 Appium 环境 - name: Set up Javauses: actions/setup-java@v3with:java-version: '11' - name: Install Node.jsuses: actions/setup-node@v3with:node-version: '16' - name: Install Appiumrun: npm install -g appium
- Appium 依赖 Java、Node.js、Android SDK、Xcode 等多环境,CI/CD 环境搭建成本高,例如:
-
测试报告不够直观
- Appium 原生报告(如 JSON 格式)可读性差,需集成 Allure 等第三方工具生成可视化报告,但配置过程繁琐。
六、安全与隐私限制
-
敏感信息处理风险
- Appium 测试过程中可能暴露设备日志、网络请求等敏感信息,需额外配置数据脱敏和加密机制。
-
企业级应用适配困难
- 对于采用安全沙箱、代码混淆或反调试技术的企业应用,Appium 可能因无法获取 UI 元素信息而失效。
七、替代方案与补充策略
-
混合测试框架
- 结合 Appium 与原生测试框架(如 Android 的 Espresso),关键流程用原生框架保证稳定性,次要流程用 Appium 跨平台覆盖。
-
UI 自动化工具链组合
- 复杂场景使用 Appium + 图像识别工具(如 OpenCV、Appium 的 Image Element)提升定位准确性。
-
性能监控工具补充
- 集成 Android Profiler 或 Xcode Instruments 监控性能,弥补 Appium 在性能测试方面的不足。
10.原生、混合、web移动应用分别指什么应用
在移动应用开发领域,根据技术架构和运行环境的不同,通常将应用分为 原生应用(Native App)、混合应用(Hybrid App) 和 Web 应用(Web App)。以下是三者的具体定义、特点及对比:
一、原生应用(Native App)
定义:
使用移动设备操作系统(iOS/Android)的原生开发语言和工具开发的应用,直接运行在设备系统层上。
- iOS:使用 Swift 或 Objective-C,搭配 Xcode 开发工具。
- Android:使用 Kotlin 或 Java,搭配 Android Studio 开发工具。
核心特点:
- 性能优秀:直接调用系统底层 API,响应速度快,支持复杂动画、图形渲染(如游戏、视频编辑类应用)。
- 功能强大:可无缝访问设备硬件(摄像头、GPS、蓝牙、传感器等)和系统特性(通知栏、文件系统)。
- 用户体验佳:遵循系统设计规范(如 iOS 的 Human Interface Guidelines、Android 的 Material Design),交互流畅,界面适配性好。
- 开发成本高:需为 iOS 和 Android 分别开发,维护两套代码,人力和时间成本较高。
- 发布流程复杂:需通过应用商店(App Store/Google Play)审核,更新需用户主动下载安装包。
典型场景:
对性能、体验要求高的应用,如大型游戏(《王者荣耀》)、金融类 App(银行客户端)、高频工具类应用(相机、地图)。
二、混合应用(Hybrid App)
定义:
结合 原生开发 和 Web 技术 的应用,核心逻辑用 HTML5、CSS、JavaScript 编写,通过 原生容器(如 WebView) 嵌入原生应用中,部分功能通过桥梁(Bridge)调用原生 API。
核心特点:
- 跨平台开发:一套代码适配多平台(iOS/Android),节省开发成本(如使用 Ionic、React Native 等框架)。
- 性能折中:依赖 WebView 渲染,流畅度略低于原生应用,复杂交互可能出现卡顿。
- 功能扩展性:通过原生桥梁(如 Cordova/PhoneGap)可调用部分设备功能(摄像头、定位),但需原生代码支持。
- 更新灵活:无需通过应用商店审核,可直接推送 Web 内容更新(如修复页面显示问题)。
- 维护成本低:业务逻辑集中在 Web 层,原生层仅需维护基础容器。
典型场景:
功能中等复杂、需快速迭代的应用,如企业内部系统(OA)、资讯类 App(新闻客户端)、中小规模电商应用。
三、Web 应用(Web App)
定义:
基于 Web 技术(HTML5、CSS、JavaScript) 开发的应用,运行在移动设备的 浏览器 中,本质是响应式网页,无需下载安装。
核心特点:
- 纯 Web 技术栈:开发成本极低,一套代码适配所有设备(手机、平板、PC)。
- 无需安装:通过 URL 访问(如移动端网站),用户无需占用设备存储空间。
- 性能受限:完全依赖浏览器渲染,复杂操作易卡顿,无法离线使用(需配合 Service Worker 实现离线缓存)。
- 功能受限:无法直接访问设备硬件,需通过浏览器 API(如 Geolocation、Camera API)实现有限功能,兼容性依赖浏览器支持。
- 更新即时:修改代码后直接发布,用户访问时自动获取最新版本。
典型场景:
轻量级应用、临时项目或营销页面,如活动 H5、简易工具(汇率计算器)、企业官网移动端。
四、三者对比表格
| 维度 | 原生应用 | 混合应用 | Web 应用 |
|---|---|---|---|
| 开发语言 | Swift/Objective-C(iOS)、Kotlin/Java(Android) | HTML5/CSS/JS + 原生桥梁(如 React Native) | HTML5/CSS/JS |
| 跨平台性 | 需分别开发 | 一套代码适配多平台 | 天然跨平台(浏览器兼容) |
| 性能 | 最高(直接调用系统资源) | 中等(依赖 WebView 性能) | 最低(受限于浏览器渲染) |
| 功能扩展性 | 强(全面访问硬件 / 系统) | 中等(需原生桥梁支持) | 弱(依赖浏览器 API) |
| 用户体验 | 优(系统级交互) | 中等(接近原生,但可能卡顿) | 一般(受限于浏览器特性) |
| 更新成本 | 高(需应用商店审核) | 低(Web 内容可热更新) | 即时(无需用户操作) |
| 典型案例 | 微信、支付宝、抖音 | 淘宝、京东(部分模块混合) | 手机百度、微博移动端网站 |
五、如何选择?
