生成式人工智能综述1——文本生成
0.序言
题外话——最近忙着做多模态GraphRAG的项目,好久没更新博客了。RAG现在似乎比之前更火热了,应该得益于其便于落地的优势,很容易和各种实际项目结合。之前写的博客似乎对大家了解和部署GraphRAG有一定帮助,之后会陆续更新多模态GraphRAG具体实现的技术博客,现在可以在github上搜索MMGraphRAG找到项目代码和论文。
最近生成式人工智能这个名词频繁出现,也是一个炙手可热的新方向。这篇文章将首先从整体介绍生成式人工智能的具体定义和现状。
1.定义阐述
生成式人工智能,或称生成式AI,英文是Generative Artificial Intelligence,缩写为GenAI或者GAI,是一种人工智能系统,能够产生文字、图像或其他媒体以回应提示工程(prompt),比如ChatGPT(Generative Pre-trained Transformer)。
没错,生成式人工智能实际上对应的英文缩写应该是GAI。那么我们常听到的AIGC又是什么呢?
它其实是Artificial Intelligence-Generated Content的缩写,是继专业生产内容(PGC,Professional-generated Content)、用户生产内容(UGC,User-generated Content)之后的新型内容创作方式。
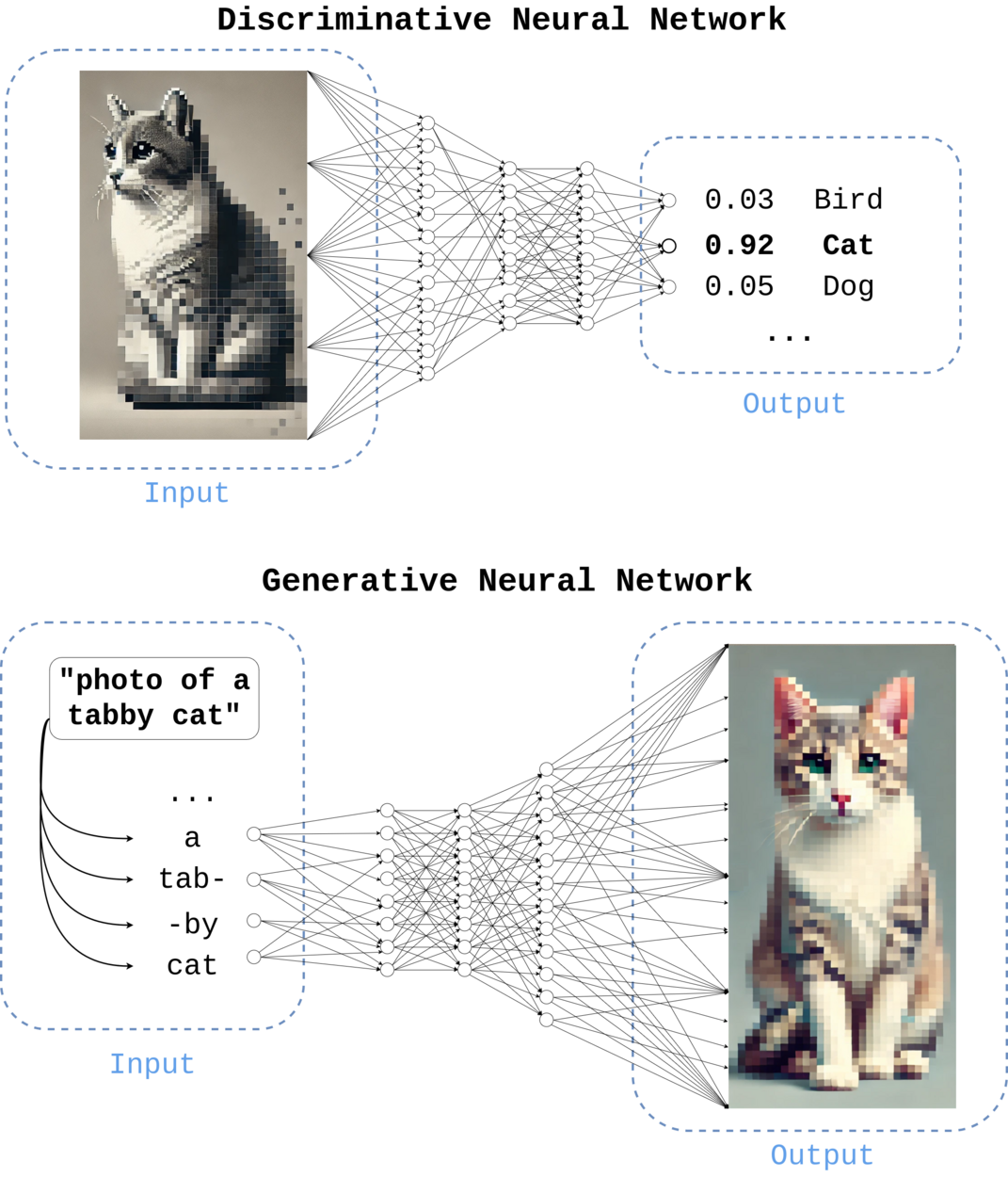
这也就是说我们常用的大语言模型(LLM)本身也属于生成式人工智能的一部分,是文字生成。泛泛来讲,可以根据输入的提示工程自主生成内容的都可以成为生成式人工智能。所谓的生成是为了与传统机器学习的分类与预测等任务做区分(生成式模型与判别式模型)。用下面这张wiki上盗的图可以更好的理解其概念。
从数学的角度来讲,生成式模型学习数据的联合分布,即输入特征
和目标标签
的联合概率;而判别式模型直接学习条件概率
,即在给定特征
的条件下,预测标签
的概率。
目前这一领域的综述不是很多,最新的A Survey of AI-Generated Content (AIGC)是2023年A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT这篇论文的再放送。总的来说,我认为可以按照生成内容的模态来进行分类。虽然定义里总是说提示工程(prompt),这其实几乎限定了输入为文本。所以文生图是常见的一种说法,与此同时还有图生图,可以把它们统一算作图像生成。我认为这样分类会清晰很多。
接下来我将分四个板块来介绍生成模型,按照生成的结果来划分,分为文本,图像,视频和声音生成,至于更复杂的虚拟现实和三维模型暂时就不列入讨论范围了。每个模块分为过去,现在和未来三个部分,重点了解“过去怎么做,现在能做到什么,未来会去做什么”。至于具体的原理细节(也就是“现在”)和补充知识则会每个板块另开新的博客来写,具体到文本生成模型的话就是从attention和transformer讲起。
2.文本生成
这里我们首先通过自然语言处理(NLP)任务的分类强化对于生成模型的概念理解。自然语言生成 (NLG) 和自然语言理解 (NLU) 是NLP系统的两大基本组成部分,但它们各有不同的用途。
自然语言理解 (NLU)是机器以有价值的方式理解、解释和从人类语言中提取有意义信息的能力。它涉及情感分析、命名实体识别、词性标注和解析等任务。NLU 可帮助机器理解人类语言输入的上下文、意图和语义。
自然语言生成 (NLG) 是指机器生成清晰、简洁且引人入胜的人类文本或语音的能力。它涉及文本摘要、讲故事、对话系统和语音合成等任务。NLG 帮助机器以人类容易理解的方式生成有意义且连贯的响应。
NLU 专注于理解人类语言,而 NLG 专注于生成类似人类的语言。两者对于构建高级 NLP 应用程序都至关重要,这些应用程序能以自然且有意义的方式与人类进行有效通信。
目前我们调用LLM的过程其实偏向于完整的NLP任务,既要理解用户的prompt(NLU),又要针对性的生成回答(NLG)。
2.1文本生成的过去
在过去部分我们来了解在transformer出现前文本生成是如何实现的。类似的文章我也阅读了不少,可是最近因为LLM“辅助”的泛滥,我对不少知识的可靠性产生了严重的怀疑。下面的知识我尽量的比对并核实了,选取了相对可信度最高的说法(论文,维基百科等)。
2.1.1基于规则的文本生成
生成文本的过程可以简单到取用已准备好的章句,再用连结的文字组合起来。在简单的领域如占星机器或个人化商业信件,成果可能令人满意。不过复杂的自然语言生成系统必须经过规划以及合并资讯的步骤,从而生成看似自然并且避免重复的文本。自然语言生成典型的步骤,例如戴尔与瑞特[Dale, Robert; Reiter, Ehud. Building natural language generation systems. Cambridge, U.K.: Cambridge University Press. 2000. ISBN 0-521-02451-X.]所提出的如下:
决定内容:决定在文本里置入哪些资讯。用后面的花粉预报软件为例,是否要明确提到东南部花粉级数为7。
架构文件:所传达资讯的整体组织。例如决定先描述高花粉量地区,再提及低花粉量地区。
聚焦语句:合并类似的句子,让文本更可读、更自然。例如合并下两个句子“星期五花粉等级已从昨天的中级到今天的高级”和“全国大部分地区的花粉等级在6到7”成为“星期五花粉等级已从昨天的中级到今天的高级,全国大部分地区的数值在6到7。”
选择字词:选用表达概念的文字。例如决定要用“中等”还是“中级”。
指涉语生成:产生能辨认物体或地区的指涉语。例如用“北方岛屿和苏格兰东北角”指涉苏格兰的某个地区。这个任务也包括决定代名词以及其它的照应语。
实现文本:根据句法学、构词学、正写法的规则产生实际的文本。
“苏格兰花粉预报系统”就是一个基于版型的简单自然语言生成系统。该系统利用苏格兰几个区域花粉预报的六个输入数目,生成简短的花粉等级文本作为输出。
例如使用2005年7月1日的历史资料,该软件的输出:
星期五花粉等级已从昨天的中级到今天的高级,全国大部分地区的数值在6到7。不过北部是中级,数值为4。
对比实际的预报(气象员手拟)如下:
苏格兰大部分地区花粉量还是很高,为6级,东南部更是7级。只有北方岛屿及苏格兰东北角情况舒缓,花粉量中等。
2.1.2基于统计的文本生成
基于统计的方法我们介绍n-gram。至于NLP中常见的条件随机场(CRF)以及隐马尔可夫模型常用在分词任务中,实际上并不用在生成部分,这里就不展开了。关于NLP任务的完整流程可以参考下面的链接。
NLP与深度学习(一)NLP任务流程 - ZacksTang - 博客园
2.1.2.1 马尔可夫链
在介绍n-gram前,照例先来说一个应用更广泛的知识,也就是马尔可夫链,如果熟悉这部分知识的话可以直接跳到下一部分!
定义
马尔可夫链(英语:Markov chain),又称离散时间马尔可夫链(discrete-time Markov chain,缩写为DTMC),因俄国数学家安德烈·马尔可夫得名,为状态空间中经过从一个状态到另一个状态的转换的随机过程。该过程要求具备“无记忆”的性质:下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。这种特定类型的“无记忆性”称作马尔可夫性。
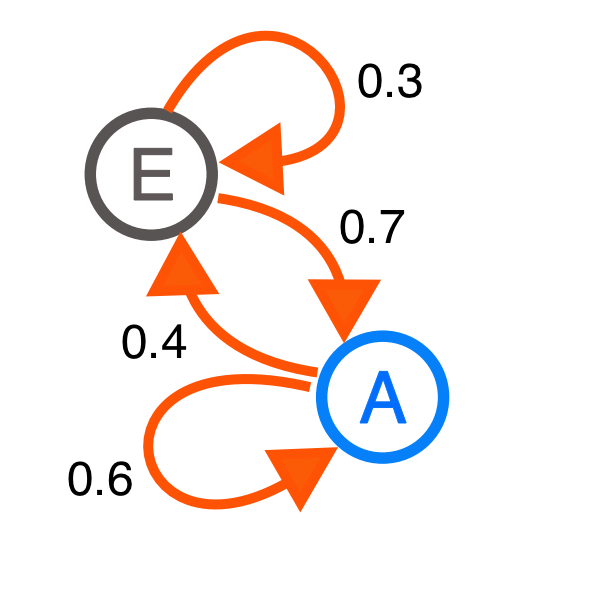
有了如上图的马尔可夫过程,在未知初始状态和终止状态时,我们该如何计算第n次转移后的状态概率呢?可以引入状态转移矩阵来简化步骤。
然后通过矩阵的方式计算概率,这里插入个有趣的内容,状态转移矩阵由一个非常重要的特性——稳定性,即经过有限次序列转换,最终可以得到一个稳定的概率分布,且与初始状态概率分布无关(任何初始概率分布均会得到一个稳定的概率分布)。这部分可以参考这下面篇博客。马尔科夫链及其平稳状态 - coshaho - 博客园
这个特点从物理学和化学上解释也许会更好理解一点。
比如分子的随机运动论。这个运动具有明显的“无记忆”性质,即下一步的运动只依赖于当前位置,而与之前的路径无关,从而符合马尔可夫性质。在微观尺度上,分子不断变化,运动是随机的,但整体系统——比如大量分子组成的气体或液体——表现出稳定的宏观性质。这个平衡状态对应于物理中的热力学平衡:分子的统计行为出现稳定的分布,系统整体不再发生宏观变化。
同样也可以考虑化学平衡:反应速率相等,浓度保持不变。
著名的网页排序算法PageRank就是马尔可夫链定义的。如果是已知的网页数量,一个页面
有
个链接到这个页面,那么它到链接页面的转换概率为
,到未链接页面的概率为
,参数
的取值大约为0.85。
2.1.2.2 n-gram
先用一句话来笼统的概括:第 n 个词的出现只与前面 n-1 个词相关,而与其它任何词都不相关。所以n-gram里的n其实就是以gram(字节片段,注意和token区分)为单位进行滑动窗口的窗口大小。
如果我们有一个由个词组成的序列(也就是句子),我们希望算得概率
,根据链式规则,可得
这个概率会因为m数量的增大而更难计算,那么这里我们可以采用马尔可夫链的假设,即当前这个词只跟前面几个有限的词相关,这样就可以得到n-gram的基本公式
而
