经典文献阅读之--LidaRefer(基于变换器的自动驾驶户外3D视觉定位)
0. 简介
三维视觉引导(VG)旨在根据自然语言描述定位三维场景中的相关物体或区域。尽管近期针对室内三维VG的方法成功利用了基于变换器的架构来捕捉全球上下文信息并实现细粒度的跨模态融合,但由于室内和室外环境之间点云分布的差异,这些方法并不适用于户外环境。具体而言,首先,广泛的激光雷达(LiDAR)点云由于高维视觉特征的存在,导致在变换器中需要不可接受的计算和内存资源。其次,稀疏LiDAR点云中的主导背景点和空白区域由于其无关的视觉信息,使得跨模态融合变得复杂。LidaRefer: Outdoor 3D Visual Grounding for Autonomous Driving with Transformers 是一种专为大规模户外场景设计的3D视觉定位框架,旨在通过自然语言描述来定位3D场景中的相关对象或区域。该框架特别针对自动驾驶领域,能够有效处理由激光雷达(LiDAR)传感器捕获的广泛且稀疏的点云数据。LidaRefer 的核心特点在于其能够捕捉全局上下文信息,并实现细粒度的跨模态融合,这使得它在处理户外环境中的复杂场景时表现出色。此外,LidaRefer在训练过程中引入了一种新颖的定位方法,能够同时定位目标对象和可能引起混淆的模糊对象,从而提高模型区分目标和非目标对象的能力。
1. 主要贡献
在视觉引导(VG)场景中,一些与目标具有相似属性或在描述中被提及的非目标物体可能会被误认为是目标,从而导致目标识别的歧义,如图1(b)所示。为了解决这个问题,我们引入了一种简单而有效的监督方法——模糊物体定位,考虑目标与每种模糊物体之间的差异。该方法在训练过程中定位目标及一些在目标识别中表现出最高置信度的非目标物体,从而通过学习它们在场景中的空间关系或属性所产生的差异,增强区分模糊物体与目标的能力。我们的贡献可以总结如下:
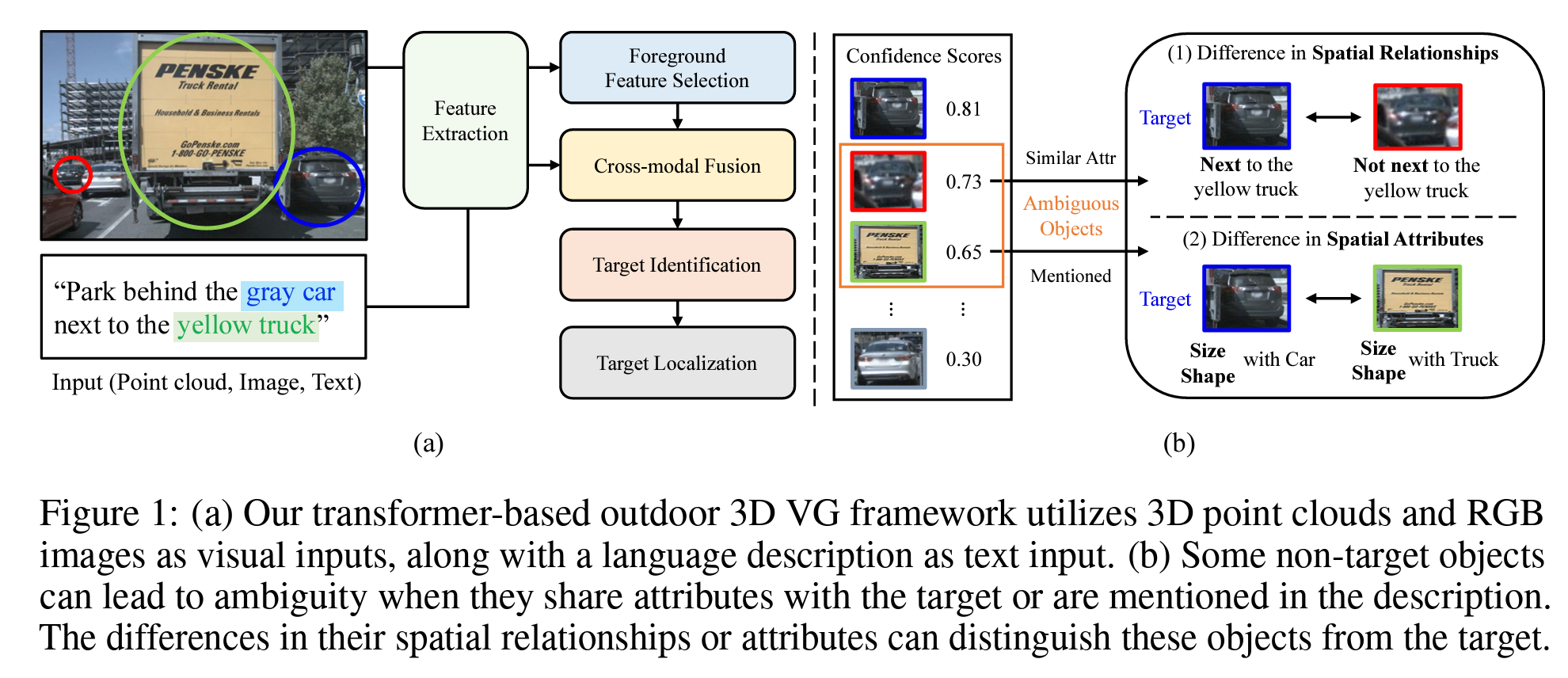
图1: (a) 我们基于变换器的户外3D视觉定位框架利用3D点云和RGB图像作为视觉输入,同时将语言描述作为文本输入。(b) 一些非目标物体可能会导致歧义,尤其是当它们与目标共享属性或在描述中被提及时。它们在空间关系或属性上的差异可以将这些物体与目标区分开来。