- 优先选原生:追求极致性能和体验,或需深度调用设备功能(如 AR/VR、高帧率游戏)。
- 优先选混合:需跨平台开发,且功能复杂度中等(如电商、社交类应用)。
- 优先选 Web:轻量级需求、快速迭代或临时项目,无需安装即可访问。
实际开发中,也可采用 渐进式策略(如 “原生容器 + Web 内核”),平衡性能与开发效率。
11.编写appinum测试的基本步骤
以下是使用 Appium 进行移动应用自动化测试的基本步骤,结合环境搭建、测试脚本编写和执行流程:
一、环境搭建
1. 安装 Appium Server
-
方式一:使用 Appium Desktop(推荐)
- 下载地址:Appium Desktop
- 启动后可通过 GUI 配置参数(如端口、日志级别)。
-
方式二:通过 npm 安装(需先安装 Node.js)
npm install -g appium appium -p 4723 # 启动Appium服务
2. 安装 Appium Python Client(以 Python 为例)
pip install Appium-Python-Client
3. 配置移动设备环境
-
真机:
- Android:开启 USB 调试模式,安装对应 SDK(如 Android Studio)。
- iOS:安装 Xcode,注册开发者账号,配置设备 UDID。
-
模拟器 / 虚拟机:
- Android:使用 Android Studio 的 AVD Manager 创建虚拟设备。
- iOS:使用 Xcode 自带的 Simulator。
二、准备测试应用
- 获取被测应用的 APK(Android)或 IPA(iOS)文件。
- 确认应用的包名(Package)和启动 Activity(Android)或 Bundle ID(iOS):
- Android:通过
aapt dump badging app.apk命令查看。 - iOS:通常为
com.example.app格式,可从 Xcode 项目中获取。
- Android:通过
三、编写测试脚本
以下是一个基本的 Appium 测试脚本示例(Python):
from appium import webdriver
import time# 配置参数
desired_caps = {"platformName": "Android", # 平台类型(iOS/Android)"platformVersion": "11", # 系统版本"deviceName": "emulator-5554", # 设备名称(可通过adb devices查看)"appPackage": "com.example.app", # 应用包名"appActivity": ".MainActivity", # 启动Activity"app": "/path/to/app.apk", # APK文件路径(本地或远程URL)"noReset": True, # 不重置应用状态,加快测试速度"newCommandTimeout": 600 # 命令超时时间(秒)
}# 连接Appium Server
driver = webdriver.Remote('http://localhost:4723/wd/hub', desired_caps)try:# 测试步骤# 1. 等待元素出现并点击login_button = driver.find_element_by_id("com.example.app:id/login_button")login_button.click()# 2. 输入用户名和密码username_input = driver.find_element_by_id("com.example.app:id/username")password_input = driver.find_element_by_id("com.example.app:id/password")username_input.send_keys("test_user")password_input.send_keys("test_password")# 3. 提交登录submit_button = driver.find_element_by_id("com.example.app:id/submit")submit_button.click()# 4. 验证登录成功(等待特定元素出现)time.sleep(2) # 简单等待,实际应使用显式等待welcome_text = driver.find_element_by_id("com.example.app:id/welcome_message")assert welcome_text.text == "欢迎回来,测试用户"except Exception as e:print(f"测试失败: {e}")
finally:# 退出驱动driver.quit()
四、元素定位技巧
-
使用 Appium Inspector:
- 启动 Appium Desktop,点击 "Start Inspector Session"。
- 配置
desired_caps后连接设备 / 模拟器,获取元素的 ID、XPath 等信息。
-
常用定位方式:
- ID:
driver.find_element_by_id("element_id") - XPath:
driver.find_element_by_xpath("//android.widget.TextView[@text='登录']") - Class Name:
driver.find_element_by_class_name("android.widget.Button") - Accessibility ID:
driver.find_element_by_accessibility_id("button_label")
- ID:
五、执行测试
-
启动 Appium Server:
- 若使用 Appium Desktop,点击 "Start Server"。
- 若使用命令行,确保
appium服务已启动。
-
运行测试脚本:
python test_script.py
- 查看测试结果:
- 控制台输出测试执行日志。
- 可集成 Allure 等工具生成可视化测试报告:
# 安装Allure pip install allure-pytest# 生成报告 pytest --alluredir=./results allure serve ./results
六、最佳实践
-
使用显式等待:
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC# 等待元素可点击(最多10秒) element = WebDriverWait(driver, 10).until(EC.element_to_be_clickable(("id", "element_id")) ) -
处理常见异常:
NoSuchElementException:元素未找到,需检查定位表达式或添加等待。StaleElementReferenceException:元素状态过期,需重新定位。
-
封装公共方法:
def login(username, password):driver.find_element_by_id("username").send_keys(username)driver.find_element_by_id("password").send_keys(password)driver.find_element_by_id("login").click() -
参数化测试:
import pytest@pytest.mark.parametrize("username, password, expected", [("valid_user", "valid_pass", "登录成功"),("invalid_user", "wrong_pass", "登录失败"), ]) def test_login(username, password, expected):login(username, password)assert driver.find_element_by_id("message").text == expected
七、常见问题与解决方案
-
Appium Server 连接失败:
- 检查端口是否被占用(默认 4723)。
- 确认设备已通过 USB 连接或模拟器已启动。
-
元素定位失败:
- 使用 Appium Inspector 重新获取元素信息。
- 检查应用是否有动态加载内容,添加适当等待。
-
iOS 测试需要开发者证书:
- 配置 Xcode 开发环境,获取开发者账号和证书。
- 在
desired_caps中添加udid和xcodeOrgId等参数。
通过以上步骤,你可以完成 Appium 自动化测试的基本流程。实际项目中,建议结合测试框架(如 Pytest)和 CI/CD 工具(如 Jenkins)实现更高效的自动化测试。
12.执行appinum测试时需要在项目路径下有.apk文件吗
在执行 Appium 测试时,是否需要在项目路径下放置 .apk 文件(Android 应用包)或 .ipa 文件(iOS 应用包)取决于你的测试环境和配置方式。以下是几种常见场景及对应要求:
一、本地设备 / 模拟器测试
1. 需要应用包的情况
- 场景:测试未安装的应用或需要频繁重新安装应用(如测试安装流程、验证应用更新)。
- 配置要求:
- 必须指定
appcapability,值为本地.apk或.ipa文件的绝对路径。 - 文件位置:应用包可以放在任意路径,但需确保 Appium 服务器有权限访问(例如,避免放在系统受保护目录)。
- 必须指定
// Java示例:指定本地.apk文件路径
DesiredCapabilities caps = new DesiredCapabilities();
caps.setCapability("app", "/path/to/your/app.apk"); // 绝对路径
2. 不需要应用包的情况
- 场景:测试已安装在设备上的应用(如生产环境应用)。
- 配置要求:
- 使用
appPackage和appActivity(Android) 或bundleId(iOS)指定应用的包名和启动 Activity/Bundle ID。 - 设备必须已安装目标应用,否则会抛出 “无法启动应用” 的错误。
- 使用
// Android示例:测试已安装应用
DesiredCapabilities caps = new DesiredCapabilities();
caps.setCapability("appPackage", "com.example.app");
caps.setCapability("appActivity", "com.example.app.MainActivity");
caps.setCapability("noReset", true); // 不重置应用状态
二、云端测试平台(如 Sauce Labs、AWS Device Farm)
1. 需要预先上传应用包
- 流程:
- 将
.apk或.ipa文件上传至云端平台。 - 通过平台提供的 API 或界面获取应用包的唯一标识符(如
app-url)。 - 在测试配置中使用该标识符代替本地路径。
- 将
