深度强化学习 pdf 董豪| 马尔科夫性质,马尔科夫过程,马尔科夫奖励过程,马尔科夫决策过程
深度强化学习 pdf
百度云
hea4
pdf
主页
概念
- 马尔可夫奖励过程和价值函数估计的结合产生了在绝大多数强化学习方法中应用的核心结果——贝尔曼
(Bellman)方程。 - 最优价值函数和最优策略可以通过求解贝尔曼方程得到,还将介绍三种贝尔曼
方程的主要求解方式:- 动态规划(Dynamic Programming)
- 蒙特卡罗(Monte-Carlo)方法
- 时间差分(Temporal Difference)方法。
我们进一步介绍深度强化学习策略优化中对 策略 和 价值 的拟合。
策略优化的内容将会被分为两大类:
- 基于价值的优化
- 基于策略的优化。
在基于价值的优化中,我们介绍基于梯度的方法,如使用深度神经网络的深度 Q 网络(Deep Q-Networks);
在基于策略的优化中,我们详细介绍确定性策略梯度(Deterministic Policy Gradient)和随机性策略梯度(Stochastic Policy Gradient),并提供充分的数学证明。
结合基于价值和基于策略的优化方法产生了著名的 Actor-Critic 结构
在线预测(Online Prediction)问题是一类智能体需要为未来做出预测的问题。假如你在夏威夷度假一周,需要预测这一周是否会下雨;或者根据一天上午的石油价格涨幅来预测下午石油的价格。在线预测问题需要在线解决。在线学习和传统的统计学习有以下几方面的不同:
- 样本是以一种有序的(Ordered)方式呈现的,而非无序的批(Batch)的方式。
- 我们更多需要考虑最差情况而不是平均情况,因为我们需要保证在学习过程中随时都对事
情有所掌控。 - 学习的目标也是不同的,在线学习企图最小化后悔值(Regret),而统计学习需要减少经验
风险。我们会稍后对后悔值进行介绍。
