学习日记-day21-6.3
完成目标:
目录
知识点:
1.集合_哈希表存储过程说明
2.集合_哈希表源码查看
3.集合_哈希表无索引&哈希表有序无序详解
4.集合_TreeSet和TreeMap
5.集合_Hashtable和Vector&Vector源码分析
6.集合_Properties属性集
7.集合_集合嵌套
8.集合_小结
9.IO流_File类
10.IO流_静态变量&构造方法
11.IO流_File类常见方法
知识点:
1.集合_哈希表存储过程说明
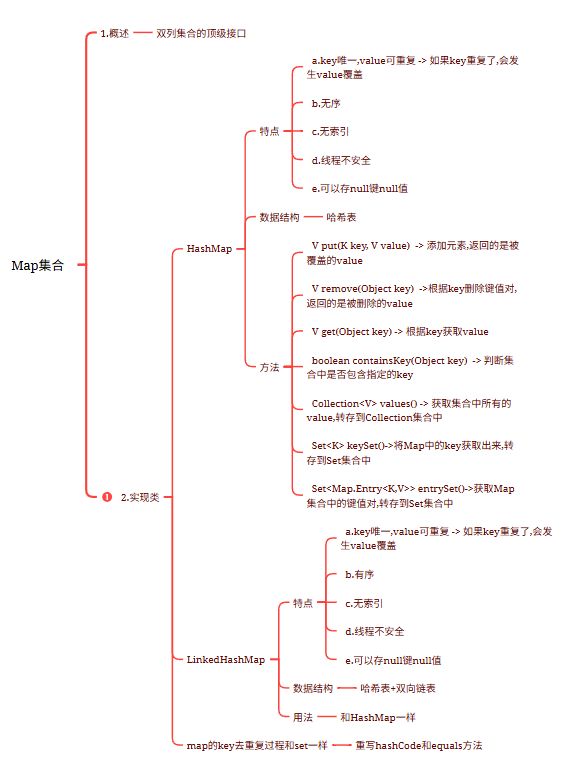
1.HashMap底层数据数据结构:哈希表
2.jdk7:哈希表 = 数组+链表jdk8:哈希表 = 数组+链表+红黑树
3.先算哈希值,此哈希值在HashMap底层经过了特殊的计算得出如果哈希值不一样,直接存如果哈希值一样,再去比较内容,如果内容不一样,也存如果哈希值一样,内容也一样,直接去重复(后面的value将前面的value覆盖)哈希值一样,内容不一样->哈希冲突(哈希碰撞)
4.要知道的点:a.在不指定长度时,哈希表中的数组默认长度为16,HashMap创建出来,一开始没有创建长度为16的数组b.什么时候创建的长度为16的数组呢?在第一次put的时候,底层会创建长度为16的数组c.哈希表中有一个数据加[加载因子]->默认为0.75(加载因子)->代表当元素存储到百分之75的时候要扩容了->2倍d.如果对个元素出现了哈希值一样,内容不一样时,就会在同一个索引上以链表的形式存储,当链表长度达到8并且当前数组长度>=64时,链表就会改成使用红黑树存储如果后续删除元素,那么在同一个索引位置上的元素个数小于6,红黑树会变回链表e.加入红黑树目的:查询快1.问题:哈希表中有数组的存在,但是为啥说没有索引呢? 哈希表中虽然有数组,但是set和map却没有索引,因为存数据的时候有可能在同一个索引下形成链表,如果2索引上有一条链表,那么我们要是按照索引2获取,咱们获取哪个元素呢?所以就取消了按照索引操作的机制2.问题:为什么HashMap是无序的,LinkedHashMap是有序的呢? 原因:HashMap底层哈希表为单向链表 LinkedHashMap底层在哈希表的基础上加了一条双向链表 | 知识点 | 核心内容 | 重点 |
| 哈希表存储过程 | 1. 比较元素哈希值(需重写hashCode); 2. 比较内容(需重写equals); 3. 哈希值不同直接存储; 4. 哈希值相同内容不同(哈希碰撞)仍存储; 5. 哈希值和内容相同则去重 | 哈希碰撞处理逻辑; 七上八下存储规则(JDK7头插法 vs JDK8尾插法) |
| 哈希表结构组成 | 三部分结构: - 横向数组(默认长度16); - 纵向链表; - 红黑树(链表过长时转换) | 数组初始化时机(首次put时创建); 链表转红黑树条件(长度≥8且数组容量≥64) |
| 哈希值计算规则 | 1. 计算原始哈希值; 2. 进行再哈希运算; 3. 通过与运算确定存储位置索引 | 二次哈希必要性; 存储位置计算公式(hash & (n-1)) |
| 扩容机制 | - 加载因子:0.75; - 扩容阈值:当前容量×0.75; - 扩容倍数:2倍; - 首次扩容临界值:12 | 性能优化设计(未满即扩容); 扩容后元素重新散列过程 |
| 结构转换条件 | - 链表→红黑树:长度≥8且数组容量≥64; - 红黑树→链表:元素≤6 | 树化阈值(8); 退化阈值(6); 最小树化容量(64) |
| 关键常量参数 | - DEFAULT_INITIAL_CAPACITY=16; - DEFAULT_LOAD_FACTOR=0.75f; - TREEIFY_THRESHOLD=8; - MIN_TREEIFY_CAPACITY=64 | 源码级记忆点; 各参数间的联动关系 |
2.集合_哈希表源码查看
## 1.HashMap无参数构造方法的分析//HashMap中的静态成员变量
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}解析:使用无参数构造方法创建HashMap对象,将加载因子设置为默认的加载因子,loadFactor=0.75F。========================================================================================
## 2.HashMap有参数构造方法分析HashMap(int initialCapacity, float loadFactor) ->创建Map集合的时候指定底层数组长度以及加载因子public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);//10
}解析:带有参数构造方法,传递哈希表的初始化容量和加载因子- 如果initialCapacity(初始化容量)小于0,直接抛出异常。
- 如果initialCapacity大于最大容器,initialCapacity直接等于最大容器- MAXIMUM_CAPACITY = 1 << 30 是最大容量 (1073741824)
- 如果loadFactor(加载因子)小于等于0,直接抛出异常
- tableSizeFor(initialCapacity)方法计算哈希表的初始化容量。- 注意:哈希表是进行计算得出的容量,而初始化容量不直接等于我们传递的参数。========================================================================================
