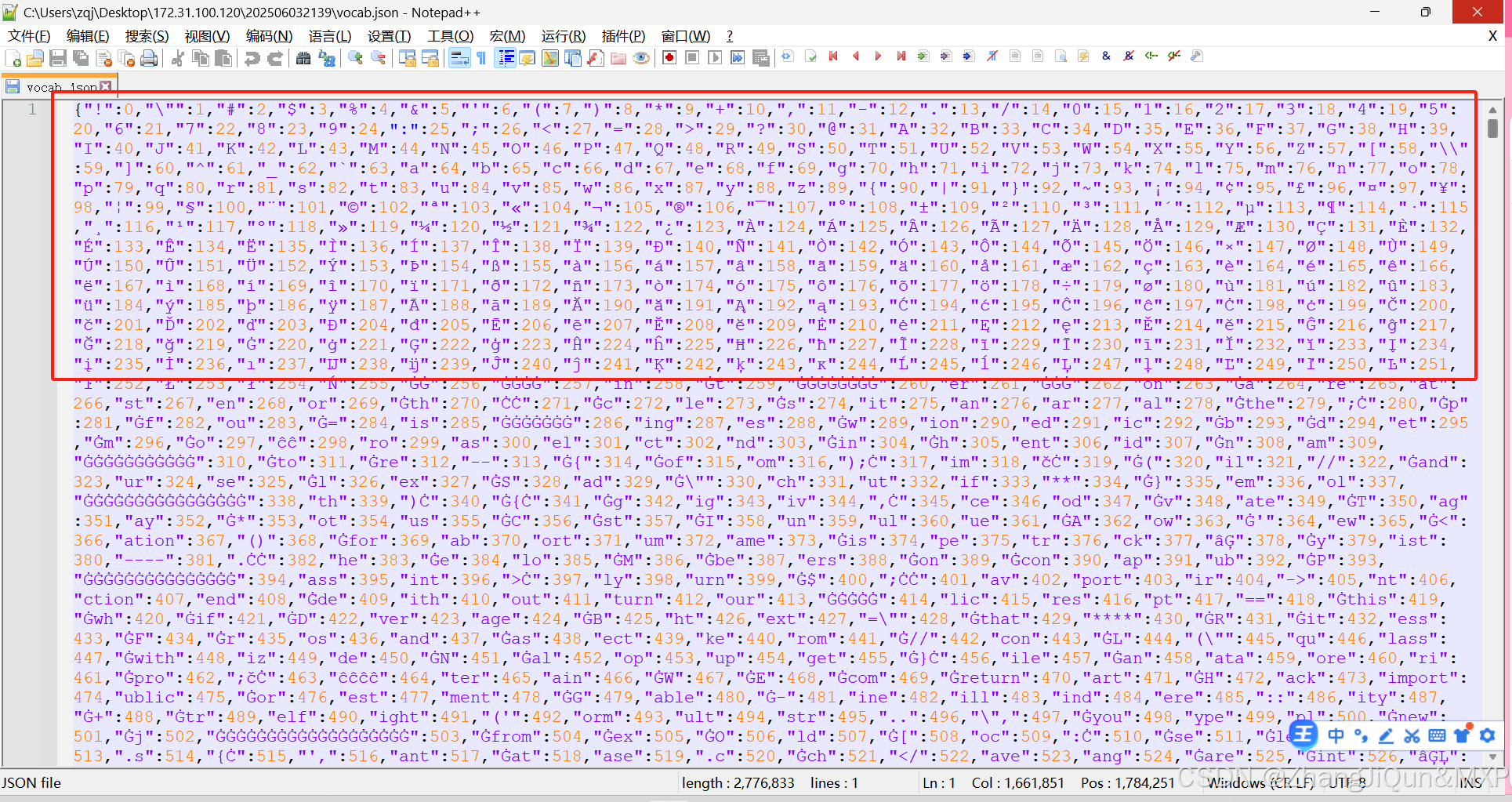
当前位置: 首页 > news >正文 中英混合编码解码全解析 news 2025/6/7 2:29:31 qwen模型分词器怎么映射的:中英混合编码解码全解析 中英文混合编码与解码的过程,本质是 字符编码标准(如 UTF-8)对多语言字符的统一处理 ,核心逻辑围绕“字节序列 ↔ 字符映射”展开 北京智源人工智能研究院中文tokenID qwen模型分词器文件 一、编码阶段:统一转为字节序列 无论中文、英文,编码时都会按 UTF-8 规则转为 查看全文 http://www.xdnf.cn/news/792379.html 相关文章: 飞牛fnNAS使用群辉DSM系统 C#基础语法 DMA-BUF与mmap共享内存对比分析 辩证唯物主义精要 【Golang】使用gin框架导出excel和csv文件 基于Python协同过滤的电影推荐系统研究 DDR信号线走线关键点 Vert.x学习笔记-EventLoop与Handler的关系 WebTracing:一站式前端埋点监控解决方案 多线程编程中的重要概念 CSP模式下如何保证不抖动 查询去重使用 DISTINCT 的性能分析 Ubuntu安装Docker命令清单(以20.04为例) 文件批量重命名 Tiktok App 登录账号、密码、验证码 XOR 加密算法 C++指针加减法详解:深入理解指针运算的本质 ES6 Promise 状态机 外贸建站平台推荐 shell脚本的常用命令 2024年认证杯SPSSPRO杯数学建模D题(第二阶段)AI绘画带来的挑战解题全过程文档及程序 Linux 命令全讲解:从基础操作到高级运维的实战指南 人脸识别技术应用备案系统已开启! Python趣学篇:Pygame重现《黑客帝国》数字雨 ArcGIS Pro 3.4 二次开发 - 地图创作 2 车规级BMS芯片国产化!精准电量监测延长电池寿命 JS语法笔记 PyTorch——非线性激活(5) Linux系统下Google浏览器无法使用中文输入的临时解决方案 AIGC学习笔记(9)——AI大模型开发工程师 OD 算法题 B卷【代码编辑器】
qwen模型分词器怎么映射的:中英混合编码解码全解析 中英文混合编码与解码的过程,本质是 字符编码标准(如 UTF-8)对多语言字符的统一处理 ,核心逻辑围绕“字节序列 ↔ 字符映射”展开 北京智源人工智能研究院中文tokenID qwen模型分词器文件 一、编码阶段:统一转为字节序列 无论中文、英文,编码时都会按 UTF-8 规则转为