mysql-MySQL体系结构和存储引擎
1. MySQL体系结构和存储引擎
- MySQL被设计成一个单进程多线程架构的数据库,MySQL数据库实例在系统上的表现就是一个进
程 - 当启动实例时,读取配置文件,根据配置文件的参数来启动数据库实例;若没有,按编译时的默认
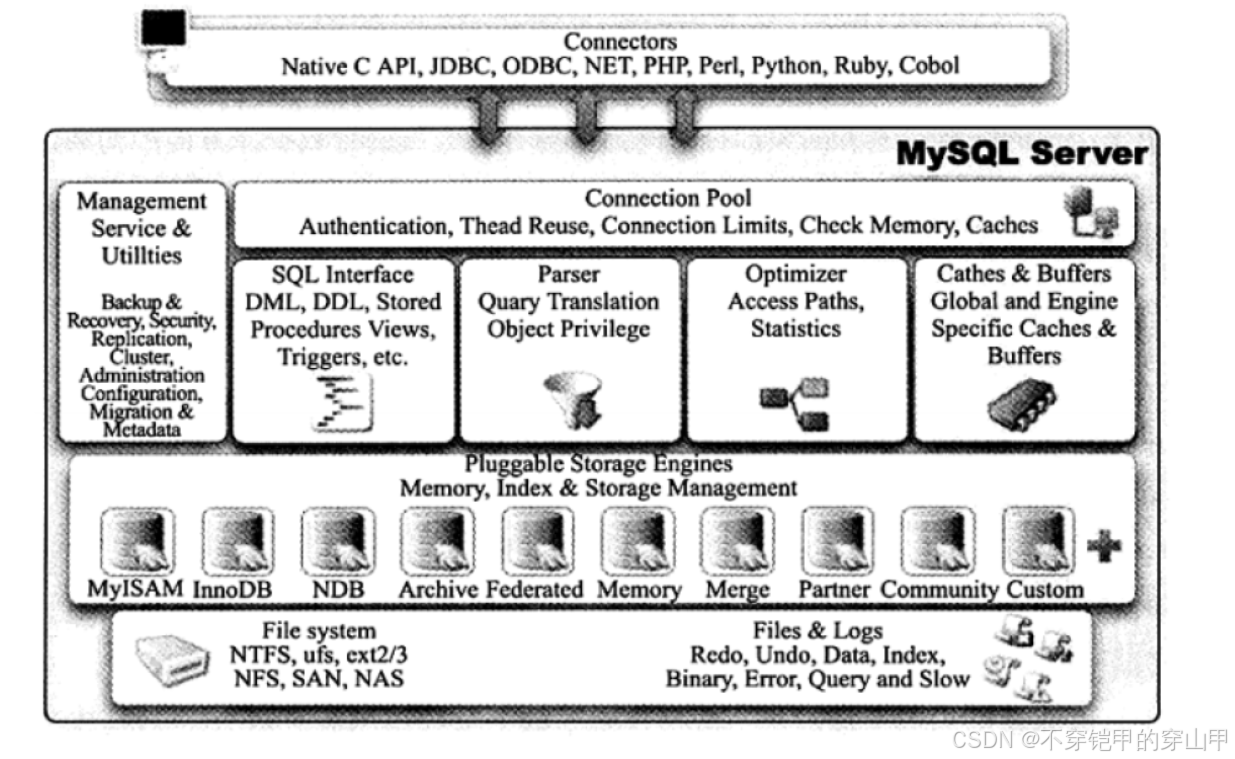
参数设置启动 - MySQL体系结构
- InnoDB存储引擎
存储引擎是基于表的,而不是数据库
支持事务:行锁设计、支持外键
将数据放到一个逻辑的表空间中,ibd文件
通过多版本并发控制(MVCC)来获得高并发性,并且实现了SQL的4个标准隔离级别,默认
为可重复读
提供插入缓存、二次写、自适应哈希索引、预读等高性能和高可用的功能
采用聚集的方式存储表中数据,按主键的顺序进行存放。没有指定主键,会为每一行生成一
个6字节的ROWID,并以此作为主键 - MyISAM
不支持事务、表锁设计、支持全文索引
2. InnoDB存储引擎
show engine innodb status;
注意:显示的不是当前的状态,而是过去某个时间范围内InnoDB存储引擎的状态。从下面的例子可以
发现, Per second averages calculated from the last 23 seconds 代表的信息为过去23秒内
数据库状态。
mysql> show engine innodb status\G;
*************************** 1. row ***************************
Type: InnoDB
Name:
Status:
=====================================
2019-09-11 04:31:08 7f4c7398a700 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 23 seconds
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 10 srv_active, 0 srv_shutdown, 227 srv_idle
srv_master_thread log flush and writes: 237
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 12
OS WAIT ARRAY INFO: signal count 12
Mutex spin waits 0, rounds 0, OS waits 0
RW-shared spins 12, rounds 360, OS waits 12
RW-excl spins 0, rounds 0, OS waits 0
Spin rounds per wait: 0.00 mutex, 30.00 RW-shared, 0.00 RW-excl
------------
TRANSACTIONS
------------
Trx id counter 3128
Purge done for trx's n:o < 3125 undo n:o < 0 state: running but idle
History list length 41
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 0, not started
MySQL thread id 1, OS thread handle 0x7f4c7398a700, query id 89 localhost root