## 3.tableSizeFor方法分析static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}8 4 2 1规则->无论指定了多少容量,最终经过tableSizeFor这个方法计算之后,都会遵循8421规则去初始化列表容量为了存取高效,尽量较少碰撞解析:该方法对我们传递的初始化容量进行位移运算,位移的结果是 8 4 2 1 码- 例如传递2,结果还是2,传递的是4,结果还是4。
- 例如传递3,结果是4,传递5,结果是8,传递20,结果是32。======================================================================================
## 4.Node 内部类分析哈希表是采用数组+链表的实现方法,HashMap中的内部类Node非常重要,证明HashSet是一个单向链表static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;
}解析:内部类Node中具有4个成员变量- hash,对象的哈希值
- key,作为键的对象
- value,作为值得对象(讲解Set集合,不牵扯值得问题)
- next,下一个节点对象======================================================================================
## 5.存储元素的put方法源码public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}解析:put方法中调研putVal方法,putVal方法中调用hash方法。- hash(key)方法:传递要存储的元素,获取对象的哈希值
- putVal方法,传递对象哈希值和要存储的对象key=======================================================================================
## 6.putVal方法源码Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;解析:方法中进行Node对象数组的判断,如果数组是null或者长度等于0,那么就会调研resize()方法进行数组的扩容。========================================================================================
## 7.resize方法的扩容计算if (oldCap > 0) {if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold
}解析:计算结果,新的数组容量=原始数组容量<<1,也就是乘以2。========================================================================================
## 8.确定元素存储的索引if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);解析:i = (数组长度 - 1) & 对象的哈希值,会得到一个索引,然后在此索引下tab[i],创建链表对象。不同哈希值的对象,也是有可能存储在同一个数组索引下。其中resize()扩容的方法,默认是16tab[i] = newNode(hash, key, value, null);->将元素放在数组中 i就是索引i = (n - 1) & hash0000 0000 0000 0000 0000 0000 0000 1111->15& 0&0=0 0&1=0 1&1=10000 0000 0000 0001 0111 1000 0110 0011->96355
--------------------------------------------------------0000 0000 0000 0000 0000 0000 0000 0011->30000 0000 0000 0000 0000 0000 0000 1111->15& 0&0=0 0&1=0 1&1=10000 0000 0001 0001 1111 1111 0001 0010->1179410
--------------------------------------------------------0000 0000 0000 0000 0000 0000 0000 0010->2=========================================================================================
## 9.遇到重复哈希值的对象Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;解析:如果对象的哈希值相同,对象的equals方法返回true,判断为一个对象,进行覆盖操作。else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}解析:如果对象哈希值相同,但是对象的equals方法返回false,将对此链表进行遍历,当链表没有下一个节点的时候,创建下一个节点存储对象.| 知识点 | 核心内容 | 重点 |
| 哈希表源码解析 | 哈希表的无参构造、put方法、扩容方法(resize)、元素存储位置计算 | 默认加载因子、数组初始化、链表转红黑树条件 |
| 默认加载因子 | 默认加载因子为0.75 | 加载因子的作用和影响 |
| 数组初始化 | 首次put时,数组初始化为长度16 | 数组初始长度和扩容机制 |
| 元素存储位置计算 | 通过哈希值与数组长度-1进行与运算得到存储位置 | 哈希碰撞和存储位置的计算方法 |
| 链表转红黑树 | 链表长度>=8且数组长度>=64时,链表转为红黑树 | 链表转红黑树的条件和目的 |
| 值覆盖 | 新值覆盖老值 | 值覆盖的机制和实现 |
| 指定长度和加载因子 | 可以自行指定哈希表的初始容量和加载因子 | 指定容量和加载因子的方法和注意事项 |
