进阶日记(一)大模型的本地部署与运行
目录
一、背景知识
为什么要在本地部署大模型?
在本地部署大模型需要做哪些准备工作?
(1)硬件配置
(2)软件环境
有哪些部署工具可供选择?
二、Ollma安装
Ollama安装完之后,还需要进行环境变量的配置
配置完环境变量后,就可以从Ollama上下载模型到本地了
接上一篇(非科班大模型工程师进阶日记(〇)),这次我们来试试本地部署一个大模型。
开门见山,要想在本地部署自己的大模型,大致可以分以下几步:
- 下载Ollama,通过Ollama将DeepSeek模型下载到本地运行;
- 下载RAGflow源代码和Docker,通过Docker来本地部署RAGflow;
- 在RAGflow中构建个人知识库并实现基于个人知识库的对话问答。
But,光了解操作步骤是不够的,下面我们先从背景知识开始进行一些简单的介绍。
一、背景知识
注:不了解以下背景知识并不会对后续的安装部署产生决定性影响,但是授人以鱼不如授人以渔,大家各取所需就好。
为什么要在本地部署大模型?
本地部署的核心价值在于自主性与安全性,尤其适合对数据隐私、响应速度或定制化有高需求的场景:
-
数据主权保障
-
敏感数据(如企业文档、个人隐私)无需上传云端,避免第三方泄露风险。例如扬州环境监测中心部署DeepSeek-R1,就是因环境数据涉及国家安全,必须本地处理5。
-
-
性能与响应优化
-
本地推理消除网络延迟,实现毫秒级响应(如实时数据分析、边缘计算场景)16。
-
-
长期成本可控
-
云端模型按Token计费,高频使用成本高昂;本地部署一次性投入硬件,后续近乎零成本67。
-
-
高度定制化能力
-
支持模型微调(如LoRA、P-Tuning)、知识库集成(上传私有文档训练),突破公版模型的功能限制18。
-
💡 典型场景:企业机密数据处理、离线环境应用(野外监测)、个性化AI助手开发。
在本地部署大模型需要做哪些准备工作?
(1)硬件配置
根据模型规模选择硬件,显存是关键瓶颈:
| 模型规模 | 最低配置 | 推荐配置 | 适用工具 |
|---|---|---|---|
