【NLP中向量化方式】序号化,亚编码,词袋法等
1.序号化
将单词按照词典排序,给定从0或者1或者2开始的序号即可,一般情况有几 个特征的单词: PAD表示填充字符,UNK表示未知字符

在这个例子中,我们可以看到我们分别将3个文本分为了4个token,每个token用左侧的词典表示(词典可自定义)
2.one-hot编码
使用一个非常稀疏的向量来表示单词的特征向量信息,假设现在有n个单词 (词表大小为n),那么转换的特征向量就是n维,仅在对应位置为1,其它位 置全部为0。

注意:当一个文本有多个词同时出现时文本向量就会累加。根据这个特性我们可以知道每个词在文本中出现的次数
3.词袋法
词袋模型(Bag-of-Words model,BOW)BoW(Bag of Words)词袋模型最初被用在文本分类中,将文档表示成特征矢量。它的基本思想是假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些词汇的集合,而文本中的每个词汇都是独立的。简单说就是讲每篇文档都看成一个袋子(因为里面装的都是词汇,所以称为词袋,Bag of words即因此而来),然后看这个袋子里装的都是些什么词汇,将其分类。如果文档中猪、马、牛、羊、山谷、土地、拖拉机这样的词汇多些,而银行、大厦、汽车、公园这样的词汇少些,我们就倾向于判断它是一篇描绘乡村的文档,而不是描述城镇的。
例如三个句子如下:
句子1:小孩喜欢吃零食。
句子2:小孩喜欢玩游戏,不喜欢运动。
句子3 :大人不喜欢吃零食,喜欢运动。
首先根据语料中出现的句子分词,然后构建词袋(每一个出现的词都加进来)。计算机不认识字,只认识数字,那在计算机中怎么表示词袋模型呢?其实很简单,给每个词一个位置索引就可以了。小孩放在第一个位置,喜欢放在第二个位置,以此类推。
{“小孩”:1,“喜欢”:2,“吃”:3,“零食”:4,“玩”:5,“游戏”:6,“大人”:7,“不”:8,“运动”:9}
其中key为词,value为词的索引,预料中共有9个单词, 那么每个文本我们就可以使用一个9维的向量来表示。
如果文本中含有的一个词出现了一次,就让那个词的位置置为1,词出现几次就置为几,那么上述文本可以表示为:
句子1:[1,1,1,1,0,0,0,0,0]
句子2:[1,2,0,0,1,1,0,1,1]
句子3:[0,2,1,1,0,0,1,1,1]
该向量与原来文本中单词出现的顺序没有关系,仅仅是词典中每个单词在文本中出现的频率。
与词袋模型非常类似的一个模型是词集模型(Set of Words,简称SoW),和词袋模型唯一的不同是它仅仅考虑词是否在文本中出现,而不考虑词频。也就是一个词在文本在文本中出现1次和多次特征处理是一样的。在大多数时候,我们使用词袋模型。
词袋模型的作用
将两篇文本通过词袋模型变为向量模型,通过计算向量的余弦距离来计算两个文本间的相似度。
词袋模型的缺点:
- 词袋模型最重要的是构造词库,需要维护一个很大的词库。
- 词袋模型严重缺乏相似词之间的表达。
- “我喜欢北京”“我不喜欢北京”其实这两个文本是严重不相似的。但词袋模型会判为高度相似。
- “我喜欢北京”与“我爱北京”其实表达的意思是非常非常的接近的,但词袋模型不能表示“喜欢”和“爱”之间严重的相似关系。(当然词袋模型也能给这两句话很高的相似度,但是注意我想表达的含义)
- 向量稀疏
为了让词袋模型能够表达更多语义,尝试使用n元语法来构建词袋模型。n表示聚合的词个数,比如2就表示2个2个聚合在一起,叫做2元模型。
例如:
“我,喜欢”
“喜欢,北京”
...