| 数组容量计算 | 实际数组容量为指定容量的二次幂(如8, 16, 32等) | 数组容量计算规则和目的(减少哈希碰撞) |
3.集合_哈希表无索引&哈希表有序无序详解
| 知识点 | 核心内容 | 易混淆点 |
| 哈希表结构特性 | 哈希表包含数组但取消索引机制 | 数组存在与索引缺失的因果关系 |
| 哈希冲突处理 | 同一索引下可能形成链表结构 | 链表长度与查询效率的关系 |
| HashMap无序原理 | 使用单向链表导致遍历顺序与存储顺序不一致 | 存储顺序与检索顺序的差异 |
| LinkedHashMap有序原理 | 通过双向链表维护元素插入顺序 | 双向链表的前驱/后继指针机制 |
| 数据结构对比 | 普通HashMap vs LinkedHashMap的底层实现差异 | 单向链表与双向链表的结构差异 |
4.集合_TreeSet和TreeMap
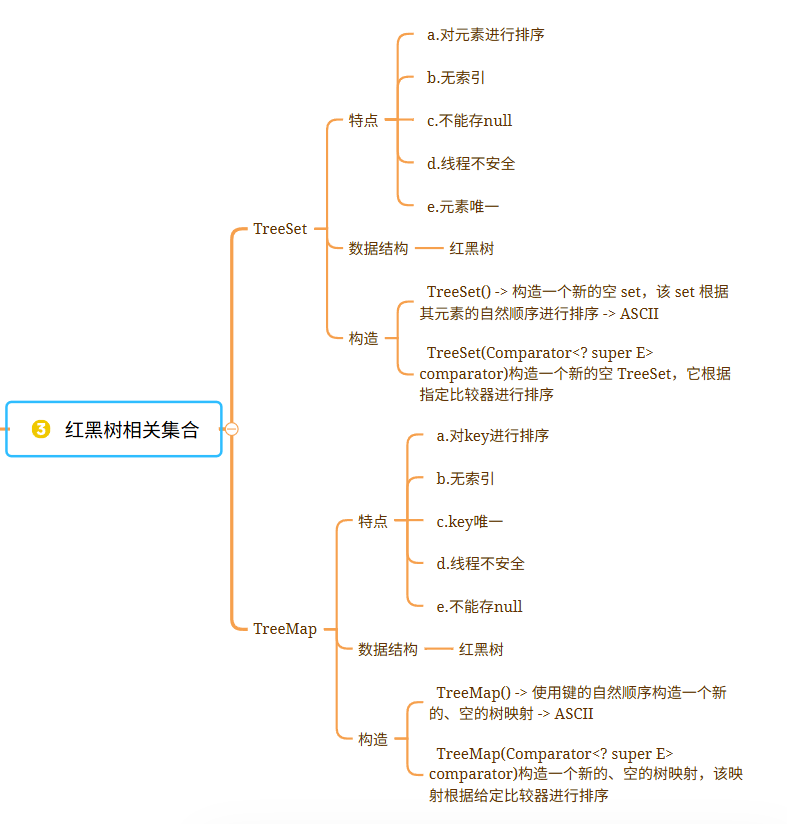
## TreeSet1.概述:TreeSet是Set的实现类
2.特点:a.对元素进行排序b.无索引c.不能存nulld.线程不安全e.元素唯一
3.数据结构:红黑树 构造:TreeSet() -> 构造一个新的空 set,该 set 根据其元素的自然顺序进行排序 -> ASCII TreeSet(Comparator<? super E> comparator)构造一个新的空 TreeSet,它根据指定比较器进行排序 public class Person {private String name;private Integer age;public Person() {}public Person(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return Objects.equals(name, person.name) && Objects.equals(age, person.age);}@Overridepublic int hashCode() {return Objects.hash(name, age);}
}public class Demo01TreeSet {public static void main(String[] args) {TreeSet<String> set1 = new TreeSet<>();set1.add("c.白毛浮绿水");set1.add("a.鹅鹅鹅");set1.add("b.曲项向天歌");set1.add("d.红掌拨清波");System.out.println(set1);System.out.println("=====================");TreeSet<Person> set2 = new TreeSet<>(new Comparator<Person>() {@Overridepublic int compare(Person o1, Person o2) {return o1.getAge()-o2.getAge();}});set2.add(new Person("柳岩",18));set2.add(new Person("涛哥",12));set2.add(new Person("张三",20));System.out.println(set2);}
}================================================================================## TreeMap1.概述:TreeMap是Map的实现类
2.特点:a.对key进行排序b.无索引c.key唯一d.线程不安全e.不能存null
3.数据结构:红黑树 构造:TreeMap() -> 使用键的自然顺序构造一个新的、空的树映射 -> ASCII TreeMap(Comparator<? super E> comparator)构造一个新的、空的树映射,该映射根据给定比较器进行排序public class Person {private String name;private Integer age;public Person() {}public Person(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return Objects.equals(name, person.name) && Objects.equals(age, person.age);}@Overridepublic int hashCode() {return Objects.hash(name, age);}
}public class Demo02TreeMap {public static void main(String[] args) {TreeMap<String, String> map1 = new TreeMap<>();map1.put("c","白毛浮绿水");map1.put("a","鹅鹅鹅");map1.put("b","曲项向天歌");map1.put("d","红掌拨清波");System.out.println(map1);System.out.println("=============");TreeMap<Person, String> map2 = new TreeMap<>(new Comparator<Person>() {@Overridepublic int compare(Person o1, Person o2) {return o1.getAge()-o2.getAge();}});map2.put(new Person("柳岩",18),"北京");map2.put(new Person("涛哥",12),"北京");map2.put(new Person("三上",20),"北京");System.out.println(map2);}
