构建高性能风控指标系统
一、引言
在金融风控领域,指标是风险识别的核心依据。风控平台核心系统之一--规则引擎的运行依赖规则、变量和指标,一个高性能的指标系统非常重要,本文将深入探讨风控平台指标系统的全链路技术实现,涵盖从指标配置到查询优化的完整闭环。
一个高效的指标系统需支持:
1)灵活配置;
2)多源采集;
3) 低延迟计算;
4) 毫秒级查询。
基于金融交易所的业务特性,指标计算所依赖的业务数据既有短周期(比如一个月内的业务数据),也有时间较为久远的数据(比如一年内的业务数据),所以根据依赖业务数据的时间特性,需要设计实时与离线双引擎驱动的指标计算系统。
二、系统架构概览
风控指标系统采用分层架构设计:
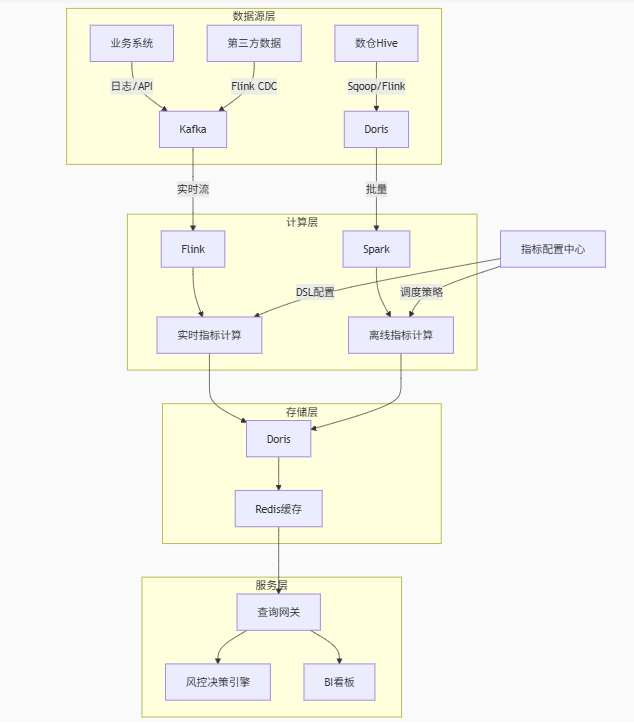
三、核心模块技术实现
1. 指标配置:灵活定义与动态解析
**技术栈:Spring Boot + Groovy DSL + 关系数据库**
- **动态DSL引擎**
通过Groovy脚本实现指标逻辑的灵活配置,支持动态加载:
```groovy
// 示例:计算用户近1小时交易次数
def calculate(Event event) {
return event.where("event_time > NOW()-3600")
.groupBy("user_id")
.count("txn_id");
}
```
- **元数据管理**
指标基础属性(名称、类型、数据源)存储于MySQL,计算逻辑以脚本形式存储。
2. 数据采集:多源异构数据统一接入
(1) 业务系统实时数据
- **采集方式**:通过`Logstash`或`Filebeat`抓取业务日志,写入Kafka
- **Kafka Topic设计**:
```bash
# 按业务领域划分Topic
risk_platform.payment_txn # 支付交易
risk_platform.user_behavior # 用户行为
```
(2) 数仓离线数据
- **采集策略**:
- 每日增量:通过Sqoop同步Hive表至Doris
- 小时级更新:Flink消费Kafka写入Doris
(3) Doris实时接入层
```sql
-- 创建Doris Kafka导入作业
CREATE ROUTINE LOAD risk_platform.payment_load ON payment_txn
PROPERTIES (
"format" = "json",
"kafka_broker_list" = "broker1:9092",
"kafka_topic" = "risk_platform.payment_txn"
);
```
3. 指标计算:批流一体计算引擎
(1) 实时计算:Doris Streaming
**优势**:
- 支持秒级数据可见性
- 内置Rollup预聚合加速查询
**典型场景实现**:
```sql
-- 创建实时聚合物化视图(近10分钟交易金额)
CREATE MATERIALIZED VIEW txn_amt_10min AS
SELECT
user_id,
SUM(amount) AS total_amt,
NOW() AS calc_time
FROM payment_txn
WHERE event_time > NOW() - 600
GROUP BY user_id;
```
(2) 离线计算:Spark分布式批处理
**T+1指标计算流程**:
```python
# PySpark计算用户历史欺诈率
df = spark.sql("""
SELECT
user_id,
COUNT_IF(status='fraud') / COUNT(*) AS fraud_rate
FROM dwd_risk_txn
WHERE dt='${date}'