init
show engine innodb status
---TRANSACTION 3107, not started
MySQL thread id 4, OS thread handle 0x7f4c73906700, query id 84 125.70.76.210
root
---TRANSACTION 3127, not started
MySQL thread id 3, OS thread handle 0x7f4c73948700, query id 86 125.70.76.210
root
--------
FILE I/O
--------
I/O thread 0 state: waiting for completed aio requests (insert buffer thread)
I/O thread 1 state: waiting for completed aio requests (log thread)
I/O thread 2 state: waiting for completed aio requests (read thread)
I/O thread 3 state: waiting for completed aio requests (read thread)
I/O thread 4 state: waiting for completed aio requests (read thread)
I/O thread 5 state: waiting for completed aio requests (read thread)
I/O thread 6 state: waiting for completed aio requests (write thread)
I/O thread 7 state: waiting for completed aio requests (write thread)
I/O thread 8 state: waiting for completed aio requests (write thread)
I/O thread 9 state: waiting for completed aio requests (write thread)
Pending normal aio reads: 0 [0, 0, 0, 0] , aio writes: 0 [0, 0, 0, 0] ,
ibuf aio reads: 0, log i/o's: 0, sync i/o's: 0
Pending flushes (fsync) log: 0; buffer pool: 0
356 OS file reads, 88 OS file writes, 56 OS fsyncs
0.00 reads/s, 0 avg bytes/read, 0.00 writes/s, 0.00 fsyncs/s
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 276707, node heap has 0 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
---
LOG
---
Log sequence number 1886077
Log flushed up to 1886077
Pages flushed up to 1886077
Last checkpoint at 1886077