}| 知识点 | 核心内容 | 重点 |
| TreeSet | - Set接口实现类; - 红黑树数据结构; - 元素唯一且自动排序; - 无索引、线程不安全; - 不允许存储null | - 排序规则:自然排序(如ASCII码)或自定义比较器; - 自定义对象需实现Comparable或传入Comparator |
| TreeMap | - Map接口实现类; - 红黑树数据结构; - 对Key自动排序; - Key唯一且不可为null; - 线程不安全 | - Key排序逻辑与TreeSet一致; - 自定义Key需处理比较逻辑 |
| 红黑树特性 | - 自平衡二叉查找树; - 保证基本操作时间复杂度为O(log n); - 排序依赖节点比较规则 | - 与哈希表(HashMap)的查询效率对比; - 平衡性维护机制 |
| Comparator使用 | - 通过比较器定制排序规则; - 示例:(o1, o2) -> o1.getAge() - o2.getAge() | - 升序/降序写法易混淆; - Lambda表达式简化代码 |
5.集合_Hashtable和Vector&Vector源码分析
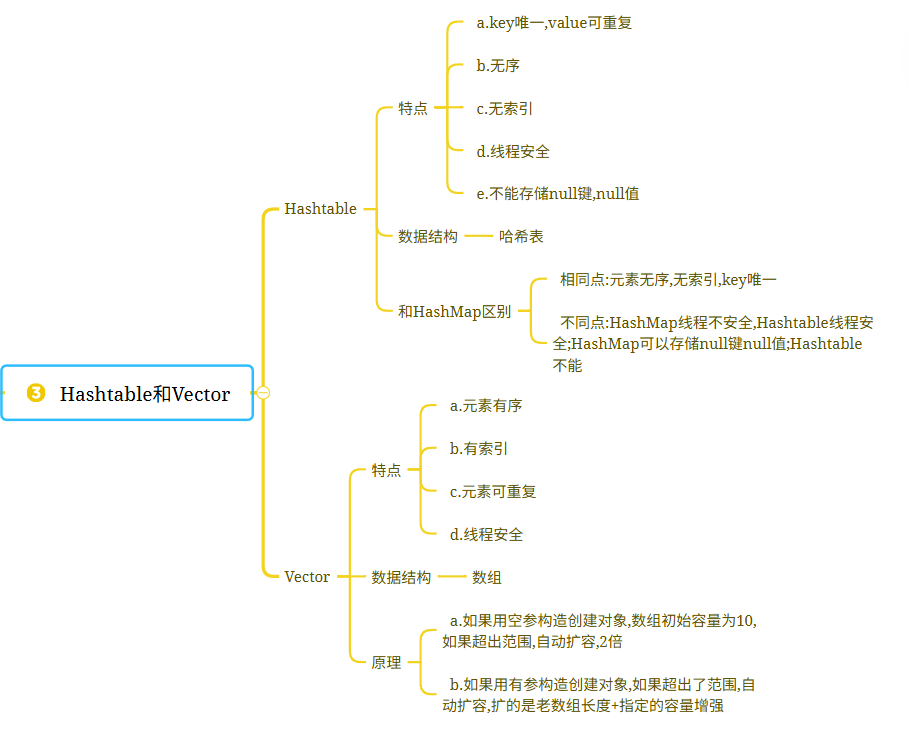
## 1.Hashtable集合1.概述:Hashtable是Map的实现类
2.特点:a.key唯一,value可重复b.无序c.无索引d.线程安全 e.不能存储null键,null值
3.数据结构:哈希表 public class Demo01Hashtable {public static void main(String[] args) {Hashtable<String, String> table = new Hashtable<>();table.put("迪丽热巴","马尔扎哈");table.put("古力娜扎","涛哥思密达");table.put("古力娜扎","雷霆嘎巴");table.put("玛卡巴卡","哈哈哈哈");//table.put(null,null);System.out.println(table);}
}> HashMap和Hashtable区别:
>
> 相同点:元素无序,无索引,key唯一
>
> 不同点:HashMap线程不安全,Hashtable线程安全
> HashMap可以存储null键null值;Hashtable不能============================================================================
## 2.Vector集合1.概述:Vector是List接口的实现类
2.特点:a.元素有序b.有索引c.元素可重复d.线程安全
3.数据结构:数组
4.源码分析:a.如果用空参构造创建对象,数组初始容量为10,如果超出范围,自动扩容,2倍b.如果用有参构造创建对象,如果超出了范围,自动扩容,扩的是老数组长度+指定的容量增强public class Demo02Vector {public static void main(String[] args) {Vector<String> vector = new Vector<>();vector.add("张三");vector.add("李四");for (String s : vector) {System.out.println(s);}}
}
| 知识点 | 核心内容 | 重点 |
| HashTable特点 | Map实现类、键唯一值可重复、无序无索引、线程安全、不允许null键值 | 与HashMap的线程安全性对比 |
| HashTable数据结构 | 哈希表结构,基本使用与HashMap类似 | 存储null值会抛出NullPointerException |
| HashTable与HashMap对比 | 相同点:无序无索引、键唯一; 不同点:HashTable线程安全/不允许null,HashMap反之 | 面试高频对比维度 |
| Vector特点 | List实现类、有序有索引、元素可重复、线程安全 | 与ArrayList的线程安全性对比 |
| Vector数据结构 | 数组结构,通过索引访问元素 | 初始容量和扩容机制的特殊性 |
| Vector扩容机制 | 空参构造:初始容量10,2倍扩容; 有参构造:自定义初始容量,扩容量为原容量+增量值 | 容量增量参数的作用 |
| Vector源码分析 | 构造时立即初始化数组,add方法用synchronized实现线程安全 | 与ArrayList延迟初始化的区别 |
6.集合_Properties属性集
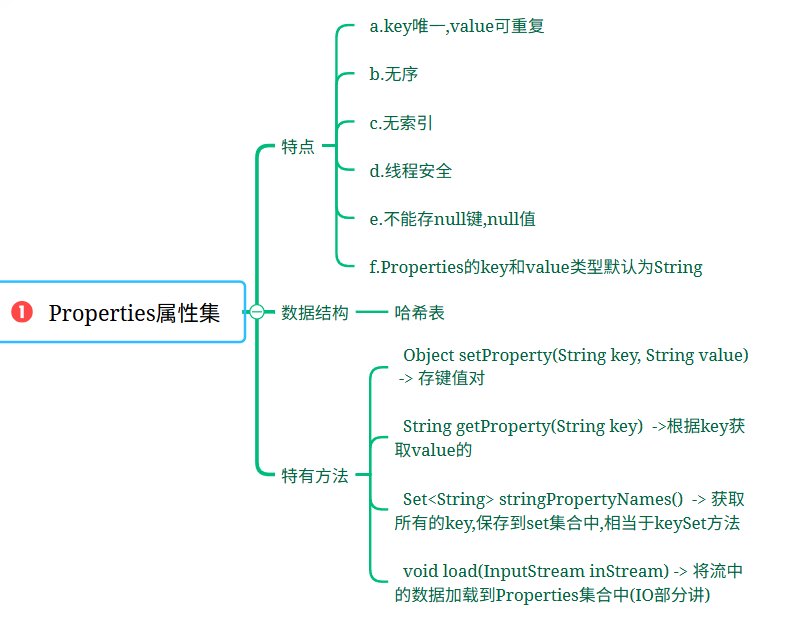
1.概述:Properties 继承自 Hashtable
2.特点:a.key唯一,value可重复b.无序c.无索引d.线程安全e.不能存null键,null值f.Properties的key和value类型默认为String
3.数据结构:哈希表
4.特有方法:Object setProperty(String key, String value) -> 存键值对String getProperty(String key) ->根据key获取value的Set<String> stringPropertyNames() -> 获取所有的key,保存到set集合中,相当于keySet方法void load(InputStream inStream) -> 将流中的数据加载到Properties集合中(IO部分讲) public class Demo01Properties {public static void main(String[] args) {Properties properties = new Properties();//Object setProperty(String key, String value) -> 