n元模型比词袋模型在某些任务上表现得更好,比如文档分类,但也会带来麻烦。
实现
对于中文来说,词袋模型首先会进行分词,在分词之后,通过统计每个词在文本中出现的次数,我们就可以得到该文本基于词的特征,如果将各个文本样本的这些词与对应的词频放在一起,就是我们常说的向量化。向量化完毕后一般也会使用TF-IDF进行特征的权重修正,再将特征进行标准化。 再进行一些其他的特征工程后,就可以将数据带入机器学习算法进行分类聚类了。
为了实现方便,本文使用英文来介绍怎么实现。
# 操作词袋模型:
# CountVectorizer:对语料库中出现的词汇进行词频统计,相当于词袋模型。
# 操作方式:将语料库当中出现的词汇作为特征,将词汇在当前文档中出现的频率(次数)作为特征值。
import numpy as np
from sklearn.feature_extraction.text import CountVectorizercount = CountVectorizer()# 语料库
docs = np.array(["Where there is a will, there is a way.","There is no royal road to learning.",
])
# bag是一个稀疏的矩阵。因为词袋模型就是一种稀疏的表示。
bag = count.fit_transform(docs)# 输出单词与编号的映射关系。
print(count.vocabulary_)
# 调用稀疏矩阵的toarray方法,将稀疏矩阵转换为ndarray对象。
print(bag)
print(bag.toarray())# where映射为编号8 there映射为编号5······
# 编号也是bag.toarray转换来的ndarray数组的索引x = np.array(["Where there is a will, there is a way.",
])y = count.transform(x)
print(y.toarray())4. TF-IDF
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术,常用于挖掘文章中的关键词,而且算法简单高效,常被工业用于最开始的文本数据清洗。
TF-IDF有两层意思,一层是"词频"(Term Frequency,缩写为TF),另一层是"逆文档频率"(Inverse Document Frequency,缩写为IDF)
TF-IDF算法步骤
第一步,计算词频:

考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。

第二步,计算逆文档频率:
这时,需要一个语料库(corpus),用来模拟语言的使用环境。
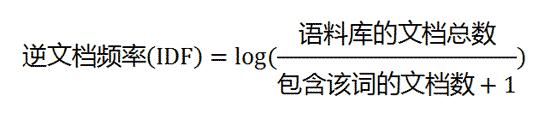
