每日八股文6.6
每日八股-6.6
- Mysql
- 1.怎么查看一条sql语句是否走了索引?
- 2.能说说 MySQL 事务都有哪些关键特性吗?
- 3.MySQL 是如何保证事务的原子性的?
- 4.MySQL 是如何保证事务的隔离性的?
- 5.能简单介绍一下 MVCC 吗?或者说,你理解的 MVCC 是什么?
- 6.事务的持久性又是如何保证的?
- 7.MySQL 都有哪些事务隔离级别呢?它们分别解决了哪些并发问题?
- 8.MySQL 默认的事务隔离级别是什么?它是怎么实现的呢?
- 9.你了解读已提交和可重复读这两种隔离级别在使用 MVCC 实现时有什么区别吗?
Mysql
1.怎么查看一条sql语句是否走了索引?
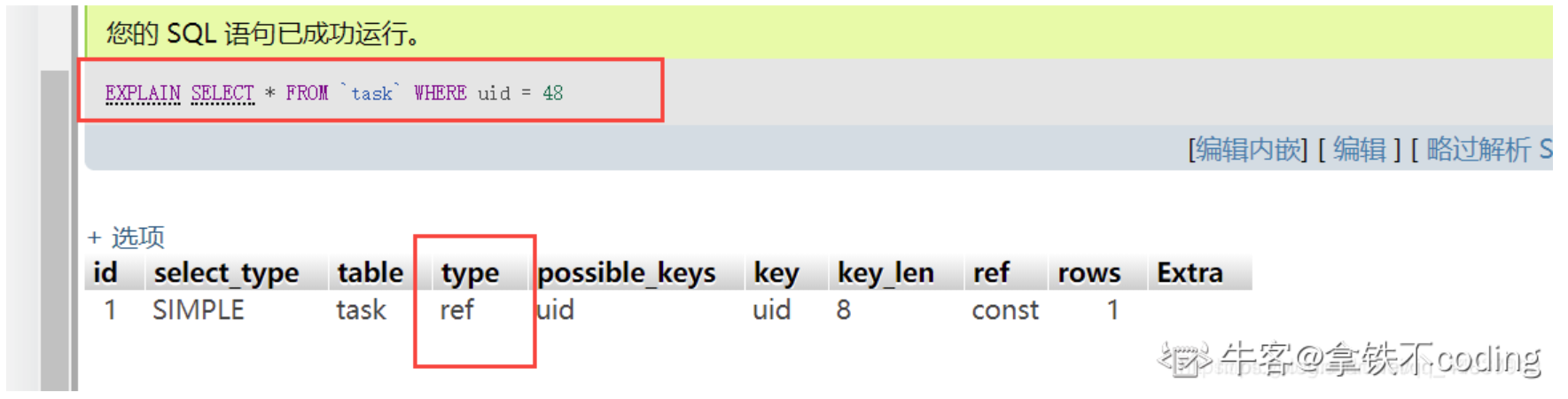
最常用的方法是使用explain命令,在待执行的sql语句最前面加上explain,这样做会返回一个执行计划,而不会真正的去执行这条命令。
我们分析这个执行计划需要重点关注以下几个字段:
- type:他表示mysql的访问方法,如果这个字段显示的不是ALL或者Index,那么通常就说明使用了索引。
- possible_keys:这个字段的值表示的是可能使用的索引,可能会有多个。
- key:表示实际用到的索引,如果这个字段的值为null,表示没有用到任何索引。
- key_len:表示实际用到的索引的长度。
- rows:表示估计需要扫描的行数,如果使用了索引的话,这个值应该比全表扫描要小很多。
2.能说说 MySQL 事务都有哪些关键特性吗?