存键值对properties.setProperty("username","root");properties.setProperty("password","1234");System.out.println(properties);//String getProperty(String key) ->根据key获取value的System.out.println(properties.getProperty("username"));//Set<String> stringPropertyNames() -> 获取所有的key,保存到set集合中,相当于keySet方法Set<String> set = properties.stringPropertyNames();for (String key : set) {System.out.println(properties.getProperty(key));}}
}| 知识点 | 核心内容 | 重点 |
| properties属性集基本概念 | 是一个集合,与IO流结合使用,继承自HashTable | 与其他集合的区别,继承关系 |
| properties属性集特点 | - k唯一,value可重复 - 无序 - 无索引 - 线程安全 - 不能存null键和null值 | 与HashTable特点的异同 |
| 数据类型 | k和value类型默认都是String | 与其他集合需要指明元素泛型不同 |
| 数据结构 | 哈希表结构 | 与HashTable和Map接口的关系 |
| 特有方法 | - setProperty(设置属性) - getProperty(根据k获取value) - stringPropertyNames(获取所有k的集合) | 与HashTable和Map接口方法的区别 |
| 与IO流结合 | load方法(将流中的数据加载到properties集合中) | 需先掌握IO流知识 |
| 基本使用示例 | 创建Properties对象,使用set/put方法添加属性,使用getProperty方法获取值,使用stringPropertyNames方法遍历所有k | 实际操作中的步骤和注意事项 |
7.集合_集合嵌套
## 1.List嵌套List需求:创建2个List集合,每个集合中分别存储一些字符串,将2个集合存储到第3个List集合中public class Demo01ListInList {public static void main(String[] args) {ArrayList<String> list1 = new ArrayList<>();list1.add("杨过");list1.add("小龙女");list1.add("尹志平");ArrayList<String> list2 = new ArrayList<>();list2.add("涛哥");list2.add("金莲");list2.add("三上");/*list中的元素是两个 ArrayList<String>所以泛型也应该是 ArrayList<String>*/ArrayList<ArrayList<String>> list = new ArrayList<>();list.add(list1);list.add(list2);/*先遍历大集合,将两个小集合遍历出来再遍历两个小集合,将元素获取出来*/for (ArrayList<String> arrayList : list) {for (String s : arrayList) {System.out.println(s);}}}
}=======================================================================================
## 2.List嵌套Map1班级有第三名同学,学号和姓名分别为:1=张三,2=李四,3=王五,2班有三名同学,学号和姓名分别为:1=黄晓明,2=杨颖,3=刘德华,请将同学的信息以键值对的形式存储到2个Map集合中,在将2个Map集合存储到List集合中。public class Demo02ListInMap {public static void main(String[] args) {//1.创建两个map集合HashMap<Integer, String> map1 = new HashMap<>();map1.put(1,"张三");map1.put(2,"李四");map1.put(3,"王五");HashMap<Integer, String> map2 = new HashMap<>();map2.put(1,"黄晓明");map2.put(2,"杨颖");map2.put(3,"刘德华");//2.创建一个存储map集合的list集合ArrayList<HashMap<Integer, String>> list = new ArrayList<>();list.add(map1);list.add(map2);//3.先遍历list集合,再遍历map集合for (HashMap<Integer, String> map : list) {Set<Map.Entry<Integer, String>> set = map.entrySet();for (Map.Entry<Integer, String> entry : set) {System.out.println(entry.getKey()+"..."+entry.getValue());}}}
}=====================================================================## 3.Map嵌套Map- JavaSE 集合 存储的是 学号 键,值学生姓名- 1 张三- 2 李四