GROUP BY user_id
""")
df.write.format("doris").save("risk_user_stats")
```
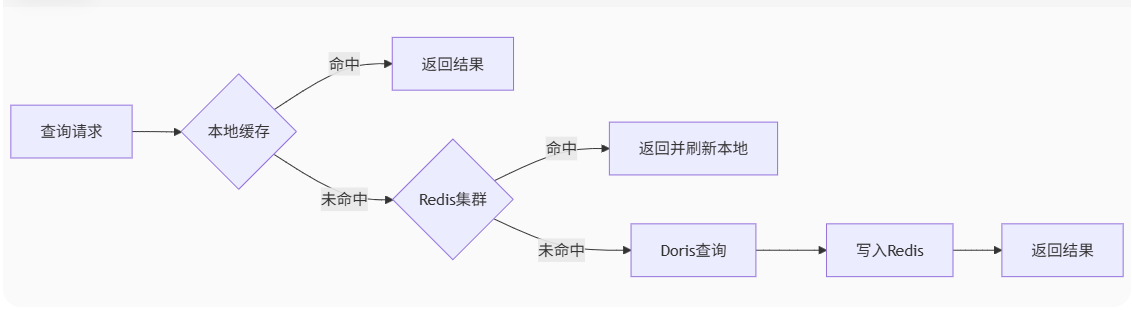
4. 指标存储:分级存储策略
| 存储类型 | 适用场景 | 性能指标 |
|-------------|-------------------|----------------|
| **Doris** | 复杂聚合查询 | 99% < 200ms |
| **Redis** | 高频单点查询 | 99% < 5ms |
| **HBase** | 历史明细存储 | 范围查询优化 |
**Redis缓存设计**:
```java
// 伪代码:查询优先走缓存
public MetricResult getMetric(String key) {
// 1. 布隆过滤器预判
if(!bloomFilter.mightContain(key)) return null;
// 2. 分布式锁防击穿
RLock lock = redisson.getLock(key);
try {
lock.lock(3, TimeUnit.SECONDS);
ValueWrapper value = redisTemplate.opsForValue().get(key);
if(value != null) return (MetricResult)value;
// 3. 回源查询
MetricResult result = queryFromDoris(key);
redisTemplate.opsForValue().set(key, result, 5, TimeUnit.MINUTES);
return result;
} finally {
lock.unlock();
}
}
```
5. 查询服务:统一网关与优化
**技术实现要点**:
- **查询路由引擎**:
- 简单KV查询 → Redis
- 复杂OLAP → Doris
- **Doris查询优化**:
```sql
-- 启用分桶裁剪和物化视图匹配
SET enable_bucket_shuffle_join=true;
SET enable_materialized_view_rewrite=true;
```
- **API网关**:基于Spring Cloud Gateway封装RESTful接口,支持QPS限流。、
四、关键技术挑战与解决方案
挑战1:实时与离线数据一致性
**解决方案**:
- 使用`Doris Unique Key模型`实现Upsert
- 离线计算结果覆盖实时数据时采用`版本号比对`
挑战2:高并发查询压力
**应对策略**:
- **Redis分片集群**:Codis架构支持横向扩展
- **Doris查询分流**:
```mermaid
graph LR
A[查询请求] --> B{查询类型}
B -->|简单聚合| C[Doris FE]
B -->|复杂SQL| D[Doris BE集群]
```
挑战3:指标回溯计算
**实现方案**:
- 基于`Apache Iceberg`构建数仓历史快照
- Spark批量重算时指定时间戳:
```scala
spark.read.format("iceberg")
.option("snapshot-id", "123456789")
.load("risk_db.txn_table")
```
五、总结
> **技术栈全景图**:
> Kafka → Flink/Logstash → Doris/Spark → Redis
案例示意图:
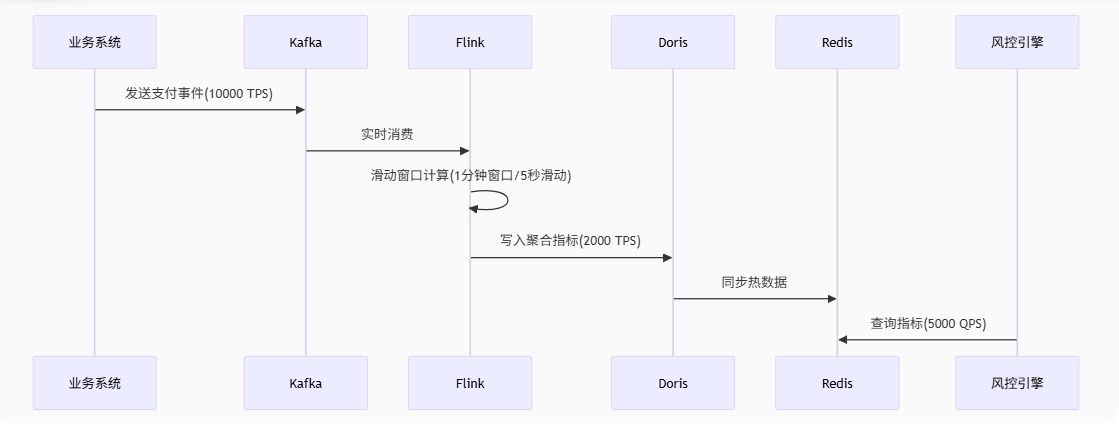
> 通过分层解耦与组件优化,实现毫秒级延迟与TB级数据支撑能力。