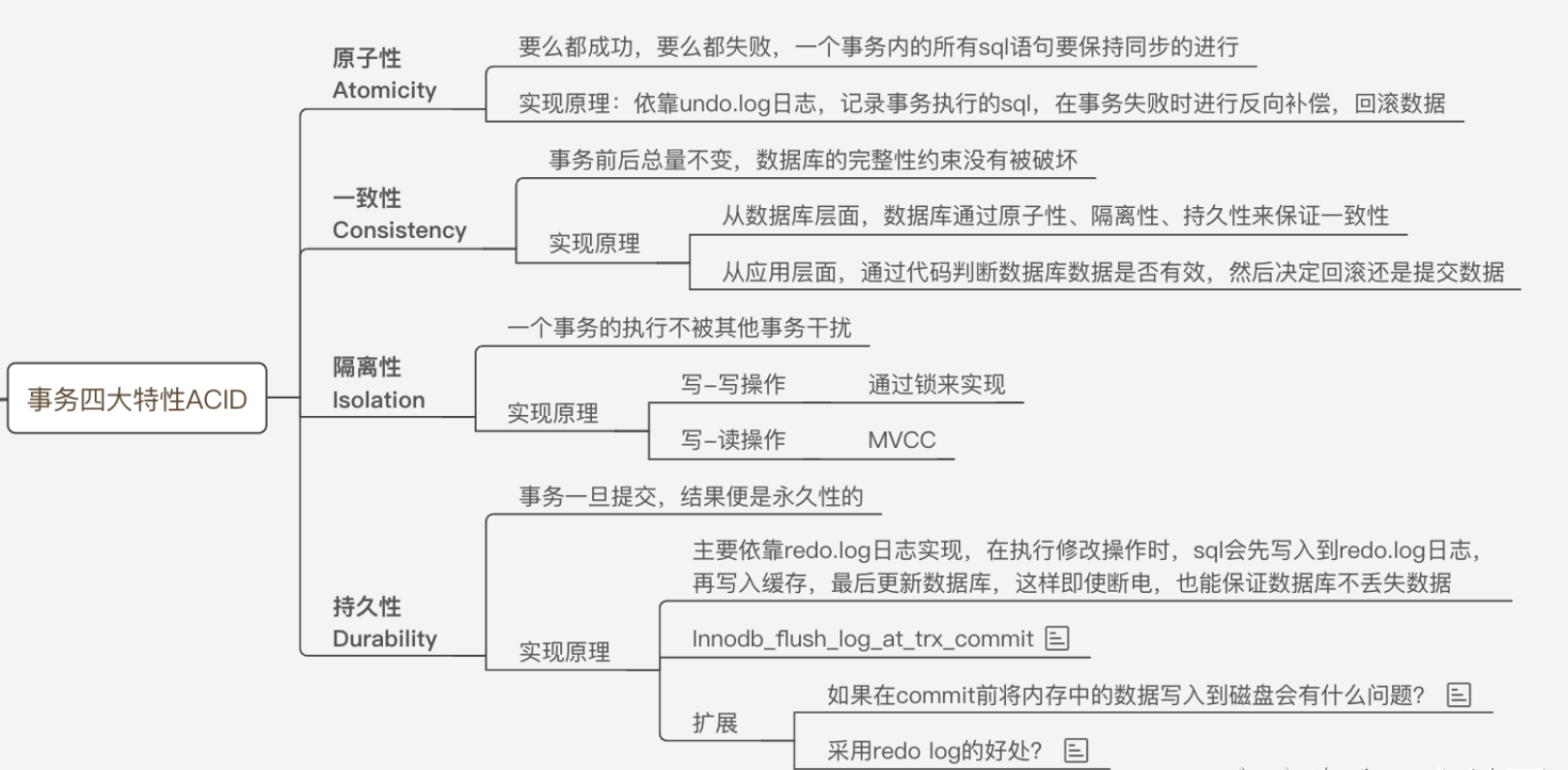
- 原子性A:定义在事务里面的操作要么全部执行,要么全部都不执行。原子性是由undo_log实现的,undo_log会在事务执行的时候存储和当前操作对应相反的操作,以便于之后恢复到原始状态。
- 持久性D:如果我们执行了事务的所有操作,那么他对数据库的影响是永久的,就算这些操作的结果现在还未被写入磁盘,依然可以保证这一点;这是通过redo_log实现的,这里面记录了事务所做的所有操作,在系统恢复时也可以重新执行。
- 隔离性I:允许多个事务并发操作,在多个事务进行并发操作同一个表时,该表不会产生不可预测的后果。隔离性主要是通过MVCC和锁实现的。
- 一致性C:执行完事务的所有操作后,原数据库的完整性约束不可以发生改变。这条性质与前面三条息息相关,只要实现了原子性、持久性和隔离性,那么也就实现了一致性。
3.MySQL 是如何保证事务的原子性的?