# Python示例:使用Sauce Labs云端应用
desired_caps = {'app': 'sauce-storage:your-app.apk', # Sauce Labs存储的应用标识符'platformName': 'Android','deviceName': 'Android Emulator'
}
2. 无需本地保存应用包
- 优势:避免在本地维护多个版本的应用包,尤其适合团队协作场景。
- 注意:需确保云端平台的应用包版本与测试代码兼容。
三、持续集成 / 自动化部署(CI/CD)场景
1. 从构建产物获取应用包
- 典型流程:
- CI 工具(如 Jenkins、GitHub Actions)编译生成
.apk文件。 - Appium 测试任务从构建输出目录读取应用包路径。
- CI 工具(如 Jenkins、GitHub Actions)编译生成
# GitHub Actions示例:使用构建产物
jobs:test:steps:- name: Build APKrun: ./gradlew assembleDebug # 编译生成APK- name: Run Appium Testrun: pytest tests/ # 测试脚本中引用生成的APK路径
2. 缓存应用包以提高效率
- 优化策略:对于频繁执行的测试,可将应用包缓存到 CI 环境中,避免重复构建。
四、常见误区与注意事项
-
混淆
app和appPackage- 错误配置:同时设置
app和appPackage,可能导致 Appium 优先使用app并重新安装应用。 - 正确做法:
- 测试未安装应用 → 使用
app。 - 测试已安装应用 → 使用
appPackage+appActivity/bundleId。
- 测试未安装应用 → 使用
- 错误配置:同时设置
-
文件路径问题
- 相对路径风险:在 CI 环境或不同机器上,相对路径可能指向错误位置,建议使用绝对路径或环境变量。
- 示例:
import os app_path = os.path.abspath("app/app.apk") # 基于项目根目录的相对路径转为绝对路径
-
性能考虑
- 频繁重新安装应用(通过
app配置)会显著增加测试时间,建议在非必要场景使用noReset或fullReset控制应用状态。
- 频繁重新安装应用(通过
五、总结
是否需要 .apk 文件取决于测试策略:
- 需要文件的场景:本地安装测试、应用更新测试、云端测试平台、CI/CD 自动化构建。
- 不需要文件的场景:仅测试已安装应用、使用设备农场的预安装应用。
建议根据项目需求选择合适的方式,并通过版本控制工具(如 Git)管理应用包(若需要)。对于大型项目,考虑将应用包存储在制品库(如 Artifactory)中,避免直接提交到代码仓库。
13.appinum iOS应用的重置策略是什么
在 Appium 中测试 iOS 应用时,重置策略(Reset Strategy)直接影响测试前后应用的状态,合理配置可提高测试稳定性和效率。以下是 iOS 应用的主要重置策略及其使用场景:
一、核心重置参数
在desired_caps中,与 iOS 重置相关的关键参数有:
| 参数名 | 类型 | 描述 |
|---|---|---|
noReset | Boolean | 不重置应用状态(默认false)。✅ 保留应用数据和缓存(如登录状态)。 ⚠️ 可能导致测试间数据污染。 |
fullReset | Boolean | 完全重置应用(默认false)。✅ 每次测试后删除应用并重新安装,清除所有数据。 ⚠️ 测试耗时增加。 |
resetOnSessionStartOnly | Boolean | 仅在会话开始时重置(默认true)。✅ 多个测试用例共享一个会话时,避免重复重置。 |
shouldUseSingletonTestManager | Boolean | 是否使用单例测试管理器(默认true)。✅ 提升测试执行速度。 ⚠️ 可能影响重置效果。 |
二、重置策略组合与应用场景
1. 快速测试(保留状态)
desired_caps = {"platformName": "iOS","deviceName": "iPhone 14","platformVersion": "16.4","app": "/path/to/app.ipa","noReset": True, # 不重置应用"fullReset": False,"autoAcceptAlerts": True # 自动处理弹窗(如权限请求)
}
适用场景:
- 功能验证(如登录后操作),需保留登录状态。
- 冒烟测试,快速验证核心流程。
优点:测试速度快,无需重复安装应用。
缺点:需手动清理测试数据,可能导致用例间干扰。
2. 彻底隔离(每次测试重置)
desired_caps = {"platformName": "iOS","deviceName": "iPhone 14","platformVersion": "16.4","app": "/path/to/app.ipa","noReset": False, # 重置应用"fullReset": True, # 完全重置(删除并重装)"autoGrantPermissions": True # 自动授予权限
}
适用场景:
- 新安装流程测试(如首次启动引导页)。
- 数据敏感测试(如支付流程,确保账户干净)。
优点:测试环境完全隔离,结果可靠。
缺点:每次测试需重新安装应用,耗时较长(约 30-60 秒)。
3. 混合策略(会话级重置)
desired_caps = {"platformName": "iOS","deviceName": "iPhone 14","platformVersion": "16.4","app": "/path/to/app.ipa","noReset": True,"fullReset": False,"resetOnSessionStartOnly": True, # 仅会话开始时重置"newCommandTimeout": 300 # 延长会话超时时间