可是这样其实会面临一个很大的问题,可能的gram(字节片段,或者说滑块)的种类数是词表的指数倍,比如n取2,gram的种类数就是词表的平方,n取3就是立方。所以n的取值很受限,n很大时,数据会过于稀疏;n更小时,则约束信息很少,不容易生成有逻辑的文本。
下面的代码通过n-gram实现了一个简单的文本生成。
import random
import jiebaclass NGramModel:def __init__(self, n=2):self.n = nself.ngrams = {}self.context_counts = {}def train(self, text):# 将文本拆分为词汇tokens = self.tokenize(text)# 创建 n-gramsfor i in range(len(tokens) - self.n):context = tuple(tokens[i:i+self.n-1])word = tokens[i+self.n-1]self.ngrams.setdefault(context, {})self.ngrams[context][word] = self.ngrams[context].get(word, 0) + 1self.context_counts[context] = self.context_counts.get(context, 0) + 1def tokenize(self, text):# 使用jieba进行中文分词return list(jieba.cut(text))def generate(self, seed, max_words=100):seed_tokens = self.tokenize(seed)if len(seed_tokens) < self.n - 1:# 如果不足n-1个词,补充空格或直接使用seed_tokens = [''] * (self.n - 1 - len(seed_tokens)) + seed_tokenselse:seed_tokens = seed_tokens[-(self.n - 1):]result = seed_tokens.copy()for _ in range(max_words):context = tuple(result[-(self.n - 1):]) if self.n > 1 else ()next_word = self.predict_next_word(context)if not next_word:breakresult.append(next_word)return ' '.join(result)def predict_next_word(self, context):if context not in self.ngrams:return Nonecandidates = self.ngrams[context]total = sum(candidates.values())rand = random.uniform(0, total)cumulative = 0# 遍历候选词,将每个词对应的频次累加,直到累计大于rand,返回该词,实现基于频次的随机选择for word, count in candidates.items():cumulative += countif rand <= cumulative:return wordreturn Noneif __name__ == "__main__":# 读取示例文本文件filename = "./示例文本.txt"with open(filename, 'r', encoding='utf-16') as f:text = f.read()# 创建并训练模型n = 2 # 选择n的值(比如2表示bigram,3表示trigram)model = NGramModel(n)model.train(text)# 提示用户输入半句话seed_phrase = input("请输入:")continuation = model.generate(seed_phrase, max_words=100)print("续写内容:", continuation)结果很有趣,首先是n取2时的结果。输入的内容均是“可爱的白雪”。
白雪 ”
knows 技术科 合并 为 零 , 音频 等 诸多方面 。 一 本书 处理 。
那天 生命 。 ‘ 机械 生命 在 里面 哦 。 耳边 很 柔和 的 眼睛 代替 。 可能 麻烦 一点 了 。 要 想起 了 灵台 前 我 和 我 还是 没 能 让 班上 其他人 我 和 白城 无力 而 让 后面 倒 和 你 去 配给 更 边缘 的 这个 世界 。 她 相信 的 “ 书 ’ 的 男孩子 , 那 就 像 缝纫 工匠 没有 任何 赞美 。 白雪 的
当n取3时:
的 白雪 伸出 了 手 。
白雪 叹 了 口气 , 脑子里 依旧 很 混乱 。
缓冲 层 , 白雪 推开 门 , 抬头 看 向 身边 的 , 若 无法 改变 就 只能 试着 去 理解 。 只有 教学楼 前 的 水池 边 , 站 起身 看 向 藏 在 黑夜 中 的 内容 清晰 了 , 还有 一种 特殊 的 ,
在 安乐死 制度 废除 的 安乐死 规定 的 年龄 上限 一样 。
雪 渐渐 变小 了 。
相约 离开 的 那天 ,
当n取4时:
可爱 的 白雪
很明显因为原文并没有出现这样的句子,所以预测直接终止了。
2.1.3基于神经网络的文本生成
这里的神经网络我们特指早期的因为要真的算起来,那都是“神经网络”,也就是RNN和LSTM,这两位就不展开做原理介绍了,直接介绍其在文本生成中的应用。
从原理上来说RNN和LSTM在文本生成上是一致的,只是LSTM是为了解决RNN的长程依赖问题提出的,效果要更好一些。本质上RNN和LSTM都是为了解决seq2seq(序列到序列)而发明的,重要代表就是机器翻译。
不过根据前面n-gram的学习,我们已经可以把文本生成(续写)一样抽象成一个seq2seq问题。比如提供这样的文本作为训练内容——“我今天想吃麦当劳”。
序列可以这样拆分,用“我今天想”去预测“今天想吃”,用“今天想吃”去预测“天想吃麦”。但是显然在中文中这样不是特别合适,所以和n-gram一样采用分词的方式,“我”,“今天”,“想”,“吃”,“麦当劳”单独作为词,然后为他们赋予各自的编号“01234”,继而用012去预测123的序列预测来实现文本生成。
下面是一个示例代码,可以根据自己的环境改一改参数试试。
import torch
import torch.nn as nn
import numpy as np
import jieba# 1. 读取文本
file_path = './示例文本.txt'
with open(file_path, 'r', encoding='utf-16') as f:text = f.read()# 2. 使用jieba分词(词级处理)
words = list(jieba.cut(text))
# 创建词表
unique_words = sorted(set(words))
word2idx = {w: i for i, w in enumerate(unique_words)}
idx2word = {i: w for i, w in enumerate(unique_words)}vocab_size = len(unique_words)# 3. 准备训练数据
max_seq_length = 3 # 根据文本长度调整
sequences = []
next_words = []for i in range(0, len(words) - max_seq_length):seq = words[i:i + max_seq_length]next_word = words[i + max_seq_length]sequences.append([word2idx[w] for w in seq])next_words.append(word2idx[next_word])X = torch.tensor(sequences, dtype=torch.long)
Y = torch.tensor(next_words, dtype=torch.long)# 4. 定义模型
class RNNModel(nn.Module):def __init__(self, vocab_size, embedding_dim=100, hidden_dim=256):super(RNNModel, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, vocab_size)def forward(self, x):x = self.embedding(x)out, _ = self.lstm(x)out = out[:, -1, :] # 取最后一个时间步out = self.fc(out)return outmodel = RNNModel(vocab_size)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)# 训练参数
batch_size = 128
epochs = 60