• 我们提出了LidaRefer,一个基于变换器的3D视觉引导框架,旨在有效理解全球上下文信息,并促进大规模户外场景中的跨模态融合,以支持自动驾驶。
• 我们引入了一种简单而有效的定位方法,通过识别空间关系和属性的差异来区分模糊物体与目标。
• 我们通过在Talk2Car-3D数据集上取得最先进的结果,并分析在各种评估设置下的效果,展示了LidaRefer的优越性。
2. 框架
图2展示了LidaRefer的总体结构。它处理同步输入,包括点云和RGB图像(可选)作为视觉输入,以及语言描述作为文本输入。尽管我们的目标是为描述中提到的目标物体预测一个三维边界框,但LidaRefer被监督以定位目标物体和模糊物体。
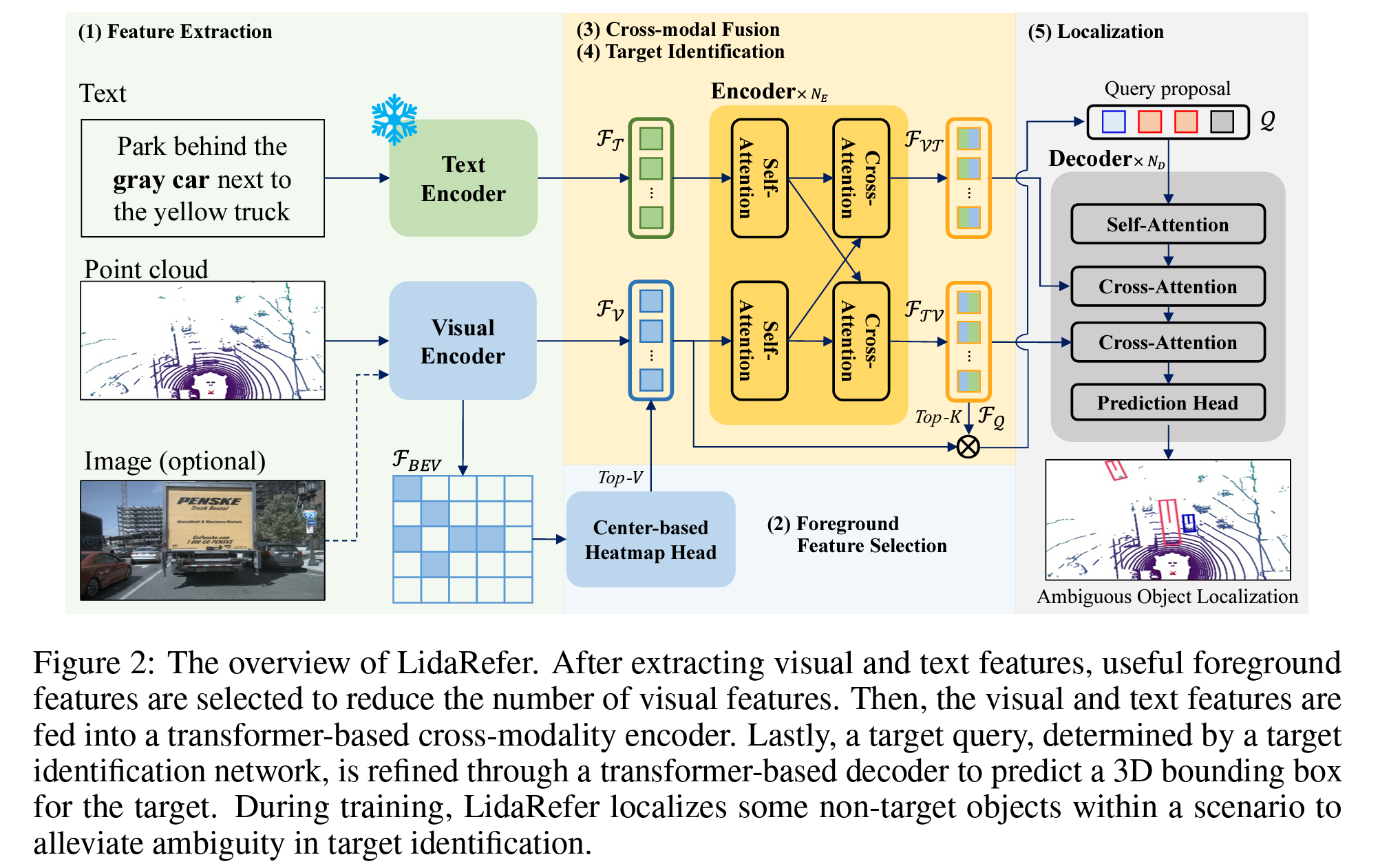
图2:LidaRefer的总体概述。在提取视觉和文本特征后,选择有用的前景特征以减少视觉特征的数量。然后,将视觉特征和文本特征输入到基于变换器的跨模态编码器中。最后,通过目标识别网络确定的目标查询经过基于变换器的解码器进行优化,以预测目标的三维边界框。在训练过程中,LidaRefer定位场景中的一些非目标物体,以减轻目标识别中的模糊性。
2.1 特征提取
视觉编码器 :视觉数据有两种类型:点云和图像。在仅使用点云的设置(激光雷达仅设置)中,点被编码为鸟瞰图(BEV)平面上的视觉特征,采用标准的基于体素的三维骨干网络[42],因其在各种户外检测器中的高效性和有效性而被选用[35, 45, 51, 52]。在点云与图像融合的设置(多模态设置)中,我们采用Focals Conv的多模态融合策略[8]。具体而言,使用ResNet-50[17]作为骨干网络提取二维图像特征,以获取RGB图像中的纹理信息。在转换为BEV平面之前,使用三维到二维的投影将每个三维体素特征与其对应的二维图像特征进行匹配,并通过对匹配特征进行求和操作进行融合。生成的纹理对齐的三维体素特征以与激光雷达仅设置相同的方式转换到BEV平面。设 F B E V ∈ R h × w × d F_{BEV} \in \mathbb{R}^{h \times w \times d} FBEV∈Rh×w×d为视觉特征,其中 h h h和 w w w为BEV特征图的大小, d d d为隐藏维度的数量。
