描述性统计——让数据说话
第03篇:描述性统计——让数据说话
写在前面:大家好,我是蓝皮怪!前两篇我们聊了统计学的基本概念和数据类型,这一篇我们要正式进入数据分析的第一步——描述性统计。别被名字吓到,其实就是用一组数字,把一堆杂乱的数据变得有条理、能看懂。你会发现,很多生活中的"平均分"、“中位数”、“标准差”,其实都是描述性统计量。今天我们就来聊聊,怎么用这些数字,把数据的故事讲清楚。
🎯 这篇文章你能学到什么
- 描述性统计的核心概念和作用
- 常见的统计量有哪些,怎么用、怎么选
- 生活化案例和常见误区
- 简单的代码演示和基础可视化
- 如何用这些统计量总结和解读数据
1. 从生活说起:为什么要学描述性统计?
你有没有遇到过这些场景:
📊 看成绩单时:老师说"这次数学平均分75分",但你发现大部分同学都没考到75分?
💰 聊工资时:新闻说"本市平均工资6000元",可你和身边朋友都没达到?
🏠 看房价时:中介说"本小区房价中位数5000/平",这和平均价有啥区别?
这些问题,其实都和描述性统计量有关。它们帮我们用数字快速看懂一堆数据的"全貌",也能避免被"平均数陷阱"忽悠。
2. 位置类统计量:数据的"中心"在哪里?
2.1 算术平均数(非分组数据)
- 定义:所有数据之和除以数据个数。
- 公式:
x ˉ = 1 n ∑ i = 1 n x i \bar{x} = \frac{1}{n} \sum_{i=1}^n x_i xˉ=n1i=1∑nxi - 举例:5个人的身高分别为160、165、170、175、180cm,平均身高=(160+165+170+175+180)/5=170cm。
- 适用场景:原始数据已知,数据分布较对称、无极端值。
- 优缺点:简单直观,但对极端值敏感。
- 注意:平均数不等于"典型水平",极端值会拉高或拉低均值。
【例子与代码】
(1)生活化例子:
假设你和4个朋友的月工资分别是5000、6000、7000、8000、20000元。你们想知道大家的平均工资是多少。
- 总工资:
5000 + 6000 + 7000 + 8000 + 20000 = 46000 5000 + 6000 + 7000 + 8000 + 20000 = 46000 5000+6000+7000+8000+20000=46000 - 人数 = 5
- 平均工资 = 46000 / 5 = 9200元
你会发现,虽然平均工资是9200元,但其实只有一个人远高于这个数,其他人都没达到,这就是极端值影响均值的典型例子。
(2)Python代码实现:
import numpy as np
salaries = np.array([5000, 6000, 7000, 8000, 20000])
print('平均工资:', np.mean(salaries))
输出:
平均工资: 9200.0
2.2 算术平均数(分组数据)
- 定义:数据已分组时,用组中值近似每组数据。
- 公式:
x ˉ = ∑ i = 1 k f i m i N \bar{x} = \frac{\sum_{i=1}^k f_i m_i}{N} xˉ=N∑i=1kfimi
其中 f i f_i fi 为第 i i i 组频数, m i m_i mi 为组中值, N N N 为总频数。 - 举例:三组组中值10、20、30,频数2、3、5,则均值为
均值 = 2 × 10 + 3 × 20 + 5 × 30 10 = 23 \text{均值} = \frac{2\times10 + 3\times20 + 5\times30}{10} = 23 均值=102×10+3×20+5×30=23 - 适用场景:原始数据不可得,数据已分组。
- 优缺点:近似计算,精度略低。
【例子与代码】
(1)生活化例子:
某公司员工工资分为三档:
- 3000-5000元(组中值4000元),有10人
- 5001-8000元(组中值6500元),有20人
- 8001-15000元(组中值11500元),有5人
用分组均值公式:
- 总工资:
10 × 4000 + 20 × 6500 + 5 × 11500 = 40000 + 130000 + 57500 = 227500 10 \times 4000 + 20 \times 6500 + 5 \times 11500 = 40000 + 130000 + 57500 = 227500 10×4000+20×6500+5×11500=40000+130000+57500=227500 - 总人数 = 10 + 20 + 5 = 35
- 平均工资 ≈ 227500 / 35 ≈ 6500元
(2)Python代码实现:
import numpy as np
mid_values = np.array([4000, 6500, 11500])
counts = np.array([10, 20, 5])
mean_grouped = np.sum(mid_values * counts) / np.sum(counts)
print('分组均值:', mean_grouped)
输出:
分组均值: 6500.0
2.3 加权平均数
- 定义:不同数据有不同权重时使用。
- 公式:
x ˉ w = ∑ i = 1 n w i x i ∑ i = 1 n w i \bar{x}_w = \frac{\sum_{i=1}^n w_i x_i}{\sum_{i=1}^n w_i} xˉw=∑i=1nwi∑i=1nwixi - 举例:计算不同班级人数加权的平均分。
【例子与代码】
(1)生活化例子:
有两个班级,A班有30人,平均分80分;B班有50人,平均分70分。全体学生的加权平均分是多少?