0 pending log writes, 0 pending chkp writes
29 log i/o's done, 0.00 log i/o's/second
----------------------
BUFFER POOL AND MEMORY
----------------------
Total memory allocated 137363456; in additional pool allocated 0
Dictionary memory allocated 108374
Buffer pool size 8192
Free buffers 7854
Database pages 338
Old database pages 0
Modified db pages 0
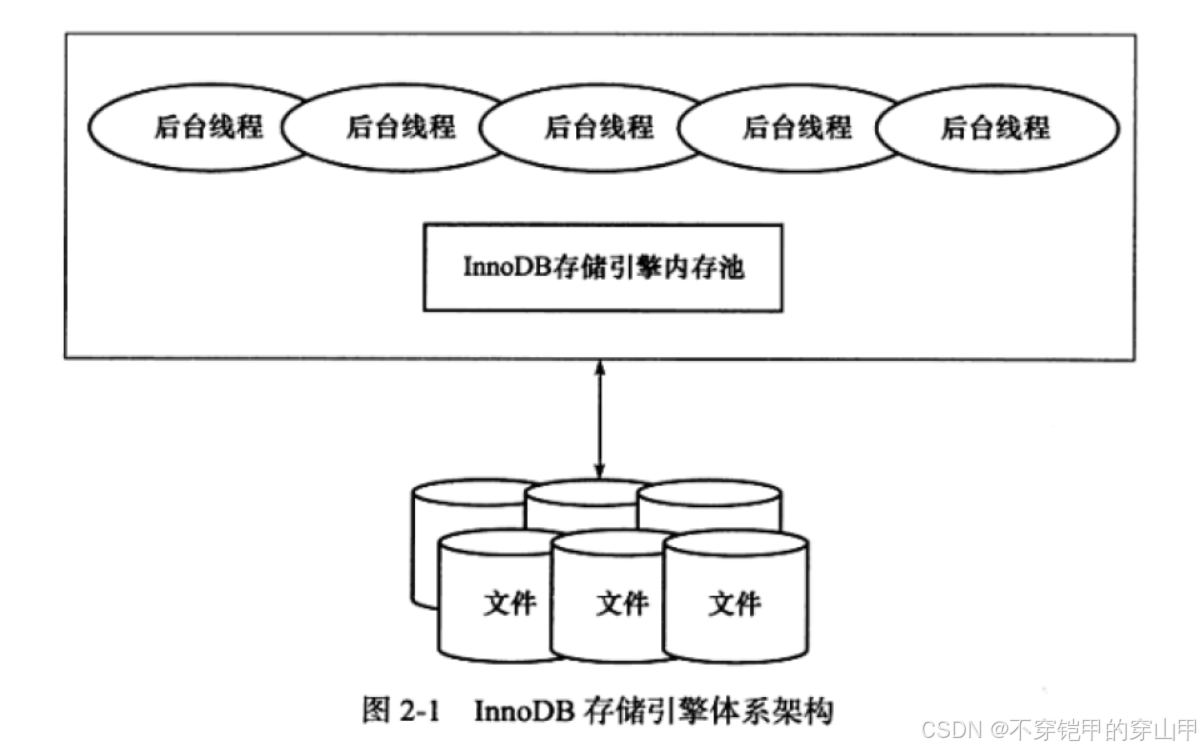
2.1 InnoDB体系结构
2.1.1 后台线程
后台线程的主要作用是负责刷新内存池中的数据,保证缓存池中的内存缓存的是最近的数据。
1. Master Thread
是一个非常核心的后台线程,主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包
括脏页的刷新、合并插入缓冲、UNDO页的回收等
2. IO Thread
大量使用AIO(Async IO)来处理写IO请求(write、read、insert buffer和IO thread),这样可
以极大提高数据库的性能。而IO Thread的工作主要是负责这些IO请求的回调(call back)处理。
有4种类型的IO Thread:write、read、insert buffer和log IO thread
3. Purge Thread
事务被提交后,其所使用的undo log(回滚日志)可能不再需要,因此需要Purge Thread来回收已经
使用并分配的undo页。
在 1.1版本之前,purge操作仅在InnoDB的Master Thread中完成。而从1.1开始,purge操作可以
独立到单独的线程中进行。
4. Page Cleaner Thread
在InnoDB 1.2.x版本引入。作用是将之前版本中脏页的刷新操作都放到单独的线程中完成,以减轻
Master Thread的工作
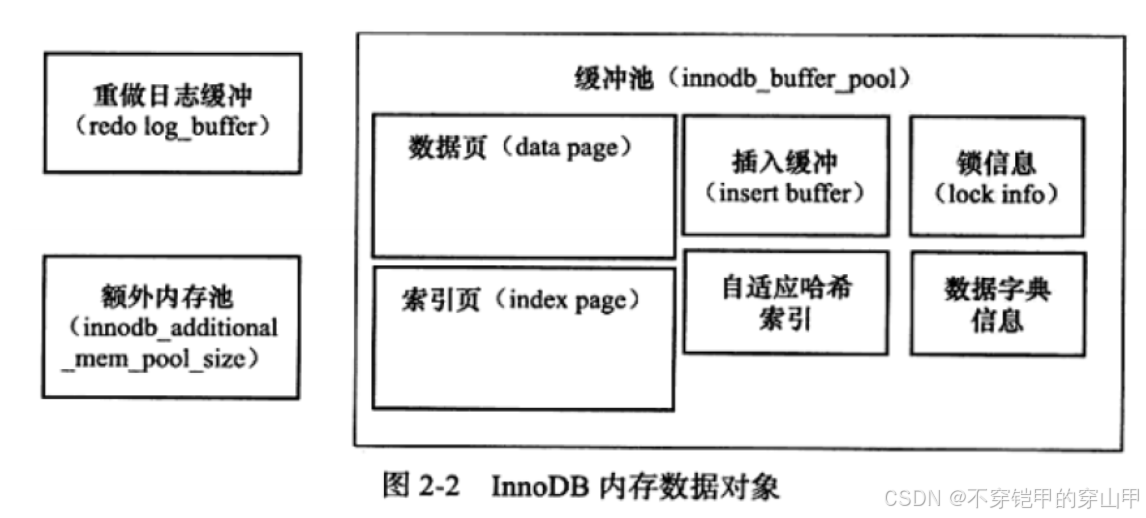
2.1.2 内存
缓冲池
InnoDB存储引擎是基于磁盘存储的,并将其中的记录按照页的方式进行管理。由于CPU速度与磁盘速
度之间的鸿沟,基于磁盘的系统通常使用缓存池技术来提供数据库的整体性能。
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 328, created 10, written 53
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 338, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
0 read views open inside InnoDB
Main thread process no. 1, id 139966295516928, state: sleeping
Number of rows inserted 0, updated 11, deleted 0, read 67
0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s
----------------------------
