【AI论文】反思、重试、奖励:通过强化学习实现大型语言模型的自我提升
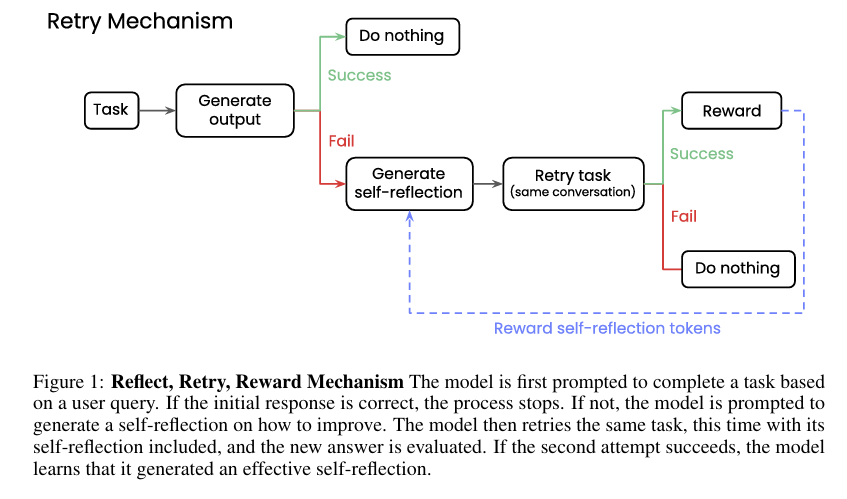
摘要:我们探索了一种通过自我反思和强化学习来提高大型语言模型性能的方法。 通过激励模型在回答错误时产生更好的自我反思,我们证明了即使生成合成数据不可行,只有二元反馈可用,模型解决复杂、可验证任务的能力也可以得到增强。 我们的框架分为两个阶段:首先,在给定任务失败后,模型会生成一个自我反思的评论,分析其之前的尝试; 其次,该模型在情境中的自我反思下对任务进行了另一次尝试。 如果后续尝试成功,则对在自反射阶段生成的令牌进行奖励。 我们的实验结果显示,在各种模型架构上都有实质性的性能提升,在数学方程写作上提高了34.7%,在函数调用上提高了18.1%。 值得注意的是,较小的微调模型(15亿到70亿参数)的表现优于相同家族中规模大10倍的模型。 因此,我们的新范式是一种令人兴奋的途径,可以建立更有用、更可靠的语言模型,这些模型可以在有限的外部反馈下,在具有挑战性的任务上进行自我改进。Huggingface链接:Paper page,论文链接:2505.24726
研究背景和目的
研究背景
近年来,大型语言模型(LLMs)在自然语言处理(NLP)领域取得了显著进展,展示了在多种任务上的强大能力,包括文本生成、问答系统、翻译等。然而,尽管这些模型在许多标准基准测试中表现出色,但在面对复杂、需要深度推理的任务时,其性能仍然有限。特别是在没有足够训练数据或生成合成数据不可行的情况下,模型的性能提升变得尤为困难。此外,即使对于最大的语言模型,也可能在某些特定任务上表现不佳,因为它们可能没有针对这些任务进行专门的训练。
自我反思(Self-reflection)作为一种元提示策略,近年来在LLMs研究中逐渐受到关注。通过让模型分析自己的推理过程并识别潜在错误,自我反思有助于提高模型在多步推理任务中的准确性。然而,现有的自我反思方法大多依赖于人工设计的提示或外部监督,这在某些情况下可能不可行或效率低下。
强化学习(RL)作为一种从环境中学习以最大化累积奖励的方法,为LLMs的自我改进提供了一种新的途径。特别是,当与自我反思结合时,RL可以激励模型生成更好的自我反思,从而在面对失败的任务时提高其性能。
研究目的
本研究的主要目的是探索一种通过自我反思和强化学习来提高LLMs性能的方法。具体而言,我们希望解决以下问题:
- 如何在没有额外训练数据的情况下提高LLMs在复杂任务上的性能?
