深入理解 transforms.Normalize():PyTorch 图像预处理中的关键一步
深入理解 transforms.Normalize():PyTorch 图像预处理中的关键一步
在使用 PyTorch 进行图像分类、目标检测等深度学习任务时,我们常常会在数据预处理部分看到如下代码:
python复制编辑transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
其中的 transforms.Normalize() 是什么?为什么我们要对图像进行归一化?本文将深入讲解这个操作的原理、用途以及如何正确使用。
一、什么是 transforms.Normalize()?
transforms.Normalize(mean, std) 是 torchvision.transforms 模块提供的一个图像预处理方法,用于对图像的每个通道(例如 RGB)进行标准化处理。具体公式如下:
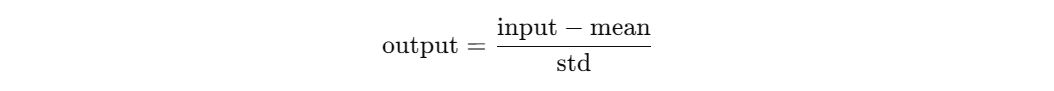
其中:
input:原始图像张量(已经通过ToTensor()转换为 [C, H, W] 格式,值域在 [0, 1])mean:每个通道的均值std:每个通道的标准差
二、为什么要使用 Normalize()?
在深度学习中,输入数据的标准化(Normalization)是一种常见的预处理手段,原因如下:
-
加速模型收敛
标准化可以让输入数据在各个维度上具有相似的分布,避免梯度在某些维度上过大或过小,有助于模型更快收敛。 -
提高模型性能
统一的数据分布让模型更容易学习规律,通常能提高准确率或减少损失。 -
与预训练模型保持一致
如果使用预训练模型(如 ResNet、VGG 等),正确的归一化参数是必须的。例如,ImageNet 预训练模型的标准化参数为:transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
三、实战举例
示例 1:标准化 RGB 图像
from torchvision import transforms
from PIL import Imagetransform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.5, 0.5, 0.5], # 每个通道减去0.5std=[0.5, 0.5, 0.5]) # 再除以0.5
])img = Image.open('example.jpg') # 假设是 RGB 图像
img_tensor = transform(img) # 处理后的张量范围是 [-1, 1]
💡 注意:
ToTensor()会将像素值从 [0, 255] 变为 [0.0, 1.0],而Normalize()会进一步变为 [-1, 1]。
四、如何选择 mean 和 std?
通常有三种选择方式:
-
使用通用值
- 如果不讲究数据分布,一般用
[0.5, 0.5, 0.5]的均值和标准差即可(适用于轻量级模型或小数据集)。
- 如果不讲究数据分布,一般用
-
使用 ImageNet 预训练模型的值
-
如果使用预训练模型(如
torchvision.models提供的 ResNet),请使用以下标准值:mean = [0.485, 0.456, 0.406] std = [0.229, 0.224, 0.225]
-
-
根据自己的数据计算
-
对于自定义数据集,建议先用一部分数据统计均值和标准差,更符合实际数据分布。
-
示例代码(简化):
import torch from torchvision import datasets, transformsdataset = datasets.ImageFolder('your_data_path', transform=transforms.ToTensor()) loader = torch.utils.data.DataLoader(dataset, batch_size=64, shuffle=False)mean = 0. std = 0. total = 0for images, _ in loader:batch_samples = images.size(0)images = images.view(batch_samples, images.size(1), -1)mean += images.mean(2).sum(0)std += images.std(2).sum(0)total += batch_samplesmean /= total std /= total print(mean, std)
-
五、总结
| 内容 | 说明 |
|---|---|
| 作用 | 对图像进行标准化,减均值、除以标准差 |
| 位置 | 一般放在 ToTensor() 之后 |
| 输入要求 | 形状为 [C, H, W],像素值范围 [0, 1] |
| 好处 | 加快模型收敛,提高精度,与预训练模型匹配 |
| 建议 | 预训练模型用其标准值,自定义数据集建议自己计算 |
📌 最后
掌握 transforms.Normalize() 的使用,对于训练一个稳定、高效的模型至关重要。希望本文能帮助你理解其背后的数学原理和实践方法。
如果你喜欢这篇文章,欢迎点赞、评论或关注我分享更多 PyTorch 深度学习干货!