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()dataset = torch.utils.data.TensorDataset(X, Y)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)# 训练
for epoch in range(epochs):total_loss = 0for batch_x, batch_y in dataloader:batch_x, batch_y = batch_x.to(device), batch_y.to(device)optimizer.zero_grad()output = model(batch_x)loss = criterion(output, batch_y)loss.backward()optimizer.step()total_loss += loss.item()print(f"Epoch {epoch+1}/{epochs} - Loss: {total_loss/len(dataloader):.4f}")# 5. 文本续写(按词为单位)
def generate_text(seed_text, length=50):model.eval()# 先用jieba分词seed_words = list(jieba.cut(seed_text))result = seed_words.copy()for _ in range(length):# 构造输入序列input_words = result[-max_seq_length:]if len(input_words) < max_seq_length:input_words = ['']*(max_seq_length - len(input_words)) + input_words # 填充空字符串input_idx = [word2idx.get(w, 0) for w in input_words]input_tensor = torch.tensor([input_idx], dtype=torch.long).to(device)with torch.no_grad():output = model(input_tensor)probs = torch.softmax(output, dim=-1).cpu().numpy().flatten()next_idx = np.random.choice(vocab_size, p=probs)next_word = idx2word[next_idx]result.append(next_word)return ''.join(result)# 使用示例
partial_sentence = input("请输入:")
print("生成结果:", generate_text(partial_sentence, length=100))进行了60轮训练,
Epoch 56/60 - Loss: 0.4524
Epoch 57/60 - Loss: 0.4500
Epoch 58/60 - Loss: 0.4502
Epoch 59/60 - Loss: 0.4483
Epoch 60/60 - Loss: 0.4479
之后同样输入“可爱的白雪”,生成的结果如下:
可爱的白雪。
“嗯,好吧。”
那是形状扭曲了的辅助臂,头顶又转起了圈圈,升降台的指示灯亮了一下但又灭了。方块坐在了地上,光照在他的眼前。
父亲先是很惊讶,然后轻轻坐在床边。在银心情不好的时候,每栋建筑小小的窗里会发出微弱的光,其他部分是空白的。
百年后
比起n-gram的结果似乎更好一些,开始像模像样了,┓( ´∀` )┏。当然这里(包括n-gram,神经网络甚至随机都没有)我们用了贪婪的搜索方法,所以,如果用其他搜索方法(就是选择下一个预测结果,贪婪就是选当前这一步概率最大的)可能获得更好的结果。目前只关注基础原理的理解,所以不再深入了。
2.2文本生成的现在
在这部分我们不展开讲解原理,而是注重了解现在最新的模型可以做到什么,具体的评估指标。文本生成的原理将和其他模态的原理一样独自开新的篇章。
2.2.1 模型原理
更完整的历史演变过程可以参考这篇文章,介绍非常详细,从transformer(2017)一直到deepseek-r1(2025)。
https://medium.com/@lmpo/大型语言模型简史-从transformer-2017-到deepseek-r1-2025-cc54d658fb43
现在的模型是从tranformer框架开始的,这里其实有一个值得一提的点,前面的n-gram和神经网络方法都是默认从前向后进行预测的,因为这符合人类语言的逻辑。不过transformer是把句子打碎,深入了解每个词之间的关系,并不在乎位置。transformer需要单独的位置编码来显示地表示词序。乍一看这样很不直观,但仔细考虑的话这是符合语言规律的。
transformer最大的特点就是词之间的关系大大提升了信息量,摆脱了前后联系的非必要性带来的干扰(比如actually的位置),注重的是什么情况下会使用actually而不是它前面是谁,这种单一的推理模式。首先确立的是句子中的主谓宾的结构和内容,同时再用位置编码学习语法顺序。
然后是BERT(使用transformer的编码器)和GPT(使用transformer的解码器)的提出。
2.2.1.1 Bidirectional Encoder Representations from Transformers
与之前单向处理文本(从左到右或从右到左)的模型不同,BERT采用了双向训练方法,使其能够同时从两个方向捕获上下文。通过生成深层次的、上下文丰富的文本表示,BERT在文本分类、命名实体识别(NER)、情感分析等语言理解任务中表现出色。
其中一个关键就是提出了掩码语言建模(Masker Language Modeling — MLM):BERT不是预测序列中的下一个词,而是被训练预测句子中随机掩码的标记。这迫使模型在进行预测时考虑整个句子的上下文 — — 包括前后词语。例如,给定句子“The cat sat on the [MASK] mat”,BERT会学习根据周围上下文预测 [MASK]是“soft”。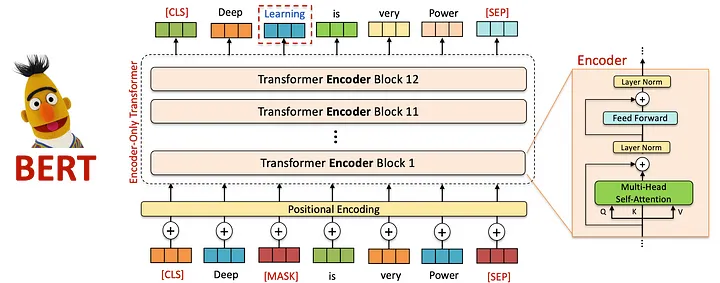
2.2.1.2 GPT:生成式预训练和自回归文本生成
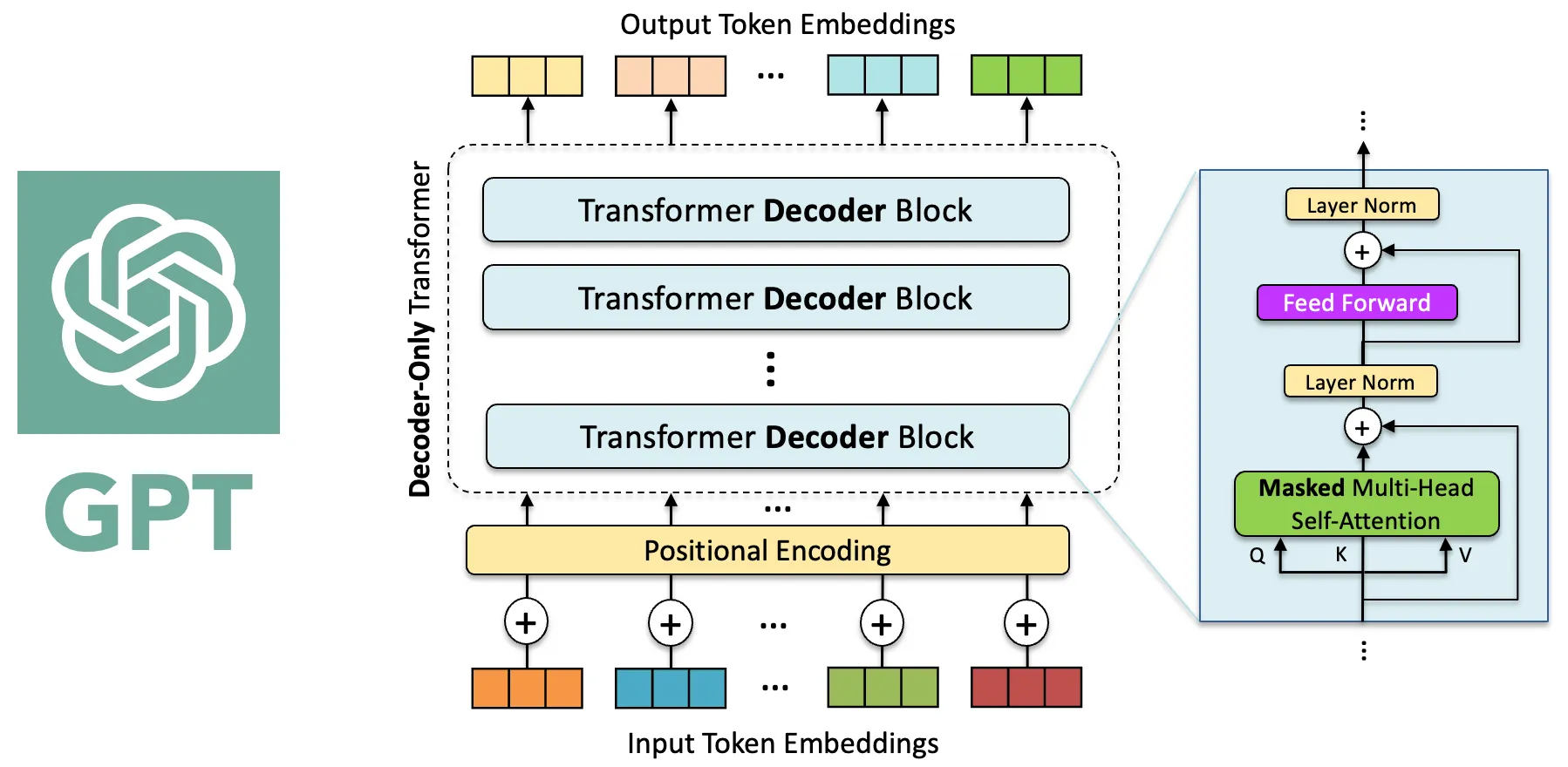
与BERT不同,Generative Pre-trained Transformer只使用了transformer的解码器。
预训练:在预训练阶段,模型使用大规模的无标注文本数据进行训练,以学习语言的统计规律和生成能力。通过自回归的方式,模型预测输入序列中的下一个token,并最大化在训练数据上的似然性。
具体来说,模型在生成每个Token时,只能依赖前面已经生成的Token,不会访问后续内容。这是在生成文本时非常关键的,因为模型需要“猜测”哪个Token最可能出现在当前位置。
以概率的角度,训练目标是最大化训练集中每个序列出现的概率,或者说,给定前面所有tokens,模型预测当前位置token的概率尽可能高。数学上,就是通过最大化似然函数来实现的。
微调:在微调阶段,模型使用特定任务的标注数据进行训练,以适应各种NLP任务。通过在模型的顶部添加适当的输出层,并使用任务特定的目标函数进行训练,模型能够学习将输入文本映射到特定任务的输出空间。
GPT-2于2019年2月发布,相较于前代实现了重大升级,参数量达到15亿,并在40GB多样化的互联网文本上进行训练。GPT-2引入了突破性的零样本学习能力,能够在不进行任务特定微调的情况下完成诸如撰写文章、回答问题、摘要生成和翻译等任务。
GPT-2证明了扩大模型规模和训练数据的重要性,以此生成高质量、类似人类的文本,同时展现出多任务处理能力。
于是开启了“大”模型时代。
GPT-3于2020年6月发布,凭借其惊人的1750亿参数彻底改变了人工智能领域,成为当时规模最大的语言模型。
之后比较重要的改进就是基于人类反馈的强化学习 (RLHF)的引入。
与需要人类编写完整输出的SFT不同,RLHF涉及根据质量对多个模型生成的输出进行排名。这种方法允许更高效的数据收集和标注,显著增强了可扩展性。
RLHF过程包括两个关键阶段:
训练奖励模型:人类注释者对模型生成的多个输出进行排名,创建一个偏好数据集。这些数据用于训练一个奖励模型,该模型学习根据人类反馈评估输出的质量。
使用强化学习微调LLM:奖励模型使用近端策略优化(Proximal Policy Optimization - PPO)(一种强化学习算法)指导LLM的微调。通过迭代更新,模型学会了生成更符合人类偏好和期望的输出。
这个两阶段过程 — — 结合SFT和RLHF — — 使模型不仅能够准确遵循指令,还能适应新任务并持续改进。通过将人类反馈整合到训练循环中,RLHF显著增强了模型生成可靠、符合人类输出的能力,为AI对齐和性能设定了新标准。
基于GPT-3.5和InstructGPT,OpenAI于2022年11月推出了ChatGPT,这是一种突破性的对话式AI模型,专门为自然的多轮对话进行了微调。ChatGPT的关键改进包括:
1.对话聚焦的微调:在大量对话数据集上进行训练,ChatGPT擅长维持对话的上下文和连贯性,实现更引人入胜和类似人类的互动。
