# 利用迁移学习优化食物分类模型:基于ResNet18的实践
利用迁移学习优化食物分类模型:基于ResNet18的实践
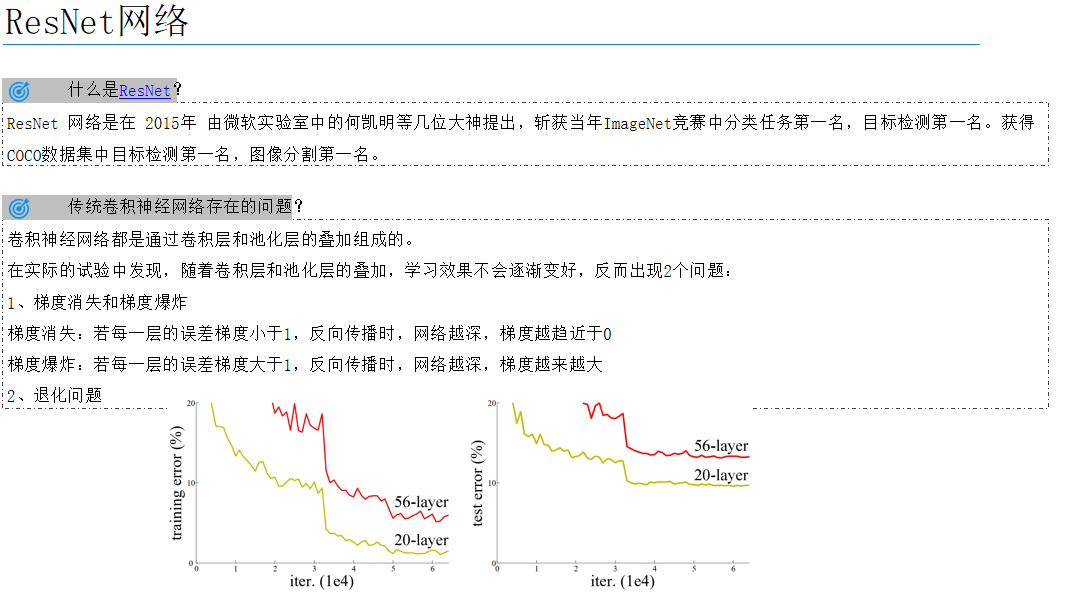
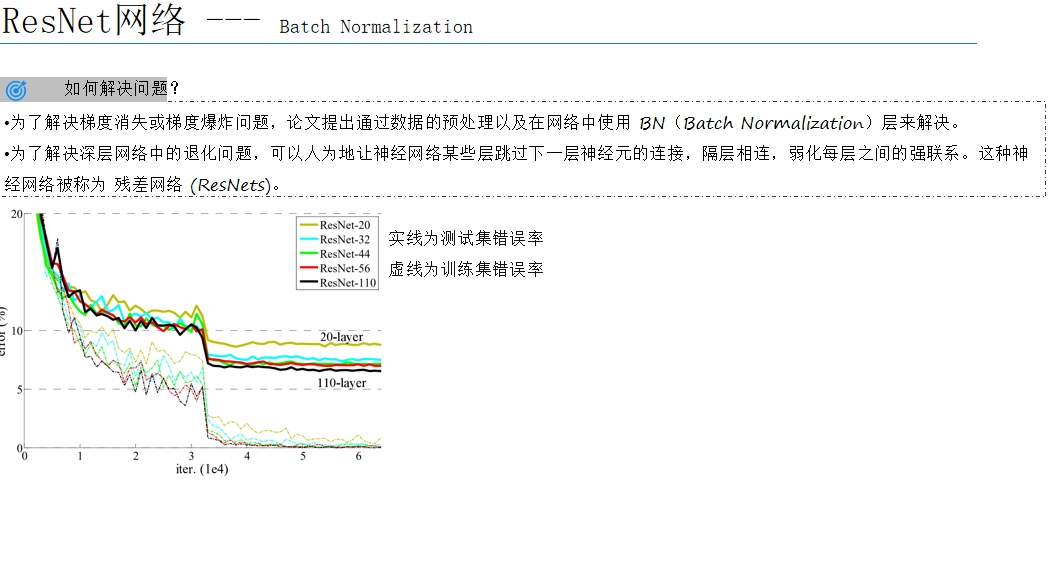
在深度学习的众多应用中,图像分类一直是一个热门且具有挑战性的领域。随着研究的深入,我们发现利用预训练模型进行迁移学习是一种非常有效的策略,可以显著提高模型的性能,尤其是在数据量有限的情况下。在这篇文章中,我们将探讨如何将ResNet18模型迁移到食物分类项目中,并通过一系列技术优化模型性能。
一、迁移学习的背景
迁移学习是一种机器学习技术,它允许模型在一个任务上训练获得的知识应用到另一个相关任务上。在图像分类领域,迁移学习尤其有效,因为不同类别的图像往往共享一些通用的特征。

二、项目概述
本项目的目标是构建一个能够准确分类食物图像的模型。我们选择了ResNet18作为基础模型,因为它在多个图像分类任务上都表现出色。通过迁移学习,我们可以利用ResNet18在ImageNet数据集上预训练的权重,加速模型的收敛并提高分类准确率。
三、模型迁移
1. 加载预训练模型
我们首先加载了ResNet18的预训练模型,并将其所有参数设置为不需要梯度更新,这样可以防止在训练过程中改变这些预训练的权重。
resnet_model = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
for param in resnet_model.parameters():param.requires_grad = False
2. 修改全连接层
由于我们的食物分类任务有20个类别,因此我们需要修改ResNet18的最后一个全连接层,以输出20个类别的预测。
in_features = resnet_model.fc.in_features
resnet_model.fc = nn.Linear(in_features, 20)
3. 选择性更新参数
在迁移学习中,我们通常只更新模型的最后几层参数。在我们的案例中,我们只更新了全连接层的参数。
params_to_update= []
for param in resnet_model.parameters():if param.requires_grad == True:params_to_update.append(param)
四、数据准备与增强
为了提高模型的泛化能力,我们对训练数据进行了一系列的增强操作,包括随机旋转、裁剪、翻转和灰度化等。
data_transforms = {'train': transforms.Compose([transforms.Resize([300, 300]),transforms.RandomRotation(45),transforms.CenterCrop(244),transforms.RandomHorizontalFlip(p=0.5),transforms.RandomVerticalFlip(p=0.5),transforms.RandomGrayscale(p=0.1),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'valid': transforms.Compose([transforms.Resize([244, 244]),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
}
五、模型训练与评估
我们使用交叉熵损失函数和Adam优化器进行模型训练,并采用学习率调度器来动态调整学习率。
optimizer = torch.optim.Adam(params_to_update, lr=0.001)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)
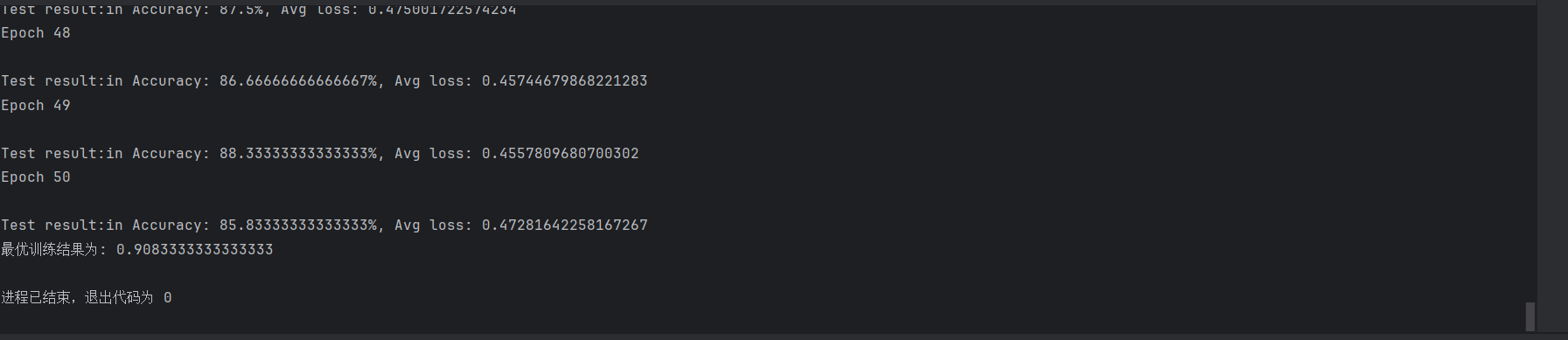
在每个训练周期结束后,我们在测试集上评估模型的性能,并记录最佳准确率。
for t in range(epochs):print(f"Epoch {t+1}\n")train(train_dataloader, model, loss_fn, optimizer)scheduler.step()test(test_dataloader, model, loss_fn)
print('最优训练结果为:', best_acc)
完整代码
import numpy as np
from PIL import Image
import torch
from torch.utils.data import DataLoader,Dataset
from torchvision import transforms
import torchvision.models as models
from torch import nn'''将resnet18模型迁移到食物分类项目中'''