- 总分:
30 × 80 + 50 × 70 = 2400 + 3500 = 5900 30 \times 80 + 50 \times 70 = 2400 + 3500 = 5900 30×80+50×70=2400+3500=5900 - 总人数 = 30 + 50 = 80
- 加权平均分 = 5900 / 80 = 73.75分
(2)Python代码实现:
import numpy as np
scores = np.array([80, 70])
weights = np.array([30, 50])
weighted_mean = np.average(scores, weights=weights)
print('加权平均分:', weighted_mean)
输出:
加权平均分: 73.75
2.4 调和平均数
- 定义:用于"平均速度""平均单价"等倒数关系场景。
- 公式:
H = n ∑ i = 1 n 1 x i H = \frac{n}{\sum_{i=1}^n \frac{1}{x_i}} H=∑i=1nxi1n - 适用场景:如平均速度、平均每单位成本。
- 举例:一段路程一半以60km/h,一半以40km/h,平均速度不是(60+40)/2,而是调和平均数。
【例子与代码】
(1)生活化例子:
你开车去外婆家,去程一半路程以60km/h,另一半以40km/h。问全程的平均速度是多少?
- 普通平均数:(60+40)/2=50km/h(错误)
- 调和平均数:
2 1 60 + 1 40 = 2 5 240 = 48 km/h \frac{2}{\frac{1}{60} + \frac{1}{40}} = \frac{2}{\frac{5}{240}} = 48 \text{km/h} 601+4012=24052=48km/h
(2)Python代码实现:
import numpy as np
speeds = np.array([60, 40])
harmonic_mean = len(speeds) / np.sum(1/speeds)
print('调和平均速度:', harmonic_mean)
输出:
调和平均速度: 48.0
2.5 几何平均数
- 定义:用于增长率、比率等场景。
- 公式:
G = x 1 × x 2 × ⋯ × x n n G = \sqrt[n]{x_1 \times x_2 \times \cdots \times x_n} G=nx1×x2×⋯×xn - 适用场景:年均增长率、投资收益率等。
- 举例:三年增长率分别为10%、20%、30%,则几何平均增长率为
几何平均增长率 = ( 1.1 × 1.2 × 1.3 ) 1 / 3 − 1 ≈ 0.197 ≈ 19.7 % \text{几何平均增长率} = (1.1 \times 1.2 \times 1.3)^{1/3} - 1 \approx 0.197 \approx 19.7\% 几何平均增长率=(1.1×1.2×1.3)1/3−1≈0.197≈19.7%
【例子与代码】
(1)生活化例子:
你投资理财,三年收益率分别为10%、20%、30%。问三年平均每年增长率是多少?