}
适用场景:
- 批量执行多个用例,共享一个 Appium 会话。
- 测试套件需保持一致的初始状态(如所有用例前登录一次)。
优点:平衡测试速度与环境隔离,适合持续集成。
三、iOS 特有重置注意事项
1. 权限管理
- 自动处理权限:
desired_caps = {"autoAcceptAlerts": True, # 自动接受所有弹窗"autoGrantPermissions": True # 自动授予所有权限(iOS 10+) } - 手动处理权限弹窗:
try:# 定位"允许"按钮(iOS可能使用不同文案)allow_button = WebDriverWait(driver, 10).until(EC.element_to_be_clickable(("xpath", "//*[contains(@name, '允许')]")))allow_button.click() except:pass # 无权限弹窗时忽略
2. 应用状态清理
对于noReset=True的场景,需在测试后手动清理数据:
def teardown(self):# 退出登录(示例)driver.find_element_by_accessibility_id("设置").click()driver.find_element_by_accessibility_id("退出登录").click()# 清除缓存(如有API)requests.post("https://api.example.com/clear-cache?userId=123")
3. Simulator vs 真机
- Simulator:
- 支持快速重置(无需重新安装应用)。
- 可通过
simctl命令清除数据:bash
xcrun simctl erase all # 清除所有Simulator数据
- 真机:
fullReset会真正删除并重装应用,耗时较长。- 建议优先在 Simulator 上执行高频测试,真机上执行关键路径验证。
四、性能优化建议
-
减少不必要的重置:
- 对独立用例使用
noReset=True,仅在必要时手动清理数据。 - 通过
beforeEach/afterEach钩子处理用例间状态。
- 对独立用例使用
-
缓存应用安装:
- 首次安装应用后,使用
noReset=True避免重复安装:# 首次安装 desired_caps["fullReset"] = True driver = webdriver.Remote(...)# 后续测试复用已安装的应用 desired_caps["fullReset"] = False desired_caps["noReset"] = True
- 首次安装应用后,使用
-
并行测试:
- 使用 Appium 的多会话功能,在不同设备 / 模拟器上并行执行测试:
# 启动多个会话(示例) def test_parallel():threads = []for device in ["iPhone 14", "iPad Pro"]:t = threading.Thread(target=run_test, args=(device,))threads.append(t)t.start()
- 使用 Appium 的多会话功能,在不同设备 / 模拟器上并行执行测试:
五、常见问题与解决方案
| 问题 | 解决方案 |
|---|---|
| 测试后应用未重置 | 检查fullReset是否为true,并确认 Appium 有足够权限删除应用。 |
| 权限弹窗未自动处理 | 使用autoAcceptAlerts或autoGrantPermissions,或手动定位弹窗元素。 |
| 测试速度过慢 | 改用noReset=True并手动清理数据,或在 Simulator 上测试。 |
| 真机测试时证书失效 | 确保开发者证书有效,或使用 TestFlight 版本进行测试。 |
通过合理配置重置策略,可在测试效率与可靠性之间找到平衡点,尤其在 iOS 环境中需注意权限管理和设备特性差异。
14.接口测试的主要难点有哪些
接口测试是验证系统组件间交互的重要手段,但由于接口类型多样、依赖复杂及运行环境差异,在实施过程中存在诸多难点。以下是主要挑战及应对策略:
一、依赖管理与环境隔离
难点:
-
外部服务依赖
- 接口可能依赖第三方服务(如支付网关、短信平台),测试时难以模拟其真实响应。
- 示例:调用微信支付 API 进行测试时,生产环境的支付操作会产生真实交易。
-
数据状态一致性
- 接口测试可能影响数据库状态,导致测试结果不可重复。
- 示例:多次执行订单创建接口会生成重复数据,干扰后续测试。
应对策略:
- 服务 mock:使用工具(如 WireMock、Mockito)模拟外部服务响应。
// Mock HTTP响应示例(WireMock) stubFor(get(urlEqualTo("/api/payment")).willReturn(aResponse().withStatus(200).withBody("{\"status\":\"success\"}"))); - 测试数据隔离:使用数据库事务回滚、测试专用环境或数据快照恢复测试数据。
二、参数组合爆炸
难点:
- 接口参数的不同组合可能导致海量测试用例。
示例:一个包含 3 个可选参数(每个参数 3 种取值)的接口,理论上有 33=27 种组合。
应对策略:
- 正交试验法:选择部分代表性参数组合覆盖主要场景。
- 自动化测试框架:使用工具(如 Pytest 的 parametrize)自动生成参数组合。