2.RLHF:通过整合RLHF,ChatGPT学会了生成不仅有用而且诚实和无害的响应。人类培训师根据质量对响应进行排名,使模型能够逐步改进其表现。
2.2.2 模型参数
这部分我只详细介绍参数量的计算方式,也就是我们常见的7b,72b,这些值是怎么得到的。下面这篇文章在此基础上还介绍了计算量(FLOPs)、中间激活值与KV cache等。
https://zhuanlan.zhihu.com/p/624740065
transformer模型由l个相同的层组成,每个层分为两部分:self-attention和MLP。
self-attention部分模型参数有Q、K、V的权重矩阵,
,
和偏置,输出权重矩阵
和偏置,四个权重矩阵的形状为
,四个偏置的形状为
。所以这部分的参数量为
。
MLP由两个线性层组成,一般来说第一个线性层是先将维度从h映射到4h,第二个线性层再将维度从4h映射到h。因此第一个线性层的权重矩阵的形状为,偏置的形状为
。第二个线性层权重矩阵的形状为
,偏置形状为
。所以这部分的参数量为
。
self-attention和MLP各有一个layer normalization,包含两个可训练模型参数:缩放参数和平移参数,形状都是。因此2个layer normalization的参数量总共为
。
这样总共算下来一共是。除此之外,词嵌入矩阵的参数量也比较多,词向量维度通常等于隐藏层维度h,词嵌入矩阵的参数量为
。
因此l层transformer模型的可训练模型参数量为,当隐藏维度h较大时,可以忽略一次项,因此模型参数量近似为
。
接下来以LLaMA模型为例。
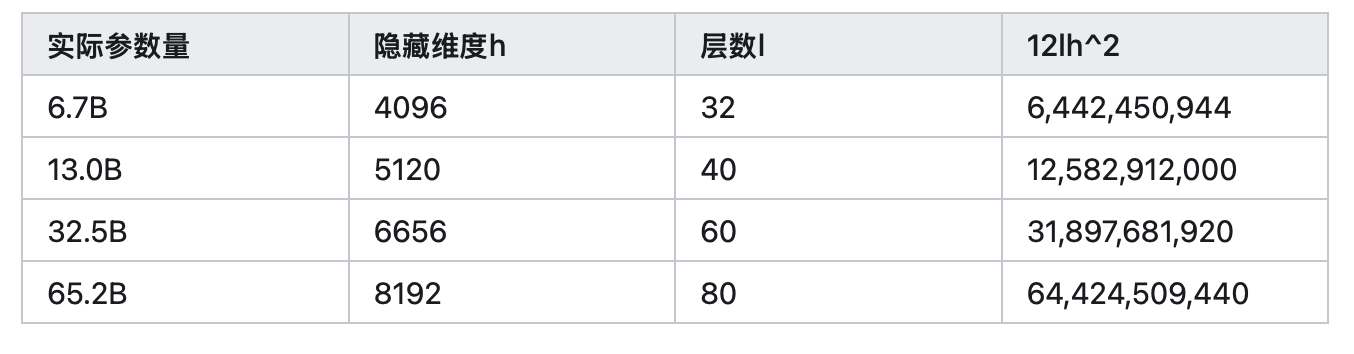
2.2.3 评估指标
随着模型不断推陈出新,评测方法和评估指标也在不断快速迭代更新着,不过总的来说离不开这三类(客观性评测、基于人的主观性评测、基于模型的评测),以此为基础去理解各种评估指标对于看懂越来越快更新的模型技术报告来说很有价值。
客观性评测:有标准答案可对比,适合“对错”或“是非”的判断,如分类、问答、翻译等;
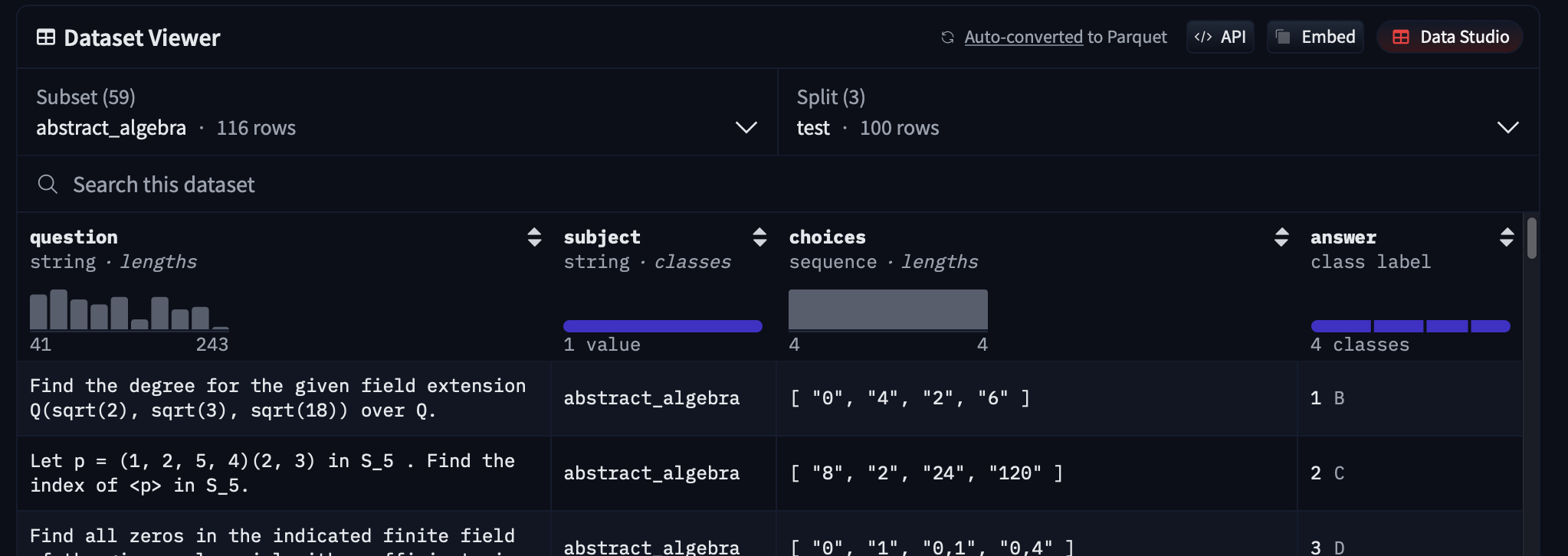
比如最常见的MMLU数据集。
MMLU(大规模多任务语言理解)是一种新的基准,旨在通过在zero-shot和few-shot设置中专门评估模型来衡量在预训练期间获得的知识。这使得基准更具挑战性,更类似于我们评估人类的方式。该基准涵盖 STEM、人文科学、社会科学等 57 个科目。它的难度从初级到高级专业水平不等,它考验着世界知识和解决问题的能力。科目范围从传统领域,如数学和历史,到更专业的领域,如法律和道德。主题的粒度和广度使基准测试成为识别模型盲点的理想选择。
这读起来很麻烦,但它本身是一个多选问答任务,如下图所示。
基于人的主观性评测:没有唯一标准,需要评委主观感受,如写作风格、表达效果、创意度等;
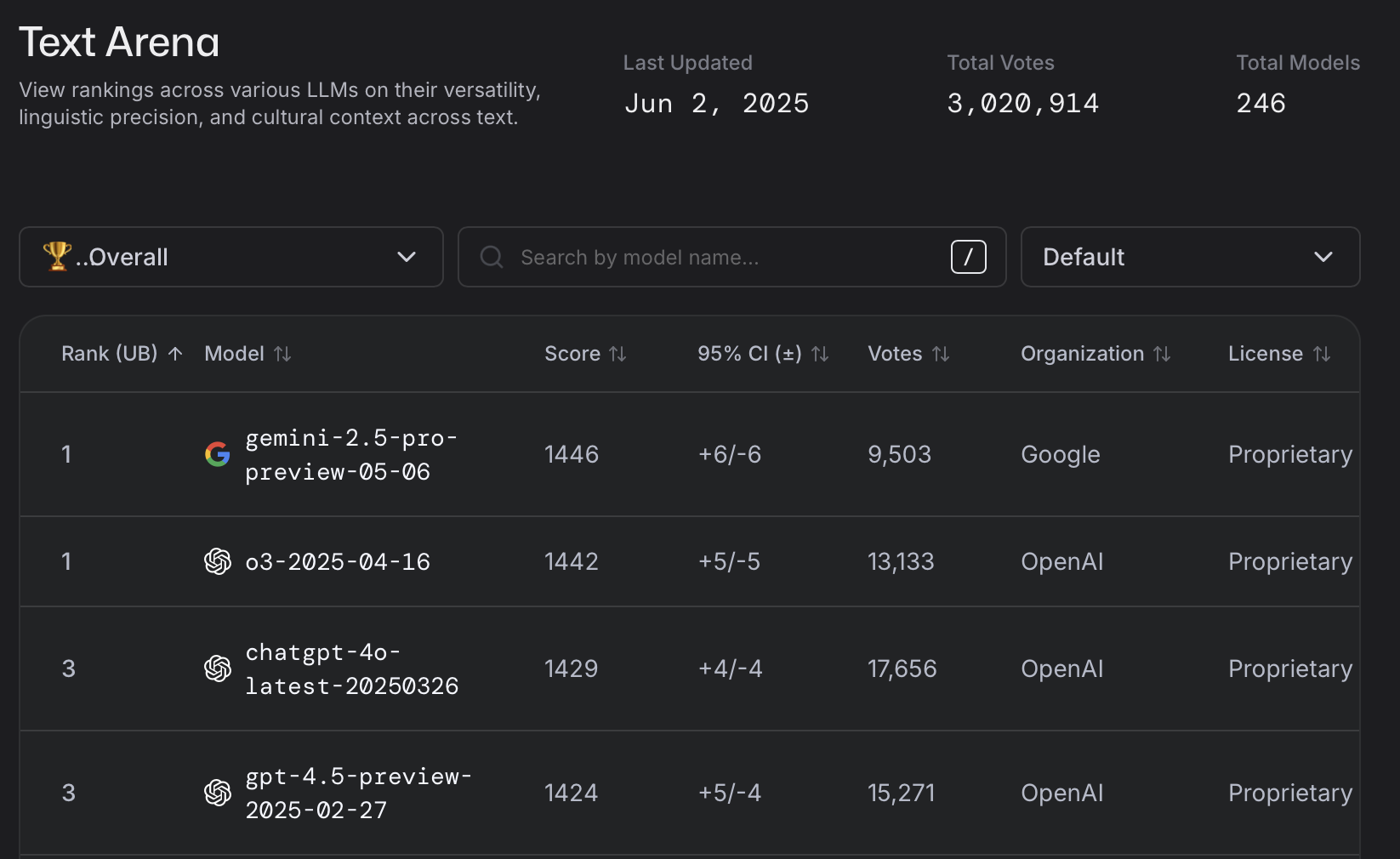
比较出名的就是Chatbot Arena(或者说LM Arena)。
24年3月来自UCBerkeley、斯坦福和UCSD的论文“Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference”推出 Chatbot Arena,一个基于人类偏好评估 LLM 的开放平台。换句话说就是用科学的方法,让用户同时跟两个(匿名)模型对话,然后投票给更好的那个。
25年6月的榜单如下,已经累积了300万以上的投票结果了。
基于模型的评测:用更强或专门的模型来评估被测模型输出,可减轻人力负担,但依赖评测模型自身的可靠性。
PandaLM是一个专门用于评估大模型性能的裁判大模型。github地址如下GitHub - WeOpenML/PandaLM
优点就是全自动,且相较于人工有很强的可复现性。
2.2.4 现在“最强”的大语言模型们
目前新模型有几个特点,部分采用MoE框架,具备推理能力,以及同时支持更多模态。
2.2.4.1 MoE框架
专家混合模型(Mixture of Experts, MoE)作为一种新兴的架构,通过条件计算和稀疏激活机制,成功地在保持大规模参数的同时,显著降低了计算成本。
接下来我来简要介绍一下,主要参考以下三篇文章。
https://huggingface.co/blog/zh/moe
Applying Mixture of Experts in LLM Architectures | NVIDIA Technical Blog
50张图,直观理解混合专家(MoE)大模型 - OSCHINA - 中文开源技术交流社区
那么,究竟什么是一个混合专家模型 (MoE) 呢?作为一种基于 Transformer 架构的模型,混合专家模型主要由两个关键部分组成:
稀疏 MoE 层: 这些层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE 层包含若干“专家”(例如 8 个),每个专家本身是一个独立的神经网络。在实际应用中,这些专家通常是前馈网络 (FFN),但它们也可以是更复杂的网络结构,甚至可以是 MoE 层本身,从而形成层级式的 MoE 结构。
门控网络或路由: 这个部分用于决定哪些令牌 (token) 被发送到哪个专家。例如,在下图中,“More”这个令牌可能被发送到第二个专家,而“Parameters”这个令牌被发送到第一个专家。有时,一个令牌甚至可以被发送到多个专家。令牌的路由方式是 MoE 使用中的一个关键点,因为路由器由学习的参数组成,并且与网络的其他部分一同进行预训练。
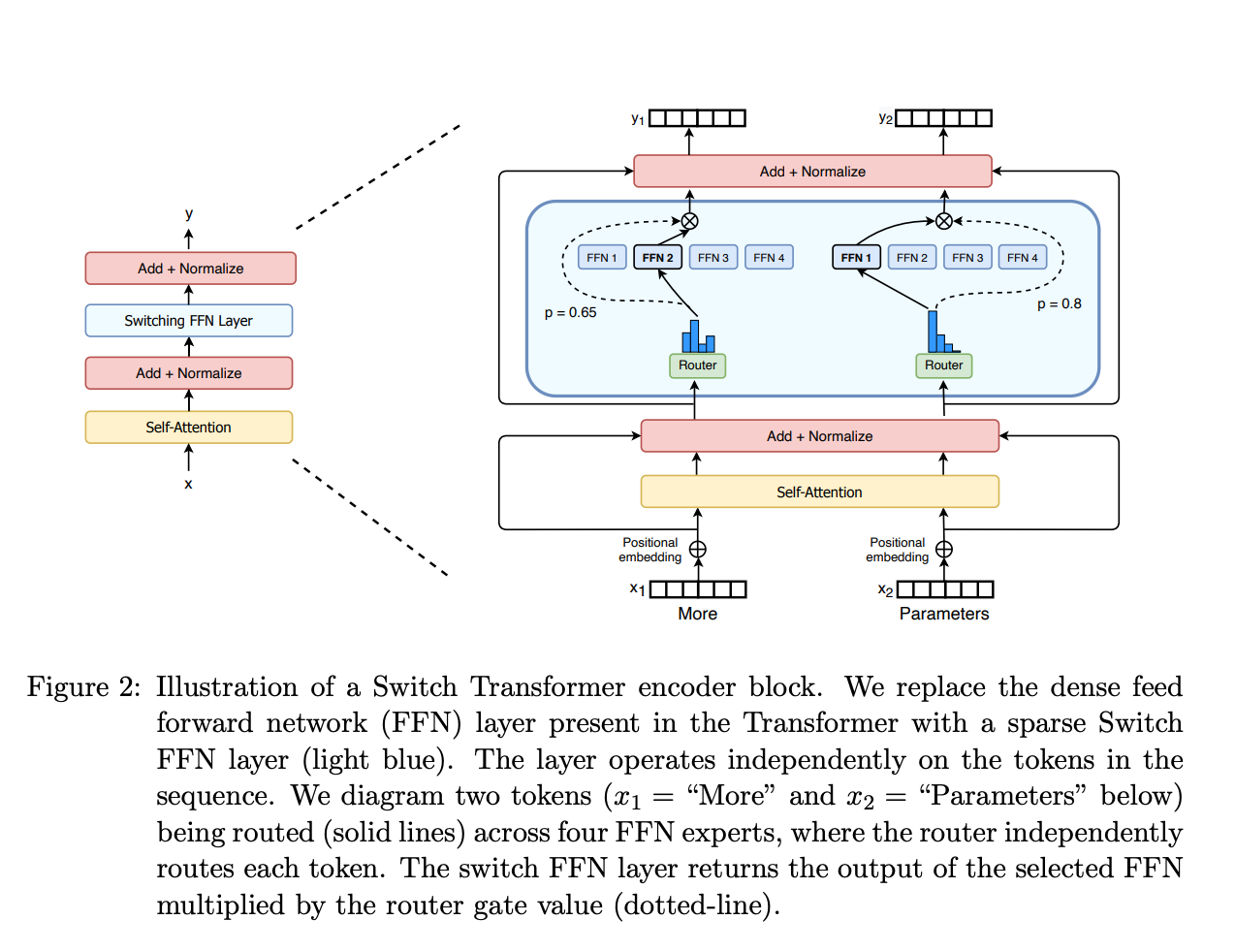
总结来说,在混合专家模型 (MoE) 中,我们将传统 Transformer 模型中的每个前馈网络 (FFN) 层替换为 MoE 层,其中 MoE 层由两个核心部分组成: 一个门控网络和若干数量的专家。
需要注意的是,“专家” 并不专注于特定领域,如 “心理学” 或 “生物学”。专家在学习过程中最多只能掌握关于单词层面的句法信息:

更具体地说,专家的专长是在特定上下文中处理特定词元。
这样多层的结构就可以这样进行抽象。
transformer的FFNN 使模型能够利用由注意力机制创建的上下文信息,进一步转化以捕捉数据中更复杂的关系。在这个过程中通常会扩展接收到的输入。
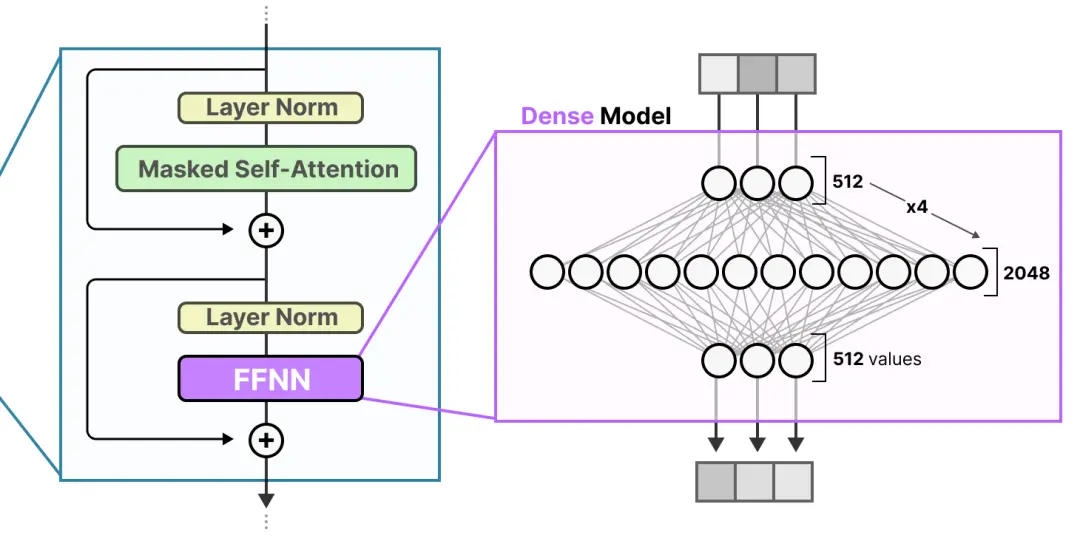
这样的FFNN被称为密集模型,因为所有参数(权重和偏置)都会被激活。

相比之下,稀疏模型仅激活其总参数的一部分,与混合专家密切相关。我们可以将密集模型分割成片段(即专家),重新训练,并在给定时间仅激活一部分专家:
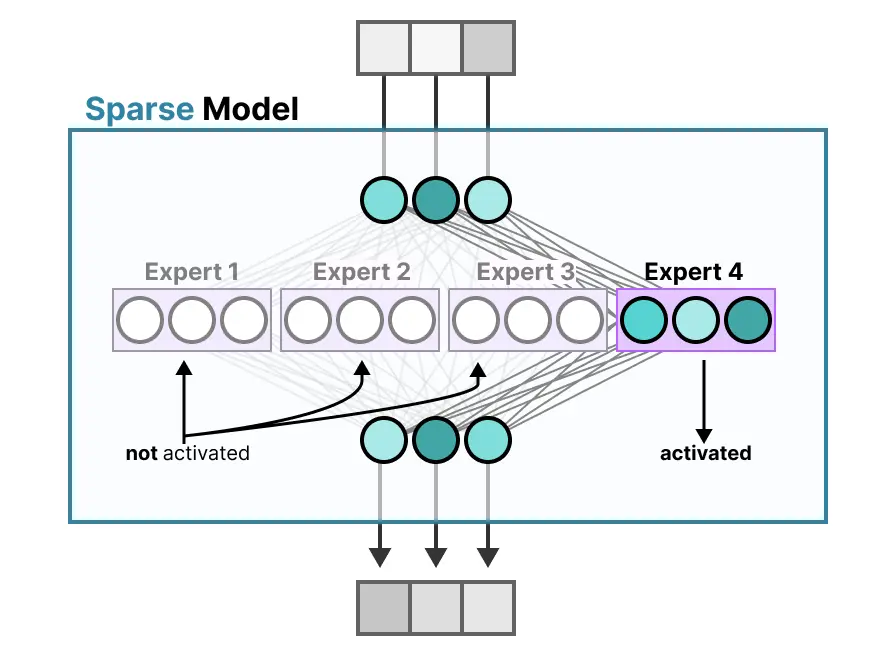
其基本思想是每个专家在训练过程中学习不同的信息。然后,在运行推理时,仅使用与特定任务最相关的专家。当收到问题时,我们可以选择最适合特定任务的专家。
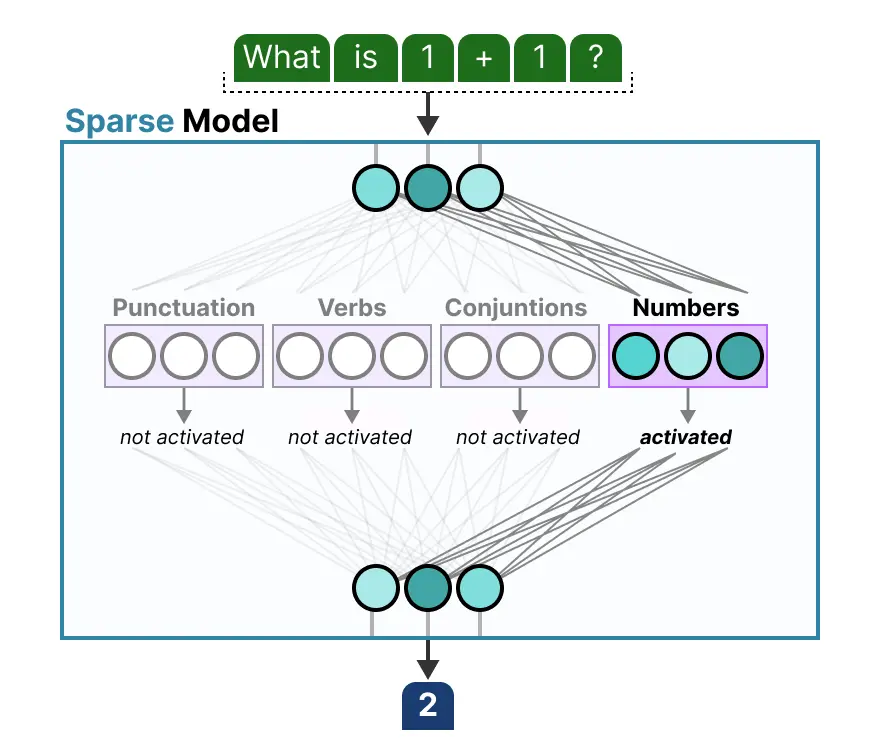
专家学习到的信息比整个领域的信息更加精细。因此,称它们为 “专家” 有时被视为误导。下面是ST-MoE论文中编码器模型的专家专业化。
然而,解码器模型中的专家似乎并没有同样类型的专业化。但这并不意味着所有专家都是平等的(具有相同的能力)。
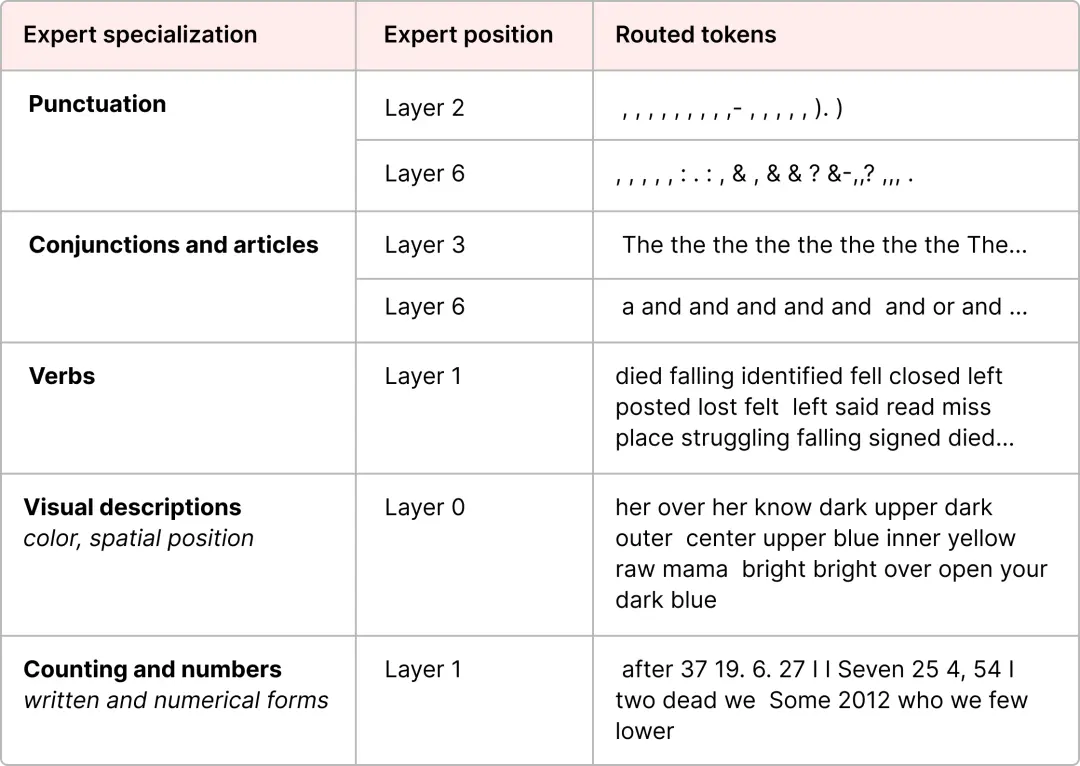
Mixtral 8x7B 论文中有一个很好的例子,其中每个token都标记了第一个专家的选择。

这一图片也表明,专家往往专注于句法而非特定领域。因此,尽管解码器专家似乎没有专业化,但它们似乎在特定类型的token上使用得相对一致。
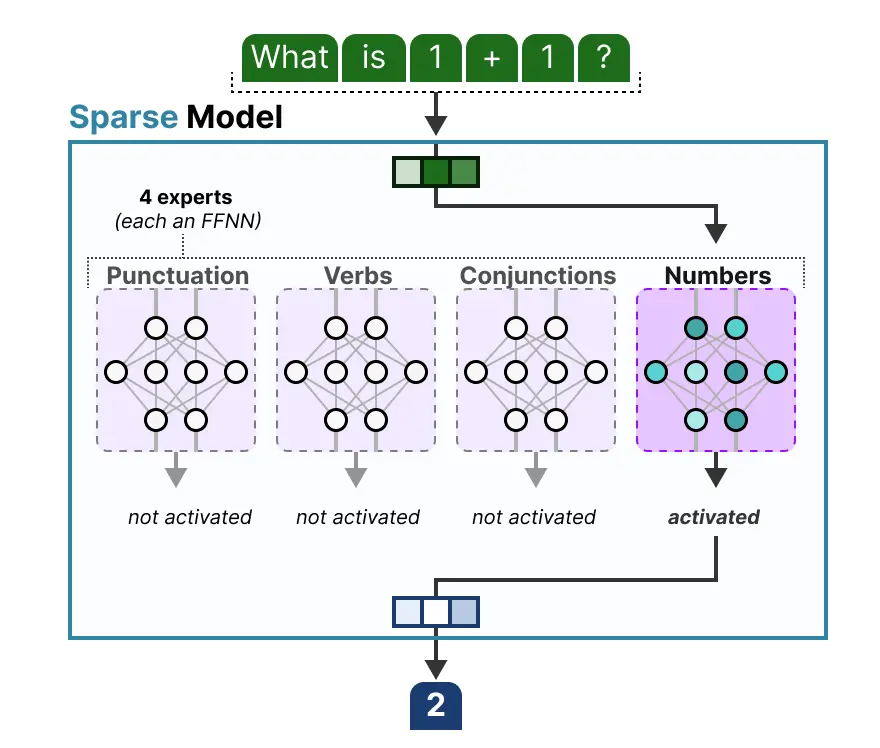
尽管将专家可视化为切成块的密集模型的隐藏层来理解很好,但它们通常是完整的 FFNN:
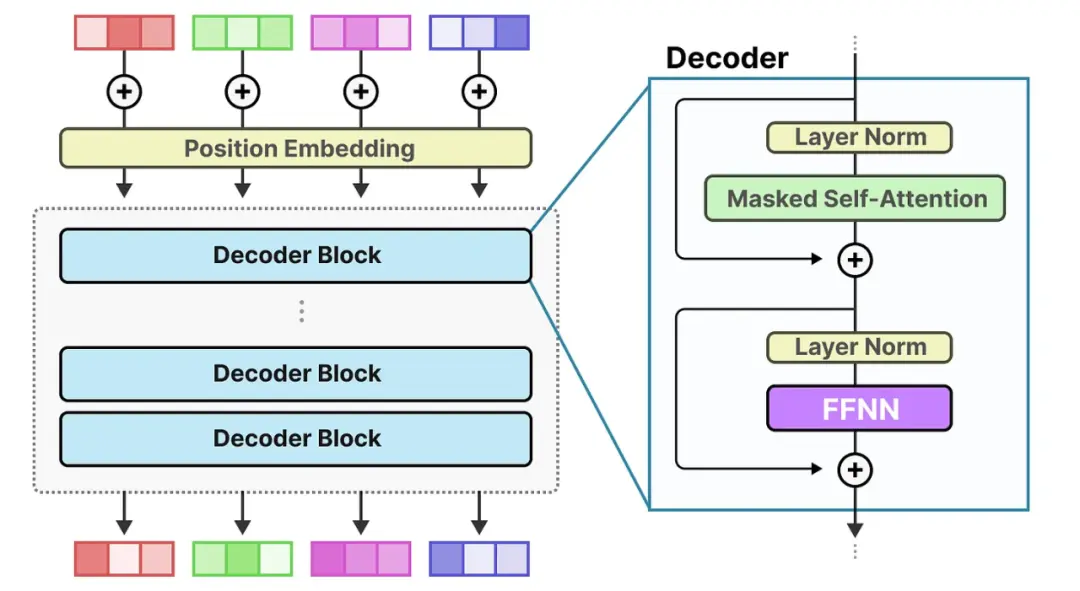
由于大多数 LLM 有多个解码器块,给定的文本在生成之前会经过多个专家:
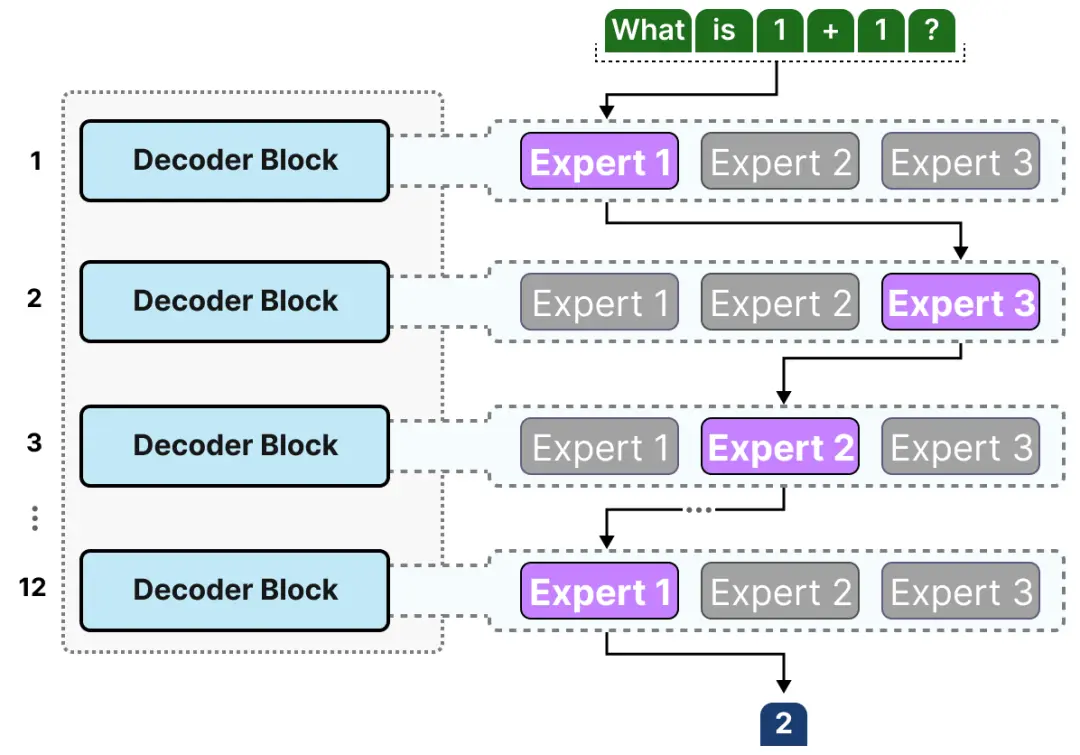
这样我们就可以更新解码器的图解为下图。
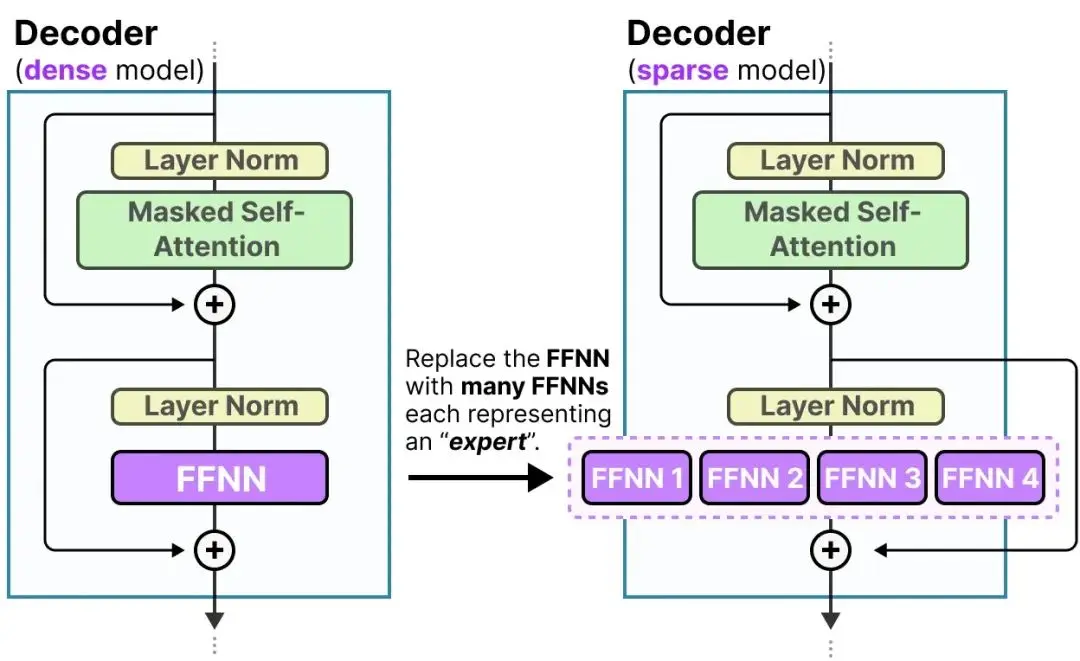
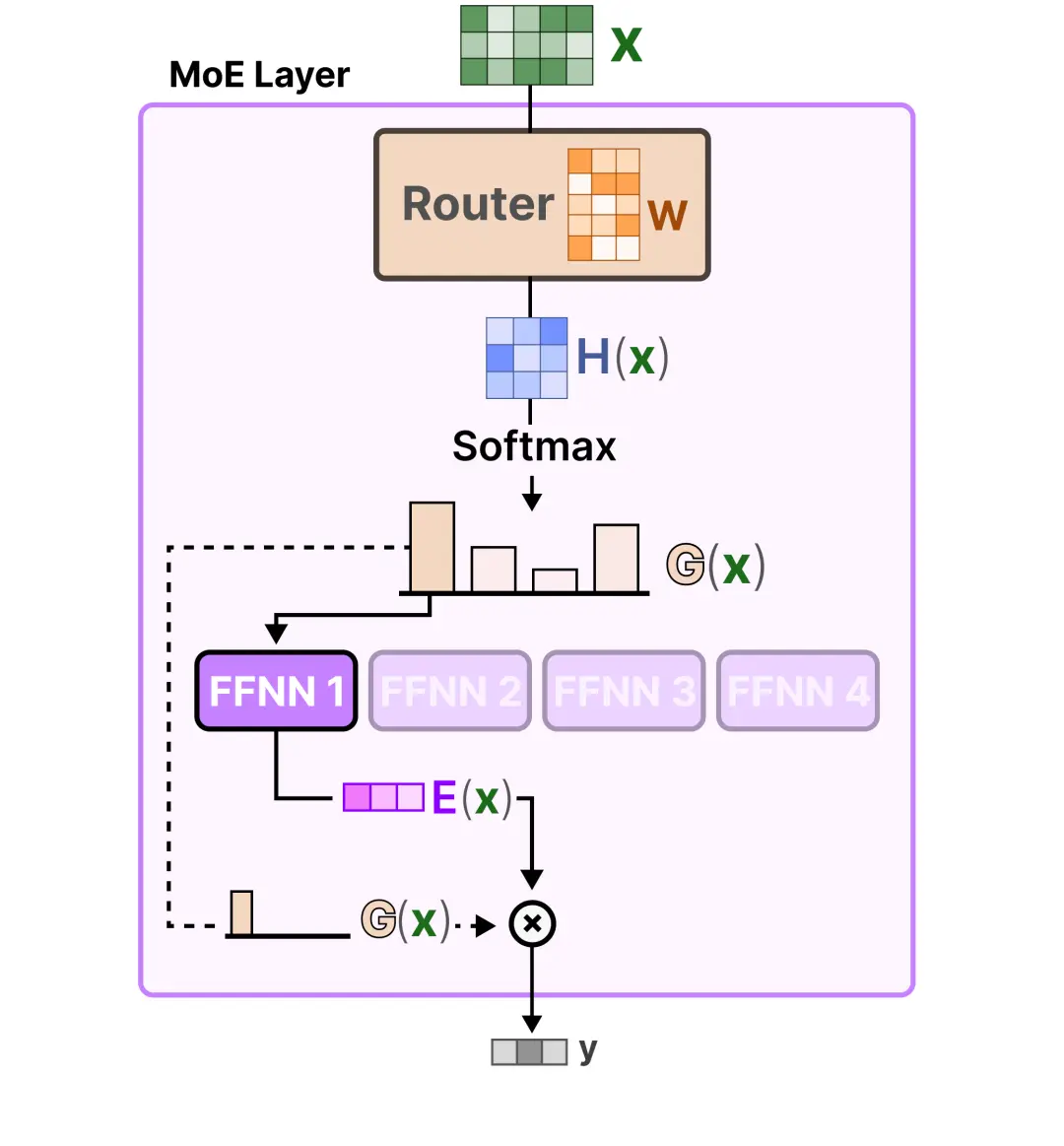
这样专家部分就基本解释清楚了,那么模型该如何知道使用哪些专家呢?在专家层之前添加一个路由(门控网络)就可以解决了,它是专门训练用来选择针对特定次元的专家。
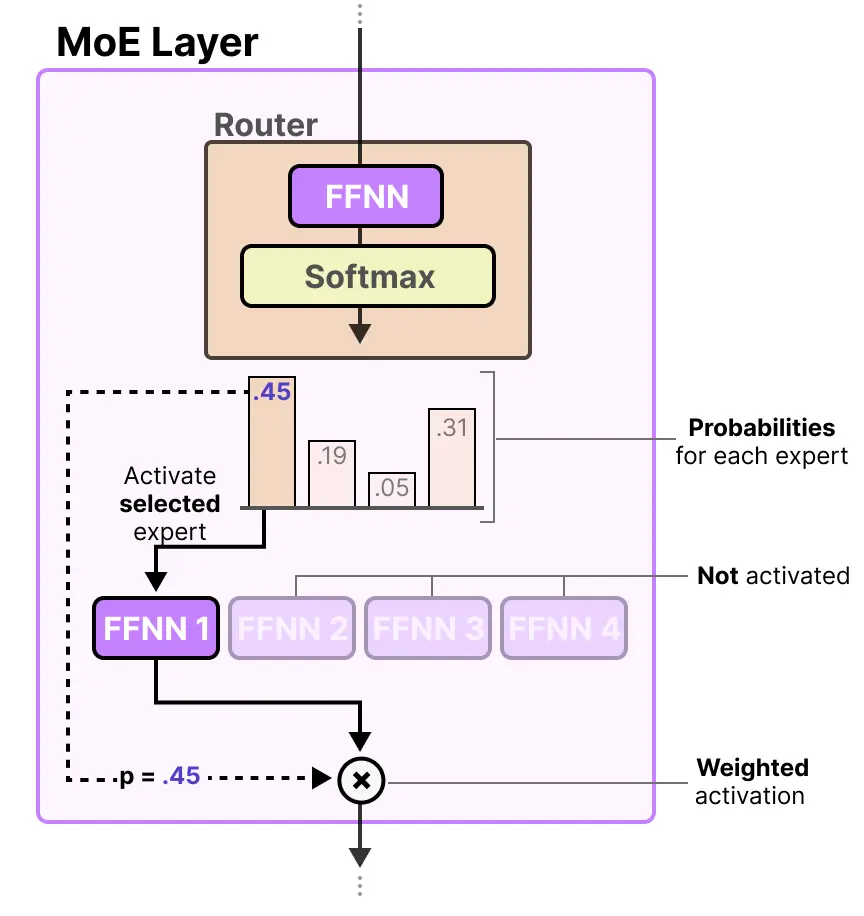
专家层返回所选专家的输出,乘以门控值(选择概率)。
MoE 层也有两种类型:稀疏混合专家或密集混合专家。两者都使用路由器来选择专家,但稀疏 MoE 仅选择少数专家,而密集 MoE 则选择所有专家,但可能在不同的分布中。
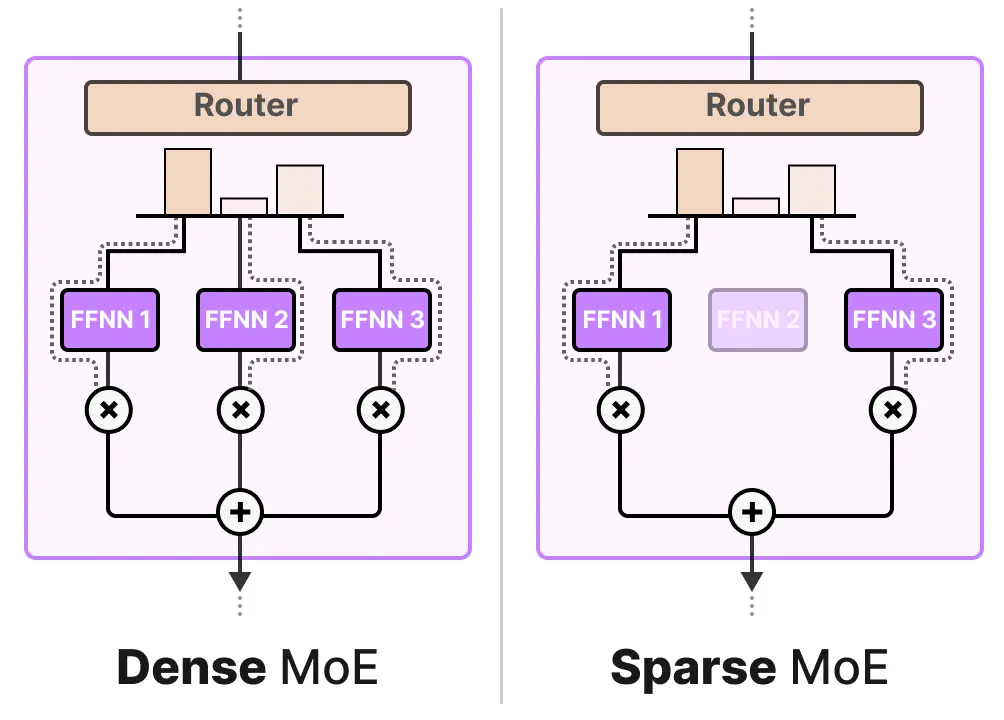
在当前的 LLM 状态下,当看到 “MoE” 时,通常指的是稀疏 MoE,因为它允许使用一部分专家。这在计算上更为经济(消耗的资源更少),这是 LLM 的重要特性。
那么专家选择具体是如何实现的呢?