Mysql是通过undo log来保证事务的原子性的。当我们在执行事务中的对应操作时,undo log会记录与当前操作相反的操作,比如,我们在事务中执行了insert,那么在undo log中就添加一条delete;如果我们执行update,那么在undo log中就会记录更新前的值。
如果在事务的执行过程中出现了错误或者显式的使用rollback回滚操作,那么就会根据undo log中记录的操作,从后往前执行(逻辑上是栈,但实际存储结构是链表),这样就可以恢复到事务未开始前的数据。
4.MySQL 是如何保证事务的隔离性的?
保证事务的隔离性是通过mvcc和锁协同实现的。
mvcc用来保证读写分离。当一个事务在读数据,一个事务在写数据时,读数据的事务会维护一个历史版本的数据快照,这样可以保证不会读到脏数据(即另一个事务写的数据),其次,这样还可以避免不可重复读的问题,即保证了每一次读的结果都是相同的。
锁用来保证写写分离。当多个事务都在写同一份数据时,只有一个事物可以获得对数据的实际操作权,其他事务想要写必须得等到锁的释放。Mysql提供了不同粒度的锁,比如行级锁和表级锁,可以根据具体的情况来添加锁。
5.能简单介绍一下 MVCC 吗?或者说,你理解的 MVCC 是什么?
MVCC的全称是多版本并发控制(Multi-Version Concurrency Control),是一种高并发数据库系统中的事务隔离技术。
我理解的MVCC就是在实现事务隔离的基础上,进一步提升并发能力。传统的隔离技术比如锁,在并发读写时不可避免地会阻塞;MVCC通过维护多个版本的数据,实现了并发读写,从而很大程度的提高了吞吐量。
6.事务的持久性又是如何保证的?
Mysql的InnoDB引擎使用WAL(write ahead logging)和redo log 来保证事务的持久性,即先写日志,再写数据。
在进入事务执行真正的操作前,会将执行的操作同步写入redo log的缓冲区和buffer pool内存缓冲区,当事务提交时,会以追加写的方式写入到redo log中,这个速度非常快;现在即使buffer pool中的一些数据并没有写入到数据库中(可能因为数据库或服务器原因),那么之后也会根据redo log日志记录的操作重新按顺序执行,这样就保证了事务的持久性。
7.MySQL 都有哪些事务隔离级别呢?它们分别解决了哪些并发问题?