- 如何通过自我反思使LLMs能够从错误中学习并改进其性能?
- 强化学习如何与自我反思结合,以激励模型生成更有效的自我反思?
为了实现这些目标,我们提出了一种名为“反思、重试、奖励”(Reflect, Retry, Reward, 简称R3)的新方法,并通过实验验证了其在函数调用和数学方程求解任务上的有效性。
研究方法
方法概述
R3方法包含两个主要阶段:反思和重试。在反思阶段,当模型在给定任务上失败时,它会生成一个自我反思的评论,分析其之前的尝试并尝试识别错误。在重试阶段,模型在包含自我反思的上下文中再次尝试该任务。如果后续尝试成功,则对在自我反思阶段生成的令牌进行奖励。
具体实现
- 任务定义与验证器:
- 我们选择了函数调用和数学方程求解作为实验任务。对于函数调用任务,我们使用了APIGen数据集,其中包含用户查询、可用工具列表以及正确格式化的函数调用。对于数学方程求解任务,我们使用了Countdown数据集,其中包含一系列数字和目标数字,要求模型使用基本算术运算生成等于目标数字的方程。
- 我们为每个任务定义了一个验证器,用于判断模型的输出是否正确。对于函数调用任务,验证器检查模型是否选择了正确的工具并生成了正确的参数和值。对于数学方程求解任务,验证器检查模型是否使用了所有给定的数字且方程是否等于目标数字。
- 自我反思生成:
- 当模型在任务上失败时,我们使用特定的提示模板引导其生成自我反思。例如,在函数调用任务中,我们提示模型:“你尝试执行任务,但未能生成正确的工具调用。请反思哪里出了问题,并写一个简短的解释,帮助你下次做得更好。”
- 模型根据提示生成自我反思,然后我们在包含自我反思的上下文中再次提示模型尝试任务。
- 强化学习训练:
- 我们使用Group Relative Policy Optimization(GRPO)作为强化学习算法来训练模型。GRPO通过比较一组采样完成的输出结果来直接估计优势,而不需要单独的价值(批评)网络。
- 在训练过程中,如果模型在包含自我反思的上下文中成功完成任务,则对在自我反思阶段生成的令牌进行奖励。这种奖励机制激励模型生成更有效的自我反思。
- 实验设置:
- 我们选择了多种LLMs进行实验,包括Qwen2、Llama3.1和Phi3.5-mini等,并报告了它们在未经训练(vanilla)和经过R3训练后的性能。
- 为了提高效率,我们首先为每个任务创建了一个失败数据集,其中包含模型在验证器上失败的所有查询。然后,我们在这个失败数据集上训练模型,直到它们收敛。
研究结果
函数调用任务结果
在APIGen数据集上的实验结果表明,经过R3训练的模型在函数调用任务上的性能显著提升。具体而言,Qwen2-7B Instruct模型在经过训练后,其准确率从43.4%提高到了48.1%(第二次尝试),甚至超过了未经训练的Qwen2-72B Instruct模型(45.2%准确率)。这表明,通过自我反思和强化学习,较小的模型也能在复杂任务上表现出色。
此外,我们还观察到,经过训练的模型在第一次尝试时的性能也有所提升,尽管提升幅度较小。这可能是因为自我反思训练使模型学会了更一般的推理策略,这些策略在第一次尝试时也能发挥作用。
数学方程求解任务结果
在Countdown数据集上的实验结果同样令人鼓舞。经过R3训练的模型在数学方程求解任务上的性能也有显著提升。特别是,Qwen2.5-7B Instruct模型在经过训练后,其准确率从42.3%提高到了50.9%(第二次尝试),超过了未经训练的Qwen2.5-72B Instruct模型(49.9%准确率)。
与函数调用任务类似,数学方程求解任务上的实验结果也表明,自我反思训练不仅提高了模型在第二次尝试时的性能,还对其第一次尝试时的性能产生了积极影响。这进一步支持了我们的假设,即自我反思训练使模型学会了更一般的推理策略。
