Linux正则三剑客篇
一、历史命令
-
history命令 :用于输出历史上使用过的命令行数量及具体命令。通过history可以快速查看并回顾之前执行过的命令,方便重复操作或追溯执行过程。 -
!行号:通过指定历史命令的行号来重新执行该行号对应的命令。例如,若history显示第 5 行命令为ls -l,则执行!5将重新运行ls -l命令。 -
!!:用于重复执行上一次使用过的命令。这是一个便捷的方式,尤其在需要多次执行同一命令时,可提高工作效率。
二、Bash 特性
-
命令处理器 :Bash 是一种运行在文本窗口中的命令处理器,能够执行用户直接输入的命令,实现与系统的交互。
-
脚本支持 :Bash 可以从文件中读取 Linux 命令,这样的文件被称为脚本。通过编写脚本,可以实现命令的批量执行,自动化任务处理,提高工作效率。
-
功能支持 :Bash 支持多种功能,如通配符(用于模式匹配和文件操作)、管道(用于命令间的数据传递)、命令替换(将命令输出作为其他命令的输入)、条件判断(基于条件执行不同命令)等逻辑控制语句,为用户提供了强大的命令组合和处理能力。
三、快捷键
-
Ctrl + a:将光标快速移动到当前行的行首位置,方便对命令行开头的内容进行修改或补充。 -
Ctrl + e:将光标快速移动到当前行的行尾位置,便于在命令行末尾继续输入或编辑内容。 -
Ctrl + u:用于删除光标之前的所有字符,快速清空当前光标前面的内容,适合在输入错误或需要大幅修改命令时使用。 -
Ctrl + k:用于删除光标之后的所有字符,能够迅速截断光标后面的内容,方便重新输入或调整命令的后半部分。 -
Ctrl + l:清空屏幕终端内容,与clear命令功能相同,可使终端界面保持整洁,便于查看新的输出信息。
四、命令补全
-
Tab键 :在输入命令时,可通过按下Tab键来自动补全命令。Bash 会根据$PATH环境变量中配置的目录路径,查找并匹配可能的命令名称,若唯一匹配则自动补全,若存在多个匹配项则提示用户进行选择,这样可减少命令输入量,提高命令行操作的效率,避免因拼写错误导致的命令无法识别等问题。
五、Linux 正则表达式