文本编码器: 语言描述通过预训练的RoBERTa[27]编码为词级文本特征,该模型通常在其他VG模型中使用[20, 21, 41, 48]作为文本编码器,以利用关于单词的先验知识。设 F T ∈ R l × d F_{T} \in \mathbb{R}^{l \times d} FT∈Rl×d为文本特征,其中 l l l为描述的长度。
2.2 前景特征选择
一些基于变换器的室内3D视觉引导(VG)模型 [20, 41] 利用包含完整场景信息的所有视觉特征作为跨模态融合中的视觉标记。不幸的是,直接使用高维的鸟瞰视图(BEV)特征作为视觉标记会在变换器的注意力层中带来不可接受的计算和内存开销。这迫使我们使用低维视觉特征,但这使得捕捉小物体变得具有挑战性。此外,由于背景点生成的无关视觉特征主导了大规模稀疏点云,这可能导致跨模态融合中的学习不稳定。最近在3D户外检测器 [11, 12, 13, 32, 51] 中的成就表明,前景特征通常集中在其高维特征表示中的物体上。受到此启发,我们从BEV特征中选择有用的前景特征,以作为我们基于变换器的跨模态编码器中的视觉标记,从而减少计算和内存开销。我们遵循CenterFormer [51] 中使用的选择策略。中心热图头生成一个C通道热图 F H M ∈ R h × w × c F_{HM} \in \mathbb{R}^{h \times w \times c} FHM∈Rh×w×c,用于所有物体的中心,其中每个通道对应于C个类别之一。在BEV特征中,前景特征 F V ∈ R v × d ⊂ F B E V F_V \in \mathbb{R}^{v \times d} \subset F_{BEV} FV∈Rv×d⊂FBEV 在热图得分前V的位置被选中。它有效地保留了与物体高度相关的小数量视觉特征,即使是对于小物体,这增强了视觉上下文信息的捕捉,并促进了细粒度的跨模态对齐。
2.3 跨模态融合
在我们的基于变换器的跨模态编码器中,视觉和文本标记通过NE个跨模态编码层进行交互。每个编码层分别为BEV平面和描述添加位置嵌入到视觉和文本标记中。然后,视觉和文本标记执行自注意力,以捕捉每种模态的全局上下文信息,随后进行交叉注意力以实现细粒度的跨模态对齐。因此,我们分别获得文本对齐的视觉特征 F T V ∈ R v × d F_{T V} \in \mathbb{R}^{v \times d} FTV∈Rv×d 和视觉对齐的文本特征 F V T ∈ R l × d F_{V T} \in \mathbb{R}^{l \times d} FVT∈Rl×d。
