DPDK与网络协议栈
DPDK与网络协议栈
- DPDK简介
- 实现使用DPDK收发数据
- 通过UDP收发数据
- 通过 TCP 收发数据
DPDK简介
DPDK 是是 Intel 提供的数据平面开发工具集,为(IA)处理器架构下用户高效的数据包处理提供函数以及驱动支持,不同于 Linux 下是以通用性为目的,他主要就是为了网络数据包的高效处理,DPDK 应用程序是运行在用户空间上利用自身提供的数据平面库来收发数据包,绕过了 Linux 内核协议栈对数据包处理过程。
通过下图我们更好的理解一下这个概念:
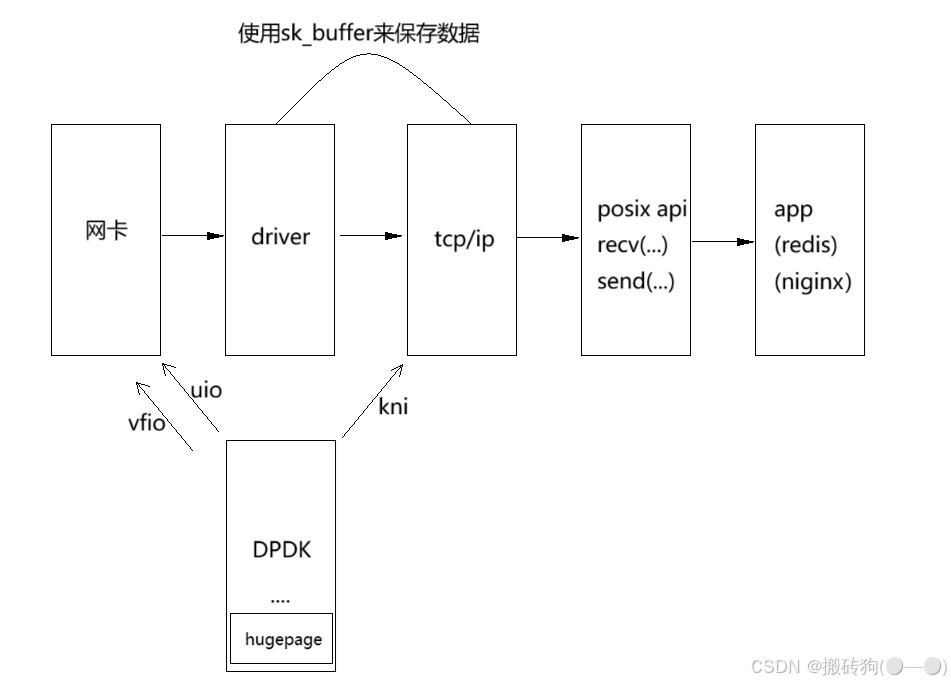
在这儿我们需要理解几个概念:
- 网卡(NIC):是一块被设计用来允许计算机在计算机网络上进行通讯的计算机硬件。由于其拥有MAC地址,因此属于OSI模型的第1层和2层之间,他其实就是提供模电信号与数字信号之间的转换。
- 网卡驱动:负责网卡的正常工作,网卡中保存的都是原始数据,TCP/IP 是不会识别这些原始数据的,网卡驱动就为网卡分配了 sk_buffer 用于保存这些数据,在传输过程中使用 sk_buffer 进行数据传输,TCP/IP 只认这些 sk_buffer。
- UIO:UIO 是一种通用型 IO ,我们可以理解为他在底层截获 PCI 地址,然后截获其出的数据,就比如说一辆高铁,有很多节车厢,中途到达某一站,就有很多乘客下车,换乘站就相当于将这些乘客截获下来,就是这样一个意思。
- VFIO:与 UIO 相似,是一种比较特殊的形式,是一种特殊的方式截获 IO,因为内核中一些网卡的工作模式是不一样的。
- KNI:内核中实现的网络编程接口,它提供了一种高效的方式来处理网络数据包。
- 巨页(hugepage):一般情况下,一页的大小是 4KB ,而采用巨页进行管理,一页的大小可以是 2M 或者是 1G ,以减少页表项的数量,从而降低内存管理开销,提高TLB(转换后备缓冲区)命中率,加速内存访问。
实现使用DPDK收发数据
DPDK 就是使用巨页来进行管理的,接下我们通过代码的方式来更清楚的理解这种处理方式:
通过UDP收发数据
通过UDP收数据
#include <stdio.h>
#include <rte_eal.h>
#include <rte_ethdev.h>
#include <arpa/inet.h>#define NUM_BUFFERS 4096
#define BURST_SIZE 128// 只设置当前每一帧接收数据最大的数量
static const struct rte_eth_conf port_conf_default = {.rxmode = {.max_rx_pkt_len = RTE_ETHER_MAX_LEN}};// 网口就是从0开始绑定的
static int global_portid = 0;static int usatck_init_port(struct rte_mempool *mbuf_pool)
{// (void)mbuf_pool;// 获取到对应网口的数量,用当前网口实现数据接收uint16_t nb_sys_port = rte_eth_dev_count_avail();// printf("count: %d\n", nb_sys_port);if (nb_sys_port == 0){rte_exit(EXIT_FAILURE, "Not supported eth find\n");}// 获取当前网卡中的一些信息// struct rte_eth_dev_info dev_info;// rte_eth_dev_info_get(global_portid, &dev_info);// 配置当前接收发送队列const int num_rx_queue = 1;const int num_tx_queue = 0;rte_eth_dev_configure(global_portid, num_rx_queue, num_tx_queue, &port_conf_default);// 配置rx_queueif (rte_eth_rx_queue_setup(global_portid, 0, 128, rte_eth_dev_socket_id(global_portid), NULL, mbuf_pool) < 0){rte_exit(EXIT_FAILURE, "Could not setup rxquue\n");}// 网卡启动if (rte_eth_dev_start(global_portid) < 0){rte_exit(EXIT_FAILURE, "Could not start\n");}return 0;
}int main(int argc, char *argv[])
{// 环境初始化,绑定网口数量if (rte_eal_init(argc, argv) < 0){rte_exit(EXIT_FAILURE, "Error with EAL init\n");}// printf("hello dpdk\n");// 创建一个mbuf_pool对mubf进行管理, 就相当于Linux下的sk_buffer// rte_socket_id()表示当前使用的是哪一块内存分配的struct rte_mempool *mbuf_pool = rte_pktmbuf_pool_create("mbuf pool", NUM_BUFFERS, 0, 0, RTE_MBUF_DEFAULT_BUF_SIZE, rte_socket_id());if (mbuf_pool == NULL){rte_exit(EXIT_FAILURE, "Could not create mbuf pool\n");}usatck_init_port(mbuf_pool);while (1){// 向对应的 mbuf 中写入数据,并不需要拷贝struct rte_mbuf *mbufs[BURST_SIZE] = {0};uint16_t num_recvd = rte_eth_rx_burst(global_portid, 0, mbufs, BURST_SIZE);if (num_recvd > BURST_SIZE) {rte_exit(EXIT_FAILURE, "Error recv from eth\n");}int i = 0;for(i = 0; i < num_recvd; i++){printf("enter1\n");// 先准备一个以太网头struct rte_ether_hdr* ethhdr = rte_pktmbuf_mtod(mbufs[i], struct rte_ether_hdr*);// 判断网络层的协议, 非网络层协议继续continueif (ethhdr->ether_type != rte_cpu_to_be_16(RTE_ETHER_TYPE_IPV4)){continue;}printf("enter2\n");// ip头为以太网头偏移过来struct rte_ipv4_hdr* iphdr = rte_pktmbuf_mtod_offset(mbufs[i], struct rte_ipv4_hdr*, sizeof(struct rte_ether_hdr));// 接下来就进入UDP的处理if (iphdr->next_proto_id == IPPROTO_UDP){printf("enter3\n");struct rte_udp_hdr* udphdr = (struct rte_udp_hdr*)(iphdr + 1);// printf("udp: %s\n", (char*)(udphdr + 1));}}}return 0;
}
简单说一下这儿需要注意的几个点:
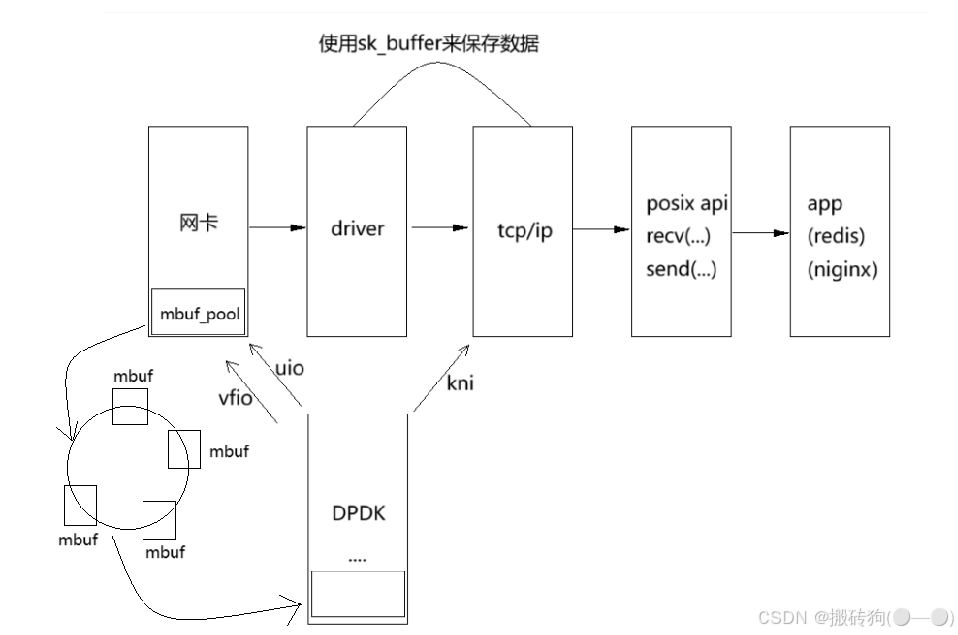
- 对于 DPDK 来说,通过截断的方式来获取到网卡所发的数据,但是对于 TCP/UDP 来说,我们还是只识别对应的 buffer,在 DPDK 中,mbuf 起到的就是这个作用,而我们首先就需要去创建一个 buf_pool 去对网卡中的数据进行管理,最终将其放入到 mbuf 中去;
- rx_queue 其实就是代表着环形的队列结构,他当中放的就是我们的 mbuf ,通过轮转的方式来进行数据的操作,网卡可以有多个,队列也可以拥有多个,我们只要根据对应的关系给他安排好就可以了
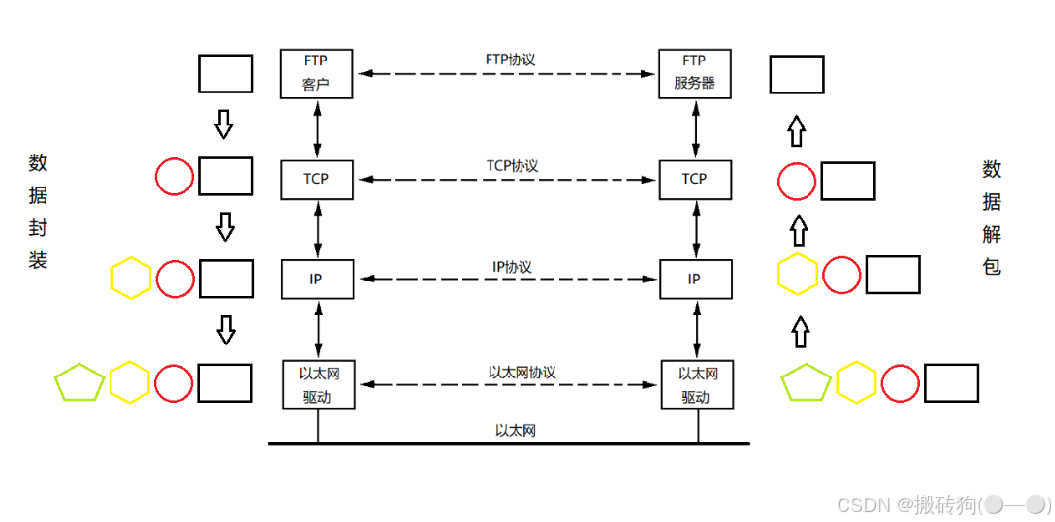
- OSI 的五层模型告诉我们,网络数据传输的过程中需要一层一层的封装报头,首先是以太网报头,然后是 IP 报头,然后是 UDP/TCP 报头,网卡启动以后,我们要做到发数据,就需要对报头进行封装,数据接收亦是如此,需要删掉一个一个的报头,这也跟代码中所体现的一样。
通过 UDP 回发数据
#include <stdio.h>
#include <rte_eal.h>
#include <rte_ethdev.h>
#include <arpa/inet.h>#define ENABLE_SEND 1
#define NUM_BUFFERS 4096
#define BURST_SIZE 128#if ENABLE_SEND
// 以太网目的地址以及源地址
uint8_t global_smac[RTE_ETHER_ADDR_LEN];
uint8_t global_dmac[RTE_ETHER_ADDR_LEN];// 目的IP地址以及源IP地址
uint32_t global_sip;
uint32_t global_dip;// 源端口号以及目的端口号
uint16_t global_sport;
uint16_t global_dport;#endif// 只设置当前每一帧接收数据最大的数量
static const struct rte_eth_conf port_conf_default = {.rxmode = {.max_rx_pkt_len = RTE_ETHER_MAX_LEN}};// 网口就是从0开始绑定的
static int global_portid = 0;static int usatck_init_port(struct rte_mempool *mbuf_pool)
{// (void)mbuf_pool;// 获取到对应网口的数量,用当前网口实现数据接收uint16_t nb_sys_port = rte_eth_dev_count_avail();// printf("count: %d\n", nb_sys_port);if (nb_sys_port == 0){rte_exit(EXIT_FAILURE, "Not supported eth find\n");}// 获取当前网卡中的一些信息struct rte_eth_dev_info dev_info;rte_eth_dev_info_get(global_portid, &dev_info);// 配置当前接收发送队列const int num_rx_queue = 1;
#if ENABLE_SEND// 要接收这儿就也需要设置为1const int num_tx_queue = 1;
#elseconst int num_tx_queue = 0;