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
第三步,计算TF-IDF:
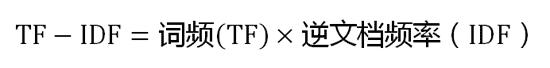
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
优缺点
TF-IDF的优点是简单快速,而且容易理解。缺点是有时候用词频来衡量文章中的一个词的重要性不够全面,有时候重要的词出现的可能不够多,而且这种计算无法体现位置信息,无法体现词在上下文的重要性。如果要体现词的上下文结构,那么你可能需要使用word2vec算法来支持。
5.Word2Vec
Word2Vec算法原理:
skip-gram: 用一个词语作为输入,来预测它周围的上下文
cbow: 拿一个词语的上下文作为输入,来预测这个词语本身
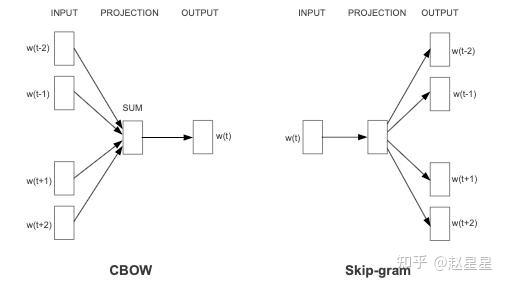
Skip-gram 和 CBOW 的简单情形
当上下文只有一个词时,语言模型就简化为:用当前词 x 预测它的下一个词 y
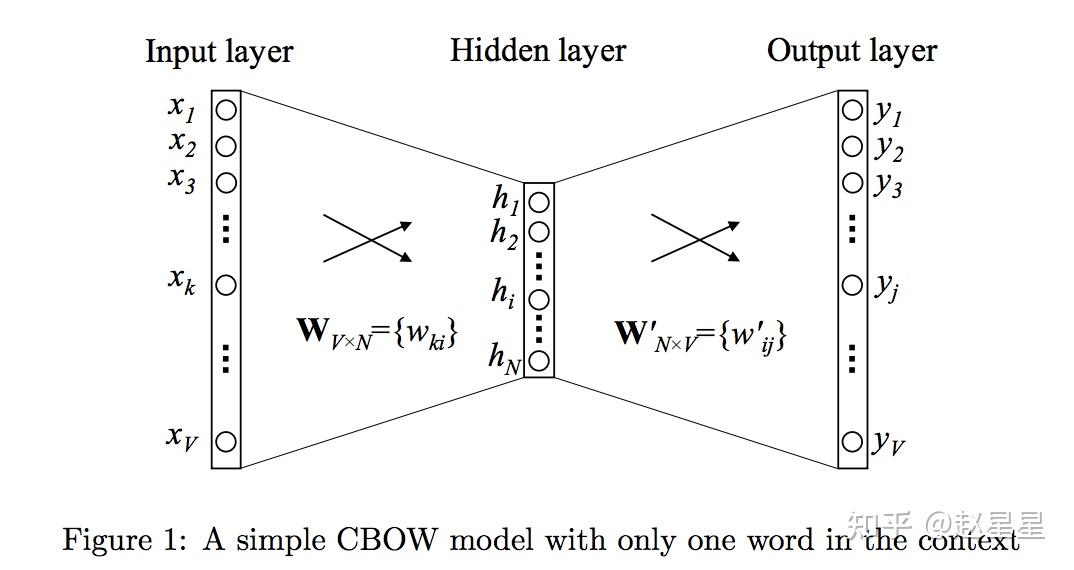
V是词库中词的数量,xx 是one-hot encoder 形式的输入,yy 是在这 V 个词上输出的概率。
隐层的激活函数是线性的,相当于没做任何处理(这也是 Word2vec 简化之前语言模型的独到之处)。当模型训练完后,最后得到的其实是神经网络的权重【输入层到隐层、隐层到输出层】,这就是生成的词向量,词向量的维度等于隐层的节点数。注意,由输入层到隐层的网络权重(输入向量)以及隐层到输出层的网络权重(输出向量)均可以作为词向量,一般我们用“输入向量”。
需要提到一点的是,这个词向量的维度(与隐含层节点数一致)一般情况下要远远小于词语总数 V 的大小,所以 Word2vec 本质上是一种降维操作—把词语从 one-hot encoder 形式的表示降维到 Word2vec 形式的表示。
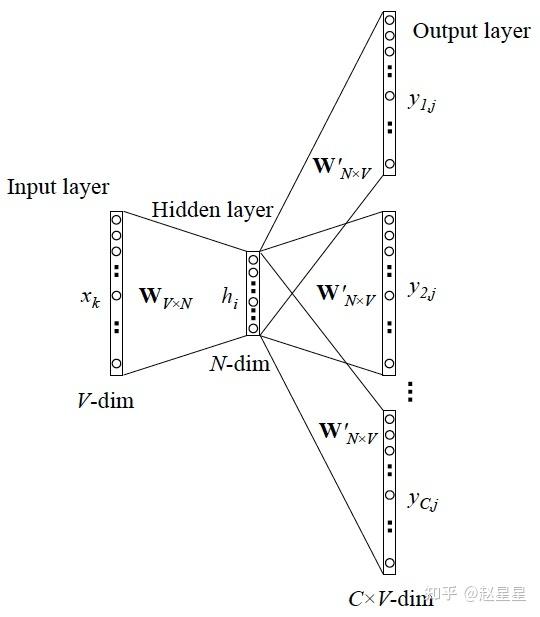
Skip-gram更一般的情形
当 y 有多个词时,网络结构如下:
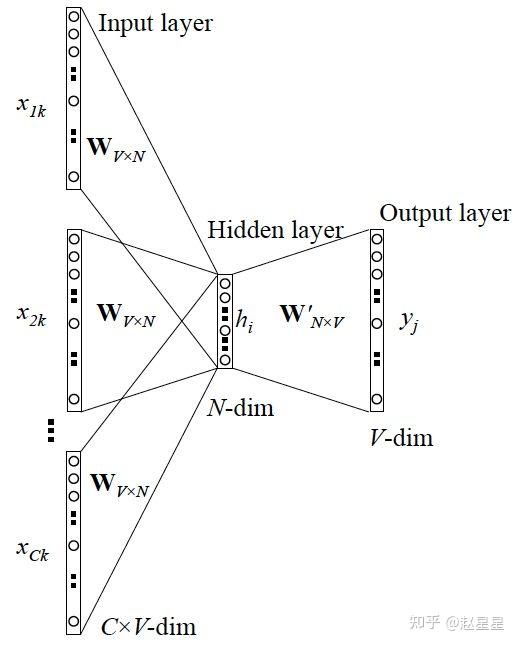
CBOW更一般的情形
网络结构如下:
Word2vec 的训练trick
Word2vec 本质上是一个语言模型,它的输出节点数是 V 个,对应了 V 个词语,本质上是一个多分类问题,但实际当中,词语的个数非常非常多,会给计算造成很大困难,所以需要用技巧来加速训练。
为了更新输出向量的参数,我们需要先计算误差,然后通过反向传播更新参数。在计算误差是我们需要遍历词向量的所有维度,这相当于遍历了一遍单词表,碰到大型语料库时计算代价非常昂贵。要解决这个问题,有三种方式:
Hierarchical Softmax:通过 Hierarchical Softmax 将复杂度从 O(n) 降为 O(log n);
Sub-Sampling Frequent Words:通过采样函数一定概率过滤高频单词;
Negative Sampling:直接通过采样的方式减少负样本。
Application
Word2vec 主要原理是根据上下文来预测单词,一个词的意义往往可以从其前后的句子中抽取出来。
而用户的行为也是一种相似的时间序列,可以通过上下文进行推断。当用户浏览并与内容进行交互时,我们可以从用户前后的交互过程中判断行为的抽象特征,这就使得我们可以用词向量模型应用到推荐、广告领域当中。
Word2vec 已经应用于多个领域,并取得了巨大成功:
- Airbnb 将用户的浏览行为组成 List,通过 Word2Vec 方法学习 item 的向量,其点击率提升了 21%,且带动了 99% 的预定转化率;
- Yahoo 邮箱从发送到用户的购物凭证中抽取商品并组成 List,通过 Word2Vec 学习并为用户推荐潜在的商品;
- 将用户的搜索查询和广告组成 List,并为其学习特征向量,以便对于给定的搜索查询可以匹配适合的广告。
Conclusion
简单总结一下: Word2Vec 是一个词向量开源工具,包括 Skip-Gram 和 CBOW 的两种算法,加速训练的方法有:Hierarchical Softmax、Sub-Sampling 和 Negative Sampling。
- Skip-Gram:利用中心词预测上下文;
- CBOW:利用上下文预测中心词,速度比 Skip-Gram 快;
- Hierarchical Softmax:引入 Hierarchical 加速 Softmax 的计算过程,对词频低的友好;
- Sub-Sampling:依据词频进行采样,对词频低的友好;
- Negative Sampling:通过负采样避免更新全部参数,对词频高的友好;
6. **pytorch nn.embedding
其为一个简单的存储固定大小的词典的嵌入向量的查找表,意思就是说,给一个编号,嵌入层就能返回这个编号对应的嵌入向量,嵌入向量反映了各个编号代表的符号之间的语义关系。
输入为一个编号列表,输出为对应的符号嵌入向量列表。
import torch
import torch.nn as nnembedding = nn.Embedding(10000, 128) # 语料库中有10000个词,每个词 embedding 到 128维向量表示x = torch.randint(10000, (3, 4)) # 随机生成3个样本,每个样本有4个词y = embedding(x)print(y.shape) # 输出torch.Size([3, 4, 128])