RK3588 InsightFace人脸识别移植及精度测试全解析
RK3588 InsightFace人脸识别移植及精度测试全解析
- 一、背景介绍
- 二、RK3588测试数据
- 三、环境搭建
- 四、模型获取与转换
- 4.1 获取源代码
- 4.2 下载预训练模型(`model_ir_se50.pth`)
- 4.2 下载LFW人脸对齐后的测试集并解压(`lfw112.tar.gz`)
- 4.3 PyTorch转ONNX
- 4.4 ONNX转RKNN量化模型
- 五、精度验证
- 5.1 LFW数据集说明
- 5.2 精度测试
一、背景介绍
在边缘计算领域,RK3588作为一款高性能AIoT芯片,具备6TOPS的NPU算力,非常适合部署人脸识别等计算机视觉应用。本文将详细讲解如何将先进的InsightFace人脸识别模型移植到RK3588平台,并进行精度验证。
为什么选择InsightFace?
InsightFace是当前最先进的开源人脸识别项目之一,其核心是基于深度卷积神经网络的特征提取模型。与传统方法相比,它能生成具有更强区分度的128维人脸特征向量(embedding),即使在不同光照、角度和遮挡条件下也能保持高识别精度。
二、RK3588测试数据
- 模型Shape:1x3x112x112
- 精度类型:INT8
- 推理耗时:14.23 ms
- 平均准确率: 99.43% 官方精度: 99.52%
- 最佳阈值: 0.2740
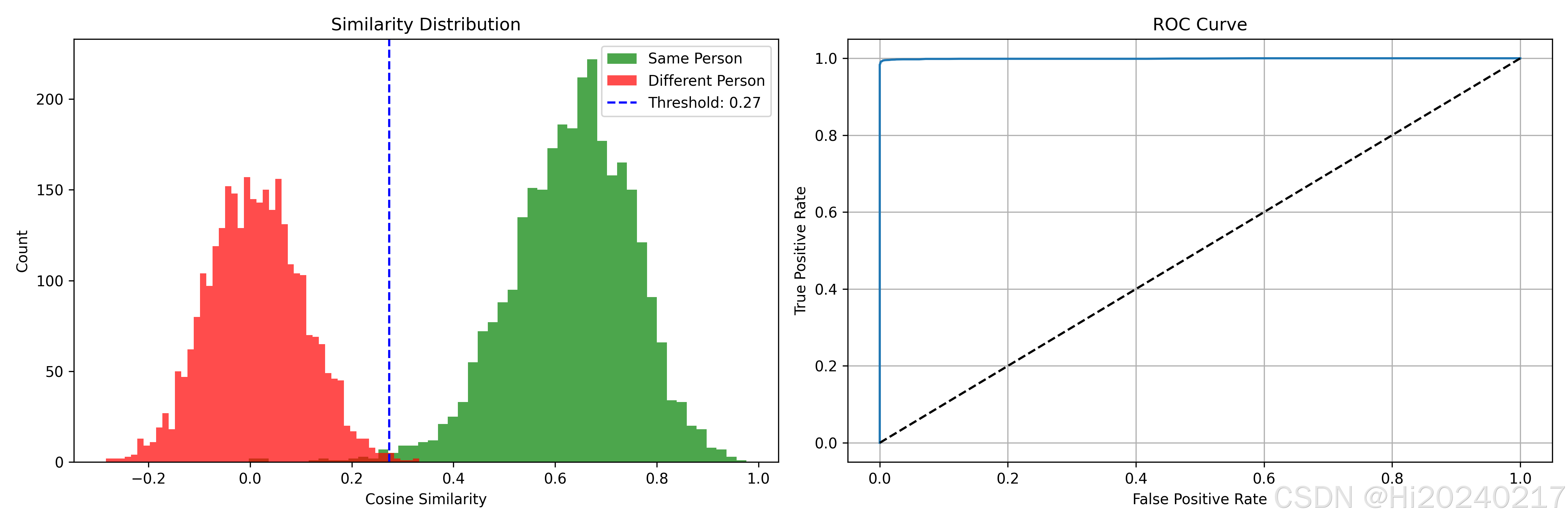
- 左图:正负样本相似度分布
理想情况:同人相似度>0.4,不同人<0.2- 右图:ROC曲线
曲线越靠近左上角,模型性能越好(AUC>0.99为优秀)
三、环境搭建
请参考: 在RK3588上实现YOLOv8n高效推理
四、模型获取与转换
4.1 获取源代码
git clone https://github.com/TreB1eN/InsightFace_Pytorch.git
cd InsightFace_Pytorch
4.2 下载预训练模型(model_ir_se50.pth)
- model_ir_se50.pth @ BaiduNetdisk
4.2 下载LFW人脸对齐后的测试集并解压(lfw112.tar.gz)
- lfw112.tar.gz @ BaiduNetdisk
4.3 PyTorch转ONNX
cat> torch2onnx.py <<-'EOF'
from model import Backbone, Arcface, MobileFaceNet, Am_softmax, l2_norm
import torchmodel = Backbone(50,0.6, 'ir_se').eval()
model.load_state_dict(torch.load("model_ir_se50.pth",map_location=torch.device('cpu')))dummy_input = torch.randn(1, 3, 112, 112)
torch.onnx._export(model, dummy_input.to("cpu"),"face_rec.onnx", export_params=True, verbose=False,opset_version=11)
EOF
python3.10 torch2onnx.py
为什么需要ONNX中间格式?