@pytest.mark.parametrize("username, password, expected", [("valid", "valid", 200),("invalid", "valid", 401),("valid", "invalid", 401), ]) def test_login(username, password, expected):response = requests.post("/login", json={"username": username, "password": password})assert response.status_code == expected
三、异步处理与定时任务
难点:
-
异步响应验证
- 接口返回的是处理中状态,实际结果通过消息队列或回调通知。
示例:文件上传接口返回 “处理中”,需轮询查询结果接口。
- 接口返回的是处理中状态,实际结果通过消息队列或回调通知。
-
定时任务验证
- 某些业务逻辑依赖定时任务(如每日结算),测试周期长。
应对策略:
- 消息队列监听:在测试代码中订阅消息队列,验证异步处理结果。
- 时间旅行技术:修改系统时钟或触发定时任务的执行(如通过测试专用接口)。
四、幂等性与并发测试
难点:
-
幂等性验证
- 重复调用同一接口需确保不会产生副作用,但验证逻辑复杂。
示例:多次调用 “订单支付” 接口,需确保只扣款一次。
- 重复调用同一接口需确保不会产生副作用,但验证逻辑复杂。
-
并发场景模拟
- 传统测试工具难以模拟高并发,可能遗漏线程安全问题。
应对策略:
- 幂等性测试用例:设计重复调用接口的测试,验证结果一致性。
- 并发测试工具:使用 JMeter、Gatling 模拟多用户并发请求。
// JMeter Java DSL并发测试示例 JMeterTestPlan.testPlan(threadGroup(10, 100, // 10个线程,每个线程执行100次httpSampler("https://api.example.com/order")) ).run();
五、认证与授权复杂性
难点:
-
动态令牌管理
- OAuth2.0、JWT 等认证方式需要在测试中动态获取和刷新令牌。
-
权限边界测试
- 验证不同角色用户对接口的访问权限,需准备多套测试账号。
应对策略:
- 令牌自动化获取:在测试框架中集成认证流程,自动刷新令牌。
def get_token():response = requests.post("/auth", json={"username": "test", "password": "test"})return response.json()["token"]def test_protected_api():token = get_token()headers = {"Authorization": f"Bearer {token}"}response = requests.get("/protected", headers=headers)assert response.status_code == 200 - RBAC 模型验证:通过自动化脚本批量验证角色权限矩阵。
六、数据验证与断言复杂性
难点:
-
动态数据处理
- 接口返回的部分数据(如时间戳、流水号)是动态变化的,无法直接断言。
-
复杂业务规则验证
- 响应数据需符合复杂的业务逻辑(如金额计算、数据关联)。
应对策略:
- 忽略动态字段:使用工具(如 JSONPath)提取关键字段进行断言。
response = requests.get("/order/123") assert response.json()["status"] == "paid" # 验证关键字段 - 业务规则抽象:将复杂验证逻辑封装为独立组件(如金额计算器)。
七、错误处理与异常覆盖
难点:
-
异常场景覆盖不全
- 测试用例易忽略边界条件(如空值、超长字符串、非法格式)。
-
错误码一致性
- 不同接口的错误码和错误信息需保持统一规范。
应对策略:
- 边界值分析:针对输入参数设计边界测试用例(如最小值、最大值、空值)。
- 错误码自动校验:编写脚本扫描接口文档和代码,确保错误码规范一致。
八、性能与稳定性测试
难点:
-
性能指标定义模糊
- 缺乏明确的响应时间、吞吐量阈值,难以判断是否达标。
-
资源泄漏检测
- 长时间运行测试可能暴露内存泄漏、连接未释放等问题。
应对策略:
- 性能基准建立:通过压测工具(如 LoadRunner)确定接口性能基线。
- 监控与告警集成:在测试过程中实时监控系统资源(CPU、内存、连接数)。
九、跨版本兼容性
难点:
- 接口升级时需保证旧版本客户端的兼容性,但测试成本高。
示例:API 从 v1 升级到 v2,需同时支持新旧客户端调用。
应对策略:
- 契约测试(Consumer-Driven Contract):使用工具(如 Pact)确保服务提供者不破坏现有契约。
- 灰度发布验证:在生产环境小流量验证新版本接口兼容性。
十、测试工具与框架选择
难点:
- 工具生态复杂,需根据接口类型(REST、SOAP、RPC)选择合适的测试框架。
示例:测试 gRPC 接口需使用专门的工具(如 BloomRPC)。
应对策略:
- 分层测试工具链:根据接口类型组合使用工具(如 Postman、REST Assured、grpcurl)。
- 测试框架统一:在团队内建立标准化测试框架,减少工具学习成本。
总结
接口测试的难点主要源于系统复杂性、环境依赖性和质量标准多样性。应对策略需从自动化框架建设、测试数据管理、工具链集成三方面入手,通过分层测试(单元测试、集成测试、端到端测试)覆盖不同维度的质量风险,最终实现高效、稳定的接口测试体系。
15.如果封装了requests请求库,发送请求后如何获取响应报文?