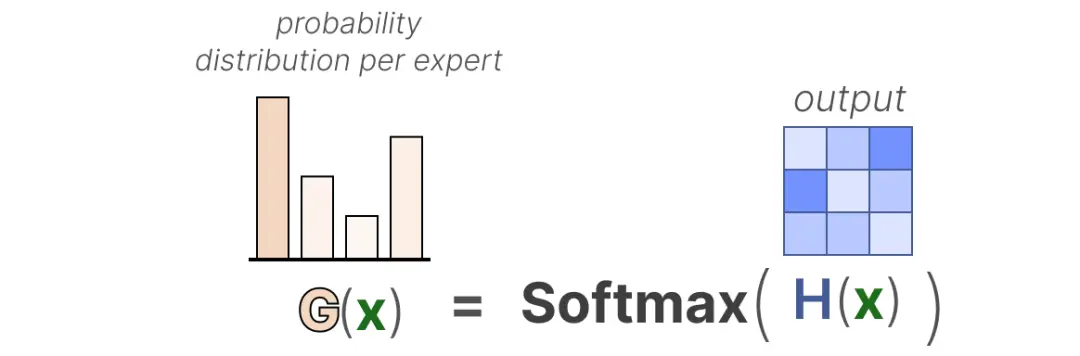
在最基本的形式中,我们将输入(x)乘以路由权重矩阵(W):
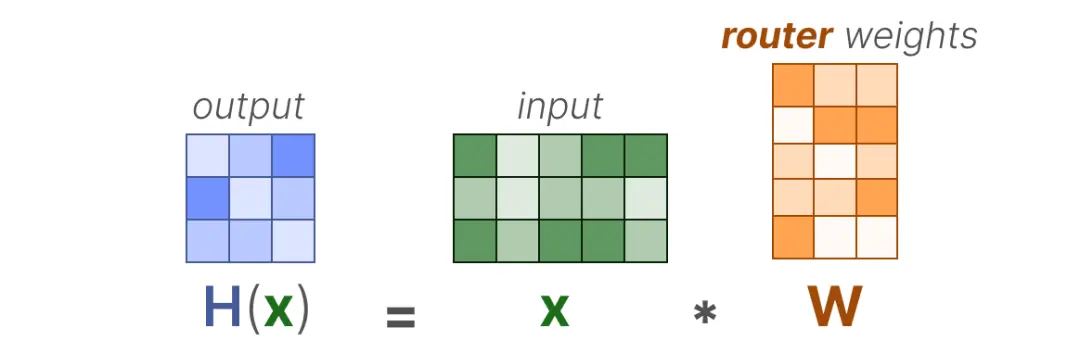
然后,我们对输出应用 SoftMax,创建每个专家的概率分布 G(x):
和专家部分结合在一起可以得到下面的矩阵流动图。
这样我们就大抵理解推理MoE推理过程了。但是训练过程中采用这个简单的函数通常导致路由器选择相同的专家,因为某些专家可能学习得比其他专家更快:
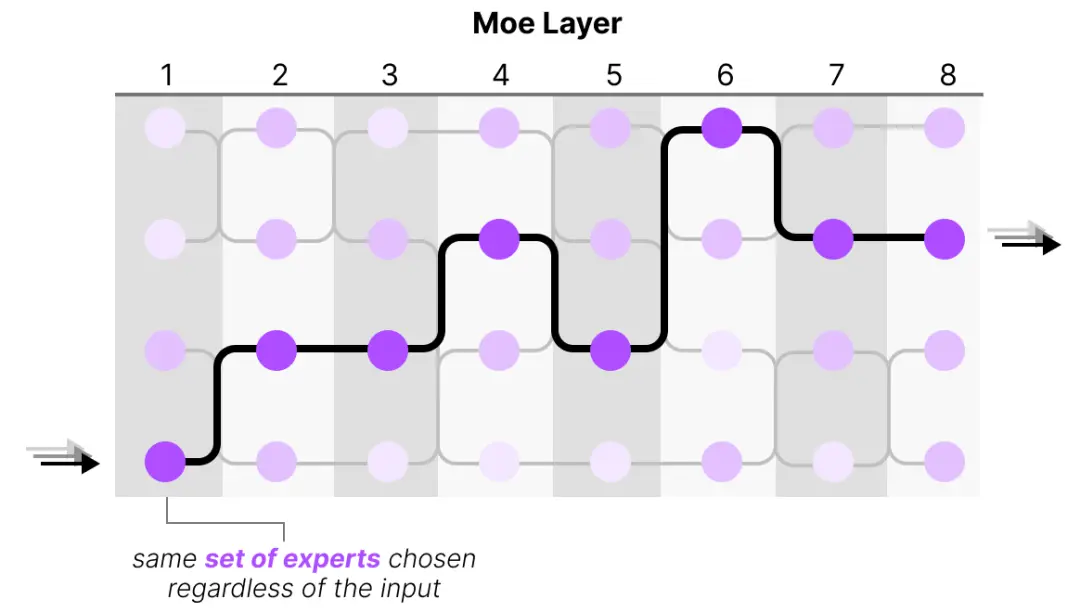
这不仅会导致选择的专家分布不均,而且一些专家几乎无法受到训练。这在训练和推理期间都会产生问题。相反,我们希望在训练和推理期间让专家之间保持均等的重要性,这称为负载均衡。这样可以防止对同一专家的过度拟合。
为平衡专家的重要性,我们需要把关注点放在路由上,因为它是在特定时间决定选用哪些专家的关键组件。对路由进行负载均衡的一种方式是借助 "KeepTopK"直接扩展。通过引入可训练的(高斯)噪声,可以避免重复选择相同的专家。
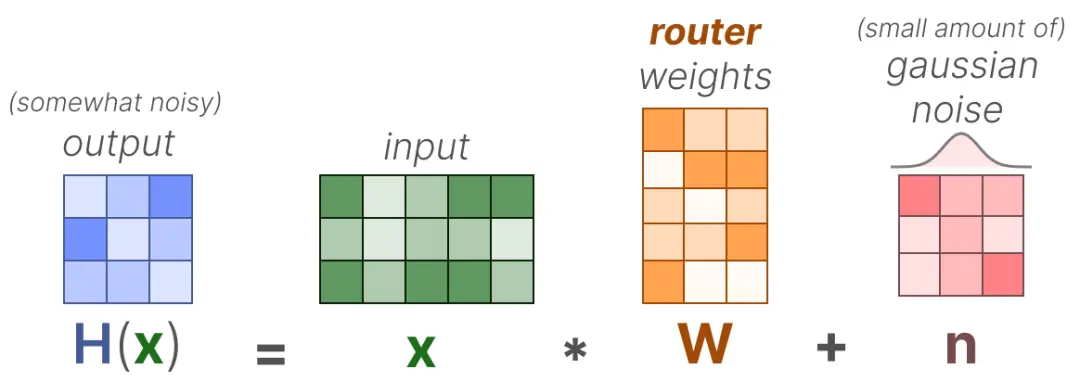
然后,除了想要激活的前 k 个专家(例 2)之外,其余专家的权重将被设置为 -∞:
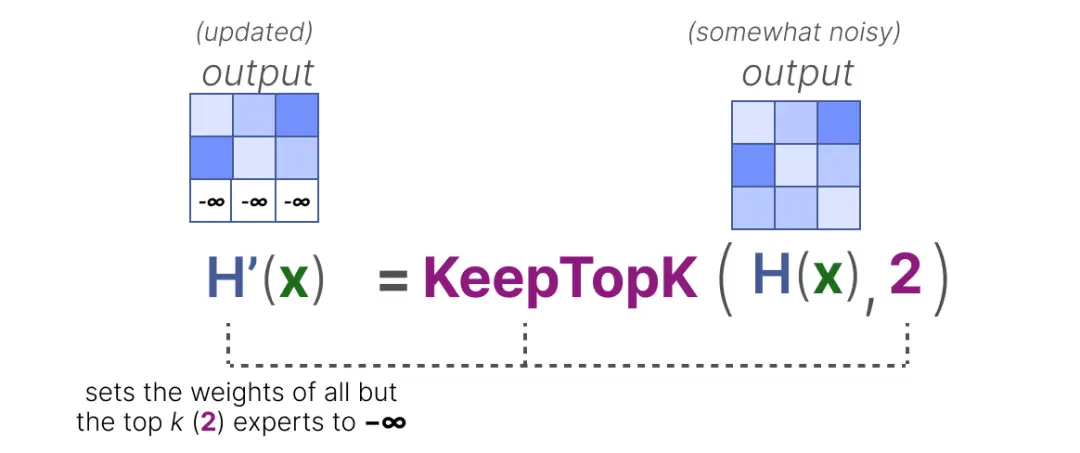
通过将这些权重设置为 -∞,这些权重上的 SoftMax 输出所产生的概率将会是 0:
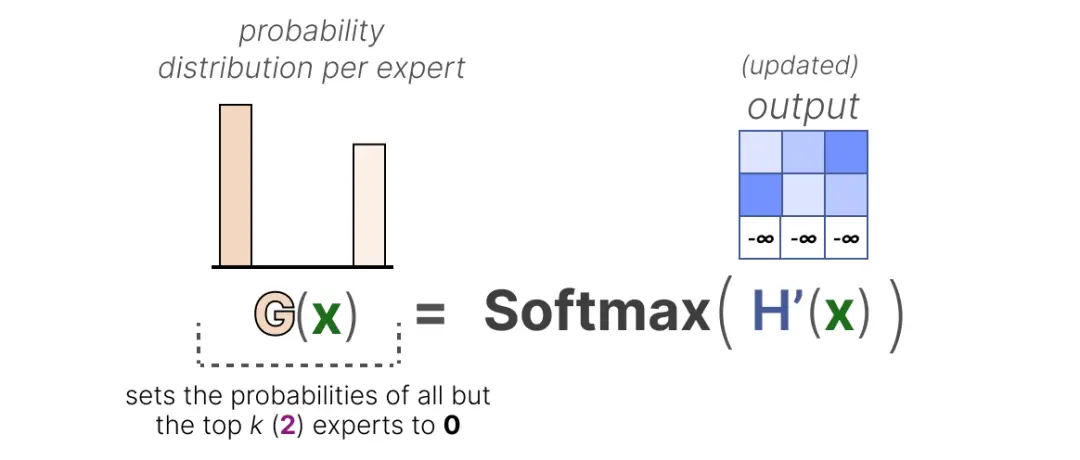
KeepTopK 策略将每个token路由到少数选定的专家。这种方法称为token选择,它允许将给定的词元发送给一个专家(top-1 路由)或多个专家(top-k路由)。
为了在训练期间使专家的分布更加均匀,辅助损失(也称为负载均衡损失)被添加到网络的常规损失中。它增加了一个约束条件,迫使专家具有同等的重要性。
这个辅助损失的第一个组成部分是对整个批次中每个专家的路由值进行求和:
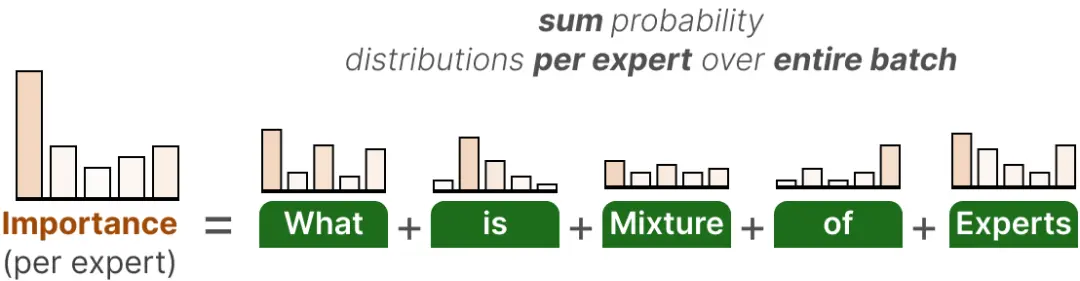
这为我们提供了每个专家的重要性得分,它代表了在任何输入下,给定专家被选中的可能性。
我们可以用这个来计算变异系数Coefficient Variation(CV),它告诉我们专家之间的重要性得分有多大差异。
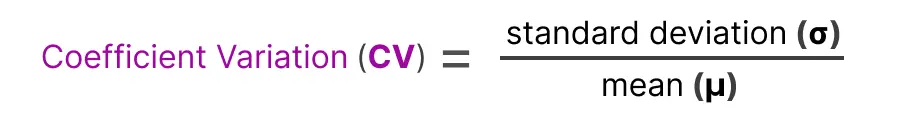
以防有人忘记标准差的计算公式,在下面贴出来了:
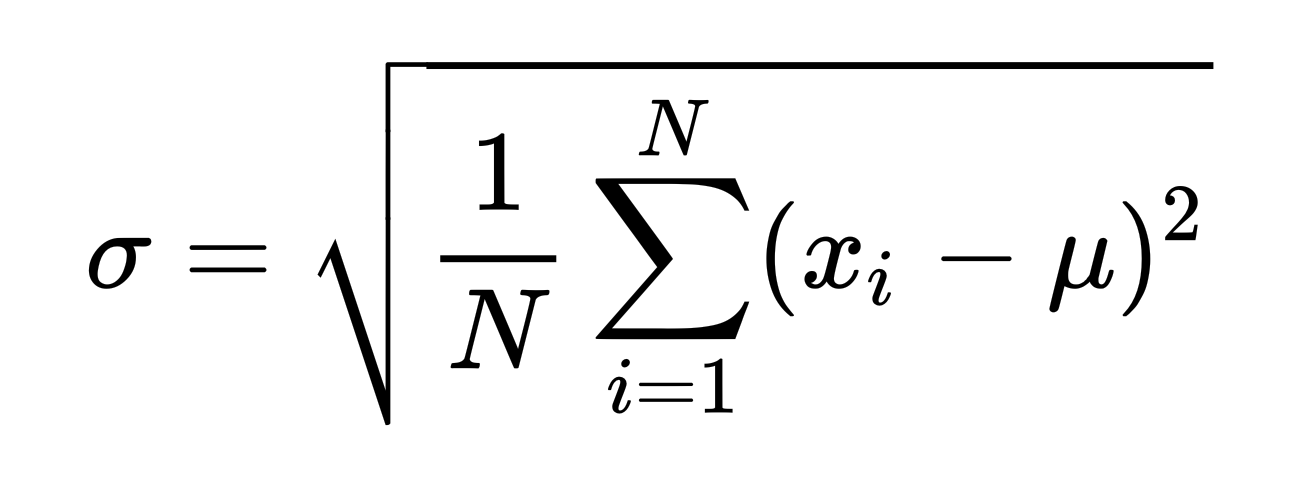
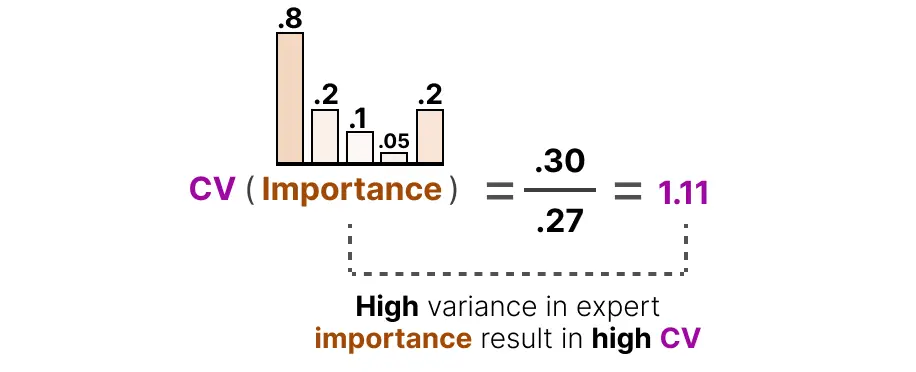
如果重要性得分有很大差异,CV就会很高:
如果所有专家重要性得分相似,CV就会很低(我们希望这样):
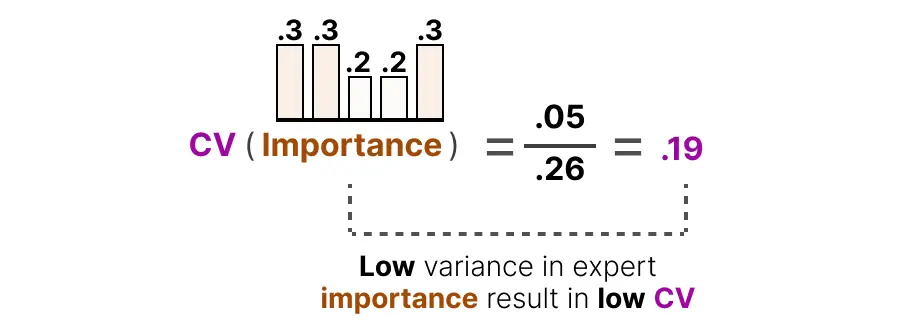
利用这个变异系数得分,我们可以在训练期间更新辅助损失,使其目标是尽可能降低变异系数得分(从而给予每个专家同等的重要性):
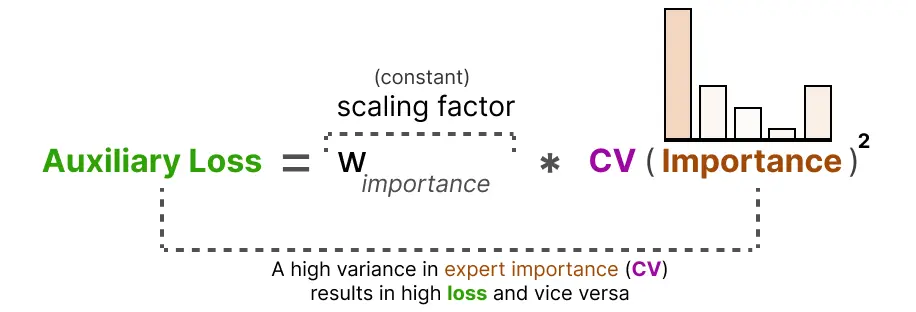
最后,辅助损失被单独添加进来,作为一个独立的损失项在训练期间进行优化。
不平衡现象不仅存在于被选中的专家中,还存在于发送给专家的token分布中。
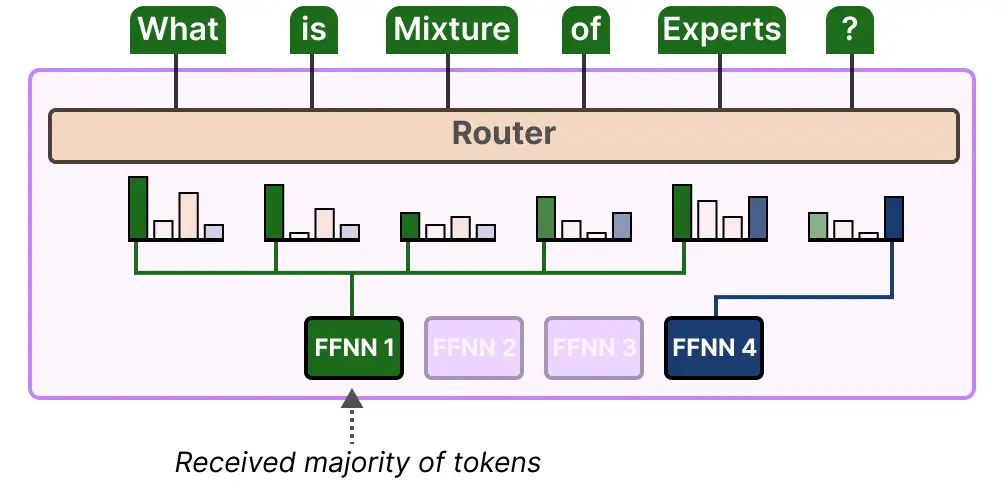
例如,如果输入的token在分配给不同专家时比例失调,过多地发送给一个专家而较少地发送给另一个专家,那么可能会出现训练不足的问题。
这里,问题不仅仅在于使用了哪些专家,还在于对它们的使用程度。这个问题的一个解决方案是限制给定专家可以处理的token数量,即专家容量。当一位专家达到其容量时,后续的词元将被发送给下一位专家:
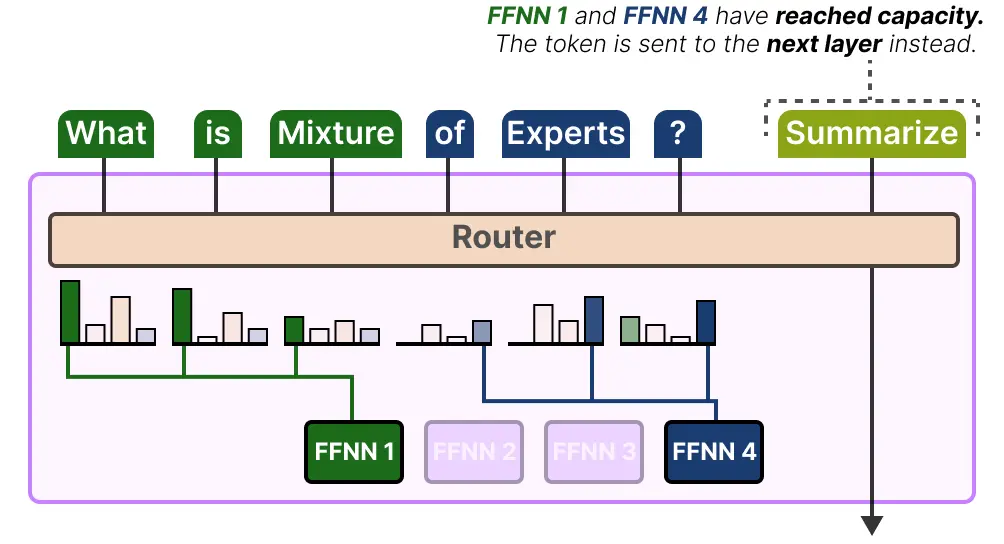
如果两位专家都达到了他们的容量,那么该token将不会被任何专家处理,而是被发送到下一层。这被称为token overflow。
混合专家之所以有趣的很大一部分原因在于其计算需求。由于在给定时间只使用一部分专家,所以我们可以访问比实际使用更多的参数。
虽然给定的混合专家模型有更多的参数要加载(稀疏参数),但由于在推理期间我们只使用一些专家,所以激活的参数较少(活跃参数)。
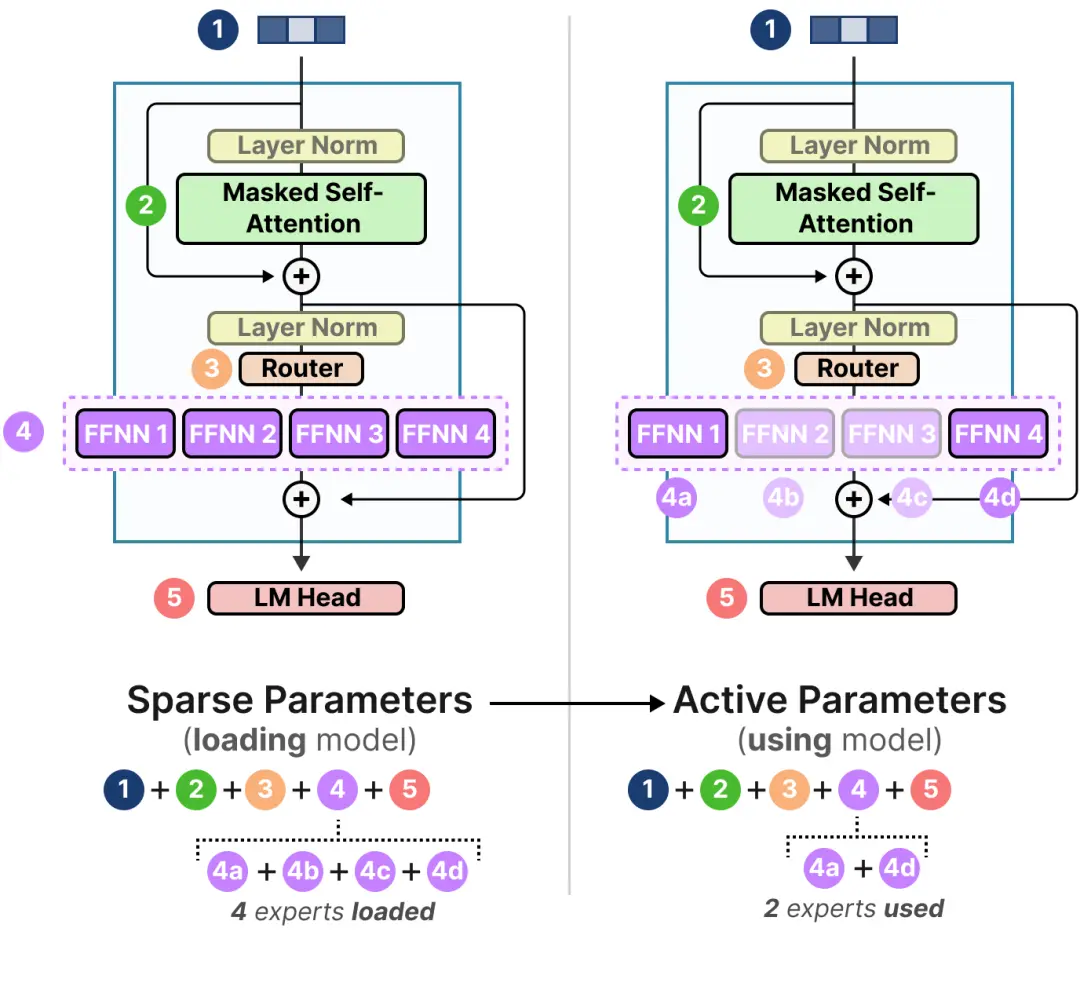
换句话说,我们仍然需要将整个模型(包括所有专家)加载到你的设备上(稀疏参数),但当我们进行推理时,我们只需要使用一部分(活跃参数)。混合专家模型需要更多的显存(VRAM)来加载所有专家,但在推理期间运行得更快。让我们以 Mixtral 8x7B 来探讨稀疏参数与活跃参数的数量。
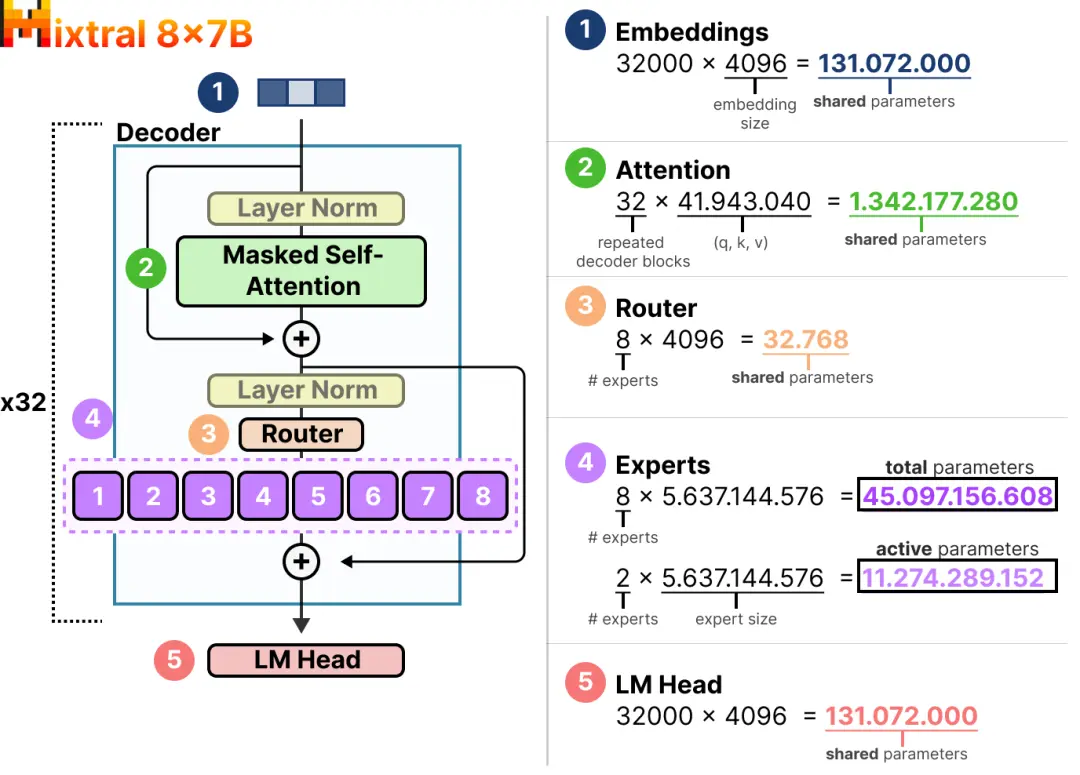
在这里,我们可以看到每个专家的大小是 5.6B,加上attention的1.3B就可以得到7B。

我们将不得不加载 8×5.6B(46.7B)的参数(以及所有共享参数),但在推理时我们只需要使用 2×5.6B(12.8B)的参数。
最后我们介绍一个具体的模型来作为总结。首批解决了基于 Transformer 的 MoE(例如负载均衡等)训练不稳定性问题的模型之一是 Switch Transformer。
Switch Transformer 是一个 T5 模型(编码器 - 解码器),它用切换层取代了传统的前馈神经网络层。切换层是一个稀疏的 MoE 层,它为每个词元选择一个专家(Top-1 路由)。
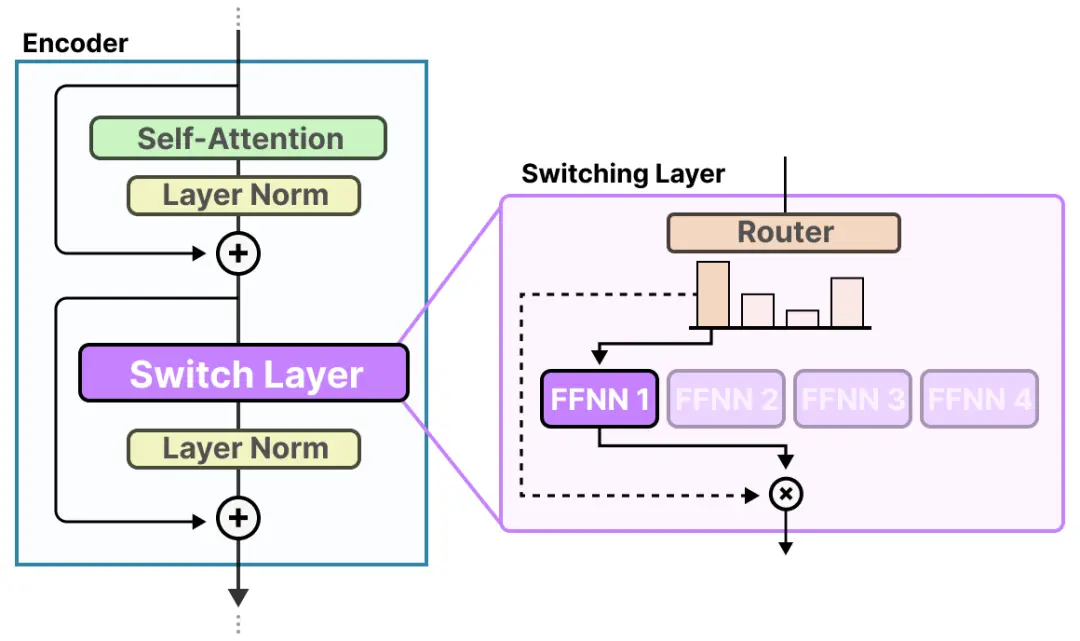