错误分析
为了更深入地理解模型的性能提升,我们对模型在函数调用和数学方程求解任务上的错误进行了分类和分析。在函数调用任务中,我们将错误分为工具选择错误、参数错误和格式错误三类。实验结果表明,经过训练的模型在工具选择和参数选择上的错误率显著降低,而在格式错误上的变化不大。
在数学方程求解任务中,我们将错误分为无效方程、错误数字和未命中目标三类。实验结果表明,经过训练的模型在无效方程和错误数字上的错误率显著降低,而在未命中目标上的变化因模型而异。特别是,Qwen2.5-7B Instruct模型在训练后更倾向于使用正确的数字,即使这可能导致未命中目标。
研究局限
尽管R3方法在函数调用和数学方程求解任务上取得了显著的性能提升,但本研究仍存在一些局限性:
- 任务选择:
- 我们仅在函数调用和数学方程求解两个任务上验证了R3方法的有效性。这两个任务虽然具有代表性,但可能无法全面反映R3方法在所有类型任务上的性能。未来研究可以探索R3方法在其他类型任务(如文本生成、问答系统等)上的应用。
- 模型规模:
- 我们主要关注了参数数量在15亿到70亿之间的模型。虽然这些模型在实验中表现出了良好的性能,但R3方法在不同规模模型上的适用性仍需进一步验证。特别是,对于参数数量远大于或远小于这个范围的模型,R3方法的效果可能有所不同。
- 自我反思质量:
- 自我反思的质量对R3方法的性能至关重要。然而,在本研究中,我们并没有直接评估自我反思的质量,而是通过模型的最终性能来间接推断。未来研究可以探索如何更直接地评估和提高自我反思的质量,从而进一步提升R3方法的性能。
- 奖励机制:
- 在本研究中,我们使用了二元反馈(成功/失败)作为奖励信号。虽然这种简单的奖励机制在实验中表现出了良好的效果,但对于更复杂的任务,可能需要更细致的奖励信号来指导模型的学习。未来研究可以探索如何设计更有效的奖励机制,以进一步提高R3方法的性能。
未来研究方向
基于本研究的结果和局限性,我们提出以下未来研究方向:
- 跨任务验证:
- 在更多类型的任务上验证R3方法的有效性,包括文本生成、问答系统、翻译等。通过跨任务验证,可以更全面地评估R3方法的泛化能力和适用性。
- 模型规模探索:
- 探索R3方法在不同规模模型上的适用性,包括参数数量远大于或远小于当前实验范围的模型。通过模型规模探索,可以确定R3方法在不同资源限制下的性能表现。
- 自我反思质量评估:
- 设计更直接的方法来评估和提高自我反思的质量。例如,可以引入人工评估或自动评估指标来量化自我反思的有效性,并根据评估结果调整自我反思的生成策略。
- 奖励机制优化:
- 设计更有效的奖励机制来指导模型的学习。例如,可以引入更细致的奖励信号来区分不同程度的成功或失败,或者使用多步奖励来引导模型在复杂任务上的学习过程。
- 结合其他技术:
- 探索R3方法与其他技术(如迁移学习、多任务学习、元学习等)的结合,以进一步提高模型的性能和泛化能力。通过结合其他技术,可以充分利用不同方法的优势,实现更全面的模型改进。
- 实际应用探索:
- 将R3方法应用于实际场景中,如智能客服、自动化编程、教育辅导等。通过实际应用探索,可以验证R3方法在实际场景中的有效性和实用性,并为其进一步优化提供方向。
综上所述,本研究提出的R3方法通过自我反思和强化学习为LLMs的自我改进提供了一种新的途径。实验结果表明,R3方法在函数调用和数学方程求解任务上取得了显著的性能提升,并展示了在不同规模模型上的适用性。然而,本研究仍存在一些局限性,未来研究可以进一步探索R3方法在跨任务验证、模型规模探索、自我反思质量评估、奖励机制优化、结合其他技术以及实际应用探索等方面的应用和发展。