#endifrte_eth_dev_configure(global_portid, num_rx_queue, num_tx_queue, &port_conf_default);// 配置rx_queueif (rte_eth_rx_queue_setup(global_portid, 0, 128, rte_eth_dev_socket_id(global_portid), NULL, mbuf_pool) < 0){rte_exit(EXIT_FAILURE, "Could not setup RX quue\n");}#if ENABLE_SEND// 在这想要接收数据那么我们也需要这是tx_queue,关于tx_queue的东西也需要,不然就接收不了数据struct rte_eth_txconf txconf = dev_info.default_txconf;// offloads代表的就是发送和接收的数据包的大小txconf.offloads = port_conf_default.rxmode.offloads;// 设置tx_queueif (rte_eth_tx_queue_setup(global_portid, num_tx_queue, 512, rte_eth_dev_socket_id(global_portid), &txconf) < 0){rte_exit(EXIT_FAILURE, "Could not setup TX quue\n");}#endif// 网卡启动if (rte_eth_dev_start(global_portid) < 0){rte_exit(EXIT_FAILURE, "Could not start\n");}return 0;
}static int ustack_encode_udp_pkt(uint8_t *msg, uint8_t *data, uint16_t total_len)
{/*1. ether header2. ip headder3. udp header*/// ether headerstruct rte_ether_hdr *eth = (struct rte_ether_hdr *)msg;rte_memcpy(eth->s_addr.addr_bytes, global_smac, RTE_ETHER_ADDR_LEN);rte_memcpy(eth->d_addr.addr_bytes, global_dmac, RTE_ETHER_ADDR_LEN);eth->ether_type = htons(RTE_ETHER_TYPE_IPV4);/*struct rte_ipv4_hdr {uint8_t version_ihl; < version and header lengthuint8_t type_of_service; < type of serviceuint16_t total_length; < length of packetuint16_t packet_id; < packet IDuint16_t fragment_offset; < fragmentation offsetuint8_t time_to_live; < time to liveuint8_t next_proto_id; < protocol IDuint16_t hdr_checksum; < header checksumuint32_t src_addr; < source addressuint32_t dst_addr; < destination address} __attribute__((__packed__));*/// ip headerstruct rte_ipv4_hdr *ip = (struct rte_ether_hdr *)(eth + 1);ip->version_ihl = 0x45;ip->type_of_service = 0;ip->total_length = total_len - sizeof(struct rte_ether_hdr);ip->packet_id = 0;ip->fragment_offset = 0;ip->time_to_live = 64;ip->next_proto_id = IPPROTO_UDP;ip->src_addr = global_sip;ip->dst_addr = global_dip;// 每次配置前都设置为0ip->hdr_checksum = 0;ip->hdr_checksum = rte_ipv4_cksum(ip);/*struct rte_udp_hdr {uint16_t src_port; < UDP source portuint16_t dst_port; < UDP destination portuint16_t dgram_len; < UDP datagram lengthuint16_t dgram_cksum; < UDP datagram checksum} __attribute__((__packed__));*/// udp headerstruct rte_udp_hdr *udp = (struct rte_ipv4_hdr *)(ip + 1);udp->src_port = global_sport;udp->dst_port = global_dport;uint16_t udplen = total_len - sizeof(struct rte_ether_hdr) -sizeof(struct rte_ipv4_hdr);udp->dgram_len = htons(udplen);rte_memcpy((uint8_t*)(udp + 1), data, udplen);udp->dgram_cksum = 0;udp->dgram_cksum = rte_ipv4_udptcp_cksum(ip, udp);return 1;
}int main(int argc, char *argv[])