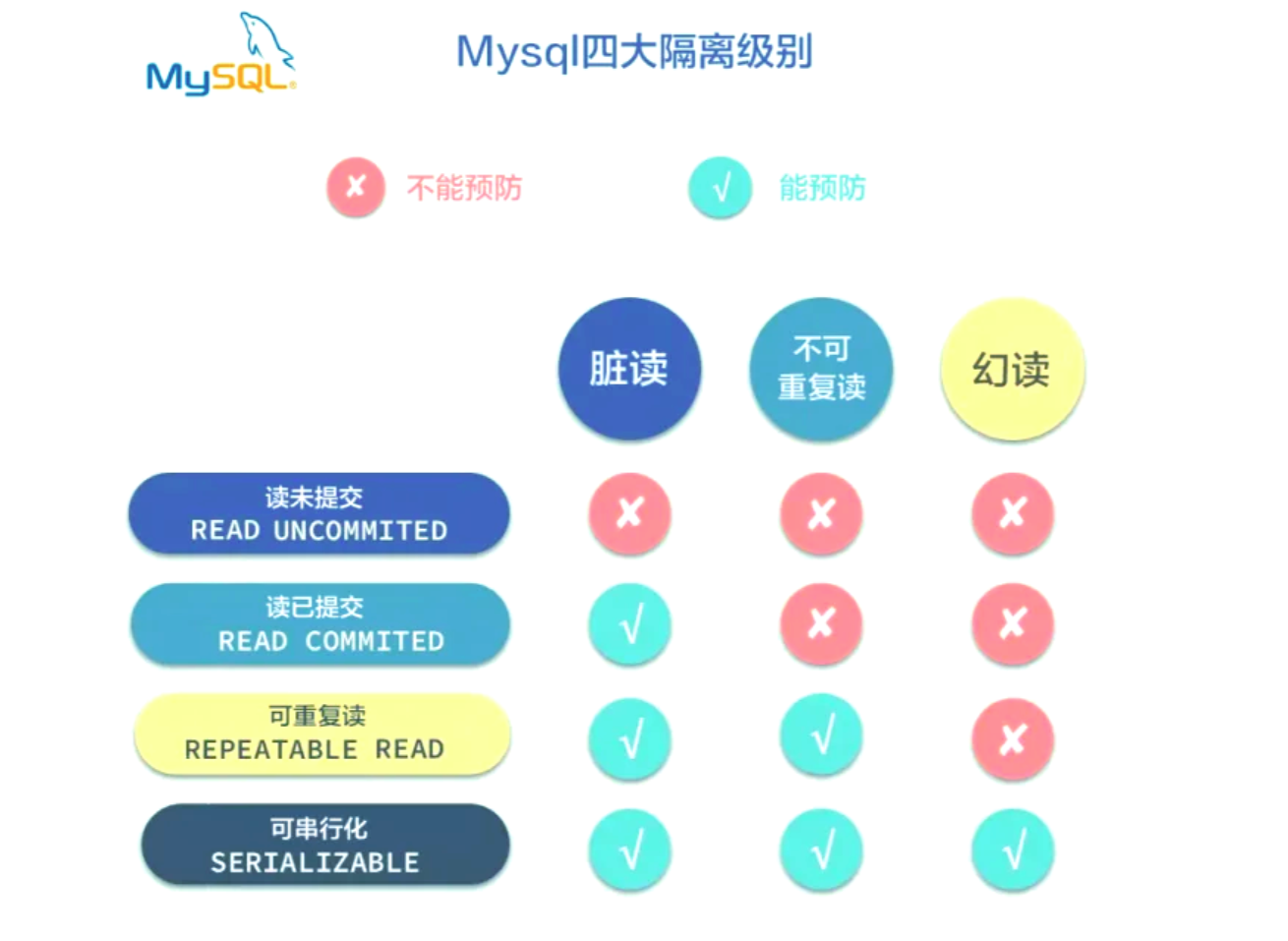
Mysql的事务有四大隔离级别,分别是读未提交,读已提交,可重复读和串行化。
- 读未提交:这是最低的隔离级别,在这个级别下,mysql可以读取其他尚未提交的事务所做出的修改,会导致读取脏数据的问题,该级别在实践中基本不会使用。
- 读已提交:在这个级别下,mysql只能在其他事务已经提交后的数据,这避免了读取脏数据的问题,但是没有解决可重复读的问题,因为重复读的情况下,可能每次读取到的数据都不一样(因为其他事务做出了修改)。
- 可重复读:这是mysql的默认事务隔离级别,在这个级别下,mysql通过mvcc和锁成功避免了前面的两个问题,但如果是当前读(读取数据的最新版本),那么可能会出现幻读的情况,即多次读取的结果行数不一致;InnoDB引擎通过引入next-key locks机制很大程度避免了这个问题。
- 串行化:这是最高的事务隔离级别,即完全摒弃了并发,只能一个事务一个事务的执行,这种级别严格保证了数据一致性,但是效率非常低。
补充关于当前读:
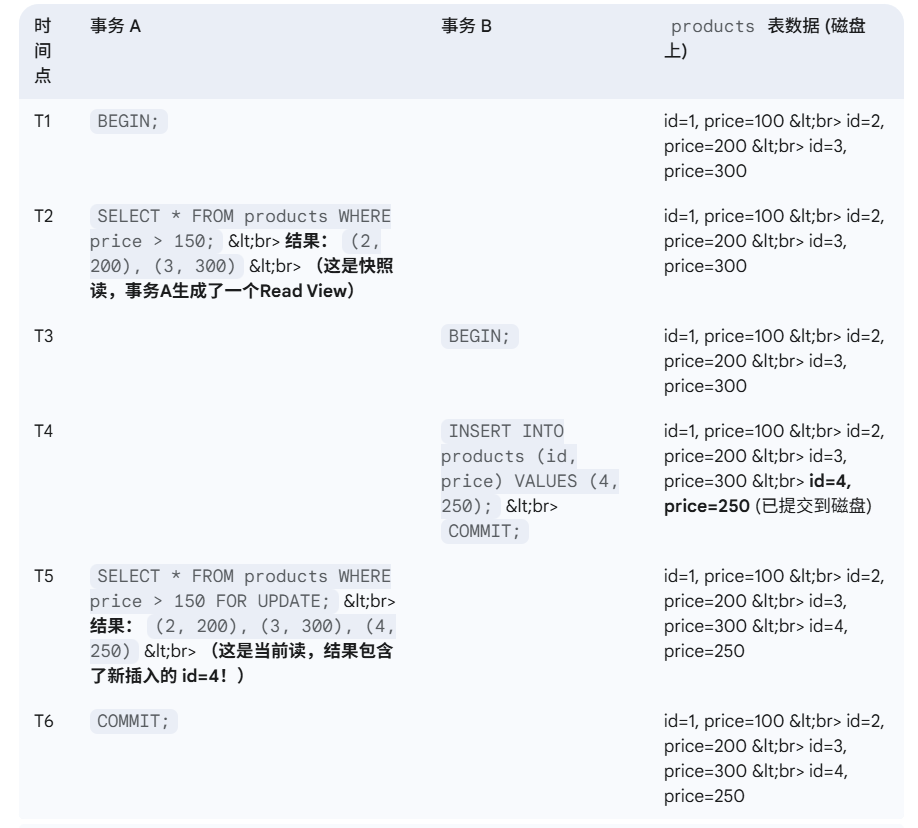
8.MySQL 默认的事务隔离级别是什么?它是怎么实现的呢?
当channel已经有数据时,再往channel里面发送数据就会造成发送方阻塞,直到有新的接收方来接收数据
9.你了解读已提交和可重复读这两种隔离级别在使用 MVCC 实现时有什么区别吗?
Go 语言中把错误当成一种特殊的值来处理,不支持其他语言中使用try/catch捕获异常的方式。
Go 语言中使用一个名为 error接口来表示错误类型。
type error interface {Error() string
}
如果需要自定义 error,最简单的方式是使用errors包提供的New函数创建一个错误。
// New returns an error that formats as the given text.
// Each call to New returns a distinct error value even if the text is identical.
func New(text string) error {return &errorString{text}
}
// errorString is a trivial implementation of error.
type errorString struct {s string
}
func (e *errorString) Error() string {return e.s
}
我们还可以自己定义结构体类型,实现error接口
// WrapError 自定义结构体类型
type WrapError struct {s string
}
// WrapError 类型实现error接口
func (e *WrapError) Error() string {return fmt.Sprintf("err:%s", e.s)
}