ONNX(Open Neural Network Exchange)是通用的模型交换格式:
- 解决框架差异(PyTorch/TensorFlow等)
- 标准化模型结构,便于后续优化
- 支持跨平台部署(RKNN/TensorRT等)
4.4 ONNX转RKNN量化模型
cat> onnx2rknn.py <<-'EOF'
import os
import numpy as np
import cv2
from rknn.api import RKNN
from math import expONNX_MODEL = 'face_rec.onnx'
RKNN_MODEL = 'face_rec.rknn'
is_quant=1rknn = RKNN(verbose=True)
rknn.config(mean_values=[[127.5,127.5,127.5]],std_values=[[127.5,127.5,127.5]], target_platform='rk3588')
ret = rknn.load_onnx(model=ONNX_MODEL)
if ret != 0:print('Load model failed!')exit(ret)
ret = rknn.build(do_quantization=is_quant, dataset='./dataset.txt',auto_hybrid=True)
if ret != 0:print('Build model failed!')exit(ret)
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:print('Export rknn model failed!')exit(ret)rknn.release()
EOF
find lfw112/ -name "*.jpg" | head -n 32 > dataset.txt
python3.10 onnx2rknn.py
量化原理:
量化将FP32权重转换为INT8格式:
原始范围:[-2.3, 5.1] → 映射到:0~255
缩放系数 = 255 / (5.1 - (-2.3)) ≈ 34.5
优势:
- 模型体积缩小75%(4字节→1字节)
- 内存带宽需求降低
- NPU运算速度提升3-5倍
注意事项:
- 使用真实数据(
dataset.txt中的图片)校准量化参数 - 避免使用纯色/无意义图片导致量化误差
五、精度验证
5.1 LFW数据集说明
Labeled Faces in the Wild(LFW)是权威人脸识别测试集:
- 包含5749个人的13,233张面部图像
- 提供6000对正负样本(3000对相同/3000对不同人)
- 测试结果可横向对比学术论文
5.2 精度测试
cat> lfw_evaluation.py <<-'EOF'
import os
import time
import matplotlib
matplotlib.use('agg')
import numpy as np
from PIL import Image
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
from tqdm import tqdm
import cv2
import time
import numpy as np
from rknnlite.api import RKNNLiteclass FaceRec(object):def __init__(self):RKNN_MODEL = 'face_rec.rknn'self.rknn_lite = RKNNLite()ret = self.rknn_lite.load_rknn(RKNN_MODEL)if ret != 0:print('Load RKNN model failed')exit(ret)ret = self.rknn_lite.init_runtime(core_mask=RKNNLite.NPU_CORE_AUTO)if ret != 0:print('Init runtime environment failed')exit(ret)self.model_width=112self.model_height=112self.count=0def get_embedding(self,orig_img): img_rgb = cv2.cvtColor(orig_img, cv2.COLOR_BGR2RGB)blob = img_rgb.astype(np.uint8)blob = blob[np.newaxis]t0=time.time()outputs = self.rknn_lite.inference(inputs=[blob],data_format=['nhwc'])t1=time.time()self.count+=1if self.count==10:print(f"Infer Time:{(t1-t0)*1000:.4f} ms")return outputs[0][0]# LFW数据集路径配置
LFW_DIR = "lfw112/aligned"
PAIRS_FILE = "lfw112/pairs.txt"def load_lfw_pairs(pairs_filepath):"""加载LFW pairs.txt文件返回格式: [(path1, path2, same_flag), ...]"""pairs = []with open(pairs_filepath, 'r') as f:for line in f.readlines()[1:]: # 跳过标题行pair = line.strip().split()if len(pair) == 3:# 相同人name, id1, id2 = pairpath1 = os.path.join(LFW_DIR, name, f"{name}_{id1.zfill(4)}.jpg")path2 = os.path.join(LFW_DIR, name, f"{name}_{id2.zfill(4)}.jpg")pairs.append((path1, path2, 1))elif len(pair) == 4:# 不同人name1, id1, name2, id2 = pairpath1 = os.path.join(LFW_DIR, name1, f"{name1}_{id1.zfill(4)}.jpg")path2 = os.path.join(LFW_DIR, name2, f"{name2}_{id2.zfill(4)}.jpg")pairs.append((path1, path2, 0))return pairsdef load_and_preprocess_image(image_path):"""加载并预处理图像返回PIL.Image对象 (RGB格式)"""img = cv2.imread(image_path) return imgdef compute_cosine_similarity(emb1, emb2):"""计算两个特征向量之间的余弦相似度"""return np.dot(emb1, emb2) / (np.linalg.norm(emb1) * np.linalg.norm(emb2))def evaluate_lfw(model, pairs, batch_size=32):"""在LFW数据集上评估模型参数:model: 人脸识别模型实例pairs: LFW对列表 [(path1, path2, same_flag), ...]batch_size: 批处理大小返回:accuracy: 平均准确率thresholds: 最佳阈值列表similarities: 所有对的相似度分数labels: 所有对的真实标签"""similarities = []labels = []thresholds = []# 进度条pbar = tqdm(total=len(pairs), desc="Processing pairs")# 分批处理for i in range(0, len(pairs), batch_size):batch_pairs = pairs[i:i+batch_size]batch_embs1 = []batch_embs2 = []# 加载并提取特征for path1, path2, label in batch_pairs:try:img1 = load_and_preprocess_image(path1)img2 = load_and_preprocess_image(path2)emb1 = model.get_embedding(img1)emb2 = model.get_embedding(img2)batch_embs1.append(emb1)batch_embs2.append(emb2)labels.append(label)except Exception as e:print(f"Error processing {path1} or {path2}: {str(e)}")continue# 计算相似度for emb1, emb2 in zip(batch_embs1, batch_embs2):sim = compute_cosine_similarity(emb1, emb2)similarities.append(sim)pbar.update(len(batch_pairs))pbar.close()# 转换为numpy数组similarities = np.array(similarities)labels = np.array(labels)# 10折交叉验证寻找最佳阈值kf = KFold(n_splits=10, shuffle=True)accuracies = []for train_idx, test_idx in kf.split(similarities):train_sims = similarities[train_idx]train_labels = labels[train_idx]# 寻找最佳阈值best_threshold = 0best_accuracy = 0for threshold in np.arange(-1.0, 1.0, 0.01):preds = (train_sims > threshold).astype(int)acc = accuracy_score(train_labels, preds)if acc > best_accuracy:best_accuracy = accbest_threshold = threshold# 在测试集上评估test_sims = similarities[test_idx]test_labels = labels[test_idx]test_preds = (test_sims > best_threshold).astype(int)test_acc = accuracy_score(test_labels, test_preds)accuracies.append(test_acc)thresholds.append(best_threshold)# 计算平均准确率mean_accuracy = np.mean(accuracies) * 100mean_threshold = np.mean(thresholds)return mean_accuracy, mean_threshold, similarities, labelsdef plot_results(similarities, labels, threshold):"""绘制相似度分布和ROC曲线"""# 相似度分布图plt.figure(figsize=(15, 5))plt.subplot(1, 2, 1)same_sims = similarities[labels == 1]diff_sims = similarities[labels == 0]plt.hist(same_sims, bins=50, alpha=0.7, label='Same Person', color='green')plt.hist(diff_sims, bins=50, alpha=0.7, label='Different Person', color='red')plt.axvline(x=threshold, color='blue', linestyle='--', label=f'Threshold: {threshold:.2f}')plt.xlabel('Cosine Similarity')plt.ylabel('Count')plt.title('Similarity Distribution')plt.legend()# ROC曲线plt.subplot(1, 2, 2)tpr_list = []fpr_list = []thresholds = np.arange(-1.0, 1.0, 0.01)for thresh in thresholds:preds = (similarities > thresh).astype(int)tp = np.sum((preds == 1) & (labels == 1))fp = np.sum((preds == 1) & (labels == 0))tn = np.sum((preds == 0) & (labels == 0))fn = np.sum((preds == 0) & (labels == 1))tpr = tp / (tp + fn) if (tp + fn) > 0 else 0fpr = fp / (fp + tn) if (fp + tn) > 0 else 0tpr_list.append(tpr)fpr_list.append(fpr)plt.plot(fpr_list, tpr_list)plt.plot([0, 1], [0, 1], 'k--') # 随机猜测线plt.xlabel('False Positive Rate')plt.ylabel('True Positive Rate')plt.title('ROC Curve')plt.grid(True)plt.tight_layout()plt.savefig('lfw_results.png', dpi=300)plt.show()if __name__ == "__main__":# 1. 初始化模型model = FaceRec()# 2. 加载LFW数据对print("加载LFW数据集...")pairs = load_lfw_pairs(PAIRS_FILE)print(f"加载完成! 共有 {len(pairs)} 对图像")# 3. 评估模型print("开始评估模型...")start_time = time.time()accuracy, threshold, similarities, labels = evaluate_lfw(model, pairs)elapsed = time.time() - start_time# 4. 打印结果print("\n" + "="*50)print(f"LFW测试结果:")print(f"平均准确率: {accuracy:.2f}%")print(f"最佳阈值: {threshold:.4f}")print(f"总耗时: {elapsed:.2f}秒")print("="*50)# 5. 可视化结果print("生成结果可视化...")plot_results(similarities, labels, threshold)print("结果图已保存为 'lfw_results.png'")
EOF
pip3.10 install scikit-learn -i https://mirrors.aliyun.com/pypi/simple/
python3.10 lfw_evaluation.py