2.4 目标识别与定位
由于我们的解码器利用从先前提取的特征生成的非参数查询,因此从这些特征中确定初始查询至关重要。现有方法 [20, 41] 通过基于目标置信度分数(由多层感知器(MLP)作为目标识别头计算)选择前K个特征 F Q ∈ R k × d ⊂ F T V F_Q \in \mathbb{R}^{k \times d} \subset F_{T V} FQ∈Rk×d⊂FTV 来初始化查询提议特征,然后用线性投影对 F Q F_Q FQ 进行编码。然而,从文本对齐的视觉特征进行这样的初始化可能会在框回归中带来挑战,因为在跨模态编码器中与文本信息对齐时,物体的纯视觉信息可能会退化。为了保留原始视觉信息,我们从与 F Q F_Q FQ 相同位置的 F V F_V FV 中提取并编码一部分纯视觉特征,而不是直接编码 F Q F_Q FQ。通过ND个解码层更新查询以生成3D边界框。在每个解码层中,为查询提议特征添加BEV平面的位置信息嵌入。然后,查询彼此自注意,并依次交叉注意到 F V T F_{V T} FVT 和 F T V F_{T V} FTV。优化后的查询被输入到回归头中以预测边界框。在推理时,我们使用从具有最高目标置信度分数的查询生成的框作为最终预测。
3. 模糊对象定位
在视觉引导(VG)场景中,由于两种类型的模糊对象,目标识别出现了模糊性问题。首先,目标对象所属类别中属性相似的对象在大小、形状和颜色等特征上存在相似性,可能导致误识别。这个问题在户外环境中尤为严重,因为在同一场景中,许多与目标同类的对象共存。其次,描述中提到的上下文对象(即非目标对象)如果模型误解了描述,也可能被错误地识别为目标。为了解决这个问题,我们需要识别差异,以区分这些模糊对象与目标对象。如图1(b-1)所示,视觉对象之间空间关系的差异应被识别,因为属性相似的对象通过描述中提到的对象之间的空间关系来区分于目标对象。同样,空间属性的差异也应被识别,因为上下文对象通常属于与目标不同的类别,具有如大小和形状等独特特征,如图1(b-2)所示。基于这些见解,我们提出了一种简单而有效的定位方法,能够同时定位目标和模糊对象。我们的方法通过基于变换器的解码器识别空间关系和属性的差异。首先,查询通过自注意力机制学习空间关系的差异,并在与目标和模糊对象匹配后,通过与融合的文本和视觉特征的交叉注意力进行学习。