{// 环境初始化,绑定网口数量if (rte_eal_init(argc, argv) < 0){rte_exit(EXIT_FAILURE, "Error with EAL init\n");}// printf("hello dpdk\n");// 创建一个mbuf_pool对mubf进行管理, 就相当于Linux下的sk_buffer// rte_socket_id()表示当前使用的是哪一块内存分配的struct rte_mempool *mbuf_pool = rte_pktmbuf_pool_create("mbuf pool", NUM_BUFFERS, 0, 0, RTE_MBUF_DEFAULT_BUF_SIZE, rte_socket_id());if (mbuf_pool == NULL){rte_exit(EXIT_FAILURE, "Could not create mbuf pool\n");}usatck_init_port(mbuf_pool);while (1){// 向对应的 mbuf 中写入数据,并不需要拷贝struct rte_mbuf *mbufs[BURST_SIZE] = {0};uint16_t num_recvd = rte_eth_rx_burst(global_portid, 0, mbufs, BURST_SIZE);if (num_recvd > BURST_SIZE){rte_exit(EXIT_FAILURE, "Error recv from eth\n");}int i = 0;for (i = 0; i < num_recvd; i++){// 先准备一个以太网头struct rte_ether_hdr *ethhdr = rte_pktmbuf_mtod(mbufs[i], struct rte_ether_hdr *);// 判断网络层的协议, 非网络层协议继续continueif (ethhdr->ether_type != rte_cpu_to_be_16(RTE_ETHER_TYPE_IPV4)){continue;}// ip头为以太网头偏移过来struct rte_ipv4_hdr *iphdr = rte_pktmbuf_mtod_offset(mbufs[i], struct rte_ipv4_hdr *, sizeof(struct rte_ether_hdr));// 接下来就进入UDP的处理if (iphdr->next_proto_id == IPPROTO_UDP){struct rte_udp_hdr *udphdr = (struct rte_udp_hdr *)(iphdr + 1);
#if ENABLE_SEND// 接收数据回发,就意味着以太网地址/ip地址/端口号都得对调// 以太网地址对调rte_memcpy(global_smac, ethhdr->d_addr.addr_bytes, RTE_ETHER_ADDR_LEN);rte_memcpy(global_dmac, ethhdr->s_addr.addr_bytes, RTE_ETHER_ADDR_LEN);// IP 地址对调rte_memcpy(global_sip, &iphdr->dst_addr, sizeof(uint32_t));rte_memcpy(global_dip, &iphdr->src_addr, sizeof(uint32_t));// 端口号的对调rte_memcpy(global_sport, &udphdr->dst_port, sizeof(uint16_t));rte_memcpy(global_dport, &udphdr->src_port, sizeof(uint16_t));// UDP 数据报的长度uint16_t length = ntohs(udphdr->dgram_len);// 总长度 = UDP + IP头 + 以太网头uint16_t total_len = length + sizeof(struct rte_ether_hdr) + sizeof(struct rte_ipv4_hdr);// 去mbuf_pool中申请bufferstruct rte_mbuf *mbufs = rte_pktmbuf_alloc(mbuf_pool);if (mbufs == NULL){rte_exit(EXIT_FAILURE, "Error rte_pktmbuf_alloc\n");}mbufs->pkt_len = total_len;mbufs->data_len = total_len;// msg就代表要发的数据报的地址uint8_t *msg = rte_pktmbuf_mtod(mbufs, uint8_t *);// 组织一个要发的数据包ustack_encode_udp_pkt(msg, mbufs, total_len);// 回发数据rte_eth_rx_burst(global_portid, 0, &mbufs[i], 1);
#endif// printf("udp: %s\n", (char*)(udphdr + 1));}}}return 0;
}
回发数据这儿也有几点需要注意:
- 接收数据我们调用 rte_eth_rx_burst 接口,同样,回发数据我们就的调用 rte_eth_rx_burst 接口,那么对应的 tx_queue 就得进行设置,收数据的时候我们设置了一个 rx_queue,那么同样回发数据就必须得有 tx_queue 。
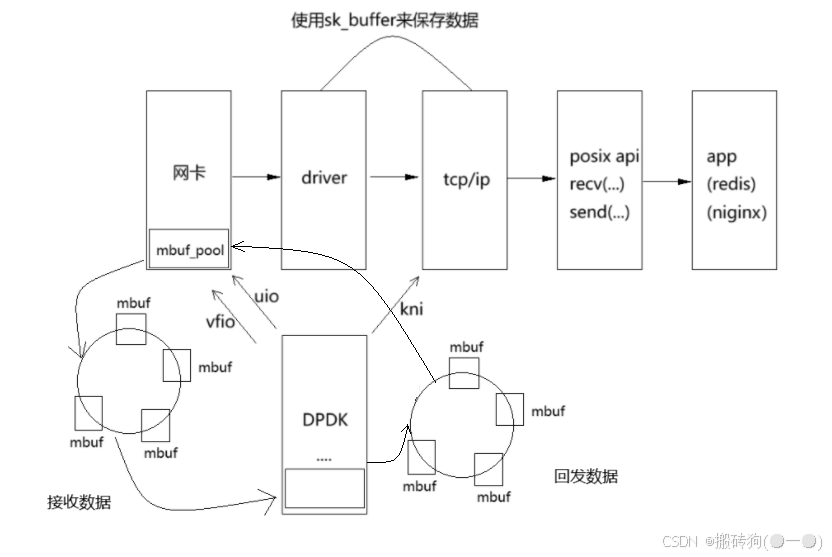
- 接收数据和回发数据在这里源地址(src)与目的地址(dst)我们是需要进行调整的,也就是接收到数据以后,我们需要回发,那么此时的源地址就变为了目的地址,目的地址也就变为了源地址,举个例子,你给朋友寄快递,源地址是你,目的地址是你朋友,你的朋友要给你回发,那么源地址就是你朋友,目的地址是你,如果不改变,那么你就会永远收不到你朋友发给你的快递。
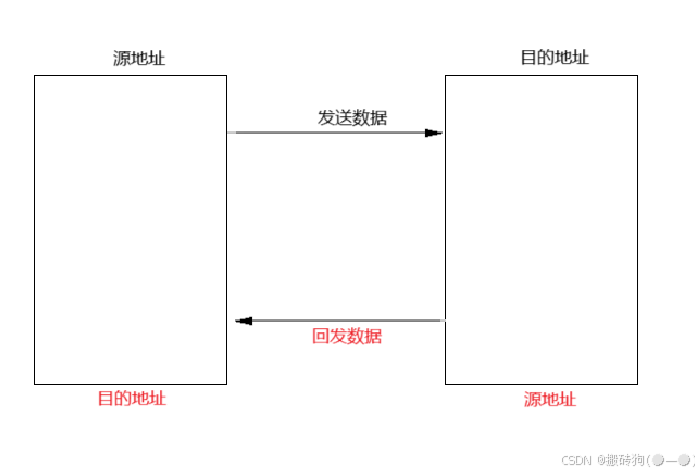
- 回发数据,我们就需要对回发的数据包进行封装,根据 OSI 五层模型,那么就需要以太网头部字段,IP 头部字段,UDP头部字段以及数据具体内容,以上代码也对这一层次进行了封装,但是要注意,在设置 checksum 字段是我们需要每次都重置为 0 ,然后再进行设置,这样就是为了防止脏数据对其产生影响,至于设置的原理就如下面三个图所示:
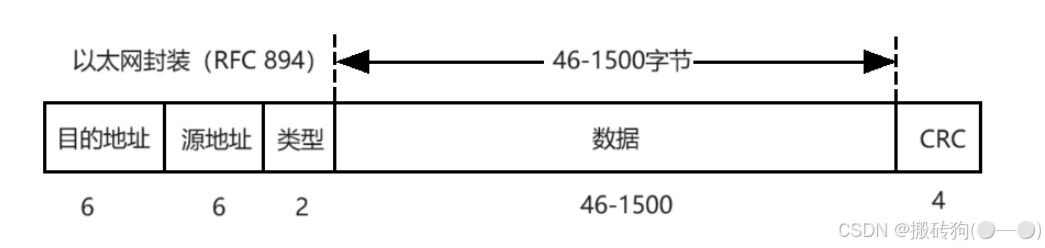
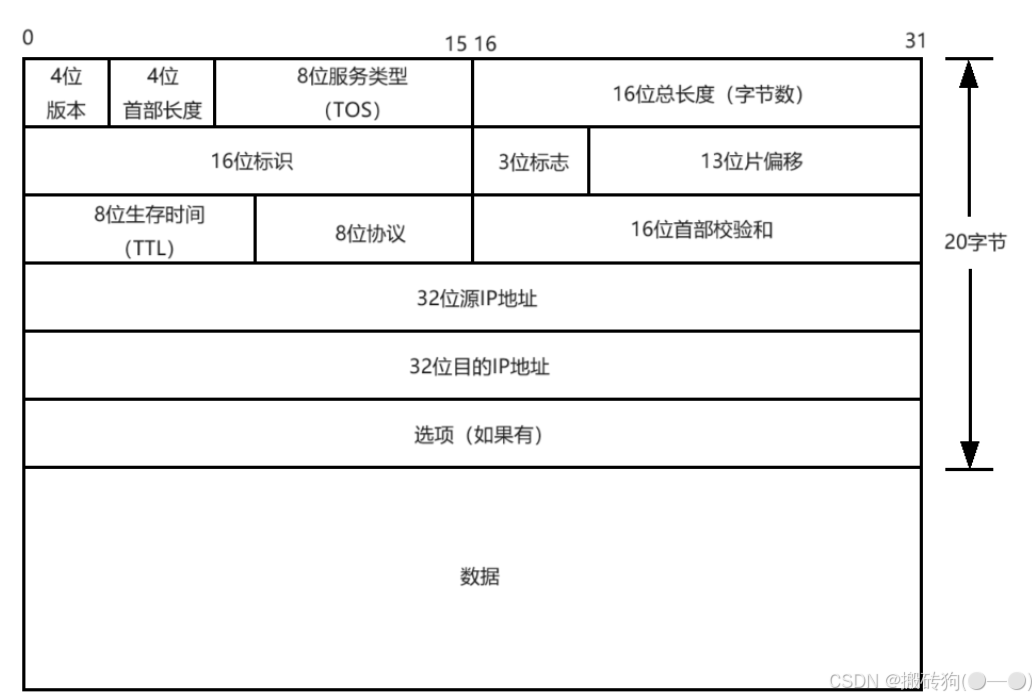

- 在网络通信的过程中,是存在大小端问题的,此时就需要进行网络字节序的转换,为使网络程序具有可移植性,使同样的C代码在大端和小端计算机上编译后都能正常运行,系统提供了四个函数,可以通过调用以下库函数实现网络字节序和主机字节序之间的转换
#include <arpa/inet.h>uint32_t htonl(uint32_t hostlong); // 主机字节序转换为网络字节序
uint16_t htons(uint16_t hostshort);
uint32_t ntohl(uint32_t netlong); // 网络字节序转换为主机字节序
uint16_t ntohs(uint16_t netshort);
通过 TCP 收发数据
#include <stdio.h>
#include <rte_eal.h>
#include <rte_ethdev.h>
#include <arpa/inet.h>#define ENABLE_TCP 1
#define ENABLE_SEND 1
#define NUM_BUFFERS 4096
#define BURST_SIZE 128
#define TCP_INIT_WINDOWS 14600#if ENABLE_SEND
// 以太网目的地址以及源地址
uint8_t global_smac[RTE_ETHER_ADDR_LEN];
uint8_t global_dmac[RTE_ETHER_ADDR_LEN];// 目的IP地址以及源IP地址
uint32_t global_sip;
uint32_t global_dip;// 源端口号以及目的端口号
uint16_t global_sport;
uint16_t global_dport;
#endif#if ENABLE_TCPuint8_t global_flags;
uint32_t global_seqnum;
uint32_t global_acknum;// TCP 过程中每一个状态枚举出来
typedef enum __USTACK_TCP_STATUS
{USTACK_TCP_STATUS_CLOSED = 0,USTACK_TCP_STATUS_LISTEN,USTACK_TCP_STATUS_SYN_RCVD,USTACK_TCP_STATUS_SYN_SENT,USTACK_TCP_STATUS_ESTABLISHED,USTACK_TCP_STATUS_FIN_WAIT_1,USTACK_TCP_STATUS_FIN_WAIT_2,USTACK_TCP_STATUS_CLOSING,USTACK_TCP_STATUS_TIMEWAIT,USTACK_TCP_STATUS_CLOSE_WAIT,USTACK_TCP_STATUS_LAST_ACK
} USTACK_TCP_STATUS;// 默认状态为 LISTEN
uint8_t tcp_status = USTACK_TCP_STATUS_LISTEN;#endif// 只设置当前每一帧接收数据最大的数量
static const struct rte_eth_conf port_conf_default = {.rxmode = {.max_rx_pkt_len = RTE_ETHER_MAX_LEN}};// 网口就是从0开始绑定的
static int global_portid = 0;static int usatck_init_port(struct rte_mempool *mbuf_pool)
{// (void)mbuf_pool;// 获取到对应网口的数量,用当前网口实现数据接收uint16_t nb_sys_port = rte_eth_dev_count_avail();// printf("count: %d\n", nb_sys_port);if (nb_sys_port == 0){rte_exit(EXIT_FAILURE, "Not supported eth find\n");}// 获取当前网卡中的一些信息struct rte_eth_dev_info dev_info;rte_eth_dev_info_get(global_portid, &dev_info);// 配置当前接收发送队列const int num_rx_queue = 1;
#if ENABLE_SEND// 要接收这儿就也需要设置为1const int num_tx_queue = 1;
#elseconst int num_tx_queue = 0;
#endifrte_eth_dev_configure(global_portid, num_rx_queue, num_tx_queue, &port_conf_default);// 配置rx_queueif (rte_eth_rx_queue_setup(global_portid, 0, 128, rte_eth_dev_socket_id(global_portid), NULL, mbuf_pool) < 0){rte_exit(EXIT_FAILURE, "Could not setup RX quue\n");}#if ENABLE_SEND// 在这想要接收数据那么我们也需要这是tx_queue,关于tx_queue的东西也需要,不然就接收不了数据struct rte_eth_txconf txconf = dev_info.default_txconf;// offloads代表的就是发送和接收的数据包的大小txconf.offloads = port_conf_default.rxmode.offloads;// 设置tx_queueif (rte_eth_tx_queue_setup(global_portid, 0, 512, rte_eth_dev_socket_id(global_portid), &txconf) < 0){rte_exit(EXIT_FAILURE, "Could not setup TX quue\n");}#endif// 网卡启动if (rte_eth_dev_start(global_portid) < 0){rte_exit(EXIT_FAILURE, "Could not start\n");}return 0;