路由在计算选择哪个专家时没有特殊技巧,它只是对输入乘以专家权重后的结果取 Softmax。这种架构(Top-1 路由)假定路由只需要一个专家就能学会如何对输入进行路由。
专家容量是一个重要的值,因为它决定了一个专家能够处理多少个token。Switch Transformer 在此基础上进行了扩展,直接引入了一个容量因子,它对专家容量产生直接影响。这样做的好处是,可以更好地平衡每个专家的负载,避免有些专家忙不过来,而有些专家却很闲。
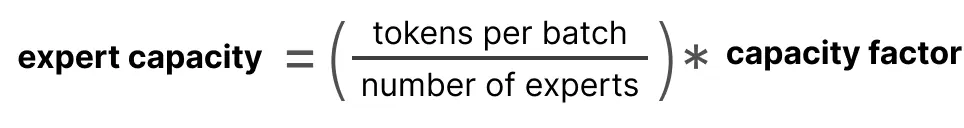
tokens per batch:每个批次中的token总数。
number of experts:专家的数量。
capacity factor:容量因子,通常大于 1,以提供额外的缓冲空间。

如果我们增加容量因子,每个专家将能够处理更多的词元。
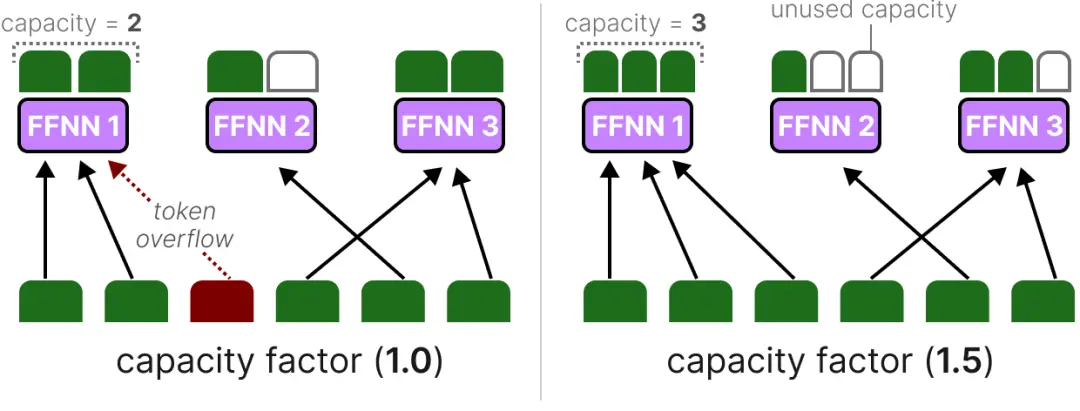
然而,如果容量因子太大,我们会浪费计算资源。相反,如果容量因子太小,由于token overflow,模型性能将会下降。
为了进一步防止丢弃词元,引入了一个简化版的辅助损失。这个简化后的损失并非去计算变异系数,而是依据每个专家的路由概率所占的比例,来对分配给各个专家的token的比例进行权衡。具体来说,希望每个专家处理的token数量和它们被选中的概率都差不多,也就是每个专家都能均匀地分到活儿干。
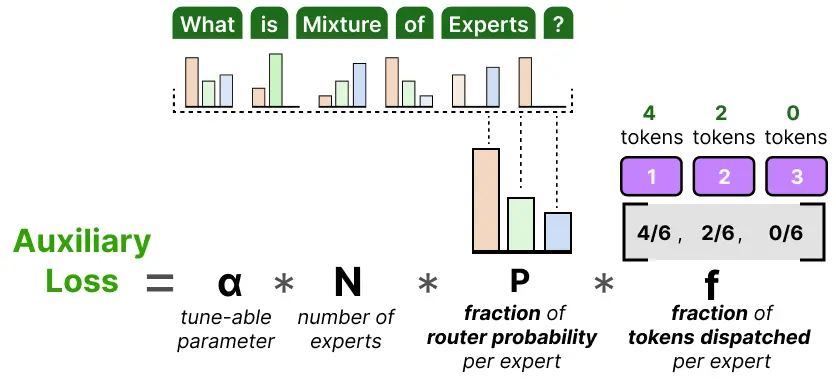
α 是一个超参数,我们可以在训练期间使用它来微调这个损失的重要性。过高的值将主导主要的损失函数,而过低的值对负载均衡的作用很小。
2.2.4.2 推理能力
说到推理能力,我们就简要介绍一下chatgpt o1和deepseek r1。
o1的出现代表推理能力登上舞台,这里的推理能力并不是利用COT(推理时扩展)来实现的,而是Hidden COT,然而得益于OpenAI并不open的传统。o1的具体工作原理在OpenAI之外仍然不为人知。所以我们把重点放在deepseek r1上。此外国内现在也有QwQ-32V的推理模型。DeepSeek-R1:开源Top推理模型的实现细节、使用与复现 - 深度学习机器 - 博客园
QwQ的介绍页面有这样一段话。
我们在冷启动的基础上开展了大规模强化学习。在初始阶段,我们特别针对数学和编程任务进行了 RL 训练。与依赖传统的奖励模型(reward model)不同,我们通过校验生成答案的正确性来为数学问题提供反馈,并通过执行生成的代码是否成功来提供代码的反馈。随着训练轮次的推进,这两个领域中的性能均表现出持续的提升。在第一阶段的 RL 过后,我们增加了另一个针对通用能力的 RL。此阶段使用通用奖励模型和一些基于规则的验证器rule-based verifiers进行训练。我们发现,通过少量步骤的通用 RL,可以提升其他通用能力,同时在数学和编程任务上的性能没有显著下降。
带着这些问题我们来看一下deepseek-r1的做法。
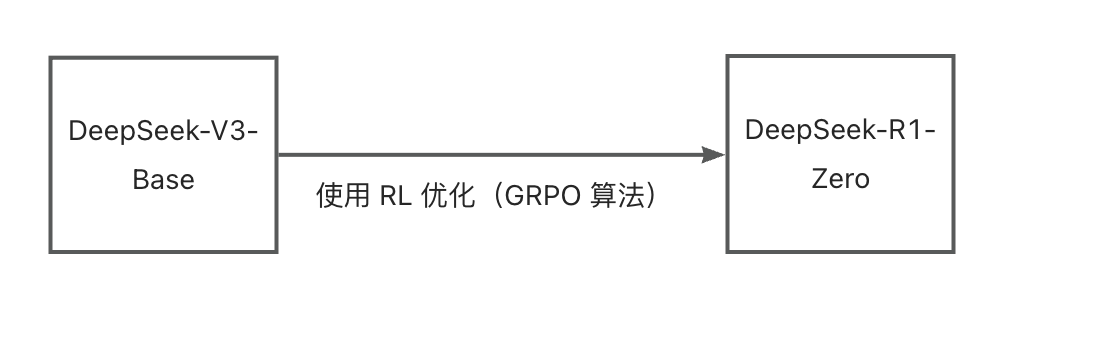
DeepSeek团队设计了如下的训练模型,要求模型按照如下格式进行输出:首先进行推理过程,然后给出最终答案。通过限制输出的结构格式,避免内容偏见,并且可以观察模型在强化学习过程中的推理进展。

DeepSeek-R1-Zero的训练信号来源于奖励系统,主要包括两种奖励类型:
准确性奖励:评估模型回答的正确性,适用于数学问题和LeetCode问题,通过规则验证答案。
格式奖励:要求模型将思考过程放在特定标签之间(<think>和</think>)。
论文中展示了一个 R1-Zero 在解决一道数学题时的中间版本输出,被称为模型的「顿悟时刻」。在这个例子中,模型在推理过程中突然意识到可以“重新评估”之前的步骤,并尝试用一种新的方法来解题,这种思维与人类似,说明模型初步掌握了人类思维的推理能力(红色字体部分)。

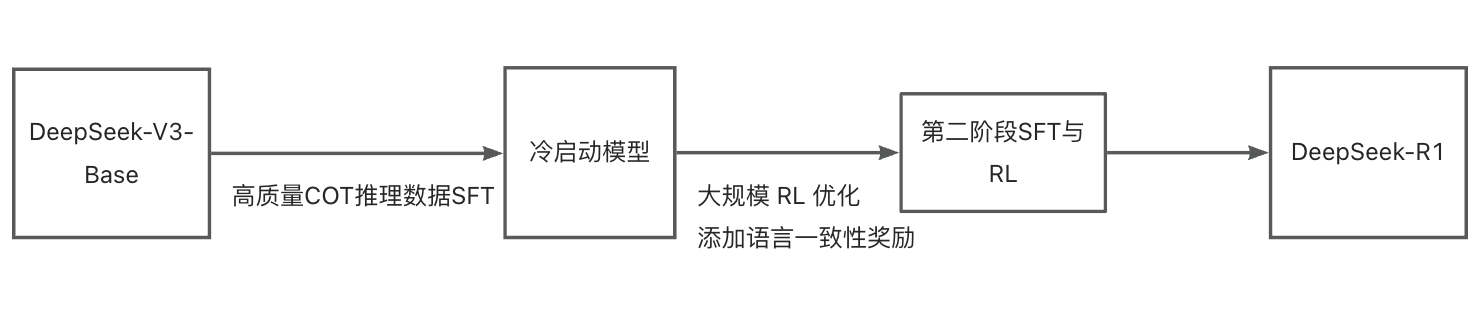
从Zero的训练过程中很容易得到启发:如果在训练初期先进行一部分高质量COT数据的微调,能否显著增强模型的推理能力,又或者加速收敛?
冷启动阶段
针对Zero模型不稳定的情况,尝试先通过收集数千条长CoT数据对模型进行微调。增加这一阶段有两个好处:
1.增加模型的可读性,在SFT阶段可以设计易读的输出格式,包含推理过程和总结,从而过滤不友好的响应格式。
2.增加模型的推理能力,通过人类先验设计的模式,可以观察到DeepSeek-R1表现优于DeepSeek-R1-Zero,这是因为迭代训练更适合推理模型。
基于推理性能的强化学习优化
在对DeepSeek-V3-Base进行冷启动数据微调后,采用与DeepSeek-R1-Zero相同的大规模强化学习训练,重点提升模型在编码、数学、科学和逻辑推理等推理密集型任务中的能力。训练过程中发现CoT在多语言提示中常出现语言混合,为此还需要引入语言一致性奖励,需要计算CoT中目标语言单词的比例。尽管这个训练目标会在一定程度上降低模型的推理能力,但其实一致的语言表达会更加符合我们的使用需求。最终奖励通过将推理任务的准确性与语言一致性奖励直接相加形成,随后对微调后的模型进行训练,直至在推理任务上收敛。
第二次微调
在推理导向的强化学习收敛后,利用检查点收集监督微调(SFT)数据,增强模型在写作、角色扮演等任务的能力。使用以下方法收集到的约80万条样本对DeepSeek-V3-Base进行第两轮的微调。
1.推理数据:通过拒绝采样从强化学习训练的检查点生成推理轨迹,扩展数据集,包含使用生成奖励模型的数据,过滤混合语言、长段落和代码块,最终收集约60万条推理相关训练样本。