- JavaEE 集合 存储的是 学号 键,值学生姓名- 1 王五- 2 赵六public class Demo03MapInMap {public static void main(String[] args) {//1.创建两个map集合HashMap<Integer, String> map1 = new HashMap<>();map1.put(1,"张三");map1.put(2,"李四");HashMap<Integer, String> map2 = new HashMap<>();map2.put(1,"王五");map2.put(2,"赵六");HashMap<String, HashMap<Integer, String>> map = new HashMap<>();map.put("javase",map1);map.put("javaee",map2);Set<Map.Entry<String, HashMap<Integer, String>>> set = map.entrySet();for (Map.Entry<String, HashMap<Integer, String>> entry : set) {HashMap<Integer, String> hashMap = entry.getValue();Set<Integer> set1 = hashMap.keySet();for (Integer key : set1) {System.out.println(key+"..."+hashMap.get(key));}}}
}| 知识点 | 核心内容 | 重点 |
| 集合嵌套基本概念 | 集合里面套集合,如list in list | 区分集合与集合中的元素 |
| list嵌套list实现 | 创建两个list集合,分别存储字符串,再将这两个list存入第三个list | 泛型的使用:第三个list的泛型应为ArrayList |
| 遍历嵌套list | 先遍历大集合,再遍历小集合,获取元素 | 遍历方法:for循环结合get()方法 |
| map嵌套map或list概念 | 将多个map集合存储到list集合中,或map的值为另一个map | 区分map的key和value,以及嵌套的层次 |
| list嵌套map实现 | 创建两个map集合,存储相关信息,再将这两个map存入list | 泛型的使用:list的泛型应为HashMap |
| 遍历嵌套map | 先遍历list,再遍历map,使用keySet()或entrySet() | 遍历map的方法选择,以及获取key和value |
| map嵌套map实现 | 创建一个map,其值为另一个map,如学号为key,学生信息为value的map | 泛型及嵌套map的声明与初始化 |
| 遍历嵌套map(深层) | 先遍历大map获取小map,再遍历小map获取具体信息 | 多层遍历的逻辑与实现 |
| 易混淆点 | 泛型的使用、嵌套集合的遍历顺序 | 泛型类型需与集合元素类型一致,遍历需按层次进行 |
8.集合_小结
9.IO流_File类
| 知识点 | 核心内容 | 重点 |
| File类 | 文件和目录路径名的抽象表示,通过路径定位文件/文件夹对象 | 目录=文件夹; 路径定位逻辑(非单纯文件名判断) |
| 文本文档定义 | 用记事本打开且人能看懂的文件(如.txt/.html/.css) | 扩展名≠绝对类型(如.doc非文本文档) |
| 路径分隔符 | 路径名称分隔符(Windows\/Linux/) vs 路径分隔符(环境变量;) | 区分“父路径”(完整路径)与“父文件夹”(单级目录) |
| 文件类型误判案例 | .jpg可能是文件夹;.txt非唯一文本文档格式 | 扩展名可伪造,需通过实际内容验证 |
| IO流模块划分 | 模块21:File类+字节流+字符流;模块22:延续IO流深化 | 知识点分阶段讲解逻辑 |
10.IO流_静态变量&构造方法
static String pathSeparator:与系统有关的路径分隔符,为了方便,它被表示为一个字符串。
static String separator:与系统有关的默认名称分隔符,为了方便,它被表示为一个字符串。 public class Demo01File {public static void main(String[] args) {//file01();file02();}/*将来写代码如何正确编写一个路径用java代码*/private static void file02() {String path1 = "E:\\Idea\\io";System.out.println(path1);System.out.println("==================");//要求代码写完,一次编写,到处运行String path2 = "E:"+File.separator+"Idea"+File.separator+"io";System.out.println(path2);}private static void file01() {//static String pathSeparator:与系统有关的路径分隔符,为了方便,它被表示为一个字符串。String pathSeparator = File.pathSeparator;System.out.println("pathSeparator = " + pathSeparator); // ;//static String separator:与系统有关的默认名称分隔符,为了方便,它被表示为一个字符串。String separator = File.separator;System.out.println("separator = " + separator); // \}
}=================================================================================