}static struct rte_ipv4_hdr *ustack_eth2ip_hdr(uint8_t *msg, uint16_t total_len)
{// ether headerstruct rte_ether_hdr *eth = (struct rte_ether_hdr *)msg;rte_memcpy(eth->s_addr.addr_bytes, global_smac, RTE_ETHER_ADDR_LEN);rte_memcpy(eth->d_addr.addr_bytes, global_dmac, RTE_ETHER_ADDR_LEN);eth->ether_type = htons(RTE_ETHER_TYPE_IPV4);/*struct rte_ipv4_hdr {uint8_t version_ihl; < version and header lengthuint8_t type_of_service; < type of serviceuint16_t total_length; < length of packetuint16_t packet_id; < packet IDuint16_t fragment_offset; < fragmentation offsetuint8_t time_to_live; < time to liveuint8_t next_proto_id; < protocol IDuint16_t hdr_checksum; < header checksumuint32_t src_addr; < source addressuint32_t dst_addr; < destination address} __attribute__((__packed__));*/// ip headerstruct rte_ipv4_hdr *ip = (struct rte_ether_hdr *)(eth + 1);ip->version_ihl = 0x45;ip->type_of_service = 0;ip->total_length = total_len - sizeof(struct rte_ether_hdr);ip->packet_id = 0;ip->fragment_offset = 0;ip->time_to_live = 64;ip->next_proto_id = IPPROTO_UDP;ip->src_addr = global_sip;ip->dst_addr = global_dip;// 每次配置前都设置为0ip->hdr_checksum = 0;ip->hdr_checksum = rte_ipv4_cksum(ip);return ip;
}#if ENABLE_SENDstatic int ustack_encode_udp_pkt(uint8_t *msg, uint8_t *data, uint16_t total_len)
{struct rte_ipv4_hdr *ip = ustack_eth2ip_hdr(msg, total_len);/*struct rte_udp_hdr {uint16_t src_port; < UDP source portuint16_t dst_port; < UDP destination portuint16_t dgram_len; < UDP datagram lengthuint16_t dgram_cksum; < UDP datagram checksum} __attribute__((__packed__));*/// udp headerstruct rte_udp_hdr *udp = (struct rte_ipv4_hdr *)(ip + 1);udp->src_port = global_sport;udp->dst_port = global_dport;uint16_t udplen = total_len - sizeof(struct rte_ether_hdr) - sizeof(struct rte_ipv4_hdr);udp->dgram_len = htons(udplen);rte_memcpy((uint8_t *)(udp + 1), data, udplen);udp->dgram_cksum = 0;udp->dgram_cksum = rte_ipv4_udptcp_cksum(ip, udp);return 1;
}
#endif#if ENABLE_TCP
static int ustack_encode_tcp_pkt(uint8_t *msg, uint16_t total_len)