resnet_model = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)for param in resnet_model.parameters():print(param)param.requires_grad = Falsein_features = resnet_model.fc.in_features
resnet_model.fc = nn.Linear(in_features, 20)params_to_update= []
for param in resnet_model.parameters():if param.requires_grad == True:params_to_update.append(param)# 数据增强
data_transforms = {'train': transforms.Compose([transforms.Resize([300, 300]),transforms.RandomRotation(45), # 随机旋转,-45到45度transforms.CenterCrop(244),#从中心裁剪240*240transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转transforms.RandomVerticalFlip(p=0.5), # 随机垂直翻转# transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),transforms.RandomGrayscale(p=0.1), # 转换为灰度图transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'valid': transforms.Compose([transforms.Resize([244, 244]),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
}class food_dataset(Dataset): #food_dataset是自己创建的类名称,可以改为你需要的名称def __init__(self, file_path, transform=None): #类的初始化,解析数据文件txtself.file_path = file_pathself.imgs = []self.labels = []self.transform = transformwith open(self.file_path) as f: #是把train.txt文件中图片的路径保存在 self.imgs,train.txt文件中标签保存在 sesamples = [x.strip().split(' ') for x in f.readlines()]for img_path, label in samples:self.imgs.append(img_path) #图像的路径self.labels.append(label) #标签,还不是tensor# 初始化:把图片目录加载到selfdef __len__(self):return len(self.imgs)def __getitem__(self, idx):image=Image.open(self.imgs[idx])if self.transform:image=self.transform(image)label=self.labels[idx]label=torch.from_numpy(np.array(label,dtype=np.int64))return image,label#training_data包含了本次需要训练的全部数据集
training_data = food_dataset(file_path=r'D:\Users\妄生\PycharmProjects\人工智能\深度学习\trainda.txt', transform=data_transforms['train'])
test_data = food_dataset(file_path=r'D:\Users\妄生\PycharmProjects\人工智能\深度学习\testda.txt', transform=data_transforms['valid'])#training_data需要具备索引的功能,还需要确保数据是tensor
train_dataloader=DataLoader(training_data,batch_size=64,shuffle=True)