-
定义与工具 :正则表达式(Regular Expression,Reg Exp)是一种由特殊字符及文本字符组成的模式,用于描述和匹配字符串。它是强大的文本处理工具,广泛应用于 Linux 系统中的文本处理任务。
-
分类 :正则表达式主要分为两类,基本正则表达式(BRE,Basic Regular Expression)和扩展正则表达式(ERE,Extended Regular Expression)。
-
基本正则表达式BRE集合: 匹配字符、匹配次数、位置锚定。
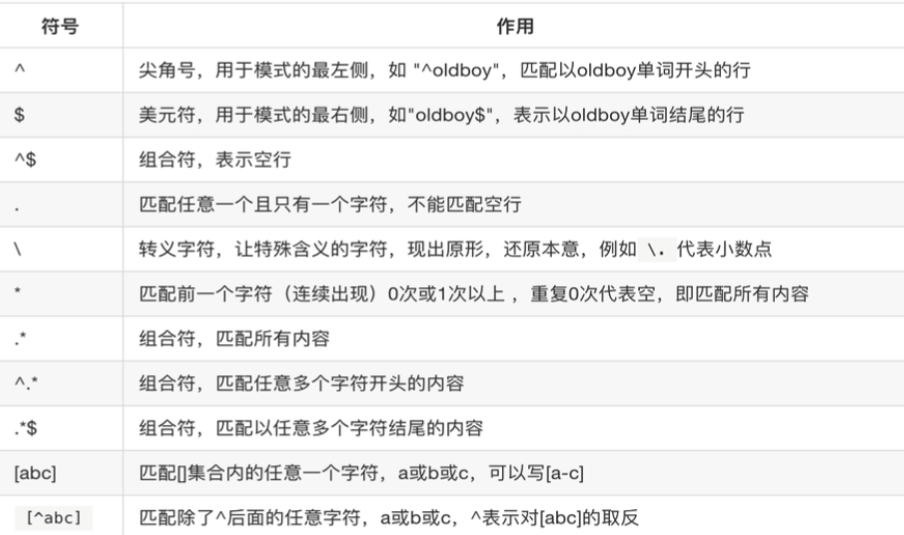
-
ERE 在 BRE 的基础上增加了更多的特殊字符和功能,提供了更强大的匹配能力。

-
-
意义与应用场景 :正则表达式的意义在于高效处理大量的字符串和文本内容。在 Linux 运维工作中,常常需要处理各种带有字符串内容的文件,如配置文件、程序代码、命令输出结果、日志文件等。通过正则表达式,管理员可以快速准确地过滤、替换和处理所需的特定字符串,从而提高工作效率,完成诸如查找特定日志条目、修改配置参数、提取代码片段等任务。
-
支持工具 :在 Linux 下,正则表达式主要受到三剑客(sed、awk、grep)的支持,其他普通命令通常无法直接使用正则表达式。通配符虽然在大部分普通命令中都支持,但主要用于查找文件或目录,而正则表达式则侧重于在文件内容或数据流中进行复杂的过滤和处理。
六、Linux 三剑客
-
grep 命令
-
作用 :作为文本过滤工具,
grep可在文件或文本数据流中查找与指定模式(pattern)匹配的内容,并输出匹配的行。这在需要从大量文本中筛选出符合特定条件的信息时非常有用,例如在日志文件中查找包含特定关键词的错误记录、从配置文件中提取相关设置等。 -
扩展正则表达式ERE集合:
-
使用grep命令只能使用基本正则表达式BRE。
-
需要使用扩展正则表达式ERE,必须使用grep -E才能生效。
-
-
格式 :
grep '查找的内容' 查找的目录/文件。-
其中
'查找的内容'是要匹配的模式,可以是简单的字符串,也可以包含正则表达式的特殊字符;后面跟要查找的文件或目录路径。