对于展示探索-利用的权衡问题,MAB 可以作为一个很好的例子。当我们已经对一些状态的q 值进行估计之后,如果一个智能体一直选择有最大 Q 值的动作的话,那么这个智能体就是贪心的(Greedy),因为它一直在利用已经估计过的 q 值。如果一个智能体总是根据最大化 Q 值来选取动作,那么我们认为这样的智能体是有一定探索(Exploration)性的。只做探索或者只对已有估计值进行利用(Exploitation),在大多数情况下都不能很好地改善策略。
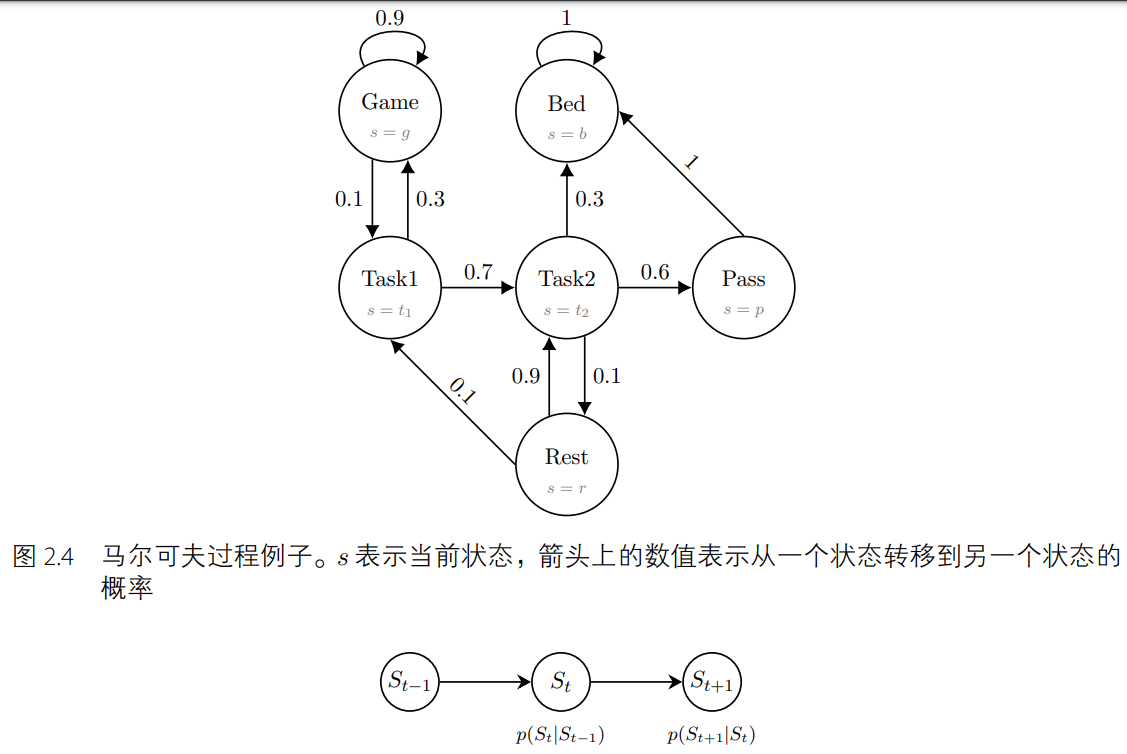
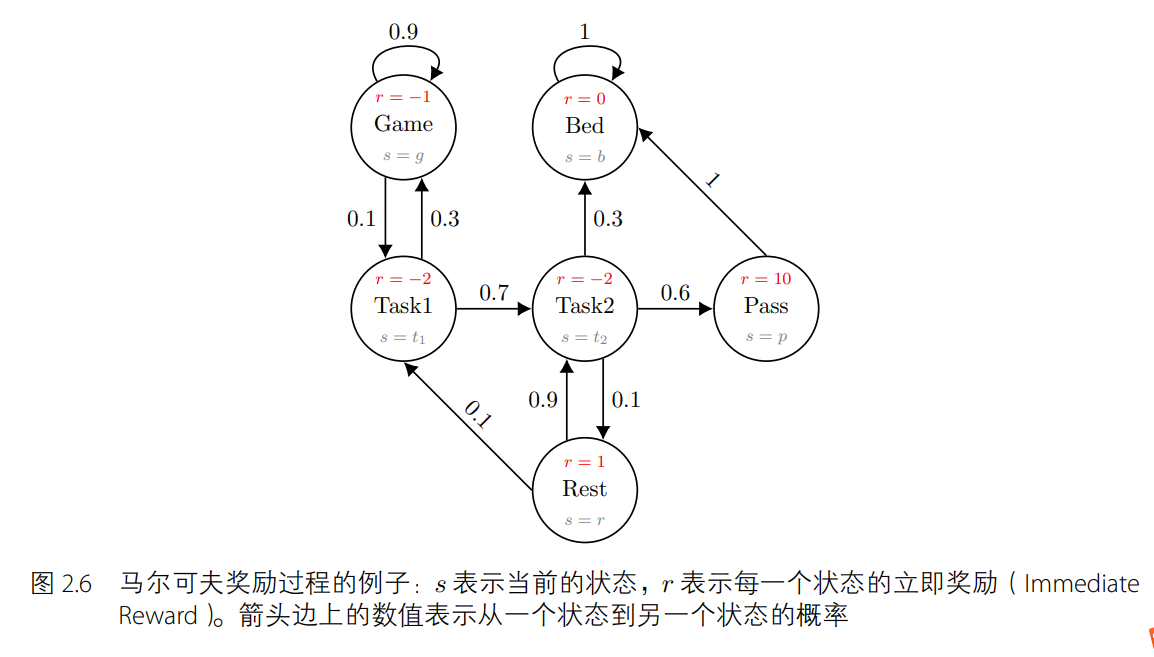
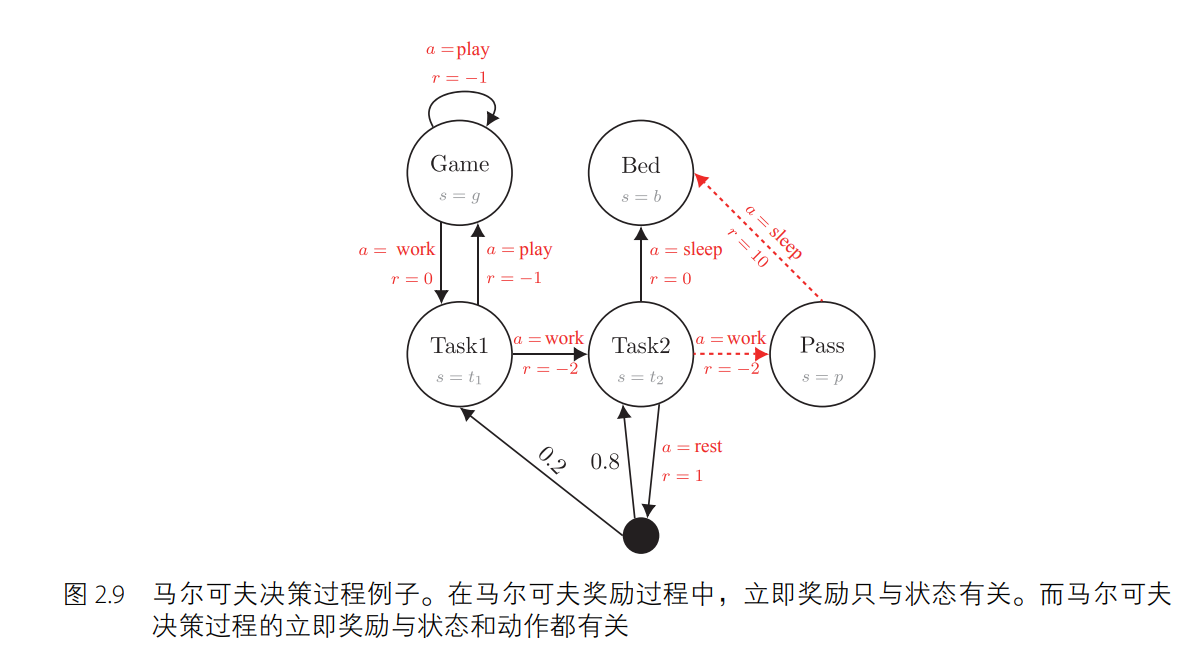
在模拟序列决策过程的问题上,马尔可夫决策过程比马尔可夫过程和马尔可夫奖励过程要好用。如图 2.9 所示,和马尔可夫奖励过程不同的地方在于,马尔可夫奖励过程的立即奖励只取决于状态(奖励值在节点上),而马尔可夫决策过程的立即奖励与状态和动作都有关(奖励值在边上)。