其次,通过预测目标和模糊对象的三维边界框来学习空间属性的差异。与之前主要关注上下文对象的方法 [3, 20, 41] 相比,我们的方法由于包含了属性相似的对象,能够捕捉到更详细的上下文信息。对于这种定位方法,有必要在每个场景中提取模糊对象及其标注的三维边界框。然而,这种标注在实际应用中通常不可用,即使手动标注也可能代价高昂。幸运的是,可以通过现成的三维物体检测器或来自物体检测数据集(VG数据集的超集)的手动标注,轻松获得场景中所有对象的标注三维边界框。利用这一便利性,我们提出了一种高效的标注策略,以动态提取模糊对象并根据模型预测(即置信度分数)从完整集合中检索其标注框。模糊对象在目标识别中通常表现出较高的置信度分数,从而导致从其位置生成查询。基于这一观察,我们通过将基于中心的物体检测器的分配策略 [45, 51] 应用于场景中的所有对象 O = { o 1 , o 2 , . . . , o n } O = \{o_1,o_2,...,o_n\} O={o1,o2,...,on} 来构建场景的模糊对象集合 A A A。如果对象成功与生成的查询 Q = { q 1 , q 2 , . . . , q k } Q = \{q_1,q_2,...,q_k\} Q={q1,q2,...,qk} 匹配,则将其指定为模糊对象。形式上,我们定义 A A A 为:
A = { o ∈ O ∣ o = o t ∧ ∃ q ∈ Q : assign ( o , q ) = true } (1) A = \{o \in O | o = o_t \land \exists q \in Q: \text{assign}(o,q) = \text{true}\} \tag{1} A={o∈O∣o=ot∧∃q∈Q:assign(o,q)=true}(1)
表1:两种IoU阈值设置。“C.V.”和“T.C.”分别指代施工车辆和交通锥。
| 类型 | 汽车 | 卡车 | C.V. | 公交车 | 拖车 | 障碍物 | 摩托车 | 自行车 | 行人 | T.C. |
|---|---|---|---|---|---|---|---|---|---|---|
| A | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.25 | 0.25 | - | - | - |