{struct rte_ipv4_hdr *ip = ustack_eth2ip_hdr(msg, total_len);/*struct rte_tcp_hdr {uint16_t src_port; < TCP source port.uint16_t dst_port; < TCP destination port.uint32_t sent_seq; < TX data sequence number.uint32_t recv_ack; < RX data acknowledgement sequence number.uint8_t data_off; < Data offset.uint8_t tcp_flags; < TCP flagsuint16_t rx_win; < RX flow control window.uint16_t cksum; < TCP checksum.uint16_t tcp_urp; < TCP urgent pointer, if any.} __attribute__((__packed__));*/// tcp headerstruct rte_tcp_hdr *tcp = (struct rte_tcp_hdr *)(ip + 1);tcp->src_port = global_sport;tcp->dst_port = global_dport;tcp->sent_seq = htonl(12345);tcp->recv_ack = htonl(global_seqnum + 1);tcp->data_off = 0x50;tcp->tcp_flags = RTE_TCP_SYN_FLAG | RTE_TCP_ACK_FLAG;tcp->rx_win = TCP_INIT_WINDOWS;tcp->tcp_urp = 0;tcp->cksum = 0;tcp->cksum = rte_ipv4_udptcp_cksum(ip, tcp);return 1;
}
#endifint main(int argc, char *argv[])
{// 环境初始化,绑定网口数量if (rte_eal_init(argc, argv) < 0){rte_exit(EXIT_FAILURE, "Error with EAL init\n");}// printf("hello dpdk\n");// 创建一个mbuf_pool对mubf进行管理, 就相当于Linux下的sk_buffer// rte_socket_id()表示当前使用的是哪一块内存分配的struct rte_mempool *mbuf_pool = rte_pktmbuf_pool_create("mbuf pool", NUM_BUFFERS, 0, 0, RTE_MBUF_DEFAULT_BUF_SIZE, rte_socket_id());if (mbuf_pool == NULL){rte_exit(EXIT_FAILURE, "Could not create mbuf pool\n");}usatck_init_port(mbuf_pool);while (1){// 向对应的 mbuf 中写入数据,并不需要拷贝struct rte_mbuf *mbufs[BURST_SIZE] = {0};uint16_t num_recvd = rte_eth_rx_burst(global_portid, 0, mbufs, BURST_SIZE);if (num_recvd > BURST_SIZE){rte_exit(EXIT_FAILURE, "Error recv from eth\n");}int i = 0;for (i = 0; i < num_recvd; i++){// 先准备一个以太网头struct rte_ether_hdr *ethhdr = rte_pktmbuf_mtod(mbufs[i], struct rte_ether_hdr *);// 判断网络层的协议, 非网络层协议继续continueif (ethhdr->ether_type != rte_cpu_to_be_16(RTE_ETHER_TYPE_IPV4)){continue;}// ip头为以太网头偏移过来struct rte_ipv4_hdr *iphdr = rte_pktmbuf_mtod_offset(mbufs[i], struct rte_ipv4_hdr *, sizeof(struct rte_ether_hdr));// 接下来就进入UDP的处理if (iphdr->next_proto_id == IPPROTO_UDP){struct rte_udp_hdr *udphdr = (struct rte_udp_hdr *)(iphdr + 1);
#if ENABLE_SEND// 接收数据回发,就意味着以太网地址/ip地址/端口号都得对调// 以太网地址对调rte_memcpy(global_smac, ethhdr->d_addr.addr_bytes, RTE_ETHER_ADDR_LEN);rte_memcpy(global_dmac, ethhdr->s_addr.addr_bytes, RTE_ETHER_ADDR_LEN);// IP 地址对调rte_memcpy(global_sip, &iphdr->dst_addr, sizeof(uint32_t));rte_memcpy(global_dip, &iphdr->src_addr, sizeof(uint32_t));// 端口号的对调rte_memcpy(global_sport, &udphdr->dst_port, sizeof(uint16_t));rte_memcpy(global_dport, &udphdr->src_port, sizeof(uint16_t));// UDP 数据报的长度uint16_t length = ntohs(udphdr->dgram_len);// 总长度 = UDP + IP头 + 以太网头uint16_t total_len = length + sizeof(struct rte_ether_hdr) + sizeof(struct rte_ipv4_hdr);// 去mbuf_pool中申请bufferstruct rte_mbuf *mbufs = rte_pktmbuf_alloc(mbuf_pool);if (mbufs == NULL){rte_exit(EXIT_FAILURE, "Error rte_pktmbuf_alloc\n");}mbufs->pkt_len = total_len;mbufs->data_len = total_len;// msg就代表要发的数据报的地址uint8_t *msg = rte_pktmbuf_mtod(mbufs, uint8_t *);// 组织一个要发的数据包ustack_encode_udp_pkt(msg, mbufs, total_len);// 回发数据rte_eth_rx_burst(global_portid, 0, &mbufs, 1);