END OF INNODB MONITOR OUTPUT
============================
1 row in set (0.00 sec)
2.1 InnoDB体系结构
2.1.1 后台线程
后台线程的主要作用是负责刷新内存池中的数据,保证缓存池中的内存缓存的是最近的数据。
- Master Thread
是一个非常核心的后台线程,主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包
括脏页的刷新、合并插入缓冲、UNDO页的回收等 - IO Thread
大量使用AIO(Async IO)来处理写IO请求(write、read、insert buffer和IO thread),这样可
以极大提高数据库的性能。而IO Thread的工作主要是负责这些IO请求的回调(call back)处理。
有4种类型的IO Thread:write、read、insert buffer和log IO thread - Purge Thread
事务被提交后,其所使用的undo log(回滚日志)可能不再需要,因此需要Purge Thread来回收已经
使用并分配的undo页。
在 1.1版本之前,purge操作仅在InnoDB的Master Thread中完成。而从1.1开始,purge操作可以
独立到单独的线程中进行。 - Page Cleaner Thread
在InnoDB 1.2.x版本引入。作用是将之前版本中脏页的刷新操作都放到单独的线程中完成,以减轻
Master Thread的工作
2.1.2 内存
缓冲池
InnoDB存储引擎是基于磁盘存储的,并将其中的记录按照页的方式进行管理。由于CPU速度与磁盘速
度之间的鸿沟,基于磁盘的系统通常使用缓存池技术来提供数据库的整体性能。
在数据库中进行读取页的操作,首先将从磁盘读到的页放在缓冲池中,这个过程称为将页“FIX”在缓冲池
中。下一次再读相同的页时,首页判断该页是否在缓存池中。若在缓冲池中,称该页在缓冲池中被命
中,直接读取该页。否则,读取磁盘上的页。
对于数据库中页的修改操作,首先修改在缓冲池中的页,然后再以一定的频率(checkpoint机制)刷新
到磁盘上。
缓冲池的大小直接影响着数据库的整体性能。
通过命令show variables like 'innodb_buffer_pool_size’可以观察缓冲池的大小。
134217728/1024/1024 = 128M
mysql> show variables like 'innodb_buffer_pool_size';
+-------------------------+-----------+
| Variable_name | Value |
+-------------------------+-----------+
| innodb_buffer_pool_size | 134217728 |
+-------------------------+-----------+
1 row in set (0.00 sec)
缓冲池中缓存的数据页类型有:索引页、数据页、UNDO页、插入缓冲(insert buffer)、自适应哈希
索引、InnoDB存储的锁信息、数据字典信息等。
从InnoDB 1.0.x版本开始,允许有多个缓冲池实例。每个页根据哈希值平均分配到不同缓冲池实例中。
减少数据库内部的资源竞争,增加数据库的并发处理能力。
LRU List、Free List和Flush List
缓冲池是一个很大的内存区域,其中存放各种类型的页,那么如何对这么大的内存区域进行管理呢?