## File的构造方法File(String parent, String child) 根据所填写的路径创建File对象parent:父路径child:子路径
File(File parent, String child) 根据所填写的路径创建File对象parent:父路径,是一个File对象child:子路径
File(String pathname) 根据所填写的路径创建File对象pathname:直接指定路径 public class Demo02File {public static void main(String[] args) {//File(String parent, String child) 根据所填写的路径创建File对象//parent:父路径//child:子路径File file1 = new File("E:\\Idea\\io", "1.jpg");System.out.println("file1 = " + file1);//File(File parent, String child) 根据所填写的路径创建File对象//parent:父路径,是一个File对象//child:子路径File parent = new File("E:\\Idea\\io");File file2 = new File(parent, "1.jpg");System.out.println("file2 = " + file2);//File(String pathname) 根据所填写的路径创建File对象//pathname:直接指定路径File file3 = new File("E:\\Idea\\io\\1.jpg");System.out.println("file3 = " + file3);}
}细节:我们创建File对象的时候,传递的路径可以是不存在的,但是传递不存在的路径| 知识点 | 核心内容 | 重点 |
| File类的静态成员 | File.pathSeparator(系统路径分隔符,如;)和File.separator(默认名称分隔符,如\) | 区分路径分隔符与名称分隔符:路径分隔符用于分隔多个路径(如环境变量),名称分隔符用于分隔路径中的层级目录 |
| 路径字符串的转义处理 | Java中需用双反斜杠\\表示单反斜杠(转义字符特性) | 易错点:直接写单反斜杠会导致转义错误(如\n被解析为换行符) |
| 跨系统路径兼容写法 | 动态拼接路径时使用File.separator替代硬编码斜杠(如"E:" + File.separator + "IO") | 关键技巧:通过静态成员适配不同操作系统(Windows/Linux)的路径格式 |
| File构造方法 | 1. File(String parent, String child); 2. File(File parent, String child); 3. File(String pathname) | 构造差异:前两种分父子路径拼接,第三种直接指定完整路径;允许传递不存在的路径(仅格式校验) |
| 路径操作演示 | 示例代码展示路径拼接(如定位E:\IO\1.jpg) 和静态成员调用(File.pathSeparator输出) | 实践注意:路径不存在时不报错,但无实际文件操作意义 |
11.IO流_File类常见方法
## File的获取方法String getAbsolutePath() -> 获取File的绝对路径->带盘符的路径
String getPath() ->获取的是封装路径->new File对象的时候写的啥路径,获取的就是啥路径
String getName() -> 获取的是文件或者文件夹名称
long length() -> 获取的是文件的长度 -> 文件的字节数 private static void file01() {//String getAbsolutePath() -> 获取File的绝对路径->带盘符的路径File file1 = new File("1.txt");System.out.println("file1.getAbsolutePath() = " + file1.getAbsolutePath());//String getPath() ->获取的是封装路径->new File对象的时候写的啥路径,获取的就是啥路径File file2 = new File("io\\1.txt");System.out.println("file2.getPath() = " + file2.getPath());//String getName() -> 获取的是文件或者文件夹名称File file3 = new File("E:\\Idea\\io\\1.jpg");System.out.println("file3.getName() = " + file3.getName());//long length() -> 获取的是文件的长度 -> 文件的字节数File file4 = new File("E:\\Idea\\io\\1.txt");System.out.println("file4.length() = " + file4.length());}=======================================================================================## File的创建方法boolean createNewFile() -> 创建文件如果要创建的文件之前有,创建失败,返回false如果要创建的文件之前没有,创建成功,返回trueboolean mkdirs() -> 创建文件夹(目录)既可以创建多级文件夹,还可以创建单级文件夹如果要创建的文件夹之前有,创建失败,返回false如果要创建的文件夹之前没有,创建成功,返回trueprivate static void file02() throws IOException {/*boolean createNewFile() -> 