| B | 0.7 | 0.7 | 0.7 | 0.7 | 0.7 | 0.5 | 0.5 | 0.25 | 0.5 | 0.25 |
其中 assign ( o , q ) \text{assign}(o,q) assign(o,q) 是一个分配函数, o t o_t ot 是目标对象。该方法减少了标注负担,使模型能够动态关注模糊对象,随着学习的进展不断适应变化的模糊性。
4. 损失函数
LidaRefer 使用三种不同损失函数的加权和进行训练。首先,在前景特征选择中,使用一般热图分类损失 L h m L_{hm} Lhm 来监督中心热图头预测场景中所有对象的中心位置。其次,使用目标分类损失 L c l s L_{cls} Lcls 来监督目标识别网络,从文本对齐的视觉特征中预测目标查询。第三,使用边界框回归损失 L r e g L_{reg} Lreg 来监督预测框的中心、大小和旋转。我们对热图和目标分类采用焦点损失 [26],对边界框回归采用 L 1 L_1 L1 损失。最终损失定义为:
L = λ 1 L h m + λ 2 L c l s + λ 3 L r e g L = \lambda_1 L_{hm} + \lambda_2 L_{cls} + \lambda_3 L_{reg} L=λ1Lhm+λ2Lcls+λ3Lreg
其中三种损失的权重 λ 1 , λ 2 , λ 3 \lambda_1, \lambda_2, \lambda_3 λ1,λ2,λ3 分别设置为 1, 1, 1.25。
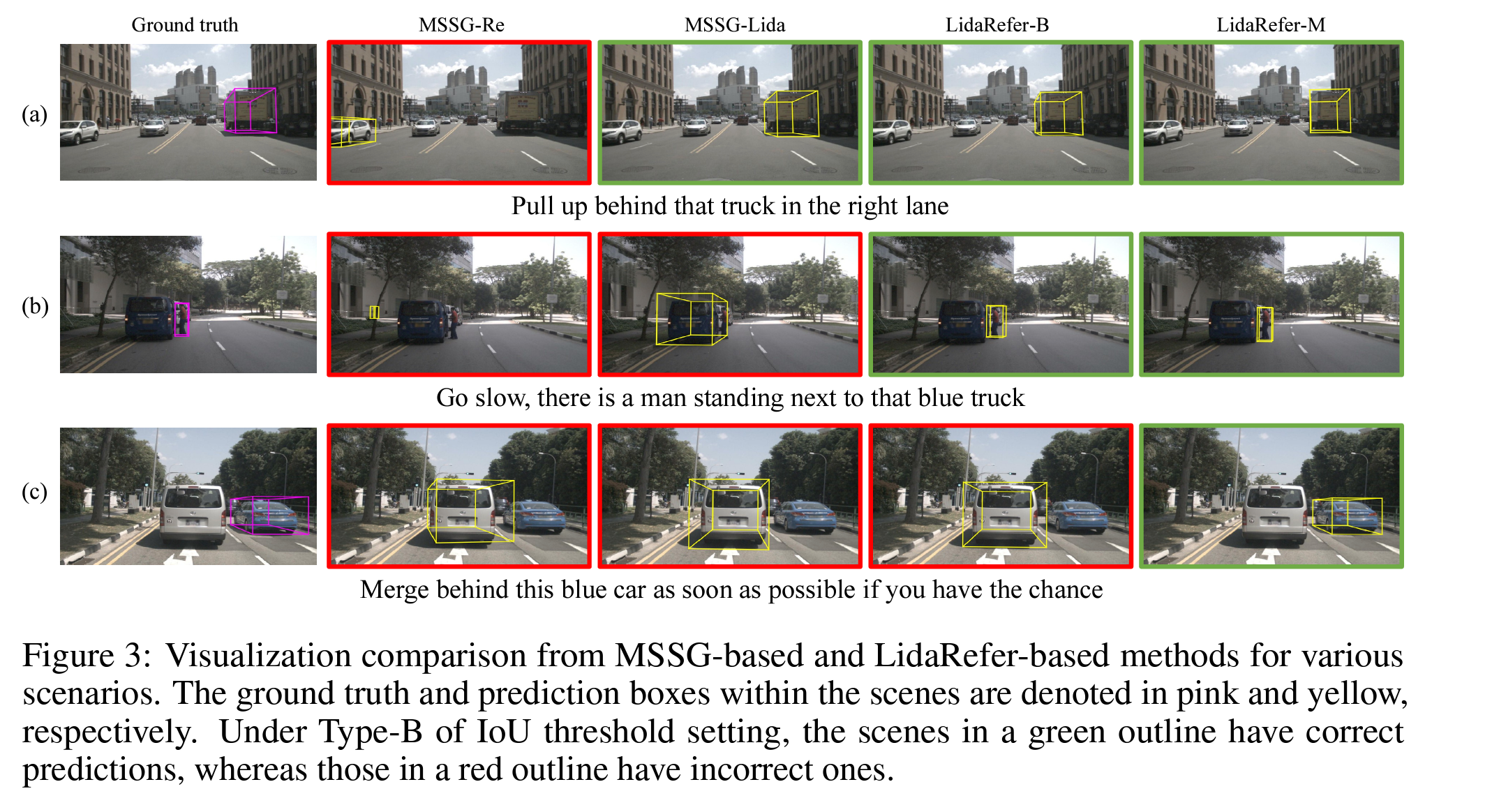
图3:基于MSSG和LidaRefer方法在不同场景下的可视化比较。场景中的真实值和预测框分别用粉色和黄色表示。在IoU阈值设置的B类下,绿色轮廓的场景具有正确的预测,而红色轮廓的场景则具有错误的预测。
5. 总结
LidaRefer 技术为自动驾驶领域提供了一种高效且准确的3D视觉定位解决方案,特别是在处理户外环境中复杂的3D场景时。随着自动驾驶技术的发展,对精确视觉定位的需求日益增长,LidaRefer能够提供强大的技术支持,帮助车辆更好地理解和响应自然语言指令,从而提高自动驾驶的安全性和效率。
6. 参考链接
https://mp.weixin.qq.com/s/AmljoBSoCexnWh8NjY0cFA