- LRU List:管理缓冲池中页的可用性
通常来说,数据库中的缓冲池是通过LRU(Lastest Recent Used,最近最少使用)算法来进行管
理的。即最频繁使用的页在LRU列表的前端,而最少使用的页在LRU列表的尾端。当缓冲池不能存
放新读取到的页时,将首先释放LRU列表中尾端的页。
InnoDB中,对传统的LRU算法做了一些优化,在列表中加入了midpoint位置。新读取到的页,虽
然是最新访问到的页,但并不直接放入到LRU列表的首部,而是放入到LRU列表的midpoint位置
(默认在LRU列表长度的5/8处)。
为什么不使用传统的LRU算法?因为有些操作仅仅是在这次操作中需要,并不是活跃数据,就会导
致LRU列表中热点数据被刷出,从而影响缓冲池的效率。
为解决这个问题,引入了另外一个参数来进一步管理LRU列表:innodb_old_blocks_time,用于
表示页读取到mid位置后需要等待多久才会被加入到LRU列表的热端。
mysql> show variables like 'innodb_old_blocks_time'\G;
*************************** 1. row ***************************
Variable_name: innodb_old_blocks_time
Value: 1000
1 row in set (0.01 sec)
- Free List
当数据库刚启动时,LRU列表是空的,即没有任何的页。这时页都存放在Free列表中。当需要从缓
冲池中分页时,首先从Free列表中查找是否有可用的空闲页,若有则将该页从Free列表中删除,
放入LRU列表中。否则,根据LRU算法,淘汰LRU列表末尾的页,将该内存空间分配给新的页。 - Flush List:管理将页刷新回磁盘
在LRU列表中的页被修改后,称该页为脏页(dirty page),即缓冲池中的页和磁盘上的页的数据产生
了不一致。这时数据库会通过CHECKPOINT机制将脏页刷新回磁盘,而Flush列表中的页即为脏页列
表。
脏页既存在LRU列表中,也存在于Flush列表中,二者互不影响。
重做日志缓冲 - InnoDB存储引擎首先将重做日志信息先放入到这个缓冲区,然后按一定频率将其刷新到重做日志
文件。 - 该值可由参数innodb_log_buffer_size控制,默认为8MB,一般不需要设置的很大。
8388608/1024/1024 = 8M
mysql> show variables like 'innodb_log_buffer_size'\G;
*************************** 1. row ***************************
Variable_name: innodb_log_buffer_size
Value: 8388608
1 row in set (0.00 sec)
- 刷新时机(三种)
Matster Thread每一秒将重做日志缓冲刷新到重做日志文件
每个事务提交时会将重做日志缓冲刷新到重做日志文件
当重做日志缓冲池剩余空间小于1/2时,重组日志缓冲刷新到重做日志文件
2.2 Checkpoint技术
- 问题描述
页的操作首先都是在缓冲池中完成的。如果一条DML语句,如Update或Delete改变了页中的记
录,那么此时页是脏的,即缓冲池中的页的版本要比磁盘的新。数据库需要将新版本的页从缓冲池
刷新到磁盘。
倘若每次一个页发生变化,就将新页的版本刷新到磁盘,那么这个开销是非常大的。若热点数据集
中在某几个页中,那么数据库的性能将变得非常差。同时,如果在从缓冲池将页的新版本刷新到磁
盘时发生了宕机,那么数据就不能恢复了。为了避免发生数据丢失的问题,当前事务数据库系统普
遍都采用了Write Ahead Log策略,即当事务提交时,先写重做日志,再修改页。当由于发生宕
机而导致数据丢失时,通过重做日志来完成数据的恢复。这也是事务ACID中D (Durability 持久性)
的要求。