同样地,给定一个状态下的一个动作,马尔可夫决策过程的下一个状态不一定是固定唯一的。举例来说,如图 2.10 所示,当智能体在状态 s = t2 时执行休息(rest)动作后,下一时刻的状态有 0.8 的概率保留在状态 s = t2 下,有 0.2 的概率变为 s = t1。
马尔科夫性质,马尔科夫过程,马尔科夫奖励过程,马尔科夫决策过程


马尔可夫过程是一个具备马尔可夫性质
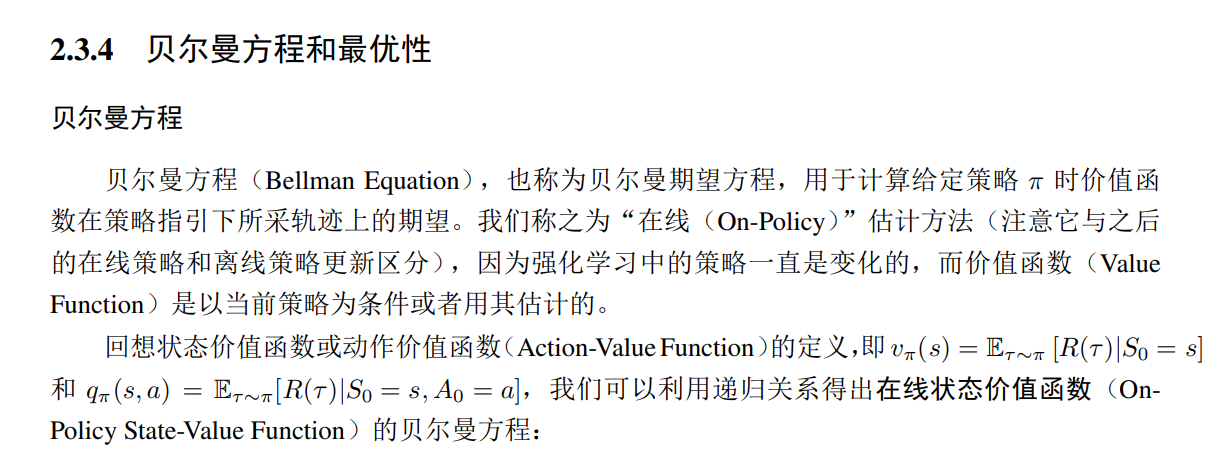
马尔可夫过程(Markov Process,MP)是一个具备马尔可夫性质(Markov Property)的离散随机过程(Discrete Stochastic Process)。图 2.4 展示了一个马尔可夫过程的例子。每个圆圈表示一个状态,每个边(箭头)表示一个状态转移(State Transition)。这个图模拟了一个人做两种不同的任务(Tasks),以及最后去床上睡觉的这样一个例子。