-
-
选项
-
-n:在输出匹配的行时,同时显示该行在文件中的行号,便于定位信息所在的物理位置。 -
-i:忽略匹配时的大小写差异,使查找更加灵活,不会因大小写不一致而遗漏潜在的匹配项。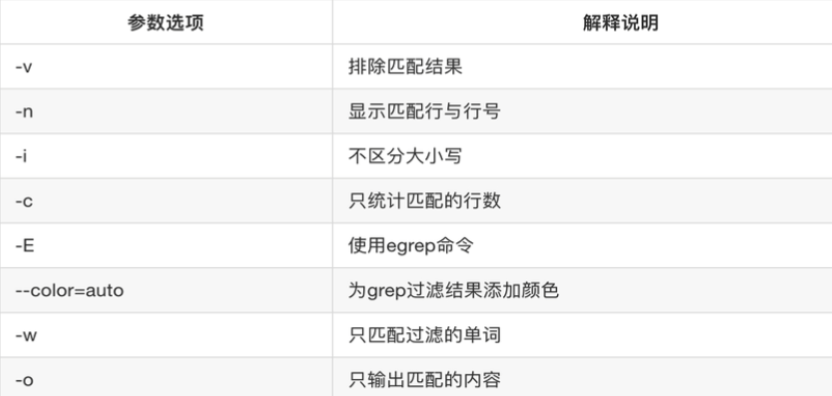
-
-
实例
-
将
/etc/passwd文件内容复制到/tmp/test_grep.txt文件中,以便进行测试操作:cat /etc/passwd > /tmp/test_grep.txt。 -
查找并输出
/tmp/test_grep.txt文件中包含 "login" 的行,并显示行号:grep "login" /tmp/test_grep.txt -n。 -
查找并输出
/tmp/test_grep.txt文件中不包含 "login" 的行,同时显示行号:grep "login" /tmp/test_grep.txt -n -v。这里-v选项用于反转匹配结果,即输出不匹配的行。 -
忽略大小写,查找并输出
/tmp/test_grep.txt文件中包含 "root" 的行:grep "ROOT" /tmp/test_grep.txt -i。 -
使用扩展正则表达式,同时过滤出
/tmp/test_grep.txt文件中包含 "root" 或 "sync" 的行,并以彩色高亮显示匹配部分:grep -E "root|sync" /tmp/test_grep.txt --color=auto。-E选项用于启用扩展正则表达式的语法,|表示逻辑或的关系,匹配任意一个模式。 -
查找并输出
/tmp/test_grep.txt文件中包含 "login" 的行,并统计匹配结果的行数:grep "login" /tmp/test_grep.txt | wc -l。 -
查找并输出
/tmp/test_grep.txt文件中包含 "login" 的行,仅显示匹配的内容部分:grep "login" /tmp/test_grep.txt -o。 -
查找并输出