| 7B参数 | 16GB内存 + RTX 3060 (6GB) | 32GB内存 + RTX 3070 (8GB) | Ollama, LM Studio |
| 13B参数 | 32GB内存 + RTX 3090 (24GB) | 64GB内存 + 双RTX 4090 | vLLM, LLaMA.cpp |
| 70B参数 | 64GB内存 + 多A100显卡 | 服务器级CPU+128GB内存+8×A100 GPU | vLLM(企业级)37 |
⚠️ 注意:若无独立显卡,可用CPU+大内存运行量化模型(但速度显著下降)。
(2)软件环境
-
操作系统:Linux(最佳兼容性)、Windows/MacOS
-
基础依赖:
-
Python 3.8+、CUDA工具包(NVIDIA显卡必需)
-
深度学习框架:PyTorch或TensorFlow6
-
-
虚拟环境:建议用Conda隔离依赖(避免版本冲突)
有哪些部署工具可供选择?
在进行大模型本地部署时,需要根据自己的技术背景和需求,选择合适工具。
| 工具 | 特点 | 适用场景 | 安装复杂度 |
|---|---|---|---|
| Ollama | 命令行操作,一键运行模型,支持多平台 | 快速体验、轻量测试 | ⭐ |
| LM Studio | 图形界面,可视化下载/运行模型(Hugging Face集成) | 非技术用户、隐私敏感场景 | ⭐⭐ |
| vLLM | 高性能推理框架,支持分布式部署、API服务化 | 企业级高并发需求 | ⭐⭐⭐⭐ |
| LLaMA.cpp | CPU/GPU通用,资源占用低(C++编写) | 老旧硬件或低显存设备 | ⭐⭐⭐ |
| GPT4All | 开源轻量化,自动调用GPU加速 | 个人开发者、跨平台应用 | ⭐⭐ |
示例:Ollama部署DeepSeek-R1(适合新手,也是本次教程的选用方案)
# 安装Ollama(Linux一键命令)
curl -fsSL https://ollama.com/install.sh | sh# 运行7B参数模型
ollama run deepseek-r1:7bOK,了解完以上知识,开展下面的工作就不会云里雾里,知其然而不知其所以然了。