创建文件如果要创建的文件之前有,创建失败,返回false如果要创建的文件之前没有,创建成功,返回true*/File file1 = new File("E:\\Idea\\io\\1.txt");System.out.println("file1.createNewFile() = " + file1.createNewFile());/*boolean mkdirs() -> 创建文件夹(目录)既可以创建多级文件夹,还可以创建单级文件夹如果要创建的文件夹之前有,创建失败,返回false如果要创建的文件夹之前没有,创建成功,返回true*/File file2 = new File("E:\\Idea\\io\\haha\\heihei\\hehe");System.out.println("file2.mkdirs() = " + file2.mkdirs());}=======================================================================================## File类的删除方法boolean delete()->删除文件或者文件夹注意:1.如果删除文件,不走回收站2.如果删除文件夹,必须是空文件夹,而且也不走回收站 private static void file03() {//boolean delete()->删除文件或者文件夹//File file1 = new File("E:\\Idea\\io\\1.txt");File file1 = new File("E:\\Idea\\io\\haha");System.out.println("file1.delete() = " + file1.delete());}=======================================================================================## File类的判断方法boolean isDirectory() -> 判断是否为文件夹
boolean isFile() -> 判断是否为文件
boolean exists() -> 判断文件或者文件夹是否存在 private static void file04() {File file = new File("E:\\Idea\\io\\1.txt");// boolean isDirectory() -> 判断是否为文件夹System.out.println("file.isDirectory() = " + file.isDirectory());// boolean isFile() -> 判断是否为文件System.out.println("file.isFile() = " + file.isFile());// boolean exists() -> 判断文件或者文件夹是否存在System.out.println("file.exists() = " + file.exists());}=======================================================================================## File的遍历方法String[] list() -> 遍历指定的文件夹,返回的是String数组
File[] listFiles()-> 遍历指定的文件夹,返回的是File数组 ->这个推荐使用细节:listFiles方法底层还是list方法调用list方法,遍历文件夹,返回一个Stirng数组,遍历数组,将数组中的内容一个一个封装到File对象中,然后再将File对象放到File数组中private static void file05() {File file = new File("E:\\Idea\\io\\aa");//String[] list() -> 遍历指定的文件夹,返回的是String数组String[] list = file.list();for (String s : list) {System.out.println(s);}//File[] listFiles()-> 遍历指定的文件夹,返回的是File数组 ->这个推荐使用System.out.println("==============");File[] files = file.listFiles();for (File file1 : files) {System.out.println(file1);}}| 知识点 | 核心内容 | 注意事项 |
| File类绝对路径获取 | getAbsolutePath()方法获取带盘符的完整路径 | 直接写文件名时路径定位在当前项目目录下 |
| File类封装路径获取 | getPath()返回new对象时传入的原始路径 | 不是相对路径,严格返回构造参数值 |
| 文件/文件夹名称获取 | getName()提取路径最后层级名称 | 对文件夹和文件通用处理逻辑 |
| 文件字节数获取 | length()返回文件字节大小 | 空文件返回0,仅适用于文件(非文件夹) |
| 文件创建方法 | createNewFile()创建新文件(存在返回false) | 需处理IOException,路径需合法 |
| 文件夹创建方法 | mkdirs()创建单级/多级目录 | 带s后缀支持多级创建,已存在返回false |
| 删除操作 | delete()删除文件/空文件夹 | 不走回收站,文件夹必须为空才能删除 |
| 类型判断方法 | isFile()/isDirectory()/exists() | 判断依据是实际类型而非名称后缀 |
| 单级遍历方法 | list()返回String数组,listFiles()返回File对象数组 | listFiles()底层仍调用list()方法 |
| 路径定位特性 | 未指定绝对路径时默认定位项目目录 | IDEA环境下的特殊路径解析规则 |