为了更好地理解这个图,我们假设这个人当前的状态是在做“Task1”,他有 0.7 的概率会转到做“Task2”的状态;如果他进一步从“Task2”以 0.6 的概率跳转到“Pass”状态,则这个人就完成了所有任务可以去睡觉了,因为“Pass”到“Bed”的概率是 1。
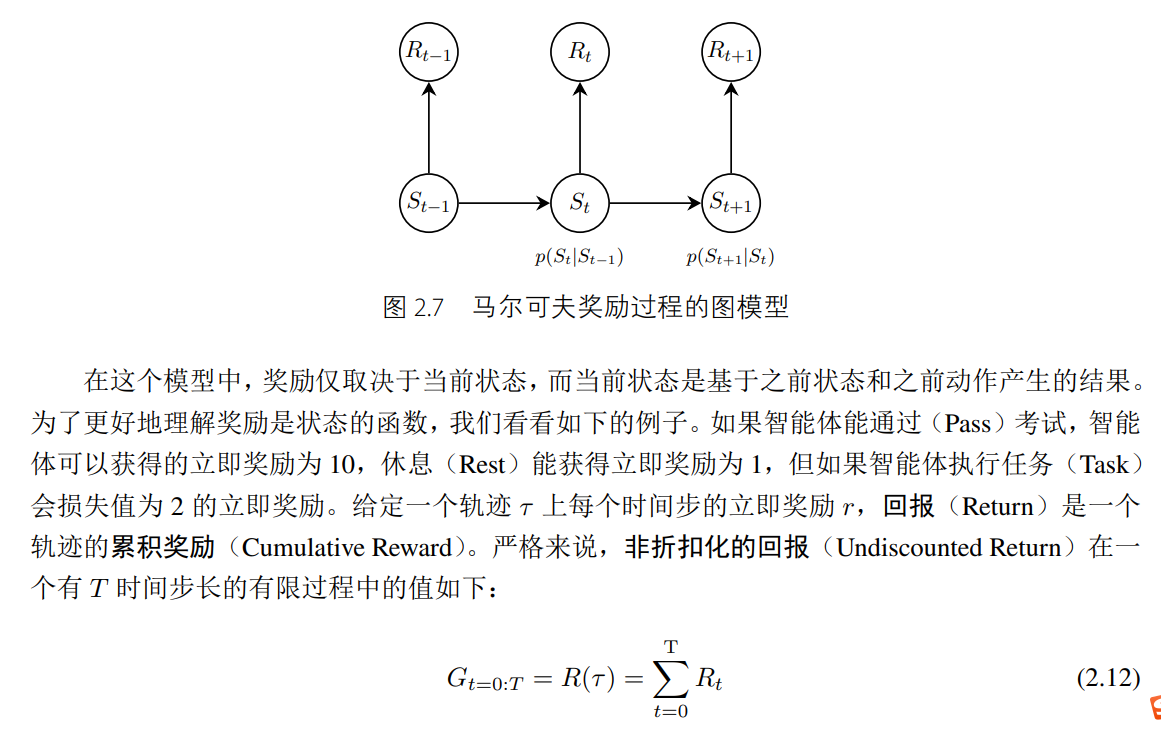


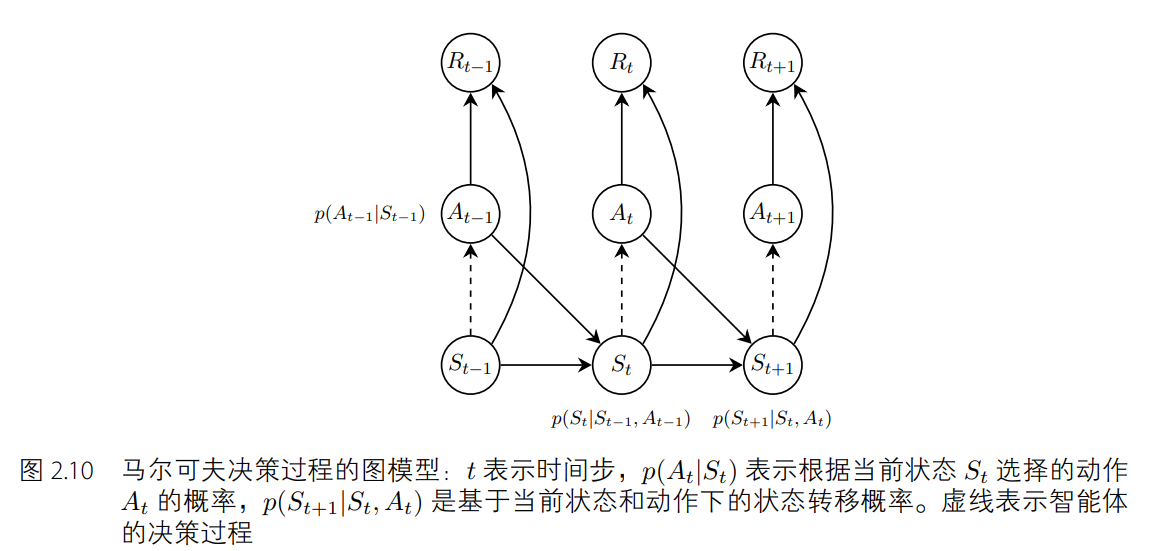


我们知道马尔可夫决策过程是基于马尔可夫性质的,满足p(Xt+1| Xt, · · · , X1) = p(Xt+1|Xt),其中 Xt 是 t 时刻的随机变量,这意味着随机变量 Xt 的时间相关性只取决于上一个时刻的随机变量 Xt−1。而 O-U 噪声就是一个具有时间相关性的随机变量,这一点与马尔可夫决策过程的性质相符,因此很自然地被运用到随机噪声的添加中。然而,实践表明,时间不相关的零均值高斯噪声也能取得很好的效果。