/tmp/test_grep.txt文件中完整匹配 "oldboy" 这个单词的行:grep "oldboy" /tmp/test_grep.txt -w。这里-w选项用于指定完整单词匹配,确保匹配的是独立的单词 "oldboy",而不是包含在其他字符串中的子串。 -
过滤掉
/tmp/test_grep.txt文件中的空白行和注释行:grep -E "^#|^$" /tmp/test_grep.txt -v。^#匹配以#开头的注释行,^$匹配空行,-v选项用于排除这些行,输出非空白行和非注释行的内容。
-
-
注意事项 :在 Linux 平台下,文件的结尾确实可能存在不可见的特殊字符,如
$符。可以使用cat -A命令查看文件内容,包括这些特殊字符,以便更好地理解和处理文件格式相关的问题。
-
-
sed 命令
-
作用 :
sed是一个流编辑器,用于对文本或数据流进行处理,包括编辑、过滤和转换文本内容。它能够按照用户指定的规则对文本进行操作,并将处理后的结果输出到标准输出设备(如屏幕),或者重定向到文件中。 -
格式 :
sed sed内置命令字符 输入的文件名称。-
其中,sed内置命令字符用于指定具体的操作指令,如替换、删除、插入等;后面跟要处理的文件名称。

-
sed参数选项
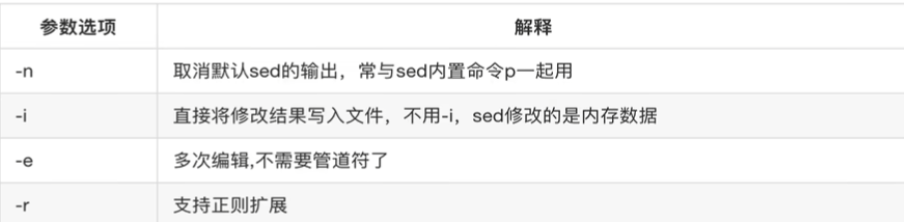
-
sed匹配范围
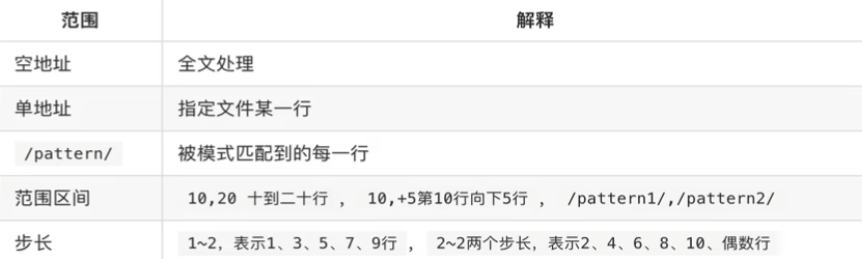
-
-
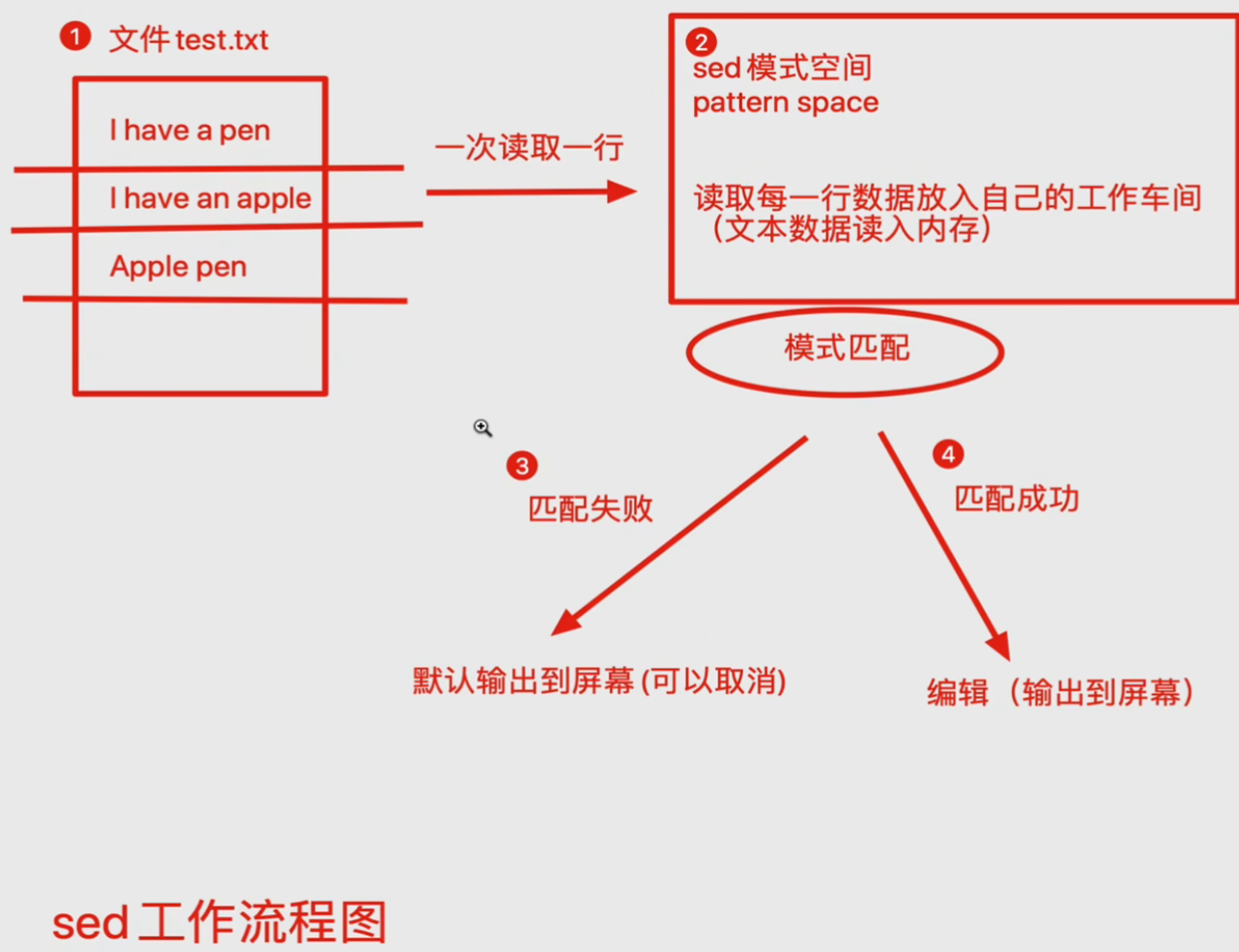
工作流程
-
sed逐行读取文件内容,每次读取一行数据。 -
将读取的每一行数据加载到一个临时的工作区域,称为
sed模式空间,相当于在内存中创建了一个文本数据的副本,用于后续的处理操作。 -
根据用户指定的模式匹配规则,对模式空间中的数据进行处理。如果数据符合匹配条件,则执行相应的编辑操作,如替换内容、删除行等;不符合匹配条件的数据则保持不变,并直接输出到屏幕或其他指定的输出位置。
-
-
示例 :假设要将文件中的某个单词替换为另一个单词,或者删除包含特定模式的行等,
sed都能高效地完成这些任务。 -