- 先转为增长因子:1.1, 1.2, 1.3
- 几何平均增长率:
几何平均增长率 = ( 1.1 × 1.2 × 1.3 ) 1 / 3 − 1 ≈ 0.197 ≈ 19.7 % \text{几何平均增长率} = (1.1 \times 1.2 \times 1.3)^{1/3} - 1 \approx 0.197 \approx 19.7\% 几何平均增长率=(1.1×1.2×1.3)1/3−1≈0.197≈19.7%
(2)Python代码实现:
import numpy as np
rates = np.array([1.1, 1.2, 1.3])
geometric_mean = np.prod(rates) ** (1/len(rates))
print('几何平均增长率:', geometric_mean - 1)
输出:
几何平均增长率: 0.197
3. 中位数:不怕"土豪"搅局的中心
3.1 中位数(非分组数据)
- 定义:把数据从小到大排好,正中间的那个数。
- 公式:
- 若 n n n 为奇数,中位数为第 n + 1 2 \frac{n+1}{2} 2n+1 个数
- 若 n n n 为偶数,中位数为第 n 2 \frac{n}{2} 2n 和 n 2 + 1 \frac{n}{2}+1 2n+1 个数的平均值
- 举例:数据[2, 3, 5, 7, 9],中位数为5。
- 适用场景:原始数据已知。
- 优缺点:不受极端值影响,适合偏态分布数据。
- 注意:中位数不能反映数据的全部信息。
【例子与代码】
(1)生活化例子:
假设你和4个朋友的月工资分别是5000、6000、7000、8000、20000元。中位数是多少?
- 排序后:[5000, 6000, 7000, 8000, 20000]
- 人数为5(奇数),中位数是第3个数:7000元
如果人数为偶数,比如工资为[5000, 6000, 7000, 8000],中位数是(6000+7000)/2=6500元。
(2)Python代码实现:
import numpy as np
salaries = np.array([5000, 6000, 7000, 8000, 20000])
print('中位数:', np.median(salaries))
输出:
中位数: 7000.0
3.2 中位数(分组数据)
- 定义:数据已分组时,用累计频数法定位中位数组。
- 公式:
M e = L + N 2 − F f × w Me = L + \frac{\frac{N}{2} - F}{f} \times w Me=L+f2N−F×w
其中:- L L L:中位数组下限
- N N N:总频数
- F F F:中位数组之前各组频数之和
- f f f:中位数组频数
- w w w:组距
- 举例:累计频数到第3组超过总人数一半,则第3组为中位数组。
- 适用场景:原始数据不可得,数据已分组。
- 优缺点:近似计算,精度略低。
- 注意:分组数据中位数不能直接取组中值。
【例子与代码】
(1)生活化例子:
某公司35名员工工资分为三档:
- 3000-5000元(10人)
- 5001-8000元(20人)
- 8001-15000元(5人)
累计频数:
- 第一组:10
- 第二组:10+20=30
- 第三组:35
总人数N=35,N/2=17.5,落在第二组。
- 第二组下限L=5001
- F=10(前一组累计频数)
- f=20(中位数组频数)
- w=8000-5001+1=3000(组距,实际可按区间)
中位数 = 5001 + 17.5 − 10 20 × 3000 ≈ 5001 + 0.375 × 3000 ≈ 6126.0 中位数 = 5001 + \frac{17.5-10}{20} \times 3000 \approx 5001 + 0.375 \times 3000 \approx 6126.0 中位数=5001+2017.5−10×3000≈5001+0.375×3000≈6126.0
注意一下:这里由于分组的下限是5001,统计学中,分组一般是左开右闭区间,所以如果在习题中,看见第二组为(5000,8000],那么此时的下限就应该是5000,公式改为:
中位数 = 5000 + 17.5 − 10 20 × 3000 ≈ 5000 + 0.375 × 3000 ≈ 6125.0 中位数 = 5000 + \frac{17.5-10}{20} \times 3000 \approx 5000 + 0.375 \times 3000 \approx 6125.0 中位数=5000+2017.5−10×3000≈5000+0.375×3000≈6125.0
(2)Python代码实现:
import numpy as np# 分组区间及频数(左开右闭)
bins = [3000, 5000, 8000, 15000] # 分组边界
freqs = [10, 20, 5] # 各组频数# 总人数
N = sum(freqs)
# 中位数位置
N2 = N / 2# 累计频数
cum_freqs = np.cumsum(freqs)
# 找到中位数组
for i, cf in enumerate(cum_freqs):if cf >= N2:median_group = ibreakL = bins[median_group] # 中位数组下限
F = cum_freqs[median_group - 1] if median_group > 0 else 0 # 中位数组前累计频数
f = freqs[median_group] # 中位数组频数
w = bins[median_group + 1] - bins[median_group] # 组距median = L + (N2 - F) / f * w
print('分组中位数:', median)
输出:
分组中位数: 6125.0
4. 众数:最常见的"主流"
4.1 众数(非分组数据)
- 定义:数据中出现频率最高的数值。
- 举例:一群人最常见的鞋码。
- 适用场景:定性数据、分类型数据。
- 优缺点:直观,适合分类数据。有时无众数或有多个众数。
- 注意:众数不是"最大值",有的数据没有众数。
【例子与代码】
(1)生活化例子:
假设10个人的鞋码分别为[38, 39, 40, 39, 41, 39, 40, 42, 39, 40],最常见的鞋码是多少?