test_dataloader=DataLoader(test_data,batch_size=64,shuffle=True)device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")model = resnet_model.to(device) # 将刚刚定义的模型传入到GPU中def train(dataloader, model, loss_fn, optimizer): # 传入参数 打包的数据,卷积模型,损失函数,优化器model.train() # 表示模型开始训练batch_size_num = 1for x, y in dataloader: # 遍历打包的图片及其对应的标签,其中batch为每一个数据的编号x, y = x.to(device), y.to(device) # 把训练数据集和标签传入cpu或GPUpred = model.forward(x) # 自动初始化 W权值loss = loss_fn(pred, y) # 传入模型训练结果的预测值和真实值,通过交叉熵损失函数计算损失值L0optimizer.zero_grad() # 梯度值清零loss.backward() # 反向传播计算得到每个参数的梯度optimizer.step() # 根据梯度更新网络参数loss = loss.item() # 获取损失值if batch_size_num % 100 == 0:print(f"loss: {loss:>7f}[number:{batch_size_num}]") # 打印损失值,右对齐,长度为7batch_size_num += 1 # 右下方传入的参数,表示训练轮数best_acc =0
def test(dataloader, model, loss_fn): # 定义一个test函数,用于测试模型性能global best_acc # 定义一个全局变量size = len(dataloader.dataset) # 返回打包的图片总数num_batches = len(dataloader) # 返回打包的包的个数model.eval() # 表示模型进入测试模式test_loss, correct = 0, 0 # 初始化两个值,一个用来存放总体损失值,一个存放预测准确的个数with torch.no_grad(): # 一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()时可以减少for x, y in dataloader: # 遍历数据加载器中测试集图片的图片及其标签x, y = x.to(device), y.to(device) # 传入GPUpred = model.forward(x) # 前向传播,返回预测结果test_loss += loss_fn(pred, y).item() # 计算所有的损失值的和,item表示将tensor类型值转化为python标量correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 判断预测的值是等于真实值,返回布尔值,将其转换为0和1,然后求和# a = (pred.argmax(1)== y) dim=1表示每一行中的最大值对应的索引号,dim=日表示每 b=(pred.argmax(1)==y).type(torch.float)test_loss /= num_batches # 总体损失值除以数据条数得到平均损失值correct /= size # 求准确率print(f"Test result:in Accuracy: {(100 * correct)}%, Avg loss: {test_loss}") # 表示准确率机器对应的损失值acc_s.append(correct)loss_s.append(test_loss)if correct > best_acc: # 如果新训练得到的准确率大于前面已经求出来的准确率best_acc = correct # 将新的准确率传入值best_accloss_fn = nn.CrossEntropyLoss() # 创建交叉熵损失雨数对象,因为食物的类别是20
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 创建一个优化器,SGD为随机梯度下降,Adam为一种自适应优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma=0.5)#调整学习率函数"训练模型"
epochs = 50acc_s =[]
loss_s=[]
for t in range(epochs):print(f"Epoch {t+1}\n")train(train_dataloader, model, loss_fn, optimizer)scheduler.step()test(test_dataloader, model, loss_fn)
#在每个epoch的训练中,使用scheduler.step()语句进行学习率更新
print('最优训练结果为:',best_acc)
运行结果
六、总结
通过本项目,我们成功地将ResNet18模型迁移到了食物分类任务中,并通过迁移学习显著提高了模型的性能。这种方法不仅减少了训练时间,还提高了模型的泛化能力。未来,我们可以尝试更多的迁移学习策略,如使用不同的预训练模型或调整迁移学习的比例,以进一步提升模型性能。