ifconfig 命令 :用于显示网络接口的 IP 地址信息等配置情况,与
sed命令本身无直接关联,但在实际应用中,可能通过sed对ifconfig命令的输出结果进行进一步的处理和分析,例如提取特定的 IP 地址信息等。
-
-
awk 命令
-
作用 :
awk是 Linux 下强大的文本报告生成器,擅长对文本数据进行格式化处理,能够将数据整理成类似专业表格的样式,便于阅读和分析。它广泛应用于数据处理、统计分析、文本转换等场景。 -
格式 :
awk awk可选参数 '条件动作' 文件/数据。-
其中,
awk可选参数用于指定一些控制选项;'条件动作'是awk程序的核心部分,定义了数据处理的逻辑和操作;最后指定要处理的文件或数据来源。
-
-
运行特点
-
awk按行处理文件内容,逐行读取并进行分析和操作。 -
它可以根据用户指定的分隔符来分割每一行的数据,默认情况下以空格作为分隔符,并且会将连续的多个空格视为一个分隔符来处理,这样可以方便地提取出字段数据。
-
例如,
awk 'NR==5{print $1}' filename表示处理文件filename的第 5 行,并输出该行的第一个字段。 -
如果需要一次性输出多个字段,并且希望以逗号(
,)作为字段之间的分隔符,则可以通过设置输出分隔符来实现。
-
-
变量
-
内置变量 :
awk提供了多种内置变量用于获取和操作数据。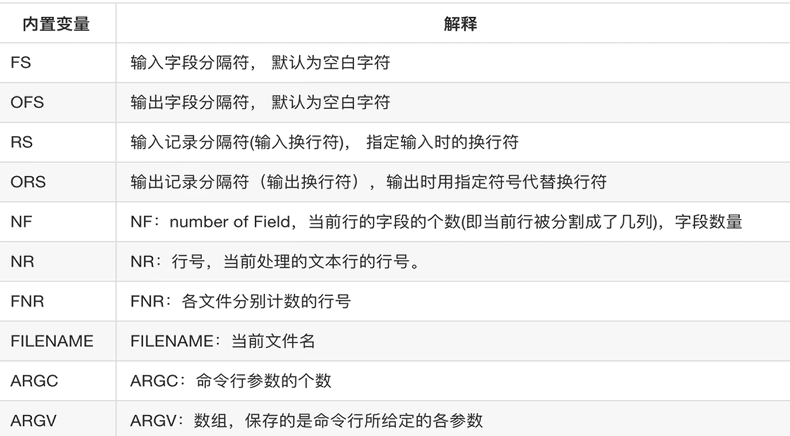
-
NR表示当前处理的行号。 -
$1表示第一个字段。 -
$0表示整行内容。 -
$2表示第二个字段。 -
$NF表示当前行的最后一个字段。 -
(NF-1)可用于引用倒数第二个字段。 -
FS表示输入分隔符,用于指定数据行中各个字段之间的分隔字符。 -
OFS表示输出分隔符,用于指定输出数据时各字段之间的分隔字符。 -
RS表示输入换行符,默认为回车键,用于定义每行数据的结束标志。 -
ORS表示输出换行符,默认为回车键,用于指定输出每行数据后的换行方式。 -
ARGV是一个数组,用于保存命令行传递给awk程序的参数,其中ARGV[0]是awk命令本身,后续元素依次为各个输入文件名等参数。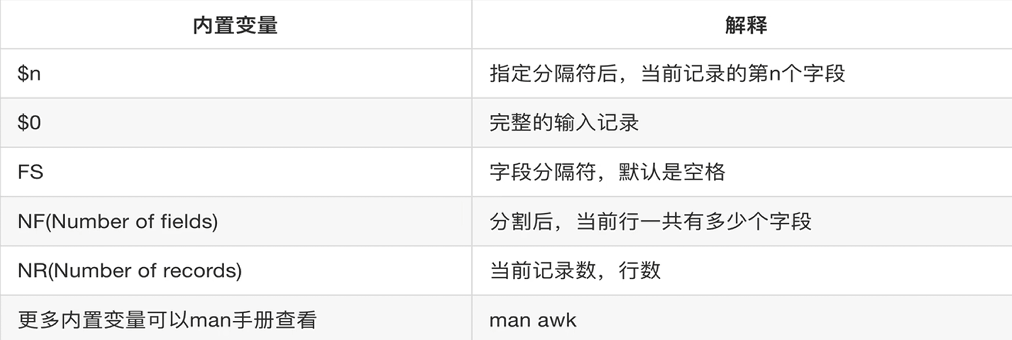