- 统计每个鞋码出现次数:39号出现4次,是众数。
(2)Python代码实现:
import numpy as np
from scipy import stats
sizes = np.array([38, 39, 40, 39, 41, 39, 40, 42, 39, 40])
mode = stats.mode(sizes, keepdims=True)[0][0]
print('最常见的鞋码(众数):', mode)
输出:
最常见的鞋码(众数): 39
4.2 众数(分组数据)
- 公式:
M o = L + f 1 − f 0 2 f 1 − f 0 − f 2 × w Mo = L + \frac{f_1 - f_0}{2f_1 - f_0 - f_2} \times w Mo=L+2f1−f0−f2f1−f0×w
其中:- L L L:众数组下限
- f 1 f_1 f1:众数组频数
- f 0 f_0 f0:众数组前一组频数
- f 2 f_2 f2:众数组后一组频数
- w w w:组距
- 举例:第2组频数最大,前一组频数为3,当前为8,后一组为5,组距为10,则 M o = 10 + 8 − 3 2 × 8 − 3 − 5 × 10 Mo=10+\frac{8-3}{2 \times 8-3-5} \times 10 Mo=10+2×8−3−58−3×10。
- 适用场景:分组数据。
- 注意:众数不一定唯一。
【例子与代码】
(1)生活化例子:
某班学生身高分组如下:
- 160-165cm(3人)
- 165-170cm(8人)
- 170-175cm(5人)
众数组是165-170cm,频数最大。
- L=165
- f1=8
- f0=3
- f2=5
- w=5
众数 = 165 + 8 − 3 2 × 8 − 3 − 5 × 5 = 165 + 5 8 × 5 ≈ 168.1 众数 = 165 + \frac{8-3}{2\times8-3-5} \times 5 = 165 + \frac{5}{8} \times 5 \approx 168.1 众数=165+2×8−3−58−3×5=165+85×5≈168.1
(2)Python代码实现:
import numpy as np# 分组区间及频数(左开右闭)
bins = [160, 165, 170, 175] # 分组边界
freqs = [3, 8, 5] # 各组频数# 找到众数组(频数最大组)
mode_group = np.argmax(freqs)L = bins[mode_group] # 众数组下限
f1 = freqs[mode_group] # 众数组频数
f0 = freqs[mode_group - 1] if mode_group > 0 else 0 # 前一组频数
f2 = freqs[mode_group + 1] if mode_group < len(freqs) - 1 else 0 # 后一组频数
w = bins[mode_group + 1] - bins[mode_group] # 组距mode = L + (f1 - f0) / (2 * f1 - f0 - f2) * w
print('分组众数:', mode)
输出:
分组众数: 168.125
5. 分位数、四分位数、百分位数:数据的"分界线"
- 定义:把数据分成若干等份,常用的有四分位数(Q1、Q2、Q3),Q2其实就是中位数。
- 公式:
- Q 1 Q_1 Q1:第25%位置的数
- Q 2 Q_2 Q2:第50%位置的数(即中位数)
- Q 3 Q_3 Q3:第75%位置的数
- P k P_k Pk:第 k k k百分位数, k ∈ [ 1 , 99 ] k\in[1,99] k∈[1,99]
- 分组数据的分位数公式:
Q p = L + p N − F f × w Q_p = L + \frac{pN - F}{f} \times w Qp=L+fpN−F×w
