如何爬取google应用商店的应用分类呢?
以下是爬取Google Play商店应用包名(package name)和对应分类的完整解决方案,采用Scrapy+Playwright组合应对动态渲染页面,并处理反爬机制:
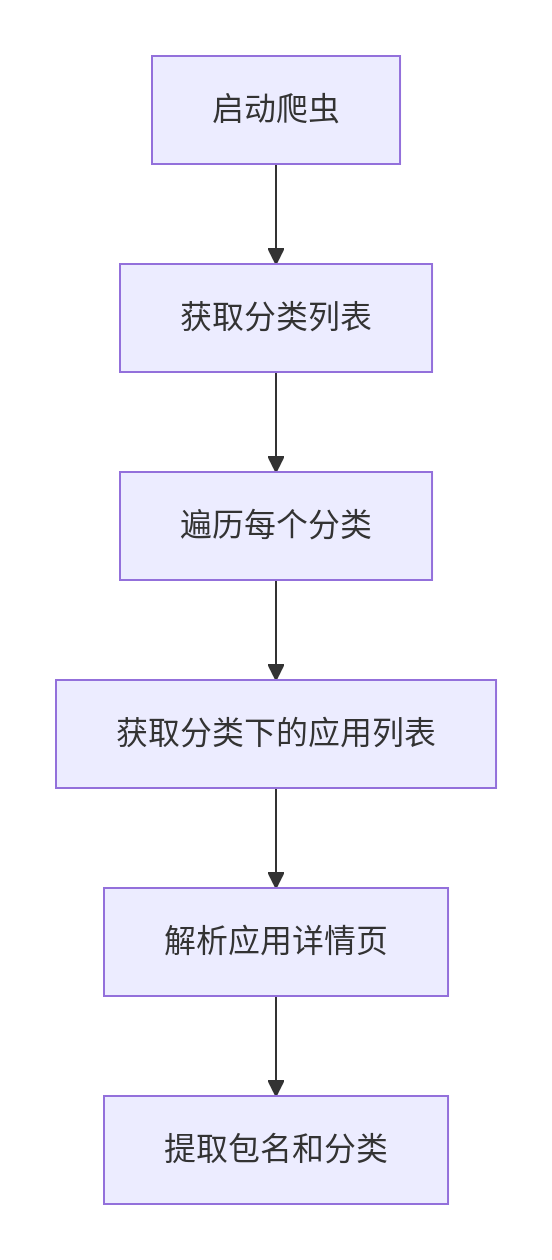
完整爬虫实现
1. 安装必要库
# 卸载现有安装pip uninstall playwright scrapy-playwright -y# 重新安装(指定国内镜像加速)pip install playwright scrapy-playwright -i https://pypi.tuna.tsinghua.edu.cn/simple# 安装浏览器二进制文件playwright install chromiumplaywright install-deps # Linux系统需要额外依赖
2. 创建Scrapy项目
scrapy startproject google_play_crawler cd google_play_crawler
3. 修改settings.py
# 启用Playwright和中间件DOWNLOAD_HANDLERS = {"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler","https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",}TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"# 反爬配置USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"ROBOTSTXT_OBEY = FalseCONCURRENT_REQUESTS = 2DOWNLOAD_DELAY = 3# Playwright设置PLAYWRIGHT_BROWSER_TYPE = "chromium"PLAYWRIGHT_LAUNCH_OPTIONS = {"headless": True,"timeout": 30000,}
4. 爬虫主代码spiders/google_play.py