二、Ollma安装
Ollama是一个用于本地运行和管理大语言模型(LLM)的工具。
Ollama的安装,直接上官网Download即可,不放心的可以看这篇教程:Ollama 安装。
Ollama安装完之后,还需要进行环境变量的配置:
(必选)OLLAMA_HOST - 0.0.0.0:11434
- 作用:默认条件下,Ollma只能通过本机访问,但出于便捷性考虑,我们这次部署是通过Docker进行,配置这一环境变量就是为了让虚拟机里的RAGFlow能够访问到本机上的 Ollama;(具体原理参见:配置Ollama环境变量,实现远程访问)
- 如果配置后虚拟机无法访问,可能是你的本机防火墙拦截了端口11434;
- 不想直接暴露 11434 端口则可通过SSH 端口转发来实现虚拟机访问。
(可选)OLLAMA_MODELS - 自定义位置
- 作用:Ollama 默认会把模型下载到C盘,如果希望下载到其他盘需要进行这一配置。
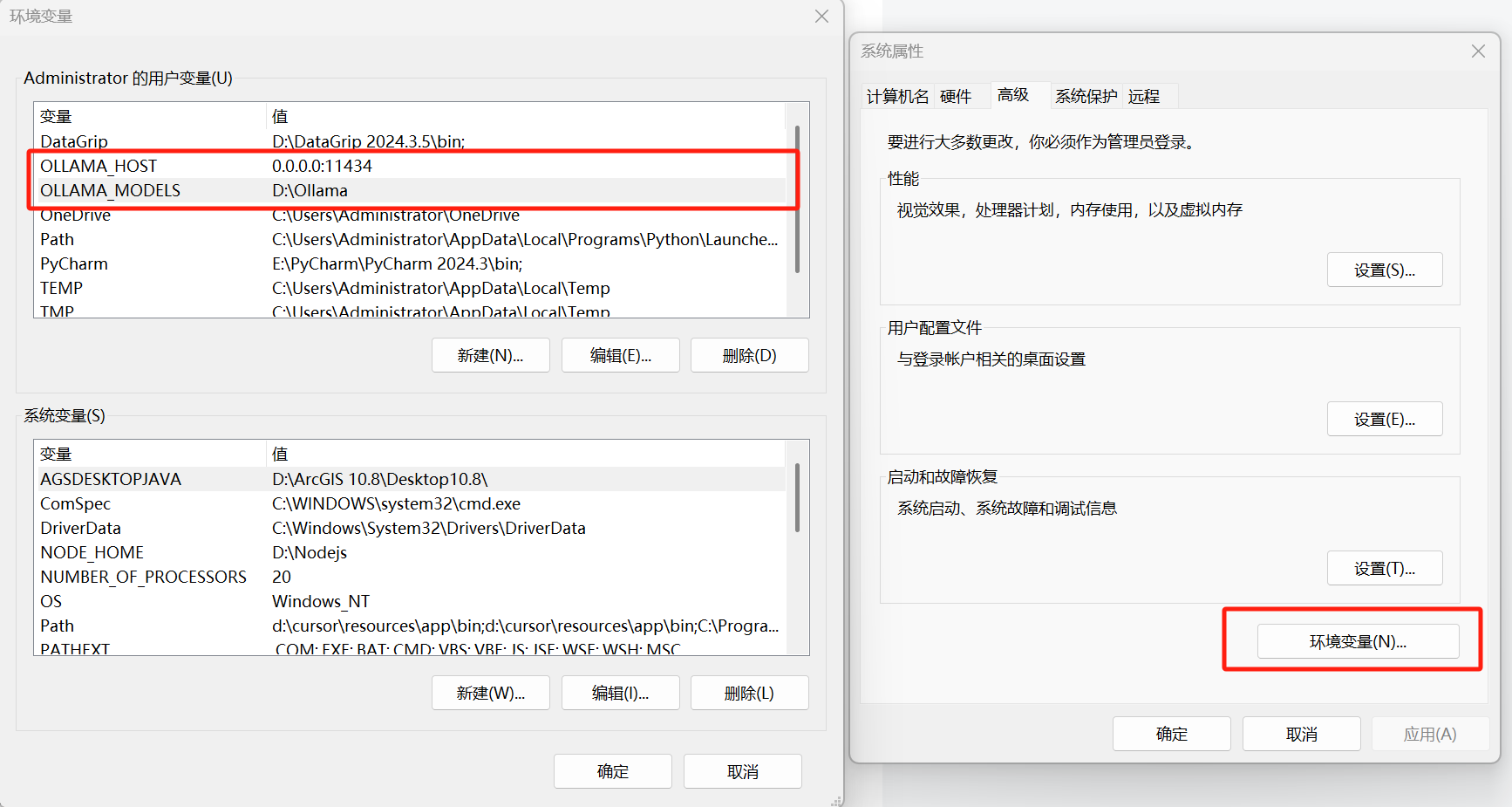
更新完两个环境变量记得重启,不然无法立即生效。
配置完环境变量后,就可以从Ollama上下载模型到本地了:
这次我们以Deepseek-R1:8b为例,需要注意的是,模型越大对本地机器配置要求越高,一般来说deepseek 32b就能达到不错的效果,更高的不一定能跑的起来。
配置及模型选择可参考:个人用户进行LLMs本地部署前如何自查和筛选
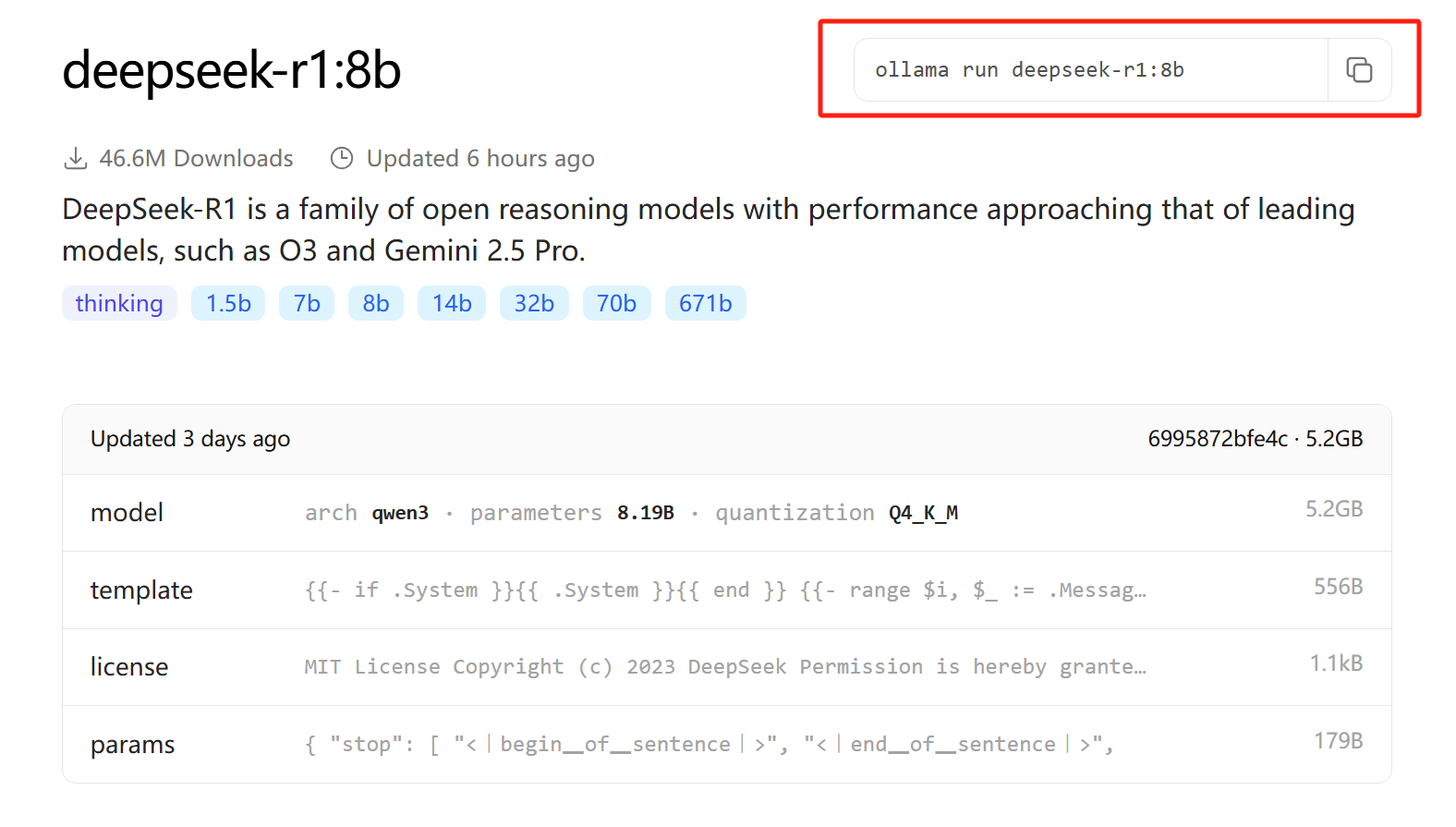
下载方式就是复制Ollama官网提供的相应指令,通过电脑命令行进行下载(Windows+R、cmd)
ollama run deepseek-r1:8b下载完成后,可以直接在命令行窗口进行问答,至此,你就成功完成了大模型的本地化部署!
Congrats!
本地化部署虽然是很简单的一步,却为未来打开了更多可能性。但是,做到这里还不算完全拥有了自己的大模型,下一篇我会讲如何结合RAGFlow来构建自己的本地知识库,从而让DeepSeek更懂你的需求。
祝大家玩儿的开心!
See you next time!:)