当封装了requests库发送 HTTP 请求后,获取响应报文的方式取决于你封装的具体实现。以下是常见的处理方式和最佳实践:
一、基础响应获取方式
在封装层返回原始requests.Response对象,调用者可直接访问其属性:
import requestsclass APIClient:def __init__(self, base_url):self.base_url = base_urldef send_request(self, method, endpoint, **kwargs):url = f"{self.base_url}{endpoint}"response = requests.request(method, url, **kwargs)return response # 返回原始响应对象# 使用示例
client = APIClient("https://api.example.com")
response = client.send_request("GET", "/users/1")# 获取响应内容
print(response.status_code) # 状态码
print(response.text) # 文本格式
print(response.json()) # JSON格式(自动解析)
print(response.headers) # 响应头
print(response.request.headers) # 请求头
print(response.elapsed.total_seconds()) # 请求耗时
二、封装层处理响应
在封装层直接解析响应并返回特定格式:
class APIClient:def send_request(self, method, endpoint, **kwargs):response = requests.request(method, url, **kwargs)# 检查状态码if response.status_code in (200, 201):try:return {"success": True, "data": response.json()}except ValueError:return {"success": True, "data": response.text}else:return {"success": False, "error": f"HTTP {response.status_code}","details": response.text}# 使用示例
result = client.send_request("GET", "/users/1")
if result["success"]:print(result["data"])
else:print(result["error"])
三、获取完整响应报文(含头信息)
若需获取原始 HTTP 响应报文(包括状态行和头信息),可使用以下方法:
1. 手动拼接(简单但不完整)
def get_raw_response(response):headers = "\n".join([f"{k}: {v}" for k, v in response.headers.items()])return f"{response.status_code} {response.reason}\n{headers}\n\n{response.text}"# 使用示例
raw_response = get_raw_response(response)
print(raw_response)
2. 使用 HTTPAdapter(完整但复杂)
通过自定义适配器捕获原始套接字数据:
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.response import HTTPResponseclass CaptureAdapter(HTTPAdapter):def build_response(self, req, resp):response = super().build_response(req, resp)# 获取原始响应数据response.raw_data = resp.data # 二进制响应数据return response# 注册适配器
session = requests.Session()
session.mount("https://", CaptureAdapter())# 发送请求
response = session.get("https://api.example.com")
print(response.raw_data.decode("utf-8")) # 完整响应报文
四、异步请求处理(使用 aiohttp)
若封装的是异步请求,响应获取方式类似:
import aiohttpclass AsyncAPIClient:async def send_request(self, method, url, **kwargs):async with aiohttp.ClientSession() as session:async with session.request(method, url, **kwargs) as response:# 获取响应内容text = await response.text()json_data = await response.json() # 异步解析JSONreturn {"status": response.status,"headers": dict(response.headers),"text": text,"json": json_data}# 使用示例
async def main():client = AsyncAPIClient()result = await client.send_request("GET", "https://api.example.com/users/1")print(result["json"])
五、最佳实践建议
-
保持响应对象的可访问性:
在封装层返回原始Response对象或包含关键信息的字典,避免过度抽象导致信息丢失。 -
统一异常处理:
在封装层捕获网络异常(如requests.exceptions.RequestException),并转换为自定义异常:try:response = requests.get(url)response.raise_for_status() # 自动检查状态码 except requests.exceptions.Timeout:raise CustomTimeoutError("请求超时") except requests.exceptions.HTTPError as e:raise APIError(f"API错误: {e}") -
日志记录:
记录请求和响应的关键信息(URL、状态码、耗时),便于调试:import logginglogger = logging.getLogger(__name__)def send_request(self, method, endpoint, **kwargs):start_time = time.time()response = requests.request(method, url, **kwargs)elapsed = time.time() - start_timelogger.info(f"{method} {endpoint} - {response.status_code} ({elapsed:.2f}s)")return response