-
ARGC的数组是一种数据类型,如下图为一个盒子,盒子有它的名字,且内部有N个小格子,标号从O开始给一个盒子起名字叫做months,月份是1~12。
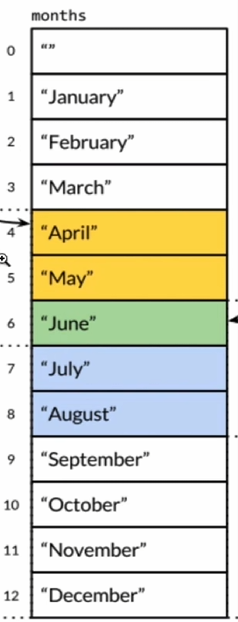
-
-
自定义变量 :用户可以在
awk程序中定义自己的变量,用于存储和处理数据。-
定义方式有两种:
-
一是在命令行中使用
-v varName=value的形式为变量赋初值。 -
二是在
awk程序的代码块中直接进行变量赋值操作。
-
-
-
-
动作:printf和pintf
-
awk中两种常用的输出操作。 -
printf需要用户指定输出格式,通过格式说明符(如%d、%s、%f等)来控制每个数据项的输出样式,且不会自动添加换行符,需要手动在格式字符串中指定\n来换行. -
而
print命令则会自动在输出内容后添加空格和换行符,默认以空格分隔各输出项,并在每项输出后换行。 -
例如,
printf "Value: %d\n", var和print var分别使用了不同的输出方式。 -
在使用
printf时,可以使用一些修饰符来进一步控制输出格式。如-用于指定左对齐,+用于强制显示数值的正负号等。
-
-
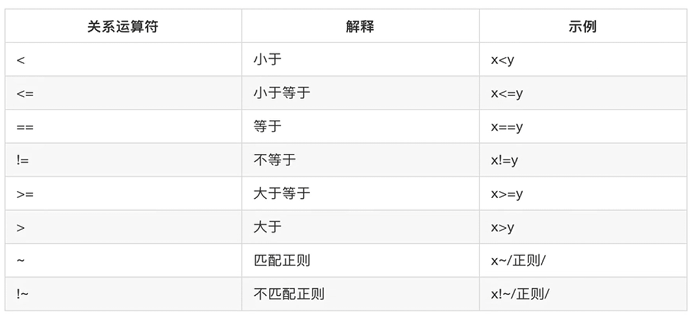
模式:BEGIN和END
-
awk中两种特殊的模式。 -
BEGIN模式中的代码会在处理任何输入数据之前执行,通常用于初始化操作,如设置变量的初始值、定义输出格式等 -
END模式中的代码则在所有输入数据处理完毕之后执行,常用于输出统计数据的汇总结果、执行清理操作等。
-
-
正则语法 : awk '/正则表达式/动作' 文件
-
awk支持使用正则表达式进行数据匹配和处理。通过在模式部分指定正则表达式,可以实现对符合条件的行进行特定的操作。例如,awk '/pattern/ {action}' filename表示对文件filename中匹配pattern正则表达式的行执行相应的action操作。
-
-