#endif// printf("udp: %s\n", (char*)(udphdr + 1));}#if ENABLE_TCPelse if (iphdr->next_proto_id == IPPROTO_TCP){struct rte_tcp_hdr *tcphdr = (struct rte_tcp_hdr *)(iphdr + 1);rte_memcpy(global_smac, ethhdr->d_addr.addr_bytes, RTE_ETHER_ADDR_LEN);rte_memcpy(global_dmac, ethhdr->s_addr.addr_bytes, RTE_ETHER_ADDR_LEN);rte_memcpy(global_sip, &iphdr->dst_addr, sizeof(uint32_t));rte_memcpy(global_dip, &iphdr->src_addr, sizeof(uint32_t));// 端口号的对调rte_memcpy(global_sport, &tcphdr->dst_port, sizeof(uint16_t));rte_memcpy(global_dport, &tcphdr->src_port, sizeof(uint16_t));// 获取到对应的标志位global_flags = tcphdr->tcp_flags;// 此时代表已经发起了第一次握手if (global_flags & RTE_TCP_SYN_FLAG){if (tcp_status == USTACK_TCP_STATUS_LISTEN){// TCP 是不需要报文长度的uint16_t total_len = sizeof(struct rte_ether_hdr) + sizeof(struct rte_ipv4_hdr) + sizeof(struct rte_tcp_hdr);// 去mbuf_pool中申请bufferstruct rte_mbuf *mbufs = rte_pktmbuf_alloc(mbuf_pool);if (mbufs == NULL){rte_exit(EXIT_FAILURE, "Error rte_pktmbuf_alloc\n");}mbufs->pkt_len = total_len;mbufs->data_len = total_len;uint8_t *msg = rte_pktmbuf_mtod(mbufs, uint8_t *);// 为什么不需要报文长度?思考ustack_encode_tcp_pkt(msg, total_len);rte_eth_rx_burst(global_portid, 0, &mbufs, 1);// 下一次就该进入SYN_RCVD状态tcp_status = USTACK_TCP_STATUS_SYN_RCVD;}}// 第二次握手已经进入了if (global_flags & RTE_TCP_ACK_FLAG){if (tcp_status == USTACK_TCP_STATUS_SYN_RCVD){// 下一次就该进入ESTABLISHED状态tcp_status = USTACK_TCP_STATUS_ESTABLISHED;}}// 第三次握手已经完成if (global_flags & RTE_TCP_PSH_FLAG){if (tcp_status == USTACK_TCP_STATUS_ESTABLISHED){uint8_t hdrlen = (tcphdr->data_off >> 4) * sizeof(uint32_t);uint8_t *data = ((uint8_t *)tcphdr + hdrlen);}}}
#endif}}return 0;
}
在使用 TCP 收发数据的过程中,我们需要注意的就是:
- 在 TCP 协议中,报头的组成是不一样的,它有 6 个标志位,所以在此我们设计一个 global_flags 来标记当前的状态,而且,在我们设计一个包的过程中,是不需要传递报文长度的,原因就在于 TCP 传输方式是面向字节流的,他与 seqnum 以及 acknum ,这就可以帮助我们去确认数据报的长度,并不需要我们将数据的长度传递进去。
- 代码中
ip->version_ihl = 0x45,tcp->data_off = 0x50,这个是定值,0x45通过 IP 协议栈的组成就很好理解,4 就表示版本号,对于 IPV4 协议来说就是 4,而 5 其实就代表 IP 报头长度就是 4 X 5 = 20 字节,0x50中 5 就表示 TCP 首部长度就是 5 X 4 = 20 个字节,0 就表示保留位设置为 0。 - 发起第一次握手以后,此时就已经要对数据包进行封装了,但是我们此时是需要知道当前 TCP 在通信过程中的一个状态,如果当前是第一次握手发起以后,并且是 LISTEN 状态,我们就回发数据包,然后设置状态为 SYN_RCVD ,以此类推,直到完成三次握手,进入到 ESTABLISHED 状态,代码中也可以体现出来。
以上就是通过 DPDK 来实现了 TCP 三次握手以及 UDP 协议收发数据,当然,TCP 协议还有着滑动窗口,拥塞控制等等东西,博主实力有限,后续也会继续进行完善,对于 以太网/TCP/UDP/IP 协议的原理可以看一下之前的文章,也有详细描述过:
传输层协议-UDP协议
传输层协议-TCP协议
网络层协议-IP协议
数据链路层-以太网协议