import scrapyfrom scrapy.http import Requestimport refrom urllib.parse import urljoinclass GooglePlaySpider(scrapy.Spider):name = 'google_play'start_urls = ['https://play.google.com/store/apps']custom_settings = {'FEEDS': {'apps.csv': {'format': 'csv','fields': ['package_name', 'app_name', 'main_category', 'sub_category'],'overwrite': True}}}def start_requests(self):for url in self.start_urls:yield Request(url,callback=self.parse_categories,meta={"playwright": True})def parse_categories(self, response):"""解析所有分类链接"""# 新版Google Play分类选择器category_links = response.xpath('//a[contains(@href, "/store/apps/category/")]/@href').extract()for link in set(category_links): # 去重full_url = urljoin(response.url, link)category_name = link.split('/')[-1]yield Request(full_url,callback=self.parse_app_list,meta={"playwright": True,"category": category_name})def parse_app_list(self, response):"""解析应用列表页"""app_links = response.xpath('//a[contains(@href, "/store/apps/details?id=")]/@href').extract()for link in set(app_links):package_name = link.split('=')[-1]full_url = urljoin(response.url, link)yield Request(full_url,callback=self.parse_app_detail,meta={"playwright": True,"package_name": package_name,"main_category": response.meta["category"]})# 分页处理next_page = response.xpath('//a[contains(@aria-label, "Next page")]/@href').extract_first()if next_page:yield Request(urljoin(response.url, next_page),callback=self.parse_app_list,meta={"playwright": True,"category": response.meta["category"]})def parse_app_detail(self, response):"""解析应用详情页"""item = {"package_name": response.meta["package_name"],"app_name": response.xpath('//h1[@itemprop="name"]/span/text()').get(),"main_category": response.meta["main_category"],"sub_category": response.xpath('//a[@itemprop="genre"]/text()').get()}# 额外信息(可选)item['rating'] = response.xpath('//div[@class="TT9eCd"]/@aria-label').get()item['downloads'] = response.xpath('//div[contains(text(), "Downloads")]/following-sibling::span//text()').get()yield item
5.google_play_crawler目录启动Google商店爬虫
scrapy crawl google_play -O Google.csv
执行后可以看到开始进行Google 应用商店的应用分类可视化爬虫
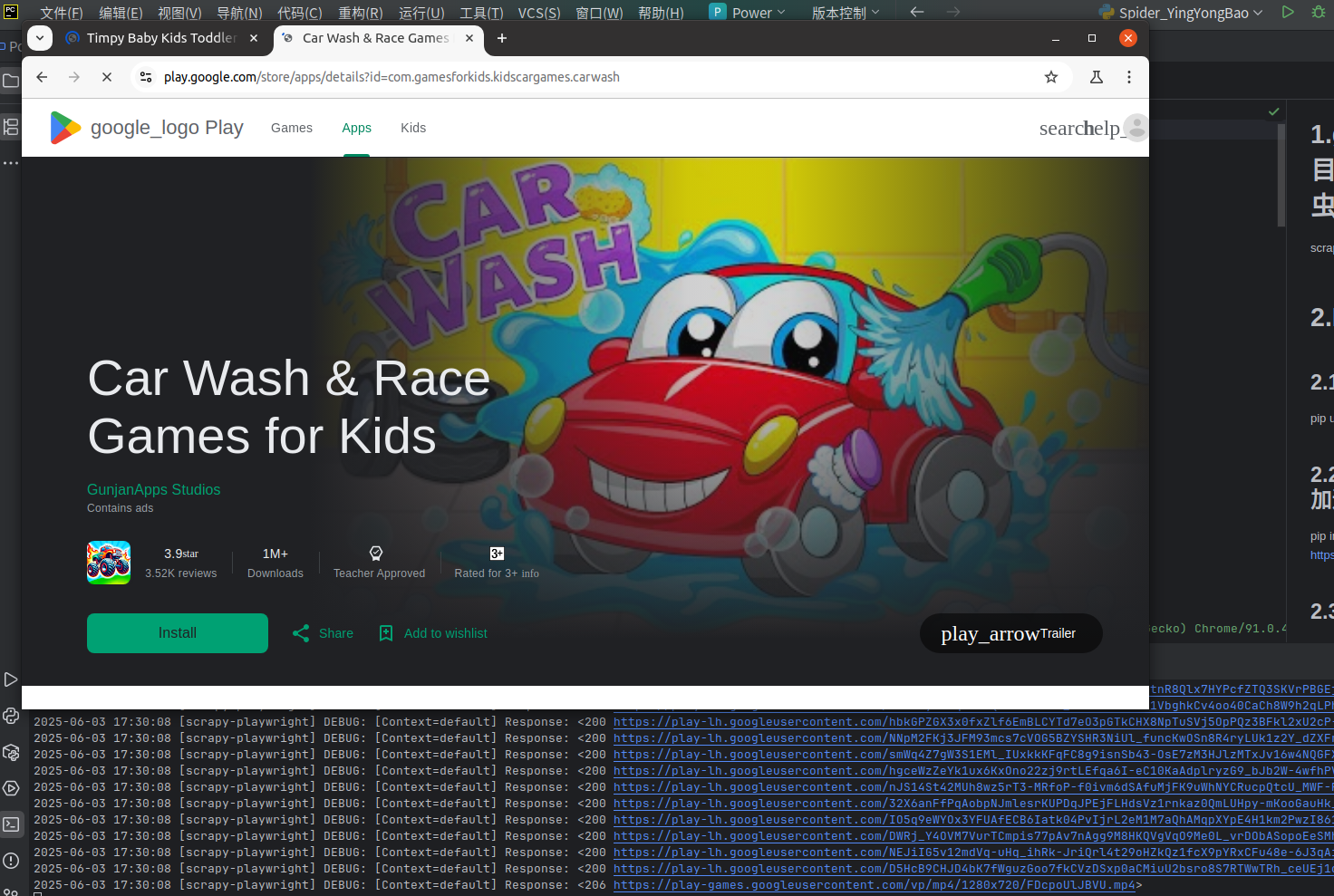
6.运行结果
可以爬取应用的分类,但是感觉稳定哈。可能是国内VPN不稳定,且爬虫很费时间,感觉跑完也需要好几小时以上哈。
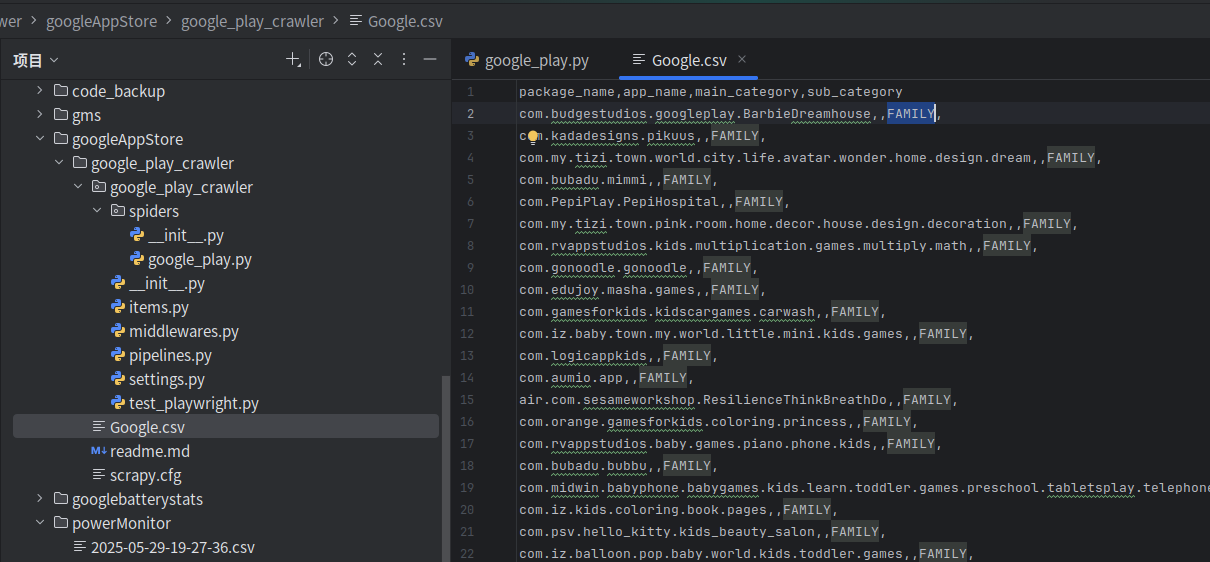
我家公司没有自己的应用商店,故应用类型需要自己爬虫生成数据库,供后续代码查询实现了。