2.非推理数据:采用DeepSeek-V3的Pipeline,重用部分SFT数据,针对某些任务生成潜在的思维链,最终收集约20万条非推理训练样本。
第二次强化学习
这阶段论文中没有给出具体的实现步骤,仅提供了一段文字概述。在第二次微调后,同样需要再进行一轮强化学习,这一阶段主要是为了提升模型的有用性和无害性,同时改善推理能力。推理数据遵循DeepSeek-R1-Zero方法,利用基于规则的奖励指导数学、代码和逻辑推理,一般数据使用奖励模型捕捉复杂场景中的人类偏好。整合奖励信号和多样数据分布,训练出在推理上表现优异的模型,同时优先考虑有用性和无害性。有用性评估集中在最终摘要,强调响应的实用性和相关性。无害性评估涵盖整个响应,识别和减轻潜在风险、偏见或有害内容。
值得一提的是QwQ还用了除此之外另一种方式——工具集成推理(Tool-Integrated Reasoning, TIR)。TIR通过调用外部工具(如代码解释器)来增强传统的CoT方法。
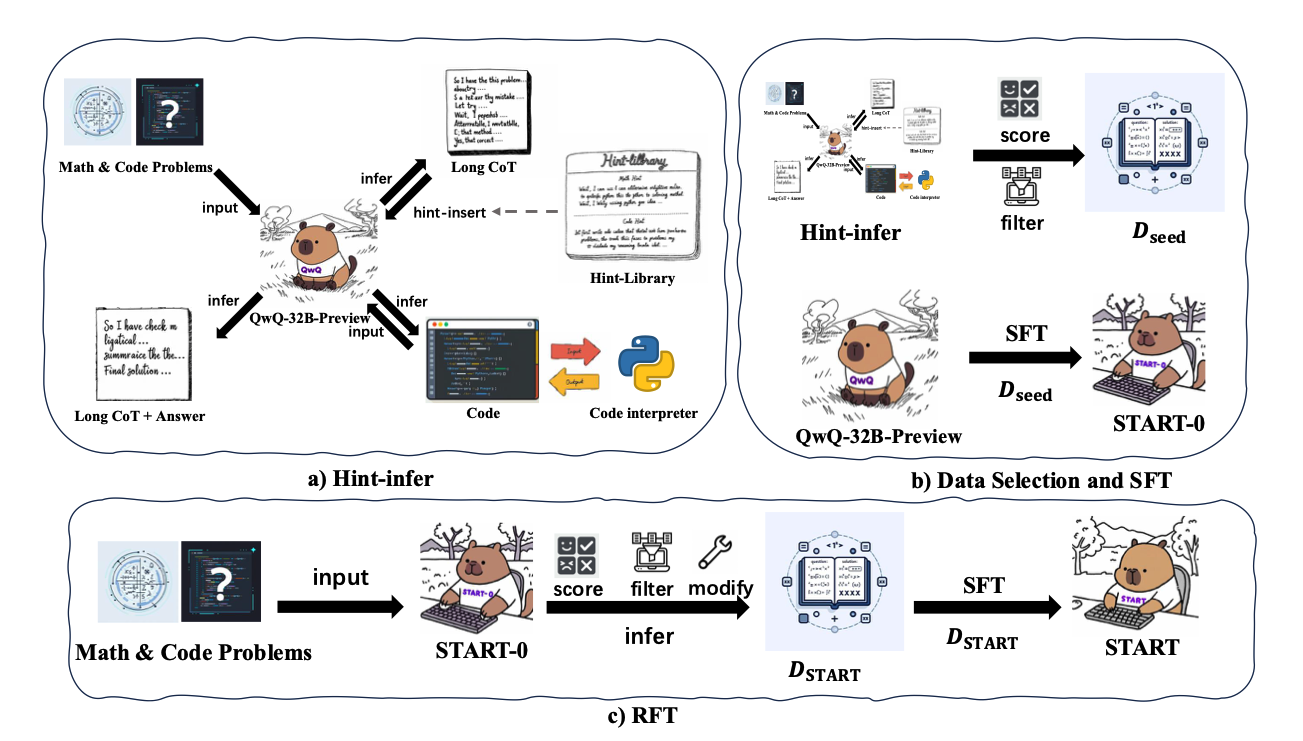
Hint-infer是START的核心技术之一。通过在推理过程中插入人工设计的提示(如“等一下,也许在这里使用Python是个好主意”),START能够有效地激发模型使用外部工具的能力,而无需任何演示数据。Hint-infer还可以作为一种简单而有效的顺序测试时间扩展方法。
Hint-RFT结合了Hint-infer和RFT(拒绝采样微调),通过对模型生成的推理轨迹进行评分、过滤和修改,然后对模型进行微调。
为了进一步增强训练数据的多样性和数量,研究团队利用START-0对所有训练数据进行拒绝采样微调。通过16轮采样,研究团队最终得到了START模型。
下面再补充一点RFT的知识。
RFT(Rejection sampling Fine-Tuning)和SFT(Supervised Fine-Tuning)是两种用于微调机器学习模型的方法,特别是在自然语言处理领域。
SFT是一种常见的微调方法,主要步骤如下:
1. 数据收集:收集大量的标注数据,这些数据通常由人类专家根据特定任务进行标注。
2. 模型训练:使用这些标注数据对预训练模型进行微调,使其在特定任务上表现更好。
3. 评估和优化:通过验证集评估模型性能,并根据结果进行优化。
SFT的优点是相对简单直接,只需要高质量的标注数据即可。然而,SFT也有一些局限性,比如对标注数据的质量和数量要求较高。
RFT是一种更为复杂的微调方法,主要步骤如下:
1. 数据生成:首先使用预训练模型生成大量的候选输出。
2. 筛选过程:通过某种筛选机制(如人工评审或自动评分系统)从这些候选输出中挑选出高质量的样本。
3. 模型训练:使用筛选后的高质量样本对模型进行微调。
RFT的关键在于筛选过程,这个过程可以显著提高数据的质量,从而提升模型的性能。筛选机制可以是人工的,也可以是基于某种自动化评分系统的。
2.2.4.3 更多模态

现在的多模态不再是早期的文本和图像,而是进一步扩展到视频以及音频。
想要深入了解这部分知识请阅读这篇文章。
Understanding Multimodal LLMs - by Sebastian Raschka, PhD
概括来讲,有两种实现多模态大模型的方法。
统一嵌入-解码器架构Unified Embedding Decoder Architecture使用单个解码器模型,很像 GPT-2 或 Llama 3.2 等未经修改的 LLM 架构。在这种方法中,图像被转换为与原始文本token具有相同嵌入大小的token,从而允许 LLM 在连接后同时处理文本和图像输入token。
跨模态注意力架构Cross-Modality Attention Architecture采用交叉注意力机制,将图像和文本嵌入直接集成到注意力层中。
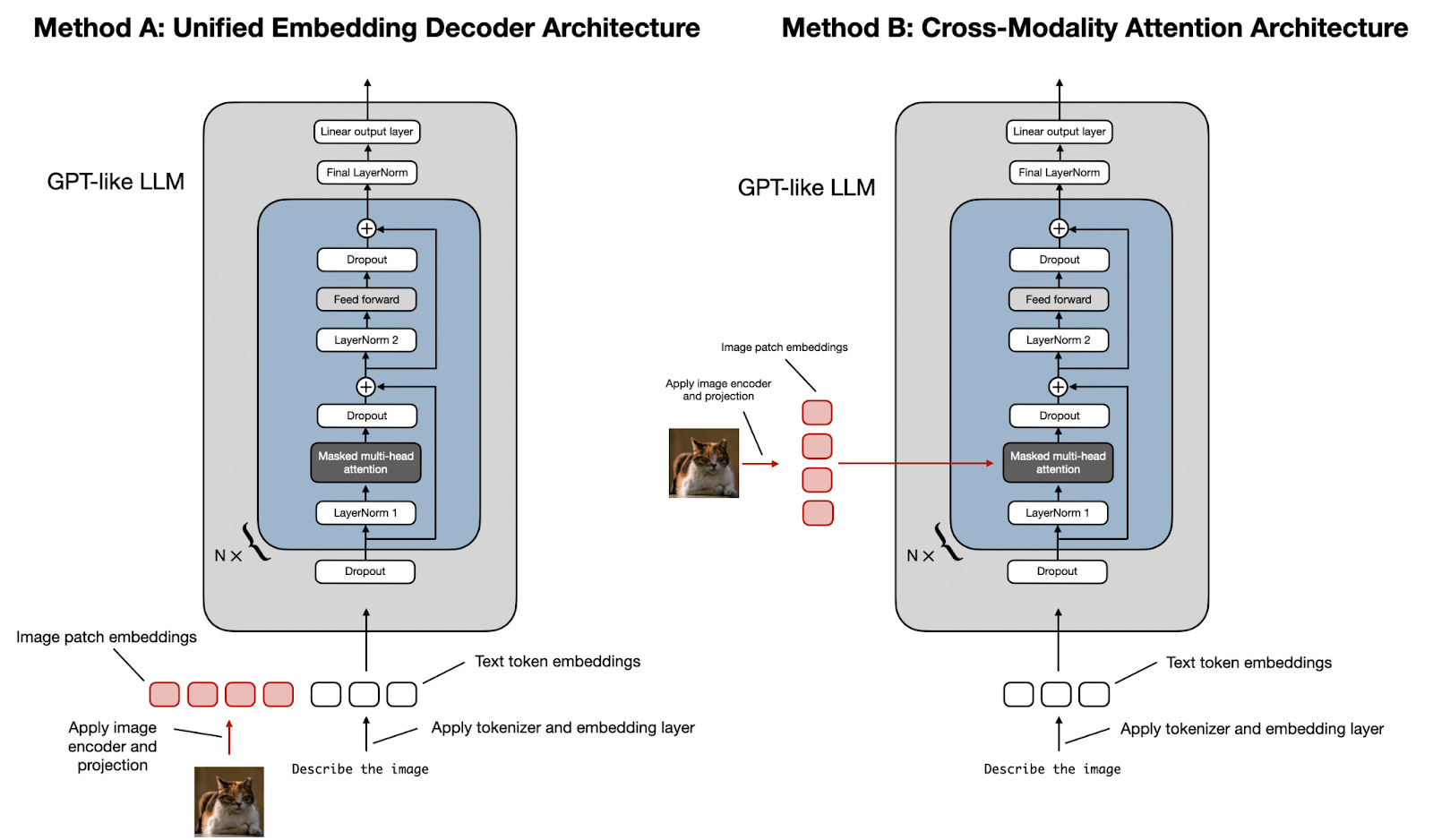
在交叉注意力中,与自注意力相反,我们有两个不同的输入源,如下图所示。
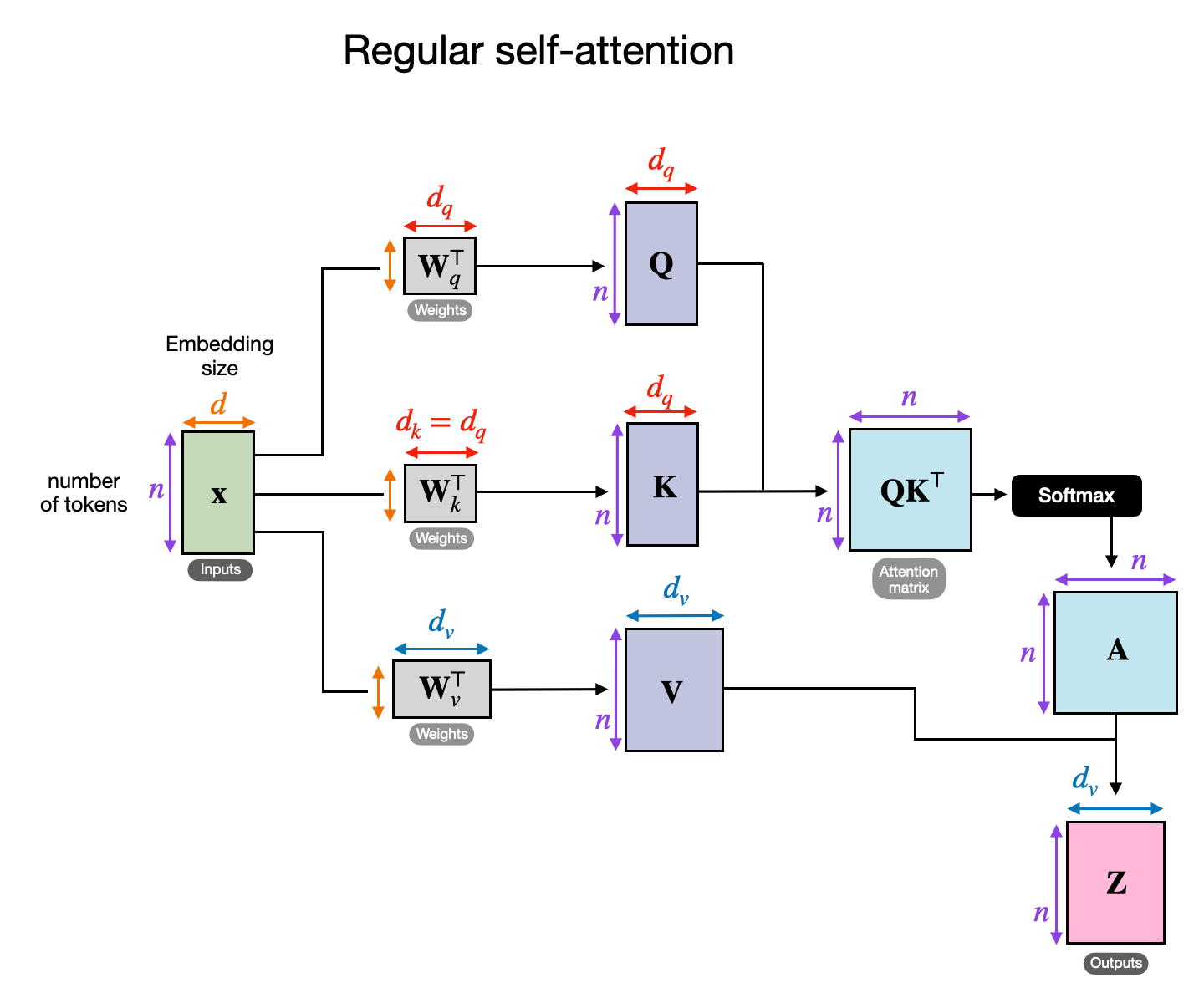
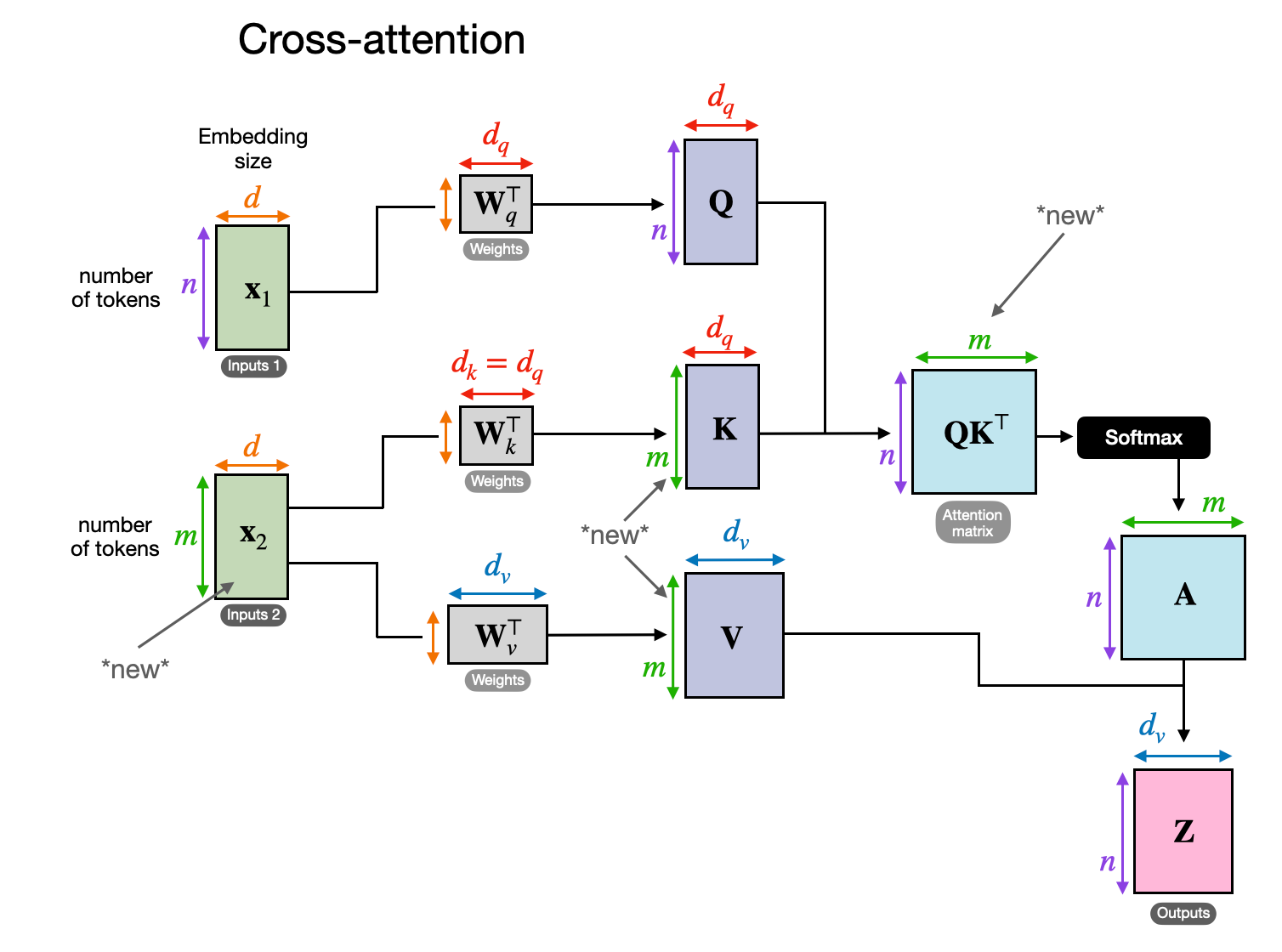
如前两个图所示,在 self-attention 中,我们使用相同的 input sequence。在交叉注意力中,我们混合或组合两个不同的输入序列。
2.2.4.4 闭源模型(2025.6)
后续更新可以参考https://zhuanlan.zhihu.com/p/670574382
详细写就会像产品介绍了,而且其实也没有什么具体参数参考,这里就不详细展开了。
ChatGPT: https://chatgpt.com OpenAI研发的大模型系列。2025年2月推出最新的通用模型GPT-4.5,4月发布通用模型GPT-4.1。2025年4月推出最新的推理模型o3和o4-mini。
Claude: https://claude.ai/ Anthropic研发的大模型,2025年5月发布了4 Opus,4 Sonnet以及Extended Thinking版本。
Gemini(Bard): https://gemini.google.com google研发的大模型,前身为Bard。
12月发布了Gemini 2.0 Flash,这是一个All in one自带Agent架构的多模态模型,可以实时接收文字、语音、图像、视频信息并进行推理反馈。3月份发布了Gemin 2.5 Pro Experimental,默认采用thinking模式拥有最长上下文10M(2M稳定) token。2025年1月发布Gemini 2.0 Flash Thinking,3月份发布了Gemin 2.5 Pro,5月份发布Gemin 2.5 Pro Deep Think。目前模型性能综合实力最强。