其中 p p p 为分位点比例(如0.25, 0.5, 0.75),其余同中位数。 - 举例:求第90百分位数, p = 0.9 p=0.9 p=0.9,代入公式。
- 实际应用:高考分数线、收入分布、身高体重的分级等。
- 优缺点:抗极端值能力强,能反映分布的不同区间。
- 注意:百分位数不是百分比,分位数位置要用累计频数法定位。
【例子与代码】
(1)生活化例子:
某班10名学生成绩:[65, 70, 72, 75, 78, 80, 82, 85, 90, 95]
- Q1(25%分位数)=72.75
- Q2(50%分位数/中位数)=79
- Q3(75%分位数)=84.25
- 第90百分位数P90=90.5
(2)Python代码实现:
import numpy as np
scores = np.array([65, 70, 72, 75, 78, 80, 82, 85, 90, 95])
q1 = np.percentile(scores, 25)
q2 = np.percentile(scores, 50)
q3 = np.percentile(scores, 75)
p90 = np.percentile(scores, 90)
print('Q1:', q1, 'Q2:', q2, 'Q3:', q3, 'P90:', p90)
输出:
Q1: 72.75 Q2: 79.0 Q3: 84.25 P90: 90.5
6. 极值与极差:数据的"边界"
- 极大值: x max x_{\max} xmax,极小值: x min x_{\min} xmin
- 范围(极差):
R = x max − x min R = x_{\max} - x_{\min} R=xmax−xmin - 举例:最大分95,最小分65,极差30。
- 实际意义:极差能快速反映数据的跨度,但对极端值极其敏感。
- 注意:极差大不代表数据分布一定分散,可能只是有极端值。
【例子与代码】
(1)生活化例子:
某班10名学生成绩:[65, 70, 72, 75, 78, 80, 82, 85, 90, 95]
- 最大值=95,最小值=65,极差=95-65=30
(2)Python代码实现:
import numpy as np
scores = np.array([65, 70, 72, 75, 78, 80, 82, 85, 90, 95])
print('最大值:', np.max(scores))
print('最小值:', np.min(scores))
print('极差:', np.ptp(scores))
输出:
最大值: 95
最小值: 65
极差: 30
7. 离散程度统计量:数据"散不散"?
7.1 极差
- 最大值-最小值,反映数据的跨度。
【例子与代码】
(1)生活化例子:
某班成绩:[65, 70, 72, 75, 78, 80, 82, 85, 90, 95],极差=95-65=30。
(2)Python代码实现:
import numpy as np
scores = np.array([65, 70, 72, 75, 78, 80, 82, 85, 90, 95])
print('极差:', np.ptp(scores))
输出:
极差: 30
7.2 四分位距(IQR)
- Q3-Q1,反映中间50%数据的分布范围,抗极端值能力强。
【例子与代码】
(1)生活化例子:
同样成绩,Q3=84.25,Q1=72.75,IQR=84.25-72.75=11.5。
(2)Python代码实现:
import numpy as np
from scipy import stats
scores = np.array([65, 70, 72, 75, 78, 80, 82, 85, 90, 95])
print('IQR:', stats.iqr(scores))
输出:
IQR: 11.5
7.3 方差
- 每个数据与均值的差的平方的平均值,反映数据波动大小。
- 公式:
s 2 = 1 n − 1 ∑ i = 1 n ( x i − x ˉ ) 2 s^2 = \frac{1}{n-1} \sum_{i=1}^n (x_i - \bar{x})^2 s2=n−11i=1∑n(xi−xˉ)2 - 分组数据的方差公式:
s 2 = ∑ i = 1 k f i ( m i − x ˉ ) 2 N − 1 s^2 = \frac{\sum_{i=1}^k f_i (m_i - \bar{x})^2}{N-1} s2=N−1∑i=1kfi(mi−xˉ)2 - 举例:三组组中值10、20、30,频数2、3、5,均值23,则方差 = 2 × ( 10 − 23 ) 2 + 3 × ( 20 − 23 ) 2 + 5 × ( 30 − 23 ) 2 10 − 1 =\frac{2 \times (10-23)^2+3\times (20-23)^2+5\times(30-23)^2}{10-1} =10−12×(10−23)2+3×(20−23)2+5×(30−23)2。
- 实际意义:方差越大,数据波动越大。
【例子与代码】
(1)生活化例子:
同样成绩,方差=每个分数与均值差的平方的平均值(无偏估计用n-1)。
(2)Python代码实现:
import numpy as np
scores = np.array([65, 70, 72, 75, 78, 80, 82, 85, 90, 95])
print('方差:', np.var(scores, ddof=1))
输出:
方差: 85.06666666666666
7.4 标准差
- 方差的平方根,单位和原数据一样,更直观。
- 实际意义:标准差越大,数据越分散。标准差为0,说明所有数据都一样。
- 生活化案例:比如班级成绩标准差大,说明成绩差异大。
- 注意:标准差不是越小越好,要结合实际场景。
【例子与代码】
(1)生活化例子:
同样成绩,标准差=方差的平方根。
(2)Python代码实现:
import numpy as np
scores = np.array([65, 70, 72, 75, 78, 80, 82, 85, 90, 95])
print('标准差:', np.std(scores, ddof=1))
输出:
标准差: 9.223159256278006
7.5 变异系数
- 标准差/均值,适合比较不同量纲的数据波动性。
- 公式:
C V = s x ˉ CV = \frac{s}{\bar{x}} CV=xˉs - 实际意义:无量纲,便于不同单位、不同均值的数据比较。
- 举例:比较身高和体重的离散程度。
- 注意:均值为0时不能用变异系数。
【例子与代码】
(1)生活化例子:
同样成绩,标准差/均值=9.5/79.2≈0.116。
(2)Python代码实现:
import numpy as np
scores = np.array([65, 70, 72, 75, 78, 80, 82, 85, 90, 95])
cv = np.std(scores, ddof=1) / np.mean(scores)
print('变异系数:', cv)
输出:
变异系数: 0.11645403101361118
8. 形态统计量:数据"长什么样"?
8.1 偏度(偏态分布)
- 衡量数据分布是否对称。偏度>0,右偏(长尾在右);偏度<0,左偏。
- 公式:
S k e w n e s s = 1 n ∑ i = 1 n ( x i − x ˉ ) 3 s 3 Skewness = \frac{\frac{1}{n} \sum_{i=1}^n (x_i - \bar{x})^3}{s^3} Skewness=s3n1∑i=1n(xi−xˉ)3 - 实际意义:
- 右偏(正偏):均值 > 中位数 > 众数,数据向左集中,右侧有长尾。
- 左偏(负偏):众数 > 中位数 > 均值,数据向右集中,左侧有长尾。
- 生活化案例:收入分布通常右偏,大多数人收入低于均值。
- 可视化演示:
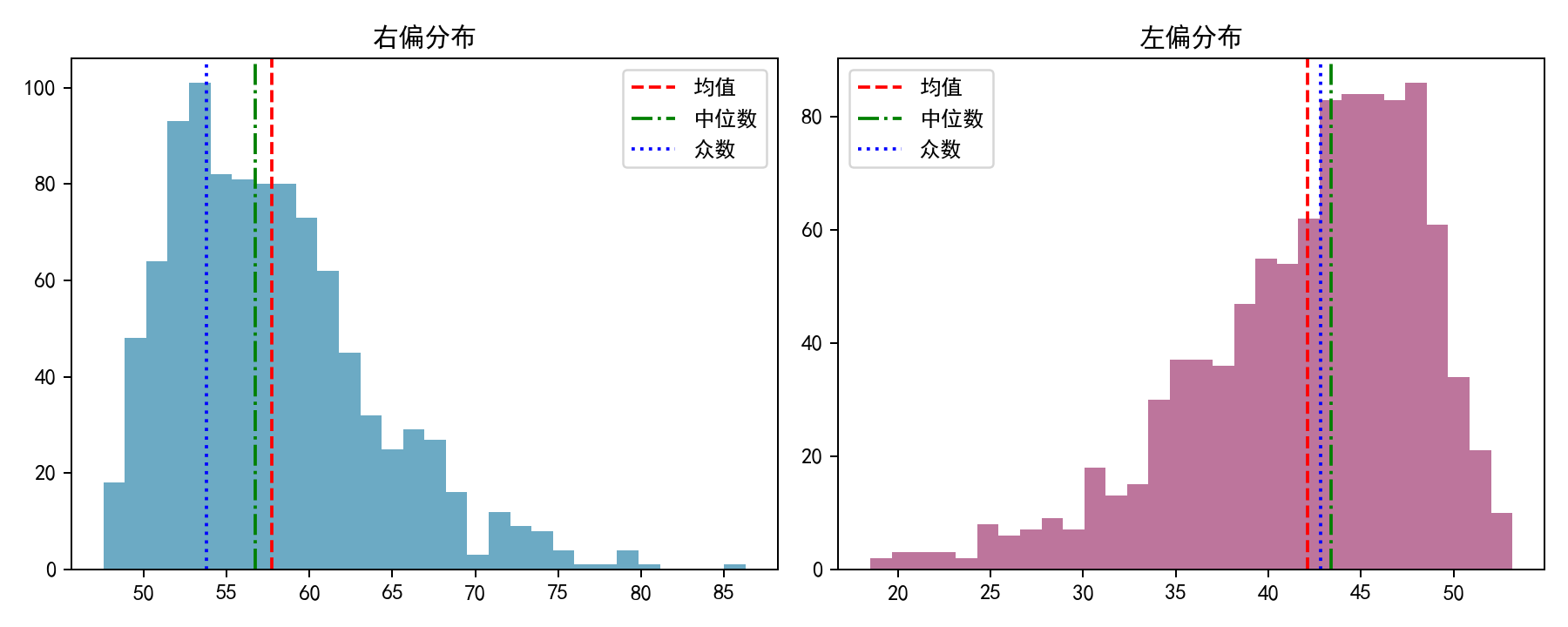
- 图解说明:
- 右偏分布:红线(均值)> 绿线(中位数)> 蓝线(众数)
- 左偏分布:蓝线(众数)> 绿线(中位数)> 红线(均值)
- 右偏常见于收入、房价等数据,左偏常见于老年人去世年龄分布(大部分人寿命较长,少数人早逝)。
- 注意:偏度大不代表数据异常,只是分布不对称。
【例子与代码】
(1)生活化例子:
某公司10名员工工资:[3000, 3200, 3500, 4000, 4200, 4500, 5000, 6000, 8000, 20000]
- 绝大多数工资集中在5000以下,只有一个人特别高,分布右偏。
(2)Python代码实现:
import numpy as np
from scipy import stats
salaries = np.array([3000, 3200, 3500, 4000, 4200, 4500, 5000, 6000, 8000, 20000])
skewness = stats.skew(salaries)
print('偏度:', skewness)
输出:
偏度: 2.2804665912927278
8.2 峰度
- 衡量分布"尖不尖"。峰度高,分布陡峭;峰度低,分布平坦。
- 公式:
K u r t o s i s = 1 n ∑ i = 1 n ( x i − x ˉ ) 4 s 4 − 3 Kurtosis = \frac{\frac{1}{n} \sum_{i=1}^n (x_i - \bar{x})^4}{s^4} - 3 Kurtosis=s4n1∑i=1n(xi−xˉ)4−3 - 实际意义:判断分布是否有"厚尾"或"尖峰"。
- 注意:对极端值敏感,解释需结合实际。
【例子与代码】
(1)生活化例子:
同样工资数据,峰度反映分布是否有尖峰或厚尾。
(2)Python代码实现:
import numpy as np
from scipy import stats
salaries = np.array([3000, 3200, 3500, 4000, 4200, 4500, 5000, 6000, 8000, 20000])
kurt = stats.kurtosis(salaries)
print('峰度:', kurt)
输出:
峰度: 3.825791712058331
9. 频数与频率统计量:数据的"热度榜"
- 频数:某个数出现的次数
- 频率:某个数出现的比例
- 累计频数/频率:小于等于某值的累计次数/比例
- 公式:
- 频数 $f_i $:第 i i i 类别出现的次数
- 频率 p i p_i pi: p i = f i n p_i = \frac{f_i}{n} pi=nfi
- 累计频数/频率:前 i i i 类别的频数/频率之和
- 累计频率曲线:以横轴为数据值,纵轴为累计频率,画出曲线,常用于分布特征直观展示。
- 举例:分组累计频数定位分位点。
- 适用场景:分类数据、分组数据、分布特征展示
- 注意:累计频率不是概率分布,累计频数定位分位点需精确
【例子与代码】
(1)生活化例子:
10名同学喜欢的水果:[‘苹果’, ‘香蕉’, ‘苹果’, ‘橙子’, ‘香蕉’, ‘苹果’, ‘葡萄’, ‘香蕉’, ‘苹果’, ‘橙子’]
- 频数:苹果4,香蕉3,橙子2,葡萄1
- 频率:苹果40%,香蕉30%,橙子20%,葡萄10%
(2)Python代码实现:
import pandas as pd
fruits = ['苹果', '香蕉', '苹果', '橙子', '香蕉', '苹果', '葡萄', '香蕉', '苹果', '橙子']
s = pd.Series(fruits)
counts = s.value_counts()
freq = s.value_counts(normalize=True)
print('频数:')
print(counts)
print('频率:')
print(freq)
输出:
频数:
苹果 4
香蕉 3
橙子 2
葡萄 1
Name: count, dtype: int64
频率:
苹果 0.4
香蕉 0.3
橙子 0.2
葡萄 0.1
Name: count, dtype: float64
10. 生活化案例:小班成绩分析
假设有10个同学的数学成绩如下:
[65, 70, 72, 75, 78, 80, 82, 85, 90, 95]
我们来用各种统计量描述这组数据:
- 📊 均值:79.2分
- 📈 中位数:79分(第5和第6个数的平均)
- 🥇 众数:无(每个分数只出现一次)
- 📏 极差:95-65=30分
- 🟩 四分位数:Q1=72.75,Q2=79,Q3=84.25
- 🟦 IQR:84.25-72.75=11.5分
- 🧮 方差/标准差:约85.07/9.2
- 🔀 偏度/峰度: 0.1986/-0.8172
11. 动手试试:用代码说话
import numpy as np
from scipy import statsscores = np.array([65, 70, 72, 75, 78, 80, 82, 85, 90, 95])print('均值:', np.mean(scores))
print('中位数:', np.median(scores))
print('众数:', stats.mode(scores, keepdims=True)[0][0])
print('极差:', np.ptp(scores))
print('方差:', np.var(scores, ddof=1))
print('标准差:', np.std(scores, ddof=1))
print('四分位数:', np.percentile(scores, [25, 50, 75]))
print('IQR:', stats.iqr(scores))
print('偏度:', stats.skew(scores))
print('峰度:', stats.kurtosis(scores))
12. 别被这些误区骗了
❌ 误区1:平均数就是"典型水平"
真相:极端值会让平均数失真,中位数或众数有时更靠谱。
❌ 误区2:标准差越小越好
真相:要结合实际场景,有时分散反而是好事。
举个例子:
比如在投资理财中,如果你的投资组合里既有稳健型资产(收益波动小),也有高风险高收益的资产(收益波动大),整体收益的标准差就会比单一资产大一些。这种"分散"有时是好事,因为它意味着你有机会获得更高的收益,而不是所有资产都表现平平。如果所有资产收益都一样(标准差为0),反而缺乏增长动力。
❌ 误区3:众数一定存在
真相:有的数据没有众数,或有多个众数。
❌ 误区4:极差越大数据越分散
真相:可能只是有极端值。
❌ 误区5:分组数据的中位数/众数可以直接取组中值
真相:必须用公式推算。
13. 重点回顾
✅ 描述性统计是数据分析的第一步,帮我们快速了解数据特征
✅ 常见统计量分为位置、离散、形态三类
✅ 每个统计量有适用场景和局限性,不能机械套用
✅ 生活中很多"平均数"其实并不代表大多数人
14. 练习一下
基础题
- 用自己的话解释均值、中位数、众数的区别。
- 什么时候用中位数比均值更合适?
- 极差和IQR分别适合什么场景?
思考题
- 某公司10名员工工资分别为[3000, 3200, 3500, 4000, 4200, 4500, 5000, 6000, 8000, 20000],你觉得用哪个统计量描述"典型工资"最合适?为什么?
- 某班数学成绩标准差为0,说明了什么?
动手题
- 用代码算出上面成绩的偏度和峰度,并解释结果。
- 试着用自己的数据,算一算均值、中位数、众数、极差、标准差。
15. 下期预告
下一篇我们聊"数据可视化:一图胜千言",会带你用各种图表把数据讲清楚,敬请期待!
📚 参考资料
- 吴喜之著《统计学:从数据到结论》,中国统计出版社
- 盛骤等著《概率论与数理统计》,高等教育出版社
- 作者个人学习和实践经验总结
写在最后:如果你觉得这篇文章对你有帮助,欢迎点赞、收藏和分享!有任何问题或建议,欢迎在评论区留言交流,我会认真回复每一条评论。让我们一起用统计学的眼光看世界,一起进步!📊