六、常见问题与解决方案
| 问题 | 解决方案 |
|---|---|
| 响应内容乱码 | 指定正确的编码:response.encoding = 'utf-8' 或使用response.content.decode('utf-8') |
| JSON 解析失败 | 先检查响应类型:if response.headers.get('Content-Type') == 'application/json' |
| 大文件下载内存溢出 | 使用流式响应:response = requests.get(url, stream=True) 并逐块处理 |
| 响应包含二进制数据 | 使用response.content获取原始字节数据,如图片、文件 |
16.selenium如何判断某个元素一定存在
在 Selenium 中判断元素是否存在是自动化测试的常见需求,但需注意 Selenium 本身的设计哲学是 “如果元素不存在,操作会抛出异常”。因此,判断元素存在需要通过显式等待或异常处理机制实现。以下是几种常见方法及适用场景:
一、使用显式等待(推荐方式)
核心思想:设置最大等待时间,轮询检查元素是否出现。若超时仍未出现,则判定元素不存在。
1. 等待元素存在(Presence)
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECdriver = webdriver.Chrome()
try:# 等待元素存在(最多10秒)element = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "targetElement")))print("元素存在")
except Exception as e:print("元素不存在或超时")
finally:driver.quit()
2. 等待元素可见(Visibility)
存在≠可见。某些元素可能已加载到 DOM 中,但由于 CSS 属性(如display: none)不可见。
try:# 等待元素可见(最多10秒)element = WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.ID, "targetElement")))print("元素可见")
except:print("元素不可见或不存在")
3. 自定义等待条件
对于复杂场景(如元素数量、属性值),可自定义等待条件:
class element_count_to_be:def __init__(self, locator, count):self.locator = locatorself.count = countdef __call__(self, driver):elements = driver.find_elements(*self.locator)return len(elements) == self.count# 等待恰好存在3个匹配的元素
try:WebDriverWait(driver, 10).until(element_count_to_be((By.CSS_SELECTOR, "div.item"), 3))print("存在3个元素")
except:print("元素数量不符合预期")
二、直接查找并捕获异常
核心思想:使用find_element方法尝试定位元素,若抛出NoSuchElementException则判定元素不存在。
1. 基础实现
from selenium.common.exceptions import NoSuchElementExceptiontry:element = driver.find_element(By.ID, "targetElement")print("元素存在")
except NoSuchElementException:print("元素不存在")
2. 封装为工具方法
def is_element_present(driver, by, value):try:driver.find_element(by, value)return Trueexcept NoSuchElementException:return False# 使用示例
if is_element_present(driver, By.ID, "targetElement"):print("元素存在")
else:print("元素不存在")
注意:此方法不推荐用于生产环境,因为 Selenium 的默认行为是立即查找元素(隐式等待为 0 时),可能导致误判。建议结合隐式等待使用,但需注意与显式等待混用可能引发意外问题。
三、使用 find_elements 替代 find_element
核心思想:find_elements方法不会抛出异常,若返回空列表则表示元素不存在。
elements = driver.find_elements(By.ID, "targetElement")
if len(elements) > 0:print("元素存在")# 使用elements[0]操作第一个匹配的元素
else:print("元素不存在")
优点:简洁高效,无需异常处理。
缺点:无法设置等待时间,若元素加载较慢可能误判。
四、判断元素存在的常见误区
-
混淆 “存在” 与 “可用”
- 元素存在≠可交互。例如,按钮可能存在但处于禁用状态(
disabled属性)。 - 验证方法:使用
EC.element_to_be_clickable。
- 元素存在≠可交互。例如,按钮可能存在但处于禁用状态(
-
隐式等待与显式等待混用
- 同时设置隐式等待和显式等待可能导致超时时间计算异常。
- 最佳实践:优先使用显式等待,避免全局隐式等待。
-
忽略 iframe / 窗口切换
- 若元素位于 iframe 中,需先切换到对应 iframe 才能定位。
# 切换到iframe iframe = driver.find_element(By.ID, "myFrame") driver.switch_to.frame(iframe) # 查找iframe内的元素
五、性能优化建议
-
合理设置超时时间
- 对于关键元素(如登录按钮),可设置较长超时时间(如 10-30 秒)。
- 对于辅助元素(如提示信息),可设置较短超时时间(如 2-5 秒)。
-
使用复合条件减少等待次数
# 同时等待元素可见且可点击 WebDriverWait(driver, 10).until(EC.and_(EC.visibility_of_element_located((By.ID, "submitBtn")),EC.element_to_be_clickable((By.ID, "submitBtn"))) ) -
并行检查多个元素
- 对于需要同时验证多个元素的场景,可使用多线程或异步方式并行检查。
六、总结
推荐方案优先级:
- 显式等待 + EC 条件(灵活且可定制超时)。
- find_elements + 列表长度判断(简洁但无等待机制)。
- 异常捕获(仅适用于简单场景或已设置隐式等待)。
使用jenkins持续集成的步骤
自动化测试 Pytest+Allure+Jenkins 持续集成(超详细)_pytest+jenkins+allure-CSDN博客
使用gitlab ci持续集成的步骤
搭建基于Pytest+Selenium+Allure+Gitlab-ci的一键自动化测试流程 - 简书
selenium+allure+gitlab+cicd 整合 - index72 - 博客园