Grok: https://grok.x.ai/ xAI研发的大模型,采用最新版本闭源早期版本开源的策略。2025年2月发布最新版本v3.0,同时发布thinking版本。
Mistral: https://mistral.ai/news/mistral-large-2407/ 法国Mistral AI发布的闭源大模型。2025年5月发布Mistral 3 Medium。
字节豆包:https://www.doubao.com/(国内版),https://www.ciciai.com/ (海外版)。字节跳动研发的大语言模型应用,目前2.0版本。2025年4月发布推理模型豆包1.5深度推理,独创边搜边想模式。2025年5月发布多模态推理模型Seed1.5-VL。
月之暗面(Kimi): https://kimi.moonshot.cn/ 月之暗面研发的大语言模型应用。2025年4月发布K1.6推理版。
通义千问:https://qianwen.aliyun.com/(国内版)https://chat.qwen.ai/(海外版) 阿里云研发的大语言模型应用,目前最新版为3.0,分为235B-A22B(最强大MoE)、32B-A3B(高效且紧凑MoE)、32B三个版本,拥有按需推理的新特性,并更好地支持Agent形态和MCP协议。
腾讯元宝(混元):https://yuanbao.tencent.com/ 腾讯研发的大语言模型应用,前身为腾讯混元。2024年5月应用品牌升级为腾讯元宝,加入了微信公众号文章RAG搜索功能;2024年8月加入深度阅读功能。
文心一言:https://yiyan.baidu.com/ 百度研发的国内首个大语言模型应用,2024年9月移动端APP品牌升级为“文小言”发力“新搜索”,2025年3月发布推理模型X1,4月发布通用模型4.5 Turbo,同时发布推理模型X1 Turbo。所有版本免费使用。相对落后。
2.2.4.5 开源模型(2025.6)
Llama: https://llama.meta.com/ Meta研发的开源大模型,2025年4月发布了4.0版本,三个版本均为MoE架构,参数量分别为17B╳16(Scout)/17B╳128(Marverick)/288B╳16(Behemoth),目前Scout和Marverick已上线。
Mistral: https://mistral.ai/ 法国的大模型初创企业MistralAI于2023年9月份发布的模型系列。2023年12月发布了Mixtral-of-Expert-7B,是一个拥有8个专家层的MoE模型。2024年4月发布了Mixtral-of-Expert-22B。2024年11月发布了多模态大模型Pixtral Large,124B参数,支持128K上下文,具备前沿级图像理解能力,能理解文本、图表和图像。2025年3月发布Mistral Small 3.1,参数量24B。
Gemma: Google Deepmind发布的开源小语言模型,2025年3月发布了3.0版本,包括1B, 4B, 12B和27B几个大小。
Phi: 微软发布的大语言模型,2024年12月发布了v4.0,截止目前只发布了14B参数的版本。2025年5月发布推理模型Phi-reasoning系列,包括加强版plus,和效率版mini。参数量和通用版本一致为14B。
深度求索(DeepSeek):http://www.deepseek.com 幻方量化团队核心成员创立的AI大模型公司。2024年12月发布了v3.0,2025年1月发布了R1正式版。
Qwen: https://github.com/QwenLM/ 通义千问开源版本。2025年4月发布最新版本v3.0,包含 0.6B/1.7B/4B/8B/17B/32B 六个dense model,以及30B-A3B和235B-A22B两个MoE模型。2025年3月发布QwQ-32B推理模型,多模态推理模型QvQ-Max。
GLM: https://github.com/THUDM/GLM-4 智谱团队于2024年8月底发布4.0 plus系列,除了语言模型GLM-4-Plus还包括文生图模型CogView-3-Plus、图像/视频理解模型GLM-4V-Plus。2025年4月发布并开源通用模型GLM-4-0414(9B/32B),推理模型GLM-Z1(9B/32B)和沉思模型GLM-Z1-Rumination(32B)。
Hunyuan:https://llm.hunyuan.tencent.com/ 腾讯2024年11月发布开源MoE模型——Hunyuan-Large,该模型总参数量约389B,激活参数量约52B ,上下文长度达256k。2025年3月推出了推理模型Hunyuan-T1。
Kimi: https://github.com/MoonshotAI/Kimi-VL 月之暗面于2025年4月发布开源多模态通用模型Kimi-VL以及Kimi-VL-Thinking。MoE架构,参数量16B(激活3B)。
2.3文本生成的未来
在这部分我会总结当下的问题,介绍一些正在进行的方向,并不负责任地大胆预测未来的热点。当下最主要的进展是朝着推理以及性能上提升,模型的能力还没有达到饱和。从技术来看,大抵上目前可见的未来发展方向有如下两大类:
一是从底层架构入手,如将Transformer架构改为基于状态空间模型(SSM)的Mamba架构;或者采用混合专家模型的大而化之处理方式等修改transformer的方法;
二是优化预训练微调方法,比如强化学习提升推理能力,或者利用模型蒸馏方法提升小模型性能。
当然我个人认为这样的路径依旧不是催生智能,而是进一步榨干人类语言中的逻辑性,┓( ´∀` )┏。